
Heute ist das Diagramm eine der akzeptabelsten Möglichkeiten, um die im maschinellen Lernsystem erstellten Modelle zu beschreiben. Diese Berechnungsgraphen bestehen aus Neuronenscheitelpunkten, die durch Synapsenkanten verbunden sind und die Verbindungen zwischen Scheitelpunkten beschreiben.
Im Gegensatz zu einem skalaren Zentral- oder Vektorgrafikprozessor können Sie mit IPU - einem neuen Prozessortyp für maschinelles Lernen - solche Diagramme erstellen. Ein Computer für die Grafikverwaltung ist eine ideale Maschine für rechnergestützte Grafikmodelle, die im Rahmen des maschinellen Lernens erstellt wurden.
Eine der einfachsten Möglichkeiten, die Funktionsweise von Machine Intelligence zu beschreiben, besteht darin, sie zu visualisieren. Das Entwicklungsteam von Graphcore hat eine Sammlung dieser Bilder erstellt, die auf der IPU angezeigt werden. Grundlage war die Pappelsoftware, die die Arbeit der künstlichen Intelligenz visualisiert. Forscher dieses Unternehmens fanden auch heraus, warum tiefe Netzwerke so viel Speicher benötigen und welche Lösungen es gibt.
Poplar enthält einen grafischen Compiler, der von Grund auf neu erstellt wurde, um die im Rahmen des maschinellen Lernens verwendeten Standardoperationen in hochoptimierten Anwendungscode für IPUs zu übersetzen. Sie können diese Diagramme nach demselben Prinzip zusammenstellen, wie POPNNs zusammengestellt werden. Die Bibliothek enthält eine Reihe verschiedener Arten von Scheitelpunkten für verallgemeinerte Grundelemente.
Grafiken sind das Paradigma, auf dem die gesamte Software basiert. In Pappel können Sie mithilfe von Diagrammen den Berechnungsprozess definieren, bei dem Scheitelpunkte Operationen ausführen und Kanten die Beziehung zwischen ihnen beschreiben. Wenn Sie beispielsweise zwei Zahlen addieren möchten, können Sie einen Scheitelpunkt mit zwei Eingaben (die Zahlen, die Sie hinzufügen möchten), einigen Berechnungen (die Funktion zum Hinzufügen von zwei Zahlen) und der Ausgabe (Ergebnis) definieren.
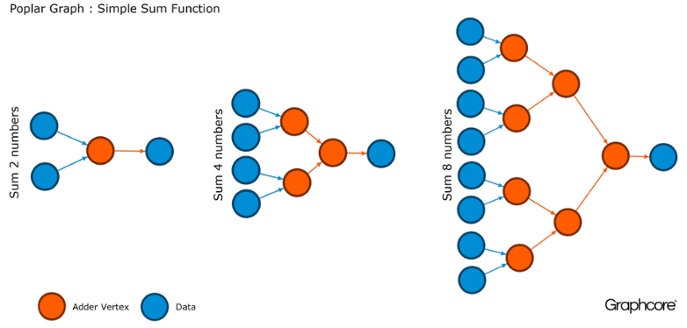
Normalerweise sind Scheitelpunktoperationen viel komplizierter als im oben beschriebenen Beispiel. Oft werden sie durch kleine Programme definiert, die als Codelets (Codenamen) bezeichnet werden. Die grafische Abstraktion ist attraktiv, da sie keine Annahmen über die Struktur von Berechnungen macht und die Berechnung in Komponenten aufteilt, mit denen der IPU-Prozessor arbeiten kann.
Pappel verwendet diese einfache Abstraktion, um sehr große Diagramme zu erstellen, die als Bilder dargestellt werden. Durch die programmatische Generierung des Diagramms können wir es an die spezifischen Berechnungen anpassen, die für eine möglichst effiziente Nutzung der IPU-Ressourcen erforderlich sind.
Der Compiler übersetzt Standardoperationen, die in maschinellen Lernsystemen verwendet werden, in hochoptimierten Anwendungscode für IPUs. Ein Diagramm-Compiler erstellt ein Zwischenbild eines Berechnungsdiagramms, das auf einem oder mehreren IPU-Geräten bereitgestellt wird. Der Compiler kann diesen Berechnungsgraphen anzeigen, sodass eine auf der Ebene der neuronalen Netzwerkstruktur geschriebene Anwendung ein Bild des Berechnungsgraphen anzeigt, der auf der IPU ausgeführt wird.
 AlexNet-Lernzyklus für den gesamten Zyklus vorwärts und rückwärts
AlexNet-Lernzyklus für den gesamten Zyklus vorwärts und rückwärtsDer Grafik-Compiler Poplar verwandelte
die Beschreibung von
AlexNet in einen Rechengraphen mit 18,7 Millionen Eckpunkten und 115,8 Millionen Kanten. Deutlich sichtbares Clustering ist das Ergebnis einer starken Verbindung zwischen den Prozessen in jeder Schicht des Netzwerks mit einer einfacheren Verbindung zwischen den Ebenen.
Ein weiteres Beispiel ist ein einfaches Netzwerk mit vollständiger Konnektivität, das bei
MNIST geschult wurde - ein einfacher Datensatz für Computer Vision, eine Art „Hallo Welt“ im maschinellen Lernen. Ein einfaches Netzwerk zum Durchsuchen dieses Datensatzes hilft dabei, die Diagramme zu verstehen, die von Pappelanwendungen gesteuert werden. Durch die Integration von Diagrammbibliotheken in Umgebungen wie TensorFlow bietet das Unternehmen eine der einfachsten Möglichkeiten, IPUs in Anwendungen für maschinelles Lernen zu verwenden.
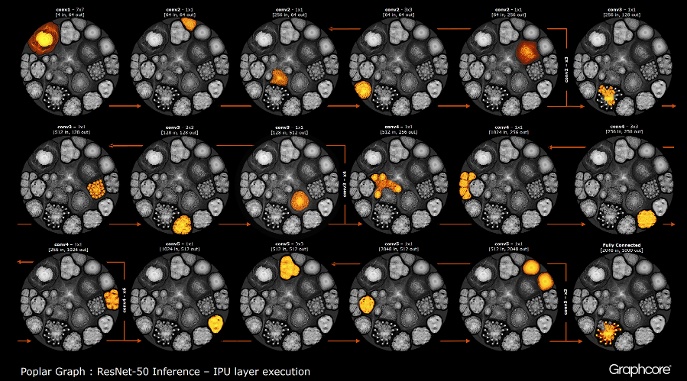
Nachdem das Diagramm mit dem Compiler erstellt wurde, muss es ausgeführt werden. Dies ist mit der Graph Engine möglich. Am Beispiel von ResNet-50 wird dessen Funktionsweise demonstriert.
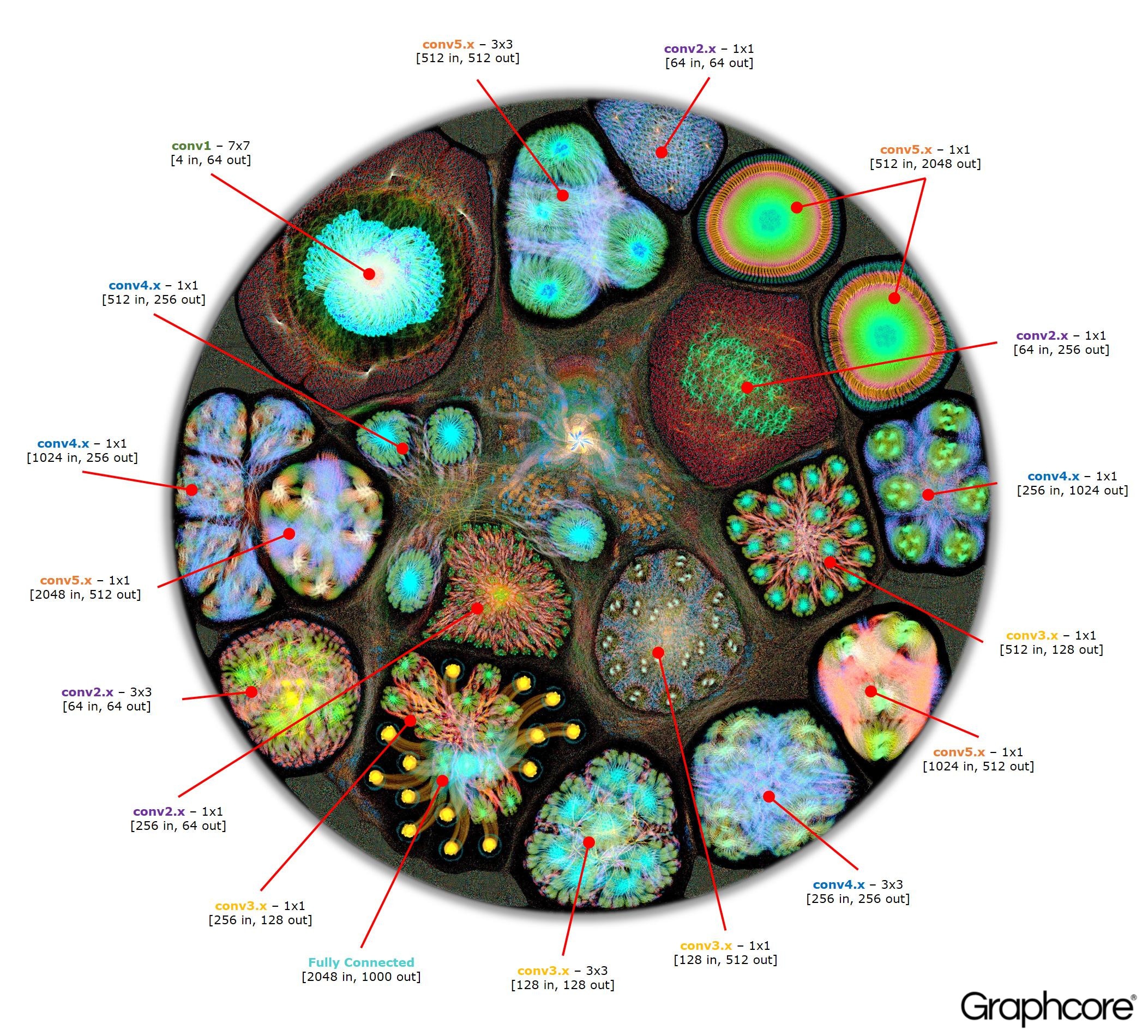
 Zählen Sie ResNet-50
Zählen Sie ResNet-50Mit der ResNet-50-Architektur können Sie aus sich wiederholenden Partitionen tiefe Netzwerke erstellen. Der Prozessor muss diese Partitionen nur einmal ermitteln und erneut aufrufen. Beispielsweise wird ein Cluster auf Conv4-Ebene sechsmal ausgeführt, jedoch nur einmal auf das Diagramm angewendet. Das Bild zeigt auch die Vielfalt der Formen von Faltungsschichten, da jede von ihnen einen Graphen aufweist, der gemäß der natürlichen Berechnungsform erstellt wurde.
Die Engine erstellt und steuert die Ausführung eines maschinellen Lernmodells mithilfe eines vom Compiler erstellten Diagramms. Nach der Bereitstellung überwacht Graph Engine IPUs oder Geräte, die von Anwendungen verwendet werden, und reagiert darauf.
Image ResNet-50 zeigt das gesamte Modell. Auf dieser Ebene ist es schwierig, zwischen einzelnen Scheitelpunkten zu unterscheiden. Es lohnt sich daher, vergrößerte Bilder zu betrachten. Das Folgende sind einige Beispiele für Abschnitte innerhalb von Schichten eines neuronalen Netzwerks.


Warum brauchen tiefe Netzwerke so viel Speicher?
Große Mengen an belegtem Speicher sind eines der größten Probleme tiefer neuronaler Netze. Forscher versuchen, mit der begrenzten Bandbreite von DRAM-Geräten umzugehen, die von modernen Systemen verwendet werden sollten, um eine große Anzahl von Gewichten und Aktivierungen in einem tiefen neuronalen Netzwerk zu speichern.
Die Architekturen wurden unter Verwendung von Prozessorchips entwickelt, die für die sequentielle Verarbeitung und Optimierung des DRAM für Speicher mit hoher Dichte ausgelegt sind. Die Schnittstelle zwischen den beiden Geräten ist ein Engpass, der Bandbreitenbeschränkungen einführt und den Energieverbrauch erheblich erhöht.
Obwohl wir immer noch kein vollständiges Bild des menschlichen Gehirns und seiner Funktionsweise haben, ist im Allgemeinen klar, dass es keinen großen separaten Speicher für das Gedächtnis gibt. Es wird angenommen, dass die Funktion des Langzeit- und Kurzzeitgedächtnisses im menschlichen Gehirn in die Struktur von Neuronen + Synapsen eingebettet ist. Selbst einfache Organismen wie
Würmer mit einer neuronalen Struktur des Gehirns, die aus etwas mehr als 300 Neuronen bestehen,
haben einen gewissen Grad an Gedächtnisfunktion.
Der Aufbau von Speicher in herkömmlichen Prozessoren ist eine Möglichkeit, Speicherengpässe zu umgehen, indem eine große Bandbreite mit viel weniger Stromverbrauch erschlossen wird. Trotzdem ist Speicher auf einem Chip eine teure Sache, die nicht für wirklich große Speichermengen ausgelegt ist, die mit den zentralen und grafischen Prozessoren verbunden sind, die derzeit für die Vorbereitung und Bereitstellung tiefer neuronaler Netze verwendet werden.
Daher ist es hilfreich zu untersuchen, wie Speicher heute in Zentraleinheiten und Deep-Learning-Systemen auf Grafikbeschleunigern verwendet wird, und sich zu fragen: Warum benötigen sie so große Speichergeräte, wenn das menschliche Gehirn ohne sie gut funktioniert?
Neuronale Netze benötigen Speicher, um Eingabedaten, Gewichtungsparameter und Aktivierungsfunktionen zu speichern, da die Eingabe über das Netzwerk verteilt wird. Im Training muss die Aktivierung am Eingang beibehalten werden, bis die Fehler der Gradienten am Ausgang berechnet werden können.
Beispielsweise verfügt ein 50-lagiges ResNet-Netzwerk über etwa 26 Millionen Gewichtungsparameter und berechnet 16 Millionen Vorwärtsaktivierungen. Wenn Sie eine 32-Bit-Gleitkommazahl verwenden, um jedes Gewicht und jede Aktivierung zu speichern, sind ca. 168 MB Speicherplatz erforderlich. Mit einem niedrigeren Genauigkeitswert zum Speichern dieser Skalen und Aktivierungen könnten wir diesen Speicherbedarf halbieren oder sogar vervierfachen.
Ein ernstes Speicherproblem ergibt sich aus der Tatsache, dass GPUs auf Daten beruhen, die als dichte Vektoren dargestellt werden. Daher können sie einen einzelnen Befehlsstrom (SIMD) verwenden, um eine Berechnung mit hoher Dichte zu erreichen. Der Zentralprozessor verwendet ähnliche Vektorblöcke für Hochleistungsrechnen.
In GPUs ist die Synapse 1024 Bit breit, daher verwenden sie 32-Bit-Gleitkommadaten, sodass sie diese häufig in parallele Mini-Batches von 32 Abtastwerten aufteilen, um 1024-Bit-Datenvektoren zu erstellen. Dieser Ansatz zur Organisation der Vektorparallelität erhöht die Anzahl der Aktivierungen um das 32-fache und den Bedarf an lokalem Speicher mit einer Kapazität von mehr als 2 GB.
GPUs und andere Maschinen, die für die Matrixalgebra entwickelt wurden, unterliegen ebenfalls einer Speicherbelastung durch die Gewichte oder die Aktivierung des neuronalen Netzwerks. GPUs können kleine Faltungen, die in tiefen neuronalen Netzen verwendet werden, nicht effizient ausführen. Daher wird eine Transformation namens "Downgrade" verwendet, um diese Faltungen in Matrix-Matrix-Multiplikationen (GEMMs) umzuwandeln, die Grafikbeschleuniger effektiv verarbeiten können.
Zusätzlicher Speicher ist auch erforderlich, um Eingabedaten, Zeitwerte und Programmanweisungen zu speichern. Die Messung der Speichernutzung beim Training von ResNet-50 auf einer Hochleistungs-GPU hat gezeigt, dass mehr als 7,5 GB lokaler DRAM erforderlich sind.
Vielleicht entscheidet jemand, dass eine geringere Genauigkeit den Speicherbedarf verringern kann, aber das ist nicht der Fall. Wenn Sie Datenwerte für Gewichte und Aktivierungen auf die halbe Genauigkeit umschalten, füllen Sie nur die Hälfte der Vektorbreite der SIMD aus und verbrauchen die Hälfte der verfügbaren Rechenressourcen. Um dies zu kompensieren, müssen Sie beim Umschalten von voller Genauigkeit auf halbe Genauigkeit auf der GPU die Größe des Mini-Batches verdoppeln, um eine ausreichende Datenparallelität zu erreichen, damit alle verfügbaren Berechnungen verwendet werden können. Der Übergang zu Skalen und Aktivierungen mit geringerer Genauigkeit auf der GPU erfordert daher immer noch mehr als 7,5 GB dynamischen Speicher mit freiem Zugriff.
Bei so vielen zu speichernden Daten ist es einfach unmöglich, all dies in die GPU zu integrieren. Auf jeder Schicht des Faltungs-Neuronalen Netzwerks muss der Status des externen DRAM gespeichert, die nächste Netzwerkschicht geladen und dann die Daten in das System geladen werden. Infolgedessen leidet die externe Speicherschnittstelle, die bereits durch die Speicherbandbreite begrenzt ist, unter der zusätzlichen Belastung, das Guthaben ständig neu zu laden sowie Aktivierungsfunktionen zu speichern und abzurufen. Dies verlangsamt die Trainingszeit erheblich und erhöht den Energieverbrauch erheblich.
Es gibt verschiedene Lösungen für dieses Problem. Erstens können Vorgänge wie Aktivierungsfunktionen „vor Ort“ ausgeführt werden, sodass Sie die Eingabe direkt in die Ausgabe überschreiben können. Somit kann vorhandener Speicher wiederverwendet werden. Zweitens kann die Möglichkeit zur Wiederverwendung von Speicher erhalten werden, indem die Abhängigkeit von Daten zwischen Operationen im Netzwerk und die Verteilung desselben Speichers für Operationen analysiert wird, die ihn derzeit nicht verwenden.
Der zweite Ansatz ist besonders effektiv, wenn das gesamte neuronale Netzwerk in der Kompilierungsphase analysiert werden kann, um einen fest zugewiesenen Speicher zu erstellen, da die Kosten für die Speicherverwaltung auf nahezu Null reduziert werden. Es stellte sich heraus, dass eine Kombination dieser Methoden die Speichernutzung des neuronalen Netzwerks um das Zwei- bis Dreifache reduziert.
Ein dritter wichtiger Ansatz wurde kürzlich vom Baidu Deep Speech-Team entdeckt. Sie verwendeten verschiedene Methoden zum Speichern von Speicher, um den Speicherverbrauch durch Aktivierungsfunktionen um das 16-fache zu reduzieren, wodurch sie Netzwerke mit 100 Schichten trainieren konnten. Zuvor konnten sie mit der gleichen Speichermenge Netzwerke mit neun Schichten trainieren.
Die Kombination von Speicher- und Verarbeitungsressourcen in einem Gerät bietet ein erhebliches Potenzial zur Steigerung der Produktivität und Effizienz von Faltungs-Neuronalen Netzen sowie anderer Formen des maschinellen Lernens. Sie können einen Kompromiss zwischen Speicher und Computerressourcen eingehen, um die Funktionen und die Leistung des Systems in Einklang zu bringen.
Neuronale Netze und Wissensmodelle in anderen Methoden des maschinellen Lernens können als mathematische Graphen betrachtet werden. In diesen Diagrammen ist eine große Menge an Parallelität konzentriert. Ein Parallelprozessor, der für die Verwendung von Parallelität in Diagrammen ausgelegt ist, ist nicht auf Mini-Batch angewiesen und kann den erforderlichen lokalen Speicher erheblich reduzieren.
Moderne Forschungsergebnisse haben gezeigt, dass all diese Methoden die Leistung neuronaler Netze erheblich verbessern können. Moderne Grafik- und Zentraleinheiten haben einen sehr begrenzten internen Speicher, insgesamt nur wenige Megabyte. Neue Prozessorarchitekturen, die speziell für maschinelles Lernen entwickelt wurden, bieten ein Gleichgewicht zwischen Speicher und On-Chip-Computing und steigern die Leistung und Effizienz im Vergleich zu modernen Zentraleinheiten und Grafikbeschleunigern erheblich.