Die maschinelle Übersetzung mit Hilfe neuronaler Netze hat vom Moment der ersten wissenschaftlichen Forschung zu diesem Thema bis zu dem Zeitpunkt, als Google die
vollständige Übertragung des Google Translate-Dienstes auf Deep Learning ankündigte
, einen langen Weg zurückgelegt .
Wie Sie wissen, ist die Basis des neuronalen Übersetzers der Mechanismus für bidirektionale wiederkehrende neuronale Netze, der auf Matrixberechnungen basiert und es Ihnen ermöglicht, wesentlich komplexere Wahrscheinlichkeitsmodelle als statistische maschinelle Übersetzer zu erstellen. Es wurde jedoch immer angenommen, dass die neuronale Übersetzung ebenso wie die statistische Übersetzung parallele zweisprachige Texte für das Training erfordert. An diesen Gebäuden wird ein neuronales Netzwerk trainiert, das eine menschliche Übersetzung als Referenz verwendet.
Wie sich jetzt herausstellte, können neuronale Netze auch ohne paralleles Textkorpus eine neue Sprache für die Übersetzung beherrschen!
Zwei Arbeiten zu diesem Thema wurden auf der Preprint-Site von arXiv.org veröffentlicht.
„Stellen Sie sich vor, Sie geben einer Person viele chinesische Bücher und viele arabische Bücher - es gibt keine identischen Bücher unter ihnen - und diese Person lernt, vom Chinesischen ins Arabische zu übersetzen. Es scheint unmöglich, oder? Aber wir haben gezeigt, dass ein Computer dazu in der Lage ist “,
sagt Mikel Artetxe, Informatiker an der Universität des Baskenlandes in San Sebastian (Spanien).
Die meisten neuronalen Netze für maschinelle Übersetzung werden „mit einem Lehrer“ unterrichtet, dessen Rolle genau das parallele Korpus von vom Menschen übersetzten Texten ist. Grob gesagt nimmt das neuronale Netzwerk im Lernprozess eine Annahme an, prüft den Standard und nimmt die erforderlichen Einstellungen in seinen Systemen vor und lernt dann weiter. Das Problem ist, dass es für einige Sprachen auf der Welt nicht viele parallele Texte gibt, weshalb sie für herkömmliche neuronale Netze mit maschineller Übersetzung nicht verfügbar sind.
Zwei neue Modelle bieten einen neuen Ansatz: das Unterrichten eines neuronalen Netzwerks für maschinelle Übersetzung
ohne Lehrer . Das System selbst versucht, eine Art paralleles Textkorpus zu bilden, in dem Wörter umeinander gruppiert werden. Tatsache ist, dass es in den meisten Sprachen der Welt die gleichen Bedeutungen gibt, die einfach verschiedenen Wörtern entsprechen. Alle diese Bedeutungen sind also in identischen Clustern zusammengefasst, dh dieselben Wortbedeutungen sind fast unabhängig von der Sprache um dieselben Wortbedeutungen gruppiert (siehe den Artikel „
Google Translate Neural Network hat eine einheitliche Basis der Bedeutungen menschlicher Wörter zusammengestellt “). .
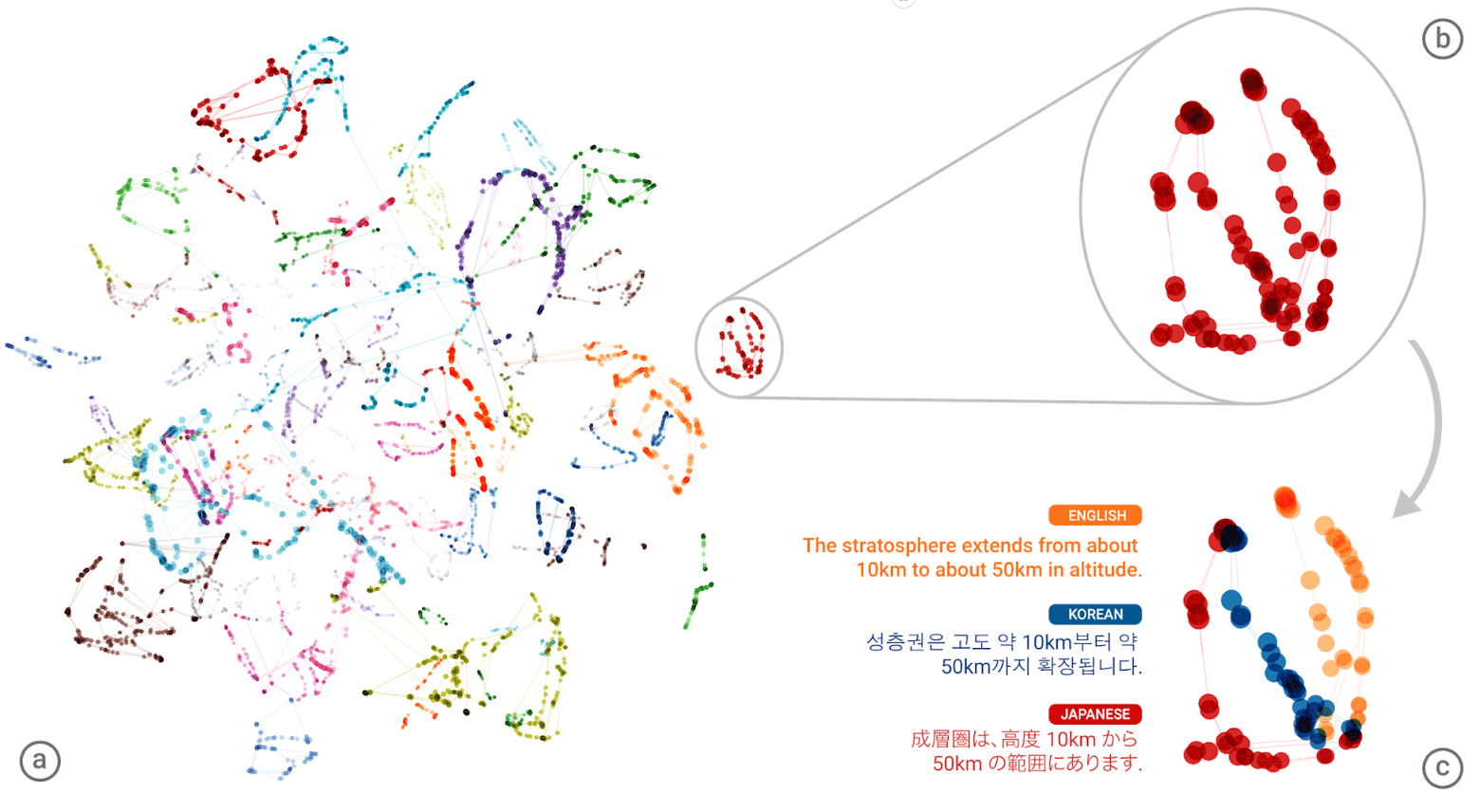 Die „universelle Sprache“ des neuronalen Netzwerks von Google Neural Machine Translation (GNMT). Bedeutungscluster jedes Wortes sind in der linken Abbildung in verschiedenen Farben dargestellt. Die unteren Bedeutungen sind die Wortbedeutungen, die für dieses Wort aus verschiedenen menschlichen Sprachen erhalten wurden: Englisch, Koreanisch und Japanisch
Die „universelle Sprache“ des neuronalen Netzwerks von Google Neural Machine Translation (GNMT). Bedeutungscluster jedes Wortes sind in der linken Abbildung in verschiedenen Farben dargestellt. Die unteren Bedeutungen sind die Wortbedeutungen, die für dieses Wort aus verschiedenen menschlichen Sprachen erhalten wurden: Englisch, Koreanisch und JapanischNachdem das System für jede Sprache einen gigantischen „Atlas“ erstellt hat, versucht es, einen solchen Atlas einem anderen zu überlagern - und hier sind Sie bereit für eine Art parallelen Textkorpus!
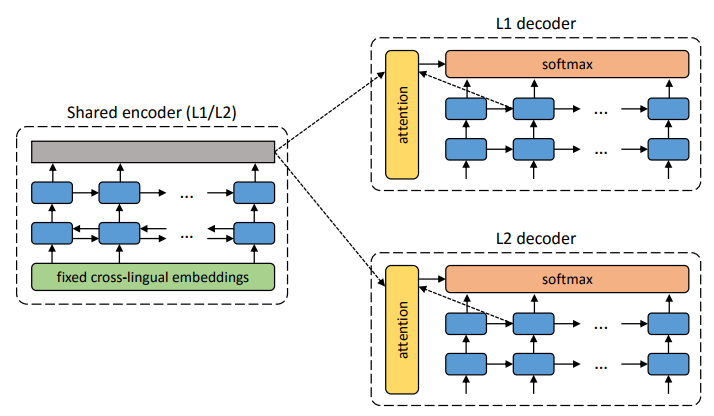
Sie können die Muster der beiden vorgeschlagenen lehrerlosen Lernarchitekturen vergleichen.
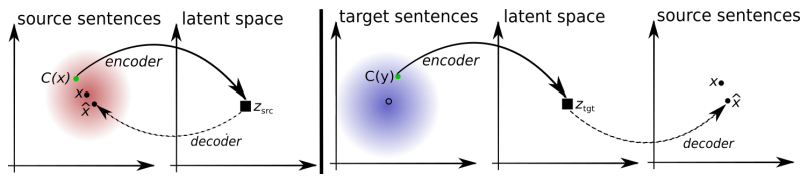
 Die Architektur des vorgeschlagenen Systems. Für jeden Satz in der L1-Sprache lernt das System, zwei Schritte abzuwechseln : 1) Entrauschen , wodurch die Wahrscheinlichkeit optimiert wird, eine verrauschte Version des Satzes mit einem gemeinsamen Codierer zu codieren und durch den L1-Decodierer zu rekonstruieren; 2) Rückübersetzung, wenn ein Satz im Ausgabemodus übersetzt wird (d. H. Von einem gemeinsamen Codierer codiert und von einem L2-Decodierer decodiert), und dann die Wahrscheinlichkeit, diesen übersetzten Satz mit einem gemeinsamen Codierer zu codieren und den ursprünglichen Satz durch einen L1-Decodierer wiederherzustellen, optimiert wird. Illustration: wissenschaftlicher Artikel von Mikel Artetks et al.
Die Architektur des vorgeschlagenen Systems. Für jeden Satz in der L1-Sprache lernt das System, zwei Schritte abzuwechseln : 1) Entrauschen , wodurch die Wahrscheinlichkeit optimiert wird, eine verrauschte Version des Satzes mit einem gemeinsamen Codierer zu codieren und durch den L1-Decodierer zu rekonstruieren; 2) Rückübersetzung, wenn ein Satz im Ausgabemodus übersetzt wird (d. H. Von einem gemeinsamen Codierer codiert und von einem L2-Decodierer decodiert), und dann die Wahrscheinlichkeit, diesen übersetzten Satz mit einem gemeinsamen Codierer zu codieren und den ursprünglichen Satz durch einen L1-Decodierer wiederherzustellen, optimiert wird. Illustration: wissenschaftlicher Artikel von Mikel Artetks et al.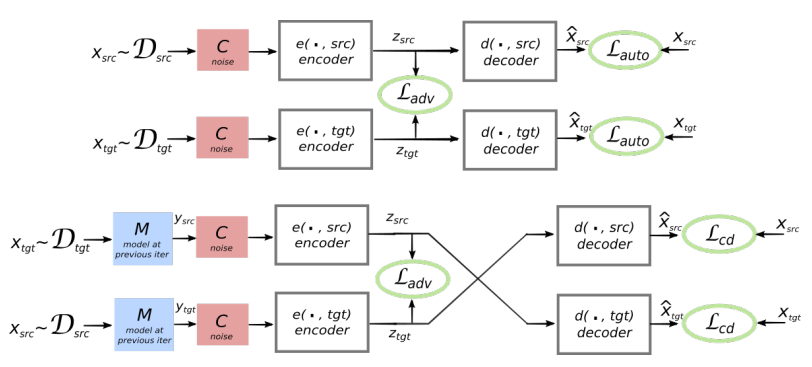 Die vorgeschlagene Architektur und Lernziele des Systems (aus der zweiten wissenschaftlichen Arbeit). Die Architektur ist ein Satzübersetzungsmodell, bei dem sowohl der Codierer als auch der Decodierer in zwei Sprachen arbeiten, abhängig von der Kennung der Eingabesprache, die die Suchtabellen austauscht. Oben (automatische Codierung): Das Modell lernt, wie in jeder Domäne eine Rauschunterdrückung durchgeführt wird. Unten (Übersetzung): Nach wie vor codieren wir aus einer anderen Sprache und verwenden als Eingabe die vom Modell in der vorherigen Iteration erzeugte Übersetzung (blaues Rechteck). Grüne Ellipsen kennzeichnen Begriffe in der Verlustfunktion. Illustration: wissenschaftlicher Artikel von Guillaume Lampl et al.
Die vorgeschlagene Architektur und Lernziele des Systems (aus der zweiten wissenschaftlichen Arbeit). Die Architektur ist ein Satzübersetzungsmodell, bei dem sowohl der Codierer als auch der Decodierer in zwei Sprachen arbeiten, abhängig von der Kennung der Eingabesprache, die die Suchtabellen austauscht. Oben (automatische Codierung): Das Modell lernt, wie in jeder Domäne eine Rauschunterdrückung durchgeführt wird. Unten (Übersetzung): Nach wie vor codieren wir aus einer anderen Sprache und verwenden als Eingabe die vom Modell in der vorherigen Iteration erzeugte Übersetzung (blaues Rechteck). Grüne Ellipsen kennzeichnen Begriffe in der Verlustfunktion. Illustration: wissenschaftlicher Artikel von Guillaume Lampl et al.Beide wissenschaftlichen Arbeiten verwenden eine deutlich ähnliche Technik mit geringfügigen Unterschieden. In beiden Fällen erfolgt die Übersetzung jedoch durch eine Zwischensprache oder besser durch eine Zwischendimension oder einen Zwischenraum. Bisher weisen neuronale Netze ohne Lehrer keine sehr hohe Übersetzungsqualität auf, aber die Autoren sagen, dass es leicht zu verbessern ist, wenn Sie ein wenig Hilfe von einem Lehrer verwenden, gerade jetzt, um die Reinheit des Experiments zu gewährleisten, das sie nicht hatten.
Beachten Sie, dass die zweite wissenschaftliche Arbeit von Forschern der Facebook AI-Abteilung veröffentlicht wurde.
Die Arbeiten werden für die Internationale Konferenz über lernende Repräsentationen 2018 vorgestellt. Keiner der Artikel wurde bisher in der wissenschaftlichen Presse veröffentlicht.