 Wie übersetze ich ein Dokument in Word und dampfe es nicht mit Formatierung ? Wie kann man nicht dasselbe übersetzen? Wie kann die Einheitlichkeit aufrechterhalten werden? Wie kaufe ich keine teure Software? Wie kann man effizient und schnell arbeiten?
Wie übersetze ich ein Dokument in Word und dampfe es nicht mit Formatierung ? Wie kann man nicht dasselbe übersetzen? Wie kann die Einheitlichkeit aufrechterhalten werden? Wie kaufe ich keine teure Software? Wie kann man effizient und schnell arbeiten?Wenn Sie mit Trados, MemoQ oder CrowdIn vertraut sind, lesen Sie direkt die Installationsanweisungen. Wenn dies neue Wörter für Sie sind, heißen wir Sie in der wundervollen Welt der
computergestützten Übersetzung willkommen
.Über Computerübersetzung
Google Translate - maschinelle Übersetzung, der Computer übersetzt für Sie. CAT ist ein Arbeitsprinzip, wenn ein Computer nur bei der Arbeit hilft und Routineprozesse automatisiert.
CAT-Programme unterteilen den Quellcode in
Segmente - Zeilen, Sätze, Absätze oder Absätze. Eine Person übersetzt ein Segment nacheinander, und die Übersetzung wird in einer speziellen Datenbank gespeichert - dem Translation Memory (
TM ). Wenn der Übersetzer auf ein
ähnliches Segment stößt, zeigt das Programm einen Hinweis oder eine mögliche Übersetzung an. Und das Programm
kann identische Segmente
selbst übersetzen .
CAT ist besonders gut darin,
Anweisungen ,
juristische Dokumente und
Programmschnittstellen zu übersetzen - wo
ähnliche Formulierungen sehr häufig sind . In der literarischen Übersetzung wird die Hilfe nicht so offensichtlich sein, aber dazu später mehr.
Je mehr Texte zu ähnlichen Themen Sie übersetzen, desto mehr Übersetzungen werden
in der Datenbank gesammelt und desto häufiger werden Tipps angezeigt. Im Laufe der Jahre kann sich eine solche Basis ansammeln, dass in dem neuen Dokument die Hälfte der Übersetzung "von selbst" fertig sein wird.
Wenn die Übersetzung abgeschlossen ist, erstellt das Programm ein Dokument, das
mit dem Original identisch ist. Dabei bleiben Struktur und Formatierung erhalten, der Quelltext wird jedoch durch Ihre Übersetzung ersetzt.
CAT-Programme ändern das Originaldokument nicht, sodass das Dokument nicht dauerhaft beschädigt werden kann. Die Ausgabe ist eine vollständig übersetzte Datei.
Was sind CAT-Programme?
Anders.
Trados ,
MemoQ - teure Unternehmenssysteme, die auf einem Computer installiert sind.
CrowdIn ,
Tolmach und andere - arbeiten direkt im Browser. In der Regel kostet alles Geld oder das Projektvolumen ist begrenzt.
Aber nicht alles ist so schlecht: Ich benutze
OmegaT seit
acht Jahren , ein kostenloses Open Source-Programm, das auf Windows-, Mac- und Linux-Systemen läuft und von der Community ständig verbessert wird. Ich arbeite darin mit
Chinesisch , Englisch und Russisch.
Was kann OmegaT?
 OmegaTwww.omegat.org
OmegaTwww.omegat.orgFreeware (GPLv3), Open Source
Windows, MacOS, Linux
Er weiß alles, was im ersten Kapitel beschrieben wird - um dem Übersetzer bei seiner Arbeit und verschiedenen anderen Kleinigkeiten zu helfen.
Dateiformate- Microsoft Word, Excel, PowerPoint (nur neue .xlsx-, .docx- und * .pptx-Dateien, alte müssen zuerst konvertiert werden)
- OpenOffice .ods, .odt und andere
- Textdateien .txt, .rtf
- Schlüssel = Wert Textdateien (* .ini und dergleichen)
- HTML
- Dateien mit einer XML-Struktur (Sie können sie selbst konfigurieren)
- Und viele andere.
SprachenBeliebig. Fast alles gibt es in Unicode. Bei seltenen Sprachen müssen Sie möglicherweise die Segmentierungsregeln anpassen, aber alles ist gelöst.
Ich werde die Anweisungen nicht nacherzählen. Es ist vollständig und informativ, und es ist sehr wichtig, sich damit vertraut zu machen. Dann gibt es nur grundlegende Operationen mit dem Programm, die Ihnen den Einstieg erleichtern.
Installation
Laden Sie die Distribution von
omegat.org herunter . Ich werde die englische Version
4.1.1 des neuesten Zweigs für Windows verwenden. Für diesen Inhalt muss Java ausgeführt werden. Wenn Sie nicht sicher sind, ob Sie eine haben, laden Sie die mit JRE gekennzeichnete Version herunter. Lassen Sie sich von der Inschrift Beta nicht beunruhigen, das Programm funktioniert mehr als stabil.
Rechtschreibprüfung
Nach der Installation ist das Programm betriebsbereit, aber standardmäßig ist die Rechtschreibprüfung nicht ausreichend.
- Starten Sie OmegaT
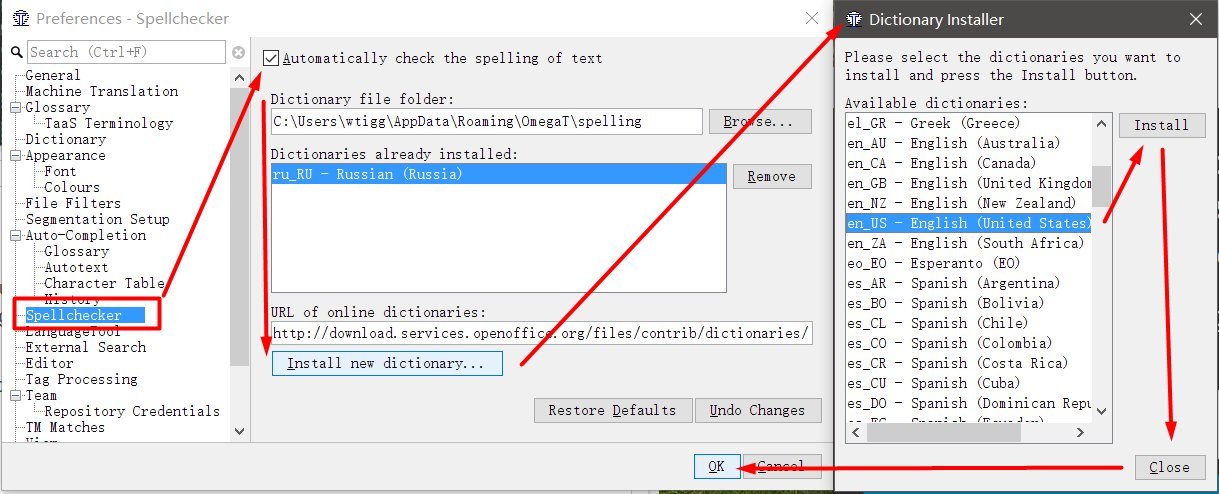
- Gehen Sie zu Optionen → Einstellungen → Rechtschreibprüfung
- Aktivieren Sie das Kontrollkästchen Automatisch die Rechtschreibung von Text überprüfen
- Klicken Sie auf Neues Wörterbuch installieren
- Wählen Sie eine Sprache (z. B. ru_RU für Russisch) und klicken Sie auf Installieren
- Klicken Sie auf Schließen . In der Liste sehen wir die russische Sprache.
- Wir verlassen die Einstellungen.
So erstellen Sie ein Projekt
OmegaT funktioniert nicht mit einzelnen Dateien, sondern mit "Projekten". Ein Projekt besteht aus einer Reihe von Ordnern mit einer bestimmten Struktur. Um eine Datei zu übersetzen, müssen Sie ein Projekt erstellen und die Datei dort hinzufügen.
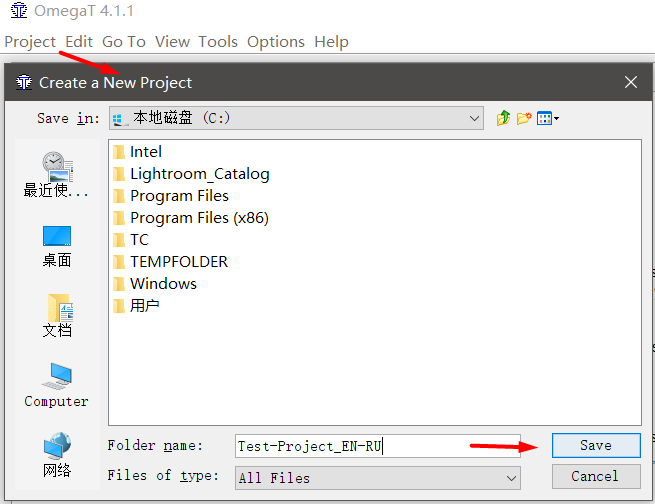
- Starten Sie OmegaT
- Projekt → Neu , wählen Sie den zu speichernden Ort und den Namen des Projekts. Ich empfehle, Projekten aussagekräftige Namen zu geben und ein Sprachpaar darin anzugeben. Zum Beispiel Test-Project_EN-RU .
- Geben Sie im angezeigten Fenster das Sprachpaar an
Sprache der Quelldateien - die Sprache, aus der Sie übersetzen; Zieldateisprache ist die Sprache, in die Sie übersetzen. Es ist notwendig, in zwei oder vier Buchstaben Code anzugeben. Zum Beispiel ist RU russisch, und RU-RU und RU-BY stellen klar, dass es russisch aus der Russischen Föderation und russisch aus Weißrussland ist. Damit die Rechtschreibprüfung funktioniert, muss der Code mit dem in den Rechtschreibeinstellungen angegebenen Code übereinstimmen (wenn RU-RU in der Rechtschreibung festgelegt ist und sich RU im Projekt befindet, funktioniert die Prüfung nicht).
- Aktivieren Sie das Kontrollkästchen neben Segmentierung auf Satzebene aktivieren (Segmente durch Sätze anstelle von Absätzen teilen) und Automatische Weitergabe von Übersetzungen ( Übersetzungen automatisch übersetzen). Deaktivieren Sie das Kontrollkästchen " Tags entfernen" . Ich werde die Arbeit später erläutern.
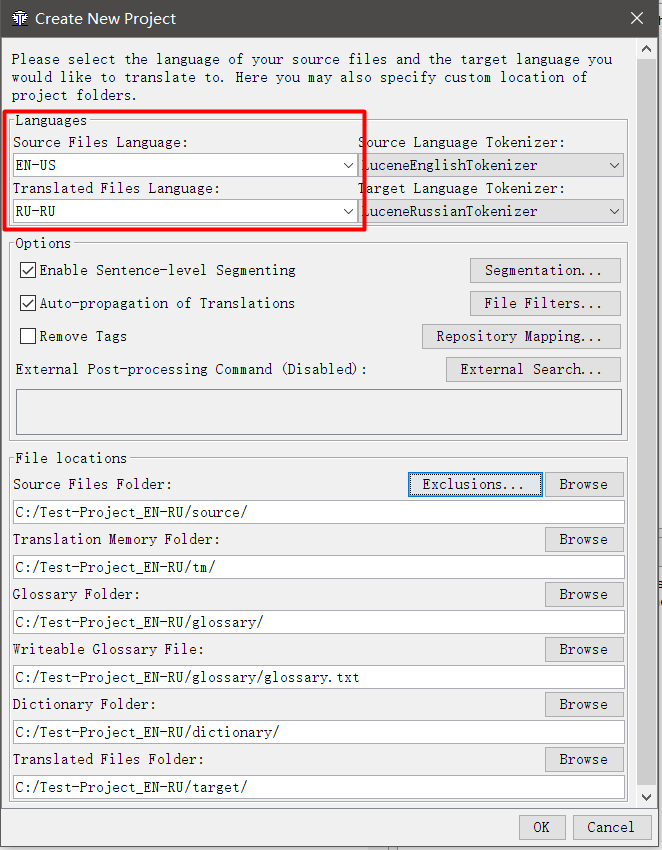
- Klicken Sie auf OK .
Was sind diese Ordner?
Im Projektordner befinden sich mehrere Unterverzeichnisse:
- Wörterbuch - Sie können Wörterbücher im StarDict-Format hinzufügen. Die Funktion ist ziemlich nutzlos.
- Glossar - eine Datenbank mit Begriffen für das Projekt, dazu später mehr;
- omegat - Translation Memory und Projektsicherungen;
- Quellordner mit Quelldateien;
- Ziel - der Ordner, in dem Übersetzungen angezeigt werden;
- tm - Ordner für zusätzliche Übersetzungsspeicher, dazu später mehr.
Und auch die Datei
omegat.project mit der Konfiguration des aktuellen Projekts.
So fügen Sie Dateien hinzu
Nachdem Sie das Projekt erstellt haben, wird das folgende Fenster angezeigt:
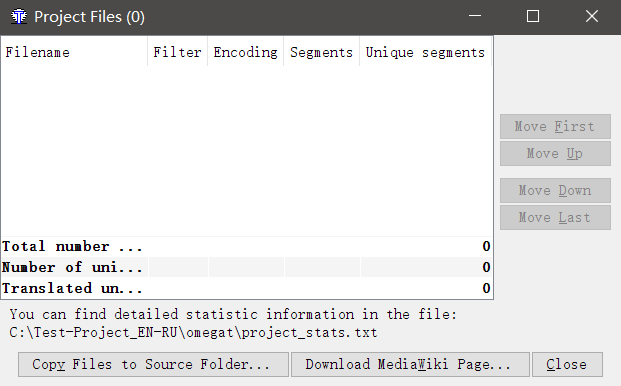
Klicken Sie auf
Dateien in Quellordner
kopieren und wählen Sie die Dateien aus, die Sie übersetzen möchten. Dateien werden in den Ordner
\ source \ des neu erstellten Projekts kopiert. Sie können dort manuell Dateien hinzufügen. Kopieren Sie einfach die Dateien über den Explorer nach
\ source \ .
Zum Beispiel habe ich zwei Dateien erstellt - Excel und Word, in denen ich die Arbeit von OmegaT zeigen werde.
Schnittstelle
OmegaT läuft, Dateien wurden hinzugefügt. Mal sehen, wie sie im Programm aussehen.
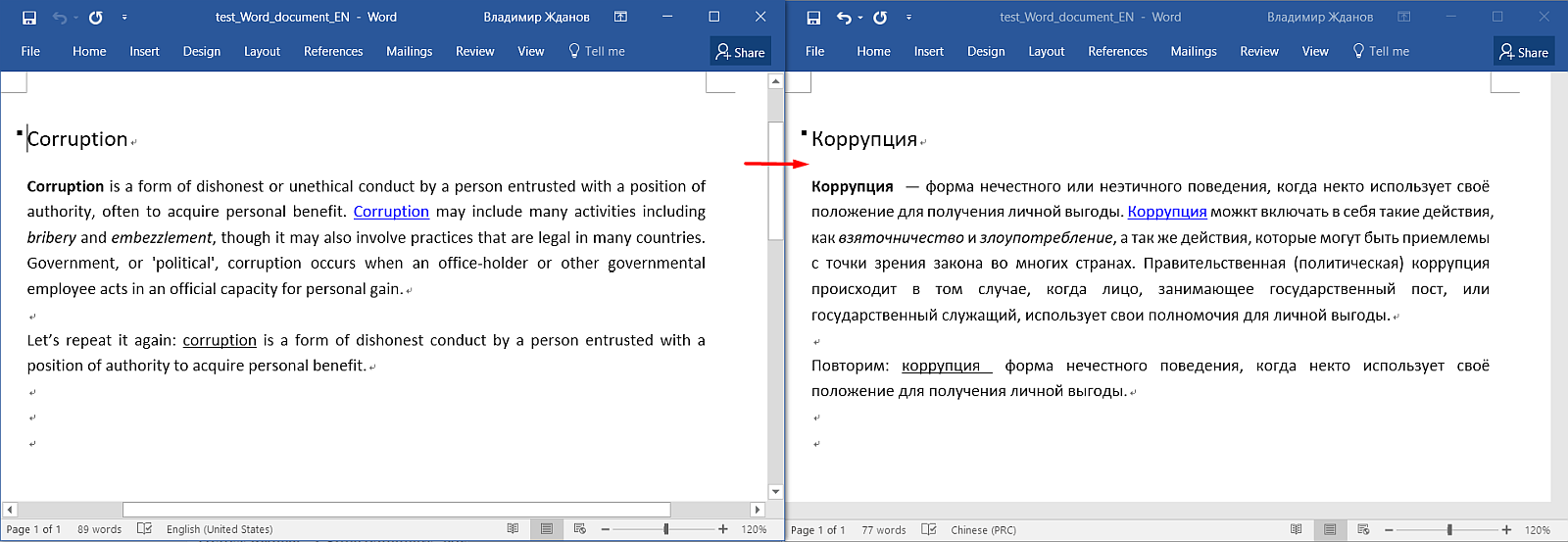
Hier ist das Quelldokument in Word. Hier sehen Sie die Überschrift, Absätze, Formatierung (fett, Links, Unterstreichungen).

Und so sieht es in OmegaT aus:
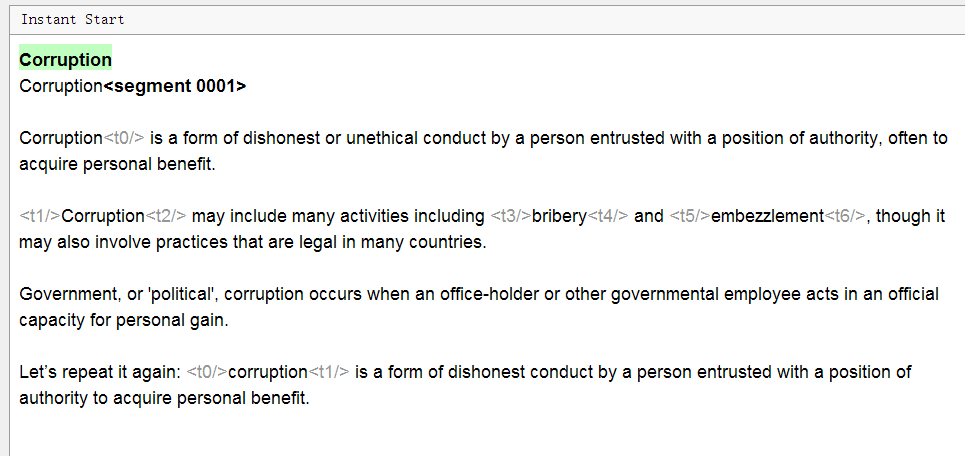
Bitte beachten Sie: Der gesamte Text ist in Sätze unterteilt, die Formatierung ist nicht sichtbar, einige graue
Tags wurden angezeigt und die Überschrift wird dupliziert. Was ist los?
- Text segmentiert
Jedes Angebot wurde in einem eigenen Segment zugeordnet. Segmentierungsregeln können bei Bedarf unabhängig konfiguriert werden. - Die Formatierung in OmegaT ist nicht sichtbar, Tags ersetzen sie
Dies sind Abkürzungen für Tags aus Word, die ansonsten wie <t> aussehen könnten. Um die ursprüngliche Formatierung beizubehalten, müssen Sie diese Tags unverändert lassen und die Übersetzung zwischen den Tags in derselben Logik wie im Original eingeben.
Die Option Tags entfernen in den Projekteinstellungen entfernt Tags zusammen mit der Formatierung. Es wird nicht empfohlen, es zu verwenden, wenn es wichtig ist, die ursprüngliche Formatierung beizubehalten. - Der Titel wird nicht dupliziert.
Tatsächlich wird der Text in der Ausgangssprache immer oben angezeigt (in Grün). Sie können ihn nicht ändern. Darunter befindet sich ein Textfeld, in das standardmäßig derselbe Text kopiert wird. Sie müssen es löschen und die Übersetzung eingeben.
Darüber hinaus befinden sich auf der rechten Seite des Programms zwei weitere Sektoren:
Fuzzy Matches und
Glossary (Projektwörterbuch).
Fuzzy- Übereinstimmungen (Fuzzy-Übereinstimmungen) - Suchergebnisse in der Projektdatenbank. Dort werden Übersetzungstipps angezeigt, die auf Ihren vorherigen Übersetzungen basieren.
Glossar (Projektwörterbuch) - das Ergebnis einer selbst erstellten Glossarsuche. Im Gegensatz zum Translation Memory ist dies kein vorgefertigter Text, sondern nur ein Hinweis auf bestimmte Begriffe. Dies ist ein leistungsstarkes Tool, mit dem die Terminologie konsistent bleibt.
Wie übersetze ich?
- Doppelklicken Sie auf ein Segment, um es zu übersetzen
Unter dem Originaltext wird eine bearbeitbare Textzeile angezeigt, der Cursor befindet sich am Anfang und der Originaltext wird in der Zeile dupliziert. - Geben Sie Ihre Übersetzung ein
- Drücken Sie die Eingabetaste
Wenn diese Taste gedrückt wird, wird die Übersetzung gespeichert und der Cursor bewegt sich zum nächsten Segment.
Wiederholen Sie diesen Vorgang, bis Sie das Dokument fertiggestellt haben. Sie können jederzeit zum vorherigen Segment zurückkehren, indem Sie einfach darauf doppelklicken.
In der unteren rechten Ecke befindet sich eine
praktische Fortschrittsanzeige . Klicken Sie darauf, um den Ansichtsmodus zu wechseln.

Aktuelle Datei:% Segmente übersetzt (Segmente links) / Projekt:% Segmente übersetzt (Segmente links), Gesamtzahl der Segmente. [/ Caption]
Diese Zeile zeigt an, dass in der aktuellen Datei 5,8% der eindeutigen Segmente übersetzt wurden, 1382 noch übersetzt werden mussten. Insgesamt wurden 63% der Segmente im Projekt übersetzt, 1756 blieben und ihre Gesamtzahl im Projekt betrug 5979.

Datei: übersetzte eindeutige Segmente / Gesamtzahl der eindeutigen Segmente (Projekt: übersetzte eindeutige Segmente / insgesamt eindeutige Segmente, Gesamtzahl der Segmente im Projekt) [/ caption]
Im
zweiten Modus heißt es in der Abbildung, dass in der Datei mit 1592 eindeutigen Segmenten 146 übersetzt wurden und im Projekt mit 4748 eindeutigen Segmenten 2992 übersetzt wurden. Insgesamt wurden 5979 Segmente (einschließlich Wiederholungen) übersetzt.
Die Zahlen 14/14 am Ende beziehen sich nicht auf den Projektzähler. Dies ist ein Indikator für die Länge des Segments, mit dem Sie arbeiten. Er sagt, dass das Original 14 Zeichen hatte und die Übersetzung auch 14. Diese Funktion ist nützlich in Fällen, in denen Sie die Länge der Zeichenfolge genau beachten müssen, beispielsweise bei der Übersetzung der Programmoberfläche.
Fuzzy-Übereinstimmungen Fuzzy-Übereinstimmungen
Das wichtigste Werkzeug jeder CAT-Anwendung, dafür gibt es sie.
Ich werde mit einem Beispiel erklären:
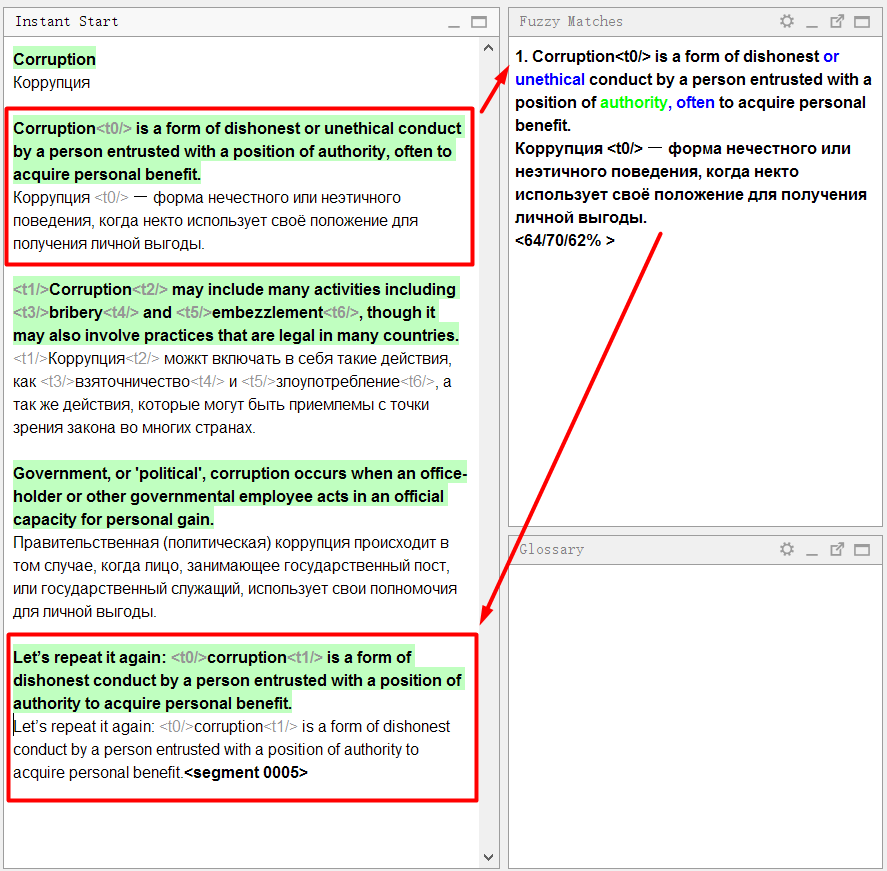
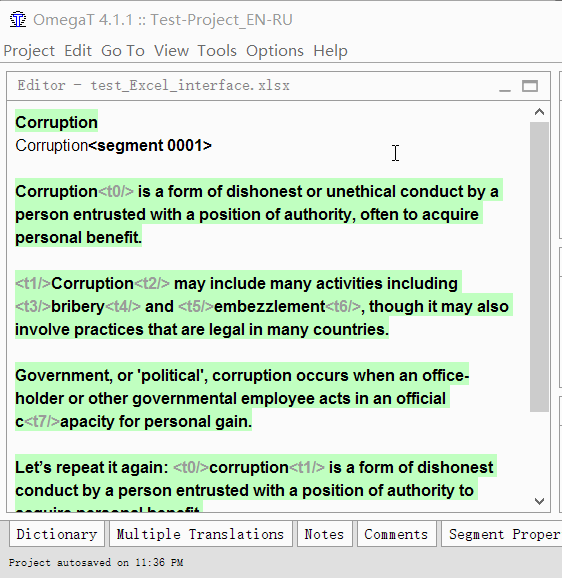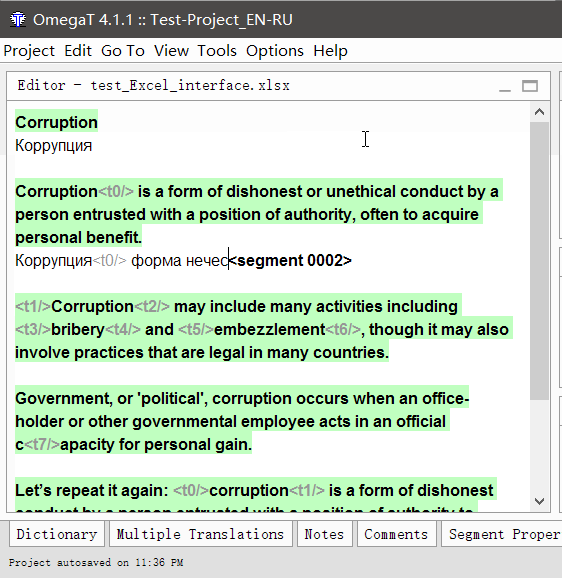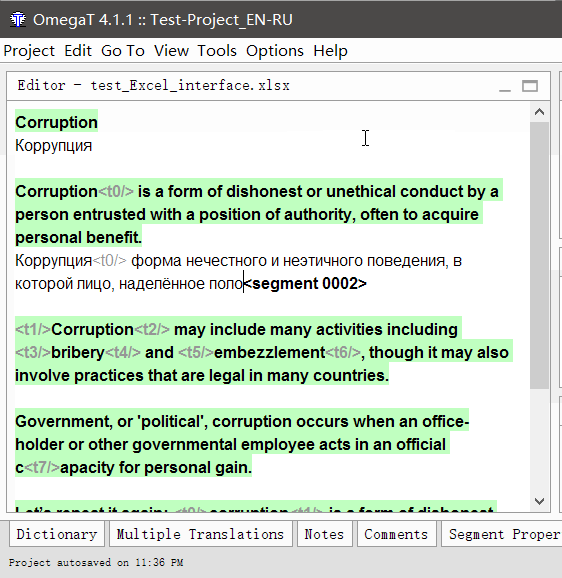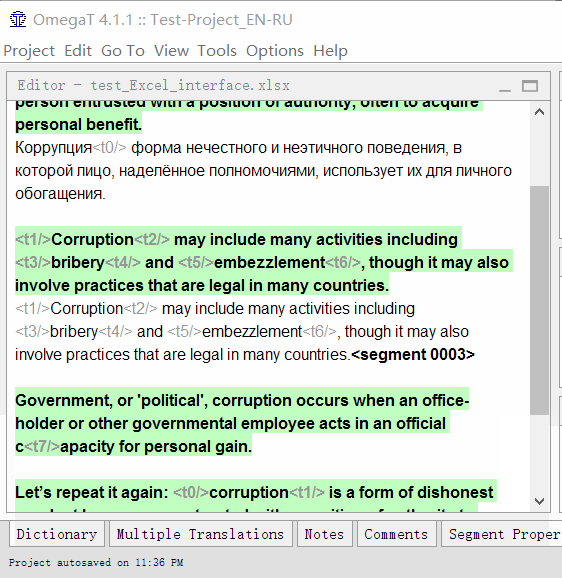
Im Beispieldokument ist der
erste Satz dem
vierten sehr ähnlich. Ich ging in der richtigen Reihenfolge und übersetzte den ersten Satz. Als ich zum vierten kam, zeigte das Programm sofort einen
unscharfen Zufall :
Schauen Sie sich das Spielfeld genau an:
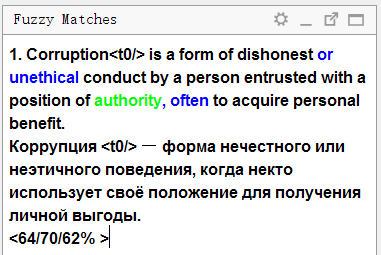
Der obere Teil zeigt den Text in der
Ausgangssprache an , die
im Translation Memory gespeichert wurde . Die Wörter, die im Translation Memory vorhanden sind, aber im aktuellen Satz fehlen (mit dem die Übereinstimmung verglichen wird), werden blau hervorgehoben, die Wörter neben den fehlenden Teilen werden grün hervorgehoben.
Unten ist eine Übersetzung im Speicher gespeichert. Wenn Sie
Strg + R drücken, wird es zur Übersetzung in das Feld kopiert.
Drei Zahlen sind unten als Prozentsatz angegeben. Sie bedeuten den Grad der Übereinstimmung zwischen dem Satz und dem Translation Memory. Weitere
Informationen zur Berechnungs-Engine finden Sie
in der OmegaT-Hilfe .
Automatische Übersetzung identischer Segmente
Wenn die
Fuzzy Match- Engine eine
100% ige Übereinstimmung findet , kann
sie diese natürlich
selbst einfügen . Nehmen Sie zum Beispiel eine andere Datei, diesmal in Excel. Ungefähr in dieser Form wird häufig der Auftrag erteilt, die Benutzeroberfläche einer Site oder eines Programms zu übersetzen.
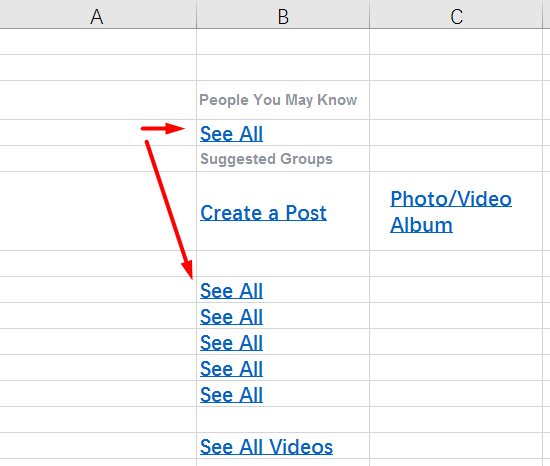
Und so sieht die Datei in OmegaT aus:
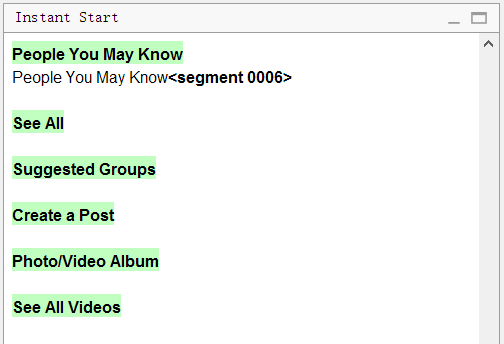
Bitte beachten Sie, dass es im Original
sechs Zeilen von
Alle anzeigen gab . Das Programm entfernte alle Duplikate und ließ nur
eine Zeile übrig. Es reicht aus, es alleine zu übersetzen, und die verbleibenden Segmente werden ebenfalls übersetzt.
Glossar
Das Glossar funktioniert sehr einfach. Zuerst
fügen Sie Wörter hinzu (Original und Übersetzung). Wenn das Wort nun im Text angezeigt wird, wird sofort eine Eingabeaufforderung im
Glossarfenster angezeigt.
Wenn also ein Begriff in einem neuen Satz erscheint, wissen Sie sofort, wie er übersetzt werden muss. Wenn Sie beispielsweise beim Übersetzen der Programmoberfläche immer "Gut" anstelle von "OK" schreiben müssen, fügen Sie dem Wörterbuch einfach das Wort "OK" mit der Übersetzung "Gut" hinzu. Wenn Sie dem Projekt einige hundert Wörter hinzufügen, vereinfachen Sie Ihr Leben erheblich.
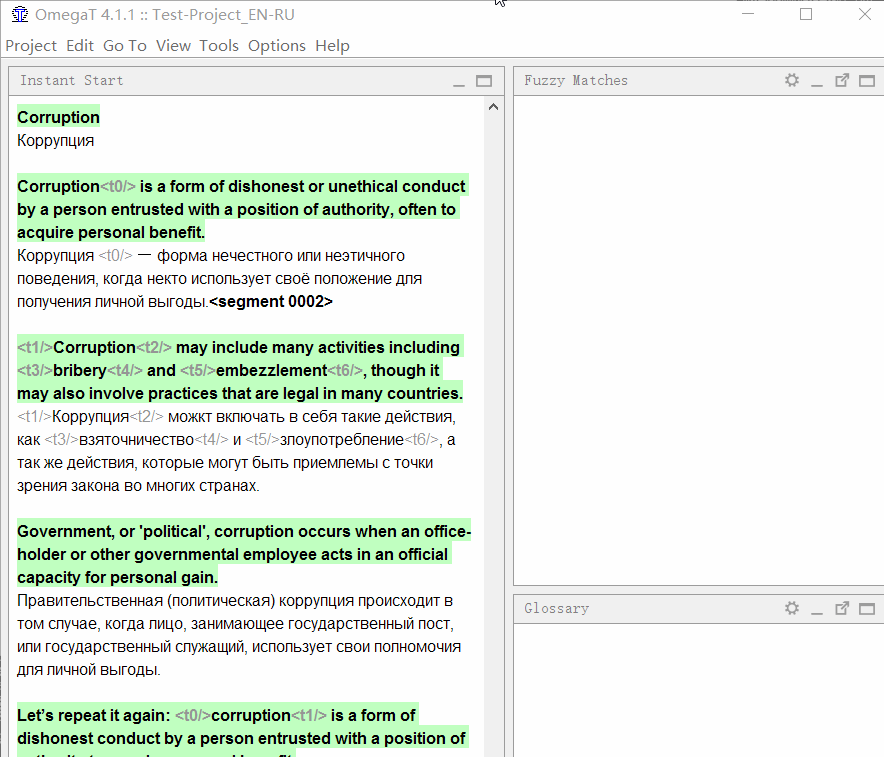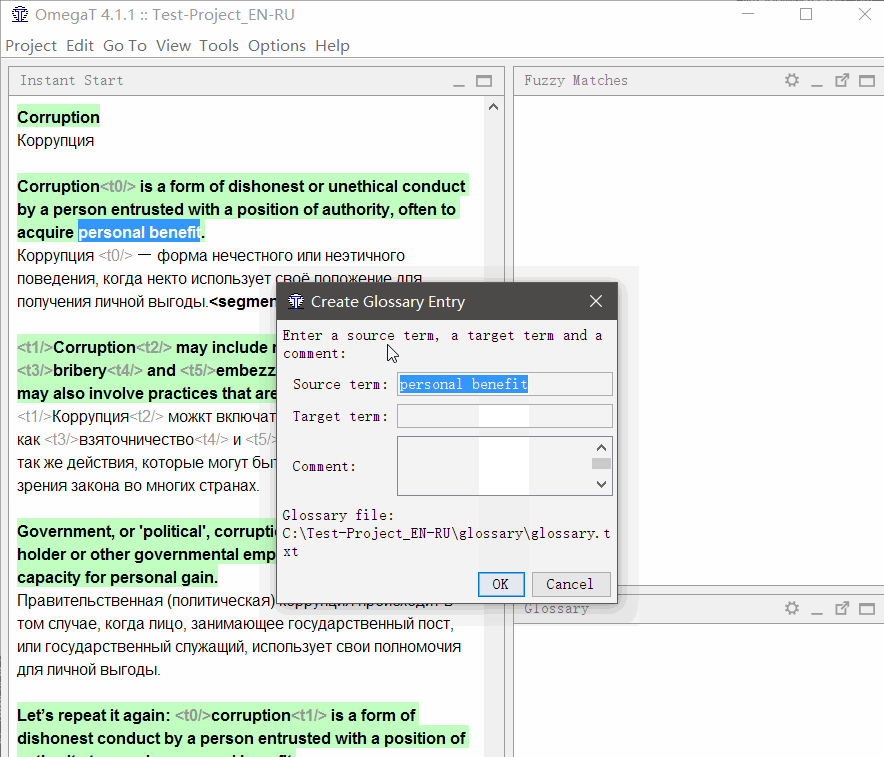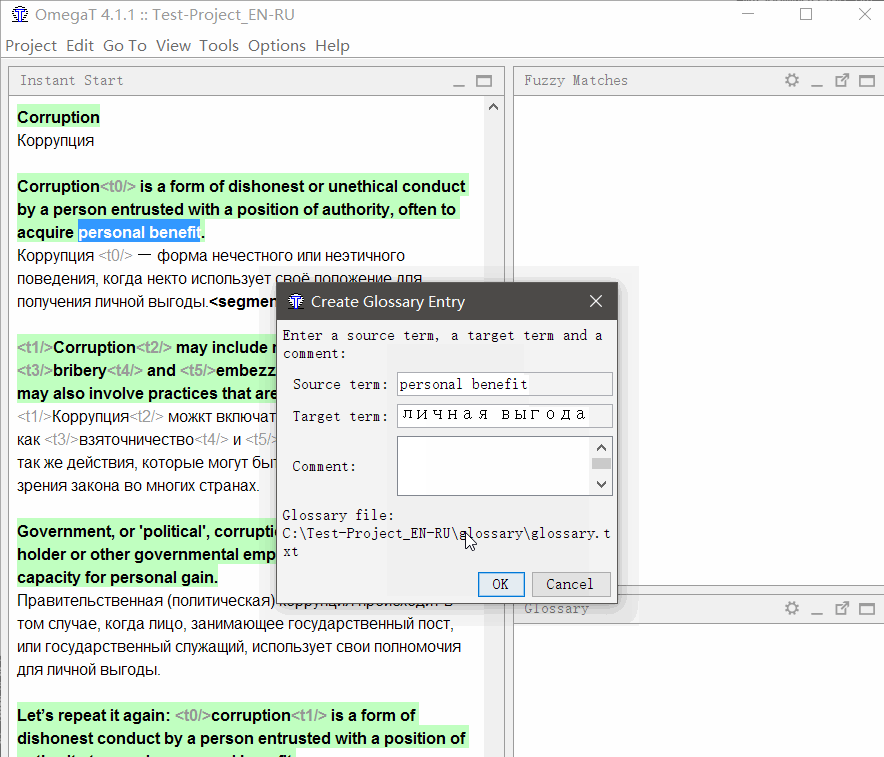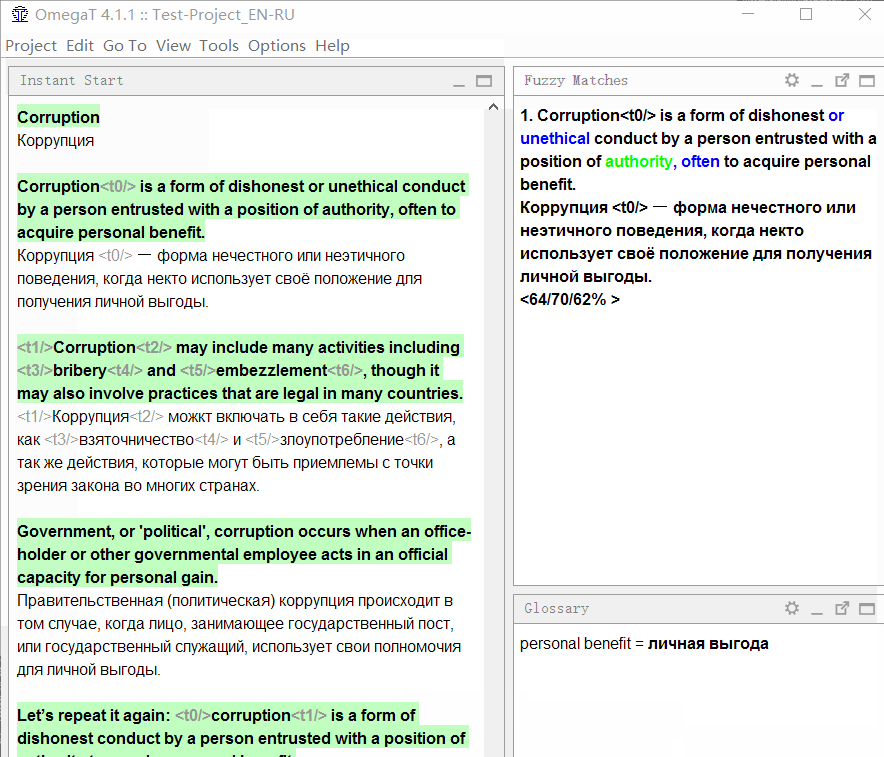
Um
dem Glossar ein Wort hinzuzufügen , wählen Sie es aus, klicken Sie mit der rechten Maustaste und wählen
Sie Glossareintrag hinzufügen .
Darüber hinaus können der Datei
\ glossary \ glossary.txt im Format „Registerkarte für Originalübersetzung“ massiv Wörter hinzugefügt werden (eine Excel-Tabelle, die im tabulatorgetrennten * CSV-Format gespeichert ist, reicht aus)
So speichern Sie
Der Punkt
Projekt → Speichern bedeutet "Projekt speichern", d. H. Schreiben aller Übertragungen in die Datenbankdatei.
Um die fertige Datei zu erhalten , müssen Sie
Projekt → Übersetzte Dokumente erstellen auswählen.
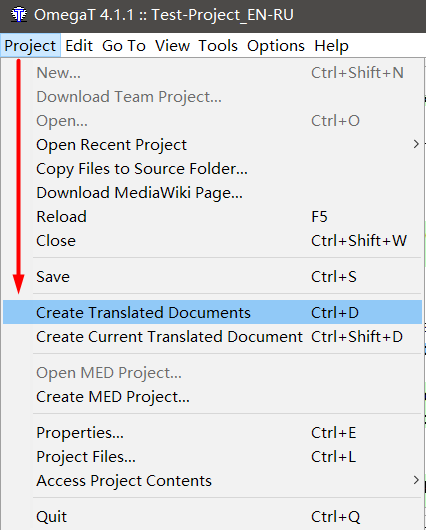
Mit diesem Befehl erstellt OmegaT eine neue Datei im Ordner
\ target \ mit demselben Namen wie das Original und
ändert den gesamten Text in Übersetzung . Wenn Sie keine Segmente übersetzt haben, befindet sich in der Datei an ihrer Stelle der Originaltext.
So fügen Sie maschinelle Übersetzung hinzu
In einigen Situationen kann die maschinelle Übersetzung (z. B.
Google Translate ) zu einer schnelleren
Übersetzung beitragen. OmegaT kann so konfiguriert werden, dass direkt in seiner Benutzeroberfläche eine maschinelle Übersetzung des Segments angezeigt wird, die Sie direkt verwenden oder sehr schnell bearbeiten können.
In OmegaT können Sie Systeme wie
Google Translate ,
Microsoft Translator und
Yandex.Translator verbinden . Sie müssen für die ersten beiden bezahlen, und
Yandex.Translator bietet seine Dienste kostenlos an (innerhalb angemessener Nutzungsgrenzen). Jetzt werde ich Ihnen sagen, wie es geht.
- Registrieren Sie ein Konto in Yandex.
Holen Sie sich zum Beispiel Mail. - Gehen Sie zur Entwicklerseite im Abschnitt "Übersetzer" unter diesem Link .
- Klicken Sie auf Neuen Schlüssel erstellen , geben Sie eine Beschreibung ein (für sich selbst) und klicken Sie auf Erstellen.
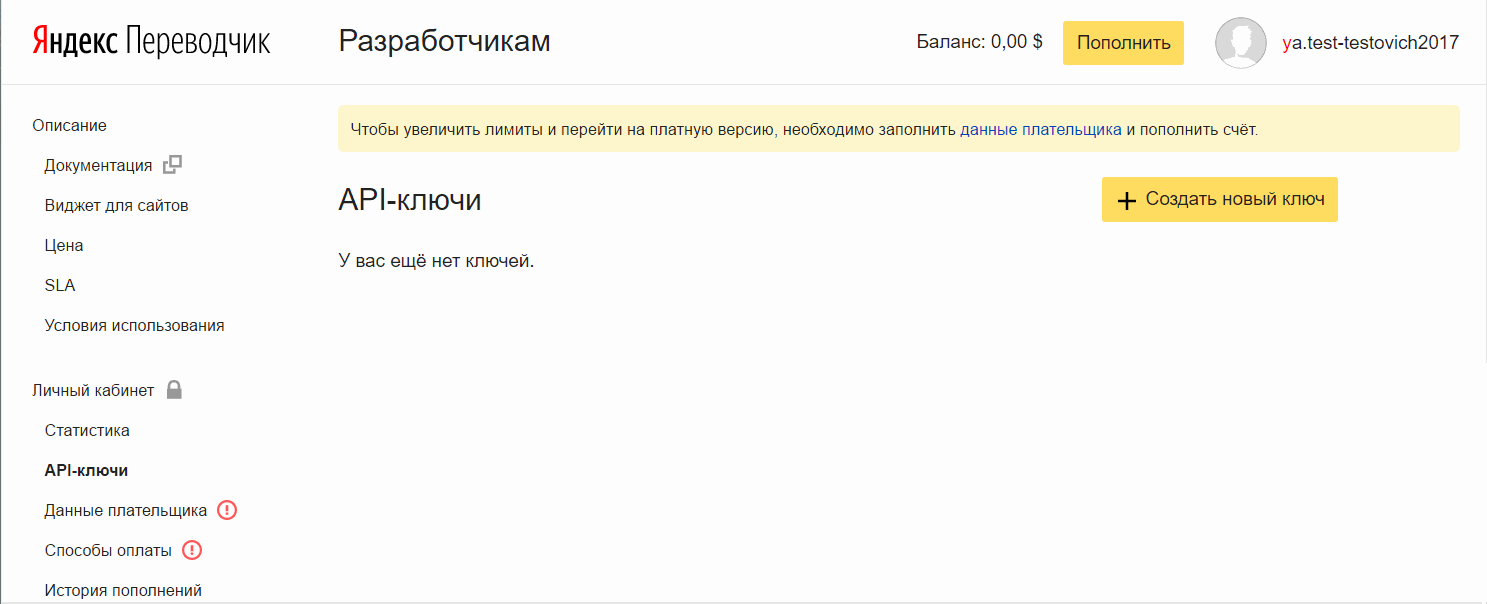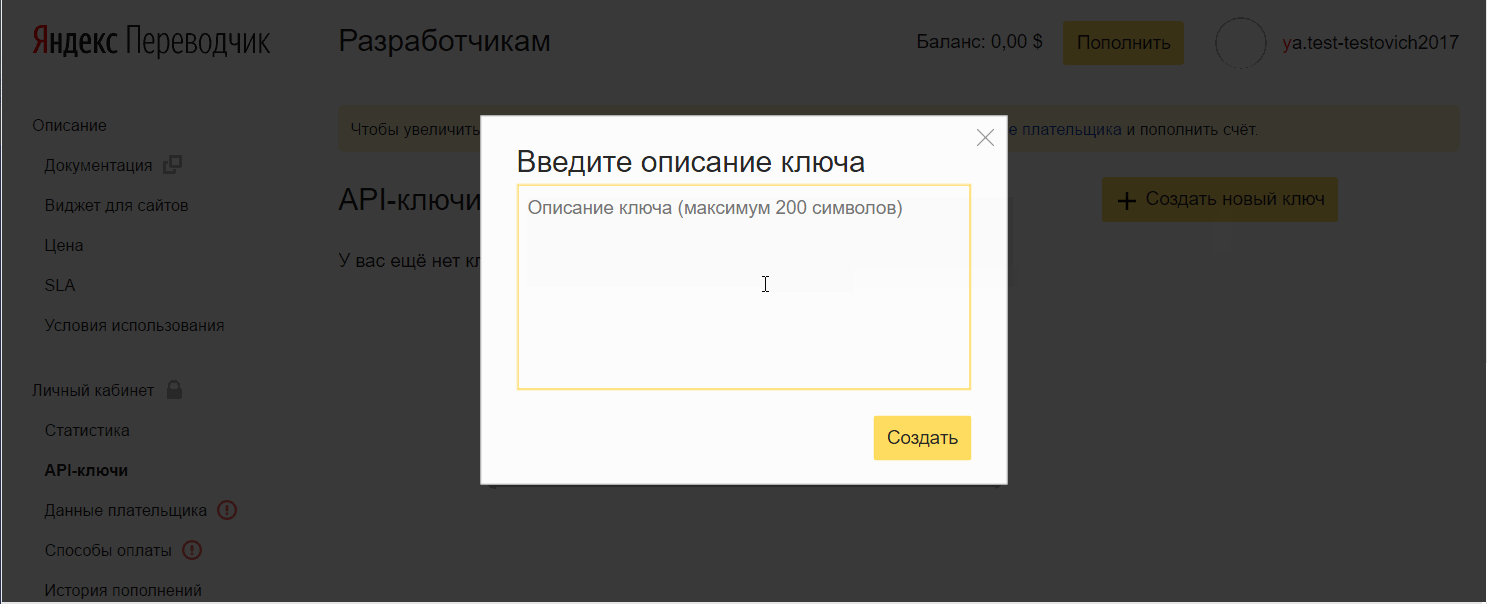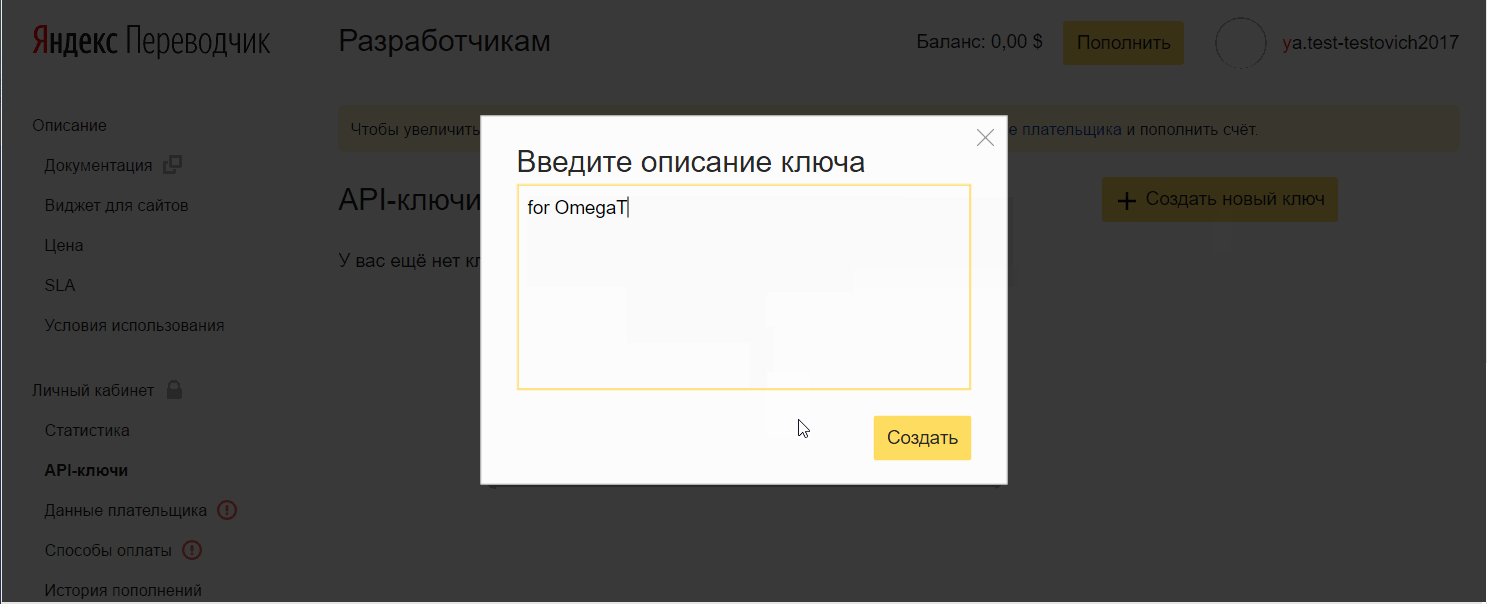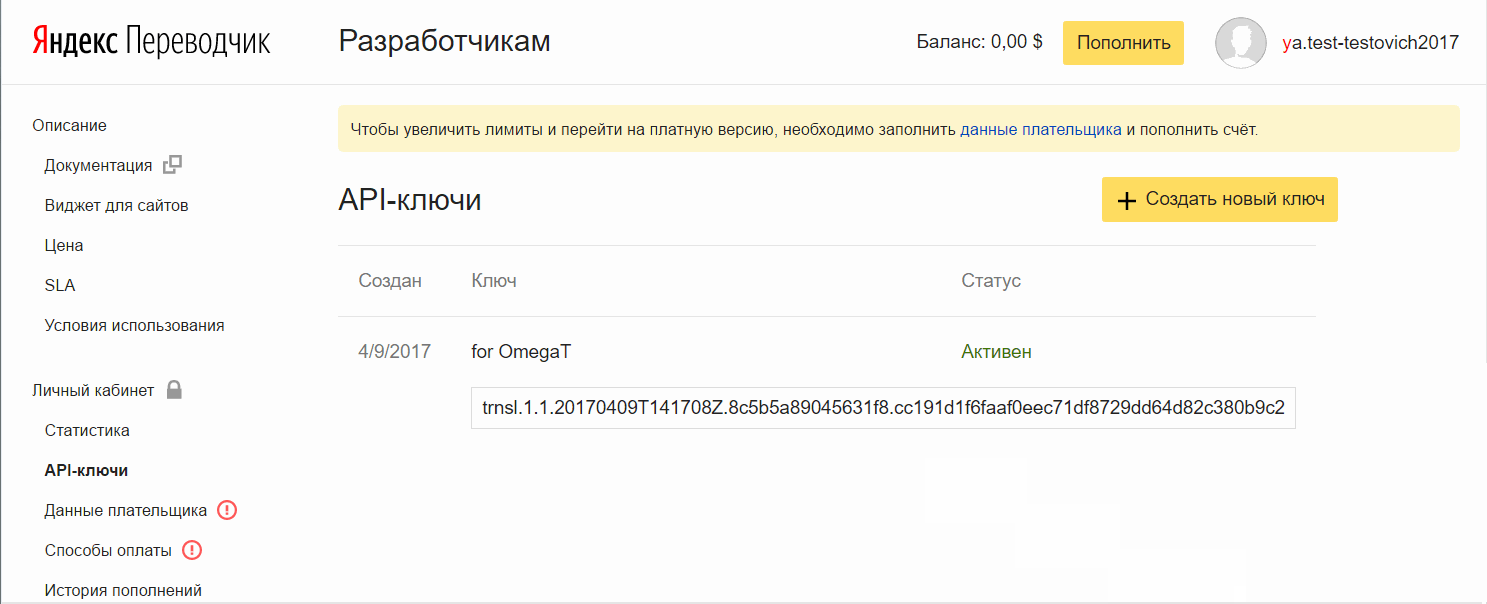 Fügen Sie den Schlüssel
Fügen Sie den Schlüssel zu OmegaT hinzu:
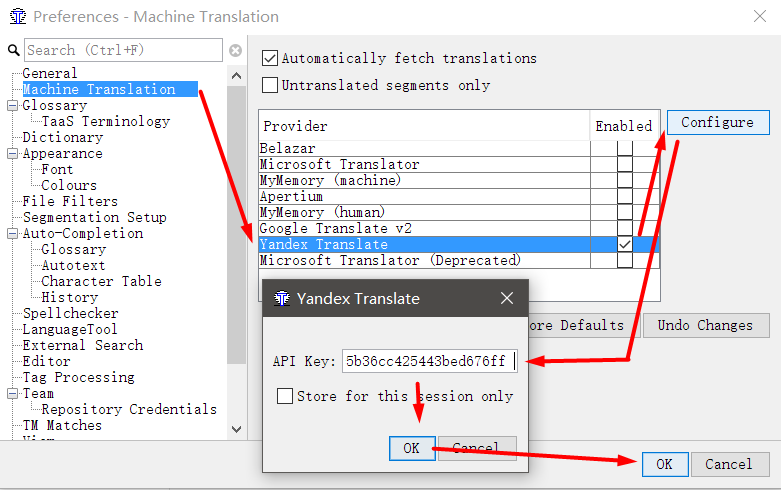
- Gehen Sie in OmegaT zu Optionen → Einstellungen → Maschinelle Übersetzung
- Wählen Sie Yandex Translate aus , kreuzen Sie es an und klicken Sie auf Konfigurieren
- Kopieren Sie den API-Schlüssel in das angezeigte Feld und klicken Sie auf OK
- Im angezeigten Fenster können Sie ein Kennwort festlegen oder diese Aktion überspringen.
Zum Schutz Ihres API-Schlüssels ist ein Kennwort erforderlich. Tatsächlich für kostenpflichtige Übersetzungssysteme.
Schließen Sie die Einstellungen. Jetzt können Sie im Hauptfenster des Programms unten im Fenster
auf die Registerkarte Maschinelle Übersetzungen klicken . Um das maschinelle Übersetzungsfenster immer im Blick zu behalten, klicken Sie auf das kleine Symbol mit zwei Fenstern.
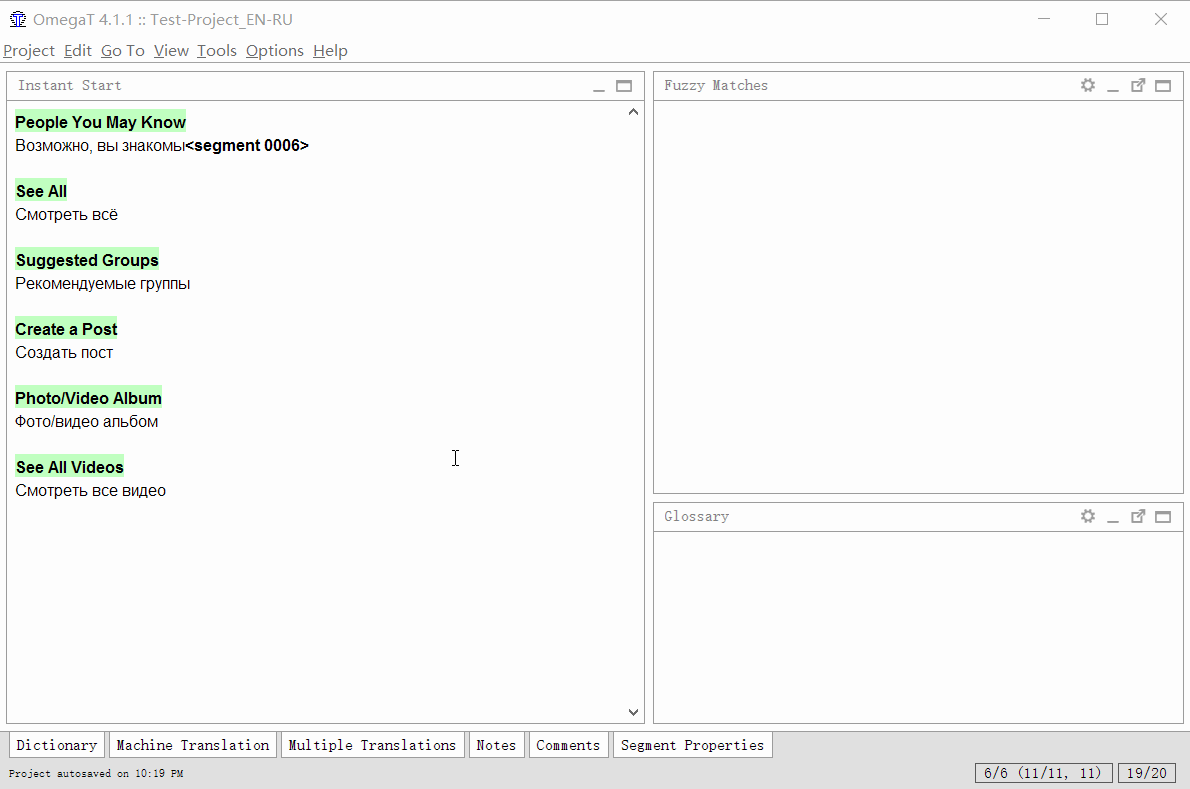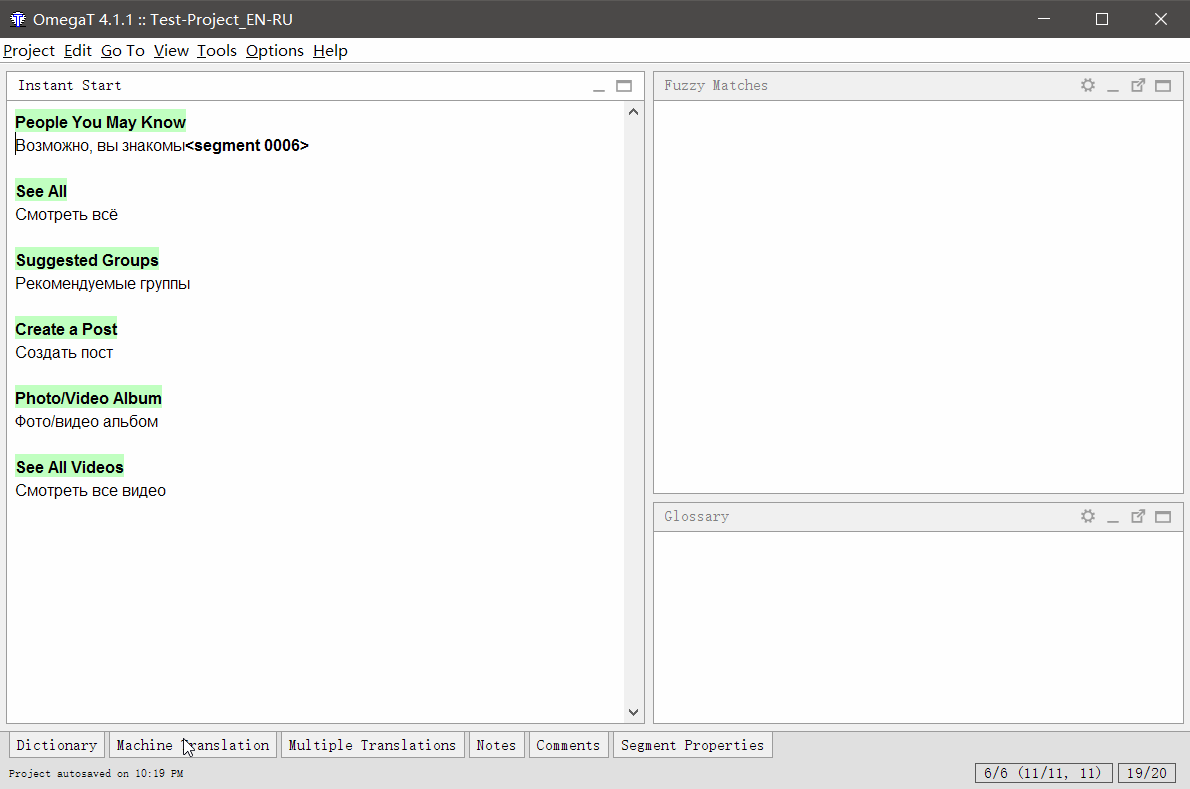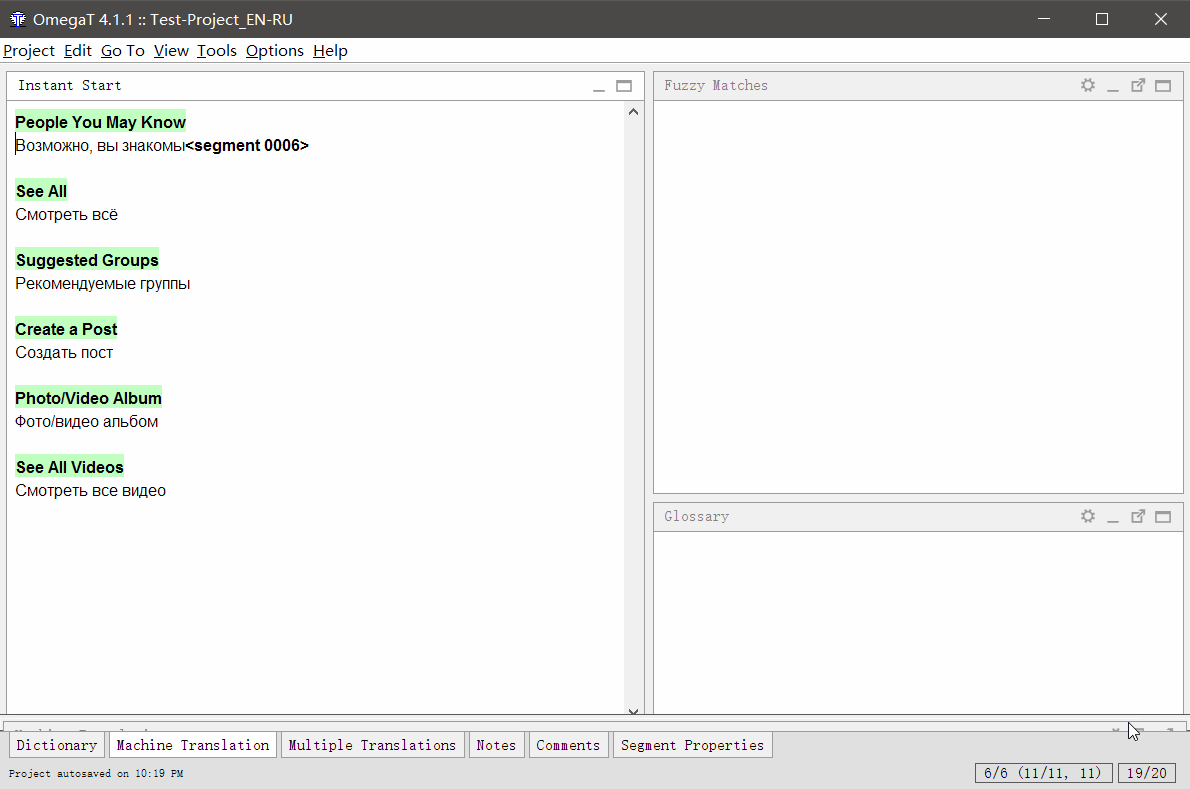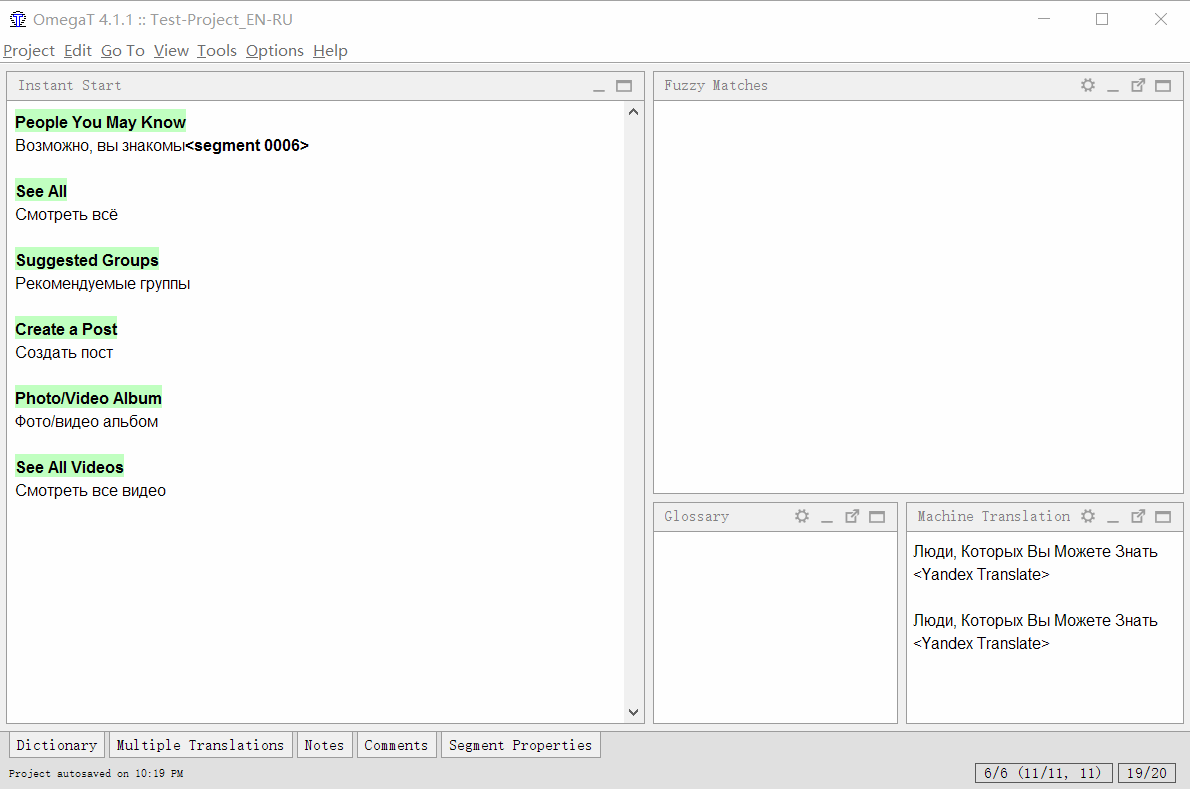
Wenn Sie jetzt in ein neues Segment wechseln, sendet das Programm eine Anfrage an Yandex.Translator, empfängt eine Antwort und zeigt sie in einem Fenster an. Hotkey Strg + M kann das Ergebnis in das Übersetzungsfeld einfügen.
Wie überprüfe ich den Text auf Fehler?
Zusätzlich zu der einfachen Rechtschreibprüfung, die wir zuvor eingerichtet haben, können Sie nach komplexeren Fehlern suchen, vom Styling bis hin zu fehlenden Tags. Zu diesem Zweck verwendet OmegaT das offene
Sprachtool . Es wird komplett mit OmegaT geliefert, kann separat installiert oder an einen Remote-Server angeschlossen werden.
- Extras → Probleme prüfen (oder Strg + Umschalt + V )
- Doppelklicken Sie auf den Fehler in der Liste, um zum zu bearbeitenden Segment zu gelangen.
Durch Klicken mit der rechten Maustaste können Sie dem Wörterbuch ein Wort hinzufügen oder die Überprüfung auf diese Art von Fehler deaktivieren.
Links im Fenster
Probleme prüfen können Sie den Filter
Tags auswählen. Dies ist nützlich beim Übersetzen von Dokumenten mit einer großen Anzahl von Tags, deren Speicherung sehr wichtig ist - beispielsweise beim Lokalisieren von Software.
Tipp: Wenn Sie Tags um jeden Preis speichern möchten, kann OmegaT daran gehindert werden, endgültige Dokumente zu erstellen, wenn die Tags Fehler enthalten. Dies erfolgt unter
Extras → Einstellungen → Tag-Verarbeitung → Erstellen von übersetzten Dokumenten mit Tag-Problemen nicht zulassen .
Die Feinabstimmung des Sprachwerkzeugs ist über
Extras → Einstellungen → LanguageTool möglich. Hier können Sie auswählen, ob Sie das integrierte Sprachtool verwenden oder eine Verbindung zu einem lokalen / Remote-Server herstellen möchten. Unten können Sie die Art der Fehler auswählen, auf die das Programm reagiert, z. B. "
Interpunktion " → "
Fehlendes Komma vor der Präposition" UND "in einem komplexen Satz " oder "
Stil " → "
Gesprochene Wörter ".
Wie öffne ich den TMX-Translation Memory?
Es kommt vor, dass Sie sehen müssen, was sich in der * .tmx-Datei befindet, oder sie sogar bearbeiten müssen. Die Struktur der Datei ist recht einfach, und zur Not kommen Sie mit dem Editor zurecht, aber das ist nicht sehr praktisch. OmegaT kann
TMX nicht zum Bearbeiten selbst öffnen: Der Translation Memory kann nur zum Projekt hinzugefügt, aber nicht von selbst geöffnet werden.
Für Windows-Benutzer ist das kostenlose Dienstprogramm
Olifant aus dem
Okapi- Paket geeignet.
Sie können es hier herunterladen .
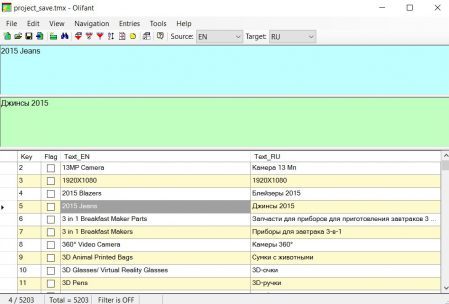
Ich sehe keinen Grund, schrittweise Anweisungen für dieses Programm zu schreiben. Alles ist intuitiv:
Datei → Öffnen , Translation Memory auswählen. Oben im Programm das Original und unten die Übersetzung - eine Liste aller Segmente.
Über
Datei → TM-Eigenschaften können Sie die Eigenschaften des Translation Memory ändern, z. B. Sprachpaare, Codierung usw.
Wie erstelle ich mein eigenes TM?
Angenommen, Sie haben bereits eine hochwertige zweisprachige Datei und möchten diese im Projekt als Referenzmaterial verwenden. Wenn die Datei im
Excel- Format vorliegt, wobei sich der Originaltext in einer Spalte befindet und die entsprechende Übersetzung in den gegenüberliegenden Zellen erfolgt, ist es sehr einfach, TM zu erstellen.
Ich benutze drei Möglichkeiten:
- Kostenloses Okapi Olifant Utility
- Eingebauter OmegaT Aligner
- Online-Dienst Translatum.gr
Olifant
Das Programm, über das wir im vorherigen Kapitel gesprochen haben, kann nicht nur vorgefertigte
TMXs öffnen , sondern auch neue erstellen sowie mehrere
* .tmx in einem Speicher kombinieren.
Installieren Sie
Olifant und führen Sie es aus. Klicken Sie auf
Datei → Neu und wählen Sie die Ausgangssprache und die Übersetzungssprache aus. Fügen Sie nun die zweisprachigen Segmente zum neuen Speicher hinzu:
Datei → Importieren . Sie können
Wordfast- Dateien
, andere
* .tmx- oder
tabulatorgetrennte Dateien hinzufügen - mit anderen Worten eine Textdatei, in der das
Quellfragment und seine Übersetzung durch Tabulatoren getrennt sind.
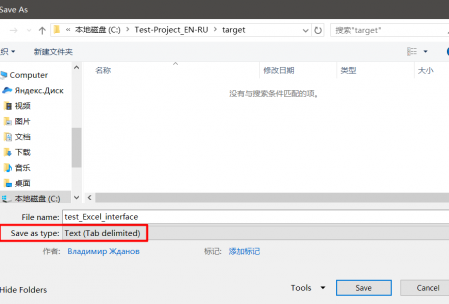
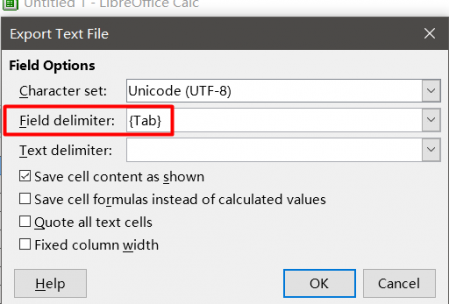
Tabulatorgetrennte Dateien können in
MS Excel oder
Libre Office Calc erstellt werden . Erstellen Sie dazu eine Tabelle mit zwei Spalten. Fügen Sie im ersten den Quelltext in die gegenüberliegenden Zellen in der zweiten Spalte ein - die Übersetzung.
Speichern Sie die Datei im
tabulatorgetrennten Textformat (in
Microsoft Office ) oder in
Text CSV mit den Parametern
Feldtrennzeichen = Tabulator, Zeichensatz = UTF-8 und
Texttrennzeichen = * leer *, wenn Sie
Libre Office verwenden .
Wenn Sie alle erforderlichen Fragmente importieren, speichern Sie sie einfach über
Datei → Speichern unter im
TMX-Format .
OmegaT Aligner
Im Gegensatz zu Olifant ist die Quelle keine Tabelle mit zwei Spalten, sondern zwei unabhängige Dateien mit derselben Struktur, jedoch in verschiedenen Sprachen. Je komplexer die Formatierung und je mehr Unterschiede vorhanden sind, desto schlechter ist das Ergebnis des automatischen Abgleichs. Es kann jedoch manuell in
Aligner korrigiert werden.
Starten Sie
OmegaT , öffnen Sie
Extras → Dateien ausrichten . Geben Sie die Sprachen des Originals und der Übersetzung an und hängen Sie die Dateien an.
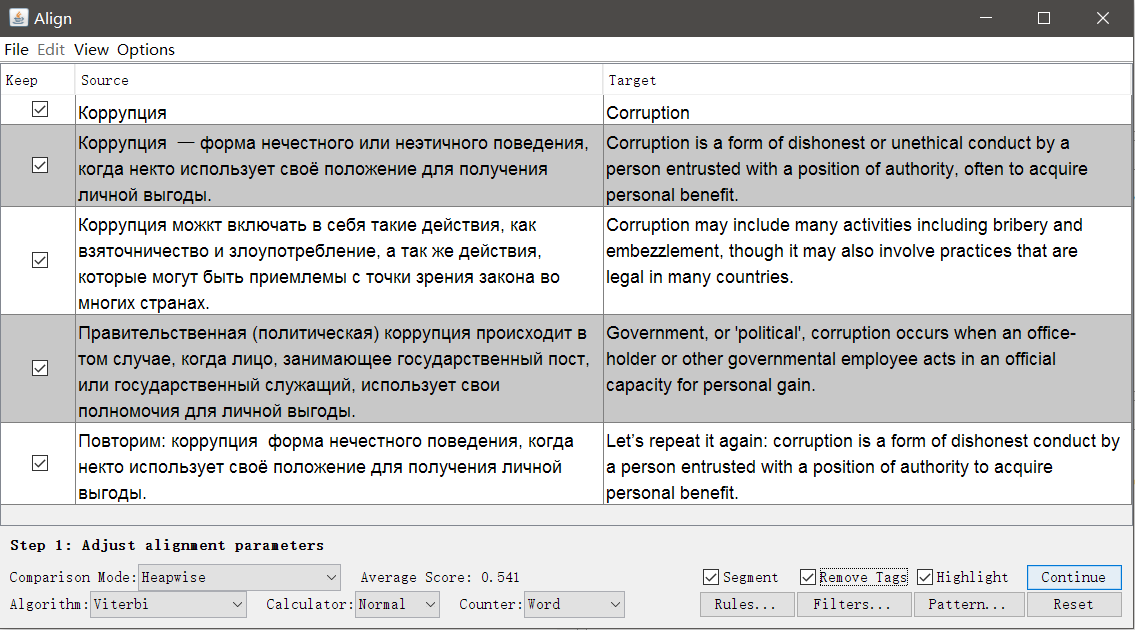
Bei Bedarf können Sie die Tags entfernen und die Segmentierungseinstellungen ändern.
Klicken Sie auf Weiter , und Sie gelangen zu einem Fenster mit manueller Anpassung der Segmente: Sie können Segmente teilen, zusammenführen oder nach oben oder unten verschieben.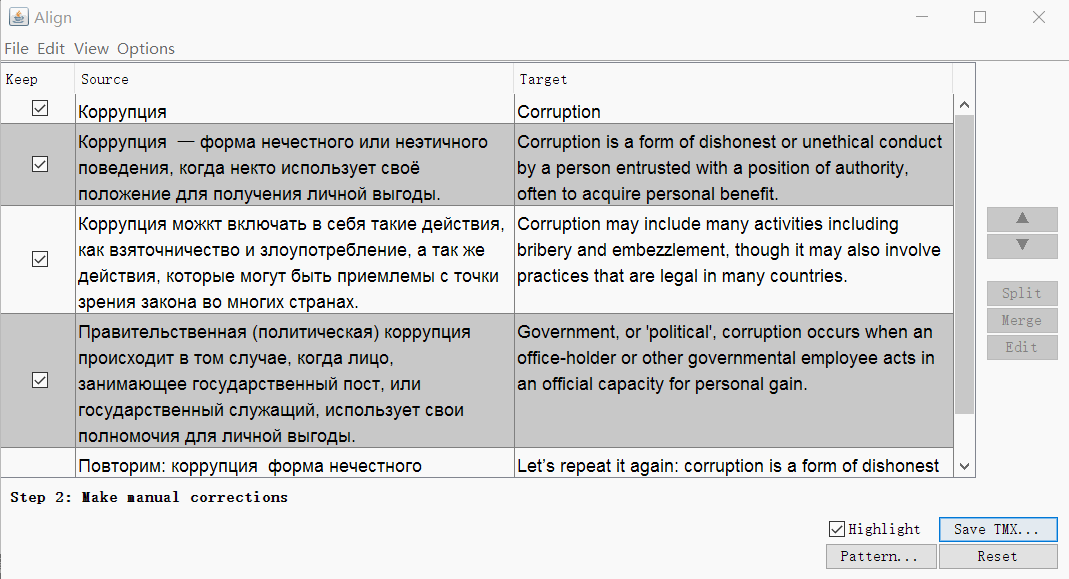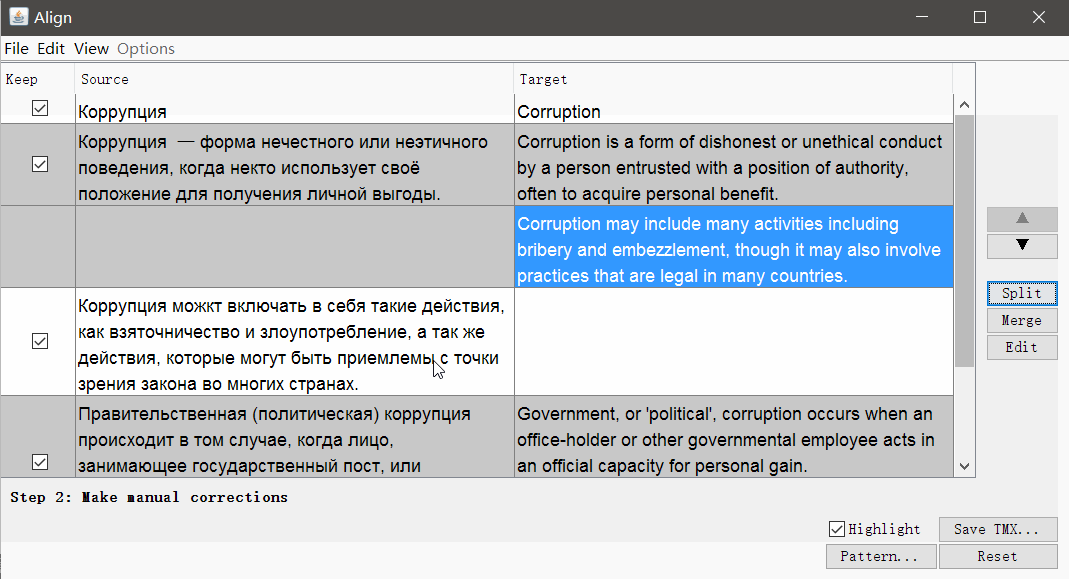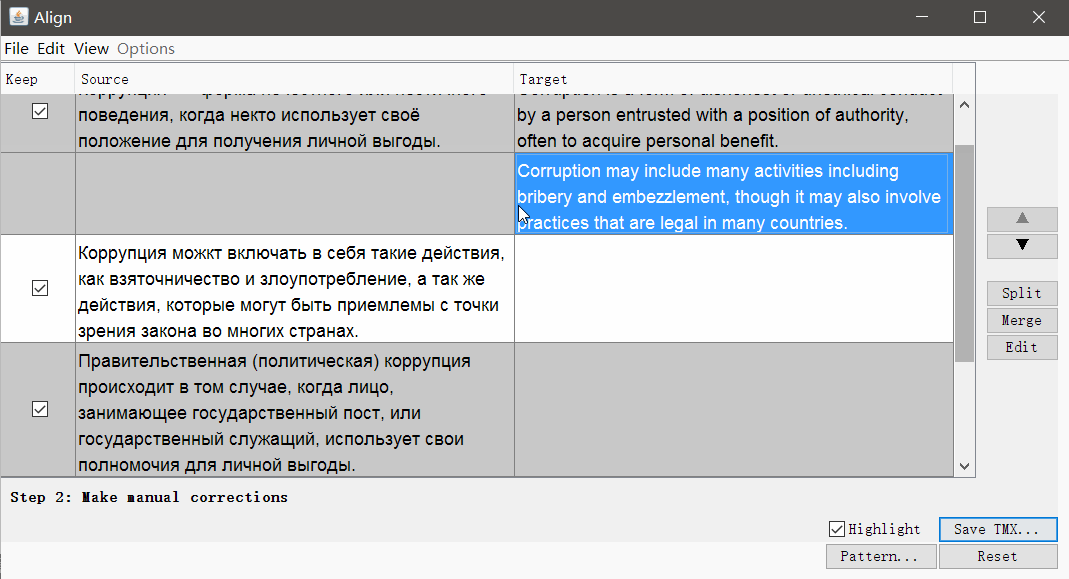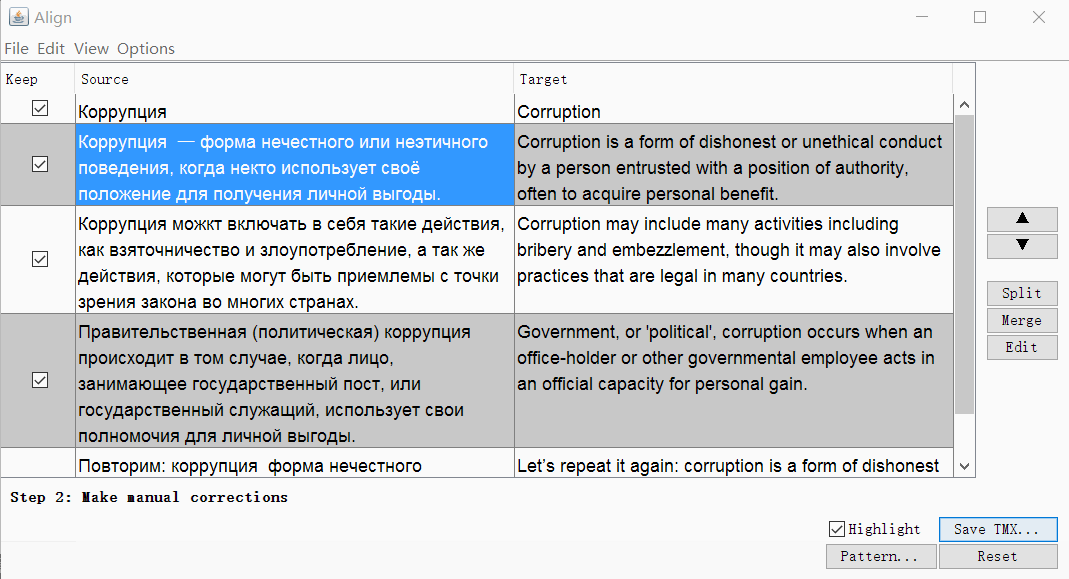 Wenn alles gut aussieht, speichern Sie das Ergebnis mit der Schaltfläche TMX speichern .
Wenn alles gut aussieht, speichern Sie das Ergebnis mit der Schaltfläche TMX speichern .Translatum.gr
Es funktioniert ähnlich wie Olifant . Bei der Eingabe müssen Sie eine Excel- Datei mit zwei Textspalten senden .- Erstellen Sie eine neue Excel-Datei (erforderlich * .xlsx)
- Fügen Sie in der ersten Spalte den Originaltext ein , in der zweiten - Übersetzung.
Verwenden Sie keine Formatierung, sie wird nicht gespeichert - Folgen Sie dem Link des Konverters
- Wählen Sie die erstellte Datei aus
- Geben Sie die Quell- und Zielsprachencodes an.
Wenn Sie beispielsweise englisch-russischen Text haben, sind dies EN-US und RU-RU - Klicken Sie auf Senden
- Es öffnet sich eine Seite, auf der Sie das Archiv mit Translation Memory herunterladen können.
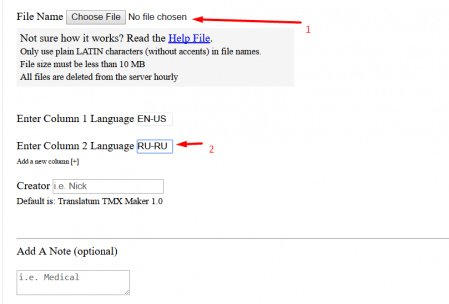 Um den Translation Memory im Projekt zu verwenden, entpacken Sie das Archiv und legen Sie die Datei im Projektordner, Unterverzeichnis \ tm \ (um Fuzzy-Übereinstimmungen anzuzeigen) oder \ tm \ auto \ (um 100% Übereinstimmungen zu erzwingen) ab.Achtung!Es gibt einen ziemlich unangenehmen Fehler beim Erstellen des Translation Memory, bei dem Sonderzeichen wie ">", "<" und sogar Apostrophe verwendet werden. TMX ist eine XML- Struktur , daher werden die in der Dokumentstruktur verwendeten Sonderzeichen in „sichere“ Textblöcke konvertiert. Zum Beispiel wird aus dem Apostroph '& pos; (kaufmännisches Und, Pos und Semikolon).In einigen Situationen kann dies den Translation Memory stark beschädigen. In Wahrheit habe ich noch keine Lösung für dieses Problem gefunden.
Um den Translation Memory im Projekt zu verwenden, entpacken Sie das Archiv und legen Sie die Datei im Projektordner, Unterverzeichnis \ tm \ (um Fuzzy-Übereinstimmungen anzuzeigen) oder \ tm \ auto \ (um 100% Übereinstimmungen zu erzwingen) ab.Achtung!Es gibt einen ziemlich unangenehmen Fehler beim Erstellen des Translation Memory, bei dem Sonderzeichen wie ">", "<" und sogar Apostrophe verwendet werden. TMX ist eine XML- Struktur , daher werden die in der Dokumentstruktur verwendeten Sonderzeichen in „sichere“ Textblöcke konvertiert. Zum Beispiel wird aus dem Apostroph '& pos; (kaufmännisches Und, Pos und Semikolon).In einigen Situationen kann dies den Translation Memory stark beschädigen. In Wahrheit habe ich noch keine Lösung für dieses Problem gefunden.So berechnen Sie das Projektvolumen
Wir müssen den Kunden mitteilen, wie viel Sie für den Transfer benötigen!In der Tat gibt es nichts einfacher. Öffnen Sie das Projekt in OmegaT und gehen Sie zu Extras → Statistik .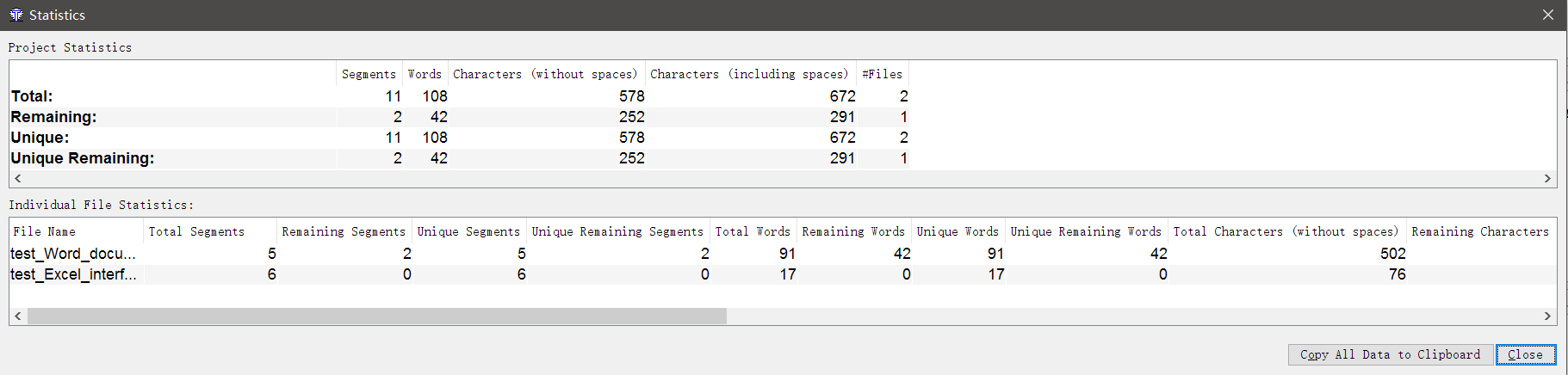 Hier finden Sie umfassende Informationen darüber, wie viele Wörter und Zeichen in den Dateien enthalten sind, wie viele Wiederholungen hier vorhanden sind, wie viele bereits übersetzt wurden und wie viel noch übersetzt werden muss usw.Leider gibt es in OmegaT keinen Taschenrechner für die Übersetzungskosten. Sie müssen alles selbst berechnen.
Hier finden Sie umfassende Informationen darüber, wie viele Wörter und Zeichen in den Dateien enthalten sind, wie viele Wiederholungen hier vorhanden sind, wie viele bereits übersetzt wurden und wie viel noch übersetzt werden muss usw.Leider gibt es in OmegaT keinen Taschenrechner für die Übersetzungskosten. Sie müssen alles selbst berechnen.Wie werden Segmente zusammengeführt und aufgeteilt?
Es kommt vor, dass Sie zwei Segmente zu einem kombinieren möchten oder umgekehrt, um ein bestimmtes Segment in zwei Teile zu teilen. Wenn das Problem bei einer großen Anzahl von Segmenten im Projekt auftritt, lohnt es sich, die Segmentierungsregeln neu zu konfigurieren. Wenn Sie Segmente punktweise zusammenführen oder teilen müssen, verwenden Sie das spezielle Skript Zusammenführen oder Segmente teilen:- Installieren Sie das Skript.
Laden Sie es hier herunter und entpacken Sie es in den Ordner \ scripts (unter Windows kann es C: \ Programme (x86) \ OmegaT \ scripts \ sein.) - Machen Sie die Segmentierungsregeln Projektspezifisch
Projekt → Eigenschaften → Segmentierung → Aktivieren Sie das Kontrollkästchen Segmentierungsregeln projektspezifisch machen - Geben Sie dem Skript eine Schaltfläche
Extras → Skripterstellung. Suchen Sie im linken Teil des Fensters Zusammenführen oder Segmente teilen, wählen Sie es mit einem Mausklick aus und klicken Sie dann mit der rechten Maustaste auf eine der Zahlen am unteren Rand des Fensters. Zum Beispiel pro Einheit. Und klicken Sie auf Skript hinzufügen.
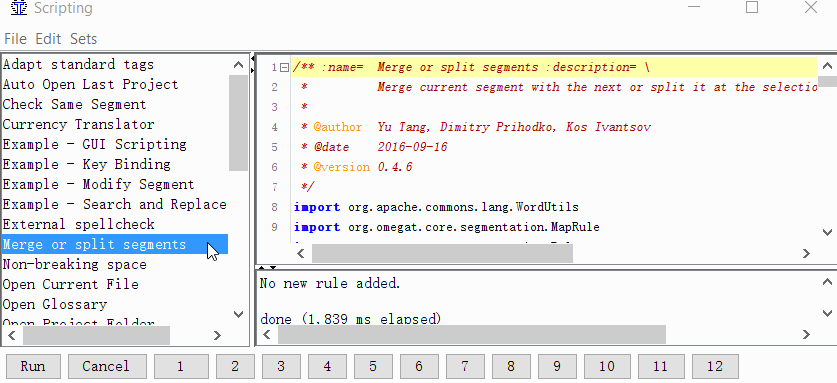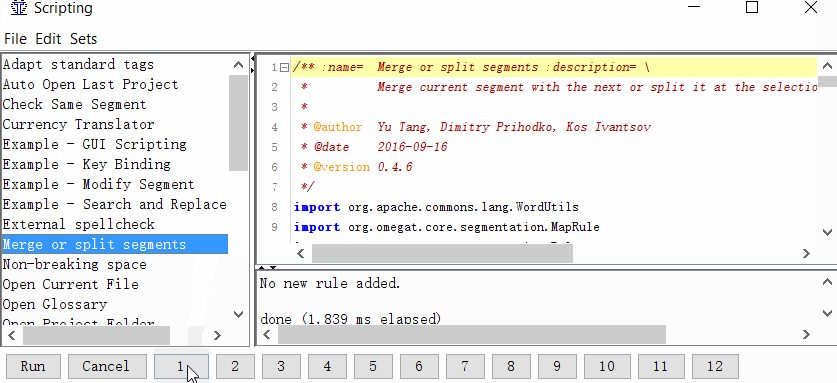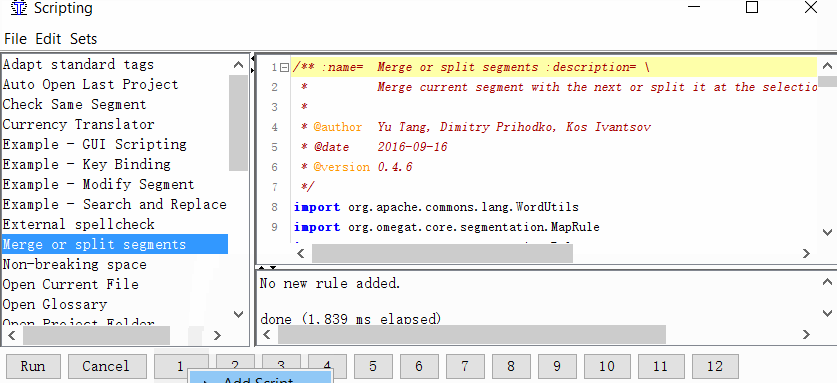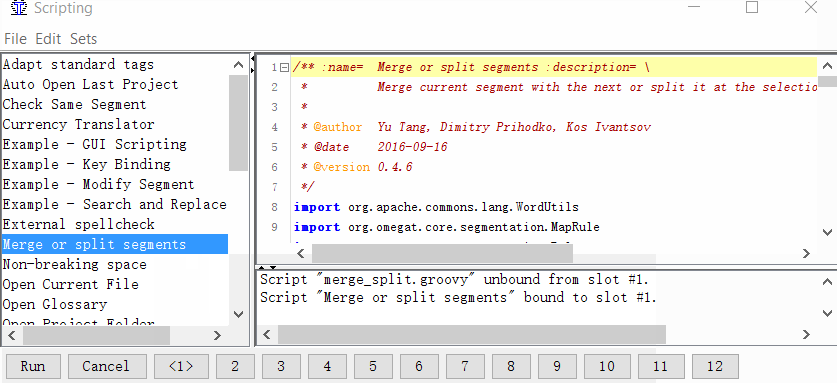 Jetzt können Sie Segmente zusammenführen oder teilen.
Jetzt können Sie Segmente zusammenführen oder teilen.Vereinigung
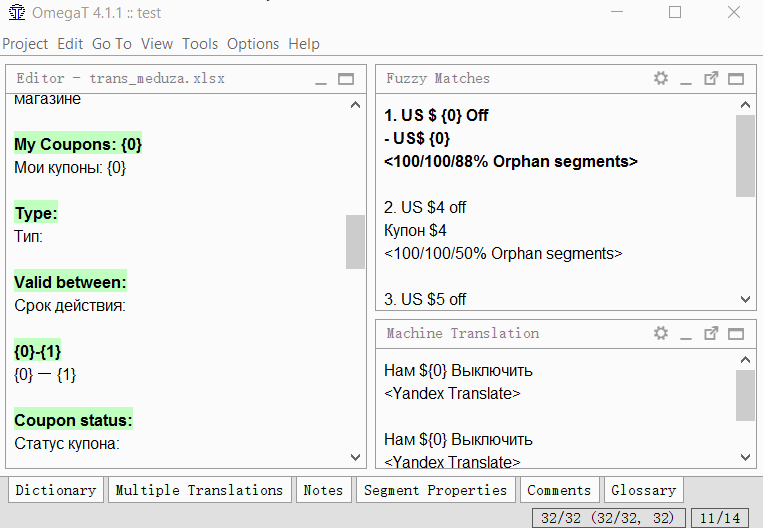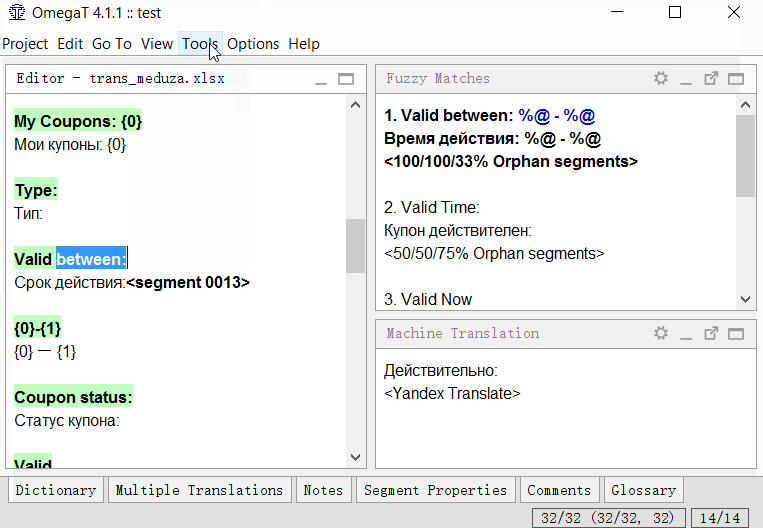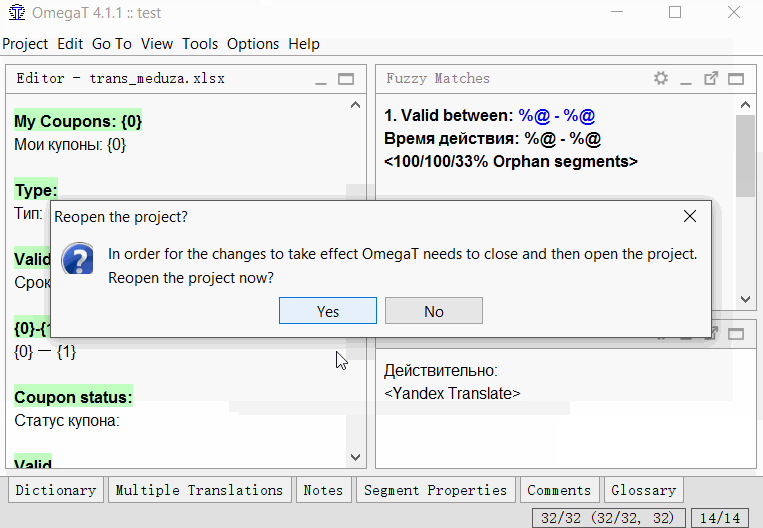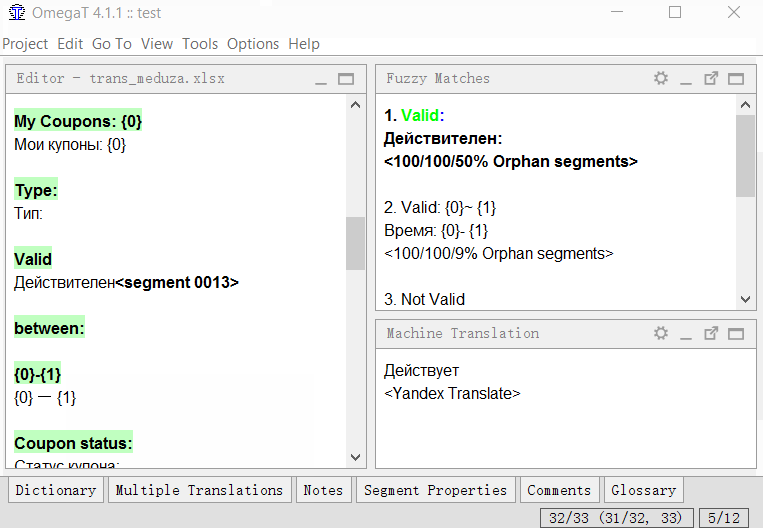
- Suchen Sie die beiden Segmente, die Sie kombinieren möchten.
- Gehe zum ersten Segment.
- Klicken Sie auf Extras → 1. Segmente zusammenführen oder teilen
Das Programm zeigt eine Warnung mit dem Ergebnis der Zusammenführung an. Sie können zum Zusammenführen auf OK klicken oder die Aktion abbrechen.Trennung
- Suchen Sie das Segment, das Sie teilen möchten.
- Wählen Sie im Quelltext des Segments (über der Übersetzung) die zweite Hälfte des Textes (von der Mitte bis zum Ende) aus, für die Sie separate Segmente erstellen möchten.
- Klicken Sie auf Extras → 1. Segmente zusammenführen oder teilen
 Das Programm zeigt eine Warnung mit dem geteilten Ergebnis an. Sie können auf OK klicken, um zu teilen, oder die Aktion abbrechen.Das Skript erstellt eine neue Segmentierungsregel und wendet sie auf das Projekt an. Das Skript ist weit vom Ideal entfernt und funktioniert nicht immer, aber bisher ist es in OmegaT die einzige Möglichkeit, Segmente punktweise zu segmentieren / zusammenzuführen.
Das Programm zeigt eine Warnung mit dem geteilten Ergebnis an. Sie können auf OK klicken, um zu teilen, oder die Aktion abbrechen.Das Skript erstellt eine neue Segmentierungsregel und wendet sie auf das Projekt an. Das Skript ist weit vom Ideal entfernt und funktioniert nicht immer, aber bisher ist es in OmegaT die einzige Möglichkeit, Segmente punktweise zu segmentieren / zusammenzuführen.Anstelle einer Schlussfolgerung
Ich habe die beiden Notizen aus meiner gemütlichen Broschüre zu einem riesigen Blatt über OmegaT zusammengefasst. Ich habe versucht, alle Hauptfunktionen zu enthüllen, die ich regelmäßig benutze. Stellen Sie sicher, dass Sie in den Kommentaren schreiben, warum der Artikel dumm ist und zu welchem Hub er wirklich gehört.Professionelle Übersetzer sollten meine englisch-russische Übersetzung kritisieren und an einer Umfrage zu normalen CAT-Programmen teilnehmen.PS: Weiß jemand, warum die GT-Engine HTML-Links auf der Seite nicht versteht?