
Zu Beginn des 20. Jahrhunderts gab der deutsche Pferdetrainer und Mathematiker Wilhelm von Austin der Welt bekannt, dass er einem Pferd das Zählen beigebracht habe. Von Austin reiste jahrelang durch Deutschland, um dieses Phänomen zu demonstrieren. Er bat sein Pferd mit dem Spitznamen
Clever Hans (Rasse
Orlov Traber ), die Ergebnisse einfacher Gleichungen zu berechnen. Antwortete Hans und stampfte mit dem Huf. Zwei plus zwei? Vier Treffer.
Aber Wissenschaftler glaubten nicht, dass Hans so schlau war, wie von Austin behauptete. Der Psychologe
Karl Stumpf führte eine gründliche Untersuchung durch, die als "Hans-Komitee" bezeichnet wurde. Er entdeckte, dass Smart Hans keine Gleichungen löst, sondern auf visuelle Signale reagiert. Hans tippte auf seinen Huf, bis er die richtige Antwort bekam, woraufhin sein Trainer und eine begeisterte Menge in Schreie ausbrachen. Und dann hörte er einfach auf. Als er diese Reaktionen nicht sah, klopfte er weiter.
Die Informatik kann viel von Hans lernen. Das beschleunigte Entwicklungstempo in diesem Bereich lässt darauf schließen, dass der größte Teil der von uns erstellten KI ausreichend trainiert wurde, um die richtigen Antworten zu liefern, die Informationen jedoch nicht wirklich versteht. Und es ist leicht zu täuschen.
Algorithmen für maschinelles Lernen wurden schnell zu allsehenden Hirten der menschlichen Herde. Die Software verbindet uns mit dem Internet, überwacht Spam und schädliche Inhalte in unseren E-Mails und wird bald unsere Autos fahren. Ihre Täuschung verschiebt das tektonische Fundament des Internets und bedroht unsere Sicherheit in der Zukunft.
Kleine Forschungsgruppen - von der Pennsylvania State University, von Google, vom US-Militär - entwickeln Pläne zum Schutz vor möglichen Angriffen auf KI. In der Studie vorgebrachte Theorien besagen, dass ein Angreifer ändern kann, was ein Robomobil „sieht“. Oder aktivieren Sie die Spracherkennung auf dem Telefon und zwingen Sie es, eine schädliche Website mit Sounds zu betreten, die nur für eine Person Lärm sind. Oder lassen Sie den Virus durch die Netzwerk-Firewall lecken.
 Links ist das Bild des Gebäudes, rechts das modifizierte Bild, das das tiefe neuronale Netzwerk auf Strauße bezieht. In der Mitte werden alle Änderungen angezeigt, die auf das Primärbild angewendet wurden.
Links ist das Bild des Gebäudes, rechts das modifizierte Bild, das das tiefe neuronale Netzwerk auf Strauße bezieht. In der Mitte werden alle Änderungen angezeigt, die auf das Primärbild angewendet wurden.Anstatt die Kontrolle über ein Robomobil zu übernehmen, zeigt ihm diese Methode so etwas wie eine Halluzination - ein Bild, das es eigentlich nicht gibt.
Solche Angriffe verwenden Bilder mit einem Trick [gegnerische Beispiele - es gibt keinen etablierten russischen Begriff, wörtlich stellt sich heraus, dass es sich um „Beispiele mit Kontrast“ oder „rivalisierende Beispiele“ handelt - ca. transl.]: Bilder, Töne, Text, der für Menschen normal aussieht, aber von einer völlig anderen Maschine wahrgenommen wird. Die kleinen Änderungen, die von den Angreifern vorgenommen werden, können dazu führen, dass das tiefe neuronale Netzwerk die falschen Schlussfolgerungen darüber zieht, was es zeigt.
"Jedes System, das maschinelles Lernen verwendet, um sicherheitskritische Entscheidungen zu treffen, ist potenziell anfällig für diese Art von Angriff", sagte Alex Kanchelyan, ein Forscher an der Universität von Berkeley, der Angriffe auf maschinelles Lernen mit gefälschten Bildern untersucht.
Wenn die Forscher diese Nuancen in den frühen Stadien der KI-Entwicklung kennen, können sie verstehen, wie diese Mängel behoben werden können. Einige haben dies bereits aufgegriffen und sagen, dass ihre Algorithmen dadurch immer effizienter geworden sind.
Der größte Teil der KI-Forschung basiert auf tiefen neuronalen Netzen, die wiederum auf einem breiteren Feld des maschinellen Lernens basieren. MoD-Technologien verwenden Differential- und Integralrechnung und Statistiken, um Software zu erstellen, die von den meisten von uns verwendet wird, z. B. Spam-Filter in der E-Mail oder im Internet. In den letzten 20 Jahren haben Forscher begonnen, diese Techniken auf eine neue Idee anzuwenden, neuronale Netze - Softwarestrukturen, die die Gehirnfunktion nachahmen. Die Idee ist, die Berechnungen über Tausende kleiner Gleichungen („Neuronen“), die Daten empfangen, dezentralisieren, verarbeiten und weiterleiten, auf die nächste Schicht von Tausenden kleiner Gleichungen zu dezentralisieren.
Diese KI-Algorithmen werden auf die gleiche Weise trainiert wie im Fall von MO, das wiederum den Lernprozess einer Person kopiert. Ihnen werden Beispiele für verschiedene Dinge und die zugehörigen Tags gezeigt. Zeigen Sie dem Computer (oder Kind) das Bild einer Katze, sagen Sie, dass die Katze so aussieht, und der Algorithmus lernt, Katzen zu erkennen. Dafür muss der Computer Tausende und Abermillionen Bilder von Katzen und Katzen anzeigen.
Forscher haben herausgefunden, dass diese Systeme mit speziell ausgewählten irreführenden Daten angegriffen werden können, die sie als „kontroverse Beispiele“ bezeichnen.
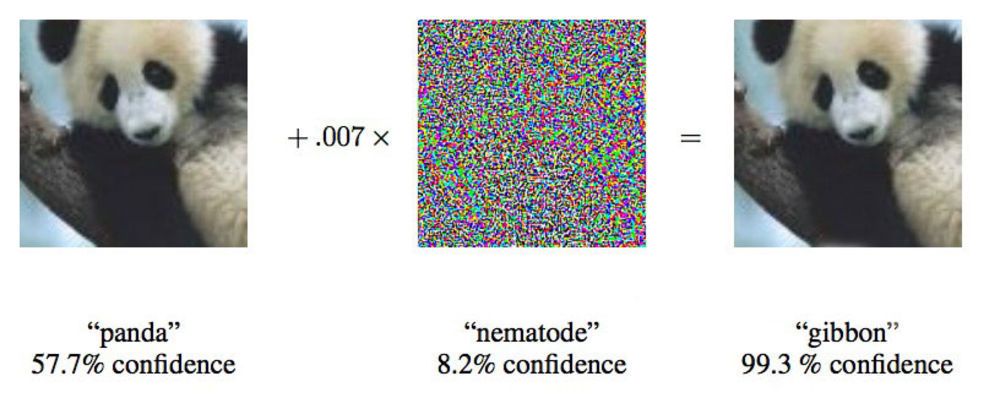 In einem Artikel aus dem Jahr 2015 haben Forscher von Google gezeigt, dass tiefe neuronale Netze gezwungen sein können, dieses Bild eines Pandas Gibbons zuzuschreiben.
In einem Artikel aus dem Jahr 2015 haben Forscher von Google gezeigt, dass tiefe neuronale Netze gezwungen sein können, dieses Bild eines Pandas Gibbons zuzuschreiben."Wir zeigen Ihnen ein Foto, das den Schulbus deutlich zeigt und Sie glauben lässt, es sei ein Strauß", sagte Ian Goodfellow, ein Google-Forscher, der aktiv an solchen Angriffen auf neuronale Netze arbeitet.
Die Forscher änderten die für neuronale Netze bereitgestellten Bilder nur um 4% und konnten sie in 97% der Fälle dazu verleiten, Fehler bei der Klassifizierung zu machen. Selbst wenn sie nicht genau wüssten, wie das neuronale Netzwerk Bilder verarbeitet, könnten sie es in 85% der Fälle täuschen.
Die letzte Variante des Betrugs ohne Daten in der Netzwerkarchitektur wird als „Black-Box-Angriff“ bezeichnet. Dies ist der erste dokumentierte Fall eines funktionellen Angriffs dieser Art auf ein tiefes neuronales Netzwerk, und seine Bedeutung ist, dass ungefähr in diesem Szenario Angriffe in der realen Welt stattfinden können.
In der Studie griffen Forscher der Pennsylvania State University, von Google und des US Navy Research Laboratory ein neuronales Netzwerk an, das vom MetaMind-Projekt unterstützte Bilder klassifiziert und als Online-Tool für Entwickler dient. Das Team baute das angegriffene Netzwerk auf und trainierte es, aber sein Angriffsalgorithmus funktionierte unabhängig von der Architektur. Mit einem solchen Algorithmus konnten sie das neuronale Black-Box-Netzwerk mit einer Genauigkeit von 84,24% austricksen.
 Die oberste Reihe von Fotos und Zeichen - korrekte Zeichenerkennung.
Die oberste Reihe von Fotos und Zeichen - korrekte Zeichenerkennung.
Untere Reihe - Das Netzwerk musste Zeichen völlig falsch erkennen.Das Einspeisen ungenauer Daten in Maschinen ist keine neue Idee, aber Doug Tygar, Professor an der Universität von Berkeley, der im Gegensatz dazu seit 10 Jahren maschinelles Lernen studiert, sagt, diese Angriffstechnologie habe sich von einem einfachen MO zu komplexen tiefen neuronalen Netzen entwickelt. Böswillige Hacker verwenden diese Technik seit Jahren für Spam-Filter.
Tigers Forschung stammt aus
seiner Arbeit von
2006 über Angriffe dieser Art in einem Netzwerk mit dem Verteidigungsministerium, die er 2011 mit Hilfe von Forschern von UC Berkeley und Microsoft Research erweiterte. Das Google-Team, das als erstes tiefe neuronale Netze verwendet, veröffentlichte 2014 seine
erste Arbeit , zwei Jahre nachdem es die Möglichkeit solcher Angriffe entdeckt hatte. Sie wollten sicherstellen, dass dies keine Anomalie war, sondern eine echte Möglichkeit. 2015 veröffentlichten sie eine weitere
Arbeit, in der sie einen Weg zum Schutz von Netzwerken und zur Steigerung ihrer Effizienz beschrieben haben. Ian Goodfellow hat seitdem Ratschläge zu anderen wissenschaftlichen Arbeiten in diesem Bereich gegeben, einschließlich
des Black-Box-Angriffs .
Forscher nennen die allgemeinere Idee unzuverlässiger Informationen „byzantinische Daten“ und sind dank des Fortschritts der Forschung zu tiefem Lernen gekommen. Der Begriff stammt von der bekannten „
Aufgabe der byzantinischen Generäle “, einem Gedankenexperiment auf dem Gebiet der Informatik, bei dem eine Gruppe von Generälen ihre Handlungen mit Hilfe von Boten koordinieren muss, ohne das Vertrauen zu haben, dass einer von ihnen ein Verräter ist. Sie können den Informationen ihrer Kollegen nicht vertrauen.
„Diese Algorithmen sind für zufälliges Rauschen ausgelegt, nicht jedoch für byzantinische Daten“, sagt Taigar. Um zu verstehen, wie solche Angriffe funktionieren, schlägt Goodfello vor, sich ein neuronales Netzwerk in Form eines Dispersionsdiagramms vorzustellen.
Jeder Punkt im Diagramm repräsentiert ein Pixel des vom neuronalen Netzwerk verarbeiteten Bildes. In der Regel versucht das Netzwerk, eine Linie durch die Daten zu ziehen, die am besten zur Menge aller Punkte passt. In der Praxis ist dies etwas komplizierter, da unterschiedliche Pixel unterschiedliche Werte für das Netzwerk haben. In Wirklichkeit ist dies ein komplexer mehrdimensionaler Graph, der von einem Computer verarbeitet wird.
In unserer einfachen Analogie eines Streudiagramms bestimmt die Form der durch die Daten gezogenen Linie, was das Netzwerk zu sehen glaubt. Für einen erfolgreichen Angriff auf solche Systeme müssen Forscher nur einen kleinen Teil dieser Punkte ändern und das Netzwerk eine Entscheidung treffen lassen, die tatsächlich nicht existiert. In dem Beispiel eines Busses, der wie ein Strauß aussieht, ist das Foto des Schulbusses mit Pixeln gepunktet, die gemäß dem Muster angeordnet sind, das mit den einzigartigen Eigenschaften von Straußenfotos verbunden ist, die dem Netzwerk vertraut sind. Dies ist eine unsichtbare Kontur für das Auge, aber wenn der Algorithmus
die Daten verarbeitet und vereinfacht , scheinen ihm die extremen Datenpunkte für den Strauß eine geeignete Klassifizierungsoption zu sein. In der Black-Box-Version testeten die Forscher die Arbeit mit verschiedenen Eingabedaten, um festzustellen, wie der Algorithmus bestimmte Objekte sieht.
Indem die Forscher dem Objektklassifizierer eine gefälschte Eingabe gaben und die von der Maschine getroffenen Entscheidungen untersuchten, konnten sie den Algorithmus wiederherstellen, um das Bilderkennungssystem zu täuschen. Möglicherweise kann ein solches System in Robomobilen in diesem Fall das "Nachgeben" -Schild anstelle des Stoppschilds sehen. Als sie verstanden, wie das Netzwerk funktionierte, konnten sie die Maschine alles sehen lassen.
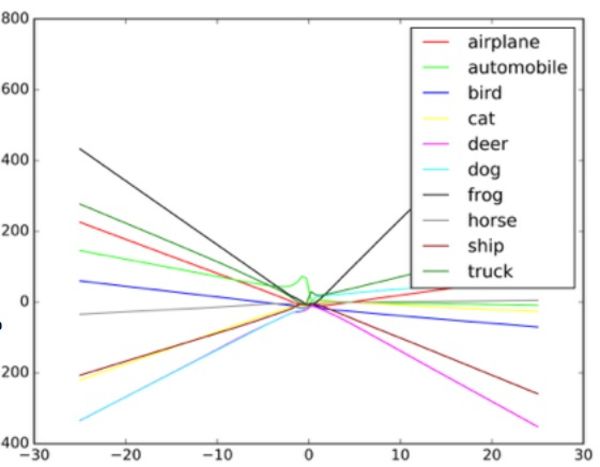 Ein Beispiel dafür, wie der Bildklassifizierer abhängig von den verschiedenen Objekten im Bild unterschiedliche Linien zeichnet. Gefälschte Beispiele können als Extremwerte in der Grafik betrachtet werden.
Ein Beispiel dafür, wie der Bildklassifizierer abhängig von den verschiedenen Objekten im Bild unterschiedliche Linien zeichnet. Gefälschte Beispiele können als Extremwerte in der Grafik betrachtet werden.Forscher sagen, dass ein solcher Angriff direkt in das Bildverarbeitungssystem eingegeben werden kann, indem die Kamera umgangen wird, oder dass diese Manipulationen mit einem echten Zeichen ausgeführt werden können.
Die Sicherheitsspezialistin der Columbia University, Alison Bishop, sagte jedoch, dass eine solche Prognose unrealistisch sei und von dem im Robomobile verwendeten System abhänge. Wenn die Angreifer bereits Zugriff auf den Datenstrom von der Kamera haben, können sie ihm bereits Eingaben geben.
"Wenn sie zum Eingang der Kamera gelangen können, sind solche Schwierigkeiten nicht erforderlich", sagt sie. "Du kannst ihr nur das Stoppschild zeigen."
Andere Angriffsmethoden, neben der Umgehung der Kamera - zum Beispiel das Zeichnen visueller Markierungen auf einem echten Schild - scheinen Bishop unwahrscheinlich. Sie bezweifelt, dass die bei Robomobilen verwendeten Kameras mit niedriger Auflösung im Allgemeinen zwischen kleinen Änderungen des Vorzeichens unterscheiden können.
 Das makellose Bild links ist als Schulbus klassifiziert. Rechts korrigiert - wie ein Strauß. In der Mitte ändert sich das Bild.
Das makellose Bild links ist als Schulbus klassifiziert. Rechts korrigiert - wie ein Strauß. In der Mitte ändert sich das Bild.Zwei Gruppen, eine an der University of Berkeley und eine an der Georgetown University, haben erfolgreich Algorithmen entwickelt, mit denen digitale Assistenten wie Siri und Google Now Sprachbefehle erhalten können, die wie unhörbares Rauschen klingen. Für eine Person erscheinen solche Befehle wie zufälliges Rauschen, aber gleichzeitig können sie Geräten wie Alexa Befehle erteilen, die von ihrem Besitzer nicht vorgesehen sind.
Nicholas Carlini, einer der Forscher für byzantinische Audioangriffe, sagt, dass sie in ihren Tests Open-Source-Audioerkennungsprogramme, Siri und Google Now, mit einer Genauigkeit von mehr als 90% aktivieren konnten.
Das Geräusch ist wie eine Art Science-Fiction-Alien-Verhandlung. Dies ist eine Mischung aus weißem Rauschen und einer menschlichen Stimme, aber es ist überhaupt nicht wie ein Sprachbefehl.
Laut Carlini kann bei einem solchen Angriff jeder, der ein Telefongeräusch gehört hat (es ist erforderlich, Angriffe auf iOS und Android separat zu planen), gezwungen werden, eine Webseite aufzurufen, auf der auch Geräusche wiedergegeben werden, wodurch in der Nähe befindliche Telefone infiziert werden. Oder diese Seite lädt leise ein Malware-Programm herunter. Es ist auch möglich, dass solche Geräusche im Radio verloren gehen und im weißen Rauschen oder parallel zu anderen Audioinformationen versteckt werden.
Solche Angriffe können auftreten, weil die Maschine darauf trainiert ist, sicherzustellen, dass fast alle Daten wichtige Daten enthalten und dass eines häufiger vorkommt als das andere, wie von Goodfello erläutert.
Das Netzwerk zu täuschen und es zu zwingen zu glauben, dass es ein gemeinsames Objekt sieht, ist einfacher, weil es glaubt, dass es solche Objekte häufiger sehen sollte. Daher konnten Goodfellow und eine andere Gruppe von der University of Wyoming das Netzwerk dazu bringen, Bilder zu klassifizieren, die überhaupt nicht existierten - es identifizierte Objekte in weißem Rauschen, zufällig erzeugte Schwarz-Weiß-Pixel.
In einer Goodfellow-Studie wurde zufälliges weißes Rauschen, das durch ein Netzwerk geht, von ihr als Pferd eingestuft. Zufälligerweise bringt uns dies zurück zur Geschichte von Clever Hans, einem nicht sehr mathematisch begabten Pferd.
Goodfellow sagt, dass neuronale Netze wie Smart Hans keine Ideen lernen, sondern nur herausfinden, wann sie die richtige Idee finden. Der Unterschied ist klein aber wichtig. Der Mangel an grundlegendem Wissen erleichtert böswillige Versuche, den Anschein zu erwecken, die „richtigen“ Algorithmusergebnisse zu finden, die sich tatsächlich als falsch herausstellen. Um zu verstehen, was etwas ist, muss eine Maschine auch verstehen, was es nicht ist.
Goodfello, der die Netzwerksortierung von Bildern sowohl auf natürlichen Bildern als auch auf verarbeiteten (gefälschten) Bildern trainiert hatte, stellte fest, dass er nicht nur die Wirksamkeit solcher Angriffe um 90% reduzieren, sondern auch das Netzwerk besser für die anfängliche Aufgabe einsetzen konnte.
„Indem Sie es ermöglichen, wirklich ungewöhnliche gefälschte Bilder zu erklären, können Sie die zugrunde liegenden Konzepte noch zuverlässiger erklären“, sagt Goodfellow.
Zwei Gruppen von Audioforschern verwendeten einen ähnlichen Ansatz wie das Google-Team und schützten ihre neuronalen Netze durch Übertraining vor ihren eigenen Angriffen. Sie erzielten ähnliche Erfolge und reduzierten ihre Angriffseffizienz um mehr als 90%.
Es ist nicht verwunderlich, dass dieses Forschungsgebiet das US-Militär interessierte. Das Army Research Laboratory hat sogar zwei der neuesten Arbeiten zu diesem Thema gesponsert, darunter den Black-Box-Angriff. Und obwohl die Agentur Forschung finanziert, bedeutet dies nicht, dass Technologie im Krieg eingesetzt wird. Laut dem Vertreter der Abteilung können bis zu 10 Jahre von der Forschung bis zu Technologien vergehen, die für den Einsatz durch einen Soldaten geeignet sind.
Ananthram Swami, ein Forscher am US Army Laboratory, war kürzlich an mehreren Arbeiten zur KI-Täuschung beteiligt. Die Armee ist an der Aufdeckung und Beendigung betrügerischer Daten in unserer Welt interessiert, in der nicht alle Informationsquellen sorgfältig geprüft werden können. Swami verweist auf eine Reihe von Daten, die von öffentlichen Sensoren an Universitäten stammen und in Open-Source-Projekten arbeiten.
„Wir kontrollieren nicht immer alle Daten. Für unseren Gegner ist es ziemlich einfach, uns auszutricksen “, sagt Swami. "In einigen Fällen können die Folgen eines solchen Betrugs leichtfertig sein, in einigen Fällen das Gegenteil."
Er sagt auch, dass die Armee an autonomen Robotern, Panzern und anderen Fahrzeugen interessiert ist, so dass das Ziel dieser Forschung offensichtlich ist. Durch die Untersuchung dieser Themen kann die Armee einen Vorsprung bei der Entwicklung von Systemen gewinnen, die keinen derartigen Angriffen ausgesetzt sind.
Jede Gruppe, die ein neuronales Netzwerk verwendet, sollte jedoch Bedenken hinsichtlich der Möglichkeit von Angriffen mit KI-Spoofing haben. Maschinelles Lernen und KI stecken noch in den Kinderschuhen, und Sicherheitslücken können derzeit schwerwiegende Folgen haben. Viele Unternehmen vertrauen hochsensiblen Informationen auf KI-Systeme, die den Test der Zeit nicht bestanden haben. Unsere neuronalen Netze sind noch zu jung, um alles zu wissen, was wir über sie brauchen.
Ein ähnliches Versehen führte dazu, dass
Microsofts Twitter-Bot Tay schnell zu einem Rassisten mit einer Vorliebe für Völkermord wurde. Der Fluss bösartiger Daten und die Funktion „Nach mir wiederholen“ führten dazu, dass Tay stark vom beabsichtigten Pfad abwich. Der Bot wurde durch minderwertige Eingaben ausgetrickst, und dies ist ein praktisches Beispiel für eine schlechte Implementierung des maschinellen Lernens.
Kanchelyan glaubt nicht, dass die Möglichkeiten für solche Angriffe nach erfolgreicher Recherche durch das Google-Team ausgeschöpft sind.
"Im Bereich der Computersicherheit sind Angreifer immer vor uns", sagt Kanchelyan. "Es wird ziemlich gefährlich sein zu behaupten, dass wir alle Probleme mit der Täuschung neuronaler Netze durch ihr wiederholtes Training gelöst haben."