Was ist differenzierte Privatsphäre?
Die ausgefeilte Technik der zufälligen Antwort wurde zuerst von Google verwendet, um Chrome-Statistiken zu sammeln. Wird Apple nachziehen?
Über den Autor. Matthew Green: Kryptograf, Professor an der Johns Hopkins University, Autor des Blogs über kryptografische SystemeVeröffentlicht am 14. Juni 2016 Gestern stellte Apple bei einem WWDC-Vortrag eine Reihe neuer Funktionen für die Sicherheit und den Schutz sensibler Daten vor, darunter eine, die besondere Aufmerksamkeit auf sich zog ... und Verwirrung. Apple kündigte nämlich die Verwendung einer neuen Technik namens "Differential Privacy" an, die als DP abgekürzt wird, um den Schutz der Privatsphäre beim Sammeln vertraulicher Benutzerdaten zu verbessern.Für die meisten Menschen warf dies eine dumme Frage auf: "Was zum ... ???", weil nur wenige zuvor von differenzierter Privatsphäre gehört haben und noch mehr verstehen, was dies bedeutet. Leider ist Apple nicht ganz klar, was die geheimen Zutaten angeht, auf denen die Plattform ausgeführt wird. Daher wird gehofft, dass Apple in Zukunft weitere Informationen veröffentlichen wird. Alles, was wir derzeit wissen, ist im Handbuch für Apple iOS 10 Preview enthalten.„Ab iOS 10 verwendet Apple die Differential Privacy-Technologie, um Muster des Benutzerverhaltens für eine große Anzahl von Benutzern zu identifizieren, ohne die Privatsphäre jedes Benutzers zu gefährden. Um die Identität einer Person zu verbergen, fügt die differenzielle Privatsphäre einer kleinen Stichprobe einer einzelnen Benutzerverhaltensvorlage für einen bestimmten Benutzer mathematisches Rauschen hinzu. Je mehr Menschen dasselbe Muster zeigen, desto häufiger treten Muster auf, die uns informieren und die allgemeine Benutzererfahrung verbessern können. In iOS 10 hilft diese Technologie dabei, QuickType- und Emoji-Tipps, Spotlight-Tipps und Nachschlagehinweise in Notizen zu verbessern. “Kurz gesagt, Apple möchte anscheinend viel mehr Daten von Ihrem Telefon erfassen.Grundsätzlich tun sie dies, um ihre Dienste zu verbessern und nicht um Informationen über die individuellen Gewohnheiten und Eigenschaften jedes Benutzers zu sammeln. Um dies zu gewährleisten, beabsichtigt Apple, ausgefeilte statistische Techniken einzusetzen, um sicherzustellen, dass die aggregierte Basis - das Ergebnis der Berechnung der statistischen Funktion nach Verarbeitung aller Ihrer Informationen - keine einzelnen Teilnehmer ausgibt. Im Prinzip klingt es ziemlich gut. Aber natürlich versteckt sich der Teufel immer im Detail.Obwohl wir diese Details nicht haben, scheint es jetzt an der Zeit zu sein, zumindest darüber zu sprechen, was differenzierter Datenschutz ist, wie er implementiert werden kann und was er für Apple und Ihr iPhone bedeuten kann.
Gestern stellte Apple bei einem WWDC-Vortrag eine Reihe neuer Funktionen für die Sicherheit und den Schutz sensibler Daten vor, darunter eine, die besondere Aufmerksamkeit auf sich zog ... und Verwirrung. Apple kündigte nämlich die Verwendung einer neuen Technik namens "Differential Privacy" an, die als DP abgekürzt wird, um den Schutz der Privatsphäre beim Sammeln vertraulicher Benutzerdaten zu verbessern.Für die meisten Menschen warf dies eine dumme Frage auf: "Was zum ... ???", weil nur wenige zuvor von differenzierter Privatsphäre gehört haben und noch mehr verstehen, was dies bedeutet. Leider ist Apple nicht ganz klar, was die geheimen Zutaten angeht, auf denen die Plattform ausgeführt wird. Daher wird gehofft, dass Apple in Zukunft weitere Informationen veröffentlichen wird. Alles, was wir derzeit wissen, ist im Handbuch für Apple iOS 10 Preview enthalten.„Ab iOS 10 verwendet Apple die Differential Privacy-Technologie, um Muster des Benutzerverhaltens für eine große Anzahl von Benutzern zu identifizieren, ohne die Privatsphäre jedes Benutzers zu gefährden. Um die Identität einer Person zu verbergen, fügt die differenzielle Privatsphäre einer kleinen Stichprobe einer einzelnen Benutzerverhaltensvorlage für einen bestimmten Benutzer mathematisches Rauschen hinzu. Je mehr Menschen dasselbe Muster zeigen, desto häufiger treten Muster auf, die uns informieren und die allgemeine Benutzererfahrung verbessern können. In iOS 10 hilft diese Technologie dabei, QuickType- und Emoji-Tipps, Spotlight-Tipps und Nachschlagehinweise in Notizen zu verbessern. “Kurz gesagt, Apple möchte anscheinend viel mehr Daten von Ihrem Telefon erfassen.Grundsätzlich tun sie dies, um ihre Dienste zu verbessern und nicht um Informationen über die individuellen Gewohnheiten und Eigenschaften jedes Benutzers zu sammeln. Um dies zu gewährleisten, beabsichtigt Apple, ausgefeilte statistische Techniken einzusetzen, um sicherzustellen, dass die aggregierte Basis - das Ergebnis der Berechnung der statistischen Funktion nach Verarbeitung aller Ihrer Informationen - keine einzelnen Teilnehmer ausgibt. Im Prinzip klingt es ziemlich gut. Aber natürlich versteckt sich der Teufel immer im Detail.Obwohl wir diese Details nicht haben, scheint es jetzt an der Zeit zu sein, zumindest darüber zu sprechen, was differenzierter Datenschutz ist, wie er implementiert werden kann und was er für Apple und Ihr iPhone bedeuten kann.Motivation
In den letzten Jahren hat sich der „normale Benutzer“ an die Idee gewöhnt, dass eine große Menge persönlicher Informationen von seinem Gerät an die verschiedenen Dienste gesendet wird, die er verwendet. Meinungsumfragen zeigen auch, dass sich die Bürger aus diesem Grund allmählich unwohl fühlen .Dieses Unbehagen ist sinnvoll, wenn Sie an Unternehmen denken, die unsere persönlichen Daten verwenden, um mit uns Geld zu verdienen. Manchmal gibt es jedoch einen guten Grund, Informationen über Benutzeraktionen zu sammeln. Beispielsweise hat Microsoft kürzlich ein Tool eingeführt, mit dem Bauchspeicheldrüsenkrebs diagnostiziert werden kann, indem Ihre Suchanfragen in Bing analysiert werden. Google unterstützt den bekannten Dienst Google Flu TrendsVorhersage der Ausbreitung von Infektionskrankheiten anhand der Häufigkeit von Suchanfragen in verschiedenen Bereichen. Und natürlich profitieren wir alle von Crowdsourcing- Daten , die die Qualität der von uns genutzten Dienste verbessern, von Kartenanwendungen bis hin zu Bewertungen in Restaurants.Leider kann auch das Sammeln von Daten für gute Zwecke schädlich sein. Zum Beispiel kündigte Netflix Ende der 2000er Jahre einen Wettbewerb an, um den besten Empfehlungsalgorithmus für Spielfilme zu entwickeln . Um den Teilnehmern des Wettbewerbs zu helfen, veröffentlichten sie einen „anonymisierten“ Datensatz mit Statistiken über die Ansichten von Filmnutzern und löschten alle persönlichen Informationen von dort. Leider reichte eine solche "Entidentifizierung" nicht aus. In der berühmten wissenschaftlichen Arbeit von Narayan und Shmatikovzeigten, dass solche Datensätze verwendet werden können, um bestimmte Benutzer zu dekanonymisieren - und sogar um ihre politischen Ansichten vorherzusagen! - einfach, wenn Sie ein paar zusätzliche Informationen über diese Benutzer kennen.Solche Dinge sollten uns stören. Nicht nur, weil kommerzielle Unternehmen gewöhnlich gesammelte Informationen über Benutzer austauschen (obwohl dies der Fall ist), sondern weil Hacks stattfinden und sogar Statistiken über die gesammelte Datenbank die Details der spezifischen einzelnen Datensätze, die verwendet wurden, irgendwie verdeutlichen können um eine aggregierte Stichprobe zu erstellen. Differential Privacy ist eine Reihe von Tools, mit denen dieses Problem gelöst werden kann.Was ist differenzierte Privatsphäre?
Differential Privacy ist eine Definition des Schutzes von Benutzerdaten, die ursprünglich von Cynthia Dwork im Jahr 2006 vorgeschlagen wurde. Grob gesagt kann es kurz wie folgt beschrieben werden:Stellen Sie sich vor, Sie haben im Übrigen zwei identische Datenbanken, eine mit Ihren Informationen und die andere ohne . Der differenzielle Datenschutz stellt sicher, dass eine statistische Abfrage an eine und die zweite Datenbank mit (fast) der gleichen Wahrscheinlichkeit zu einem bestimmten Ergebnis führt.Dies kann wie folgt dargestellt werden: DP ermöglicht es zu verstehen, ob Ihre Daten einen statistisch signifikanten Einfluss auf das Abfrageergebnis haben. Wenn nicht, können sie sicher zur Datenbank hinzugefügt werden, da dies praktisch keinen Schaden anrichtet.Stellen Sie sich dieses dumme Beispiel vor: Stellen Sie sich vor, Sie haben auf Ihrem iPhone die Option aktiviert, Apple darüber zu informieren, dass Sie  in Ihren iMessage-Chat-Sitzungen häufig Emojis verwenden . Dieser Bericht besteht aus einer Information: 1 bedeutet, dass Sie möchten , und 0 bedeutet, dass Sie dies nicht tun . Apple kann diese Berichte empfangen und in eine gigantische Datenbank eingeben. Infolgedessen möchte das Unternehmen in der Lage sein, die Anzahl der Benutzer herauszufinden, die ein bestimmtes Emoji mögen.
in Ihren iMessage-Chat-Sitzungen häufig Emojis verwenden . Dieser Bericht besteht aus einer Information: 1 bedeutet, dass Sie möchten , und 0 bedeutet, dass Sie dies nicht tun . Apple kann diese Berichte empfangen und in eine gigantische Datenbank eingeben. Infolgedessen möchte das Unternehmen in der Lage sein, die Anzahl der Benutzer herauszufinden, die ein bestimmtes Emoji mögen., DP, , , , , . ,
, - . , DP
,
zum Ergebnis. Anstatt lediglich das Endergebnis zu melden, kann der Berichterstatter beispielsweise eine Gauß- oder Laplace-Verteilung implementieren, sodass das Ergebnis nicht so genau ist, sondern jeden bestimmten Wert in der Datenbank maskiert. (Es gibt viele andere Techniken für andere interessante Funktionen ).Noch wertvoller ist die Berechnung der Menge des hinzugefügten Rauschens , ohne den Inhalt der Datenbank selbst (oder sogar ihre Größe) zu kennen . Das heißt, die Berechnung mit Rauschen kann nur auf der Grundlage der Kenntnis der Funktion selbst, die ausgeführt wird, und eines akzeptablen Niveaus an Datenlecks durchgeführt werden.Der Kompromiss zwischen Datenschutz und Genauigkeit
Jetzt ist es offensichtlich, dass das Zählen der Anzahl der Fans unter den Benutzern ein ziemlich schlechtes Beispiel ist. Im Fall von DP ist es wichtig, dass der gleiche allgemeine Ansatz auf viel interessantere Funktionen angewendet werden kann, einschließlich komplexer statistischer Berechnungen, wie sie in maschinellen Lernsystemen verwendet werden. Es kann auch angewendet werden, wenn viele verschiedene Funktionen in derselben Datenbank berechnet werden.Aber es gibt einen Haken. Tatsache ist, dass die Größe des „Informationslecks“ aus einer einzelnen Anforderung innerhalb kleiner Grenzen minimiert werden kann, jedoch nicht Null ist. Jedes Mal, wenn Sie eine Abfrage mit einer Funktion an eine Datenbank senden, erhöht sich das gesamte "Leck" - und kann niemals reduziert werden. Mit der Zeit kann das Leck mit zunehmender Anzahl von Anforderungen zunehmen.Dies ist einer der schwierigsten Aspekte von DP. Es manifestiert sich auf zwei Arten:- Je mehr Sie beabsichtigen, die Datenbank zu "fragen", desto mehr Rauschen müssen Sie hinzufügen, um Informationslecks zu minimieren . Dies bedeutet, dass DP in der Tat ein grundlegender Kompromiss zwischen Genauigkeit und Schutz personenbezogener Daten ist, der beim Training komplexer maschineller Lernmodelle zu einem großen Problem führen kann.
- , . , , , — , . . .
Die zulässige Gesamtmenge an Leckagen wird häufig als „Datenschutzbudget“ bezeichnet und bestimmt, wie viele Anfragen gestellt werden dürfen (und wie genau die Ergebnisse sein werden). Die wichtigste Lehre von DP ist, dass sich der Teufel in einem Budget versteckt. Wenn Sie den Wert zu hoch einstellen, werden wichtige Daten verloren gehen. Stellen Sie es zu niedrig ein, und Abfrageergebnisse können unbrauchbar sein.In einigen Anwendungen, wie den meisten Anwendungen in unseren iPhones, wird eine unzureichende Genauigkeit nicht zu einem besonderen Problem. Wir sind daran gewöhnt, dass unsere Smartphones Fehler machen. In Zeiten, in denen DP in komplexen Anwendungen wie dem Training von Modellen für maschinelles Lernen verwendet wird, ist dies jedoch sehr wichtig.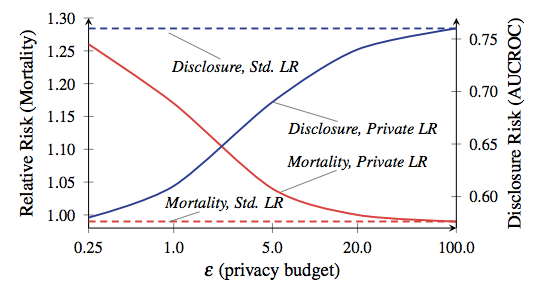 Das Verhältnis von Mortalität und Offenlegung aus der Arbeit von Frederickson et al. Ab 2014. Die rote Linie entspricht der Mortalität der Patienten.Um Ihnen ein absolut verrücktes Beispiel dafür zu geben, wie wichtig ein Kompromiss zwischen Datenschutz und Genauigkeit sein kann, schauen Sie sich dieses wissenschaftliche Papier von Frederickson et al . Aus dem Jahr 2014 an . Die Autoren korrelierten zunächst die Medikamentendosisdatenaus deroffenen Warfarin- Datenbankmit spezifischen genetischen Markern. Anschließend verwendeten sie Techniken des maschinellen Lernens, um ein Modell für die Berechnung von Dosierungen aus der Datenbank zu entwickeln. Während des Modelltrainings verwendeten sie jedoch DP mit verschiedenen Optionen für das Datenschutzbudget. Anschließend bewerteten sie den Grad der Informationsleckage und den Erfolg der Verwendung des Modells zur Behandlung virtueller „Patienten“.Die Ergebnisse zeigten, dass die Genauigkeit des Modells stark vom Datenschutzbudget abhängt, das während seiner Schulung festgelegt wurde. Wenn das Budget zu hoch eingestellt ist, wird eine erhebliche Menge vertraulicher Patienteninformationen aus der Datenbank gelöscht. Das resultierende Modell trifft jedoch Dosierungsentscheidungen, die so sicher sind wie die klinische Standardpraxis. Wenn andererseits das Budget auf ein Niveau reduziert wird, das eine akzeptable Privatsphäre bedeutet, neigt ein Modell, das auf verrauschten Daten trainiert ist, dazu, seine „Patienten“ zu töten.Bevor Sie in Panik geraten, lassen Sie mich erklären: Ihr iPhone wird Sie nicht töten. Niemand sagt, dass dieses Beispiel auch nur annähernd dem entspricht, was Apple auf Smartphones tun wird. Die Schlussfolgerung aus dieser Studie liegt einfach in der Tatsache, dass es in jedem DP-basierten System einen interessanten Kompromiss zwischen Effizienz und Datenschutz gibt - dieser Kompromiss hängt weitgehend von den spezifischen Entscheidungen der Entwickler des Systems, den ausgewählten Betriebsparametern usw. ab. Hoffen wir, dass Apple uns bald mitteilen wird, welche Optionen dies waren.
Das Verhältnis von Mortalität und Offenlegung aus der Arbeit von Frederickson et al. Ab 2014. Die rote Linie entspricht der Mortalität der Patienten.Um Ihnen ein absolut verrücktes Beispiel dafür zu geben, wie wichtig ein Kompromiss zwischen Datenschutz und Genauigkeit sein kann, schauen Sie sich dieses wissenschaftliche Papier von Frederickson et al . Aus dem Jahr 2014 an . Die Autoren korrelierten zunächst die Medikamentendosisdatenaus deroffenen Warfarin- Datenbankmit spezifischen genetischen Markern. Anschließend verwendeten sie Techniken des maschinellen Lernens, um ein Modell für die Berechnung von Dosierungen aus der Datenbank zu entwickeln. Während des Modelltrainings verwendeten sie jedoch DP mit verschiedenen Optionen für das Datenschutzbudget. Anschließend bewerteten sie den Grad der Informationsleckage und den Erfolg der Verwendung des Modells zur Behandlung virtueller „Patienten“.Die Ergebnisse zeigten, dass die Genauigkeit des Modells stark vom Datenschutzbudget abhängt, das während seiner Schulung festgelegt wurde. Wenn das Budget zu hoch eingestellt ist, wird eine erhebliche Menge vertraulicher Patienteninformationen aus der Datenbank gelöscht. Das resultierende Modell trifft jedoch Dosierungsentscheidungen, die so sicher sind wie die klinische Standardpraxis. Wenn andererseits das Budget auf ein Niveau reduziert wird, das eine akzeptable Privatsphäre bedeutet, neigt ein Modell, das auf verrauschten Daten trainiert ist, dazu, seine „Patienten“ zu töten.Bevor Sie in Panik geraten, lassen Sie mich erklären: Ihr iPhone wird Sie nicht töten. Niemand sagt, dass dieses Beispiel auch nur annähernd dem entspricht, was Apple auf Smartphones tun wird. Die Schlussfolgerung aus dieser Studie liegt einfach in der Tatsache, dass es in jedem DP-basierten System einen interessanten Kompromiss zwischen Effizienz und Datenschutz gibt - dieser Kompromiss hängt weitgehend von den spezifischen Entscheidungen der Entwickler des Systems, den ausgewählten Betriebsparametern usw. ab. Hoffen wir, dass Apple uns bald mitteilen wird, welche Optionen dies waren.Wie kann man auf jeden Fall Daten sammeln?
Sie haben festgestellt, dass ich in allen obigen Beispielen davon ausgegangen bin, dass die Abfragen von einem vertrauenswürdigen Datenbankbetreiber ausgeführt werden, der Zugriff auf alle ursprünglichen „Rohdaten“ hat. Ich habe dieses Modell gewählt, weil es eine traditionelle Version des Modells ist, die in fast der gesamten Literatur verwendet wird, und nicht, weil es eine gute Idee ist.In der Tat wird es Grund zur Besorgnis geben, wenn Apple wirklich implementiertIhr System auf ähnliche Weise. Dazu muss Apple alle anfänglichen Informationen zu Benutzeraktionen in einer massiven zentralisierten Datenbank sammeln und dann („Vertrauen Sie uns!“) Statistiken auf sichere Weise berechnen und gleichzeitig die Privatsphäre der Benutzer schützen. Diese Methode stellt zumindest Informationen zur Verfügung, um gerichtliche Vorladungen zu erhalten, sowie für ausländische Hacker, neugierige Top-Manager von Apple und so weiter.Glücklicherweise ist dies nicht die einzige Möglichkeit, ein differenziertes Datenschutzsystem zu implementieren. Theoretisch können Statistiken unter Verwendung ausgefallener kryptografischer Techniken (wie eines vertraulichen Berechnungsprotokolls oder einer vollständig homomorphen Verschlüsselung) berechnet werden) Leider sind diese Techniken wahrscheinlich zu ineffizient, um sie in dem von Apple benötigten Maßstab zu verwenden.Ein vielversprechenderer Ansatz scheint darin zu bestehen, überhaupt keine Rohdaten zu sammeln . Dieser Ansatz war kürzlich der erste unter allen, der Google zum Sammeln von Statistiken im Chrome-Browser verwendete . Ihr System namens RAPPOR basiert auf einer 50 Jahre alten randomisierten Antworttechnik . Die randomisierte Antwort funktioniert wie folgt:- ( : « Bing?»), , «», — . .
- ( , «»), «» .
Auf einer intuitiven Ebene schützt eine zufällige Antwort die Privatsphäre einzelner Benutzerberichte, da die Antwort „Ja“ entweder „Ja, ich verwende Bing“ oder einfach das Ergebnis zufälliger Münztropfen sein kann. Auf formaler Ebene bietet eine zufällige Antwort eine differenzierte Privatsphäre mit spezifischen Garantien, die durch Anpassen der Eigenschaften der Münzen angepasst werden können.RAPPOR nimmt diese relativ alte Technik und verwandelt sie in etwas viel Stärkeres. Anstatt nur eine Frage zu beantworten, kann das System einen Bericht über einen komplexen Vektor von Fragen erstellen und sogar komplexe Antworten zurückgeben, z. B. Zeichenfolgen - beispielsweise Ihre Startseite in Ihrem Browser. Letzteres wird erreicht, so dass der String zuerst durchlaufen wirdBloom-Filter - eine Folge von Bits, die mit Hash-Funktionen auf ganz bestimmte Weise generiert werden. Die empfangenen Bits werden dann mit Rauschen gemischt und summiert, und die Antworten werden unter Verwendung eines (ziemlich komplexen) Decodierungsprozesses wiederhergestellt. Obwohl es keine eindeutigen Beweise dafür gibt, dass Apple ein System wie RAPPOR verwendet, weisen einige kleine Tipps darauf hin. Zum Beispiel beschreibt Craig Federighi (im Leben sieht er genauso aus wie auf dem Foto) differenzierte Privatsphäre als "Verwenden von Hashing, Subsampling und Rauschen, um ... Crowdsourcing-Schulungen zu aktivieren und gleichzeitig einzelne Benutzerdaten vollständig privat zu halten".. Dies ist wahrscheinlich ein eher schwacher Beweis für irgendetwas, aber das Vorhandensein von "Hashing" in diesem Zitat legt zumindest die Verwendung von Filtern im RAPPOR-Stil nahe.Die Hauptschwierigkeit bei randomisierten Antwortsystemen besteht darin, dass sie sensible Daten ausgeben können, wenn der Benutzer dieselbe Frage mehrmals beantwortet. RAPPOR versucht dieses Problem auf verschiedene Weise zu lösen. Eine davon besteht darin, den statischen Teil der Informationen zu bestimmen und so die „permanente Antwort“ zu berechnen, anstatt sie jedes Mal neu zu randomisieren. Man kann sich jedoch Situationen vorstellen, in denen ein solcher Schutz nicht funktioniert. Wieder versteckt sich der Teufel oft in den Details - man muss sie nur sehen. Ich bin sicher, dass sowieso viele faszinierende wissenschaftliche Arbeiten veröffentlicht werden.
Obwohl es keine eindeutigen Beweise dafür gibt, dass Apple ein System wie RAPPOR verwendet, weisen einige kleine Tipps darauf hin. Zum Beispiel beschreibt Craig Federighi (im Leben sieht er genauso aus wie auf dem Foto) differenzierte Privatsphäre als "Verwenden von Hashing, Subsampling und Rauschen, um ... Crowdsourcing-Schulungen zu aktivieren und gleichzeitig einzelne Benutzerdaten vollständig privat zu halten".. Dies ist wahrscheinlich ein eher schwacher Beweis für irgendetwas, aber das Vorhandensein von "Hashing" in diesem Zitat legt zumindest die Verwendung von Filtern im RAPPOR-Stil nahe.Die Hauptschwierigkeit bei randomisierten Antwortsystemen besteht darin, dass sie sensible Daten ausgeben können, wenn der Benutzer dieselbe Frage mehrmals beantwortet. RAPPOR versucht dieses Problem auf verschiedene Weise zu lösen. Eine davon besteht darin, den statischen Teil der Informationen zu bestimmen und so die „permanente Antwort“ zu berechnen, anstatt sie jedes Mal neu zu randomisieren. Man kann sich jedoch Situationen vorstellen, in denen ein solcher Schutz nicht funktioniert. Wieder versteckt sich der Teufel oft in den Details - man muss sie nur sehen. Ich bin sicher, dass sowieso viele faszinierende wissenschaftliche Arbeiten veröffentlicht werden.Ist die Verwendung von DP durch Apple also gut oder schlecht?
Als Wissenschaftler und Spezialist für Informationssicherheit habe ich diesbezüglich gemischte Gefühle. Einerseits verstehe ich als Wissenschaftler, wie interessant es ist, die Umsetzung fortgeschrittener wissenschaftlicher Entwicklungen in einem realen Produkt zu beobachten. Und Apple bietet eine sehr große Plattform für solche Experimente.Andererseits ist es meine Pflicht als praktischer Sicherheitsspezialist, skeptisch zu bleiben - das Unternehmen sollte bei der geringsten Frage Code anzeigen, der für die Sicherheit von entscheidender Bedeutung ist (wie Google es bei RAPPOR getan hat ), oder zumindest explizit angeben , was es implementiert. Wenn Apple plant, riesige Mengen neuer Daten von Geräten zu sammeln, von denen wir so abhängig sind, sollten wir das wirklich tunsicher, dass sie alles richtig machen - und sie nicht gewaltsam für die Umsetzung solch cooler Ideen begrüßen. (Ich habe schon einmal einen solchen Fehler gemacht und fühle mich deshalb immer noch wie ein Idiot).Aber vielleicht sind all dies zu tiefe Details. Am Ende sieht es definitiv so aus, als würde Apple ehrlich versuchen, etwas zu tun, um die vertraulichen Informationen der Benutzer zu schützen , und unter Berücksichtigung von Alternativen könnte dies das Wichtigste sein.Source: https://habr.com/ru/post/de395313/
All Articles