Wie das regionale staatliche Rechenzentrum entstanden ist
 "Es ist kein Ort, der eine Person malt, sondern eine Person - ein Ort."Wir alle sehen regelmäßig Bewertungen verschiedener Arten von Datenverarbeitungszentren (DPCs): groß, klein, unter Wasser, arktisch, innovativ, produktiv usw. Es gibt jedoch praktisch keine Bewertungen dieser unsichtbaren Helden. dass sie für unser Wohl in Staatskerkern arbeiten, und noch mehr in den Regionen. Daher möchte ich meine eigenen Erfahrungen beim Aufbau eines Rechenzentrums im Stawropol-Territorium teilen.
"Es ist kein Ort, der eine Person malt, sondern eine Person - ein Ort."Wir alle sehen regelmäßig Bewertungen verschiedener Arten von Datenverarbeitungszentren (DPCs): groß, klein, unter Wasser, arktisch, innovativ, produktiv usw. Es gibt jedoch praktisch keine Bewertungen dieser unsichtbaren Helden. dass sie für unser Wohl in Staatskerkern arbeiten, und noch mehr in den Regionen. Daher möchte ich meine eigenen Erfahrungen beim Aufbau eines Rechenzentrums im Stawropol-Territorium teilen.Bekanntschaft
Es war ein warmer Sommertag, wie ich mich jetzt erinnere - der 18. Juni 2012. Als ich an diesem Tag in die Wände unseres zukünftigen Rechenzentrums ging, sah ich genau dieses Bild, das mich ehrlich gesagt in einen kleinen Schock versetzte. Treffen Sie GKU SK "Regionales Zentrum für Informationstechnologien" zu Beginn seines Bestehens. Alle Bilder sind anklickbar. Es sah aus wie das einzige Rack in unserem zukünftigen Rechenzentrum im Juni 2012.
Es war eine ziemlich junge Organisation. Ihre Hauptaufgabe zu Beginn meiner Tätigkeit war die Unterstützung des elektronischen Dokumentenmanagements von Behörden (OGV). Mein Ziel war es, ein Rechenzentrum und eine Organisation zu schaffen, die es bedient. Alle vorhandenen Zustandsinformationssysteme sowie alle neu erstellten sollten in das Rechenzentrum umgezogen sein. Zu dieser Zeit gab es ein schnelles Wachstum der elektronischen öffentlichen Dienste und die allgemeine Automatisierung der Behörden.Zu dieser Zeit gab es kein besonderes Verständnis dafür, was E-Government war. Die Hauptsache war das Verständnis, dass „es nicht der Ort ist, der die Person färbt, sondern die Person - der Ort“. Ich hatte ein kleines Team, bestehend aus mir, aber dies war genug, um zu beginnen, zumal die Automatisierung von Routineprozessen unnötiges Aufblähen des Personals vermeidet. Und so sah das Rechenzentrum vor meiner Abreise im Juli 2014 aus.
Mein Ziel war es, ein Rechenzentrum und eine Organisation zu schaffen, die es bedient. Alle vorhandenen Zustandsinformationssysteme sowie alle neu erstellten sollten in das Rechenzentrum umgezogen sein. Zu dieser Zeit gab es ein schnelles Wachstum der elektronischen öffentlichen Dienste und die allgemeine Automatisierung der Behörden.Zu dieser Zeit gab es kein besonderes Verständnis dafür, was E-Government war. Die Hauptsache war das Verständnis, dass „es nicht der Ort ist, der die Person färbt, sondern die Person - der Ort“. Ich hatte ein kleines Team, bestehend aus mir, aber dies war genug, um zu beginnen, zumal die Automatisierung von Routineprozessen unnötiges Aufblähen des Personals vermeidet. Und so sah das Rechenzentrum vor meiner Abreise im Juli 2014 aus. Bevor ich zu dieser Organisation kam, arbeitete ich als führender Spezialist in der Supportabteilung einer der großen Banken. Und diese Erfahrung war sehr nützlich für die Implementierung im OGV . Im Allgemeinen hat mir der Bankensektor aus IT-Sicht sehr gut gefallen, aber das ist eine andere Geschichte. Hier musste ich zum Teil die Funktionen des „grauen Kardinals“ erfüllen: des Chefingenieurs, der im Stab abwesend war.Das von mir erstellte Rechenzentrum sollte nicht nur zuverlässig, sondern auch katastrophal, produktiv und billig sein. Es scheint mir, dass ich deshalb eingeladen wurde, hier zu arbeiten, weil ich zuerst die effektive Nutzung dessen erreichen musste, was bereits da ist. Und die Integratoren hatten nur einen Vorschlag: Wenn Sie mir mehr Geld geben ... Darunter habe ich auch nicht auf die Dienste von Integratoren usw. zurückgegriffen.Da alle Ressourcen tatsächlich in unsere „Cloud“ verschoben wurden, musste ich das Konzept der „Public Private Cloud“ einführen, da der vorhandene konzeptionelle Apparat, bestehend aus „öffentlichen“ und „privaten“ „Clouds“, die Logik der Bereitstellung nicht vollständig erfüllte Ressourcen. Draußen war es eine "private Cloud", von innen war es eine "öffentliche Cloud", aber nur für die UGA. In dieser Hinsicht gab es einige Merkmale der Softwarelizenzierung.Es gelang mir, mich für einige konzeptionelle Momente zu entscheiden, bevor ich zur Organisation kam. Sie mussten als selbstverständlich angesehen werden. Das Projekt wurde in enger Zusammenarbeit mit IBM, Microsoft und Cisco entwickelt. Warum genau diese Anbieter? Für mich - so ist es historisch passiert. Bereue ich es Überhaupt nicht! Könnten andere Anbieter verwendet werden? Natürlich zum Beispiel DELL, HP oder andere sowie deren willkürliche Kombinationen.Als Virtualisierungsplattform wurde gekauft - VMWare, damals 5 Versionen. Hier, denke ich, werden sich alle einig sein, dass die Wahl praktisch unbestritten ist, weil andere boten keine ähnlichen Funktionen wie die Fehlertoleranz.Bei der ersten Prüfung der verfügbaren Kapazität in Racks in der ganzen Stadt entdeckte ich ein Paar IBM BladeCenter-Chassis: E und H. Das Chassis war mit HS22-Blades ausgestattet, die alles andere als das Schlimmste waren, eine harte Mitte zu dieser Zeit. Der Zustand war natürlich etwas bedauerlich, brennende Fehlerindikatoren waren besonders ärgerlich. Ansicht eines der im Juni 2012 erhältlichen Racks. Achten Sie auf die Installation von Geräten "durch die Box", insbesondere von Cisco-Geräten.
Bevor ich zu dieser Organisation kam, arbeitete ich als führender Spezialist in der Supportabteilung einer der großen Banken. Und diese Erfahrung war sehr nützlich für die Implementierung im OGV . Im Allgemeinen hat mir der Bankensektor aus IT-Sicht sehr gut gefallen, aber das ist eine andere Geschichte. Hier musste ich zum Teil die Funktionen des „grauen Kardinals“ erfüllen: des Chefingenieurs, der im Stab abwesend war.Das von mir erstellte Rechenzentrum sollte nicht nur zuverlässig, sondern auch katastrophal, produktiv und billig sein. Es scheint mir, dass ich deshalb eingeladen wurde, hier zu arbeiten, weil ich zuerst die effektive Nutzung dessen erreichen musste, was bereits da ist. Und die Integratoren hatten nur einen Vorschlag: Wenn Sie mir mehr Geld geben ... Darunter habe ich auch nicht auf die Dienste von Integratoren usw. zurückgegriffen.Da alle Ressourcen tatsächlich in unsere „Cloud“ verschoben wurden, musste ich das Konzept der „Public Private Cloud“ einführen, da der vorhandene konzeptionelle Apparat, bestehend aus „öffentlichen“ und „privaten“ „Clouds“, die Logik der Bereitstellung nicht vollständig erfüllte Ressourcen. Draußen war es eine "private Cloud", von innen war es eine "öffentliche Cloud", aber nur für die UGA. In dieser Hinsicht gab es einige Merkmale der Softwarelizenzierung.Es gelang mir, mich für einige konzeptionelle Momente zu entscheiden, bevor ich zur Organisation kam. Sie mussten als selbstverständlich angesehen werden. Das Projekt wurde in enger Zusammenarbeit mit IBM, Microsoft und Cisco entwickelt. Warum genau diese Anbieter? Für mich - so ist es historisch passiert. Bereue ich es Überhaupt nicht! Könnten andere Anbieter verwendet werden? Natürlich zum Beispiel DELL, HP oder andere sowie deren willkürliche Kombinationen.Als Virtualisierungsplattform wurde gekauft - VMWare, damals 5 Versionen. Hier, denke ich, werden sich alle einig sein, dass die Wahl praktisch unbestritten ist, weil andere boten keine ähnlichen Funktionen wie die Fehlertoleranz.Bei der ersten Prüfung der verfügbaren Kapazität in Racks in der ganzen Stadt entdeckte ich ein Paar IBM BladeCenter-Chassis: E und H. Das Chassis war mit HS22-Blades ausgestattet, die alles andere als das Schlimmste waren, eine harte Mitte zu dieser Zeit. Der Zustand war natürlich etwas bedauerlich, brennende Fehlerindikatoren waren besonders ärgerlich. Ansicht eines der im Juni 2012 erhältlichen Racks. Achten Sie auf die Installation von Geräten "durch die Box", insbesondere von Cisco-Geräten. Als Speichersystem wurde an einem Standort ein optisch verbundenes DS3512-Regal mit installierten 2-TB-Laufwerken installiert. An einem anderen Standort wurden die Regale DS3512 und DS3524 installiert.Auf der Sicherungssite wurde der freie Speicherplatz zugewiesen, sodass VMWare nicht ohne manuelles Eingreifen gestartet wurde: Es wurden andere installierte Kopien erkannt und gestoppt, nur das Starten mit dem entsprechenden Schlüssel half. Die Verteilung selbst erfolgte nach dem Prinzip: Jede virtuelle Maschine hat eine eigene LUN. Wenn der virtuellen Maschine zusätzlicher Speicherplatz zugewiesen werden musste, auf der vorhandenen LUN jedoch nicht ... DieStandorte waren durch ein dünnes Datennetzwerk mit einer Breite von 1 Gbit / s miteinander verbunden. Es gab kein dediziertes Netzwerk für denselben Virtualisierungs- und Serviceverkehr.Nach einer kurzen Überprüfung und Prüfung der IT-Infrastruktur (und es war kurz, da praktisch keine Infrastruktur vorhanden war) wurde der Schluss gezogen, dass ich ein klassisches Beispiel dafür habe. Es gab weder Schemata noch begleitende Dokumentationen, selbst Administratorkennwörter waren alles andere als bekannt, sie mussten zurückgesetzt und wiederhergestellt werden.Ich machte mich entschlossen an die Arbeit.
Als Speichersystem wurde an einem Standort ein optisch verbundenes DS3512-Regal mit installierten 2-TB-Laufwerken installiert. An einem anderen Standort wurden die Regale DS3512 und DS3524 installiert.Auf der Sicherungssite wurde der freie Speicherplatz zugewiesen, sodass VMWare nicht ohne manuelles Eingreifen gestartet wurde: Es wurden andere installierte Kopien erkannt und gestoppt, nur das Starten mit dem entsprechenden Schlüssel half. Die Verteilung selbst erfolgte nach dem Prinzip: Jede virtuelle Maschine hat eine eigene LUN. Wenn der virtuellen Maschine zusätzlicher Speicherplatz zugewiesen werden musste, auf der vorhandenen LUN jedoch nicht ... DieStandorte waren durch ein dünnes Datennetzwerk mit einer Breite von 1 Gbit / s miteinander verbunden. Es gab kein dediziertes Netzwerk für denselben Virtualisierungs- und Serviceverkehr.Nach einer kurzen Überprüfung und Prüfung der IT-Infrastruktur (und es war kurz, da praktisch keine Infrastruktur vorhanden war) wurde der Schluss gezogen, dass ich ein klassisches Beispiel dafür habe. Es gab weder Schemata noch begleitende Dokumentationen, selbst Administratorkennwörter waren alles andere als bekannt, sie mussten zurückgesetzt und wiederhergestellt werden.Ich machte mich entschlossen an die Arbeit.Beginn der Reise
In einer so seriösen Organisation gab es zum Zeitpunkt meiner Ankunft aus der IT-Infrastruktur in der Zukunft absolut nichts: einen einzigen intelligenten Switch, ein Peer-to-Peer-Netzwerk, gemeinsam genutzte Ressourcen an jedem Arbeitsplatz ... Im Allgemeinen ist alles genau so, wie Sie sich die Situation in der Region vorstellen.Dementsprechend wurde die Unternehmensinfrastruktur zunächst schnell erstellt. Für das, was bestellt wurde, alles, was zu dieser Zeit verfügbar war. Mit einem Netzwerktester bewaffnet, fand und signierte ich alle Kabel. Weil Zum Zeitpunkt der Verkabelung gab es keinen Plan für Jobs - irgendwo gab es anstelle von Telefonen PCs, irgendwo gab es nicht genug Kabel und viele andere Standard-Charms.Leider hat bei der Gestaltung des Serverraums für das zukünftige Rechenzentrum niemand einen Doppelboden oder eine Drahtwanne unter der Decke hergestellt. Natürlich gab es auch kein Geld mehr dafür, also musste ich selbst Schönheit mitbringen.Da mir in diesem Moment niemand erlaubt hat, die Drähte einfach zu kürzen: "Plötzlich muss man das Rack in die hinterste Ecke des Raumes stellen, was dann?" - Ich musste das 110. Kreuz unter der Decke machen, von dem aus die Drähte bereits in das Rack abgesenkt wurden. Damit bei einer Rackbewegung kurze Drähte vom Kreuz entfernt werden können und dort längere installiert werden. Ansicht der Wand 110. Querplatte während der Installation sowie ein Messer zum Abschluss von Drähten. Es wurde auch sofort festgestellt, dass die Patchkabel farbcodiert sein würden, da es nur ein blaues und ein rotes Kabel gab, die Telefonie rot sein musste und alles im Netzwerk blau war. Rack-Typ vor und nach der Installation.
Im Rack fand ich eine Büro-Telefonanlage KX-NCP500 von Panasonic, die mit 4 Stadt- und 8 Nebenstellen ausgestattet war. Die internen Telefonleitungen haben mich am wenigsten interessiert, trotzdem war es eine IP-Telefonanlage: Nach und nach habe ich alles an VOIP übertragen. Da ich keine ernsthaften Erfahrungen mit der Einrichtung der TK-Anlage hatte, musste ich ein bisschen basteln. Es hat sich gelohnt, die Notwendigkeit zu verstehen, einen eigenen STUN-Server zu erstellen ...
Es wurde auch sofort festgestellt, dass die Patchkabel farbcodiert sein würden, da es nur ein blaues und ein rotes Kabel gab, die Telefonie rot sein musste und alles im Netzwerk blau war. Rack-Typ vor und nach der Installation.
Im Rack fand ich eine Büro-Telefonanlage KX-NCP500 von Panasonic, die mit 4 Stadt- und 8 Nebenstellen ausgestattet war. Die internen Telefonleitungen haben mich am wenigsten interessiert, trotzdem war es eine IP-Telefonanlage: Nach und nach habe ich alles an VOIP übertragen. Da ich keine ernsthaften Erfahrungen mit der Einrichtung der TK-Anlage hatte, musste ich ein bisschen basteln. Es hat sich gelohnt, die Notwendigkeit zu verstehen, einen eigenen STUN-Server zu erstellen ... Daher verfügte die Organisation nicht über ein eigenes Netzwerk, sondern alle Computer befanden sich in einem großen Intranet. Es passte nicht zu mir als Person, die keine Kenntnisse der Informationssicherheit aus erster Hand hatte: Am Rande des Netzwerks installierte und konfigurierte ich einen FreeBSD-basierten Router und segmentierte das Netzwerk selbst, damit ich die Zusammenarbeit vollständig steuern konnte. Bei diesem Ansatz leidet normalerweise nur ein Segment.Über das OGV- Netzwerk selbst war nur klar, dass es irgendwo existierte. Ich musste die gesamte Netzwerktopologie basierend auf den Gerätekonfigurationen wiederherstellen, sorgfältig skizzieren und dokumentieren. Konfigurationen nahmen allmählich eine menschliche Form an, Beschreibung und Namenslogik erschienen.Nach fast sechs Monaten fand ich endlich Dokumentation im OGV- Netzwerk. Aber leider stimmte es zu 90% nicht mit dem überein, was tatsächlich war. Es wurde von sehr hoher Qualität hergestellt, es war eines der wenigen Dokumente, an denen gearbeitet werden konnte. Aber nach den Einstellungen zu urteilen, funktionierte niemand.Bei der Untersuchung des Netzwerks habe ich alle Knoten auf den neuesten Stand gebracht, da auf fast allen Geräten sehr veraltete Software installiert war. Irgendwo war dies nicht notwendig, aber irgendwo wurden die bestehenden Probleme behoben. Die alten (links, 2012) und die neuen (rechts, 2016) Ansichten der Hauptseite der Site.
Daher verfügte die Organisation nicht über ein eigenes Netzwerk, sondern alle Computer befanden sich in einem großen Intranet. Es passte nicht zu mir als Person, die keine Kenntnisse der Informationssicherheit aus erster Hand hatte: Am Rande des Netzwerks installierte und konfigurierte ich einen FreeBSD-basierten Router und segmentierte das Netzwerk selbst, damit ich die Zusammenarbeit vollständig steuern konnte. Bei diesem Ansatz leidet normalerweise nur ein Segment.Über das OGV- Netzwerk selbst war nur klar, dass es irgendwo existierte. Ich musste die gesamte Netzwerktopologie basierend auf den Gerätekonfigurationen wiederherstellen, sorgfältig skizzieren und dokumentieren. Konfigurationen nahmen allmählich eine menschliche Form an, Beschreibung und Namenslogik erschienen.Nach fast sechs Monaten fand ich endlich Dokumentation im OGV- Netzwerk. Aber leider stimmte es zu 90% nicht mit dem überein, was tatsächlich war. Es wurde von sehr hoher Qualität hergestellt, es war eines der wenigen Dokumente, an denen gearbeitet werden konnte. Aber nach den Einstellungen zu urteilen, funktionierte niemand.Bei der Untersuchung des Netzwerks habe ich alle Knoten auf den neuesten Stand gebracht, da auf fast allen Geräten sehr veraltete Software installiert war. Irgendwo war dies nicht notwendig, aber irgendwo wurden die bestehenden Probleme behoben. Die alten (links, 2012) und die neuen (rechts, 2016) Ansichten der Hauptseite der Site. Es wurde auch eine Site entwickelt, während gleichzeitig eigene Nameserver, virtuelles Hosting und Mail-Service eingerichtet wurden. Ich bin äußerst misstrauisch gegenüber Organisationen, in denen Mitarbeiter Postanschriften für eindeutig öffentliche Postdienste haben, insbesondere in Regierungsbehörden.Im Allgemeinen sind die ersten Monate der Arbeit vergangen, ich denke, sie sind sehr fruchtbar.
Es wurde auch eine Site entwickelt, während gleichzeitig eigene Nameserver, virtuelles Hosting und Mail-Service eingerichtet wurden. Ich bin äußerst misstrauisch gegenüber Organisationen, in denen Mitarbeiter Postanschriften für eindeutig öffentliche Postdienste haben, insbesondere in Regierungsbehörden.Im Allgemeinen sind die ersten Monate der Arbeit vergangen, ich denke, sie sind sehr fruchtbar.Erste Stufe
Anfänglich wurde das Rechenzentrum mit Ausnahme der Arbeit des abteilungsübergreifenden Workflows für nichts mehr verwendet. Zweifellos ist das Dokumentenmanagement einer der wichtigsten Teile der Arbeit der staatlichen Behörden. Gerade wegen der Komplexität des Workflows treten häufig viele Probleme in der Arbeit unseres Staates auf, und es ist der elektronische Workflow, der den Ausweg aus dieser Situation darstellt.Ich denke, die interessanteste Frage ist: Woran arbeitet die elektronische Regierung im Rechenzentrum?Das Rechenzentrum selbst besteht aus mehreren geografisch verteilten Standorten. Daher wird das Konzept der Katastrophenverträglichkeit umgesetzt und die Arbeiten werden rund um die Uhr durchgeführt. Die Standorte waren durch den Hauptstamm von 32 Singlemode-Fasern miteinander verbunden.Der Kern des Rechenzentrums sind die IBM HS22- und HS23-Blades (jetzt Lenovo), die paarweise auf die Plattformen verteilt sind. Jedes Chassis bietet Platz für 14 Blades. In der Anfangsphase wurden fünf Blades installiert.Jedes Blade hat zwei Prozessoren, wenn ich mich nicht irre, E5650 (6 Kerne, 12 MB Cache), RAM für die Augäpfel von 192 GB. Blades ohne Festplatten, im Inneren habe ich beschlossen, USB-Flash mit einem VMWare-Image zu installieren, um die Trennung von Leistung und Speicher zu maximieren. Die Protokolle werden in einen gemeinsamen Speicher geschrieben. Der Uplink jedes Blades beträgt 2 Gbit / s. Der Uplink kann auf 10 Gbit / s erhöht werden, indem der entsprechende Switch im Gehäuse und eine Netzwerkkarte in jedem Blade installiert werden. Unser Hauptstamm aus 32 Fasern. Als OS - VMWare vSphere (als ich ging war es 5.5) Standard. In einer fortgeschritteneren Version habe ich den Punkt nicht gesehen: Die vorgeschlagene Funktionalität war im Übermaß ausreichend. Und was fehlte - Sie konnten selbst schreiben.In Zukunft wurde die Anzahl der Blades aufgrund etwas leistungsstärkerer IBM HS23-Server erhöht.Die Stromredundanz an jedem Standort war unterschiedlich, jedoch nicht weniger als zwei Stromquellen. Außerdem sind in jedem Rack zusätzlich USVs installiert, die das Rack paarweise versorgen: Die Netzteile der Geräte werden aus verschiedenen Quellen mit Strom versorgt. Es mag unnötig sein, aber es gab einige Momente, in denen Rack-USVs zur Rettung kamen. Es gibt nicht viel, aber es gibt nicht viel Redundanz in solchen Systemen.Die Kühlung wurde ebenfalls variiert. Auf dem Hauptgelände waren dies an der Wand montierte Industrieklimaanlagen mit einer Auswuchteinheit. Die Temperatur wurde bei 21 Grad gehalten. An einem anderen Standort handelte es sich um industrielle Bodenklimageräte und eine unterirdische Luftversorgung. Die IBM SVC . Controller unseres Speichersystems.
Das Speichersystem ist skalierbar und basiert auf dem IBM SVC- Controller , der es ermöglichte, Redundanz desselben RAID 6 + 1, Redundanz auf mehreren Pfaden und Verbindung zwischen Einheiten über eine 8-Gbit / s-Uplink-Optik zu erreichen. Jeder Teil des Rechenzentrums kann im Falle eines Unfalls oder einer routinemäßigen Wartung jederzeit eigenständig in Betrieb genommen werden. Fast alle physischen Ressourcen werden in einem funktionierenden Rechenzentrum virtualisiert: Der Speicher wird auf Basis von IBM virtualisiert
Als OS - VMWare vSphere (als ich ging war es 5.5) Standard. In einer fortgeschritteneren Version habe ich den Punkt nicht gesehen: Die vorgeschlagene Funktionalität war im Übermaß ausreichend. Und was fehlte - Sie konnten selbst schreiben.In Zukunft wurde die Anzahl der Blades aufgrund etwas leistungsstärkerer IBM HS23-Server erhöht.Die Stromredundanz an jedem Standort war unterschiedlich, jedoch nicht weniger als zwei Stromquellen. Außerdem sind in jedem Rack zusätzlich USVs installiert, die das Rack paarweise versorgen: Die Netzteile der Geräte werden aus verschiedenen Quellen mit Strom versorgt. Es mag unnötig sein, aber es gab einige Momente, in denen Rack-USVs zur Rettung kamen. Es gibt nicht viel, aber es gibt nicht viel Redundanz in solchen Systemen.Die Kühlung wurde ebenfalls variiert. Auf dem Hauptgelände waren dies an der Wand montierte Industrieklimaanlagen mit einer Auswuchteinheit. Die Temperatur wurde bei 21 Grad gehalten. An einem anderen Standort handelte es sich um industrielle Bodenklimageräte und eine unterirdische Luftversorgung. Die IBM SVC . Controller unseres Speichersystems.
Das Speichersystem ist skalierbar und basiert auf dem IBM SVC- Controller , der es ermöglichte, Redundanz desselben RAID 6 + 1, Redundanz auf mehreren Pfaden und Verbindung zwischen Einheiten über eine 8-Gbit / s-Uplink-Optik zu erreichen. Jeder Teil des Rechenzentrums kann im Falle eines Unfalls oder einer routinemäßigen Wartung jederzeit eigenständig in Betrieb genommen werden. Fast alle physischen Ressourcen werden in einem funktionierenden Rechenzentrum virtualisiert: Der Speicher wird auf Basis von IBM virtualisiert SVC ; Prozessor- und RAM-Ressourcen werden basierend auf VMWare vSphere virtualisiert. Wenn wir Virtualisierung verwenden, um VLAN auf Switches zu verwenden, können wir davon ausgehen, dass die Netzwerkinfrastruktur ebenfalls virtualisiert ist.Fast alle Geräte, die Fernbedienung unterstützen, habe ich mit dem Netzwerk verbunden und konfiguriert. An entfernten Standorten funktioniert alles, auch über gesteuerte Steckdosen (sie erschienen später in der zweiten Stufe). Wenn ein Gerät ohne Fernbedienung ausfällt, kann es daher durch Stromversorgung zurückgesetzt werden.Das Rechenzentrum wurde in mehreren Schritten erstellt. Die erste Phase umfasste die Ordnung und den Aufbau einer Cloud-Infrastruktur. Das ursprüngliche Ziel bestand darin, eine virtualisierte Speicherebene basierend auf IBM SVC zu erstellen .Während der Umsetzung des Plans wurden Server, die sich zuvor in Drittanbieterorganisationen befanden, auf unsere Site verschoben. Daher haben wir mehrere alte IBM Server mit funktionierenden Services verschoben, die mehr als ein BladeCenter-Gehäuse verbraucht und beheizt haben. Natürlich wurden die Dienste von ihnen nach und nach in die "Cloud" verlagert. Art der Racks im Editor.
Das erste ist der Plan. Zu diesem Zeitpunkt konnte ich bereits nach eigenem Ermessen arbeiten (es gab jedoch bereits einige abgeschlossene Projekte, und ich habe bereits das Vertrauen gewonnen, dass es fehlerfreie Arbeiten gab). Deshalb habe ich zuerst die Racks im Editor zusammengestellt und gleichzeitig mit mir selbst diskutiert und gestritten. Der Prozess der Montage von Geräten in einem Rack.
SVC ; Prozessor- und RAM-Ressourcen werden basierend auf VMWare vSphere virtualisiert. Wenn wir Virtualisierung verwenden, um VLAN auf Switches zu verwenden, können wir davon ausgehen, dass die Netzwerkinfrastruktur ebenfalls virtualisiert ist.Fast alle Geräte, die Fernbedienung unterstützen, habe ich mit dem Netzwerk verbunden und konfiguriert. An entfernten Standorten funktioniert alles, auch über gesteuerte Steckdosen (sie erschienen später in der zweiten Stufe). Wenn ein Gerät ohne Fernbedienung ausfällt, kann es daher durch Stromversorgung zurückgesetzt werden.Das Rechenzentrum wurde in mehreren Schritten erstellt. Die erste Phase umfasste die Ordnung und den Aufbau einer Cloud-Infrastruktur. Das ursprüngliche Ziel bestand darin, eine virtualisierte Speicherebene basierend auf IBM SVC zu erstellen .Während der Umsetzung des Plans wurden Server, die sich zuvor in Drittanbieterorganisationen befanden, auf unsere Site verschoben. Daher haben wir mehrere alte IBM Server mit funktionierenden Services verschoben, die mehr als ein BladeCenter-Gehäuse verbraucht und beheizt haben. Natürlich wurden die Dienste von ihnen nach und nach in die "Cloud" verlagert. Art der Racks im Editor.
Das erste ist der Plan. Zu diesem Zeitpunkt konnte ich bereits nach eigenem Ermessen arbeiten (es gab jedoch bereits einige abgeschlossene Projekte, und ich habe bereits das Vertrauen gewonnen, dass es fehlerfreie Arbeiten gab). Deshalb habe ich zuerst die Racks im Editor zusammengestellt und gleichzeitig mit mir selbst diskutiert und gestritten. Der Prozess der Montage von Geräten in einem Rack.
 Die Installation wurde gemäß den beschriebenen Standards, Best Practices und Empfehlungen durchgeführt, einschließlich in IBM RedBook. Natürlich wurde zum ersten Mal über mein „Lass uns die Dokumentation lesen“ gelacht, aber nach der „wissenschaftlichen Stochermethode“ weigerten sich die Server, in Position zu kommen, weil zum einen der Abstand zwischen den Führungen zu groß ist, zum anderen zu klein - ich fand in Redbook Standardgrößen für die Montage von Racks, danach kam alles beim ersten Mal zusammen. Die erste Phase des Rechenzentrums, Juni 2013. Im Hintergrund das Tamburin des Obersten Administrators.
Die Installation wurde gemäß den beschriebenen Standards, Best Practices und Empfehlungen durchgeführt, einschließlich in IBM RedBook. Natürlich wurde zum ersten Mal über mein „Lass uns die Dokumentation lesen“ gelacht, aber nach der „wissenschaftlichen Stochermethode“ weigerten sich die Server, in Position zu kommen, weil zum einen der Abstand zwischen den Führungen zu groß ist, zum anderen zu klein - ich fand in Redbook Standardgrößen für die Montage von Racks, danach kam alles beim ersten Mal zusammen. Die erste Phase des Rechenzentrums, Juni 2013. Im Hintergrund das Tamburin des Obersten Administrators. Zu diesem Zeitpunkt war bereits fast ein Jahr vergangen, seit ich in dieser Organisation zum Wohle des Staates gearbeitet hatte. In diesem Jahr haben wir nie auf die Dienste von Integratoren oder anderen Auftragnehmern zurückgegriffen. Ich werde mich nicht zerstreuen, ich habe mehrmals Kollegen von IBM um Hilfe bei Fragen zu ihrer Ausrüstung gebeten und wir haben gemeinsam die aufgetretenen Probleme gelöst, wofür wir uns bei ihnen bedanken.Das Rechenzentrum wurde bereits zu diesem Zeitpunkt indikativ und empfing regelmäßig Besucher, um zu demonstrieren, wie die IT-Infrastruktur funktionieren und aussehen sollte. Dies sollte nicht wie eine IT-Infrastruktur aussehen. Das Bild wurde am zweiten Tag meiner Arbeit 2012 aufgenommen.
Zu diesem Zeitpunkt war bereits fast ein Jahr vergangen, seit ich in dieser Organisation zum Wohle des Staates gearbeitet hatte. In diesem Jahr haben wir nie auf die Dienste von Integratoren oder anderen Auftragnehmern zurückgegriffen. Ich werde mich nicht zerstreuen, ich habe mehrmals Kollegen von IBM um Hilfe bei Fragen zu ihrer Ausrüstung gebeten und wir haben gemeinsam die aufgetretenen Probleme gelöst, wofür wir uns bei ihnen bedanken.Das Rechenzentrum wurde bereits zu diesem Zeitpunkt indikativ und empfing regelmäßig Besucher, um zu demonstrieren, wie die IT-Infrastruktur funktionieren und aussehen sollte. Dies sollte nicht wie eine IT-Infrastruktur aussehen. Das Bild wurde am zweiten Tag meiner Arbeit 2012 aufgenommen. Bei der Implementierung des Rechenzentrums wurde mir klar, dass die Ressourcen effizient an Verbraucher - Regierungsstellen - geliefert werden müssen. Darüber hinaus haben einige "ursprüngliche" schriftliche Informationssysteme, die in die Cloud verschoben wurden, sehr große Informationsmengen über das Netzwerk übertragen.Der ausschließliche Zugang über das Internet schien keine so gute Idee zu sein, da er keine ausreichende Zugangsgeschwindigkeit bot. Der Ausbau der Internetverbindung in allen öffentlichen Gruppen ist ein äußerst kostspieliger Vorgang. Aus diesem Grund wurde beschlossen, ein eigenes Netzwerk bereitzustellen: Aus sicherheitstechnischer Sicht erwies sich dies als weitaus rentabler als das Leasing von Kommunikationskanälen von derselben Rostelecom.Warum wurde das anfangs nicht gemacht? Die Antwort ist einfach: Es gab keine qualifizierten Spezialisten für diese Arbeit, nur externe Auftragnehmer. Und sie versuchen, sich auf Outsourcing einzulassen.Zu diesem Zeitpunkt musste ich die Infrastruktur des Anbieters planen und aufbauen. Gleichzeitig mussten viele OGV- Netze geprüft werden . Natürlich gab es in einigen OGVs ziemlich starke IT-Dienste (zum Beispiel im Finanzministerium, im Verteidigungsministerium, im Regierungsapparat und in anderen). Aber es gab auch offen gesagt schwache, bei denen sie den Draht nicht einmal komprimieren konnten. Ich musste mich so komplett unter meine Fittiche nehmen, da die Qualifikation es erlaubte.Daher musste ich insbesondere eine typische Netzwerkarchitektur des OGV entwickelnwas man anstreben musste. Standardisierung und Typisierung sind der Schlüssel zu einem effektiven Betrieb. Nach meinen vorläufigen Berechnungen sollte es in unserer Organisation mindestens 100-150 Verwaltungsobjekte pro Person geben. Eines der Geräte von Cisco.
Natürlich wurden im im Aufbau befindlichen Netzwerk zusätzlich zu den offensichtlichen VLAN-Technologien andere moderne Technologien verwendet, um die Verwaltung zu erleichtern: OSPF, VTP, PVST, MSTP, HSRP, QoS usw. Natürlich wollte ich die Redundanz erhöhen, aber leider verfügte ASR nicht über genügend Hardwareressourcen. Leider hat es nicht funktioniert, um zu MPLS zu gelangen. Ja, und es gab keine Notwendigkeit. Als das Netzwerk erweitert wurde, begann ich, die Kontrolle über OGV- Geräte zu übernehmen
Bei der Implementierung des Rechenzentrums wurde mir klar, dass die Ressourcen effizient an Verbraucher - Regierungsstellen - geliefert werden müssen. Darüber hinaus haben einige "ursprüngliche" schriftliche Informationssysteme, die in die Cloud verschoben wurden, sehr große Informationsmengen über das Netzwerk übertragen.Der ausschließliche Zugang über das Internet schien keine so gute Idee zu sein, da er keine ausreichende Zugangsgeschwindigkeit bot. Der Ausbau der Internetverbindung in allen öffentlichen Gruppen ist ein äußerst kostspieliger Vorgang. Aus diesem Grund wurde beschlossen, ein eigenes Netzwerk bereitzustellen: Aus sicherheitstechnischer Sicht erwies sich dies als weitaus rentabler als das Leasing von Kommunikationskanälen von derselben Rostelecom.Warum wurde das anfangs nicht gemacht? Die Antwort ist einfach: Es gab keine qualifizierten Spezialisten für diese Arbeit, nur externe Auftragnehmer. Und sie versuchen, sich auf Outsourcing einzulassen.Zu diesem Zeitpunkt musste ich die Infrastruktur des Anbieters planen und aufbauen. Gleichzeitig mussten viele OGV- Netze geprüft werden . Natürlich gab es in einigen OGVs ziemlich starke IT-Dienste (zum Beispiel im Finanzministerium, im Verteidigungsministerium, im Regierungsapparat und in anderen). Aber es gab auch offen gesagt schwache, bei denen sie den Draht nicht einmal komprimieren konnten. Ich musste mich so komplett unter meine Fittiche nehmen, da die Qualifikation es erlaubte.Daher musste ich insbesondere eine typische Netzwerkarchitektur des OGV entwickelnwas man anstreben musste. Standardisierung und Typisierung sind der Schlüssel zu einem effektiven Betrieb. Nach meinen vorläufigen Berechnungen sollte es in unserer Organisation mindestens 100-150 Verwaltungsobjekte pro Person geben. Eines der Geräte von Cisco.
Natürlich wurden im im Aufbau befindlichen Netzwerk zusätzlich zu den offensichtlichen VLAN-Technologien andere moderne Technologien verwendet, um die Verwaltung zu erleichtern: OSPF, VTP, PVST, MSTP, HSRP, QoS usw. Natürlich wollte ich die Redundanz erhöhen, aber leider verfügte ASR nicht über genügend Hardwareressourcen. Leider hat es nicht funktioniert, um zu MPLS zu gelangen. Ja, und es gab keine Notwendigkeit. Als das Netzwerk erweitert wurde, begann ich, die Kontrolle über OGV- Geräte zu übernehmen , gleichzeitig einstellen, wie es sollte. Bei der Verbindung von Verwaltungen in der Region musste ich Öffentlichkeitsarbeit und Aufklärungsarbeit leisten und Kollegen in Bezirks- und ländlichen Verwaltungen helfen.Die gesamte Aufwärtsverbindung zwischen den Standorten in der ersten Phase betrug nur wenige Gigabit. Ich habe jedoch bereits einen Kanal zugewiesen, damit vSphere funktioniert.Das Netzwerk selbst erwies sich als geografisch stark verteilt, einschließlich einer relativ großen Anzahl von Remote-Knoten, die über L2 / L3-VPN verbunden sind.Vieles könnte natürlich durch ernsthafte Finanzinvestitionen gelöst werden, aber ich habe es mit dem geschafft, was ich habe. Oft wurde die verfügbare Ausrüstung ineffizient genutzt, deshalb habe ich einfach bessere Plätze dafür gefunden. Besonders im ersten Lebensjahr standen alle den Aussichten für die Umsetzung dieses Projekts sehr skeptisch gegenüber.Aber nach dem ersten Jahr, in dem dank unserer Organisation direkte und indirekte Budgeteinsparungen von mehreren zehn Millionen Rubel erzielt wurden und sich die Einstellung dramatisch änderte. Eines der Netzwerkdiagramme. Die meisten Knoten sind aus offensichtlichen Gründen ausgeblendet.
, gleichzeitig einstellen, wie es sollte. Bei der Verbindung von Verwaltungen in der Region musste ich Öffentlichkeitsarbeit und Aufklärungsarbeit leisten und Kollegen in Bezirks- und ländlichen Verwaltungen helfen.Die gesamte Aufwärtsverbindung zwischen den Standorten in der ersten Phase betrug nur wenige Gigabit. Ich habe jedoch bereits einen Kanal zugewiesen, damit vSphere funktioniert.Das Netzwerk selbst erwies sich als geografisch stark verteilt, einschließlich einer relativ großen Anzahl von Remote-Knoten, die über L2 / L3-VPN verbunden sind.Vieles könnte natürlich durch ernsthafte Finanzinvestitionen gelöst werden, aber ich habe es mit dem geschafft, was ich habe. Oft wurde die verfügbare Ausrüstung ineffizient genutzt, deshalb habe ich einfach bessere Plätze dafür gefunden. Besonders im ersten Lebensjahr standen alle den Aussichten für die Umsetzung dieses Projekts sehr skeptisch gegenüber.Aber nach dem ersten Jahr, in dem dank unserer Organisation direkte und indirekte Budgeteinsparungen von mehreren zehn Millionen Rubel erzielt wurden und sich die Einstellung dramatisch änderte. Eines der Netzwerkdiagramme. Die meisten Knoten sind aus offensichtlichen Gründen ausgeblendet.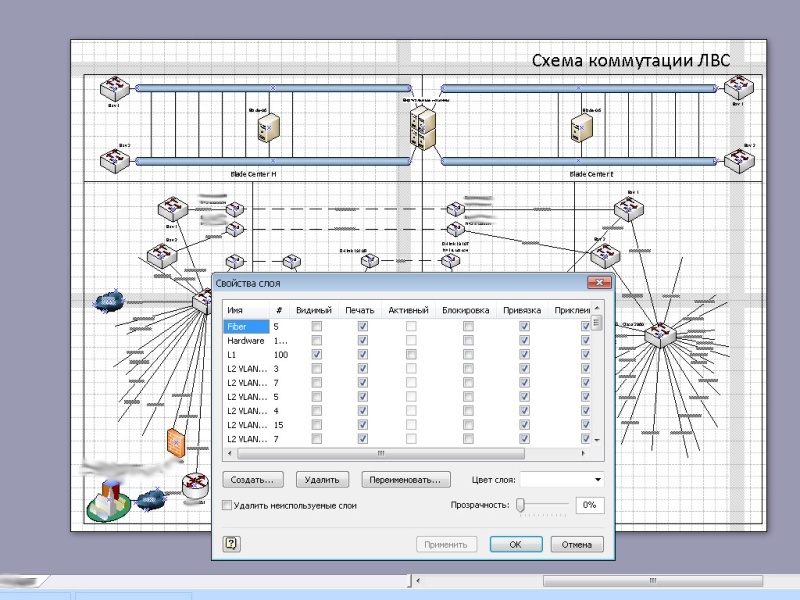
Zweite Stufe
In der zweiten Phase mussten wir bereits die Hardwarekapazitäten unseres Rechenzentrums erhöhen. Die Erweiterung der Kapazitäten erforderte einen Wechsel des Chassis von Modell E zu H und die Neuinstallation bestehender Racks. Der Speicherplatz wurde durch Erhöhen der Anzahl der Regale von der Festplatte erhöht. Regale mit IBM DS3512-Festplatten und das DS3524-Regal sind oben sichtbar.
Mehrere weitere physische Server sind zu uns umgezogen. Die Anzahl der virtuellen Maschinen hat erheblich zugenommen. Ein auf der IBM TS3200-Bandbibliothek basierendes Sicherungstool wurde hinzugefügt. Im Vordergrund steht die IBM TS3200-Bandbibliothek.
Natürlich habe ich mit der Installation neuer Geräte mit Vorplanung begonnen. Hier mussten schon Racks auf beiden Seiten modelliert werden. Planung für die Erweiterung des Rechenzentrums.

 Der Umzug wurde so schnell wie möglich abgeschlossen. Da zu diesem Zeitpunkt die Virtualisierung vollständig funktionierte, war der Umzugsprozess absolut nicht wahrnehmbar, da vor dem Verschieben und Trennen von Geräten an einem Standort alle virtuellen Server auf einen anderen migriert wurden und am Ende der Arbeit alles wieder normal war.Natürlich wurde neben dem Hauptstandort auch eine Bestellung auf dem Reservestandort aufgegeben. Gleichzeitig war es dank eines voll funktionsfähigen Backup-Systems endlich möglich, die Ordnung dort wiederherzustellen. Art der Racks nach Erweiterung der Ressource, 2014.
Der Umzug wurde so schnell wie möglich abgeschlossen. Da zu diesem Zeitpunkt die Virtualisierung vollständig funktionierte, war der Umzugsprozess absolut nicht wahrnehmbar, da vor dem Verschieben und Trennen von Geräten an einem Standort alle virtuellen Server auf einen anderen migriert wurden und am Ende der Arbeit alles wieder normal war.Natürlich wurde neben dem Hauptstandort auch eine Bestellung auf dem Reservestandort aufgegeben. Gleichzeitig war es dank eines voll funktionsfähigen Backup-Systems endlich möglich, die Ordnung dort wiederherzustellen. Art der Racks nach Erweiterung der Ressource, 2014. Und da unser Rechenzentrum zu diesem Zeitpunkt bereits vorbildlich geworden war, beschloss ich, auf Details zu achten: Die verfügbaren freien Einheiten waren mit schwarzen Lünetten bedeckt, und wo Belüftung erforderlich war, wurden perforierte Lünetten installiert. Sogar die Befestigungsschrauben, mit denen das Gerät im Rack befestigt ist, habe ich aus der Sprühdose entfernt und schwarz lackiert. Eine Kleinigkeit, aber nett. Art der Racks auf dem Reservestandort während der Installation (links) und am Ende (rechts).
Um die überall liegenden Medienkonverter loszuwerden, wurde ein Paar D-Link DMC-1000-Chassis gekauft, einschließlich Bereitstellung von Backup-Medienkonvertern aufgrund des Netzteilpaares.
Und da unser Rechenzentrum zu diesem Zeitpunkt bereits vorbildlich geworden war, beschloss ich, auf Details zu achten: Die verfügbaren freien Einheiten waren mit schwarzen Lünetten bedeckt, und wo Belüftung erforderlich war, wurden perforierte Lünetten installiert. Sogar die Befestigungsschrauben, mit denen das Gerät im Rack befestigt ist, habe ich aus der Sprühdose entfernt und schwarz lackiert. Eine Kleinigkeit, aber nett. Art der Racks auf dem Reservestandort während der Installation (links) und am Ende (rechts).
Um die überall liegenden Medienkonverter loszuwerden, wurde ein Paar D-Link DMC-1000-Chassis gekauft, einschließlich Bereitstellung von Backup-Medienkonvertern aufgrund des Netzteilpaares. Gleichzeitig wurde an der Modernisierung des Netzwerks gearbeitet. Ich habe den Ring des Kerns des Datenübertragungsnetzwerks mit einer Geschwindigkeit von 20 Gbit / s zwischen Standorten geschlossen. Durch die Optimierung der vorhandenen Ausrüstung erhielt das Servicenetz für den Betrieb der virtuellen Infrastruktur eine 10-Gbit / s-Aufwärtsverbindung, die es ermöglichte, fast alle Blades gleichzeitig mit ausreichender Bandbreite zu migrieren.Die Kompatibilität von SNR-Geräten mit vorhandenen Cisco- und Brocade-Geräten erwies sich als sehr angenehm. Natürlich war das Vorhandensein von Brocade-Geräten im Chassis einmal eine unangenehme Überraschung für mich, da ich vorher nicht damit arbeiten musste. Glücklicherweise ermöglichte uns die Kenntnis der Prinzipien des Netzwerks, schnell damit umzugehen.Ein wichtiger Teil der Arbeit ist mir die Genauigkeit der Ausführung. Alles sollte nicht nur gut funktionieren, sondern auch gut aussehen. Je mehr Ordnung in der Arbeit, desto höher die Zuverlässigkeit. Es war ein Glück, dass keiner von mir einen solchen Arbeitsansatz hatte, daher wurde ich zusammen mit einem unserer Kollegen in den Regalen in eine vorbildliche Reihenfolge gebracht, glaube ich. Es muss überall Ordnung geben.
Gleichzeitig wurde an der Modernisierung des Netzwerks gearbeitet. Ich habe den Ring des Kerns des Datenübertragungsnetzwerks mit einer Geschwindigkeit von 20 Gbit / s zwischen Standorten geschlossen. Durch die Optimierung der vorhandenen Ausrüstung erhielt das Servicenetz für den Betrieb der virtuellen Infrastruktur eine 10-Gbit / s-Aufwärtsverbindung, die es ermöglichte, fast alle Blades gleichzeitig mit ausreichender Bandbreite zu migrieren.Die Kompatibilität von SNR-Geräten mit vorhandenen Cisco- und Brocade-Geräten erwies sich als sehr angenehm. Natürlich war das Vorhandensein von Brocade-Geräten im Chassis einmal eine unangenehme Überraschung für mich, da ich vorher nicht damit arbeiten musste. Glücklicherweise ermöglichte uns die Kenntnis der Prinzipien des Netzwerks, schnell damit umzugehen.Ein wichtiger Teil der Arbeit ist mir die Genauigkeit der Ausführung. Alles sollte nicht nur gut funktionieren, sondern auch gut aussehen. Je mehr Ordnung in der Arbeit, desto höher die Zuverlässigkeit. Es war ein Glück, dass keiner von mir einen solchen Arbeitsansatz hatte, daher wurde ich zusammen mit einem unserer Kollegen in den Regalen in eine vorbildliche Reihenfolge gebracht, glaube ich. Es muss überall Ordnung geben.
Inzwischen
Parallel zur physischen Einrichtung des Rechenzentrums und des OGV- Netzwerks wurde eine Software für das Funktionieren der elektronischen Verwaltung entwickelt, an der ich auch teilnehmen konnte. Sowohl in Bezug auf die Implementierung und den Einsatz als auch in Bezug auf die ideologische Unterstützung. Für die Unterstützung einer wahren Ideologie vielen Dank an die damalige Führung.Ich musste regelmäßig Datenbanken prüfen, Entwickler dazu bringen, Indizes in Datenbanken zu verwenden, ressourcenintensive Abfragen zu erfassen und Engpässe zu optimieren. Eines der Systeme außer den Primärschlüsseln hatte keine Indizes mehr. Das Ergebnis: Zu Beginn eines intensiven Betriebs begann sich die Datenbankleistung stark zu verschlechtern.Dank rechtzeitiger Eingriffe in den Entwicklungsprozess wurden alle entwickelten staatlichen Systeme plattformübergreifend gestaltet. Und wo es nicht dringend erforderlich war, Windows als Basis zu verwenden, funktionierte alles unter der Kontrolle der Linux-Systemfamilie. Wie sich herausstellte, war das Haupthindernis für die Erstellung plattformübergreifender Anwendungen die Verwendung einer nicht universellen Notation in Schreibpfaden. Oft wurde das staatliche System nach dem Ersetzen eines Schrägstrichs durch einen anderen abrupt plattformübergreifend.Das erstellte Netzwerk deckte auf die eine oder andere Weise fast das gesamte OGV ab . Ich war bereit, Internetverbindungen bereitzustellen, Datenverkehr zu filtern, Virenschutz zu bieten und Angriffe von außerhalb und innerhalb des OGV zu verhindern. Dies sollte insbesondere aufgrund der effizienteren Nutzung der Kanalbandbreite zu erheblichen Budgeteinsparungen führen.Nachdem ich einen einheitlichen technischen Support für das OGV eingerichtet hatte , plante ich die Schaffung von High-Tech-Arbeitsplätzen, um innerhalb unserer Organisation die Hauptkräfte für qualifizierte Arbeitsunterstützung zu konzentrieren, Techniker vor Ort zu lassen und gleichzeitig das Niveau der Spezialisten auf diesem Gebiet durch die Organisation von Konferenzen und Webinaren, Retreats ... zu verbessern.Die dritte Phase der Modernisierung des Rechenzentrums sollte für mich die interessanteste sein. Am Ende der zweiten Phase wurde ein Dialog mit Elbrus, dem Entwickler von Haushaltsprozessoren, aufgenommen, der Zugang zum Prüfstand wurde erlangt und es wurde klar, dass mindestens ein Drittel der Funktionalität der Betriebssysteme auf die Haushaltshardwareplattform übertragen werden kann! Erst im nächsten Jahr 2015 sollte eine neue Hardwareversion des inländischen Prozessors veröffentlicht werden ... Das Budget für das nächste Jahr enthielt die Summe für den Kauf von Servern ...
Zusammenfassend
Aber meine Träume, öffentliche Dienste auf eine inländische Hardwareplattform zu übertragen, waren nicht dazu bestimmt (wie andere Pläne), weil ich gezwungen war, meinen Job nicht weniger interessant, sondern höher bezahlt zu machen. Schade natürlich, ich denke, ich könnte einen guten Impuls für die Implementierung der heimischen Hardwareplattform geben. Darüber hinaus war dies vor der Welle der Importsubstitution.Zum Ende meiner Karriere in dieser Organisation auf der Grundlage unseres Rechenzentrums gelang es mir, Folgendes zu planen, zu erstellen, bereitzustellen oder an der Erstellung teilzunehmen:Insgesamt arbeiteten damals mehr als 120 virtuelle Server auf unseren 7 physischen Serverpaaren und verwendeten etwa 30-40% der CPU- und RAM-Ressourcen, etwa 50% des Speichersystems. Insgesamt waren zu diesem Zeitpunkt etwa 30 bis 35 Mitarbeiter beschäftigt, einschließlich des gesamten Verwaltungs- und Managementpersonals und des Anrufbearbeitungsdienstes.Ich bin mir sicher, dass die Effizienz der Nutzung im Gesicht liegt.Tatsächlich können Sie immer noch viel im Detail über die Bildung fast aller Dienste erzählen, dann erhalten Sie eine ziemlich gewichtige Menge an Erinnerungen.Danksagung
- Erstens, lieber Leser, für das Lesen an diesem Ort.
- Meine Frau für Hilfe und Unterstützung.
- An die Leitung der staatlichen öffentlichen Einrichtung SK "Regionales Zentrum für Informationstechnologien" für das gesetzte Vertrauen.
- Verwaltung des Ministeriums für Industrie, Energie und Kommunikation des Stawropol-Territoriums zur administrativen Unterstützung.
- Alle Kollegen, die damals Glück hatten zu arbeiten.
Source: https://habr.com/ru/post/de395197/
All Articles