Die Logik des Denkens Spin-off 2: einige Verkettungsalgorithmen
Herausforderung:
Trennen Sie die oft wiederholten Abfolgen von Ereignissen in eine separate Kette, in der nichts überflüssig ist.Diese Aufgabe hat viele Lösungen. Oft verwendetes "Backen" - die Beziehungen, die oft verwendet werden, sind festgelegt, während andere geschwächt sind. Im Finale sollten Sie eine Kette erhalten, in der die am häufigsten wiederholten Ereignisse eng miteinander verbunden sind. Diese Lösung weist viele Mängel auf, darunter - niedrige Geschwindigkeit. Aber wir haben Identifikationswellen von Redozubov, wir können andere Algorithmen verwenden, die nach der ersten Wiederholung eine neue Kette bilden können. Beginnen wir mit einem einfachen.In der letzten NoteEin Verfahren zum Aufzeichnen aller Ereignisse in einer Speicherkette wird beschrieben. Lassen Sie das System einmal das Wort "Verfall" und zu einem anderen Zeitpunkt das Wort "Wasserfall" lesen. Diese beiden Wörter haben den gleichen Teil - das Ende von drei Buchstaben. Entsprechend den Bedingungen des Problems ist es notwendig, das Kettenpad hervorzuheben. Diese Kette hat keine Voraussetzungen, dh sie erkennt die entsprechende Eingabe leicht.Eine Lösung
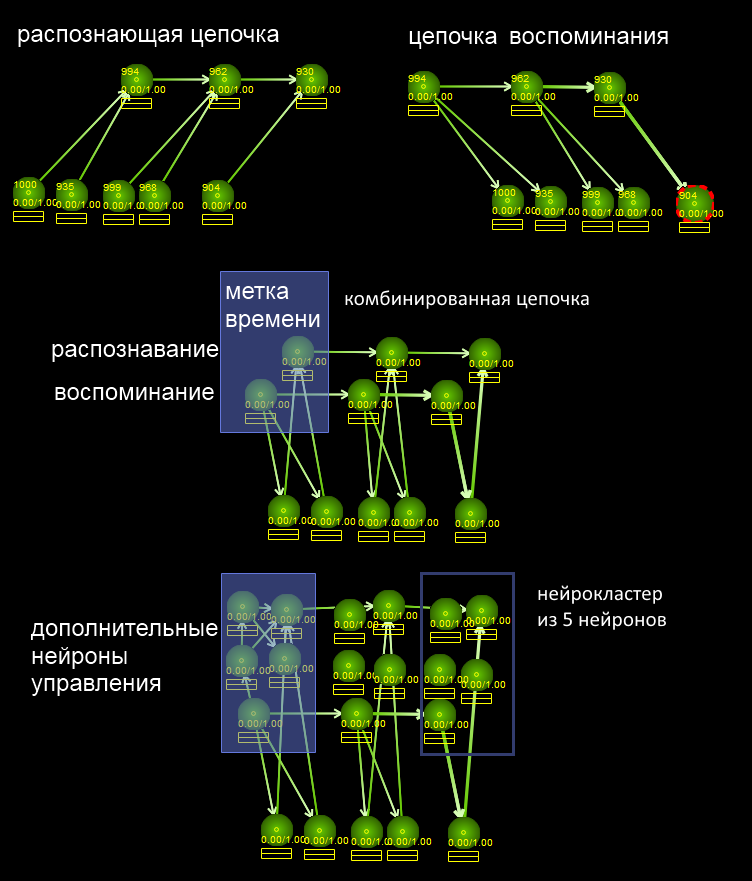 Wir teilen die Aufgabe in zwei Teile:1) Finden Sie zwei ähnliche Ereignisreihen (Sie müssen verstehen, dass ungefähr diese beiden Wörter ähnliche Sequenzen enthalten).2) Wählen Sie sie in einer separaten Kette aus („Pad“).Beginnen wir mit Teil 2. Wir komplizieren den Neurocluster mit Zeitstempeln, in denen alle Ereignisse in der Speicherkette gespeichert sind, wie im Bild gezeigt. Dank des erkennenden Teils (der Richtung der Verbindungen von den Attributen zum verallgemeinerten Zeitstempel) wird Teilaufgabe 1 gelöst - um eine Position mit gemeinsamen Attributen zu finden, und dank der Speicherkette mit nach unten verlinkenden Gliedern wird Teilaufgabe 2 gelöst. Die Lösung für Teilaufgabe 2 lautet: Wir werden zwei Wörter gleichzeitig abrufen wo sie gemeinsam haben. Das heißt, das System sendet eine Aktivierung durch Neuronen, die diesen Buchstaben entsprechen. Wenn der Buchstabe in beiden Wörtern gefunden wird, muss er gespeichert werden. Lassen Sie dazu die Erinnerung mit der halben Kraft geschehen. Wenn die Aktivierungsschwelle des Neurons T ist, sollte die Speicherkette 0,5 T des Aktionspotentials senden. Dann wird die Aktivierungsschwelle nur dann überschritten, wennwenn sich das Symptom in beiden Ketten traf. Danach wird das Symptom aktiviert. Dann können Sie den üblichen Algorithmus zum Auswendiglernen mit dem Code aus dem vorherigen Artikel verwenden - der Hippocampus erstellt eine Speicherkette und weist ihm die Zeichen zu, die beiden Ketten gemeinsam waren. Wir haben die Lösung auf die vorherige reduziert.In ENS (natürliches NS) kann eine „halbe Aktivierung“ erreicht werden, indem die Sendezeit (die Anzahl der eingetroffenen Spitzen), die Anzahl der Neurotransmitter oder möglicherweise inhibitorische Verbindungen (um 1T in 0,5T umzuwandeln) variiert werden.Unteraufgabe 1 ist etwas komplizierter, da sie mit Fuzzy-Erkennung funktionieren sollte. Das heißt, auch wenn es nur wenige gemeinsame Anzeichen in der Kette gibt, die irgendwo in der Mitte der Kette verloren gehen, sollten Sie diese Situation dennoch bemerken. Ich möchte Sie daran erinnern, dass sich Neuronen relativ gesehen in drei Modi befinden können: Ruhe, Senden eines einzelnen Signals und Hochfrequenzaktivierungsmodus. Es kann akzeptiert werden, dass "vollständige Erkennung" zum Übergang des Neurons in den Hochfrequenzaktivierungsmodus führt und die Fuzzy-Erkennung zu einer einzelnen Signalübertragung führt. Oder wir können davon ausgehen, dass der Neurocluster spezialisierte Neuronen enthält, von denen einige nur mit völliger Übereinstimmung und sicherer Erkennung funktionieren, und das andere Neuron funktioniert, wenn nur ein Teil der Merkmale erkannt wird. Es gibt viele Lösungen, die Hauptsache ist, das Auftreten einer Aktivierung auf den gewünschten Clustern irgendwie zu bemerken.
Wir teilen die Aufgabe in zwei Teile:1) Finden Sie zwei ähnliche Ereignisreihen (Sie müssen verstehen, dass ungefähr diese beiden Wörter ähnliche Sequenzen enthalten).2) Wählen Sie sie in einer separaten Kette aus („Pad“).Beginnen wir mit Teil 2. Wir komplizieren den Neurocluster mit Zeitstempeln, in denen alle Ereignisse in der Speicherkette gespeichert sind, wie im Bild gezeigt. Dank des erkennenden Teils (der Richtung der Verbindungen von den Attributen zum verallgemeinerten Zeitstempel) wird Teilaufgabe 1 gelöst - um eine Position mit gemeinsamen Attributen zu finden, und dank der Speicherkette mit nach unten verlinkenden Gliedern wird Teilaufgabe 2 gelöst. Die Lösung für Teilaufgabe 2 lautet: Wir werden zwei Wörter gleichzeitig abrufen wo sie gemeinsam haben. Das heißt, das System sendet eine Aktivierung durch Neuronen, die diesen Buchstaben entsprechen. Wenn der Buchstabe in beiden Wörtern gefunden wird, muss er gespeichert werden. Lassen Sie dazu die Erinnerung mit der halben Kraft geschehen. Wenn die Aktivierungsschwelle des Neurons T ist, sollte die Speicherkette 0,5 T des Aktionspotentials senden. Dann wird die Aktivierungsschwelle nur dann überschritten, wennwenn sich das Symptom in beiden Ketten traf. Danach wird das Symptom aktiviert. Dann können Sie den üblichen Algorithmus zum Auswendiglernen mit dem Code aus dem vorherigen Artikel verwenden - der Hippocampus erstellt eine Speicherkette und weist ihm die Zeichen zu, die beiden Ketten gemeinsam waren. Wir haben die Lösung auf die vorherige reduziert.In ENS (natürliches NS) kann eine „halbe Aktivierung“ erreicht werden, indem die Sendezeit (die Anzahl der eingetroffenen Spitzen), die Anzahl der Neurotransmitter oder möglicherweise inhibitorische Verbindungen (um 1T in 0,5T umzuwandeln) variiert werden.Unteraufgabe 1 ist etwas komplizierter, da sie mit Fuzzy-Erkennung funktionieren sollte. Das heißt, auch wenn es nur wenige gemeinsame Anzeichen in der Kette gibt, die irgendwo in der Mitte der Kette verloren gehen, sollten Sie diese Situation dennoch bemerken. Ich möchte Sie daran erinnern, dass sich Neuronen relativ gesehen in drei Modi befinden können: Ruhe, Senden eines einzelnen Signals und Hochfrequenzaktivierungsmodus. Es kann akzeptiert werden, dass "vollständige Erkennung" zum Übergang des Neurons in den Hochfrequenzaktivierungsmodus führt und die Fuzzy-Erkennung zu einer einzelnen Signalübertragung führt. Oder wir können davon ausgehen, dass der Neurocluster spezialisierte Neuronen enthält, von denen einige nur mit völliger Übereinstimmung und sicherer Erkennung funktionieren, und das andere Neuron funktioniert, wenn nur ein Teil der Merkmale erkannt wird. Es gibt viele Lösungen, die Hauptsache ist, das Auftreten einer Aktivierung auf den gewünschten Clustern irgendwie zu bemerken.Wann es zu tun ist
Die Frage ist, wann eine solche Suche durchgeführt werden muss. Es gibt verschiedene Ansätze:1) einen speziellen Schlafmodus - genauer gesagt „langsamer Schlaf“. Das System durchläuft alle Ereignisse, die es an einem Tag gelernt hat, und sucht nach Übereinstimmungen mit seinen anderen Erinnerungen. In diesem Fall verwendet das System Speicher, der in einer absteigenden Kette sendet, und gibt dann den Neuronen der Zeichen Zeit, Signale zu senden, die bereits „bis“ zu anderen Speichern reichen. Danach fasst er die Erinnerungen zusammen und sucht sie, die die größte Gesamtaktivierung aufweisen. Dann wählt er einen dieser Orte aus und startet die Unteraufgabe 2 - „Wähle die Kette“.2) ohne ein spezielles Schlafschema. Das System kann während der Wahrnehmung eine Suche im laufenden Betrieb durchführen - und wie sieht die aktuelle Situation aus? Tatsächlich erfolgt die Suche während des normalen Denkens aufgrund des Sendens von Signalen durch Neuronen automatisch. Das System kann nur auf die Erinnerungen achten, die viel mit der aktuellen Situation gemeinsam haben, und bei Bedarf die Analyse ausführen - die allgemeine Unterkette hervorheben.Ähnliche Algorithmen
Diese Algorithmen scheinen einfach zu sein, enthalten jedoch viele Feinheiten, noch mehr als beim schnellen Sortieralgorithmus, der, wie Sie wissen, lange Zeit nicht fehlerfrei geschrieben werden konnte.Diese Aufgabe ähnelt bekannten Aufgaben, beispielsweise der Suche nach gemeinsamen DNA-Teilsequenzen. Nur DNA in jedem Schritt kann nur ein Nukleotid haben, und im neuronalen Netzwerk kann es für jeden Zeitstempel eine beliebige Anzahl von Zeichen geben. Daher ist diese Aufgabe im Vergleich zur DNA-Suche ein allgemeinerer Fall. Wenn Sie versuchen, vorhandene Algorithmen zu übertragen und ein solches „Schlupfloch“ -Problem ohne neuronale Netze zu lösen, indem Sie die Zeichenlisten manipulieren, dreht sich Ihr Kopf - all diese verschachtelten Übereinstimmungslisten, Listen von Übereinstimmungssequenzen, andere Fragen. Die Lösung dieses Problems durch Senden von Aktivierungen an Neuronen ist viel einfacher - Neuronen existieren bereits, sie erledigen alles automatisch, ihr Speicher ist bereits zugewiesen, es werden keine verschachtelten Listen benötigt, es müssen nur einige Neuronen analysiert und die erforderlichen Algorithmen ausgeführt werden.Ich nenne die Unteraufgaben 1 und 2 Modi mit einer bzw. zwei führenden Ketten. Das heißt, "wie viele aktive absteigende Neuronen in den Speicherketten senden Signale, um Übereinstimmungen hervorzuheben." Wenn es nur eine solche zurückgerufene Kette gibt, sucht sie nach einem zweiten Kandidaten für die Überprüfung. Und wenn der Kandidat bereits gefunden wurde, können Sie ihn aktivieren und die Zeichen hervorheben. Solche Namen - "1 oder 2 führende Ketten" - ermöglichen es, diese Algorithmen namentlich und nicht "Teilaufgabe 1 oder 2" zu benennen. Der Modus mit einer führenden Kette kann auch als "Koinzidenz-Suchmodus" bezeichnet werden, und die beiden führenden Ketten können als Koinzidenz-Hervorhebungsmodus bezeichnet werden.Suche nach Übereinstimmungen ...
(1, 1 führende Kette) kann auf folgende Arten ausgeführt werden:1) Alle Erinnerungen, die sich während des Tages getroffen haben, linear anzeigen. Der Übergang zu Debugging-Zwecken in diesen Modus kann wie folgt erfolgen: Ein spezielles Unicode-Zeichen oder ein spezielles Wort wird in die Testsätze der Eingabedaten für das ANN eingefügt. Beim Lesen wechselt das ANN in den Modus „Slow Sleep“ und beginnt mit der Suche nach Übereinstimmungen. Die Bedeutung ist folgende: Sie füllten die ANN mit realen Daten und starteten Debugging-Algorithmen, um Verallgemeinerungen zu finden.2) keine lineare Suche zu verwenden, sondern die Analyse mit den interessantesten Situationen zu beginnen - mit denen, die die größte emotionale Farbe hatten. Diese Optimierung ist erforderlich, da diese Algorithmen sehr unersättlich sind. Bei Ratten scheint die Erinnerung an den Tag nur etwa zehnmal schneller zu sein als tagsüber. Schlaf braucht weniger Zeit als Wachheit. Bei einer gleichmäßigen Zeitverteilung über alle Speicher kann jeder Speicher so verwaltet werden, dass nur wenige ähnliche Situationen verglichen werden, von denen die meisten Müll und unbedeutende Zufälle sind. Daher ist es vorteilhaft, sich auf das Wichtigste zu konzentrieren und damit zu arbeiten. Wir können sagen, dass der Algorithmus eine weitere Schritt - 0 führende Kette hinzufügt. In diesem Schritt sollte das System das nächste Ereignis im Speicher mit maximaler Wichtigkeit auswählen.und geben Sie es an den nächsten Schritt weiter - machen Sie es zur Führungskette für die Suche nach Übereinstimmungen.3) Es ist möglich, Serifen aus der Zeit des Wachseins herzustellen - im Voraus, um Verbindungen zu den interessantesten Orten herzustellen, die nachts verglichen werden müssen.Ausgewählte Ketten mit Zufällen werden in Erinnerung behalten, aber in Zukunft können sie vergessen werden, wenn ihre Bedeutung mit der Zeit nachlässt.Vergessen
Durch das Vergessen wird der Neurocluster gelöscht - die Operation removeNC, die Umkehrung der Operation newNC. In der ENS werden Neuronen nirgendwo hingehen, sie werden nicht sterben, ihre Verbindungen werden einfach so stark geschwächt, dass sie nicht mehr auf ihre Zeichen reagieren und bereit sind, sich neu einzustellen, um sich an eine andere Kombination zu erinnern. In unserem Modell müssen solche Neuronen nicht gespeichert werden, sie können sofort entfernt werden - dies beschleunigt den Betrieb des ANN, reduziert den Speicherverbrauch und vereinfacht das Debuggen. Auf diese Weise können Sie den Speicherverbrauch möglicherweise um eine Größenordnung reduzieren.Parallelisierung
Um den Übergang vom 1- zum 2-Modus zu schaffen, habe ich zunächst versucht, Kontrollneuronen zu erstellen, die Signalumschaltung, Analyse und Modusänderung bewirken. Aber dann fand ich diese Arbeit zu niedrig und begann, zwingenden C ++ - Code zu schreiben - Code wie „Alle Cluster durchlaufen, analysieren, den gewünschten auswählen, überlegen, ob der Betriebsmodus geändert werden soll“.Die Frage nach der Leistung eines solchen Systems: Wenn Sie Neuronenhardware herstellen, können Sie diese parallelisieren (ja, zumindest auf Grafikkarten). Dann wird der Code mit der Steuerung von Neuronen und Verbindungen innerhalb des Clusters einfach und automatisch parallelisiert (dies ist nur ein Aktivierungspaket, das gemäß den Bedingungen der Aufgabe parallelisiert wird), aber der zwingende C ++ - Code muss jedes Mal unabhängig parallelisiert werden. Daher ist es für kleine neuronale Netze mit einem Thread einfacher, C ++ - Code zu schreiben, und für massiv parallele ANNs ist es besser, diese Arbeit innerhalb des ANN selbst auf die Schultern von Neuronen und die Verbindungen zwischen ihnen zu übertragen. Wir dürfen nicht vergessen, dass der "Zyklus durch alle Neuronen" oder der "Zyklus durch alle Neurocluster" in C ++ aus Sicht der Hardware ANN O (1) ist, ein einzelner Schritt zum Senden der Aktivierung. Daher kann es gesehen werdenSowohl 1VTs als auch 2VTs (führende Ketten) für ideal parallelisierte ANNs haben den gleichen Rechenaufwand.Fortsetzung: Primitive Prognose in ANNSource: https://habr.com/ru/post/de388725/
All Articles