Das neuronale Netzwerk für Bildverarbeitung wird in realistischen Computerspielen trainiert.
 Aufnahmen aus dem Computerspiel Grand Theft Auto V und semantisches Markup zum Unterrichten einesneuronalen Maschinennetzwerks Neuronale Netze stellen in fast allen Computer-Vision-Wettbewerben neue Rekorde auf und werden zunehmend auch in anderen KI-Anwendungen verwendet. Eine der Schlüsselkomponenten einer solch unglaublichen Leistung eines neuronalen Netzwerks ist die Verfügbarkeit großer Datenmengen für Training und Evaluierung. Beispielsweise wird die Imagenet Large Scale Visual Recognition Challenge (ILSVRC) mit mehr als 1 Million Bildern zur Bewertung moderner neuronaler Netze verwendet. Nach den neuesten Ergebnissen zu urteilen (ResNet zeigt das Ergebnis von nur 3,57% der Fehler) müssen Forscher bald umfangreichere Datensätze zusammenstellen. Und dann - noch umfangreicher. Das Kommentieren solcher Fotos ist übrigens eine Menge Arbeit, die teilweise manuell erledigt werden muss.Einige Entwickler von Computer-Vision-Systemen bieten eine alternative Möglichkeit, solche Systeme zu trainieren und zu testen. Anstatt Trainingsfotos manuell zu kommentieren, verwenden sie synthetisierte Frames aus realistischen Computerspielen.Dies ist ein völlig logischer Ansatz. In modernen Spielen haben Grafiken einen solchen Realismus erreicht, dass sich die synthetisierten Bilder nur geringfügig von Fotografien der realen Welt unterscheiden. Gleichzeitig kann die Spiel-Engine eine unendliche Anzahl solcher Frames erzeugen - dies löst das Problem, Millionen von Fotos für das Training und die Auswertung des neuronalen Netzwerks zu sammeln, sofort dramatisch.Obwohl die Spiel-Engine eine begrenzte Anzahl von Texturen verwendet, gibt es eine Vielzahl von Kombinationen aus Betrachtungswinkeln, Beleuchtung, Wetter und Detaillierungsgrad, die eine ausreichende Vielfalt an Datensätzen bereitstellen.In diesem Jahr haben zwei Forschergruppen in der Praxis geprüft, ob es möglich ist, die aus Computerspielen generierten Frames für das Training neuronaler Computer-Vision-Netzwerke zu verwenden. Eine Gruppe von Forschern der Informatikabteilung der University of British Columbia (Kanada) veröffentlichte einen wissenschaftlichen Artikel, für den sie mehr als 60.000 Bilder aus einem Computerspiel mit Straßenansichten sammelten, die den Datensätzen von CamVid und Cityscapes ähneln . Den Forschern gelang es zu beweisen, dass das neuronale Netzwerk nach dem Training auf synthetischen Bildern ein ähnliches Fehlerniveau aufweist wie nach dem Training auf realen Fotos. Darüber hinaus zeigt das Training synthetisierter Bilder mit realen Fotos ein noch besseres Ergebnis.Alle 60.000 Bilder wurden bei virtuell sonnigem Wetter um 11:00 Uhr mit einer Auflösung von 1024 × 768 und maximalen Grafikeinstellungen aufgenommen (der Name des Spiels wurde aus urheberrechtlichen Gründen nicht bekannt gegeben). Ein unbemanntes Fahrzeug fuhr versehentlich durch die Spielstraßen und beachtete die Straßenregeln. Die Bilder wurden einmal pro Sekunde aufgenommen. Jedes von ihnen wird von einer automatischen semantischen Segmentierung (Himmel, Fußgänger, Autos, Bäume, Hintergrund - die Segmentierung ist absolut genau und aus dem Spiel übernommen), einem tiefen Bild (Tiefenbild, Karte mit dem Markup von Objekten) sowie Normalen zur Oberfläche begleitet.Zusätzlich zum Basis-VG-Datensatz haben die Forscher einen weiteren VG + -Datensatz mit vielen semantischen Informationen erstellt, der nicht auf fünf Bezeichnungen beschränkt ist - hier ist die Segmentierung nicht genau. Das Markup wurde automatisch mit SegNet durchgeführt .
Aufnahmen aus dem Computerspiel Grand Theft Auto V und semantisches Markup zum Unterrichten einesneuronalen Maschinennetzwerks Neuronale Netze stellen in fast allen Computer-Vision-Wettbewerben neue Rekorde auf und werden zunehmend auch in anderen KI-Anwendungen verwendet. Eine der Schlüsselkomponenten einer solch unglaublichen Leistung eines neuronalen Netzwerks ist die Verfügbarkeit großer Datenmengen für Training und Evaluierung. Beispielsweise wird die Imagenet Large Scale Visual Recognition Challenge (ILSVRC) mit mehr als 1 Million Bildern zur Bewertung moderner neuronaler Netze verwendet. Nach den neuesten Ergebnissen zu urteilen (ResNet zeigt das Ergebnis von nur 3,57% der Fehler) müssen Forscher bald umfangreichere Datensätze zusammenstellen. Und dann - noch umfangreicher. Das Kommentieren solcher Fotos ist übrigens eine Menge Arbeit, die teilweise manuell erledigt werden muss.Einige Entwickler von Computer-Vision-Systemen bieten eine alternative Möglichkeit, solche Systeme zu trainieren und zu testen. Anstatt Trainingsfotos manuell zu kommentieren, verwenden sie synthetisierte Frames aus realistischen Computerspielen.Dies ist ein völlig logischer Ansatz. In modernen Spielen haben Grafiken einen solchen Realismus erreicht, dass sich die synthetisierten Bilder nur geringfügig von Fotografien der realen Welt unterscheiden. Gleichzeitig kann die Spiel-Engine eine unendliche Anzahl solcher Frames erzeugen - dies löst das Problem, Millionen von Fotos für das Training und die Auswertung des neuronalen Netzwerks zu sammeln, sofort dramatisch.Obwohl die Spiel-Engine eine begrenzte Anzahl von Texturen verwendet, gibt es eine Vielzahl von Kombinationen aus Betrachtungswinkeln, Beleuchtung, Wetter und Detaillierungsgrad, die eine ausreichende Vielfalt an Datensätzen bereitstellen.In diesem Jahr haben zwei Forschergruppen in der Praxis geprüft, ob es möglich ist, die aus Computerspielen generierten Frames für das Training neuronaler Computer-Vision-Netzwerke zu verwenden. Eine Gruppe von Forschern der Informatikabteilung der University of British Columbia (Kanada) veröffentlichte einen wissenschaftlichen Artikel, für den sie mehr als 60.000 Bilder aus einem Computerspiel mit Straßenansichten sammelten, die den Datensätzen von CamVid und Cityscapes ähneln . Den Forschern gelang es zu beweisen, dass das neuronale Netzwerk nach dem Training auf synthetischen Bildern ein ähnliches Fehlerniveau aufweist wie nach dem Training auf realen Fotos. Darüber hinaus zeigt das Training synthetisierter Bilder mit realen Fotos ein noch besseres Ergebnis.Alle 60.000 Bilder wurden bei virtuell sonnigem Wetter um 11:00 Uhr mit einer Auflösung von 1024 × 768 und maximalen Grafikeinstellungen aufgenommen (der Name des Spiels wurde aus urheberrechtlichen Gründen nicht bekannt gegeben). Ein unbemanntes Fahrzeug fuhr versehentlich durch die Spielstraßen und beachtete die Straßenregeln. Die Bilder wurden einmal pro Sekunde aufgenommen. Jedes von ihnen wird von einer automatischen semantischen Segmentierung (Himmel, Fußgänger, Autos, Bäume, Hintergrund - die Segmentierung ist absolut genau und aus dem Spiel übernommen), einem tiefen Bild (Tiefenbild, Karte mit dem Markup von Objekten) sowie Normalen zur Oberfläche begleitet.Zusätzlich zum Basis-VG-Datensatz haben die Forscher einen weiteren VG + -Datensatz mit vielen semantischen Informationen erstellt, der nicht auf fünf Bezeichnungen beschränkt ist - hier ist die Segmentierung nicht genau. Das Markup wurde automatisch mit SegNet durchgeführt . Eng markierte Frames aus dem VG +-Satz Um die Effektivität des neuronalen Netzwerktrainings zu vergleichen, wurden CamVid- und Cityscapes-Datensätze (fünf Tags) sowie CamVid + und Cityscapes + mit erweiterten Tag-Sets erstellt.
Eng markierte Frames aus dem VG +-Satz Um die Effektivität des neuronalen Netzwerktrainings zu vergleichen, wurden CamVid- und Cityscapes-Datensätze (fünf Tags) sowie CamVid + und Cityscapes + mit erweiterten Tag-Sets erstellt. Original-CamVid-Fotos mit Anmerkungen
Original-CamVid-Fotos mit Anmerkungen Zwei zufällige Bilder der Cityscapes + mit detaillierten Anmerkungen.Für die semantische Klassifizierung wurde ein langes Faltungs-Neuronales Netzwerk mit einer einfachen FCN8-Architektur auf dem 16- lagigen VGG-Netz von Simonyan und Sisserman verwendet.Die Forscher führten mehrere Experimente durch, um die Erkennungseffizienz von Objekten durch ein neuronales Netzwerk zu bewerten, das auf verschiedenen Datensätzen trainiert wurde. In fast allen Fällen zeigte ein neuronales Netzwerk, das auf synthetischen Daten trainiert wurde, ein besseres Ergebnis als ein neuronales Netzwerk, das auf realen Fotos trainiert wurde. Sie zeigte das beste Ergebnis, selbst wenn sie echte Fotos überprüfte.Die Tabelle zeigt beispielsweise die Leistung identischer neuronaler Netze, die an drei Datensätzen (reale Fotos, synthetische Daten aus dem Spiel, gemischter Satz) trainiert wurden, wenn Objekte in realen Fotos von CamVid + - und Cityscapes + -Sätzen erkannt werden.
Zwei zufällige Bilder der Cityscapes + mit detaillierten Anmerkungen.Für die semantische Klassifizierung wurde ein langes Faltungs-Neuronales Netzwerk mit einer einfachen FCN8-Architektur auf dem 16- lagigen VGG-Netz von Simonyan und Sisserman verwendet.Die Forscher führten mehrere Experimente durch, um die Erkennungseffizienz von Objekten durch ein neuronales Netzwerk zu bewerten, das auf verschiedenen Datensätzen trainiert wurde. In fast allen Fällen zeigte ein neuronales Netzwerk, das auf synthetischen Daten trainiert wurde, ein besseres Ergebnis als ein neuronales Netzwerk, das auf realen Fotos trainiert wurde. Sie zeigte das beste Ergebnis, selbst wenn sie echte Fotos überprüfte.Die Tabelle zeigt beispielsweise die Leistung identischer neuronaler Netze, die an drei Datensätzen (reale Fotos, synthetische Daten aus dem Spiel, gemischter Satz) trainiert wurden, wenn Objekte in realen Fotos von CamVid + - und Cityscapes + -Sätzen erkannt werden.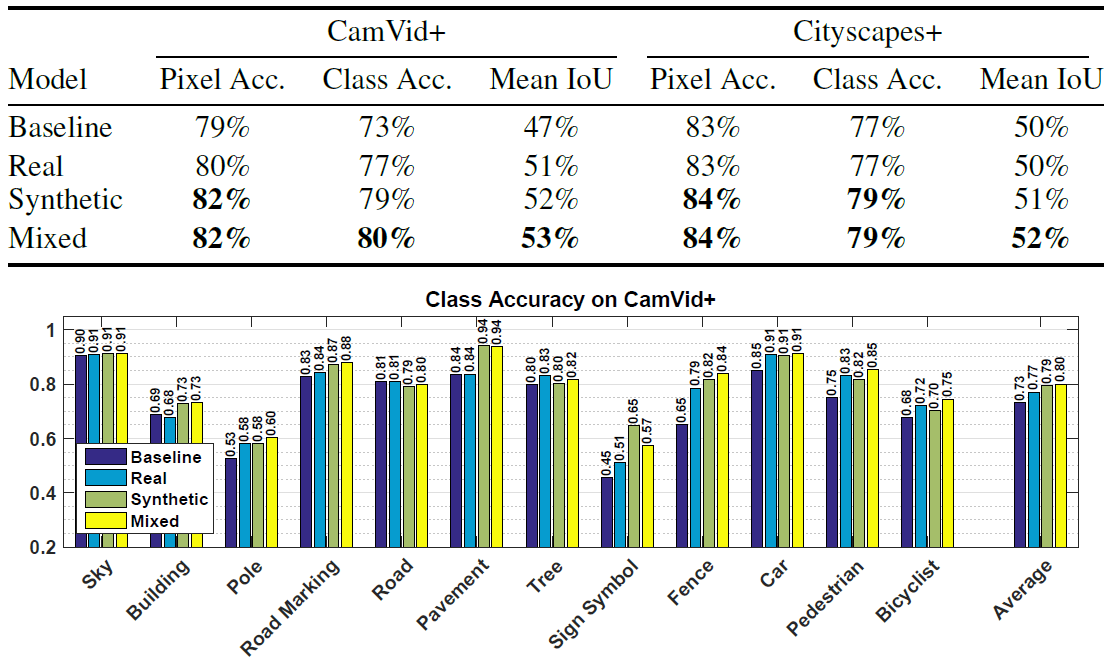 Wie Sie sehen können, ist es beim Training eines neuronalen Netzwerks am besten, die synthetischen Bilder eines Computerspiels durch echte Fotos zu ergänzen.Wissenschaftlicher Artikelveröffentlicht am 5. August 2016 auf arXiv.org, die zweite Version ist der 15. August ( pdf ).Neben Forschern der University of British Columbia wurde fast gleichzeitig dieselbe Arbeit von einer anderen Gruppe von Wissenschaftlern der Technischen Universität Darmstadt (Deutschland) und von Intel Labs geleistet . Sie nahmen 24.966 Bilder für das Training aus dem Open-World-Computerspiel Grand Theft Auto V. Die Forscher kamen zu dem gleichen Ergebnis: Bei Verwendung eines Trainingsdatensatzes, der aus 2/3 synthetischer Bilder und 1/3 CamVid-Fotos bestand, war die Genauigkeit Die Erkennung ist höher als nur bei Verwendung von CamVid-Fotos.
Wie Sie sehen können, ist es beim Training eines neuronalen Netzwerks am besten, die synthetischen Bilder eines Computerspiels durch echte Fotos zu ergänzen.Wissenschaftlicher Artikelveröffentlicht am 5. August 2016 auf arXiv.org, die zweite Version ist der 15. August ( pdf ).Neben Forschern der University of British Columbia wurde fast gleichzeitig dieselbe Arbeit von einer anderen Gruppe von Wissenschaftlern der Technischen Universität Darmstadt (Deutschland) und von Intel Labs geleistet . Sie nahmen 24.966 Bilder für das Training aus dem Open-World-Computerspiel Grand Theft Auto V. Die Forscher kamen zu dem gleichen Ergebnis: Bei Verwendung eines Trainingsdatensatzes, der aus 2/3 synthetischer Bilder und 1/3 CamVid-Fotos bestand, war die Genauigkeit Die Erkennung ist höher als nur bei Verwendung von CamVid-Fotos.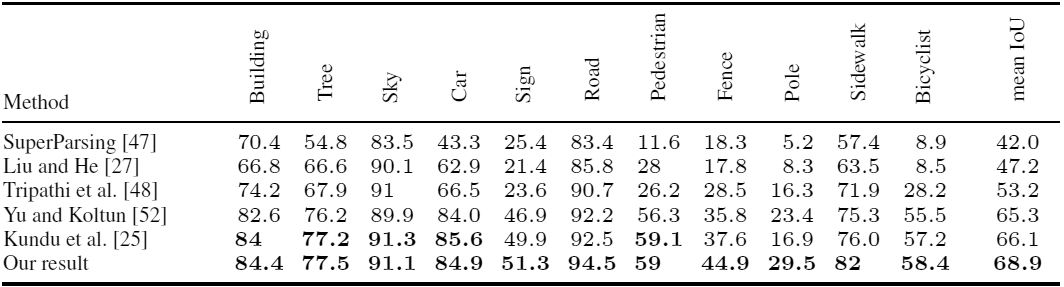 Genauigkeit der Erkennung verschiedener Objekte in Fotos aus dem CamVid-Set beim Lernen mit herkömmlichen Methoden und bei Verwendung von Frames aus GTA V (unterste Zeile)Gleichzeitig reduziert die halbautomatische Annotation in einem speziell entwickelten Editor den Zeitaufwand für die Vorbereitung eines Datensatzes zum Trainieren eines neuronalen Netzwerks erheblich. Das Annotieren eines CamVid-Fotos dauert beispielsweise 60 Minuten, ein Cityscapes-Foto 90 Minuten und die halbautomatische Annotation von GTA V-Frames dauert durchschnittlich nur 7 Sekunden ( Video, Demonstration des Editors ).Die Arbeit der Forscher von der Technischen Universität Darmstadt und Intel Labs hat für die Europäische Konferenz über Computer Vision vorbereitet ECCV'16 (11-14 Oktober) veröffentlicht auf der Website der Universität. Die Autoren legten den Quellcode zum Lesen von Etiketten und vollständigen Datensätzen fest : sowohl Quellfotos als auch detaillierte Bilder mit semantischem Markup. Der Quellcode des Editors für Anmerkungen wird voraussichtlich in Zukunft veröffentlicht.Dank der Fortschritte bei der Entwicklung realistischer Computerspiele steht Entwicklern künstlicher Intelligenz eine hervorragende Plattform zum Erlernen von Bildverarbeitungssystemen zur Verfügung. Diese Systeme werden in unbemannten Fahrzeugen und Robotern eingesetzt.Vielleicht können Computerspiele nicht nur für die Bildverarbeitung verwendet werden, sondern auch zur Schaffung natürlicher Verhaltensmuster in der Gesellschaft. Nur beim KI-Training sollten Sie bei der Auswahl eines Spiels vorsichtig sein.
Genauigkeit der Erkennung verschiedener Objekte in Fotos aus dem CamVid-Set beim Lernen mit herkömmlichen Methoden und bei Verwendung von Frames aus GTA V (unterste Zeile)Gleichzeitig reduziert die halbautomatische Annotation in einem speziell entwickelten Editor den Zeitaufwand für die Vorbereitung eines Datensatzes zum Trainieren eines neuronalen Netzwerks erheblich. Das Annotieren eines CamVid-Fotos dauert beispielsweise 60 Minuten, ein Cityscapes-Foto 90 Minuten und die halbautomatische Annotation von GTA V-Frames dauert durchschnittlich nur 7 Sekunden ( Video, Demonstration des Editors ).Die Arbeit der Forscher von der Technischen Universität Darmstadt und Intel Labs hat für die Europäische Konferenz über Computer Vision vorbereitet ECCV'16 (11-14 Oktober) veröffentlicht auf der Website der Universität. Die Autoren legten den Quellcode zum Lesen von Etiketten und vollständigen Datensätzen fest : sowohl Quellfotos als auch detaillierte Bilder mit semantischem Markup. Der Quellcode des Editors für Anmerkungen wird voraussichtlich in Zukunft veröffentlicht.Dank der Fortschritte bei der Entwicklung realistischer Computerspiele steht Entwicklern künstlicher Intelligenz eine hervorragende Plattform zum Erlernen von Bildverarbeitungssystemen zur Verfügung. Diese Systeme werden in unbemannten Fahrzeugen und Robotern eingesetzt.Vielleicht können Computerspiele nicht nur für die Bildverarbeitung verwendet werden, sondern auch zur Schaffung natürlicher Verhaltensmuster in der Gesellschaft. Nur beim KI-Training sollten Sie bei der Auswahl eines Spiels vorsichtig sein.Source: https://habr.com/ru/post/de397557/
All Articles