Denken Sie nur daran, wie hoch ist die Gesamtleistung aller Smartphones auf der Welt? Dies ist eine riesige Computerressource, die sogar die Arbeit des menschlichen Gehirns emulieren kann. Eine solche Ressource kann nicht untätig sein und Kilowatt Energie in Chatrooms und Social-Media-Feeds verbrauchen. Wenn Sie diese Computerressourcen einer einzelnen verteilten Welt-KI zur Verfügung stellen und sie sogar mit Daten von Benutzer-Smartphones versorgen - für Schulungen -, kann ein solches System in diesem Bereich einen Quantensprung machen.
Standardmethoden für maschinelles Lernen erfordern, dass der Datensatz zum Trainieren des Modells („primär“) an einem Ort gesammelt wird - auf einem Computer, Server oder in einem Rechenzentrum oder einer Cloud. Von hier aus wird er von einem Modell übernommen, das auf diesen Daten trainiert ist. Bei einem Computercluster im Rechenzentrum wird
die SGD-
Methode (Stochastic Gradient Descent) verwendet - ein Optimierungsalgorithmus, der ständig in Teilen eines Datensatzes ausgeführt wird, der homogen auf Server in der Cloud verteilt ist.
Google, Apple, Facebook, Microsoft und andere KI-Spieler tun genau das schon lange: Sie sammeln - manchmal vertrauliche - Daten von den Computern und Smartphones der Benutzer in einem einzigen (vermutlich) sicheren Speicher, auf dem ihre neuronalen Netze trainiert werden.
Jetzt haben Wissenschaftler von Google Research eine interessante Ergänzung zu dieser Standardmethode für maschinelles Lernen vorgeschlagen. Sie schlugen einen innovativen Ansatz namens Federated Learning vor. Es ermöglicht allen Geräten, die am maschinellen Lernen teilnehmen, ein einziges Modell für die Vorhersage freizugeben, jedoch
keine Primärdaten für das Modelltraining !
Dieser ungewöhnliche Ansatz verringert möglicherweise die Effektivität des maschinellen Lernens (obwohl dies keine Tatsache ist), senkt jedoch die Kosten von Google für die Wartung von Rechenzentren erheblich. Warum sollte ein Unternehmen viel Geld in seine Geräte investieren, wenn es weltweit Milliarden von Android-Geräten hat, die die Last teilen können? Benutzer können mit einer solchen Belastung zufrieden sein, da sie dadurch dazu beitragen, bessere Dienste zu erstellen, die sie selbst nutzen. Und sie schützen ihre vertraulichen Daten, ohne sie an das Rechenzentrum zu senden.
Google betont, dass es in diesem Fall nicht nur darum geht, dass das bereits trainierte Modell direkt auf dem Gerät des Benutzers ausgeführt wird, wie dies bei den Diensten
Mobile Vision API und
On-Device Smart Reply der Fall ist. Nein, es ist ein Modelltraining, das an den Endgeräten durchgeführt wird.
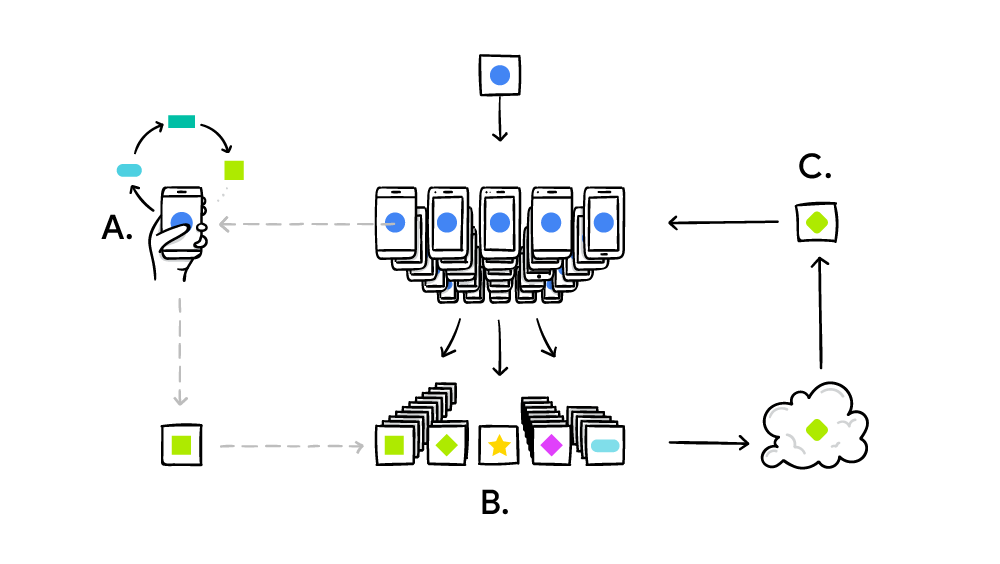
Das Verbundlernsystem arbeitet nach dem Standardprinzip des verteilten Rechnens wie SETI @ Home, wenn Millionen von Computern ein großes komplexes Problem lösen. Im Fall von SETI @ Home wurde nach Anomalien im Funksignal aus dem Weltraum über die gesamte Breite des Spektrums gesucht. Und im Fall des föderierten maschinellen Lernens perfektioniert Google ein einziges gemeinsames Modell (bisher) schwacher KI. In der Praxis wird der Trainingszyklus wie folgt durchgeführt:
- Smartphone lädt das aktuelle Modell herunter;
- Mit Hilfe der Mini-Version führt TensorFlow einen Schulungszyklus mit den eindeutigen Daten eines bestimmten Benutzers durch.
- verbessert das Modell;
- berechnet den Unterschied zwischen den verbesserten Quellmodellen und erstellt einen Patch unter Verwendung des kryptografischen Protokolls Secure Aggregation , das die Entschlüsselung von Daten nur dann ermöglicht, wenn Hunderte oder Tausende von Patches von anderen Benutzern vorhanden sind.
- sendet den Patch an den zentralen Server;
- Das angenommene Patch wird sofort mit Tausenden von Patches gemittelt, die von anderen Teilnehmern des Experiments unter Verwendung des Verbundmittelungsalgorithmus empfangen wurden.
- Eine neue Version des Modells wird eingeführt.
- Ein verbessertes Modell wird an die Teilnehmer des Experiments gesendet.
Die föderierte Mittelwertbildung ist der oben genannten stochastischen Gradientenmethode sehr ähnlich, nur dass hier die ersten Berechnungen nicht auf Servern in der Cloud, sondern auf Millionen von Remote-Smartphones stattfinden. Die Hauptleistung der Verbundmittelung ist 10-100-mal weniger Verkehr mit Clients als Verkehr mit Servern unter Verwendung der stochastischen Gradientenmethode. Die Optimierung wurde durch eine
qualitativ hochwertige Komprimierung von Updates erreicht , die von Smartphones an den Server gesendet werden. Das Plus hier ist das kryptografische Protokoll für die sichere Aggregation.
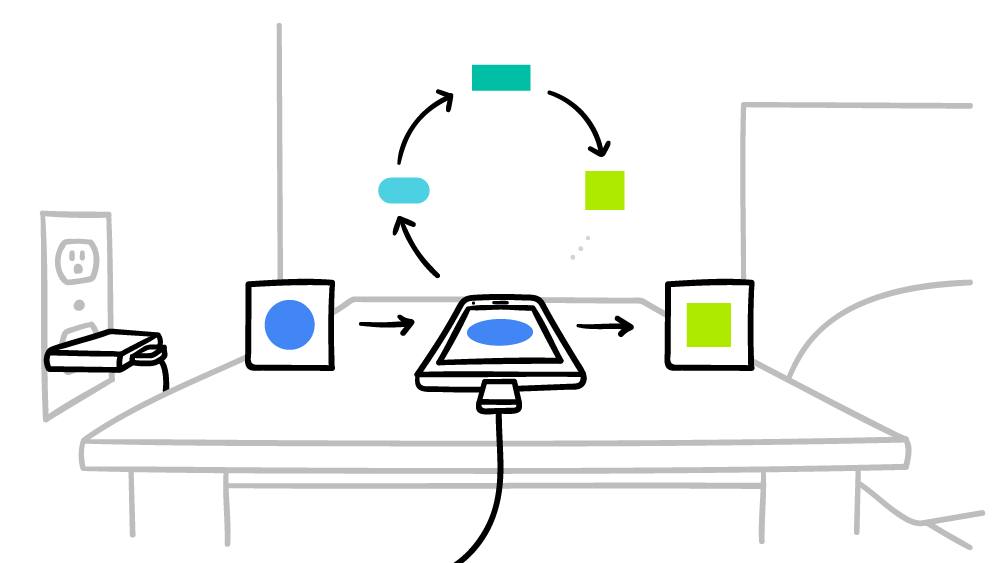
Google verspricht, dass das Smartphone nur in Ausfallzeiten Berechnungen für ein verteiltes globales KI-System durchführen wird, damit die Leistung in keiner Weise beeinträchtigt wird. Darüber hinaus können Sie die Betriebszeit nur für die Zeit einstellen, zu der das Smartphone an das Stromnetz angeschlossen ist. Somit beeinflussen diese Berechnungen nicht einmal die Batterielebensdauer. Das föderierte maschinelle Lernen wird derzeit anhand von Kontextansagen auf der Google-Tastatur getestet -
Gboard unter Android .
Der Federated Averaging-Algorithmus wird ausführlicher in der wissenschaftlichen Veröffentlichung
Kommunikationseffizientes Lernen tiefer Netzwerke aus dezentralen Daten beschrieben , die am 17. Februar 2016 auf arXiv.org (arXiv: 1602.05629) veröffentlicht wurde.