Network Security Services (
NSS ) ist eine Reihe von Bibliotheken, die bei der plattformübergreifenden Entwicklung sicherer Client- und Serveranwendungen verwendet werden.
Das NSS-Paket bietet wie OpenSSL die Möglichkeit, Befehlszeilenprogramme zum Implementieren verschiedener PKI-Funktionen zu verwenden (Schlüsselgenerierung, Ausstellung von x509v3-Zertifikaten, Arbeiten mit elektronischen Signaturen, TLS-Unterstützung usw.). Mit einem dieser Dienstprogramme, nämlich Pretty-Print (PP), können Sie den Inhalt des x509 v3-Zertifikats und der elektronischen Signatur (pkcs # 7) usw. bequem anzeigen. Darüber hinaus kann das Zertifikat sowohl in DER- als auch in PEM-Codierung vorliegen:
bash-4.3$ pp -h Usage: pp [-t type] [-a] [-i input] [-o output] [-w] [-u] Pretty prints a file containing ASN.1 data in DER or ascii format. -t type Specify input and display type: public-key (pk), certificate (c), certificate-request (cr), certificate-identity (ci), pkcs7 (p7), crl or name (n). (Use either the long type name or the shortcut.) -a Input is in ascii encoded form (RFC1113) -i input Define an input file to use (default is stdin) -o output Define an output file to use (default is stdout) -w Don't wrap long output lines -u Use UTF-8 (default is to show non-ascii as .) bash-4.3$
Darüber hinaus ermöglicht das Vorhandensein des Parameters –u (UTF-8-Codierung) das Anzeigen des Zertifikats in russischer Codierung. Wenn Sie sich jedoch die Screenshots der GUI zu den Befehlszeilenprogrammen des NSS-Pakets genau ansehen, stellen Sie fest, dass einige der Zertifikatdaten einfach verschwunden sind:
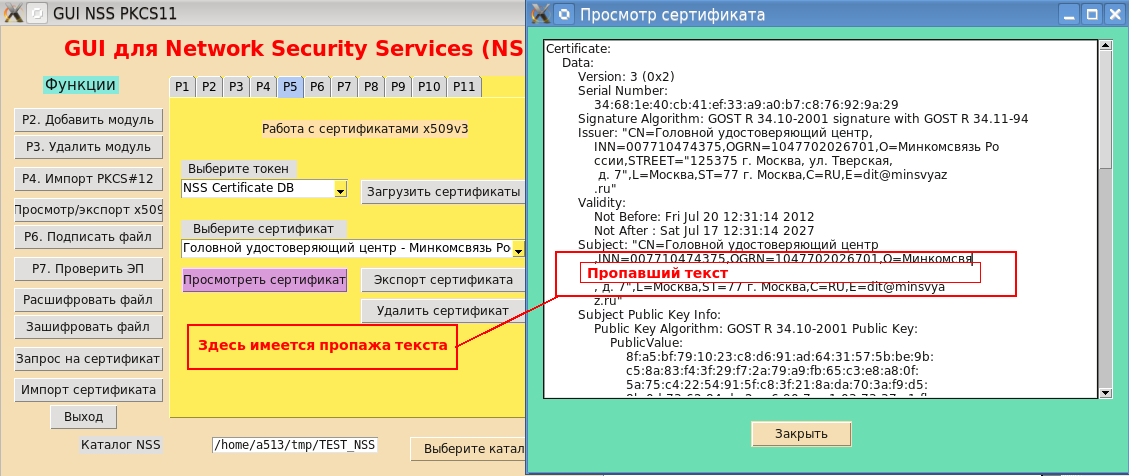
Die Suche nach den fehlenden Informationen begann. Das Dienstprogramm "cute print" (mit dem Pretty-print übersetzt wird) zum Anzeigen des Stammzertifikats der Hauptzertifizierungsstelle des Kommunikationsministeriums wurde über die Befehlszeile gestartet:
$pp – certificate –u –i _.cer … Subject: "CN= ,INN=007710474375,OGRN=1047702026701,O= ,STREET="125375 . , . , . 7",L=,ST=77 . ,C=RU,E=dit@minsvya z.ru" …. $
Das Ergebnis bestätigte den Datenverlust. Darüber hinaus erschienen zwei nicht anzeigbare Symbole auf dem Bildschirm (eine seitliche Raute von schwarzer Farbe mit einem Fragezeichen? Innen). Die Analyse ergab, dass diese nicht anzeigbaren Zeichen die Codes 0xD0 bzw. 0xBE haben:
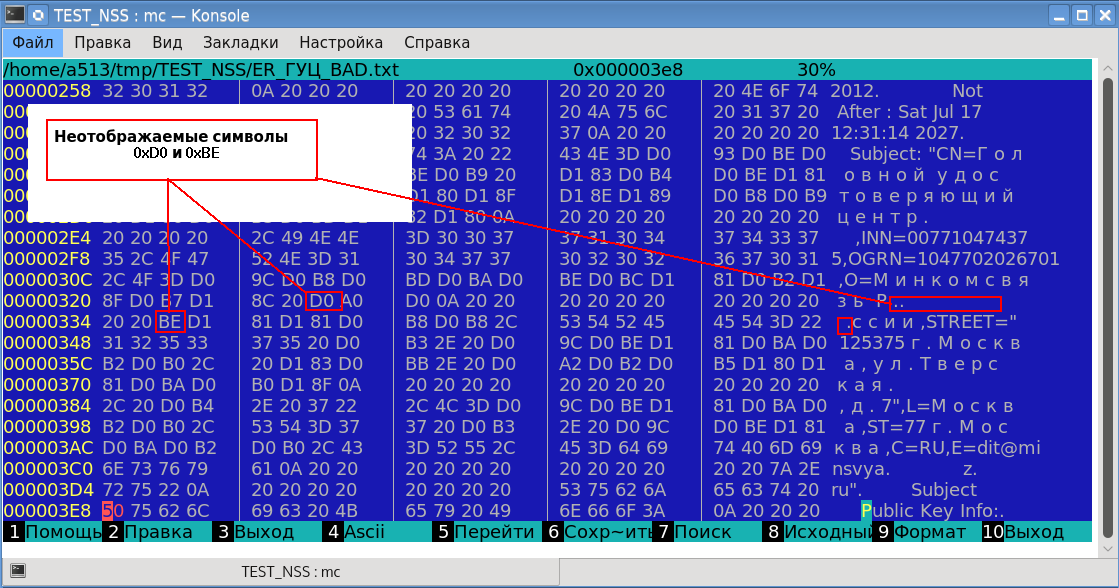
Der russische Buchstabe "o" verschwand mit einer hexadezimalen Darstellung in der UTF-8-Codierung als 0xD00xBE. Und die Codes 0xD0 und 0xBE sind unsere nicht anzeigbaren Zeichen. Und welche Art von Zeichen erschien zwischen diesen Bytes? Und dies ist ein „hübscher“ Druck - Ausrichtungssymbole des gedruckten Textes.
Was ist passiert? Die Eingabe eines "schönen" Drucks (Datei /nss/cmd/lib/secutil.c, Funktion secu_PrintRawStringQuotesOptional) empfängt Daten in Form von SECITEM, d. H. Adressen pro Byte-Array und seine Länge:
for (i = 0; i < si->len; i++) { unsigned char val = si->data[i]; unsigned char c; if (SECU_GetWrapEnabled() && column > 76) { SECU_Newline(out); SECU_Indent(out, level); column = level * INDENT_MULT; } if (utf8DisplayEnabled) { if (val < 32) c = '.'; else c = val; } else { c = printable[val]; } fprintf(out, "%c", c); column++; }
Und wenn (SECU_GetWrapEnabled () == True) für einen schönen Druck bereitgestellt wird (das PP-Dienstprogramm hat keinen –w-Parameter) und die Anzahl der Bytes in einer Zeile 76 überschreitet (Spalte> 76), dann nach dem nächsten Zeichen eine neue Zeile (SECU_Newline) und die erforderlichen Einrückungen (SECU_Indent) ) Gleichzeitig glaubte keiner der Entwickler, dass bei Verwendung der UTF-8-Codierung (utf8DisplayEnabled) die Schönheit erst nach dem nächsten Zeichen und nicht nach dem Byte induziert werden kann, da das Konzept eines Bytes und eines Zeichens in der UTF-8-Codierung möglicherweise nicht übereinstimmt . Wenn wir über russische Buchstaben sprechen, wird jeder von ihnen
in zwei Bytes
codiert . Genau diese Lücke trat bei unserem russischen Buchstaben „o“ (0xD00xBE) auf.
Was ist der Ausweg? In der Funktion secu_PrintRawStringQuotesOptional ist alles sehr einfach genug, um die Zeile zu ersetzen:
if (SECU_GetWrapEnabled() && column > 76) {
in einer Zeile der folgenden Form:
if (SECU_GetWrapEnabled() && column > 76 && (val <= 0x7F || val == 0xD0 || val == 0xD1)) {
Wenn Sie jetzt das PP-Dienstprogramm neu erstellen und im System installieren, rechtfertigt der "schöne" Druck seinen Namen für die "große, mächtige, wahrheitsgemäße und freie russische Sprache"! (I. S. Turgenev):
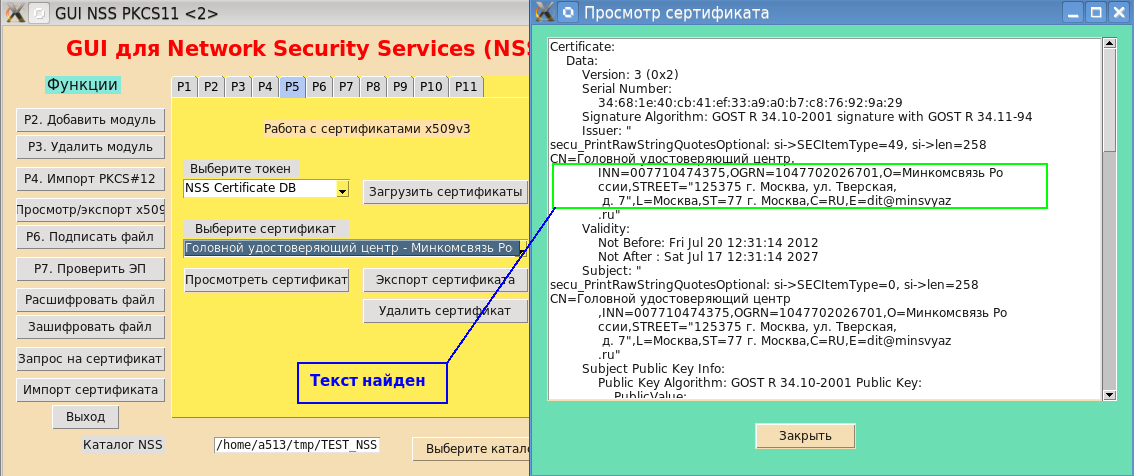
Wenn wir über die Schönheit des Druckens sprechen, wäre es möglich, die Silbentrennung nicht nur nach der Anzahl der Zeichen in der Zeile hinzuzufügen, sondern auch nach Leerzeichen, Komma, Doppelpunkt und anderen Zeichen. Ich spreche nicht von der semantischen Analyse der Übertragung. Dies ist jedoch bereits ein Bereich der künstlichen Intelligenz.
Und schließlich ist dies die zweite entdeckte Ungenauigkeit in den NSS-Dienstprogrammen. Die erste wurde im Dienstprogramm
oidcalc entdeckt .