 Digitale Doppel von berühmten Politikern und Schauspielern stehen unter der vollständigen Kontrolle des „Puppenspielers“. Illustration: Universität von Washington, 2015
Digitale Doppel von berühmten Politikern und Schauspielern stehen unter der vollständigen Kontrolle des „Puppenspielers“. Illustration: Universität von Washington, 20153D-Grafikprogramme haben in Verbindung mit neuronalen Netzen eine solche Qualität erreicht, dass gefälschte Videos kaum von echten zu unterscheiden sind. Bald kann man nicht mit Sicherheit sagen, dass die Person auf dem Fernsehbildschirm ein echter Politiker ist, keine Computersimulation.
Im Dezember 2015 stellten Wissenschaftler der University of Washington die
Technologie des „digitalen Doppel“ vor : die Erstellung von „lebenden“ 3D-Modellen aus Hunderten von Fotografien eines Charakters. Für Prominente und Politiker im Internet wurde ein riesiges Fotoarchiv zusammengestellt. Das Programm erstellt ein Modell, und dieses ist wie eine Puppe an einem Seil - es kann gesteuert werden, wie Sie möchten, verschiedene Gesichtsausdrücke geben, jede Rede mit Ihren Lippen halten.
Jetzt, am Vorabend der Computergrafikkonferenz
SIGGRAPH 2017 , hat dieselbe Forschergruppe eine neue
wissenschaftliche Arbeit mit einer erweiterten Version von „digitalen Gegenstücken“ veröffentlicht.
Beim Unterrichten des Programms werden jetzt nicht nur Fotos, sondern auch Videos verwendet, sodass das Training viel effektiver geworden ist. Um die Technologie zu demonstrieren, haben Wissenschaftler einen berühmten Charakter ausgewählt - den ehemaligen US-Präsidenten Barack Obama. Dies ist eine gute Wahl, da das Internet eine große Menge an HD-Videomaterial enthält. Für das Training eines neuronalen Netzwerks stehen Millionen von Videobildern zur Verfügung.
Das neuronale Netzwerk hat die Merkmale von Obamas Gesichtsausdrücken im Detail untersucht: Lippenbewegungen bei jedem Geräusch, das Auftreten von Falten in der Nähe der Augen, Veränderungen in der Form der Augenbrauen und die Neigung des Kopfes. Der Gesichtsausdruck des experimentellen Charakters war mit den von ihm ausgesprochenen Geräuschen verbunden: Das neuronale Netzwerk verarbeitete nicht nur die Frames der Videos, sondern auch die Audiospuren zu ihnen.
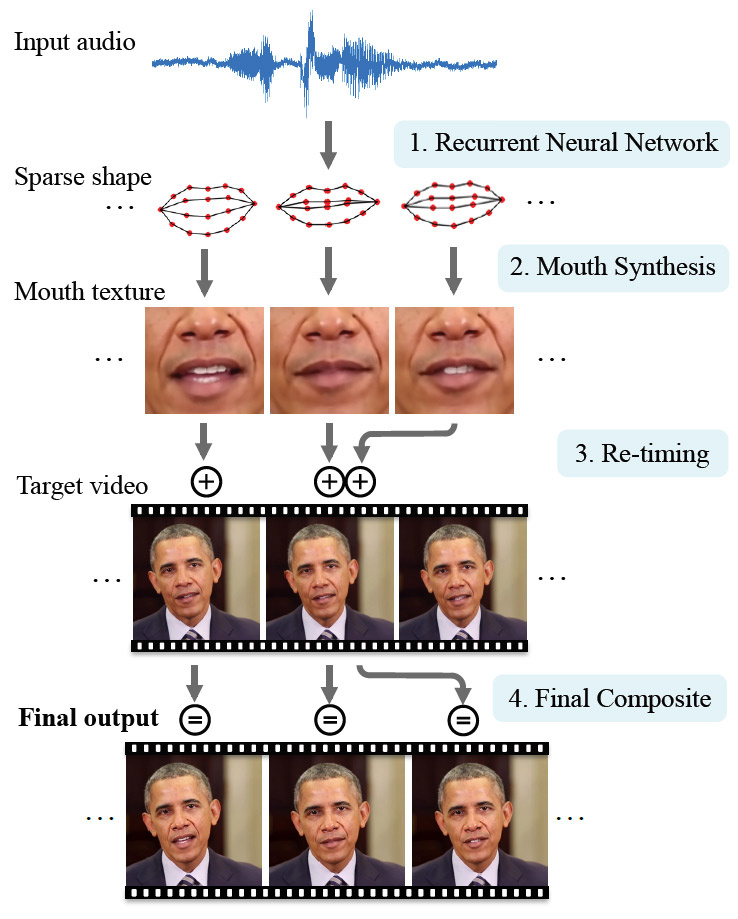
So lernte eine schwache KI, Gesichtsausdrücke und Lippenbewegungen mit jeder beliebigen Sprache zu synchronisieren, die Forscher in die Eingabe eines neuronalen Netzwerks einspeisen.
In einem Teaser für wissenschaftliche Arbeiten werden reale Aufnahmen von Obamas Reden und das von einem neuronalen Netzwerk synthetisierte Ergebnis verglichen.
Es ist zu beachten, dass sich das synthetisierte Ergebnis deutlich vom Original unterscheidet, aber dennoch sehr realistisch aussieht.
Die Forscher betonen, dass Menschen früher gezwungen waren, wiederholt dieselben Sätze vor den Kameras zu wiederholen, um alle Kombinationen von Morphemen und Gesichtsausdrücken aufzuzeichnen, um „digitale Doppel“ zu erhalten. Jetzt können Sie dies für öffentlich verfügbare Videos tun. Zwar verfügt nicht jede Person im Internet über genügend Videomaterial, um ihre Persönlichkeit vorzutäuschen, aber im Laufe der Zeit lösen Benutzer dieses Problem selbst, indem sie Gigabyte ihrer Fotos und Videos in soziale Netzwerke hochladen.
Aus praktischer Sicht kann diese Technologie auch eingesetzt werden. Zum Beispiel sagt Ira Kemelmacher-Shlizerman, eine der Mitautoren der wissenschaftlichen Arbeit, dass sie die Qualität von Videokonferenzen verbessern wird, indem sie die fehlenden Frames synthetisiert, wenn sie aus dem Videostream herausfallen. Wenn der Ton störungsfrei ist und das Video verzögert, ergänzt eine solche Synthese das Bild oder erhöht die Auflösung. Natürlich kann die Technologie in Computerspielen und in der virtuellen Realität Anwendung finden, wenn der Spieler mit einem virtuellen Charakter kommuniziert. Jetzt wird die Sprache des virtuellen Charakters realistischer und es kann sich um eine digitale Kopie einer realen Person handeln. Zum Beispiel können Sie einige historische Figuren aus der jüngeren Vergangenheit nur durch ihre Audioaufnahmen „wiederbeleben“. Natürlich wird die Schaffung von Fälschungen für politische Zwecke erleichtert. Wenn sie jetzt
in „Photoshop“ geformt und in soziale Netzwerke geworfen werden , werden in Zukunft gefälschte Videos im Fernsehen gezeigt.
Die Autoren erkennen an, dass die Technologie bisher nicht perfekt ist. Wenn Obama beispielsweise sein Gesicht leicht von der Kamera weg dreht, können sich Teile seines Mundes von seinem Gesicht lösen und sich mit dem Hintergrund überlappen. Dies sind jedoch geringfügige Fehler, die durch zusätzliches Training des neuronalen Netzwerks korrigiert werden können.
Ein weiterer Nachteil des erstellten Modells besteht darin, dass es keine Emotionen modelliert. Gesichtsausdrücke sind absolut neutral und fast immer gleich. So verliert das digitale Doppel in einigen Fällen seinen Realismus: Sein Gesichtsausdruck scheint zu ernst für die leichtfertigen Wörter, die es ausspricht. Oder umgekehrt - zu frivol für sehr ernsthafte Reden. Solche Vorfälle ereignen sich jedoch bei echten Politikern im wirklichen Leben.

Die erstellte Technologie ähnelt im Prinzip der Arbeit an einem
Programm zur Erstellung von digitalen Face2Face-Doppelbildern , bei dem Gesichtsausdrücke und Sprache einer Person auf das Gesicht einer anderen Person übertragen werden. In ihrer wissenschaftlichen Arbeit vergleichen Autoren aus Washington die Ergebnisse ihres neuronalen Netzwerks mit Face2Face. Sie erklären, dass im Fall von Face2Face immer ein Videostream zur Simulation erforderlich ist und ihr Modell nur durch Tonaufnahme funktioniert.