Hat AlphaGo eine Chance im Spiel gegen Lee Sedol: Meinungen und Bewertungen von Profispielern in th
Das 9. Go-Pro-Spiel von Google und die KI von Google finden im März statt
 Kein Computer ist in der Lage, einen professionellen Spieler im asiatischen Brettspiel zu schlagen. Die Sache dreht sich um die Eigenschaften des Spiels: Es gibt zu viele Positionen und es ist schwierig, die menschliche Intuition algorithmisch zu beschreiben. Die Welt hatte bis zum 27. Januar ähnliche Ansichten. Vor einigen Tagen veröffentlichte Google Forschungsdaten aus seiner DeepMind-Abteilung . Es geht um das AlphaGo-System, das im Oktober letzten Jahres in fünf von fünf Spielen den professionellen Zweitspieler Dan Fan schlagen konnte.Trotzdem hatten Profispieler und Bekannte von Anfang an Fragen zur Qualität des Spiels. Hui ist dreimaliger Meister, aber er ist Europameister, bei dem das Niveau des Spiels nicht zu hoch ist. Nicht nur die Entscheidung des Spielers, die Kraft von AlphaGo zu demonstrieren, sondern auch einige Bewegungen in den Gruppen werfen Fragen auf.
Kein Computer ist in der Lage, einen professionellen Spieler im asiatischen Brettspiel zu schlagen. Die Sache dreht sich um die Eigenschaften des Spiels: Es gibt zu viele Positionen und es ist schwierig, die menschliche Intuition algorithmisch zu beschreiben. Die Welt hatte bis zum 27. Januar ähnliche Ansichten. Vor einigen Tagen veröffentlichte Google Forschungsdaten aus seiner DeepMind-Abteilung . Es geht um das AlphaGo-System, das im Oktober letzten Jahres in fünf von fünf Spielen den professionellen Zweitspieler Dan Fan schlagen konnte.Trotzdem hatten Profispieler und Bekannte von Anfang an Fragen zur Qualität des Spiels. Hui ist dreimaliger Meister, aber er ist Europameister, bei dem das Niveau des Spiels nicht zu hoch ist. Nicht nur die Entscheidung des Spielers, die Kraft von AlphaGo zu demonstrieren, sondern auch einige Bewegungen in den Gruppen werfen Fragen auf.Algorithmus
Guo gilt seit langem als ein Spiel zum Trainieren, bei dem künstliche Intelligenz aufgrund des riesigen Suchraums und der Komplexität der Auswahl der Züge schwierig ist. Go gehört zur Klasse der Spiele mit perfekten Informationen, dh die Spieler sind sich aller Bewegungen bewusst, die andere Spieler zuvor gemacht haben. Die Lösung für das Problem, das Ergebnis des Spiels zu finden, besteht darin, die optimale Wertfunktion in einem Suchbaum zu berechnen, der ungefähr b d mögliche Züge enthält. Hier ist b die Anzahl der richtigen Züge in jeder Position und d die Länge des Spiels. Für Schach sind diese Werte b ≈ 35 und d ≈ 80, und eine vollständige Suche ist nicht möglich. Daher werden die Positionen der Figuren ausgewertet und anschließend die Bewertung bei der Suche berücksichtigt. 1996 gewann ein Computer zum ersten Mal Schach gegen einen Champion, und seit 2005 konnte kein Champion einen Computer schlagen.Für go b ≈ 250, d ≈ 150. Die möglichen Positionen von Steinen auf einem Standardbrett sind mehr als Googol (10 100 ) mal höher als im Schach. Die Anzahl der möglichen Positionen ist größer als die Atome im Universum. Erschwerend kommt hinzu, dass es aufgrund der Komplexität des Spiels schwierig ist, den Wert von Zuständen vorherzusagen. Zwei Spieler legen zweifarbige Steine auf ein Brett einer bestimmten Größe, das Standardfeld besteht aus 19 × 19 Linien. Die Regeln variieren in Details, aber das Hauptziel des Spiels ist einfach: Sie müssen einen größeren Bereich auf dem Brett mit Steinen Ihrer Farbe umzäunen als Ihr Gegner.Bestehende Programme können auf Amateurebene abgespielt werden. Sie verwenden die Suche im Monte-Carlo-Baum, um den Wert jedes Zustands im Suchbaum zu bewerten. Die Programme enthalten auch Richtlinien, die die Bewegungen starker Spieler vorhersagen.In jüngster Zeit konnten tiefe Faltungs-Neuronale Netze gute Ergebnisse bei der Gesichtserkennung und Bildklassifizierung erzielen. Bei Google hat AI sogar gelernt, 49 alte Atari-Spiele alleine zu spielen . In AlphaGo interpretieren ähnliche neuronale Netze die Position von Steinen auf dem Brett, was bei der Bewertung und Auswahl von Bewegungen hilft. Bei Google verfolgten die Forscher folgenden Ansatz: Sie verwendeten Wertschöpfungsnetzwerke und Richtliniennetzwerke. Dann werden diese tiefen neuronalen Netze sowohl auf einer Gruppe von Personengruppen als auch auf einem Spiel gegen ihre Kopien trainiert. Neu ist auch eine Suche, die die Monte-Carlo-Methode mit Netzwerken von Politik und Wert kombiniert. Trainingsschema und Architektur für neuronale Netze.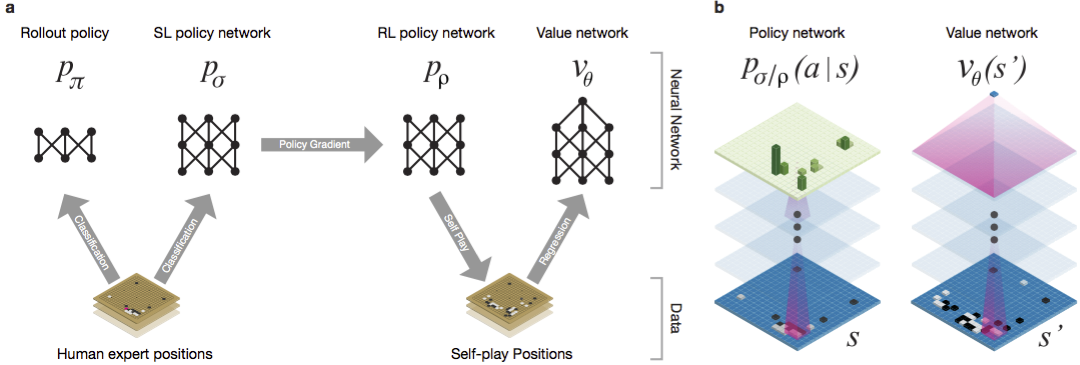 Neuronale Netze wurden in mehreren Stufen des maschinellen Lernens trainiert. Zunächst wurde ein kontrolliertes Training des politischen Netzwerks direkt unter Verwendung der Bewegungen menschlicher Akteure durchgeführt. Ein weiteres politisches Netzwerk wurde verstärkt. Der zweite spielte mit dem ersten und optimierte ihn so, dass sich die Politik auf einen Sieg verlagerte und nicht nur auf Vorhersagen von Zügen. Schließlich wurde eine Schulung durchgeführt, die durch ein Wertschöpfungsnetzwerk verstärkt wurde, das den Gewinner von Spielen vorhersagt, die von politischen Netzwerken gespielt werden. Das Endergebnis ist AlphaGo, eine Kombination aus der Monte-Carlo-Methode und Netzwerken von Politik und Wert. Das Ergebnis der korrekten Vorhersage des nächsten Schrittes wurde in 57% der Fälle erzielt. Vor AlphaGo lag das beste Ergebnis bei 44% .160.000 Spiele mit 29,4 Millionen Positionen vom KGS- Server wurden als Eingabe für das Training verwendet. Die Partys der Spieler vom sechsten bis zum neunten Dan wurden genommen. Eine Million Stellen wurden für Tests zugewiesen, und das Training selbst wurde für 28,4 Millionen Stellen durchgeführt. Die Stärke und Genauigkeit von Netzwerkrichtlinien und -werten.
Damit die Algorithmen funktionieren, benötigen sie mehrere Größenordnungen mehr Rechenleistung als bei der herkömmlichen Suche. AlphaGo ist ein asynchrones Multithread-Programm, das Simulationen auf den Kernen des Zentralprozessors durchführt und Netzwerke von Richtlinien und Werten auf Videochips ausführt. Die endgültige Version sah aus wie eine 40-Thread-Anwendung, die auf 48 Prozessoren (wahrscheinlich separate Kerne oder sogar Hyper-Threading) und 8 Grafikbeschleunigern ausgeführt wird. Außerdem wurde eine verteilte Version von AlphaGo erstellt, die mehrere Computer, 40 Suchströme, 1202 Kerne und 176 Videobeschleuniger verwendet.
Neuronale Netze wurden in mehreren Stufen des maschinellen Lernens trainiert. Zunächst wurde ein kontrolliertes Training des politischen Netzwerks direkt unter Verwendung der Bewegungen menschlicher Akteure durchgeführt. Ein weiteres politisches Netzwerk wurde verstärkt. Der zweite spielte mit dem ersten und optimierte ihn so, dass sich die Politik auf einen Sieg verlagerte und nicht nur auf Vorhersagen von Zügen. Schließlich wurde eine Schulung durchgeführt, die durch ein Wertschöpfungsnetzwerk verstärkt wurde, das den Gewinner von Spielen vorhersagt, die von politischen Netzwerken gespielt werden. Das Endergebnis ist AlphaGo, eine Kombination aus der Monte-Carlo-Methode und Netzwerken von Politik und Wert. Das Ergebnis der korrekten Vorhersage des nächsten Schrittes wurde in 57% der Fälle erzielt. Vor AlphaGo lag das beste Ergebnis bei 44% .160.000 Spiele mit 29,4 Millionen Positionen vom KGS- Server wurden als Eingabe für das Training verwendet. Die Partys der Spieler vom sechsten bis zum neunten Dan wurden genommen. Eine Million Stellen wurden für Tests zugewiesen, und das Training selbst wurde für 28,4 Millionen Stellen durchgeführt. Die Stärke und Genauigkeit von Netzwerkrichtlinien und -werten.
Damit die Algorithmen funktionieren, benötigen sie mehrere Größenordnungen mehr Rechenleistung als bei der herkömmlichen Suche. AlphaGo ist ein asynchrones Multithread-Programm, das Simulationen auf den Kernen des Zentralprozessors durchführt und Netzwerke von Richtlinien und Werten auf Videochips ausführt. Die endgültige Version sah aus wie eine 40-Thread-Anwendung, die auf 48 Prozessoren (wahrscheinlich separate Kerne oder sogar Hyper-Threading) und 8 Grafikbeschleunigern ausgeführt wird. Außerdem wurde eine verteilte Version von AlphaGo erstellt, die mehrere Computer, 40 Suchströme, 1202 Kerne und 176 Videobeschleuniger verwendet.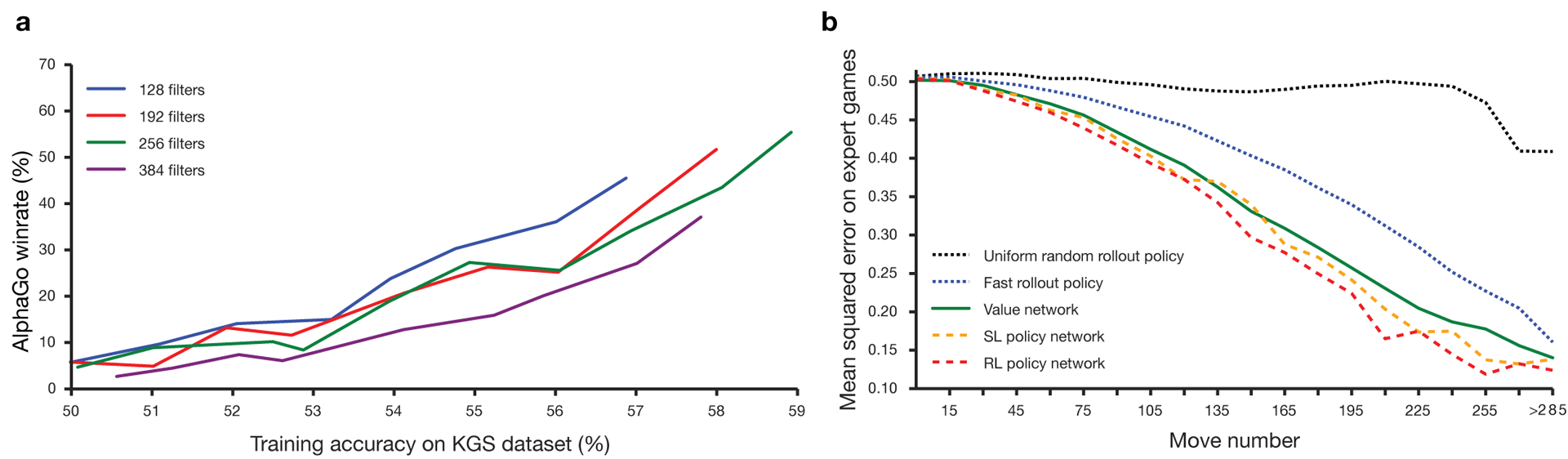 Den vollständigen DeepMind-Bericht finden Sie im Dokument . Suche nach Monte Carlo in AlphaGo.
Um die Fähigkeiten von AlphaGo zu bewerten, wurden interne Übereinstimmungen mit anderen Versionen des Programms sowie anderen ähnlichen Produkten durchgeführt. Ein Vergleich wurde mit so beliebten kommerziellen Programmen wie Crazy Stone und Zen sowie den stärksten Open-Source-Projekten Pachi und Fuego durchgeführt. Alle basieren auf leistungsstarken Monte-Carlo-Algorithmen. Aber auch AlphaGo im Vergleich zu Nicht-Monte-Carlo-GnuGo. Die Programme erhielten 5 Sekunden pro Bewegung. Es wurde ein Vergleich sowohl des auf einem einzelnen Computer ausgeführten AlphaGo als auch der verteilten Version des Algorithmus durchgeführt.
Den vollständigen DeepMind-Bericht finden Sie im Dokument . Suche nach Monte Carlo in AlphaGo.
Um die Fähigkeiten von AlphaGo zu bewerten, wurden interne Übereinstimmungen mit anderen Versionen des Programms sowie anderen ähnlichen Produkten durchgeführt. Ein Vergleich wurde mit so beliebten kommerziellen Programmen wie Crazy Stone und Zen sowie den stärksten Open-Source-Projekten Pachi und Fuego durchgeführt. Alle basieren auf leistungsstarken Monte-Carlo-Algorithmen. Aber auch AlphaGo im Vergleich zu Nicht-Monte-Carlo-GnuGo. Die Programme erhielten 5 Sekunden pro Bewegung. Es wurde ein Vergleich sowohl des auf einem einzelnen Computer ausgeführten AlphaGo als auch der verteilten Version des Algorithmus durchgeführt. Laut den Entwicklern zeigten die Ergebnisse, dass AlphaGo viel stärker ist als alle früheren Go-Programme. AlphaGo gewann 494 von 495 Spielen, was 99,8% der Spiele gegen andere ähnliche Produkte entspricht. Go-Regeln erlauben ein Handicap , Handicap: Bis zu 9 schwarze Steine können auf dem Spielfeld gesetzt werden, bevor sich Weiß bewegt. Aber selbst mit 4 Handicap-Steinen gewann die AlphaGo-Einzelmaschine 77%, 86% und 99% der Zeit gegen Crazy Stone, Zen und Pachi. Die verteilte Version von AlphaGo war deutlich stärker: In 77% der Spiele besiegte sie die Einzelmaschinenversion und in 100% der Spiele - alle anderen Programme. AlphaGo gegen andere Programme.
Laut den Entwicklern zeigten die Ergebnisse, dass AlphaGo viel stärker ist als alle früheren Go-Programme. AlphaGo gewann 494 von 495 Spielen, was 99,8% der Spiele gegen andere ähnliche Produkte entspricht. Go-Regeln erlauben ein Handicap , Handicap: Bis zu 9 schwarze Steine können auf dem Spielfeld gesetzt werden, bevor sich Weiß bewegt. Aber selbst mit 4 Handicap-Steinen gewann die AlphaGo-Einzelmaschine 77%, 86% und 99% der Zeit gegen Crazy Stone, Zen und Pachi. Die verteilte Version von AlphaGo war deutlich stärker: In 77% der Spiele besiegte sie die Einzelmaschinenversion und in 100% der Spiele - alle anderen Programme. AlphaGo gegen andere Programme.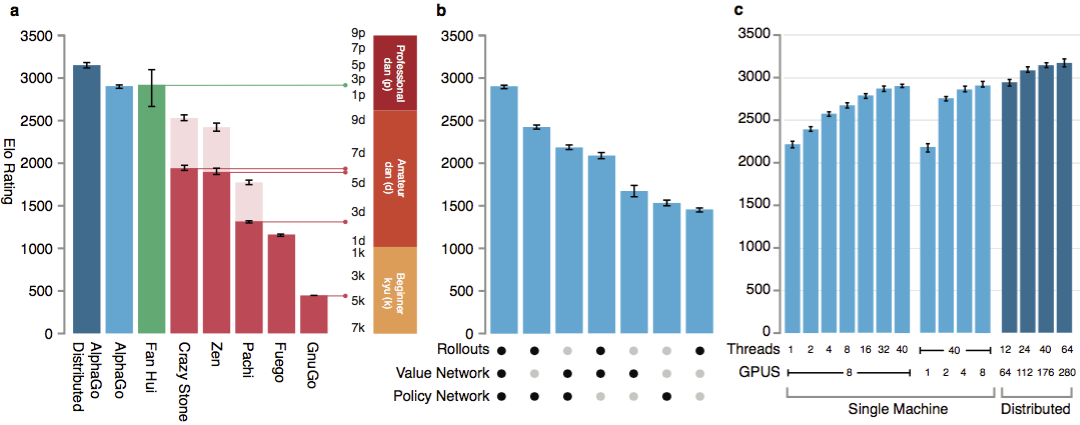 Schließlich wurde das erstellte Produkt mit einer Person verglichen. Profispieler 2 Dan kämpfte gegen die verteilte Version von AlphaGo, Fan Hui, dem Gewinner der Go-Europameisterschaft 2013, 2014 und 2015. Die Spiele wurden unter Beteiligung eines Richters der British Federation of Go und des Herausgebers der Zeitschrift Nature abgehalten. Im Zeitraum vom 5. bis 9. Oktober 2015 fanden 5 Spiele statt. Alle haben den Google DeepMind-Entwicklungsalgorithmus gewonnen. Es waren diese Spiele, die zu der Aussage führten, dass der Computer als erster in der Lage war, einen professionellen Spieler zu schlagen. Zusätzlich zu 5 offiziellen Parteien wurden 5 inoffizielle Parteien abgehalten, die nicht zählten. Fan gewann zwei von ihnen.Erhältlich Aufnahme bewegt fünf Spiele , in einem Web - Widget sehen , und Videos auf YouTube .
Schließlich wurde das erstellte Produkt mit einer Person verglichen. Profispieler 2 Dan kämpfte gegen die verteilte Version von AlphaGo, Fan Hui, dem Gewinner der Go-Europameisterschaft 2013, 2014 und 2015. Die Spiele wurden unter Beteiligung eines Richters der British Federation of Go und des Herausgebers der Zeitschrift Nature abgehalten. Im Zeitraum vom 5. bis 9. Oktober 2015 fanden 5 Spiele statt. Alle haben den Google DeepMind-Entwicklungsalgorithmus gewonnen. Es waren diese Spiele, die zu der Aussage führten, dass der Computer als erster in der Lage war, einen professionellen Spieler zu schlagen. Zusätzlich zu 5 offiziellen Parteien wurden 5 inoffizielle Parteien abgehalten, die nicht zählten. Fan gewann zwei von ihnen.Erhältlich Aufnahme bewegt fünf Spiele , in einem Web - Widget sehen , und Videos auf YouTube .Kritik von Profispielern
Die Wahl eines Profispielers und das schwache Spiel des Champions werden in Frage gestellt. Die gewählten Regeln sind ebenfalls unklar: eine Stunde pro Spiel anstelle mehrerer Stunden ernsthafter Spiele. Das Format wurde jedoch von Hui selbst gewählt. Im März wird AlphaGo gegen Lee Sedola spielen. Kann der Algorithmus den koreanischen Profi des neunten Dan schlagen, der als einer der besten Spieler der Welt gilt? Auf dem Spiel steht eine Million Dollar. Wenn eine Person gewinnt, erhält Li Sedol sie. Wenn der Algorithmus gewinnt, geht sie an einen wohltätigen Zweck.Forscher sagen, dass das AlphaGo-System während des Kampfes mit Menschen im Oktober während eines historischen Spiels mit Kasparov tausende Male weniger Positionen als Deep Blue in Betracht gezogen hat. Stattdessen verwendete das Programm ein Netzwerk von Richtlinien für intelligentere Entscheidungen und ein Netzwerk von Werten, um Positionen genauer zu messen. Vielleicht ist dieser Ansatz näher an der Art und Weise, wie Menschen spielen, sagen die Forscher. Darüber hinaus wurde das Deep Blue-Bewertungssystem manuell programmiert, während die neuronalen AlphaGo-Netze direkt aus den Spielen heraus trainiert wurden, wobei universelle Algorithmen für überwachtes Lernen und verstärkendes Lernen verwendet wurden. Lee Sedoll wird sich im März gegen AlphaGo versuchen. Professionelle Spieler haben unterschiedliche Sichtweisen. Es scheint einigen, dass Google speziell keinen sehr starken Spieler ausgewählt hat, jemand ist sich sicher, dass Sedol diesen März verlieren wird.Kim Mengwang (9. Dan), einer der stärksten englischsprachigen Profispieler, glaubt, dass Fan Hui nicht mit voller Kraft gespielt hat. In der 51. Minute des Videos gibt er ein konkretes Beispiel aus der zweiten Folge. Fan hat möglicherweise beide mit einem schwächeren gespielt, um die Leistung des Computers zu testen, sagt Kim. Mengwan gab zu, dass AlphaGo ein schockierend mächtiges Programm ist, aber es ist unwahrscheinlich, dass Lee Sedol besiegt wird.Schiedsrichter Toby Manning erzählte dem British Go Journal von dem Spiel. Er analysierte alle fünf Spiele und hob einige Punkte hervor. AlphaGo hat im zweiten, dritten und vierten Spiel Fehler gemacht, aber Fan hat sie nicht verwendet. Der dreifache Europameister antwortete mit seinem eigenen. Der Artikel in der Zeitschrift endet mit einer allgemeinen positiven Bewertung von AlphaGo: Das Programm ist stark, aber es ist nicht klar, wie viel.Außerdem erhielt ich bei der Vorbereitung des Materials Kommentare von russischen Fachleuten und Go-Liebhabern. Alexander Dinerstein (Kasan), dritter Dan (Profi), siebenmaliger Europameister:
Professionelle Spieler haben unterschiedliche Sichtweisen. Es scheint einigen, dass Google speziell keinen sehr starken Spieler ausgewählt hat, jemand ist sich sicher, dass Sedol diesen März verlieren wird.Kim Mengwang (9. Dan), einer der stärksten englischsprachigen Profispieler, glaubt, dass Fan Hui nicht mit voller Kraft gespielt hat. In der 51. Minute des Videos gibt er ein konkretes Beispiel aus der zweiten Folge. Fan hat möglicherweise beide mit einem schwächeren gespielt, um die Leistung des Computers zu testen, sagt Kim. Mengwan gab zu, dass AlphaGo ein schockierend mächtiges Programm ist, aber es ist unwahrscheinlich, dass Lee Sedol besiegt wird.Schiedsrichter Toby Manning erzählte dem British Go Journal von dem Spiel. Er analysierte alle fünf Spiele und hob einige Punkte hervor. AlphaGo hat im zweiten, dritten und vierten Spiel Fehler gemacht, aber Fan hat sie nicht verwendet. Der dreifache Europameister antwortete mit seinem eigenen. Der Artikel in der Zeitschrift endet mit einer allgemeinen positiven Bewertung von AlphaGo: Das Programm ist stark, aber es ist nicht klar, wie viel.Außerdem erhielt ich bei der Vorbereitung des Materials Kommentare von russischen Fachleuten und Go-Liebhabern. Alexander Dinerstein (Kasan), dritter Dan (Profi), siebenmaliger Europameister:Deep Blue . , , , . Google . .
4-4 ( -, starpoint ). . : 3-3, 3-4, 5-3, , , , . , . .
, , . . – , . , - . . 20-30 , , , , . , . , . .
, - 2016 (EGC), in dessen Rahmen immer ein Computerprogrammturnier stattfindet. Die Russische Föderation von Go lud alle stärksten Programme zur Teilnahme am Turnier ein. Wenn sie die Einladung annehmen, spielen Google- und Facebook-Programme möglicherweise zum ersten Mal untereinander. Letzterer geht im Gegensatz zu seinem Konkurrenten einen ehrlichen Weg. Der DarkForest-Bot spielt Tausende von Spielen auf dem KGS-Server . Die stärkste Version nähert sich dem sechsten Dan auf dem Server. Dies ist ein sehr gutes Niveau. Fan Hui und Spieler seines Levels - dies ist ungefähr der achte Dan auf dem Server (von neun möglichen). Der Unterschied liegt bei zwei steinernen Nachteilen. Mit einem solchen Unterschied kann ein Programm manchmal eine Person wirklich schlagen. Wenn zu gleichen Bedingungen, dann ungefähr in einer Charge von zehn.
Maxim Podolyak (St. Petersburg), Vizepräsident der Russischen Föderation von Go:, , , , , , , , . , Google : , . , . : , , , . , : , . Google . , . ? ?
Alexander Krainov (Moskau), Liebhaber des Spiels gehen:Aufgrund meiner beruflichen Tätigkeit kenne ich die Situation „von der anderen Seite“ recht gut.
Im Jahr 2012 gab es einen Quantensprung beim maschinellen Lernen im Allgemeinen. Die Datenmenge für das Training, das Niveau der Algorithmen und die Leistung für das Training haben ein solches Niveau erreicht, dass künstliche neuronale Netze (die seit langem als Prinzip entwickelt wurden) fantastische Ergebnisse lieferten.
Der grundlegende Unterschied zwischen dem Training in neuronalen Netzen besteht darin, dass ihnen keine Eingabefaktoren zugewiesen werden müssen (im Fall von go erklären Sie beispielsweise, welche Formen gut sind). Im Limit können ihnen sogar die Regeln nicht erklärt werden. Die Hauptsache ist, eine große Anzahl positiver (Bewegungen der Gewinnerseite) und negativer (Bewegungen der Verliererseite) Beispiele zu nennen. Und das Netzwerk wird sich selbst lernen.
, , . . : , , ( ) , .
, .
, , , . . . . , , .
Was Lee Sedol selbst sagt
Professionelle Go-Spieler kämpfen nicht um den Weltmeistertitel, sondern um Titel. Die Anerkennung und der Status des Meisters werden durch die Anzahl der Titel bestimmt, die er im Laufe des Jahres erhalten konnte. Lee Sedol ist einer der fünf stärksten Go-Spieler der Welt, und im März dieses Jahres muss er mit dem AlphaGo-System kämpfen.Der koreanische Meister selbst sagt voraus, dass er mit 4: 1 oder 5: 0 gewinnen wird. Aber nach 2-3 Jahren wird Google Rache nehmen wollen, und dann wird das Spiel mit der aktualisierten Version von AlphaGo interessanter, sagt Lee.
Die Aufgabe, einen solchen Algorithmus zu erstellen, wirft neue Fragen darüber auf, was Lernen und Denken sind. Wie M. Emelyanov erinnert , wird die dritte Stufe der Fertigkeit (Pin) von oben gemäß der alten chinesischen Klassifikation als „vollständige Klarheit“ bezeichnet. Ein solches Level des Spiels legt nahe, dass Entscheidungen intuitiv getroffen werden, ohne oder mit nur geringen Optionen. Einer der stärksten Meister des 20. Jahrhunderts, Guo Seigen, sagte, es schien ihm, als hätte er gegen den „Go-God“ mit zwei oder drei Handicap-Steinen gewonnen. Seigan glaubte, dass er fast die Grenze des Verständnisses des Spiels erreicht hatte. Kann ein neuronales Netzwerk dies erreichen? Vielleicht ist die menschliche Intuition ein von der Natur festgelegter Algorithmus?Der Autor dankt Alexander Dinerstein und der Öffentlichkeit go_secrets für Kommentare und Hilfe bei der Veröffentlichung.Source: https://habr.com/ru/post/de389825/
All Articles