 So kam es, dass die Hauptsprache für die Arbeit mit Mikrocontrollern C ist. Viele große Projekte sind darauf geschrieben. Aber das Leben steht nicht still. Moderne Entwicklungstools können C ++ seit langem bei der Entwicklung von Software für eingebettete Systeme verwenden. Dieser Ansatz ist jedoch immer noch selten. Vor nicht allzu langer Zeit habe ich versucht, C ++ zu verwenden, wenn ich an einem anderen Projekt gearbeitet habe. Ich werde in diesem Artikel über diese Erfahrung sprechen.
So kam es, dass die Hauptsprache für die Arbeit mit Mikrocontrollern C ist. Viele große Projekte sind darauf geschrieben. Aber das Leben steht nicht still. Moderne Entwicklungstools können C ++ seit langem bei der Entwicklung von Software für eingebettete Systeme verwenden. Dieser Ansatz ist jedoch immer noch selten. Vor nicht allzu langer Zeit habe ich versucht, C ++ zu verwenden, wenn ich an einem anderen Projekt gearbeitet habe. Ich werde in diesem Artikel über diese Erfahrung sprechen.Eintrag
Der größte Teil meiner Arbeit mit Mikrocontrollern ist mit C verbunden. Zuerst waren es Kundenanforderungen, und dann wurde es nur eine Gewohnheit. Zur gleichen Zeit, wenn es um Anwendungen für Windows ging, wurde dort zuerst C ++ und dann allgemein C # verwendet.Es gab lange keine Fragen zu C oder C ++. Selbst die Veröffentlichung der nächsten Version von Keils MDK mit C ++ - Unterstützung für ARM hat mich nicht sonderlich gestört. Wenn Sie sich Keil-Demo-Projekte ansehen, wird dort alles in C geschrieben. Gleichzeitig wird C ++ zusammen mit dem Blinky-Projekt in einen separaten Ordner verschoben. CMSIS und LPCOpen sind ebenfalls in C geschrieben. Und wenn „jeder“ C verwendet, gibt es einige Gründe.Aber viel hat sich geändert .Net Micro Framework. Wenn jemand es nicht weiß, handelt es sich um eine .NET-Implementierung, mit der Sie Anwendungen für Mikrocontroller in C # in Visual Studio schreiben können. Sie können ihn in näher kennenlernendiese Artikel.Daher wird .Net Micro Framework mit C ++ geschrieben. Beeindruckt davon beschloss ich, ein anderes Projekt in C ++ zu schreiben. Ich muss sofort sagen, dass ich keine eindeutigen Argumente für C ++ gefunden habe, aber es gibt einige interessante und nützliche Punkte in diesem Ansatz.Was ist der Unterschied zwischen C- und C ++ - Projekten?
Einer der Hauptunterschiede zwischen C und C ++ besteht darin, dass die zweite eine objektorientierte Sprache ist. Bekannte Einkapselung, Polymorphismus und Vererbung sind hier an der Tagesordnung. C ist eine prozedurale Sprache. Es gibt nur Funktionen und Prozeduren, und für die logische Gruppierung des Codes werden Module verwendet (ein Paar von .h + .c). Wenn Sie sich jedoch genau ansehen, wie C in Mikrocontrollern verwendet wird, können Sie den üblichen objektorientierten Ansatz erkennen.Schauen wir uns den Code für die Arbeit mit LEDs aus dem Keil-Beispiel für MCB1000 an ( Keil_v5 \ ARM \ Boards \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo ):LED.h:#ifndef __LED_H
#define __LED_H
#define LED_NUM 8
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:#include "LPC11xx.h"
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6);
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
Wenn Sie genau hinschauen, können Sie eine Analogie zu OOP geben. LED ist ein Objekt mit einer öffentlichen Konstante, einem Konstruktor, drei öffentlichen Methoden und einem privaten Feld:class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED();
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
Trotz der Tatsache, dass der Code in C geschrieben ist, verwendet er das Paradigma der Objektprogrammierung. Eine .C-Datei ist ein Objekt, mit dem Sie die Implementierungsmechanismen der in der .h-Datei beschriebenen öffentlichen Methoden einkapseln können. Aber hier gibt es keine Vererbung und damit auch Polymorphismus.Der größte Teil des Codes in den Projekten, die ich getroffen habe, ist im gleichen Stil geschrieben. Und wenn der OOP-Ansatz verwendet wird, warum dann nicht eine Sprache verwenden, die ihn vollständig unterstützt? Gleichzeitig ändert sich beim Wechsel zu C ++ im Großen und Ganzen nur die Syntax, nicht jedoch die Entwicklungsprinzipien.Betrachten Sie ein anderes Beispiel. Angenommen, wir haben ein Gerät, das einen Temperatursensor verwendet, der über I2C angeschlossen ist. Es wurde jedoch eine neue Version des Geräts veröffentlicht, und derselbe Sensor ist jetzt mit dem SPI verbunden. Was zu tun ist? Die erste und die zweite Version des Geräts müssen unterstützt werden. Dies bedeutet, dass der Code diese Änderungen flexibel berücksichtigen muss. In C können Sie #define-Vordefinitionen verwenden, um das Schreiben von zwei nahezu identischen Dateien zu vermeiden. Zum Beispiel#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
usw.In C ++ können Sie dieses Problem etwas eleganter lösen. Schnittstelle erstellenclass ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
und mache 2 Implementierungenclass Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
Und dann verwenden Sie diese oder jene Implementierung abhängig von der Revision:class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
Es scheint, dass der Unterschied zwischen C- und C ++ - Code nicht sehr groß ist. Die objektorientierte Option sieht noch umständlicher aus. Sie können jedoch eine flexiblere Entscheidung treffen.Bei Verwendung von C können zwei Hauptlösungen unterschieden werden:- Verwenden Sie #define wie oben gezeigt. Diese Option ist nicht sehr gut, da sie die Verantwortung des Moduls „untergräbt“. Es stellt sich heraus, dass er für mehrere Revisionen des Projekts verantwortlich ist. Wenn es viele solcher Dateien gibt, wird es ziemlich schwierig, sie zu pflegen.
- 2 , C++. “” , . , #ifdef. , , . , . , , .
Die Verwendung von Polymorphismus ergibt ein schöneres Ergebnis. Einerseits löst jede Klasse ein klares atomares Problem, andererseits ist der Code nicht verschmutzt und leicht zu lesen.Die „Verzweigung“ des Codes in der Revision muss im ersten und zweiten Fall noch durchgeführt werden. Die Verwendung von Polymorphismus erleichtert jedoch die Übertragung der Verzweigungsstelle zwischen den Programmebenen, ohne den Code mit unnötigem #ifdef zu überladen.Die Verwendung von Polymorphismus macht es einfach, eine noch interessantere Entscheidung zu treffen.Angenommen, es wird eine neue Version veröffentlicht, in der beide Temperatursensoren installiert sind.Mit demselben Code mit minimalen Änderungen können Sie Ihre SPI- und I2C-Implementierung in Echtzeit auswählen, indem Sie einfach die Init- (& Temperatur-) Methode verwenden.Das Beispiel ist sehr vereinfacht, aber in einem realen Projekt habe ich denselben Ansatz verwendet, um dasselbe Protokoll auf zwei verschiedenen physischen Datenübertragungsschnittstellen zu implementieren. Dies machte es einfach, die Wahl der Schnittstelle in den Geräteeinstellungen zu treffen.Bei alledem bleibt der Unterschied zwischen der Verwendung von C und C ++ jedoch nicht sehr groß. Die Vorteile von C ++ in Bezug auf OOP liegen nicht auf der Hand und stammen aus der Kategorie "Amateur". Die Verwendung von C ++ in Mikrocontrollern hat jedoch ziemlich ernsthafte Probleme.Warum ist die Verwendung von C ++ gefährlich?
Der zweite wichtige Unterschied zwischen C und C ++ ist die Speichernutzung. Die C-Sprache ist meist statisch. Alle Funktionen und Prozeduren haben feste Adressen, und die Arbeit mit einem Bündel wird nur bei Bedarf ausgeführt. C ++ ist eine dynamischere Sprache. Normalerweise impliziert seine Verwendung aktive Arbeit mit Zuweisung und Freigabe von Speicher. Dies ist, was C ++ gefährlich ist. Mikrocontroller verfügen nur über sehr wenige Ressourcen, daher ist die Kontrolle über sie wichtig. Die unkontrollierte Nutzung des Arbeitsspeichers ist mit Schäden an den dort gespeicherten Daten und solchen „Wundern“ in der Programmarbeit behaftet, die niemandem erscheinen werden. Viele Entwickler sind auf solche Probleme gestoßen.Wenn Sie sich die obigen Beispiele genau ansehen, können Sie feststellen, dass Klassen keine Konstruktoren und Destruktoren haben. Dies liegt daran, dass sie niemals dynamisch erstellt werden.Bei Verwendung des dynamischen Speichers (und bei Verwendung des neuen Speichers) wird immer die Malloc-Funktion aufgerufen, die die erforderliche Anzahl von Bytes aus dem Heap zuweist. Selbst wenn Sie darüber nachdenken (obwohl es sehr schwierig ist) und die Verwendung des Speichers steuern, kann das Problem der Fragmentierung auftreten.Ein Bündel kann als Array dargestellt werden. Zum Beispiel weisen wir ihm 20 Bytes zu: Jedes Mal, wenn Speicher zugewiesen wird, wird der gesamte Speicher (von links nach rechts oder von rechts nach links - dies ist nicht so wichtig) auf das Vorhandensein einer bestimmten Anzahl nicht besetzter Bytes gescannt. Außerdem sollten sich diese Bytes alle in der Nähe befinden:
weisen wir ihm 20 Bytes zu: Jedes Mal, wenn Speicher zugewiesen wird, wird der gesamte Speicher (von links nach rechts oder von rechts nach links - dies ist nicht so wichtig) auf das Vorhandensein einer bestimmten Anzahl nicht besetzter Bytes gescannt. Außerdem sollten sich diese Bytes alle in der Nähe befinden: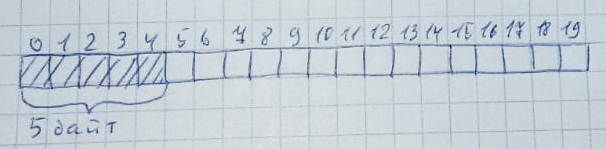 Wenn der Speicher nicht mehr benötigt wird, kehrt er in seinen ursprünglichen Zustand zurück:Dies kann sehr leicht passieren, wenn genügend freie Bytes vorhanden sind, diese jedoch nicht in einer Reihe angeordnet sind. Lassen Sie 10 Zonen mit jeweils 2 Bytes zuweisen:
Wenn der Speicher nicht mehr benötigt wird, kehrt er in seinen ursprünglichen Zustand zurück:Dies kann sehr leicht passieren, wenn genügend freie Bytes vorhanden sind, diese jedoch nicht in einer Reihe angeordnet sind. Lassen Sie 10 Zonen mit jeweils 2 Bytes zuweisen: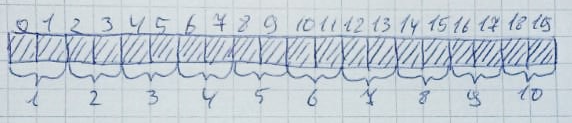 Dann werden 2,4,6,8,10 Zonen freigegeben:
Dann werden 2,4,6,8,10 Zonen freigegeben: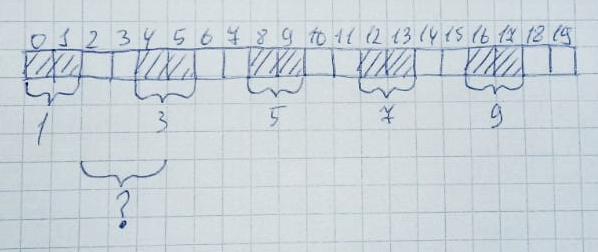 Formal bleibt die Hälfte des gesamten Heaps (10 Bytes) frei. Das Zuweisen eines Speicherbereichs von 3 Bytes schlägt jedoch weiterhin fehl, da das Array keine 3 freien Zellen in einer Reihe enthält. Dies wird als Speicherfragmentierung bezeichnet.Und auf Systemen ohne Speichervirtualisierung ist dies ziemlich schwierig. Besonders bei großen Projekten.Diese Situation kann leicht emuliert werden. Ich habe dies in Keil mVision auf dem LPC11C24-Mikrocontroller gemacht.Stellen Sie die Heap-Größe auf 256 Byte ein:
Formal bleibt die Hälfte des gesamten Heaps (10 Bytes) frei. Das Zuweisen eines Speicherbereichs von 3 Bytes schlägt jedoch weiterhin fehl, da das Array keine 3 freien Zellen in einer Reihe enthält. Dies wird als Speicherfragmentierung bezeichnet.Und auf Systemen ohne Speichervirtualisierung ist dies ziemlich schwierig. Besonders bei großen Projekten.Diese Situation kann leicht emuliert werden. Ich habe dies in Keil mVision auf dem LPC11C24-Mikrocontroller gemacht.Stellen Sie die Heap-Größe auf 256 Byte ein: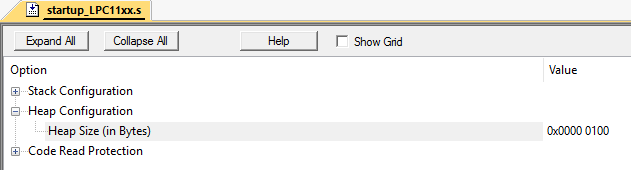 Angenommen, wir haben 2 Klassen:
Angenommen, wir haben 2 Klassen:#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
Wie Sie sehen können, nimmt die Balkenklasse mehr Speicherplatz ein als foo.14 Instanzen der Balkenklasse werden im Heap abgelegt und die Instanz der foo-Klasse passt nicht mehr:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Wenn Sie nur 7 Instanzen von Balken erstellen, wird foo auch normal erstellt:int main(void)
{
foo *f;
bar *b[14];
b[1] = new bar();
b[3] = new bar();
b[5] = new bar();
b[7] = new bar();
b[9] = new bar();
b[11] = new bar();
b[13] = new bar();
f = new foo();
}
Wenn Sie jedoch zuerst 14 Instanzen von Balken erstellen und dann 0,2,4,6,8,10 und 12 Instanzen löschen, kann foo aufgrund der Fragmentierung des Heaps keinen Speicher zuweisen:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
Es stellt sich heraus, dass Sie C ++ nicht vollständig nutzen können, und dies ist ein deutliches Minus. Aus architektonischer Sicht ist C ++ zwar C überlegen, aber unbedeutend. Infolgedessen bringt der Übergang zu C ++ keine signifikanten Vorteile (obwohl es auch keine großen negativen Punkte gibt). Aufgrund eines kleinen Unterschieds bleibt die Wahl der Sprache einfach die persönliche Präferenz des Entwicklers.Aber für mich selbst fand ich einen signifikanten positiven Punkt bei der Verwendung von C ++. Tatsache ist, dass mit dem richtigen C ++ - Ansatz der Code für Mikrocontroller leicht mit Komponententests in Visual Studio abgedeckt werden kann.Ein großes Plus von C ++ ist die Möglichkeit, Visual Studio zu verwenden.
Für mich persönlich war das Thema Codetests für Mikrocontroller schon immer recht komplex. Natürlich wurde der Code auf jede mögliche Weise überprüft, aber die Erstellung eines vollwertigen automatischen Testsystems war immer mit hohen Kosten verbunden, da ein Hardwareständer zusammengebaut und eine spezielle Firmware dafür geschrieben werden musste. Besonders wenn es um ein verteiltes IoT-System geht, das aus Hunderten von Geräten besteht.Als ich anfing, ein Projekt in C ++ zu schreiben, wollte ich sofort versuchen, den Code in Visual Studio einzufügen und Keil mVision nur zum Debuggen zu verwenden. Erstens ist es in Visual Studio, einem sehr leistungsfähigen und praktischen Code-Editor, und in Keil mVision überhaupt keine bequeme Integration in Versionskontrollsysteme, und in Visual Studio ist alles automatisch. Drittens hatte ich die Hoffnung, dass ich es schaffen könnte, zumindest einen Teil des Codes mit Unit-Tests abzudecken, die auch in Visual Studio gut unterstützt werden. Und viertens ist dies die Entstehung von Resharper C ++ - einer Visual Studio-Erweiterung für die Arbeit mit C ++ - Code, mit der Sie viele potenzielle Fehler im Voraus vermeiden und den Stil des Codes überwachen können.Das Erstellen eines Projekts in Visual Studio und das Verbinden mit dem Versionskontrollsystem verursachte keine Probleme. Aber mit Unit-Tests musste man basteln.Von der Hardware abstrahierte Klassen (z. B. Protokollparser) waren leicht zu testen. Aber ich wollte mehr! In meinen Peripherieprojekten verwende ich Keil-Header-Dateien. Für LPC11C24 ist es beispielsweise LPC11xx.h. Diese Dateien beschreiben alle erforderlichen Register gemäß dem CMSIS-Standard. Die direkte Definition eines bestimmten Registers erfolgt über #define:#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
Es stellte sich heraus, dass der Code, der Peripheriegeräte verwendet, sehr gut in VisualStudio kompiliert werden kann, wenn Sie die Register korrekt überschreiben und einige Stubs erstellen. Wenn Sie eine statische Klasse erstellen und ihre Felder als Registeradressen angeben, erhalten Sie nicht nur einen vollwertigen Mikrocontroller-Emulator, mit dem Sie auch die Arbeit mit Peripheriegeräten vollständig testen können:#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
Und dann mach das:#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
Auf diese Weise können Sie den gesamten Projektcode für Mikrocontroller in VisualStudio mit minimalen Änderungen kompilieren und testen.Während der Entwicklung eines Projekts in C ++ habe ich über 300 Tests geschrieben, die sowohl reine Hardwareaspekte als auch von der Hardware abstrahierten Code abdecken. Gleichzeitig wurden im Voraus ungefähr 20 ziemlich schwerwiegende Fehler festgestellt, die aufgrund der Größe des Projekts ohne automatische Tests nicht leicht zu erkennen wären.Schlussfolgerungen
C ++ zu verwenden oder nicht zu verwenden, wenn mit Mikrocontrollern gearbeitet wird, ist eine ziemlich komplizierte Frage. Ich habe oben gezeigt, dass einerseits die architektonischen Vorteile eines vollwertigen OOP nicht so groß sind und die Unfähigkeit, vollständig mit einem Haufen zu arbeiten, ein ziemlich großes Problem ist. Angesichts dieser Aspekte gibt es keinen großen Unterschied zwischen C und C ++ für die Arbeit mit Mikrocontrollern. Die Wahl zwischen diesen kann durchaus durch die persönlichen Vorlieben des Entwicklers gerechtfertigt sein.Es gelang mir jedoch, einen großen positiven Punkt bei der Verwendung von C ++ in der Arbeit mit Visaul Studio zu finden. Auf diese Weise können Sie die Zuverlässigkeit der Entwicklung aufgrund der vollständigen Arbeit mit Versionskontrollsystemen, der Verwendung vollständiger Komponententests (einschließlich Tests für die Arbeit mit Peripheriegeräten) und anderer Vorteile von Visual Studio erheblich erhöhen.Ich hoffe, dass meine Erfahrung nützlich ist und jemandem hilft, die Effektivität seiner Arbeit zu steigern.Update :In den Kommentaren zur englischen Version dieses Artikels gab es nützliche Links zu diesem Thema: