Neuronales Netzwerk LipNet liest Lippen mit einer Genauigkeit von 93,4%
 Commander Dave Bowman und Co-Pilot Frank Poole, die dem Computer nicht vertrauten, beschlossen, ihn von der Kontrolle des Schiffes zu trennen. Dazu konferieren sie in einem schallisolierten Raum, aber HAL 9000 liest ihre Konversation auf den Lippen. Aufnahme aus dem Film „Space Odyssey of 2001“Lippenlesen spielt eine wichtige Rolle in der Kommunikation. Weitere Experimente im Jahr 1976 zeigten, dass Menschen völlig unterschiedliche Phoneme „hören“, wenn Sie den falschen Klang auf die Bewegung der Lippen anwenden (siehe „Lippen hören und Stimmen sehen“ , Nature 264, 746-748, 23. Dezember 1976, doi: 10.1038 / 264746a0). .Aus praktischer Sicht ist das Lippenlesen eine wichtige und nützliche Fähigkeit. Sie können den Gesprächspartner verstehen, ohne die Musik im Kopfhörer auszuschalten, die Gespräche aller Personen im Sichtfeld (z. B. aller Passagiere im Wartezimmer) lesen, Personen mit einem Fernglas oder einem Teleskop zuhören. Der Umfang der Fertigkeit ist sehr breit. Ein Profi, der es gemeistert hat, wird leicht einen gut bezahlten Job finden. Zum Beispiel im Bereich Sicherheit oder Competitive Intelligence.Automatische Lippenlesesysteme haben auch ein großes praktisches Potenzial. Dies sind medizinische Hörgeräte der neuen Generation mit Spracherkennung, Systemen für stille Vorträge an öffentlichen Orten, biometrischer Identifizierung, Systemen für die geheime Übermittlung von Informationen für Spionage, Spracherkennung per Video von Überwachungskameras usw. Am Ende werden auch Computer der Zukunft Lippen lesen, wie der HAL 9000 .Daher haben Wissenschaftler seit vielen Jahren versucht, automatische Lippenlesesysteme zu entwickeln, jedoch ohne großen Erfolg. Selbst für relativ einfaches Englisch, bei dem die Anzahl der Phoneme viel geringer ist als bei Russisch, ist die Erkennungsgenauigkeit gering.Das Verstehen von Sprache basierend auf menschlichen Gesichtsausdrücken ist eine entmutigende Aufgabe. Menschen, die diese Fähigkeit beherrschen, versuchen, Dutzende von Konsonantenphonemen zu erkennen, von denen viele im Aussehen sehr ähnlich sind. Für eine nicht geschulte Person ist es besonders schwierig, zwischen fünf Kategorien von visuellen Phonemen (d. H. Visemen) der englischen Sprache zu unterscheiden. Mit anderen Worten, es ist fast unmöglich, die Aussprache einiger Konsonanten durch die Lippen zu unterscheiden. Es ist nicht überraschend, dass Menschen mit genauem Lippenlesen sehr schlecht abschneiden. Selbst die besten Hörgeschädigten weisen eine Genauigkeit von nur 17 ± 12% von 30 einsilbigen oder 21 ± 11% der mehrsilbigen Wörter auf (im Folgenden die Ergebnisse für die englische Sprache).Das automatische Ablesen der Lippen ist eine der Aufgaben der Bildverarbeitung, bei der es um die Einzelbildverarbeitung einer Videosequenz geht. Die Aufgabe wird durch die geringe Qualität der meisten praktischen Videomaterialien sehr kompliziert, die kein genaues Lesen des raumzeitlichen, d. H. Räumlich-zeitlichen Merkmals einer Person während eines Gesprächs ermöglichen. Gesichter bewegen sich und drehen sich in verschiedene Richtungen. Jüngste Entwicklungen auf dem Gebiet der Bildverarbeitung versuchen, die Bewegung des Gesichts im Rahmen zu verfolgen, um dieses Problem zu lösen. Trotz der Erfolge konnten sie bis vor kurzem nur einzelne Wörter, aber keine Sätze erkennen.Ein bedeutender Durchbruch in diesem Bereich wurde von Entwicklern der Universität Oxford erzielt. Das LipNet haben sie trainiertwar der erste auf der Welt, der Lippen auf der Ebene ganzer Sätze erfolgreich erkannte und Videomaterial verarbeitete.
Commander Dave Bowman und Co-Pilot Frank Poole, die dem Computer nicht vertrauten, beschlossen, ihn von der Kontrolle des Schiffes zu trennen. Dazu konferieren sie in einem schallisolierten Raum, aber HAL 9000 liest ihre Konversation auf den Lippen. Aufnahme aus dem Film „Space Odyssey of 2001“Lippenlesen spielt eine wichtige Rolle in der Kommunikation. Weitere Experimente im Jahr 1976 zeigten, dass Menschen völlig unterschiedliche Phoneme „hören“, wenn Sie den falschen Klang auf die Bewegung der Lippen anwenden (siehe „Lippen hören und Stimmen sehen“ , Nature 264, 746-748, 23. Dezember 1976, doi: 10.1038 / 264746a0). .Aus praktischer Sicht ist das Lippenlesen eine wichtige und nützliche Fähigkeit. Sie können den Gesprächspartner verstehen, ohne die Musik im Kopfhörer auszuschalten, die Gespräche aller Personen im Sichtfeld (z. B. aller Passagiere im Wartezimmer) lesen, Personen mit einem Fernglas oder einem Teleskop zuhören. Der Umfang der Fertigkeit ist sehr breit. Ein Profi, der es gemeistert hat, wird leicht einen gut bezahlten Job finden. Zum Beispiel im Bereich Sicherheit oder Competitive Intelligence.Automatische Lippenlesesysteme haben auch ein großes praktisches Potenzial. Dies sind medizinische Hörgeräte der neuen Generation mit Spracherkennung, Systemen für stille Vorträge an öffentlichen Orten, biometrischer Identifizierung, Systemen für die geheime Übermittlung von Informationen für Spionage, Spracherkennung per Video von Überwachungskameras usw. Am Ende werden auch Computer der Zukunft Lippen lesen, wie der HAL 9000 .Daher haben Wissenschaftler seit vielen Jahren versucht, automatische Lippenlesesysteme zu entwickeln, jedoch ohne großen Erfolg. Selbst für relativ einfaches Englisch, bei dem die Anzahl der Phoneme viel geringer ist als bei Russisch, ist die Erkennungsgenauigkeit gering.Das Verstehen von Sprache basierend auf menschlichen Gesichtsausdrücken ist eine entmutigende Aufgabe. Menschen, die diese Fähigkeit beherrschen, versuchen, Dutzende von Konsonantenphonemen zu erkennen, von denen viele im Aussehen sehr ähnlich sind. Für eine nicht geschulte Person ist es besonders schwierig, zwischen fünf Kategorien von visuellen Phonemen (d. H. Visemen) der englischen Sprache zu unterscheiden. Mit anderen Worten, es ist fast unmöglich, die Aussprache einiger Konsonanten durch die Lippen zu unterscheiden. Es ist nicht überraschend, dass Menschen mit genauem Lippenlesen sehr schlecht abschneiden. Selbst die besten Hörgeschädigten weisen eine Genauigkeit von nur 17 ± 12% von 30 einsilbigen oder 21 ± 11% der mehrsilbigen Wörter auf (im Folgenden die Ergebnisse für die englische Sprache).Das automatische Ablesen der Lippen ist eine der Aufgaben der Bildverarbeitung, bei der es um die Einzelbildverarbeitung einer Videosequenz geht. Die Aufgabe wird durch die geringe Qualität der meisten praktischen Videomaterialien sehr kompliziert, die kein genaues Lesen des raumzeitlichen, d. H. Räumlich-zeitlichen Merkmals einer Person während eines Gesprächs ermöglichen. Gesichter bewegen sich und drehen sich in verschiedene Richtungen. Jüngste Entwicklungen auf dem Gebiet der Bildverarbeitung versuchen, die Bewegung des Gesichts im Rahmen zu verfolgen, um dieses Problem zu lösen. Trotz der Erfolge konnten sie bis vor kurzem nur einzelne Wörter, aber keine Sätze erkennen.Ein bedeutender Durchbruch in diesem Bereich wurde von Entwicklern der Universität Oxford erzielt. Das LipNet haben sie trainiertwar der erste auf der Welt, der Lippen auf der Ebene ganzer Sätze erfolgreich erkannte und Videomaterial verarbeitete.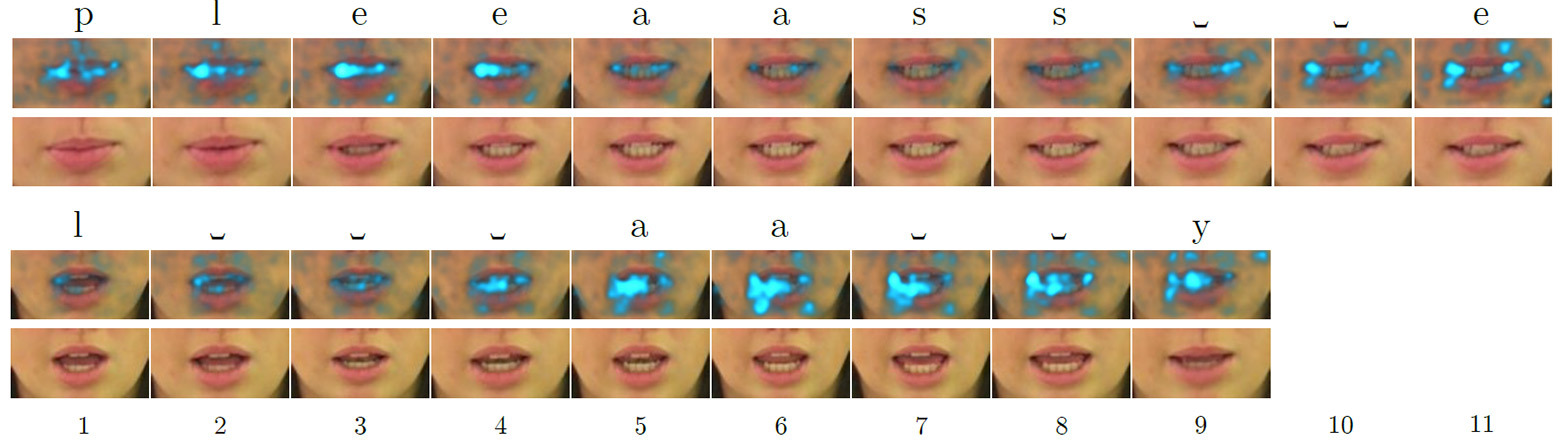 Frame-für-Frame- Salience-Maps für die englischen Wörter "Please" (oben) und "Lay" (unten), wenn sie von einem neuronalen Netzwerk verarbeitet werden, das Lippen liest, wobei die auffälligsten (hervorstechendsten) Merkmale vonLipNet hervorgehoben werden - ein wiederkehrendes neuronales Netzwerk vom Typ LSTM (Langzeit-Kurzzeitgedächtnis). Die Architektur ist in der Abbildung dargestellt. Das neuronale Netzwerk wurde mit der CTC-Methode (Connectionist Temporal Classification) trainiert, die in modernen Spracherkennungssystemen weit verbreitet ist, da kein Training für einen Satz von Eingabedaten erforderlich ist, die mit dem richtigen Ergebnis synchronisiert sind.
Frame-für-Frame- Salience-Maps für die englischen Wörter "Please" (oben) und "Lay" (unten), wenn sie von einem neuronalen Netzwerk verarbeitet werden, das Lippen liest, wobei die auffälligsten (hervorstechendsten) Merkmale vonLipNet hervorgehoben werden - ein wiederkehrendes neuronales Netzwerk vom Typ LSTM (Langzeit-Kurzzeitgedächtnis). Die Architektur ist in der Abbildung dargestellt. Das neuronale Netzwerk wurde mit der CTC-Methode (Connectionist Temporal Classification) trainiert, die in modernen Spracherkennungssystemen weit verbreitet ist, da kein Training für einen Satz von Eingabedaten erforderlich ist, die mit dem richtigen Ergebnis synchronisiert sind.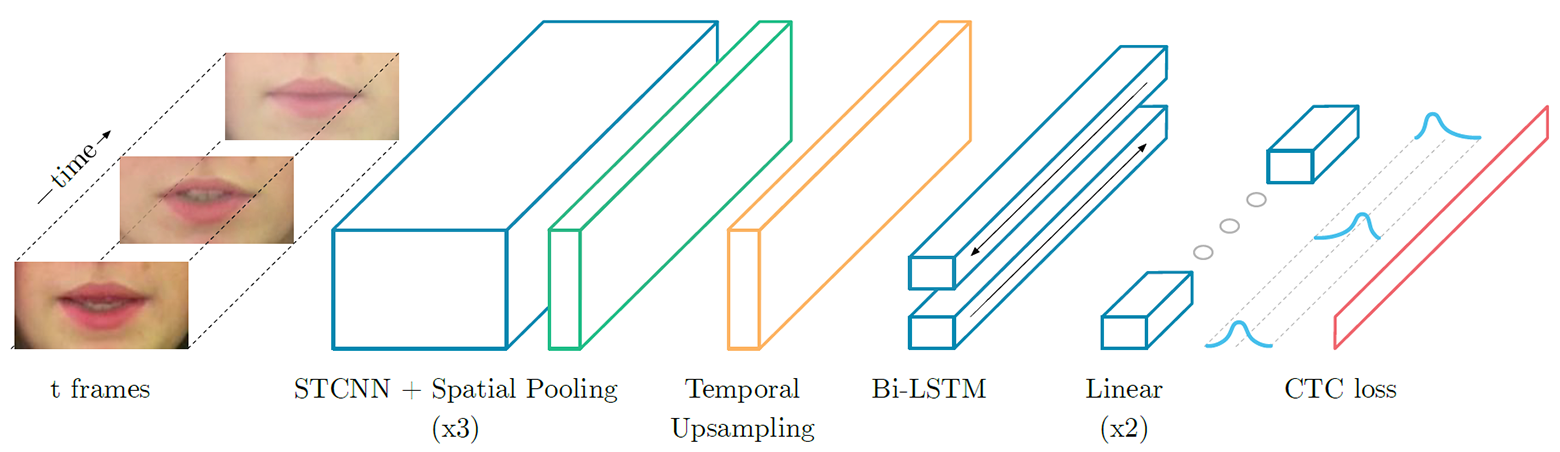 Neuronale LipNet-Netzwerkarchitektur. Am Eingang wird eine Folge von T-Frames geliefert, die dann von drei Schichten des raumzeitlichen (raumzeitlichen) Faltungs-Neuronalen Netzwerks (STCNN) verarbeitet werden, von denen jede von einer räumlichen Abtastschicht begleitet wird. Für die extrahierten Merkmale wird die Abtastrate auf der Zeitachse erhöht (Upsampling), und dann werden sie durch doppeltes LTSM verarbeitet. Jeder Zeitschritt am LTSM-Ausgang wird von einem zweischichtigen Direktverteilungsnetzwerk und der letzten SoftMax-Schicht verarbeitet.In einem speziellen GRID-Angebotspaket weist das neuronale Netzwerk eine Erkennungsgenauigkeit von 93,4% auf. Dies übertrifft nicht nur die Erkennungsgenauigkeit anderer Softwareentwicklungen (die in der folgenden Tabelle angegeben sind), sondern auch die Effizienz des Lesens auf den Lippen von speziell geschulten Personen.
Neuronale LipNet-Netzwerkarchitektur. Am Eingang wird eine Folge von T-Frames geliefert, die dann von drei Schichten des raumzeitlichen (raumzeitlichen) Faltungs-Neuronalen Netzwerks (STCNN) verarbeitet werden, von denen jede von einer räumlichen Abtastschicht begleitet wird. Für die extrahierten Merkmale wird die Abtastrate auf der Zeitachse erhöht (Upsampling), und dann werden sie durch doppeltes LTSM verarbeitet. Jeder Zeitschritt am LTSM-Ausgang wird von einem zweischichtigen Direktverteilungsnetzwerk und der letzten SoftMax-Schicht verarbeitet.In einem speziellen GRID-Angebotspaket weist das neuronale Netzwerk eine Erkennungsgenauigkeit von 93,4% auf. Dies übertrifft nicht nur die Erkennungsgenauigkeit anderer Softwareentwicklungen (die in der folgenden Tabelle angegeben sind), sondern auch die Effizienz des Lesens auf den Lippen von speziell geschulten Personen.| Methode | Datensatz | Größe | Problem | Genauigkeit |
|---|
| Fu et al. (2008) | AVICAR | 851 | | 37,9% |
| Zhao et al. (2009) | AVLetter | 78 | | 43,5% |
| Papandreou et al. (2009) | CUAVE | 1800 | | 83,0% |
| Chung & Zisserman (2016a) | OuluVS1 | 200 | | 91,4% |
| Chung & Zisserman (2016b) | OuluVS2 | 520 | | 94,1% |
| Chung & Zisserman (2016a) | BBC TV | >400000 | | 65,4% |
| Wand et al. (2016) | GRID | 9000 | | 79,6% |
| LipNet | GRID | 28853 | | 93,4% |
Der spezielle GRID-Fall setzt sich nach folgender Vorlage zusammen:Befehl (4) + Farbe (4) + Präposition (4) + Buchstabe (25) + Ziffer (10) + Adverb (4),wobei die Anzahl der Anzahl der Wortvarianten für jede der sechs verbalen Kategorien entspricht .Mit anderen Worten, die Genauigkeit von 93,4% ist immer noch das Ergebnis, das unter Gewächshauslaborbedingungen erhalten wird. Natürlich wird das Ergebnis mit der Erkennung willkürlicher menschlicher Sprache viel schlechter sein. Ganz zu schweigen von der Analyse von Daten aus echten Videos, bei denen das Gesicht einer Person nicht in hervorragender Beleuchtung und hoher Auflösung aus der Nähe aufgenommen wird.Der Betrieb des neuronalen LipNet-Netzwerks wird im Demo-Video gezeigt.Wissenschaftliche Arbeit vorbereitet für die Konferenz ICLR 2017 und veröffentlicht 4. November 2016 in der Public Domain.Source: https://habr.com/ru/post/de398901/
All Articles