 „Ein Wissenschaftler kann einen neuen Stern entdecken, aber nicht erschaffen. Dazu müsste er sich an einen Ingenieur wenden. “ Gordon Lindsay Glass, Design Design (1969)
„Ein Wissenschaftler kann einen neuen Stern entdecken, aber nicht erschaffen. Dazu müsste er sich an einen Ingenieur wenden. “ Gordon Lindsay Glass, Design Design (1969)Vor einigen Monaten schrieb ich über die Unterschiede zwischen Experten für Theorie und Methoden der Datenanalyse (Datenwissenschaftler) und Spezialisten für Datenverarbeitung (Dateningenieur). Ich sprach über ihre Fähigkeiten und gemeinsamen Ausgangspunkte. Es passierte etwas Interessantes: Datenwissenschaftler machten Fortschritte und behaupteten, sie seien auf dem Gebiet der Datenentwicklung tatsächlich genauso kompetent wie Datenverarbeitungsspezialisten. Dies war interessant, da die Datenverarbeitungsexperten keine Einwände erhoben und nicht sagten, sie seien Spezialisten für die Theorie der Datenanalyse.
Daher habe ich in den letzten Monaten Informationen gesammelt und das Verhalten von Spezialisten in der Theorie der Datenanalyse in ihrem natürlichen Arbeitsumfeld überwacht. In diesem Beitrag werde ich mehr darüber sprechen, warum ein Datenwissenschaftler kein Dateningenieur ist.
Warum ist das überhaupt wichtig?
Einige beklagen, dass der Unterschied zwischen einem Spezialisten für Datenanalysetheorie und einem Spezialisten für Datenverarbeitung nur im Namen liegt. "
Namen sollten die Menschen nicht davon abhalten, etwas Neues zu lernen oder zu tun ", sagen sie. Ich stimme zu, Sie müssen so viel wie möglich lernen. Beachten Sie jedoch, dass sich Ihr Training nur aus der Ferne auf das beziehen kann, was in der Praxis getan werden muss. Andernfalls kann dies zum Scheitern von Projekten mit Big Data führen.
Viel hängt auch von der Führungsebene in Unternehmen ab. Das Management stellt Spezialisten für Datenanalysetheorie ein und erwartet, dass sie Spezialisten für Datenverarbeitung sind.
Ich habe die gleiche Geschichte in verschiedenen Unternehmen gehört: Ein Unternehmen entscheidet, dass Data Science ein Weg ist, um Geld für Investoren, jede Menge Gewinne, Glaubwürdigkeit in der Geschäftswelt usw. zu erlangen. Diese Entscheidung wird auf der Ebene der Geschäftsleitung getroffen. Lassen Sie zum Beispiel eine bestimmte Alice zu solchen Top-Managern gehören. Nach langer Suche findet das Unternehmen den weltweit besten Spezialisten für die Theorie der Datenanalyse - nennen wir ihn Bob.
Der erste Arbeitstag von Bob kam. Alice kommt auf ihn zu und spricht eifrig über all ihre Pläne.
„Großartig. Wo sind die Datenpipelines und Ihr Spark-Cluster? “, Fragt Bob.
Alice antwortet: „Das erwarten wir von dir. Wir haben Sie mit der Datenanalyse beauftragt. “
"Ich weiß nicht, wie das geht", sagt Bob.
Alice sieht überrascht aus: „Aber Sie sind Spezialist für Datenverarbeitungstheorie. Richtig? Das machst du. “
"Nein, ich verwende bereits erstellte Pipelines und Daten."
Alice kehrt in ihr Büro zurück, um herauszufinden, was passiert ist. Sie betrachtet vereinfachte Diagramme wie das in Abbildung 1 gezeigte und kann nicht verstehen, warum Bob einfache Aufgaben mit Big Data nicht ausführen kann.
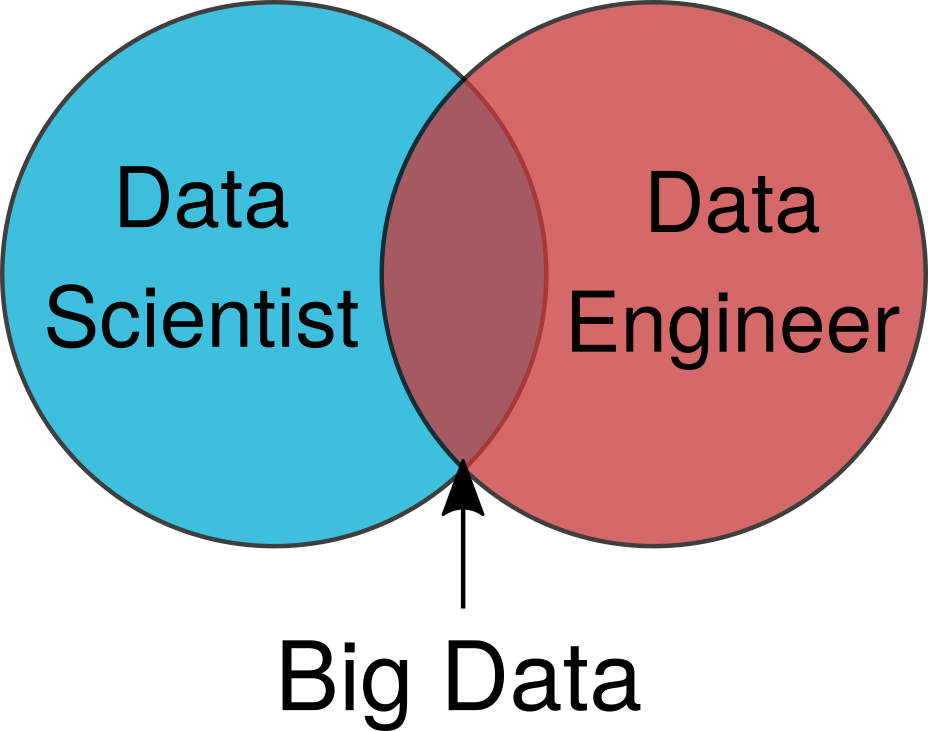 Abbildung 1. Ein vereinfachtes Venn-Diagramm mit einem Spezialisten für Datenanalysetheorie und einem Spezialisten für Datenverarbeitung.
Abbildung 1. Ein vereinfachtes Venn-Diagramm mit einem Spezialisten für Datenanalysetheorie und einem Spezialisten für Datenverarbeitung.Scheinwerfer
Aus diesen Wechselwirkungen ergeben sich zwei Probleme:
- Warum versteht das Management nicht, dass ein Spezialist für Datenanalysetheorie kein Spezialist für Datenverarbeitung ist?
- Warum glauben einige Analysetheoretiker, Verarbeitungsspezialisten zu sein?
Ich werde von der Führungsseite ausgehen. Später werden wir über die Spezialisten für Datenanalysetheorie selbst sprechen.
Seien wir ehrlich: Die Datenverarbeitung steht nicht im Rampenlicht. Sie wird nicht zum besten Werk des 21. Jahrhunderts erklärt. Über sie wird in den Medien nicht oft geschrieben. Auf Konferenzen werden die ersten Personen des Unternehmens nicht über die Vorteile der Datenverarbeitung informiert. Alle Nachrichten beziehen sich auf die Datenanalyse und die Suche nach Spezialisten für Theorie und Methoden der Datenanalyse.
Aber die Dinge beginnen sich zu ändern. Wir haben Konferenzen zur Datenverarbeitung. Die Notwendigkeit der Entwicklung technischer Datenverarbeitungswerkzeuge wird schrittweise erkannt. Ich hoffe, dass meine Arbeit Organisationen dabei helfen wird, diesen dringenden Bedarf zu erkennen.
Anerkennung und Wertschätzung
Selbst in Fällen, in denen Unternehmen Teams von Datenverarbeitungsspezialisten haben, wird ihre Arbeit häufig immer noch nicht angemessen bewertet.
Bei Konferenzen ist ein Mangel an Anerkennung festzustellen. Ein Spezialist in der Theorie der Datenanalyse sagt, dass er erstellt hat. Ich sehe eine umfassende Datenverarbeitungstechnologie, die die Grundlage seines Modells bildete, die jedoch während eines Gesprächs nie erwähnt wird. Ich erwarte nicht, dass es im Detail untersucht wird, aber es wäre schön, die geleistete Arbeit zur Kenntnis zu nehmen, damit die Erstellung seines Modells möglich wird. Management und Anfänger auf dem Gebiet der Datenanalyse glauben, dass mit den Fähigkeiten eines Spezialisten für Datenanalysetheorie alles möglich ist.
Wie man Anerkennung erreicht
Vor kurzem haben mich Datenverarbeitungsexperten gefragt, wie ich in ihren Unternehmen ins Rampenlicht rücken kann. Sie haben das Gefühl, dass Experten der Analysetheorie, wenn sie ihre neuesten Entwicklungen zeigen, die volle Wertschätzung des Managements erhalten. Die Hauptfrage, die Ingenieure mir stellen, lautet: „Wie kann ich einen Datenwissenschaftler dazu bringen, unsere gemeinsame Arbeit nicht mehr als mein Verdienst zu betrachten?“
Dies ist eine fundierte Frage, die auf den Situationen basiert, die ich in Unternehmen sehe. Das Management erkennt (und offenbart) keine Datenverarbeitungsarbeiten, die sich auf alles beziehen, was mit Datenanalyse zu tun hat. Wenn Sie dies lesen und denken:
- Meine Spezialisten für Datenanalysetheorie sind Spezialisten für Datenverarbeitung.
- Meine Experten für Datenanalysetheorie erstellen wirklich komplexe Datenpipelines.
- Der Autor darf nicht wissen, wovon er spricht.
... dann haben Sie wahrscheinlich einen Datenverarbeitungsspezialisten, der nicht im Rampenlicht steht.
Da Spezialisten für Datenanalysetheorie in Abwesenheit von Ingenieuren kündigen, wird ein Ingenieur, der keine ausreichende Anerkennung seiner Arbeit erhält, kündigen. Lass dich nicht täuschen; Für qualifizierte Datenverarbeitungsspezialisten ist der Arbeitsmarkt genauso heiß wie für Spezialisten für Datenanalysetheorie.
Datenanalyse ist nur mit Unterstützung unserer Freunde möglich
Sie haben wahrscheinlich den
Mythos von Atlanta gehört . Zur Strafe war er gezwungen, die Welt / den Himmel / die Himmelssphäre für sich zu behalten. Die Erde existiert in ihrer gegenwärtigen Form nur, weil Atlas sie hält.
Ebenso unterstützen Datenwissenschaftler die Welt der Datenanalyse. Ein Mensch, der die ganze Welt auf seinen Schultern hält, erhält nicht so viel Wertschätzung, obwohl er sollte. Auf allen Ebenen der Organisation sollte klar sein, dass eine Datenanalyse nur dank der Arbeit einer Gruppe von Datenverarbeitungsspezialisten möglich ist.
 Abb. 2. Sogar Italiener im 14. Jahrhundert wussten um die Bedeutung von Datenverarbeitungsspezialisten.
Abb. 2. Sogar Italiener im 14. Jahrhundert wussten um die Bedeutung von Datenverarbeitungsspezialisten.Datenwissenschaftler sind keine Dateningenieure.
Dies bringt uns zu dem Grund, warum die Datenanalysetheorie sie für Datenverarbeitungsspezialisten hält.
Bevor wir fortfahren, einige Vorbehalte, um Kommentare zu warnen:
- Ich weiß, dass Experten für Datenanalysetheorie wirklich sehr klug sind, und ich arbeite gerne mit ihnen.
- Ich frage mich, ob ein solcher Intellekt einen stärkeren Mahn-Krüger-IQ-Effekt verursacht.
- Einige der besten Experten für Datenanalysetheorie, die ich kannte, waren Datenverarbeitungsexperten, aber es gab nur sehr wenige.
- Wir überprüfen ständig unsere eigenen Fähigkeiten.
 Abb. 3. Ein empirisches Diagramm der Wahrnehmung ihrer Fähigkeiten durch Spezialisten der Analysetheorie im Vergleich zu ihren tatsächlichen Fähigkeiten.
Abb. 3. Ein empirisches Diagramm der Wahrnehmung ihrer Fähigkeiten durch Spezialisten der Analysetheorie im Vergleich zu ihren tatsächlichen Fähigkeiten.Als ich ihre Datenverarbeitungsfähigkeiten mit Experten der Datenanalysetheorie besprach, stellte ich fest, dass ihr Selbstwertgefühl sehr unterschiedlich ist. Dies ist ein interessantes soziales Experiment mit Vorurteilen. Die meisten Experten für Datenanalysetheorie haben ihre eigenen Datenverarbeitungsfähigkeiten überschätzt. Einige gaben eine genaue Einschätzung, aber niemand gab eine Bewertung, die niedriger war als ihre tatsächlichen Fähigkeiten.
In diesem Diagramm fehlen zwei Dinge:
- Was ist das Qualifikationsniveau von Datenverarbeitungsprofis?
- Welche Fähigkeiten sind für eine mäßig komplexe Datenpipeline erforderlich?
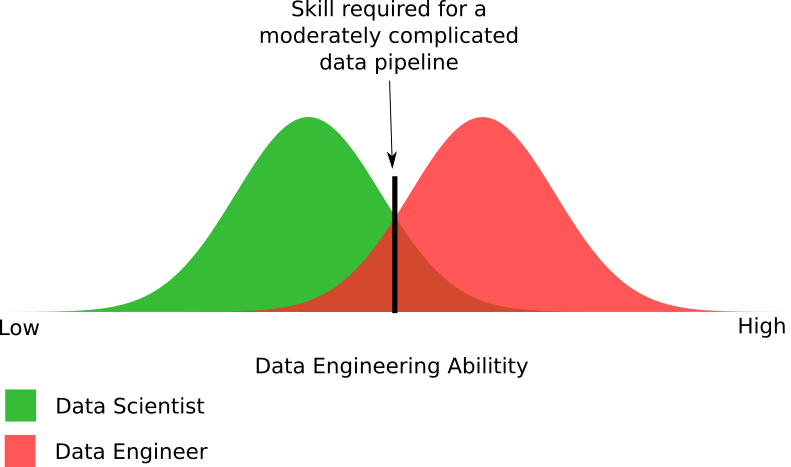 Abbildung 4. Ein empirisches Diagramm der Fähigkeiten von Spezialisten in der Theorie der Analyse und Datenverarbeitung, die zur Erstellung einer mäßig komplexen Datenpipeline erforderlich sind.
Abbildung 4. Ein empirisches Diagramm der Fähigkeiten von Spezialisten in der Theorie der Analyse und Datenverarbeitung, die zur Erstellung einer mäßig komplexen Datenpipeline erforderlich sind.Die Abbildung zeigt die Unterschiede in den für die Datenverarbeitung erforderlichen Funktionen. Tatsächlich habe ich mit der Anzahl der Wissenschaftler, die in der Lage sind, eine mäßig komplexe Datenpipeline zu erstellen, etwas übertrieben. Die Realität kann sein, dass die Experten der Analysetheorie die Hälfte des im Diagramm gezeigten Anteils ausmachen.
Im Allgemeinen werden die ungefähren Teile dieser beiden Gruppen dargestellt, mit denen Datenpipelines erstellt werden können und nicht. Ja, einige Datenverarbeitungsspezialisten können keine mäßig komplexe Pipeline erstellen, wie die meisten Experten in der Analysetheorie. Dies bringt uns zurück zu dem dringenden Problem: Organisationen geben ihre Projekte mit Big Data an diejenigen weiter, die nicht die Möglichkeit haben, sie korrekt umzusetzen.
Was ist eine mäßig komplexe Datenpipeline?
Eine mäßig komplexe Datenpipeline liegt einen Schritt über dem Mindestniveau, das zum Erstellen
einer Datenpipeline erforderlich ist. Ein Beispiel für eine Mindeststufe ist die Verarbeitung von in HDFS / S3 gespeicherten Textdateien mit Spark: Angenommen, der Beginn der Speicheroptimierung mit der korrekt verwendeten NoSQL-Datenbank.
Ich denke, dass Experten in der Theorie der Datenanalyse denken, dass ihre einfache Pipeline die Datenverarbeitung ist. In Wirklichkeit geht es jedoch um die einfachsten Lösungen, und es ist ein viel komplexeres Förderband erforderlich. In der Vergangenheit führte ein Datenverarbeitungsspezialist hinter den Kulissen ein wirklich komplexes Engineering durch, und Experten für Analysetheorie mussten sich nicht damit befassen.
Sie könnten denken: „Nun, 20% meiner Experten für Datenanalysetheorie können damit umgehen. Am Ende brauche ich keinen Verarbeitungsspezialisten. “ Denken Sie zunächst daran, dass dieses Diagramm die Fähigkeiten von Experten für Datenanalysetheorie überträgt. Ein mäßig schwieriges Niveau ist immer noch ein eher niedriges Niveau. Ich muss ein weiteres Diagramm erstellen, um zu zeigen, wie wenige Theoretiker der Datenanalyse den nächsten Schritt ausführen können. In diesem Stadium sinkt ihr Anteil unter den an der Theorie der Datenanalyse beteiligten Spezialisten auf 1% oder weniger.
Warum sind Datenwissenschaftler keine Dateningenieure?
Manchmal ziehe ich es vor, die reflektierten Manifestationen von Problemen zu betrachten. Hier sind einige dieser Probleme, die dazu führen, dass Experten der Datenanalysetheorie keine Verarbeitungsfähigkeiten besitzen.
Universität und Kurse
Data Analysis ist ein neues beliebtes Programm für Universitäten und Online-Kurse. Es gibt alle Arten von Vorschlägen, aber das gleiche Problem tritt fast überall auf: Der Lehrplan enthält entweder überhaupt keine Datenverarbeitungsklassen oder nur ein Paar fällt auf.
Wenn ich ein neues Trainingsprogramm für die Datenanalyse sehe, schaue ich es mir an. Manchmal werde ich gebeten, mich zu Kursen zu äußern, die von Universitäten angeboten werden. Ich sage allen dasselbe: „Benötigen Sie erfahrene Programmierer? Weil Ihr Kurs überhaupt nicht die Programmierung oder Systeme betrifft, die für die Verwendung der erstellten Datenpipeline erforderlich sind. “
Der Kurs konzentriert sich allgemein auf die notwendigen statistischen Werkzeuge und die Mathematik. Dies spiegelt wider, wie laut Unternehmen und Wissenschaftlern die Datenanalyse aussehen sollte. Aber die reale Welt sieht ganz anders aus. Arme Schüler können nur bis zum Ende dieser nicht trivialen Klassen schwanken.
Wir können einen Schritt zurücktreten und alles aus akademischer Sicht betrachten, unter Berücksichtigung der Anforderungen für einen Master-Abschluss im Bereich verteilter Systeme. Natürlich braucht ein Spezialist für Datenanalysetheorie kein so tiefes Niveau, aber es hilft zu zeigen, welche Lücken in den Fähigkeiten eines Spezialisten für Datenanalysetheorie bestehen. Es gibt mehrere gravierende Lücken.
Datenverarbeitung! = Funke
Ein häufiges Missverständnis unter Spezialisten in der Theorie der Datenanalyse und -verwaltung ist, dass sie glauben, dass die Datenverarbeitung nur eine Art Spark-Code schreibt, um die Datei zu verarbeiten. Spark ist eine gute Batch-Lösung, aber nicht die einzige Technologie, die Sie benötigen. Eine Big-Data-Lösung erfordert 10 bis 30 verschiedene Technologien, die zusammenarbeiten.
Dieser Irrtum ist der Kern von Big-Data-Fehlern. Das Management ist der Ansicht, dass das Unternehmen eine neue universelle Lösung zur Lösung von Problemen mit Big Data hat. Die Realität ist viel komplizierter.
Wenn ich die Organisation in Big-Data-Fragen berate, überprüfe ich auf allen Unternehmensebenen, ob dieser Fehler vorliegt. Wenn ja, muss ich sicher sein, dass ich alle Technologien auflisten werde, die sie benötigen. Dies beseitigt das Missverständnis, dass es im Big-Data-Bereich eine einfache Schaltfläche und eine einzige Technologie gibt, um alle Probleme zu lösen.
Woher kommt der Code?
Manchmal sagen mir Experten der Datenanalysetheorie, wie einfach die Datenverarbeitungstechnologie ist. Ich frage sie, warum sie so denken? „Ich kann den Code, den ich brauche, von StackOverflow oder Reddit erhalten. Wenn ich etwas von Grund auf neu erstellen muss, kann ich das Projekt einer Person in eine Vorlesung auf einer Konferenz oder in ein technisches Dokument kopieren. "
Für einen Fremden mag dies normal erscheinen. Für einen Datenverarbeitungsspezialisten ist dies ein Alarm. Abgesehen von rechtlichen Fragen ist dies keine Datenverarbeitung. Im Bereich Big Data gibt es nur sehr wenige Vorlagenprobleme. Alles, was nach „Hallo Welt“ passiert, hat eine komplexere Struktur, die einen Datenverarbeitungsspezialisten erfordert, da es keinen Vorlagenansatz für die Arbeit damit gibt. Das Kopieren eines Projekts aus der technischen Dokumentation kann zu
schlechter Leistung oder etwas Schlimmerem führen .
Ich musste mich mit mehreren Gruppen über die Theorie der Datenanalyse befassen, die den Ansatz „Affe sieht - Affe tut“ ausprobierten. Es funktioniert nicht sehr gut. Dies ist auf eine stark zunehmende Komplexität von Big Data und die
genaue Berücksichtigung von Anwendungsfällen zurückzuführen. Ein Team von Spezialisten für Datenanalysetheorie lehnt ein Projekt häufig ab, weil es über ihre Fähigkeiten in der Datenverarbeitung hinausgeht. Einfach ausgedrückt gibt es einen großen Unterschied zwischen "Ich kann Code aus StackOverflow kopieren" oder "Ich kann etwas ändern, das bereits geschrieben wurde" und "Ich kann dieses System von Grund auf neu erstellen".
Persönlich befürchte ich, dass Gruppen von Spezialisten für Datenanalysetheorie zu einer Quelle enormer technischer Schulden werden könnten, die die Effektivität von Big Data in Organisationen verringern. Wenn dies klar wird, wird die technische Verschuldung so hoch sein, dass es unmöglich sein wird, sie zu beheben.
Was war der längste Code, der für den industriellen Gebrauch eingeführt wurde?
Der Hauptunterschied zwischen Spezialisten in der Theorie der Datenanalyse ist ihre Tiefe. Diese Tiefe kann auf zwei Arten angezeigt werden. Was ist die längste Anwendungsdauer ihres Codes in der Praxis - und wurde er überhaupt in Betrieb genommen? Was ist das längste, größte oder komplexeste Programm, das sie jemals geschrieben haben?
Es geht nicht um Wettbewerb, sondern darum, ob sie wissen, was passiert, wenn Sie etwas in Betrieb nehmen, und wie der Code gepflegt wird. Das Schreiben eines Programms mit 20 Codezeilen ist relativ einfach. Es ist eine ganz andere Sache, 1000 Codezeilen zu schreiben, die kohärent und einfach zu warten sind. Personen, die noch nie mehr als 20 Zeilen geschrieben haben, verstehen den Unterschied in der Wartungsfreundlichkeit nicht. Alle ihre Beschwerden über die Ausführlichkeit von Java und die Notwendigkeit, Best Practices bei der Programmierung anzuwenden, beziehen sich auf große Softwareprojekte.
Wenn Sie Daten auswerten und ermitteln, müssen Sie schnell arbeiten und den Code wiederholen. Die Arbeit mit dem Code für die Verwendung in der Produktion ist auf einer anderen, tieferen Ebene erforderlich. Aus diesem Grund muss der Code der meisten Experten für Datenanalysetheorie vor Inbetriebnahme neu geschrieben werden.
Verteiltes Systemdesign
Eine Möglichkeit, den Unterschied zwischen Experten für Datenanalysetheorie und Datenverarbeitungsspezialisten herauszufinden, besteht darin, zu sehen, was passiert, wenn sie ihre eigenen verteilten Systeme schreiben. Ein Experte für Datenanalysetheorie wird etwas schreiben, das sich sehr auf Mathematik konzentriert, aber nicht gut funktioniert. Ein Datenverarbeitungsspezialist, der verteilte Systeme schreibt, erstellt eine verteilte Lösung, die gut funktioniert (
aber schreiben Sie Ihre eigenen Systeme nicht besser ). Ich werde einige Geschichten über meine Interaktion mit Organisationen erzählen, in denen Experten der Theorie der Datenanalyse ein verteiltes System geschaffen haben.
In Begleitung meines Kunden hat eine Abteilung, die aus Spezialisten für die Theorie der Datenanalyse besteht, ein solches System geschaffen. Ich wurde geschickt, um mit ihnen zu sprechen und zu verstehen, warum sie ihre eigene Entscheidung geschrieben haben und was sie bewirken können. Sie beschäftigten sich mit (verteilter) Bildverarbeitung.
Ich fragte sie zunächst, warum sie ihr eigenes verteiltes System erstellt haben. Sie antworteten, dass es unmöglich sei, den Algorithmus zu verteilen. Um ihre Ergebnisse zu bestätigen, unterzeichneten sie einen Vertrag mit einem anderen Spezialisten für Datenanalyse, der sich auf Bildverarbeitung spezialisiert hat. Der Auftragnehmer bestätigte die Unmöglichkeit der Verbreitung des Algorithmus.
In den zwei Stunden, die ich mit dem Team verbracht habe, wurde klar, dass der Algorithmus auf einer universellen Computer-Engine wie Spark verteilt werden kann. , . data scientist'e data engineer', -.
, , . , . . , . . RPC- , .
:
- , . , .
- , .
- : « ?» : « ?»
- , , , .
?
, , : — . , ? ?
— , big data.
, , . , . Hier sind einige davon:
, , , , . , . , , : « » « . . ». , . .
? , - , production ? «». , .
data scientist'? , ( ), . , . «» .
?
, , data scientist' data engineer'. , . : , , .
, , , .
, , data scientist' data engineer' , , . 2-5 . , , .
, . , , , . , , . , , , , , .
, . . , . , , , , .
, . , , , , . :
- . , , , .
- , — . , .
- ? , -?
- , data scientist'. .
- , . , . — , .
Was tun?
, , ? , . . .
, . , . .
, . .
big data
, big data — . , . big data-, . .
big data- , . , , . ( ) , .
Ähnliche Fehler bilden ein sich wiederholendes Muster. Sie können auf die neueste Technologie aktualisieren, vergessen jedoch, Systemprobleme zu beheben. Nur wenn Sie das Grundproblem behoben haben, können Sie Ihre Reise zum Erfolg beginnen.