Letztes Mal [
Herunterladen von Daten von der Open-Data-Site data.gov.ru ] habe ich mit einigen Problemen gelernt, wie man Daten vom russischen Open-Data-Portal herunterlädt. Das Open-Data-Portal sollte die relevantesten Informationen zu den Open-Data-Daten von Bundesbehörden, Regionalbehörden und anderen Organisationen enthalten (Zitat aus data.gov.ru). Mal sehen, welche Daten auf dem Portal, wie relevant sie sind und in welcher Form sie platziert sind.
Das folgende Kreisdiagramm zeigt die Verteilung der Datensätze nach Kategorien.
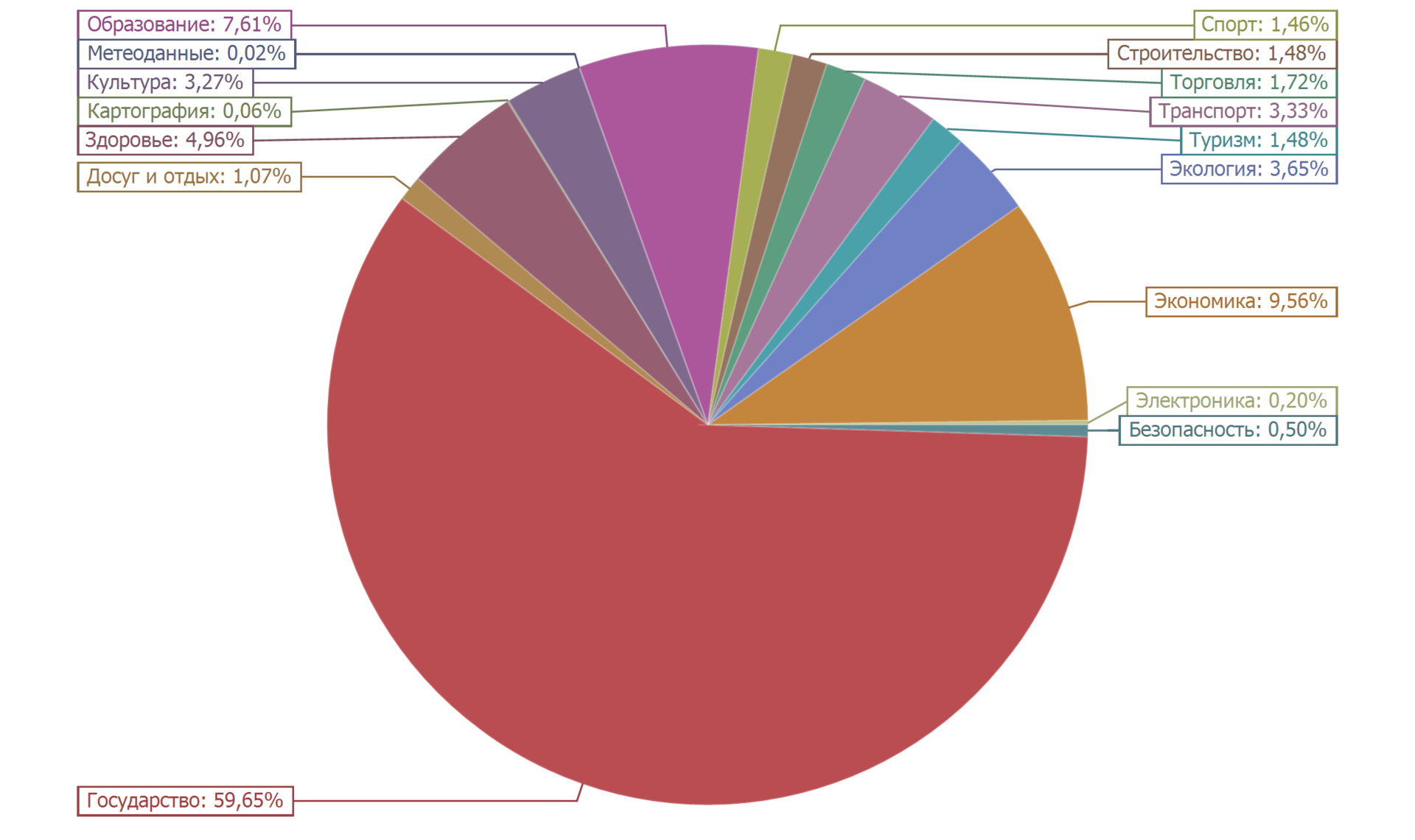
Mehr als die Hälfte der Datensätze (59,65%) gehört zur Kategorie „Staat“. Etwa zehn Prozent (9,56%) gehören zur Kategorie „Wirtschaft“. Fast zehn Prozent (7,61%) ist die Anzahl der Datensätze in der Kategorie Bildung. Der Rest beträgt weniger als fünf Prozent. Die Verteilung ist ganz natürlich.
Wir werden unsere Bekanntschaft mit den auf dem Portal veröffentlichten Daten erweitern. Schauen wir uns die Statistiken zur Platzierung im Datenportal bis zum Datum der ersten Veröffentlichung des Datensatzes an.
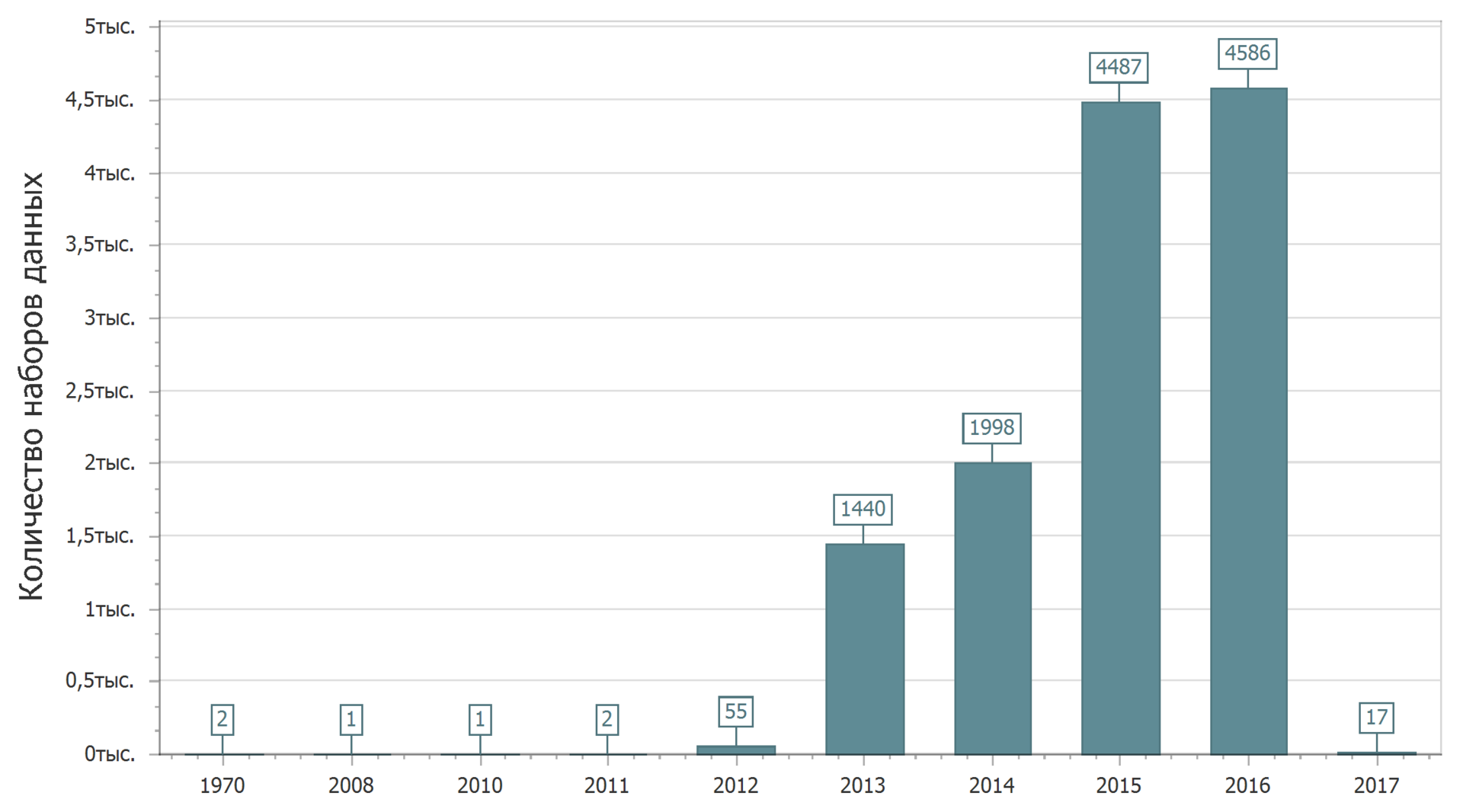
2017 hat gerade erst begonnen und es ist natürlich, dass die Menge der 2017 veröffentlichten Daten zunehmen wird. Ja, während ich den Text schreibe, werden neue Datensätze in das Portal hochgeladen.
Anscheinend hat es jemand in der Vergangenheit geschafft, Daten im fernen 1970 zu platzieren.
Im Allgemeinen ist das Bild klar: erst scharfes Wachstum, dann Stabilität. Obwohl es wahrscheinlich zu früh ist, um über Stabilität zu sprechen.
Ein interessantes Bild zeigt sich, wenn wir die Verteilung der Datensätze nach dem relevanten Datum betrachten (dem Datum, nach dem die aktuelle Version des Datensatzes aktualisiert werden sollte).
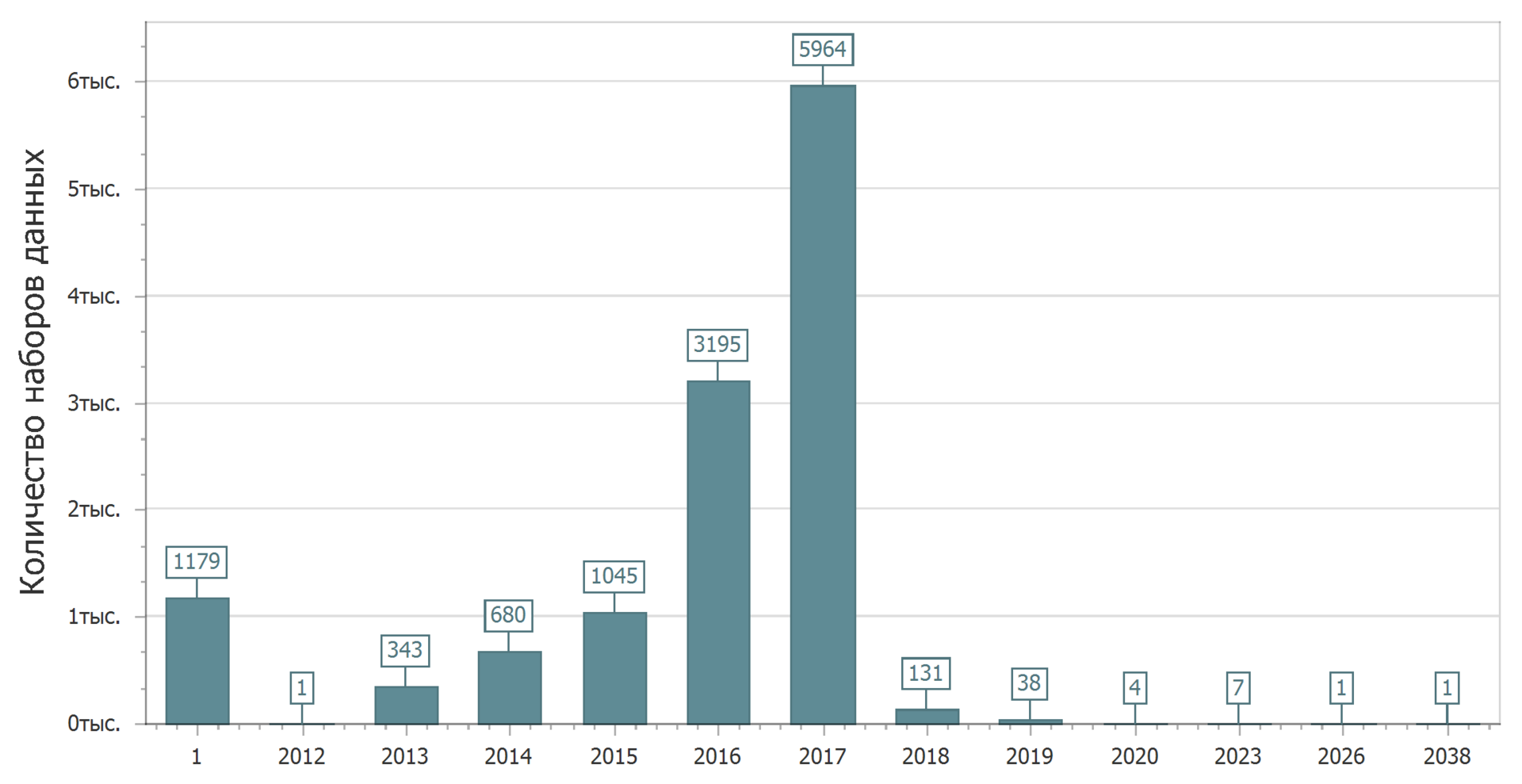
Eilt sofort 1 Jahr. Daher habe ich Datensätze festgelegt, die kein aktuelles Datum haben. Basierend auf der Bestimmung des relevanten Datums können wir den Schluss ziehen, dass es sich um Datensätze handelt, die überhaupt nicht aktualisiert werden müssen. Natürlich haben solche Datensätze ein Existenzrecht. Es gibt immer archivierte (historische) Daten, die sich wahrscheinlich nicht ändern (naja, wenn es keine Fehler gibt), und es gibt aktuelle - aktuelle Daten, die sich ständig ändern. Sowohl diese als auch andere können von Interesse sein. Es kommt schließlich vor, dass Sie herausfinden müssen: Wie war es dort in der Vergangenheit (unter dem Zaren oder unter dem Sowjetregime)? Interessanter sind natürlich aktuelle (Live-) Daten, die ständig aktualisiert werden.
Auch wenn Sie das Diagramm nicht sehr sorgfältig betrachten, ist es klar, dass einige Daten in eher ferner Zukunft aktualisiert werden sollten. Wir können sagen, dass diejenigen, die sie veröffentlicht haben, großes Vertrauen in die Zukunft haben. In den nächsten fünf, zehn, zwanzig (?) Jahren werden sie nichts ändern. Oder ist es nur ein Fehler? Und es ist möglich.
Aber im Allgemeinen ist das Bild ziemlich glücklich - fast die Hälfte der Datenpläne soll in diesem Jahr aktualisiert werden.
Und jetzt werden wir dieses freudige Bild bestätigen. Berücksichtigen Sie die Verteilung der Datensätze bis zum Datum der letzten Änderung.
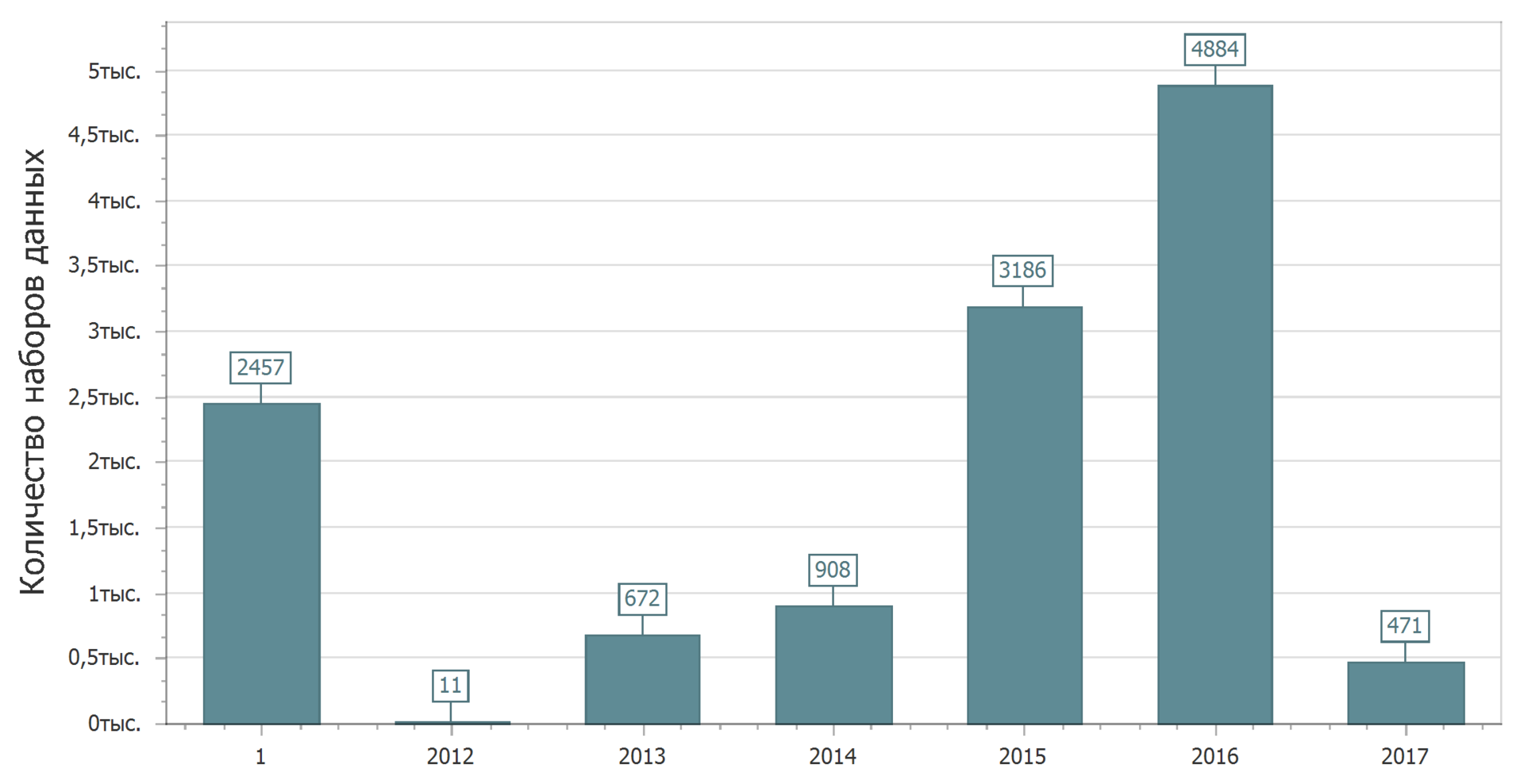
Ja Wieder 1 Jahr. Diese Datensätze wurden nicht geändert. Ich will nur jemanden fangen. Sie versprachen ein Update, nahmen aber keine Änderungen vor. Oder sie versprachen nicht zu aktualisieren und zu aktualisieren. Aber das nächste Mal werden wir nach Mustern suchen (oder nach deren Fehlen).
Kombinieren Sie Informationen zur ersten Veröffentlichung und zum letzten Update. Das heißt, wenn es ein Update gab - nehmen Sie das Update-Datum, wenn es kein Update gab - nehmen Sie das Datum der ersten Veröffentlichung. Das Ergebnis ist das Datum der letzten Datenänderung.

Schönheit Der Trend ist deutlich sichtbar - mehr als die Hälfte der Daten hat sich zuletzt geändert oder wurde in den Jahren 2016-2017 erstellt. Vielleicht können Sie sie für relevant halten.
Es ist notwendig, eine Einschränkung zu beachten. Einige Datensätze werden wiederholt: Der gleiche Datensatzname und Eigentümer werden mehrmals in der Registrierung gefunden.
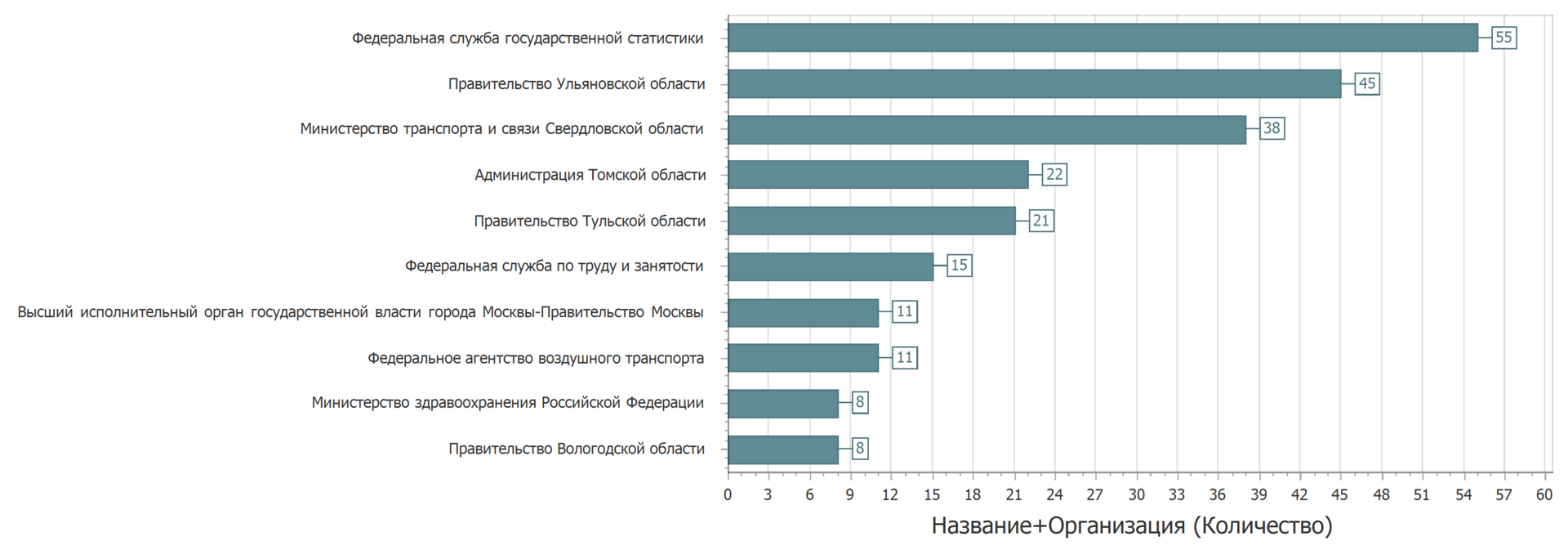
Anstatt zu aktualisieren, wurde der Datensatz erneut angelegt. Manchmal wurden Sets in einer anderen Kategorie angeordnet. Wenn Sie sich jedoch Datensätze mit demselben Namen, Eigentümer und derselben Kategorie ansehen, sieht das Bild wie folgt aus.
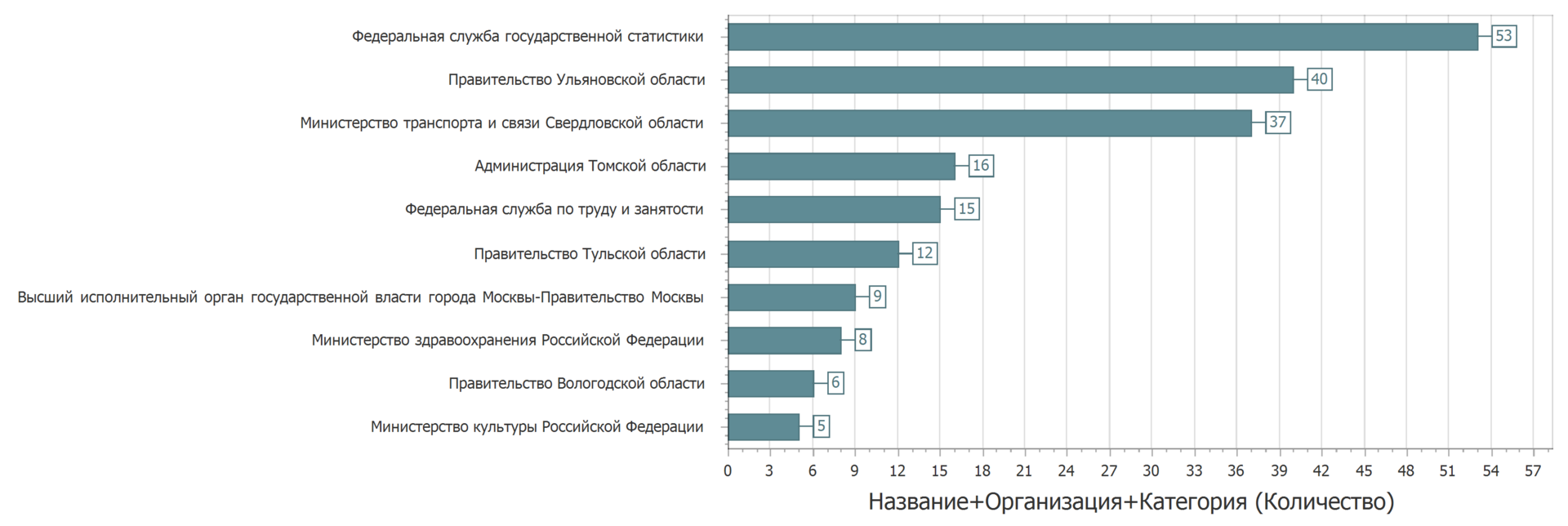
Zumindest sehr ähnlich. Aber kaum kritisch. Einige Dateneigentümer müssen die Daten offenbar sorgfältig verbreiten.
Eine kleine Überprüfung beim Ausfüllen der Textfelder in den Passdatensätzen.
| Das Feld | Set by | Nicht eingestellt |
|---|
| Titel | 100% | 0% |
| Beschreibung | 80,84% | 19,16% |
| Kategorien | 100% | 0% |
| Der Besitzer | 99,7% | 0,03% |
| Stichworte | 99,48% | 0,52% |
| Verantwortliche Person | 96,43% | 3,57% |
| Telefonnummer der verantwortlichen Person | 96% | 4% |
| Verantwortliche Person E-Mail | 92,68% | 7,32% |
| Datenformat | 97,79% | 2,21% |
| Link wählen | 96,86% | 3,14% |
Der Name und die Kategorie sind überall definiert. Fast ein Fünftel der Datensätze enthält keine Beschreibung. Fast überall ist der Besitzer bekannt und einige Schlüsselwörter werden gesetzt. Die verantwortliche Person ist auch fast überall anwesend. Es ist nicht klar, warum wir Datensätze benötigen, die nicht heruntergeladen werden können (ca. 3%).
Infolgedessen teilen wir alle Datensätze in zwei Kategorien ein: Alle Felder sind angegeben, mindestens ein Feld ist nicht angegeben.

Dreißig Prozent (30,3%) haben mindestens ein undefiniertes Feld. In welchem Format werden die Daten hochgeladen?
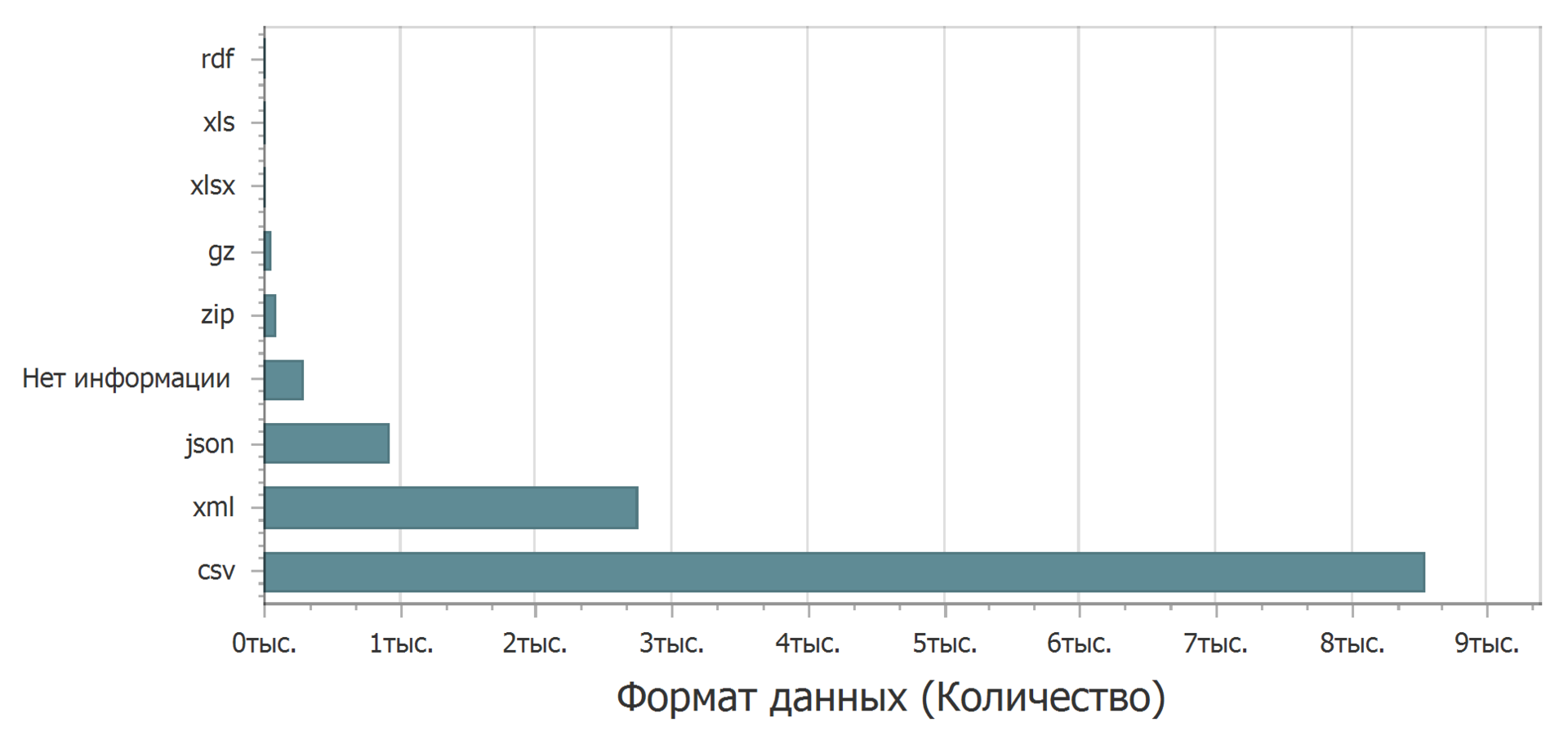
Meistens in einfachem Textformat (CSV). An zweiter Stelle steht xml. Am dritten json. Der klare Anführer ist das CSV-Format - Sie können es in jedem Texteditor öffnen, fast überall zur Verarbeitung importieren und mit ein wenig Aufwand als Tabelle in einen Texteditor einfügen. Das XML-Format ist auch recht einfach zu erkennen. Beim JSON-Format kann es jedoch zu Problemen kommen. Wenn Sie sich auf Excel als den am häufigsten verwendeten Tabellenkalkulationseditor konzentrieren, ist json bereits ein Problem. Sie können zu diesem Thema googeln und einen Weg zum Herunterladen finden, aber nicht direkt. Excel verfügt nicht über integrierte Tools zum Laden von json.
Natürlich ist das Problem furchtlos, nicht tödlich, aber unangenehm. Sicherlich wird dieses Format jemanden stoppen oder verwirren.
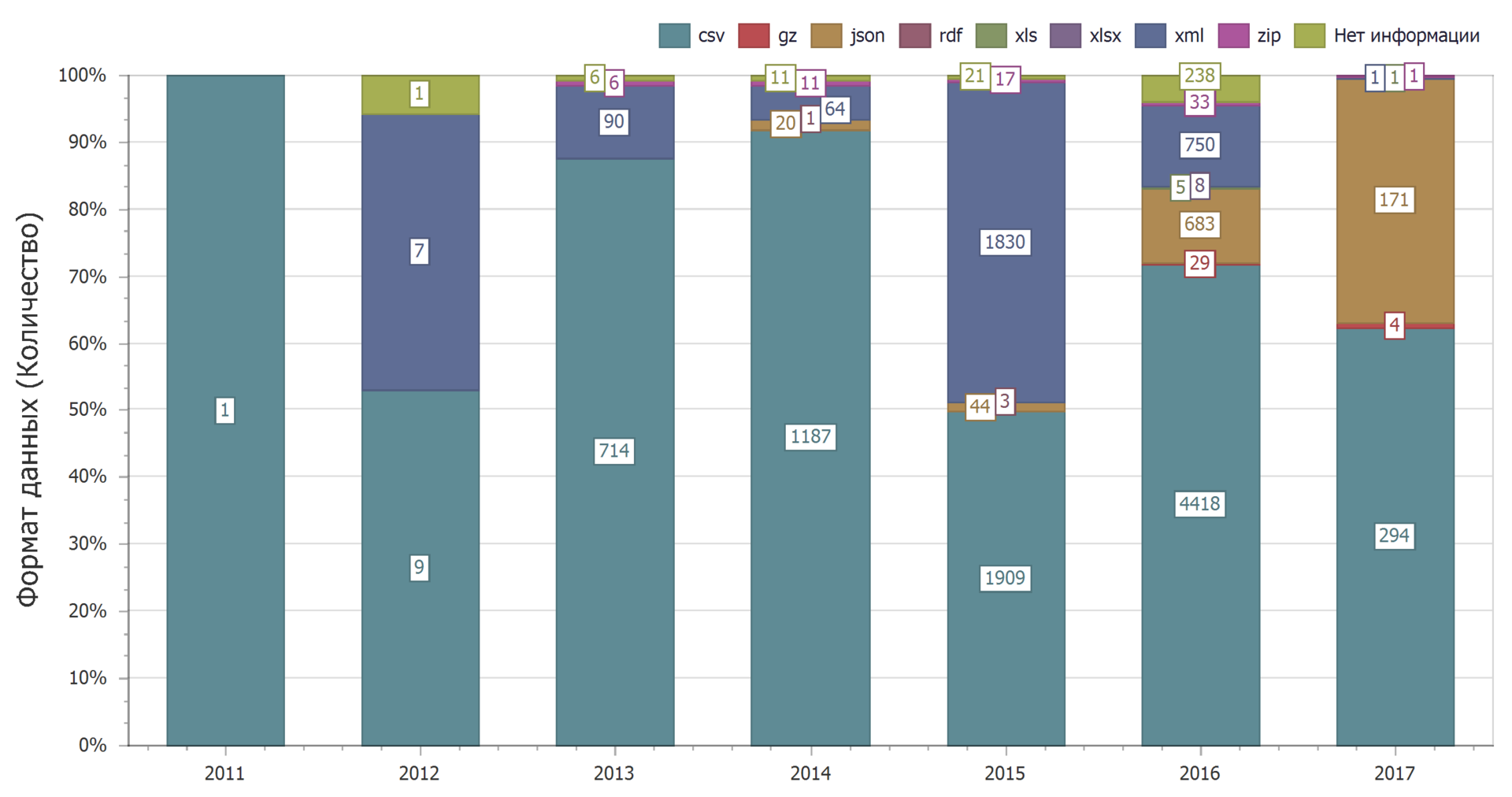
Die Verteilung nach Jahren zeigt, dass die Dominanz des CSV-Formats im Laufe der Zeit anhält.

Die Verwendung des JSON-Formats wird dramatisch zunehmen. Dies reduziert die Verwendung des XML-Formats.
Und das kann erklärt werden. Das CSV-Format ist das einfachste und wird daher häufig verwendet. Gleichzeitig verwenden Webdienste zunehmend das JSON-Format und immer weniger XML.
Schlussfolgerungen
Mehr als die Hälfte der auf dem russischen Open-Data-Portal veröffentlichten Daten gehört zur Kategorie „Staat“.
Mehr als die Hälfte der Daten wurde zuletzt in den Jahren 2016-2017 geändert oder erstellt.
Dreißig Prozent der Datensatzpässe haben mindestens ein nicht zugewiesenes Feld.
Die gängigsten Formate zum Speichern offener Daten: csv, xml, json. Gleichzeitig nimmt die Anzahl der Datensätze im JSON-Format zu und die Anzahl der Datensätze im XML-Format ab.
Was weiter?
Lassen Sie uns nach der Analyse der Datensätze sehen, wie oft sie verwendet werden - angezeigt, heruntergeladen. Welche Bewertungen legen Benutzer für Datensätze fest? Welche Datensätze sind von Interesse? Wie oft werden Datensätze aktualisiert? Welche Größe Datensätze? Und gibt es eine Beziehung zwischen all dem?