Die Chips auf den meisten modernen Desktop-Computern haben vier Kerne, aber die Chiphersteller haben bereits Pläne für ein Upgrade auf sechs Kerne angekündigt, und 16-Kern-Prozessoren sind für Hochleistungsserver keine Seltenheit.
Je mehr Kerne vorhanden sind, desto größer ist das Problem der Speicherzuordnung zwischen allen Kernen während der Zusammenarbeit. Mit zunehmender Anzahl von Kernen wird es immer rentabler, den Zeitverlust bei der Verwaltung der Kerne während der Datenverarbeitung zu minimieren, da die Datenaustauschrate hinter der Geschwindigkeit des Prozessors und der Datenverarbeitung im Speicher zurückbleibt. Sie können sich physisch dem schnellen Cache einer anderen Person zuwenden oder Ihren eigenen langsamen Cache verwenden, aber Zeit für die Datenübertragung sparen. Die Aufgabe wird durch die Tatsache kompliziert, dass die von den Programmen angeforderte Speichermenge nicht eindeutig den Cache-Größen jedes Typs entspricht.
Nur eine sehr begrenzte Speichermenge kann physisch so nahe wie möglich am Prozessor platziert werden - ein Prozessor-Cache der Stufe L1, dessen Größe extrem gering ist. Daniel Sanchez, Po-An Tsai, und Nathan Beckmann, Forscher am Labor für Informatik und künstliche Intelligenz des Massachusetts Institute of Technology,
brachten dem Computer bei,
wie verschiedene Speichertypen so konfiguriert werden können, dass sie in eine flexible Hierarchie von Programmen passen Echtzeit. Das neue System namens Jenga analysiert den Volumenbedarf und die Häufigkeit des Programmzugriffs auf den Speicher und verteilt die Leistung jedes der drei Arten von Prozessor-Cache in Kombinationen, die eine höhere Effizienz und Energieeinsparung bieten.

Zunächst testeten die Forscher die Leistungssteigerung mit einer Kombination aus statischem und dynamischem Speicher bei der Arbeit an Programmen für einen Single-Core-Prozessor und erhielten die primäre Hierarchie - wann welche Kombination am besten zu verwenden ist. Aus 2 Arten von Speicher oder aus einem. Es wurden zwei Parameter bewertet - Signalverzögerung (Latenz) und Energieverbrauch während des Betriebs jedes Programms. Ungefähr 40% der Programme begannen mit einer Kombination von Speichertypen schlechter zu funktionieren, der Rest - besser. Nachdem die Forscher festgelegt hatten, welche Programme gemischte Leistung „mögen“ und welche - die Größe des Speichers -, bauten sie ihr Jenga-System auf.
Sie testeten virtuell 4 Arten von Programmen auf einem virtuellen Computer mit 36 Kernen. Testete das Programm:
- omnet - Objective Modular Network Testbed, C-Modellierungsbibliothek und Plattform für Netzwerkmodellierungswerkzeuge (blau im Bild)
- mcf - Meta Content Framework (rot)
- astar - Software zur Anzeige der virtuellen Realität (grün)
- bzip2 - Archivierer (lila Farbe)
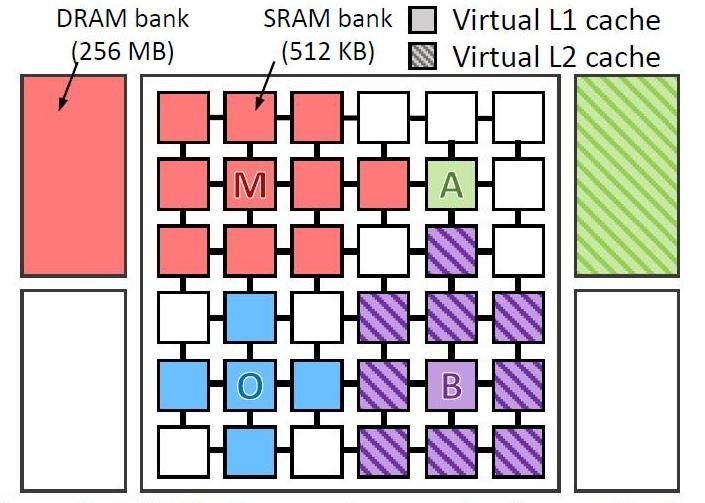
Das Bild zeigt, wo und wie die Daten jedes Programms verarbeitet wurden. Die Buchstaben geben an, wo jede Anwendung ausgeführt wird (eine pro Quadrant), die Farben geben an, wo sich ihre Daten befinden, und die Schraffur zeigt die zweite Ebene der virtuellen Hierarchie an, wenn sie vorhanden ist.
Cache-EbenenDer CPU-Cache ist in mehrere Ebenen unterteilt. Für Universalprozessoren - bis zu 3. Der schnellste Speicher ist der Cache der ersten Ebene - der L1-Cache, da er sich auf demselben Chip wie der Prozessor befindet. Besteht aus einem Befehls-Cache und einem Daten-Cache. Einige Prozessoren ohne L1-Cache können nicht funktionieren. Der L1-Cache läuft mit der Prozessorfrequenz und kann bei jedem Taktzyklus aufgerufen werden. Es ist oft möglich, mehrere Lese- / Schreibvorgänge gleichzeitig auszuführen. Das Volumen ist normalerweise klein - nicht mehr als 128 KB.
Der L1-Cache interagiert mit einem Cache der zweiten Ebene - L2. Es ist das zweitschnellste. Normalerweise befindet es sich entweder auf dem Chip wie L1 oder in unmittelbarer Nähe des Kerns, beispielsweise in einer Prozessorkartusche. Bei älteren Prozessoren ein Chipsatz auf dem Motherboard. Die Größe des L2-Cache beträgt 128 KB bis 12 MB. In modernen Multi-Core-Prozessoren ist der Cache der zweiten Ebene, der sich auf demselben Chip befindet, ein gemeinsam genutzter Speicher - mit einer Gesamt-Cache-Größe von 8 MB, 2 MB pro Core. Typischerweise liegt die Latenz des auf dem Kernchip befindlichen L2-Cache zwischen 8 und 20 Taktzyklen. Bei Aufgaben im Zusammenhang mit zahlreichen Zugriffen auf einen begrenzten Speicherbereich, z. B. ein DBMS, verzehnfacht sich die Produktivität durch seine vollständige Nutzung.
Der L3-Cache ist normalerweise noch größer, wenn auch etwas langsamer als L2 (aufgrund der Tatsache, dass der Bus zwischen L2 und L3 schmaler ist als der Bus zwischen L1 und L2). L3 befindet sich normalerweise getrennt vom CPU-Kern, kann jedoch groß sein - mehr als 32 MB. Der L3-Cache ist langsamer als die vorherigen Caches, aber immer noch schneller als der RAM. In Multiprozessorsystemen wird häufig verwendet. Die Verwendung des Caches der dritten Ebene ist in einem sehr engen Aufgabenbereich gerechtfertigt und erhöht möglicherweise nicht nur nicht die Produktivität, sondern auch umgekehrt und führt zu einer allgemeinen Verringerung der Systemleistung.
Das Deaktivieren des Caches der zweiten und dritten Ebene ist bei mathematischen Problemen am nützlichsten, wenn die Datenmenge kleiner als die Größe des Caches ist. In diesem Fall können Sie alle Daten sofort in den L1-Cache laden und dann verarbeiten.
In regelmäßigen Abständen konfiguriert Jenga auf Betriebssystemebene virtuelle Hierarchien neu, um den Datenaustausch angesichts von Ressourcenbeschränkungen und Anwendungsverhalten zu minimieren. Jede Neukonfiguration besteht aus vier Schritten.
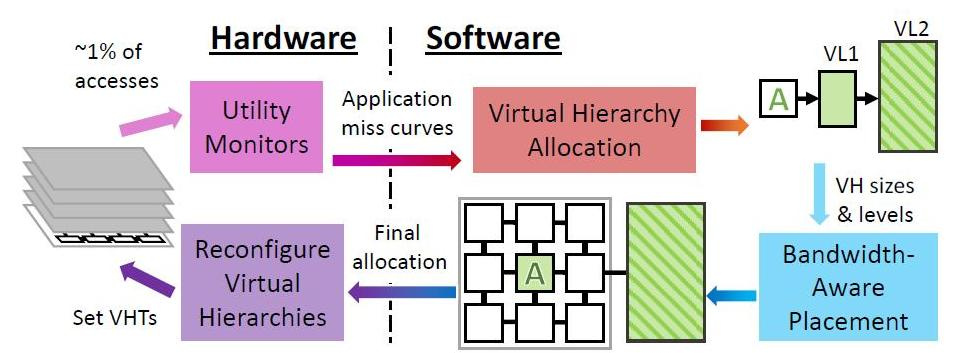
Jenga verteilt Daten nicht nur abhängig davon, welche Programme gesendet werden - diejenigen, die großen Single-Speed-Speicher lieben oder die Leistung gemischter Caches mögen, sondern auch abhängig von der physischen Nähe der Speicherzellen zu den verarbeiteten Daten. Unabhängig davon, welche Art von Cache das Programm standardmäßig oder in der Hierarchie benötigt. Die Hauptsache ist, die Signalverzögerung und den Energieverbrauch zu minimieren. Je nachdem, wie viele Arten von Speicher das Programm „mag“, modelliert Jenga die Latenz jeder virtuellen Hierarchie mit einer oder zwei Ebenen. Zweistufige Hierarchien bilden eine Oberfläche, einstufige Hierarchien bilden eine Kurve. Jenga entwirft dann die minimale Verzögerung in VL1-Größen, die zwei Kurven ergibt. Schließlich verwendet Jenga diese Kurven, um die beste Hierarchie (d. H. VL1-Größe) auszuwählen.
Die Verwendung von Jenga ergab einen spürbaren Effekt. Der virtuelle 36-Kern-Chip war 30 Prozent schneller und verbrauchte 85 Prozent weniger Strom. Während Jenga nur eine Simulation eines funktionierenden Computers ist, wird es natürlich einige Zeit dauern, bis Sie echte Beispiele für diesen Cache sehen und sogar bevor die Chiphersteller ihn akzeptieren, wenn sie die Technologie mögen.
Bedingte 36 Kernmaschinenkonfiguration
- Prozessoren . 36 Kerne, x86-64 ISA, 2,4 GHz, Silvermont-ähnliches OOO: 8B breit
ifetch; 2-Level-Bpred mit 512 × 10-Bit-BHSRs + 1024 × 2-Bit-PHT, 2-Wege-Decodierung / Ausgabe / Umbenennung / Commit, IQ und ROB mit 32 Einträgen, LQ mit 10 Einträgen, SQ mit 16 Einträgen; 371 pJ / Anweisung, 163 mW / statische Kernleistung - L1-Level-Caches . 32 KB, 8-Wege-Set-assoziative, geteilte Daten- und Anweisungs-Caches,
3-Zyklus-Latenz; 15/33 pJ pro Treffer / Fehlschlag - Prefetchers Prefetch Service . Stream-Prefetchers mit 16 Einträgen, die nachgebildet und anhand dieser validiert wurden
Nehalem - L2-Level-Caches . 128 KB private 8-Wege-Set-assoziative 8-Wege-Latenz pro Kern; 46/93 pJ pro Treffer / Fehlschlag
- Kohärenter Modus (Kohärenz) . 16-Wege-Verzeichnisbanken mit 6 Latenzzeiten für Jenga; In-Cache-L3-Verzeichnisse für andere
- Global NoC . 6 × 6-Mesh, 128-Bit-Flits und -Verbindungen, XY-Routing, 2-Zyklus-Pipeline-Router, 1-Zyklus-Verbindungen; 63/71 pJ pro Router / Link Flit Traversal, 12 / 4mW Router / Link statische Leistung
- Statische SRAM-Speicherblöcke . 18 MB, eine 512-KB-Bank pro Kachel, 4-Wege-Zcache mit 52 Kandidaten, 9-Zyklus-Banklatenz, Vantage-Partitionierung; 240/500 pJ pro Treffer / Fehlschlag, 28 mW / Bank statische Leistung
- Mehrschichtiger dynamischer Speicher Gestapelter DRAM . 1152 MB, ein 128 MB-Tresor pro 4 Kacheln, Legierung mit MAP-I DDR3-3200 (1600 MHz), 128-Bit-Bus, 16 Ränge, 8 Bänke / Rang, 2 KB Zeilenpuffer; 4,4 / 6,2 nJ pro Treffer / Fehlschlag, 88 mW / Tresor statische Leistung
- Hauptspeicher . 4 DDR3-1600-Kanäle, 64-Bit-Bus, 2 Ränge / Kanal, 8 Bänke / Rang, 8 KB Zeilenpuffer; 20 nJ / Zugang, 4 W statische Leistung
- DRAM-Timings . tCAS = 8, tRCD = 8, tRTP = 4, tRAS = 24, tRP = 8, tRRD = 4, tWTR = 4, tWR = 8, tFAW = 18 (alle Timings in tCK; gestapelter DRAM hat die Hälfte des tCK als Hauptspeicher )