
Vor vier Jahren erkannte Google das wahre Potenzial der Verwendung neuronaler Netze in seinen Anwendungen. Dann begann sie, sie überall einzuführen - bei der Textübersetzung, der Sprachsuche mit Spracherkennung usw. Es wurde jedoch sofort klar, dass die Verwendung neuronaler Netze die Belastung der Google-Server erheblich erhöht. Grob gesagt, wenn jeder nur drei Minuten am Tag eine Sprachsuche auf Android (oder diktiertem Text mit Spracherkennung) durchführen würde, müsste Google die Anzahl der Rechenzentren (!) Verdoppeln, damit die neuronalen Netze eine solche Menge an Sprachverkehr verarbeiten.
Es musste etwas getan werden - und Google fand eine Lösung. 2015 entwickelte sie eine eigene Hardwarearchitektur für maschinelles Lernen (Tensor Processing Unit, TPU), die hinsichtlich der Leistung bis zu 70-mal schneller als herkömmliche GPUs und CPUs und hinsichtlich der Anzahl der Berechnungen pro Watt bis zu 196-mal schneller ist. Herkömmliche GPUs / CPUs beziehen sich auf Allzweckprozessoren Xeon E5 v3 (Haswell) und Nvidia Tesla K80-GPUs.
Die TPU-Architektur wurde diese Woche erstmals in einem
wissenschaftlichen Artikel
(pdf) beschrieben , der auf dem 44. Internationalen Symposium für Computerarchitekturen (ISCA) am 26. Juni 2017 in Toronto vorgestellt wird. Ein führender Autor von mehr als 70 Autoren dieser wissenschaftlichen Arbeit,
ein herausragender Ingenieur Norman Jouppi, der als einer der Schöpfer des MIPS-Prozessors bekannt ist
, erklärte in
einem Interview mit
The Next Platform in seinen eigenen Worten die Merkmale der einzigartigen TPU-Architektur, die eigentlich ein spezialisierter ASIC ist, d. H. spezielle integrierte Schaltung.
Im Gegensatz zu herkömmlichen FPGAs oder hochspezialisierten ASICs werden TPU-Module wie eine GPU oder CPU programmiert, es handelt sich nicht um ein Gerät mit enger Reichweite für ein einzelnes neuronales Netzwerk. Laut Norman Yuppy unterstützt TPU CISC-Anweisungen für verschiedene Arten von neuronalen Netzen: Faltungs-Neuronale Netze, LSTM-Modelle und große, vollständig verbundene Modelle. Damit es weiterhin programmierbar bleibt, wird die Matrix nur als Grundelement und nicht als Vektor- oder Skalargrundelement verwendet.
Google betont, dass andere Entwickler zwar ihre Mikrochips für Faltungs-Neuronale Netze optimieren, diese Neuronalen Netze jedoch nur 5% der Last in Google-Rechenzentren ausmachen. Die meisten Google-Anwendungen verwenden die
mehrschichtigen Rumelhart-Perzeptrone. Daher war es so wichtig, eine universellere Architektur zu erstellen, die nicht nur für Faltungs-Neuronale Netze „geschärft“ wurde.
 Eines der Elemente der Architektur ist die systolische Datenstrom-Engine, ein Array von 256 × 256, das Aktivierung (Gewichte) von den Neuronen auf der linken Seite erhält, und dann verschiebt sich alles Schritt für Schritt, multipliziert mit den Gewichten in der Zelle. Es stellt sich heraus, dass die systolische Matrix pro Zyklus 65.536 Berechnungen durchführt. Diese Architektur ist ideal für neuronale Netze.
Eines der Elemente der Architektur ist die systolische Datenstrom-Engine, ein Array von 256 × 256, das Aktivierung (Gewichte) von den Neuronen auf der linken Seite erhält, und dann verschiebt sich alles Schritt für Schritt, multipliziert mit den Gewichten in der Zelle. Es stellt sich heraus, dass die systolische Matrix pro Zyklus 65.536 Berechnungen durchführt. Diese Architektur ist ideal für neuronale Netze.Laut Uppy ähnelt die Architektur von TPUs eher dem FPU-Coprozessor als einer regulären GPU, obwohl zahlreiche Multiplikationsmatrizen keine Programme in sich speichern, sondern lediglich vom Host empfangene Anweisungen ausführen.
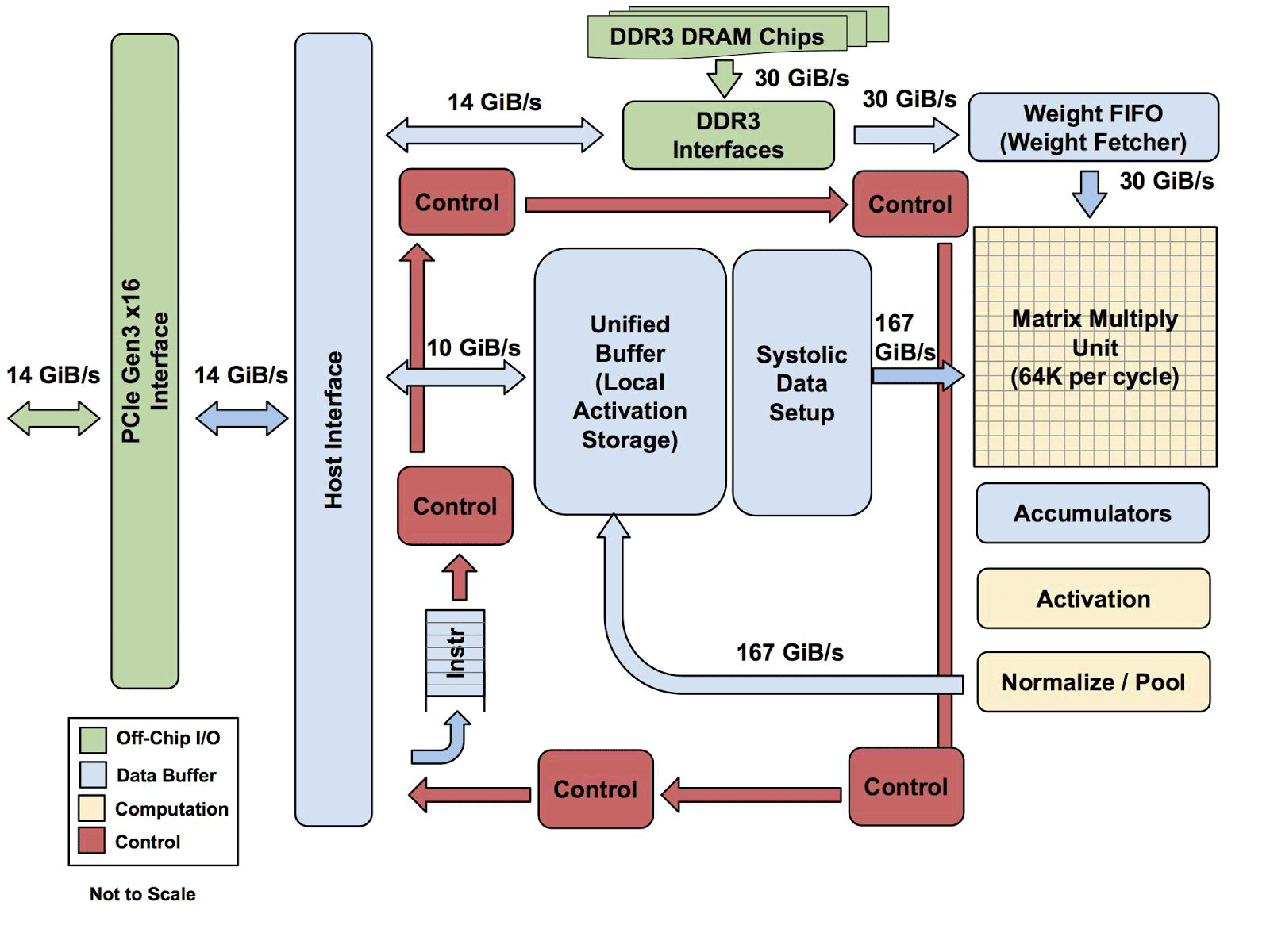 Alle TPU-Architekturen mit Ausnahme des DDR3-Speichers. Anweisungen werden vom Host (links) an die Warteschlange gesendet. Dann kann die Steuerlogik abhängig von der Anweisung jede von ihnen wiederholt ausführen
Alle TPU-Architekturen mit Ausnahme des DDR3-Speichers. Anweisungen werden vom Host (links) an die Warteschlange gesendet. Dann kann die Steuerlogik abhängig von der Anweisung jede von ihnen wiederholt ausführenEs ist noch nicht bekannt, wie skalierbar diese Architektur ist. Yuppy sagt, dass es in einem System mit dieser Art von Host immer einen Engpass geben wird.
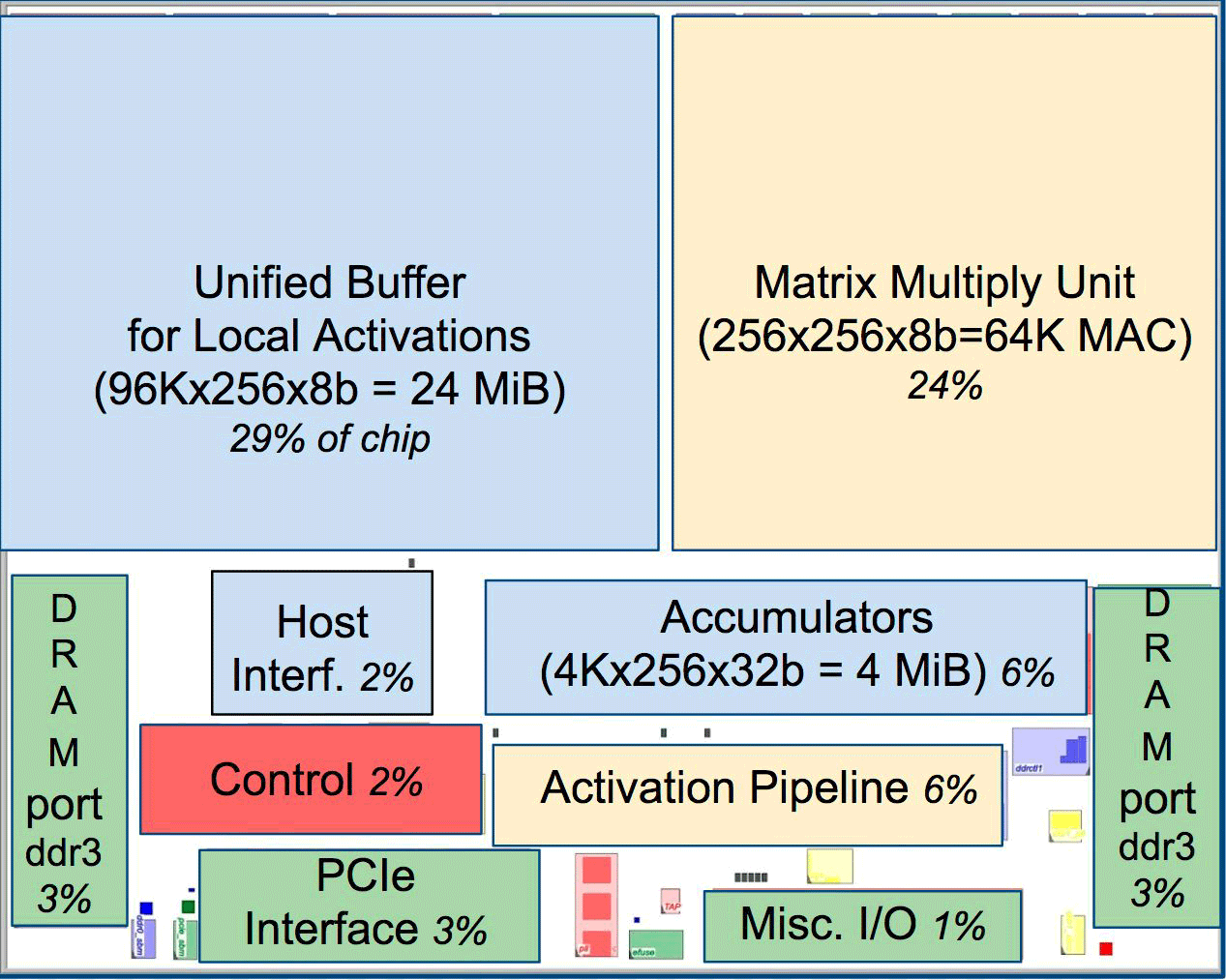
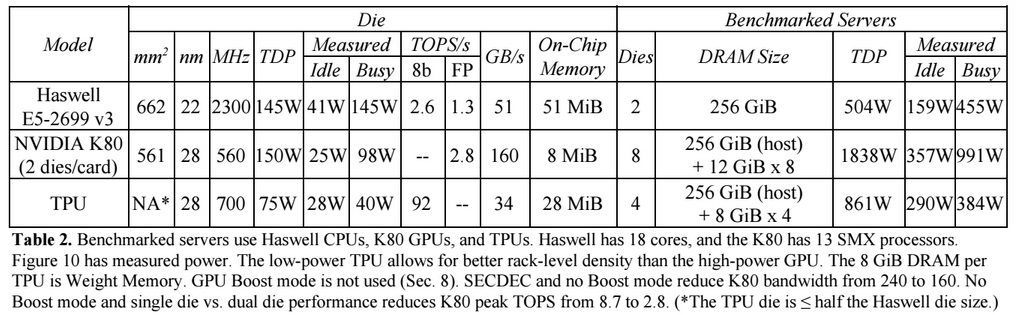
Im Vergleich zu herkömmlichen CPUs und GPUs übertrifft die Maschinenarchitektur von Google diese um das Zehnfache. Beispielsweise führt ein Haswell Xeon E5-2699 v3-Prozessor mit 18 Kernen bei einer Taktfrequenz von 2,3 GHz und einem 64-Bit-Gleitkomma 1,3 Tera-Operationen pro Sekunde (TOPS) aus und zeigt eine Datenübertragungsrate von 51 GB / s. In diesem Fall verbraucht der Chip selbst 145 Watt und das gesamte System mit 256 GB Speicher - 455 Watt.
Zum Vergleich zeigt TPU bei 8-Bit-Operationen mit 256 GB externem Speicher und 32 GB eigenem Speicher eine Übertragungsgeschwindigkeit von 34 GB / s Speicher, aber die Karte führt 92 TOPS aus, d. H. Ungefähr 71-mal mehr als der Haswell-Prozessor. Der Stromverbrauch des Servers auf der TPU beträgt 384 Watt.
Das folgende Diagramm vergleicht die relative Leistung pro Watt eines Servers mit einer GPU (blaue Spalte), einem Server auf TPU (rot), relativ zu einem Server auf der CPU. Außerdem wird die relative Leistung pro Watt des Servers mit der TPU im Verhältnis zum Server auf der GPU (orange) und der verbesserten Version der TPU im Verhältnis zum Server auf der CPU (grün) und dem Server auf der GPU (lila) verglichen.

Es ist zu beachten, dass Google bei Tests von Anwendungen auf TensorFlow Vergleiche mit der relativ alten Version von Haswell Xeon anstellte, während in der neueren Version von Broadwell Xeon E5 v4 die Anzahl der Anweisungen pro Zyklus aufgrund von Architekturverbesserungen um 5% und in der Version von Skylake Xeon E5 v5 zunahm , was im Sommer erwartet wird, kann sich die Anzahl der Anweisungen pro Zyklus um weitere 9-10% erhöhen. Und mit der Erhöhung der Anzahl der Kerne von 18 auf 28 in Skylake kann sich die Gesamtleistung von Intel-Prozessoren in Google-Tests um 80% verbessern. Trotzdem wird es bei TPU einen großen Leistungsunterschied geben. In der Testversion mit 32-Bit-Gleitkomma wird der Unterschied zwischen TPUs und CPUs auf ungefähr das 3,5-fache reduziert. Die meisten Modelle quantisieren jedoch perfekt auf 8 Bit.
Google dachte über die Verwendung von GPU, FPGA und ASIC in seinen Rechenzentren seit 2006 nach, fand sie jedoch erst beim letzten Mal, als es maschinelles Lernen für eine Reihe praktischer Aufgaben einführte und die Belastung dieser neuronalen Netze mit Milliarden von Anfragen von Benutzern zunahm. Jetzt hat das Unternehmen keine andere Wahl, als sich von herkömmlichen CPUs zu entfernen.
Das Unternehmen plant nicht, seine Prozessoren an Dritte zu verkaufen, hofft jedoch, dass die wissenschaftliche Arbeit mit dem ASIC 2015 es anderen ermöglichen wird, die Architektur zu verbessern und verbesserte Versionen des ASIC zu erstellen, die "die Messlatte noch höher legen". Google selbst arbeitet wahrscheinlich bereits an einer neuen Version von ASIC.