"Photoshop" für menschliche Sprache
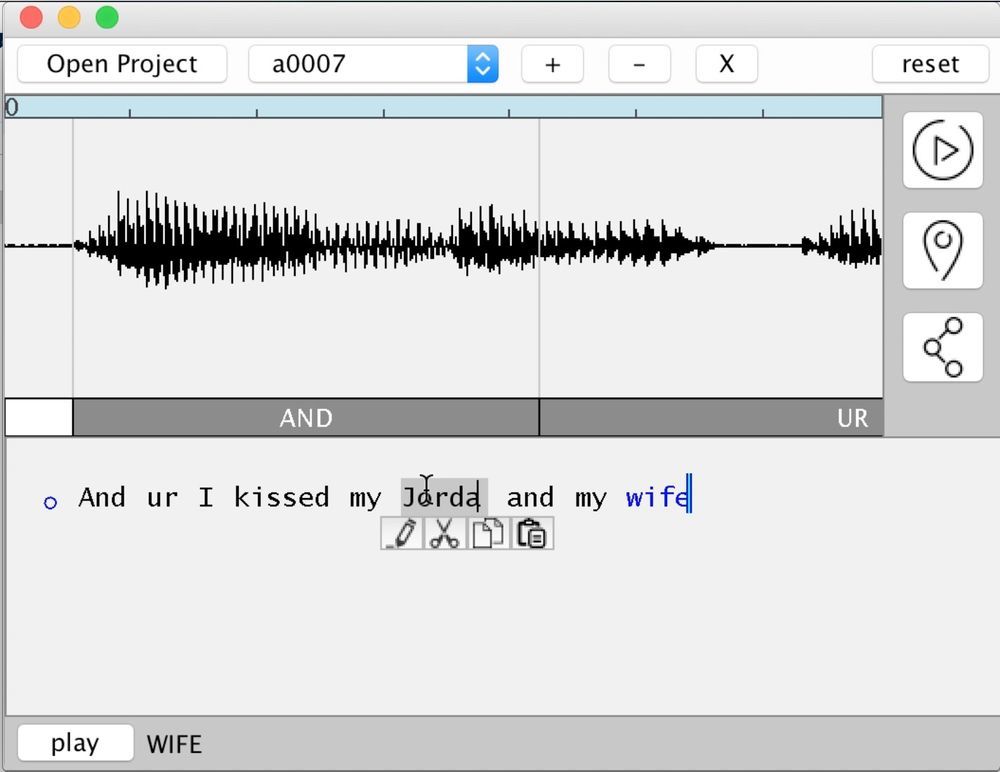 Am 3. November 2016 präsentierte Adobe auf der Adobe MAX-Technologiekonferenz eine sehr interessante wissenschaftliche und technische Entwicklung, die sich in Zukunft zu einer beliebten Softwareanwendung entwickeln könnte. Kurz gesagt ist die Erfindung ein Programm zur semantischen Bearbeitung menschlicher Sprache. In diesem Fall wird nicht nur die Standardsynthesemethode aus gesammelten Phonemen (Kompilierungssynthese) verwendet, sondern auch Hilfsmethoden, die den Realismus erhöhen. Dies ist eine intelligente Auswahl von Trifons und die Verwendung der spezifischen Eigenschaften der Beispielstimme.Infolgedessen schreibt der Benutzer beliebigen Text - und das Programm spricht ihn mit der Stimme aus, auf der er trainiert wurde. Sie können der Rede schnell beliebige Wörter hinzufügen oder unnötige Wörter ausschneiden.In der Praxis funktioniert das im Rahmen des VoCo-Projekts vorgestellte Programm wie folgt. Zunächst wird die Phonembasis für die Stimme einer bestimmten Person in einer bestimmten Sprache zusammengestellt. Für realistische Ergebnisse benötigt das Programm mindestens 20 Minuten menschliche Sprache. Je mehr desto besser. Basierend auf den gesammelten Phonemen (Trifons) kann das Programm dann fast alle neuen Wörter wie aus Ziegeln sammeln.Fragment der VoCo-Präsentation auf der MAX-KonferenzIn gewisser Weise funktioniert VoCo wie die Arbeit eines Kontextpinsels in Photoshop. Sie nimmt auch Fragmente von verschiedenen Stellen des Bildes - und sammelt ein neues Bild von diesen Fragmenten. Ein Stück Holz von einem Foto eines Waldes, ein Stück Gras von einem anderen Bild und ein Mädchen vom dritten Foto - und wir bekommen eine völlig neue fotorealistische Arbeit mit einem Wald, Gras und einem Mädchen im Vordergrund. Wenn die Arbeit professionell ausgeführt wird, ist die Installation sehr schwer zu bestimmen. In der Sowjetzeit wurden Menschen, die plötzlich zu Feinden des Volkes wurden, aus der Geschichte gestrichen . Auf dem Foto war eine Person - und jetzt gibt es eine Leere oder eine andere Person.Mit der VoCo-Technologie können Sie die menschliche Sprache mit beliebigen Wörtern und Phrasen ergänzen.Auf der MAX-Konferenz hielt einer der Entwickler, Zeyu Jin, eine Präsentation. In einer zuvor veröffentlichten wissenschaftlichen Arbeit wird er zusammen mit seinem Kollegen Adam Finkelstein als Mitarbeiter der Princeton University aufgeführt. Die Technologie wurde von Adobe Research in Zusammenarbeit mit der Princeton University entwickelt.Wie von Adobe konzipiert, hilft die Technologie den Erstellern von Inhalten dabei, die Audiospur einfacher zu bearbeiten: Dialoge und Voice-Over-Text, um Fehler schnell zu beheben oder Änderungen an der Storyline vorzunehmen.Adobe betont, dass es in diesem Fall angemessener ist, von „Sprachkonvertierung“ als von klassischer Sprachsynthese zu sprechen. Der Zweck der Sprachumwandlung besteht darin, die Originalstimme so zu transformieren, dass sie für den Hörer die Stimme einer anderen Person zu sein scheint, die dem Modell der Stimme der letzteren folgt.Die technischen Grundlagen der Sprachumwandlung werden in der oben genannten wissenschaftlichen Arbeit ausführlicher beschrieben .gemeinsam mit der Princeton University vorbereitet. Die Autoren zeigen, dass die entwickelte CUTE-Technik anderen Methoden der Sprachumwandlung qualitativ überlegen ist. Alternative Konvertierungsmethoden basieren normalerweise auf der parallelen Analyse identischer Phrasen von Quelle und Ziel, gefolgt von der Berechnung bestimmter Transformationsvektoren in einem beliebigen Adressraum. Danach kann jedes beliebige Fragment der Originalstimme unter Verwendung der erhaltenen Vektoren transformiert werden. Diese Methoden leiden jedoch unter unangenehmen Nebenwirkungen - die auf diese Weise synthetisierte Sprache ist taub und verschwommen.Mit der Hybrid-CUTE-Methode konnten Adobe-Forscher die Mängel anderer Techniken überwinden. Der Titel verschlüsselt die vier Hauptkomponenten dieser Technik: Kompilierungssynthese (verkettete Synthese); Einheitenauswahl; vorläufige Auswahl von Trifons, dh Einheiten von drei Phonemen (Triphone-Vorauswahl); Verwenden von Beispieleigenschaften (beispielbasierte Funktionen).Die Kompilierungssynthese reduziert sich auf das Verfassen einer Nachricht aus einem zuvor aufgezeichneten Wörterbuch von Phonemen. Dies ist die Hauptmethode für die Arbeit mit Sprachsynthesizern, die mit verschiedenen Geräten ausgestattet sind: von Militärflugzeugen bis zu Haushaltsgeräten, in den Hilfsdiensten von Mobilfunkbetreibern usw.Wie der Name schon sagt, kombiniert die entwickelte Hybridtechnik verschiedene Methoden der Sprachsynthese und Sprachumwandlung.Die wissenschaftliche Arbeit präsentiert die Ergebnisse von Vergleichstests mit anderen Methoden der Sprachumwandlung, bei denen CUTE den Wettbewerbern deutlich überlegen ist. Gleichzeitig werden einige seiner Mängel erwähnt: Er leidet wie alle anderen unter einer unzureichenden Anzahl von Phonemen in der Datenbank, wenn er neue Wörter synthetisiert, was zu phonetisch korrekten, aber nicht sehr realistischen Ergebnissen führt. Darüber hinaus hängt es vom Betrieb der Spracherkennungsmaschine für eine korrekte phonetische Segmentierung ab.Es ist noch nicht bekannt, ob Adobe diese vielversprechende Entwicklung in Form eines echten kommerziellen Produkts umsetzen wird. Aber jetzt können wir sagen, dass ein solches Programm sehr populär werden würde, vorausgesetzt, die Synthese der Stimme aus Phonemen ist realistisch. Podcaster könnten damit beispielsweise Podcasts aus Text generieren. Es kann auch verwendet werden, um Hörbücher mit der Stimme einer beliebigen Person (z. B. Ihres eigenen Mädchens) zu sprechen. Eine solche Technologie wird wahrscheinlich in Hollywood Anwendung für Sprachausgabe finden, wenn kein Schauspieler vorhanden ist. Zum Beispiel, wenn ein Vertrag mit ihm gebrochen wurde oder er mitten in den Dreharbeiten starb.
Am 3. November 2016 präsentierte Adobe auf der Adobe MAX-Technologiekonferenz eine sehr interessante wissenschaftliche und technische Entwicklung, die sich in Zukunft zu einer beliebten Softwareanwendung entwickeln könnte. Kurz gesagt ist die Erfindung ein Programm zur semantischen Bearbeitung menschlicher Sprache. In diesem Fall wird nicht nur die Standardsynthesemethode aus gesammelten Phonemen (Kompilierungssynthese) verwendet, sondern auch Hilfsmethoden, die den Realismus erhöhen. Dies ist eine intelligente Auswahl von Trifons und die Verwendung der spezifischen Eigenschaften der Beispielstimme.Infolgedessen schreibt der Benutzer beliebigen Text - und das Programm spricht ihn mit der Stimme aus, auf der er trainiert wurde. Sie können der Rede schnell beliebige Wörter hinzufügen oder unnötige Wörter ausschneiden.In der Praxis funktioniert das im Rahmen des VoCo-Projekts vorgestellte Programm wie folgt. Zunächst wird die Phonembasis für die Stimme einer bestimmten Person in einer bestimmten Sprache zusammengestellt. Für realistische Ergebnisse benötigt das Programm mindestens 20 Minuten menschliche Sprache. Je mehr desto besser. Basierend auf den gesammelten Phonemen (Trifons) kann das Programm dann fast alle neuen Wörter wie aus Ziegeln sammeln.Fragment der VoCo-Präsentation auf der MAX-KonferenzIn gewisser Weise funktioniert VoCo wie die Arbeit eines Kontextpinsels in Photoshop. Sie nimmt auch Fragmente von verschiedenen Stellen des Bildes - und sammelt ein neues Bild von diesen Fragmenten. Ein Stück Holz von einem Foto eines Waldes, ein Stück Gras von einem anderen Bild und ein Mädchen vom dritten Foto - und wir bekommen eine völlig neue fotorealistische Arbeit mit einem Wald, Gras und einem Mädchen im Vordergrund. Wenn die Arbeit professionell ausgeführt wird, ist die Installation sehr schwer zu bestimmen. In der Sowjetzeit wurden Menschen, die plötzlich zu Feinden des Volkes wurden, aus der Geschichte gestrichen . Auf dem Foto war eine Person - und jetzt gibt es eine Leere oder eine andere Person.Mit der VoCo-Technologie können Sie die menschliche Sprache mit beliebigen Wörtern und Phrasen ergänzen.Auf der MAX-Konferenz hielt einer der Entwickler, Zeyu Jin, eine Präsentation. In einer zuvor veröffentlichten wissenschaftlichen Arbeit wird er zusammen mit seinem Kollegen Adam Finkelstein als Mitarbeiter der Princeton University aufgeführt. Die Technologie wurde von Adobe Research in Zusammenarbeit mit der Princeton University entwickelt.Wie von Adobe konzipiert, hilft die Technologie den Erstellern von Inhalten dabei, die Audiospur einfacher zu bearbeiten: Dialoge und Voice-Over-Text, um Fehler schnell zu beheben oder Änderungen an der Storyline vorzunehmen.Adobe betont, dass es in diesem Fall angemessener ist, von „Sprachkonvertierung“ als von klassischer Sprachsynthese zu sprechen. Der Zweck der Sprachumwandlung besteht darin, die Originalstimme so zu transformieren, dass sie für den Hörer die Stimme einer anderen Person zu sein scheint, die dem Modell der Stimme der letzteren folgt.Die technischen Grundlagen der Sprachumwandlung werden in der oben genannten wissenschaftlichen Arbeit ausführlicher beschrieben .gemeinsam mit der Princeton University vorbereitet. Die Autoren zeigen, dass die entwickelte CUTE-Technik anderen Methoden der Sprachumwandlung qualitativ überlegen ist. Alternative Konvertierungsmethoden basieren normalerweise auf der parallelen Analyse identischer Phrasen von Quelle und Ziel, gefolgt von der Berechnung bestimmter Transformationsvektoren in einem beliebigen Adressraum. Danach kann jedes beliebige Fragment der Originalstimme unter Verwendung der erhaltenen Vektoren transformiert werden. Diese Methoden leiden jedoch unter unangenehmen Nebenwirkungen - die auf diese Weise synthetisierte Sprache ist taub und verschwommen.Mit der Hybrid-CUTE-Methode konnten Adobe-Forscher die Mängel anderer Techniken überwinden. Der Titel verschlüsselt die vier Hauptkomponenten dieser Technik: Kompilierungssynthese (verkettete Synthese); Einheitenauswahl; vorläufige Auswahl von Trifons, dh Einheiten von drei Phonemen (Triphone-Vorauswahl); Verwenden von Beispieleigenschaften (beispielbasierte Funktionen).Die Kompilierungssynthese reduziert sich auf das Verfassen einer Nachricht aus einem zuvor aufgezeichneten Wörterbuch von Phonemen. Dies ist die Hauptmethode für die Arbeit mit Sprachsynthesizern, die mit verschiedenen Geräten ausgestattet sind: von Militärflugzeugen bis zu Haushaltsgeräten, in den Hilfsdiensten von Mobilfunkbetreibern usw.Wie der Name schon sagt, kombiniert die entwickelte Hybridtechnik verschiedene Methoden der Sprachsynthese und Sprachumwandlung.Die wissenschaftliche Arbeit präsentiert die Ergebnisse von Vergleichstests mit anderen Methoden der Sprachumwandlung, bei denen CUTE den Wettbewerbern deutlich überlegen ist. Gleichzeitig werden einige seiner Mängel erwähnt: Er leidet wie alle anderen unter einer unzureichenden Anzahl von Phonemen in der Datenbank, wenn er neue Wörter synthetisiert, was zu phonetisch korrekten, aber nicht sehr realistischen Ergebnissen führt. Darüber hinaus hängt es vom Betrieb der Spracherkennungsmaschine für eine korrekte phonetische Segmentierung ab.Es ist noch nicht bekannt, ob Adobe diese vielversprechende Entwicklung in Form eines echten kommerziellen Produkts umsetzen wird. Aber jetzt können wir sagen, dass ein solches Programm sehr populär werden würde, vorausgesetzt, die Synthese der Stimme aus Phonemen ist realistisch. Podcaster könnten damit beispielsweise Podcasts aus Text generieren. Es kann auch verwendet werden, um Hörbücher mit der Stimme einer beliebigen Person (z. B. Ihres eigenen Mädchens) zu sprechen. Eine solche Technologie wird wahrscheinlich in Hollywood Anwendung für Sprachausgabe finden, wenn kein Schauspieler vorhanden ist. Zum Beispiel, wenn ein Vertrag mit ihm gebrochen wurde oder er mitten in den Dreharbeiten starb.Source: https://habr.com/ru/post/de398865/
All Articles