 Wir im Wirex Blockchain-Zahlungsservice- Team sind mit der Erfahrung vertraut, dass die vorhandene technologische Lösung ständig weiterentwickelt und verbessert werden muss. Der Autor des folgenden Materials spricht über die Geschichte der Entwicklung der Codebereitstellung der berühmten Social-News-Plattform Reddit.
Wir im Wirex Blockchain-Zahlungsservice- Team sind mit der Erfahrung vertraut, dass die vorhandene technologische Lösung ständig weiterentwickelt und verbessert werden muss. Der Autor des folgenden Materials spricht über die Geschichte der Entwicklung der Codebereitstellung der berühmten Social-News-Plattform Reddit."Es ist wichtig, der Richtung Ihrer Entwicklung zu folgen, um sie rechtzeitig in eine gute Richtung senden zu können."
Das Reddit-Team stellt ständig Code bereit. Alle Mitglieder des Entwicklungsteams schreiben regelmäßig Code, der vom Autor selbst überprüft und von außen getestet wird, damit er dann zur "Produktion" gehen kann. Jede Woche führen wir mindestens 200 „Bereitstellungen“ durch, von denen jede normalerweise weniger als 10 Minuten dauert.
Das System, das all dies bietet, hat sich im Laufe der Jahre weiterentwickelt. Mal sehen, was sich die ganze Zeit daran geändert hat und was unverändert geblieben ist.
Beginn der Geschichte: stabile und wiederkehrende Bereitstellungen (2007-2010)
Das gesamte System, das wir heute haben, ist aus einem Samen gewachsen - einem Perl-Skript namens Push. Es wurde vor langer Zeit geschrieben, zu sehr unterschiedlichen Zeiten für Reddit. Unser gesamtes technisches Team war zu dieser Zeit so klein, dass es leise
in einen kleinen „Besprechungsraum“ passte . Wir haben AWS damals nicht verwendet. Die Site arbeitete auf einer begrenzten Anzahl von Servern, und jede zusätzliche Kapazität musste manuell hinzugefügt werden. Alles funktionierte auf einer großen, monolithischen Python-Anwendung namens r2.
Eines ist im Laufe der Jahre unverändert geblieben. Anforderungen wurden im Load Balancer klassifiziert und auf die "Pools" verteilt, die mehr oder weniger identische Anwendungsserver enthielten. Beispielsweise werden
Themen- und
Kommentarlistenseiten von verschiedenen Serverpools verarbeitet. Tatsächlich kann jeder r2-Prozess jede Art von Anforderung verarbeiten. Durch die Aufteilung in Pools können Sie jedoch jeden von ihnen vor plötzlichen Verkehrssprüngen in benachbarten Pools schützen. Im Falle eines Verkehrswachstums bedroht ein Ausfall nicht das gesamte System, sondern die einzelnen Pools.
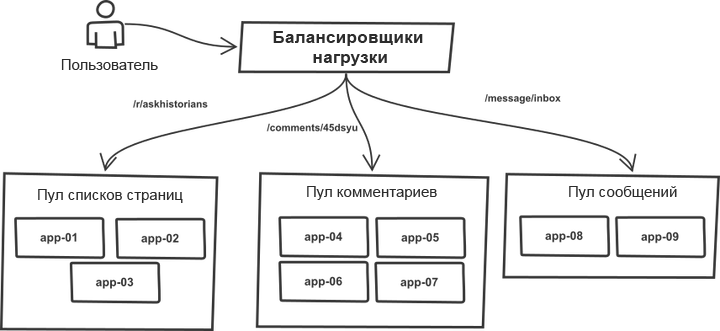
Die Liste der Zielserver wurde manuell in den Push-Tool-Code geschrieben, und der Bereitstellungsprozess arbeitete mit einem monolithischen System. Das Tool durchlief die Liste der Server, war über SSH angemeldet, führte eine der vordefinierten Befehlssequenzen aus, mit denen die aktuelle Kopie des Codes mit git aktualisiert wurde, und startete alle Anwendungsprozesse neu. Das Wesentliche des Prozesses (der Code ist für ein allgemeines Verständnis stark vereinfacht):
# `make -C /home/reddit/reddit static` `rsync /home/reddit/reddit/static public:/var/www/` # app- # , foreach $h (@hostlist) { `git push $h:/home/reddit/reddit master` `ssh $h make -C /home/reddit/reddit` `ssh $h /bin/restart-reddit.sh` }
Die Bereitstellung erfolgte nacheinander, ein Server nach dem anderen. Bei aller Einfachheit hatte das Programm ein wichtiges Plus: Es ist dem „
kanarischen Einsatz “ sehr ähnlich. Durch die Bereitstellung des Codes auf mehreren Servern und das Erkennen von Fehlern haben Sie sofort festgestellt, dass Fehler aufgetreten sind. Sie können den Prozess unterbrechen (Strg-C) und einen Rollback durchführen, bevor Probleme mit allen Anforderungen gleichzeitig auftreten. Die einfache Bereitstellung machte es einfach und ohne schwerwiegende Konsequenzen, Dinge in der Produktion zu überprüfen und zurückzusetzen, wenn sie nicht funktionierten. Darüber hinaus war es praktisch zu bestimmen, welche bestimmte Bereitstellung Fehler verursachte, wo genau und was zurückgesetzt werden muss.
Ein solcher Mechanismus hat gute Arbeit geleistet, um Stabilität und Kontrolle während des Einsatzes zu gewährleisten. Das Tool hat ziemlich schnell funktioniert. Die Dinge liefen gut.
Unser Regiment ist angekommen (2011)
Dann stellten wir mehr Leute ein, jetzt gab es sechs Entwickler, und unser neuer
„Besprechungsraum“ wurde geräumiger . Wir stellten fest, dass der Code-Bereitstellungsprozess jetzt mehr Koordination erfordert, insbesondere wenn Kollegen von zu Hause aus arbeiten. Das Push-Dienstprogramm wurde aktualisiert: Jetzt wurde der Beginn und das Ende von Bereitstellungen mithilfe des IRC-Chatbots angekündigt, der sich einfach im IRC befand und Ereignisse ankündigte. Die Prozesse, die während der Bereitstellung ausgeführt wurden, wurden fast nicht geändert, aber jetzt hat das System alles für den Entwickler getan und alle anderen über die vorgenommenen Änderungen informiert.
Von diesem Moment an begann die Verwendung von Chat im Bereitstellungsworkflow. Die Diskussion über die Verwaltung der Bereitstellung aus Chats war zu dieser Zeit sehr beliebt. Da wir jedoch IRC-Server von Drittanbietern verwendeten, konnten wir dem Chat bei der Verwaltung der Produktionsumgebung nicht hundertprozentig vertrauen, und daher blieb der Prozess auf der Ebene eines einseitigen Informationsflusses.
Mit dem wachsenden Datenverkehr auf der Website wuchs auch die Infrastruktur, die diese unterstützte. Von Zeit zu Zeit mussten wir eine neue Gruppe von Anwendungsservern starten und in Betrieb nehmen. Der Prozess war noch nicht automatisiert. Insbesondere musste die Hostliste in Push noch manuell aktualisiert werden.
Die Leistung der Pools wurde normalerweise durch Hinzufügen mehrerer Server gleichzeitig erhöht. Infolgedessen gelang es Push, nacheinander durch die Liste zu laufen, Änderungen auf eine ganze Gruppe von Servern im selben Pool zu übertragen, ohne die anderen zu beeinflussen, dh es gab keine Diversifizierung nach Pools.

UWSGI wurde zur Steuerung von Arbeitsprozessen verwendet. Als wir der Anwendung einen Neustartbefehl erteilten, wurden alle vorhandenen Prozesse gleichzeitig beendet und durch neue ersetzt. Es dauerte einige Zeit, bis neue Prozesse für die Bearbeitung von Anforderungen vorbereitet waren. Im Falle eines unbeabsichtigten Neustarts einer Gruppe von Servern im selben Pool hat die Kombination dieser beiden Umstände die Fähigkeit dieses Pools, Anforderungen zu bedienen, ernsthaft beeinträchtigt. Daher ist die Geschwindigkeit der sicheren Bereitstellung von Code auf allen Servern begrenzt. Mit der Anzahl der Server stieg auch die Dauer des gesamten Vorgangs.
Bereitstellung von Recycling-Instrumenten (2012)
Wir haben das Bereitstellungstool gründlich überarbeitet. Und obwohl sein Name trotz einer vollständigen Änderung derselbe blieb (Push), wurde er diesmal in Python geschrieben. Die neue Version hat einige wesentliche Verbesserungen erfahren.
Zunächst nahm er die Liste der Hosts von DNS und nicht von der Sequenz, die im Code fest codiert war. Dadurch konnte nur die Liste aktualisiert werden, ohne dass der Push-Code aktualisiert werden musste. Die Anfänge eines Service Discovery Systems sind entstanden.
Um das Problem der aufeinanderfolgenden Neustarts zu lösen, haben wir die Liste der Hosts vor der Bereitstellung gemischt. Das Mischen reduzierte die Risiken und ermöglichte es, den Prozess zu beschleunigen.

In der Originalversion wurde die Liste jedes Mal nach dem Zufallsprinzip gemischt. Dies machte es jedoch schwierig, schnell einen Rollback durchzuführen, da die Liste der ersten Servergruppe jedes Mal anders war. Daher haben wir das Mischen korrigiert: Es wurde nun eine bestimmte Reihenfolge generiert, die während der wiederholten Bereitstellung nach dem Rollback verwendet werden konnte.
Eine weitere kleine, aber wichtige Änderung war die ständige Bereitstellung einer festen Version des Codes. In der vorherigen Version des Tools wurde der Master-Zweig auf dem Zielhost immer aktualisiert. Was passiert jedoch, wenn sich der Master direkt während der Bereitstellung ändert, weil jemand den Code versehentlich gestartet hat? Durch die Bereitstellung einer bestimmten Git-Revision anstelle des Aufrufs nach Zweigstellennamen konnte sichergestellt werden, dass auf jedem Produktionsserver dieselbe Codeversion verwendet wurde.
Und schließlich unterschied das neue Tool seinen Code (es arbeitete hauptsächlich mit einer Liste von Hosts und griff über SSH darauf zu) und die auf den Servern ausgeführten Befehle. Es hing immer noch sehr stark von den Anforderungen von r2 ab, hatte aber so etwas wie einen API-Prototyp. Dies ermöglichte es r2, seine eigenen Bereitstellungsschritte zu befolgen, was das Rollen von Änderungen vereinfachte und den Fluss freisetzte. Das folgende Beispiel zeigt Befehle, die auf einem separaten Server ausgeführt werden. Der Code ist wiederum nicht der genaue Code, aber insgesamt beschreibt diese Sequenz den r2-Workflow gut:
sudo /opt/reddit/deploy.py fetch reddit sudo /opt/reddit/deploy.py deploy reddit f3bbbd66a6 sudo /opt/reddit/deploy.py fetch-names sudo /opt/reddit/deploy.py restart all
Besonders erwähnenswert sind Abrufnamen: Diese Anweisung gilt nur für r2.
Autoscaling (2013)
Dann haben wir uns endlich entschlossen, zu einer Cloud mit automatischer Skalierung zu wechseln (ein Thema für einen ganzen separaten Beitrag). Auf diese Weise konnten wir in den Momenten, in denen die Website nicht mit Datenverkehr belastet war, eine ganze Menge Geld sparen und automatisch die Kapazität erhöhen, um mit einem starken Anstieg der Anforderungen fertig zu werden.
Frühere Verbesserungen, bei denen die Hostliste automatisch aus DNS geladen wurde, haben diesen Übergang zur Selbstverständlichkeit gemacht. Die Liste der Hosts wurde häufiger als zuvor geändert, aus Sicht des Bereitstellungstools spielte dies jedoch keine Rolle. Die Änderung, die ursprünglich als Qualitätsverbesserung eingeführt wurde, ist zu einer der Schlüsselkomponenten für die automatische Skalierung geworden.
Die automatische Skalierung hat jedoch zu einigen interessanten Grenzfällen geführt. Starts mussten kontrolliert werden. Was passiert, wenn der Server direkt während der Bereitstellung gestartet wird? Wir mussten sicherstellen, dass jeder neue Server, der ausgeführt wurde, die Verfügbarkeit von neuem Code überprüfte und ihn nahm, falls es einen gab. Wir konnten nicht vergessen, dass die Server zum Zeitpunkt der Bereitstellung offline gingen. Das Tool musste intelligenter werden und lernen, festzustellen, ob der Server im Rahmen des Vorgangs offline geschaltet wurde und nicht aufgrund eines Fehlers, der während der Bereitstellung aufgetreten ist. Im letzteren Fall musste er alle an dem Problem beteiligten Kollegen lautstark warnen.
Gleichzeitig haben wir übrigens aus verschiedenen Gründen von uWSGI zu
Gunicorn gewechselt . Aus Sicht des Themas dieses Beitrags führte ein solcher Übergang jedoch zu keinen wesentlichen Änderungen.
Also hat es eine Weile funktioniert.
Zu viele Server (2014)
Im Laufe der Zeit wuchs die Anzahl der Server, die für die Wartung des Spitzenverkehrs benötigt werden. Dies führte dazu, dass Bereitstellungen immer mehr Zeit benötigten. Im schlimmsten Fall dauerte eine normale Bereitstellung etwa eine Stunde - ein schlechtes Ergebnis.
Wir haben das Tool neu geschrieben, damit es die parallele Arbeit mit Hosts unterstützen kann. Die neue Version heißt
Nudelholz . Die alte Version benötigte viel Zeit, um SSH-Verbindungen zu initialisieren und auf den Abschluss aller Befehle zu warten. Durch die Parallelisierung innerhalb angemessener Grenzen konnten wir die Bereitstellung beschleunigen. Die Bereitstellungszeit verringerte sich erneut auf fünf Minuten.

Um die Auswirkungen des gleichzeitigen Neustarts mehrerer Server zu verringern, wurde die Mischkomponente des Tools intelligenter. Anstatt die Liste blind zu mischen, sortierte er die Serverpools so, dass Hosts von einem Pool
so weit wie möglich voneinander entfernt waren.
Die wichtigste Änderung im neuen Tool war, dass die
API zwischen dem Bereitstellungstool und den Tools auf jedem Server viel klarer definiert und von den Anforderungen von r2 getrennt wurde. Ursprünglich geschah dies aus dem Wunsch heraus, den Code Open Source-orientierter zu gestalten, aber bald war dieser Ansatz auf andere Weise sehr nützlich. Das Folgende ist eine Beispielbereitstellung mit der Auswahl von remote gestarteten API-Befehlen:

Zu viele Leute (2015)
Plötzlich kam ein Moment, in dem, wie sich herausstellte, bereits viele Leute an r2 arbeiteten. Es war cool und bedeutete gleichzeitig, dass es noch mehr Bereitstellungen geben würde. Die Einhaltung der Regel eines Einsatzes zu einem Zeitpunkt wurde immer schwieriger. Die Entwickler mussten sich auf das Verfahren zur Ausgabe des Codes einigen. Um die Situation zu optimieren, haben wir dem Chatbot ein weiteres Element hinzugefügt, das die Bereitstellungswarteschlange koordiniert. Ingenieure haben eine Bereitstellungsreserve angefordert und diese entweder erhalten oder ihren Code in die Warteschlange gestellt. Dies trug zur Rationalisierung der Bereitstellungen bei, und diejenigen, die sie abschließen wollten, konnten ruhig warten, bis sie an der Reihe waren.
Eine weitere wichtige Ergänzung im Zuge des Teamwachstums war die Verfolgung von Bereitstellungen an
einem Ort . Wir haben das Bereitstellungstool geändert, um Metriken an Graphite zu senden. Dies machte es einfach, die Korrelation zwischen Bereitstellungen und Metrikänderungen zu verfolgen.
Viele (zwei) Dienste (auch 2015)
Nur plötzlich kam der Moment der Veröffentlichung des zweiten Online-Dienstes. Es war eine mobile Version der Website mit einem eigenen, völlig anderen Stack, eigenen Servern und dem Build-Prozess. Dies war der erste echte Test einer API für ein Split-Deployment-Tool. Durch die Möglichkeit, alle Montagestufen an verschiedenen "Standorten" für jedes Projekt zu erarbeiten, konnte er der Last standhalten und die Wartung von zwei Diensten innerhalb desselben Systems bewältigen.
25 Dienstleistungen (2016)
Im nächsten Jahr haben wir die schnelle Erweiterung des Teams miterlebt. Anstelle von zwei Diensten erschienen zwei Dutzend anstelle von zwei Entwicklungsteams fünfzehn. Die meisten Dienste wurden entweder auf
Baseplate , unserem Backend-Framework, oder auf Clientanwendungen, ähnlich dem mobilen Web, erstellt. Die Infrastruktur hinter den Bereitstellungen ist für alle gleich. Bald werden viele andere neue Dienste online veröffentlicht, und all dies ist hauptsächlich auf die Vielseitigkeit des Nudelholzes zurückzuführen. Sie können den Start neuer Dienste mithilfe von Tools vereinfachen, die den Benutzern vertraut sind.
Airbag (2017)
Mit zunehmender Anzahl von Servern im Monolithen nahm die Bereitstellungszeit zu. Wir wollten die Anzahl der parallelen Bereitstellungen erheblich erhöhen, dies würde jedoch zu vielen gleichzeitigen Neustarts der Anwendungsserver führen. Solche Dinge führen natürlich zu einem Rückgang des Durchsatzes und einem Verlust der Fähigkeit, eingehende Anforderungen zu bearbeiten, da die verbleibenden Server überlastet sind.
Der Hauptprozess von Gunicorn verwendete dasselbe Modell wie uWSGI und lud alle Arbeiter gleichzeitig neu. Neue Worker-Prozesse konnten Anforderungen erst bearbeiten, wenn sie vollständig geladen waren. Die Startzeit unseres Monolithen lag zwischen 10 und 30 Sekunden. Dies bedeutete, dass wir in diesem Zeitraum Anfragen überhaupt nicht bearbeiten konnten. Um einen Ausweg aus dieser Situation zu finden, haben wir den Hauptprozess für das Gunicorn durch den
Einhorn- Arbeitsmanager von Stripe ersetzt
und dabei den Gunicorn-HTTP-Stack und den WSGI-Container beibehalten . Während des Neustarts erstellt Einhorn einen neuen Worker, wartet, bis er fertig ist, entfernt einen alten Worker und wiederholt den Vorgang, bis das Update abgeschlossen ist. Dies erzeugt einen Airbag und ermöglicht es uns, die Bandbreite während der Auslösung auf einem Niveau zu halten.
Das neue Modell verursachte ein weiteres Problem. Wie bereits erwähnt, dauerte das Ersetzen eines Arbeiters durch einen neuen und vollständig fertigen bis zu 30 Sekunden. Dies bedeutete, dass ein Fehler im Code nicht sofort angezeigt wurde und auf vielen Servern bereitgestellt werden konnte, bevor er erkannt wurde. Um dies zu verhindern, haben wir einen Mechanismus zum Blockieren des Übergangs des Bereitstellungsverfahrens zum neuen Server eingeführt, der bis zum Neustart aller Arbeitsprozesse wirksam war. Es wurde einfach umgesetzt - indem der Staat Einhorn abgefragt und auf die Bereitschaft aller neuen Arbeiter gewartet wurde. Um die Geschwindigkeit auf dem gleichen Niveau zu halten, haben wir die Anzahl der parallel verarbeiteten Server erhöht, was unter den neuen Bedingungen völlig sicher war.
Ein solcher Mechanismus ermöglicht die gleichzeitige Bereitstellung auf einer viel größeren Anzahl von Computern, und die Bereitstellungszeit, die ungefähr 800 Server umfasst, wird auf 7 Minuten reduziert, wobei zusätzliche Pausen für die Überprüfung auf Fehler berücksichtigt werden.
Rückblick
Die hier beschriebene Bereitstellungsinfrastruktur ist ein Produkt, das aus langjährigen konsequenten Verbesserungen und nicht aus einer einmaligen, gezielten Anstrengung entstanden ist. Die Echos der einmal getroffenen und in den frühen Phasen von Kompromissen getroffenen Entscheidungen machen sich im gegenwärtigen System immer noch bemerkbar, und dies war in allen Phasen immer der Fall. Ein solcher evolutionärer Ansatz hat seine Vor- und Nachteile: Er erfordert in jedem Stadium ein Minimum an Aufwand, es besteht jedoch das Risiko, dass er früher oder später zum Stillstand kommt. Es ist wichtig, der Richtung Ihrer Entwicklung zu folgen, um sie rechtzeitig in eine gute Richtung senden zu können.
Die Zukunft
Die Reddit-Infrastruktur sollte für die kontinuierliche Unterstützung des Teams bereit sein, wenn es wächst und neue Dinge auf den Markt bringt. Die Wachstumsrate des Unternehmens ist schneller als je zuvor und wir arbeiten an noch interessanteren und umfangreicheren Projekten als alles, was wir zuvor getan haben. Die Probleme, mit denen wir heute konfrontiert sind, haben zwei Gründe: Einerseits muss die Autonomie der Entwickler erhöht werden, andererseits muss die Sicherheit der Produktionsinfrastruktur aufrechterhalten und der Airbag verbessert werden, wodurch Entwickler schnell und sicher Bereitstellungen durchführen können.
