Anfang November 2017 hat Qualcomm Datacenter Technologies (QDT) die Arbeiten an seiner neuen Idee - einem Prozessor auf Basis der 10-nm-Technologie - Centriq 2400 abgeschlossen. Welche Zukunft erwartet die Branche nach Ansicht der Entwickler dieser Innovation? Was sind die Vorteile von Servern und warum ist der Centriq 2400 so einzigartig? Lesen Sie mehr darüber und mehr.
Am 8. November fand in San Jose (Kalifornien) eine Pressekonferenz von QDT statt, bei der der Beginn der Auslieferung des neuen Prozessors offiziell angekündigt wurde. Anand Chandrasekher, Senior Vice President und Chief Executive Officer, sagte:
Die heutige Präsentation ist eine wichtige Errungenschaft und der Höhepunkt von mehr als 4 Jahren sorgfältigen Entwurfs, der Entwicklung und des Supports des Systems ... Wir haben den fortschrittlichsten Serverprozessor der Welt entwickelt, der hohe Leistung bei gleichzeitig hoher Energieeffizienz bietet und es unseren Kunden ermöglicht, ihre Kosten erheblich zu senken.
Neben dem offensichtlichen Stolz auf ihr Produkt scheuen sich Unternehmensvertreter nicht, zu erklären, dass ihr Centriq 2400-Prozessor Konkurrenzprodukten wie Intel Xeon Platinum 8180 deutlich überlegen ist. Nach ihren Berechnungen erhält der Benutzer für jeden ausgegebenen Dollar (und die Kosten des Prozessors 1995 US-Dollar) Leistung 4 mal. Und bei einer Neuberechnung der Leistung um 1 Watt - um 45% mehr. Mutige Aussagen, die viele Vertreter verschiedener Unternehmen, die an dem neuen Produkt interessiert sind, sind jedoch mehr als erfreut, sie zu hören.
Technische Daten des Qualcomm Centriq 2400
CPU-Architektur:- bis zu 48 64-Bit-Kerne mit einer Spitzenfrequenz von 2,6 GHz;
- Armv8-Kompatibilität
- Nur AArch64;
- Armv8 FP / SIMD;
- Erweiterung von CRC und Armv8 Crypto;
CPU-Cache:- 64 Kb Cache mit Anweisungen (Anweisungen) L1 und 24 Kb Einzelzyklus-Cache L0;
- 32 Kb L1-Datencache;
- 512 KB des gesamten L2-Cache pro 2 Kerne;
- 60 MB gemeinsam genutzter L3-Cache;
- Filtern von Interprozessoranforderungen L2;
- QoS;
wobei L (L1, L2, L3, L0) der Pegel ist, d.h. L0 ist der Nullpegel.Technologie:- Samsungs 10-nm-FinFET-Technologie;
Speicherbandbreite:- 6 Kanäle zum Anschluss von DDR4-Speichermodulen;
- bis zu 2667 MT / s pro Verbindung;
- 128 GB / s - maximale Gesamtbandbreite;
- Integrierte Bandbreitenkomprimierung
Speicherkapazität:- 768 GB = 128 GB x 6 Verbindungen;
Speichertyp:- 64-Bit-DDR4-Verbindungen mit 8-Bit-ECC;
- RDIMM und LRDIMM;
Unterstützte Schnittstelle:- GPIO
- I²C;
- SPI
- 8-Band-SATA-Gen 3;
- 32 PCIe Gen3 mit der Möglichkeit, bis zu 6 PCIe-Controller anzuschließen;
Zusätzlich zu den obigen Eigenschaften ist anzumerken, dass dieser Prozessor 18 Milliarden Transistoren auf jedem Chip hat. Und alle seine Kerne sind durch einen bidirektionalen Ringbus verbunden. Bei maximaler Belastung verbraucht der Centriq 2400 nur 120 Watt.
Das Hauptaugenmerk des neuen Prozessors liegt nach wie vor auf Cloud-Lösungen. Laut Unternehmensvertretern können Sie mit Centriq 2400 Serversysteme erstellen, die sich durch hohe Leistung, Effizienz und Skalierbarkeit auszeichnen.
Dies konnte nicht umhin, viele Unternehmen anzulocken, deren Cloud-Technologien fast die Grundlage ihrer Aktivitäten bilden. An der Präsentation nahmen teil: Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Cadence Design Systems, Canonical, Chelsio Communications, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Synopsys, Uber, Xilinx. Die Liste ist ziemlich beeindruckend, was auf eine erhöhte Aufmerksamkeit für dieses Produkt hinweist.
Derzeit gewinnt der Qualcomm Centriq 2400-Prozessor nur an Dynamik, sowohl in der Verbreitung als auch in der Popularität. Was natürlich dazu führen wird, dass bei den Konkurrenten von QDT etwas Neues, Ähnliches oder sogar Produktiveres auftaucht.
Aber nicht jeder glaubt blind an die Coolness neuer Gegenstände. Wenn diejenigen, die glauben, dass die Durchführung von Tests und vergleichenden Analysen mehrerer Prozessoren viel aussagekräftigere Ergebnisse liefert als die Worte der Centriq 2400-Promotoren.
Cloudflare führte eine vergleichende Analyse von drei Plattformen durch: Grantley (Intel), Purley (Intel) und Centriq (Qualcomm).
Nachfolgend werden Grafiken dieser Analyse und die Schlussfolgerungen ihres Autors -
Vlad Krasnov - vorgestellt . (
Original dieser Analyse auf Cloudflares Blog )
Kryptographie mit öffentlichen Schlüsseln
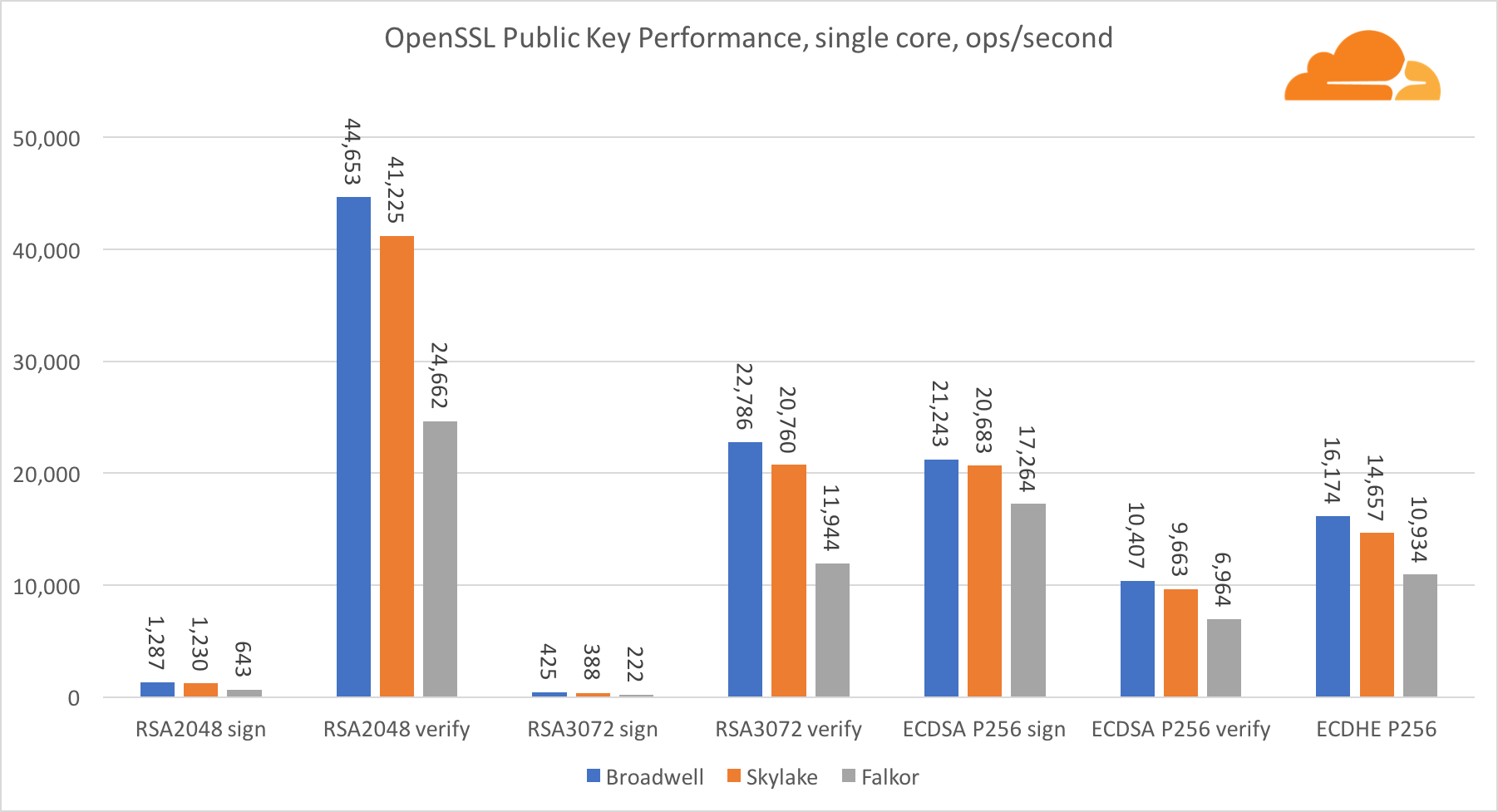
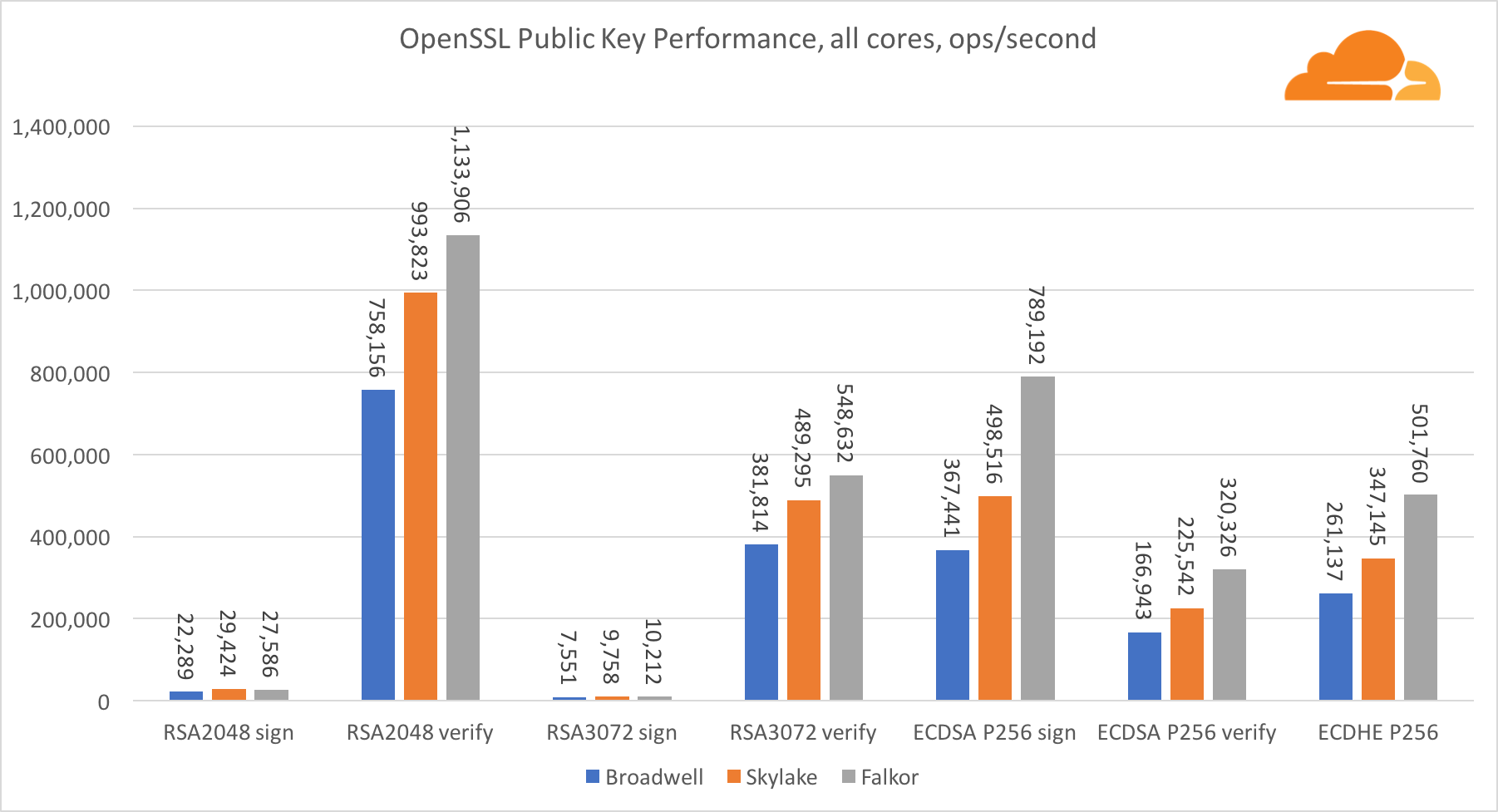
Die Kryptographie mit öffentlichen Schlüsseln ist die reinste Leistung von ALU (arithmetisches Logikgerät). Es ist interessant, aber nicht überraschend, dass in einem grundlegenden Benchmark der Broadwell-Kern schneller als Skylake ist und beide schneller als Falkor. Dies liegt daran, dass Broadwell mit einer höheren Frequenz arbeitet, obwohl es in Bezug auf die Architektur Skylake nicht viel unterlegen ist.
Falkor ist den anderen in diesem Test unterlegen. Erstens wurde der Turbomodus in einem der grundlegenden Benchmarks aktiviert, was bedeutet, dass Intel-Prozessoren mit einer höheren Frequenz arbeiten. Darüber hinaus hat Intel bei Broadwell zwei spezielle Anweisungen eingeführt, um die Verarbeitung großer Zahlen zu beschleunigen: ADCX und ADOX. Sie führen zwei unabhängige Add-with-Carry-Operationen pro Zyklus aus, während ARM nur eine ausführen kann. In ähnlicher Weise verfügt der ARMv8-Befehlssatz nicht über einen einzigen Befehl zum Durchführen einer 64-Bit-Multiplikation, sondern es wird ein Paar von MUL- und UMULH-Befehlen verwendet.
Auf SoC-Ebene gewinnt Falkor jedoch. Es ist in Bezug auf RSA2048 etwas langsamer als Skylake und nur, weil RSA2048 keine für ARM optimierte Implementierung hat. Die Leistung von ECDSA ist lächerlich hoch. Ein einziger Centriq-Chip kann mit ECDSA die Anforderungen fast aller Unternehmen auf der Welt erfüllen.
Es ist auch sehr interessant zu sehen, dass Skylake Broadwell um 30% übertrifft, obwohl es im Test einen Kern verloren hat und nur 20% mehr Kerne als Broadwell hat. Dies kann durch einen effizienteren Turbomodus und ein verbessertes Hyper-Threading erklärt werden.
Symmetrische Kryptographie
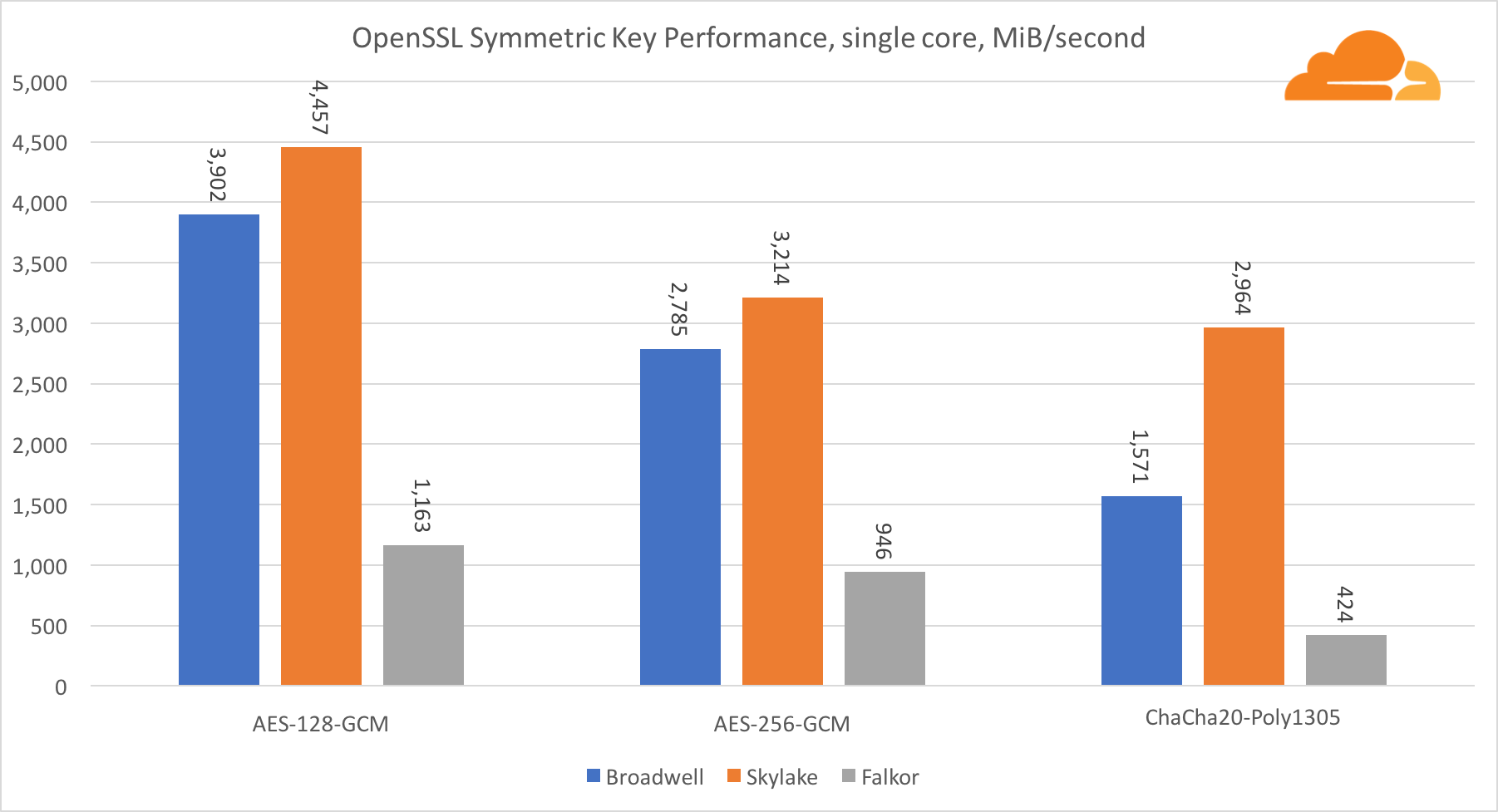
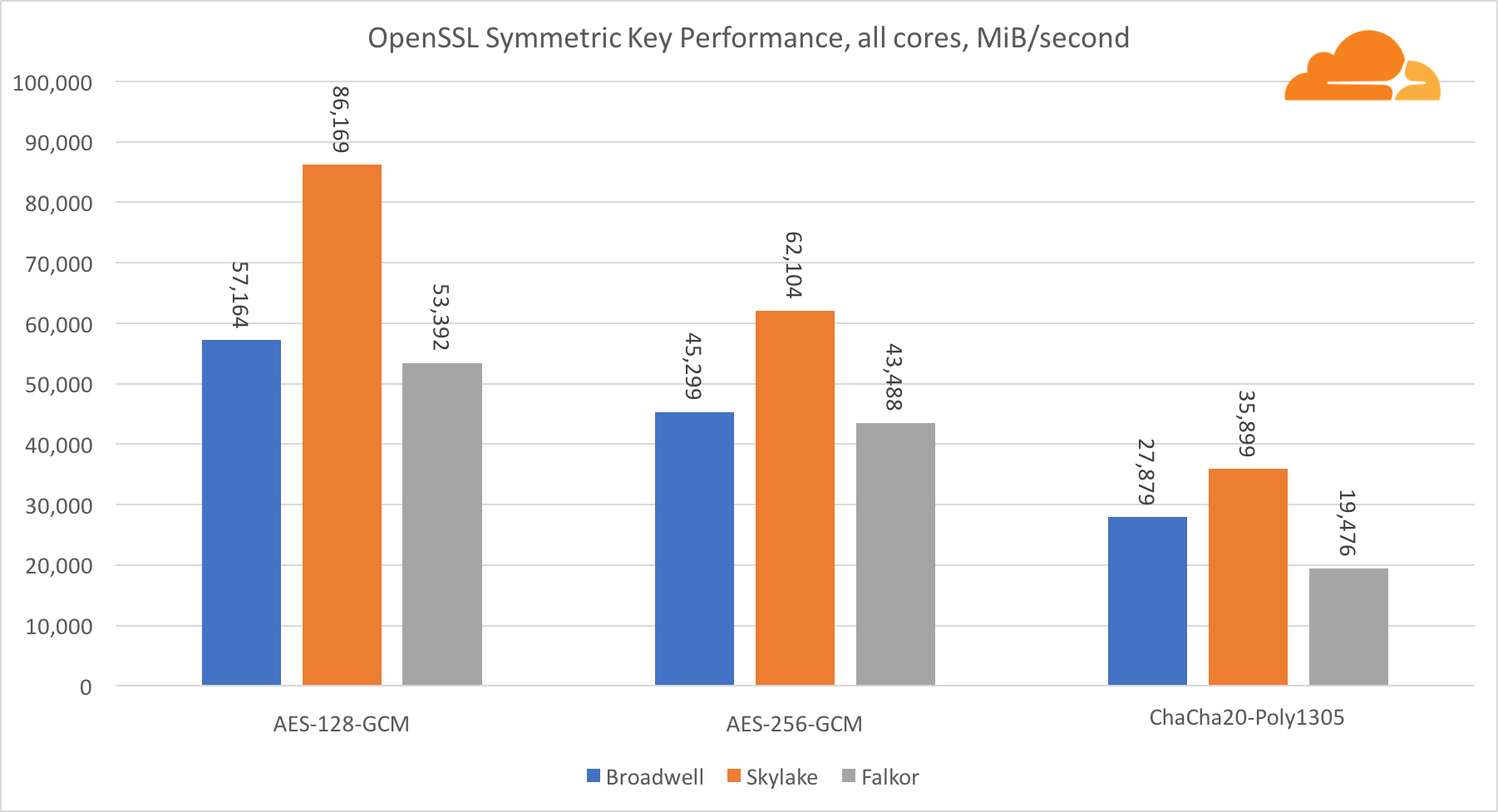
Die Leistung von Intel-Kernen in der symmetrischen Kryptographie ist einfach hervorragend.
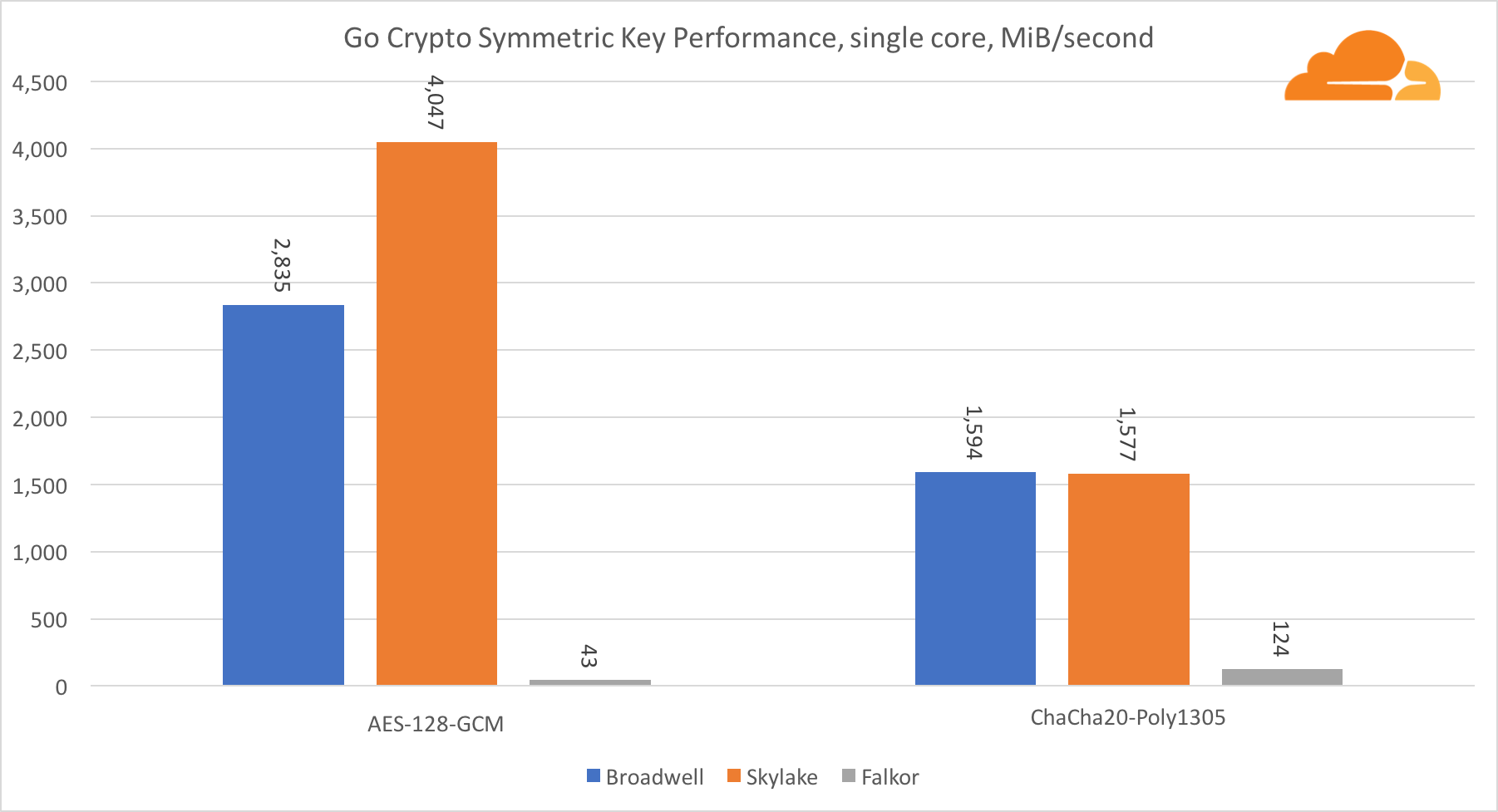
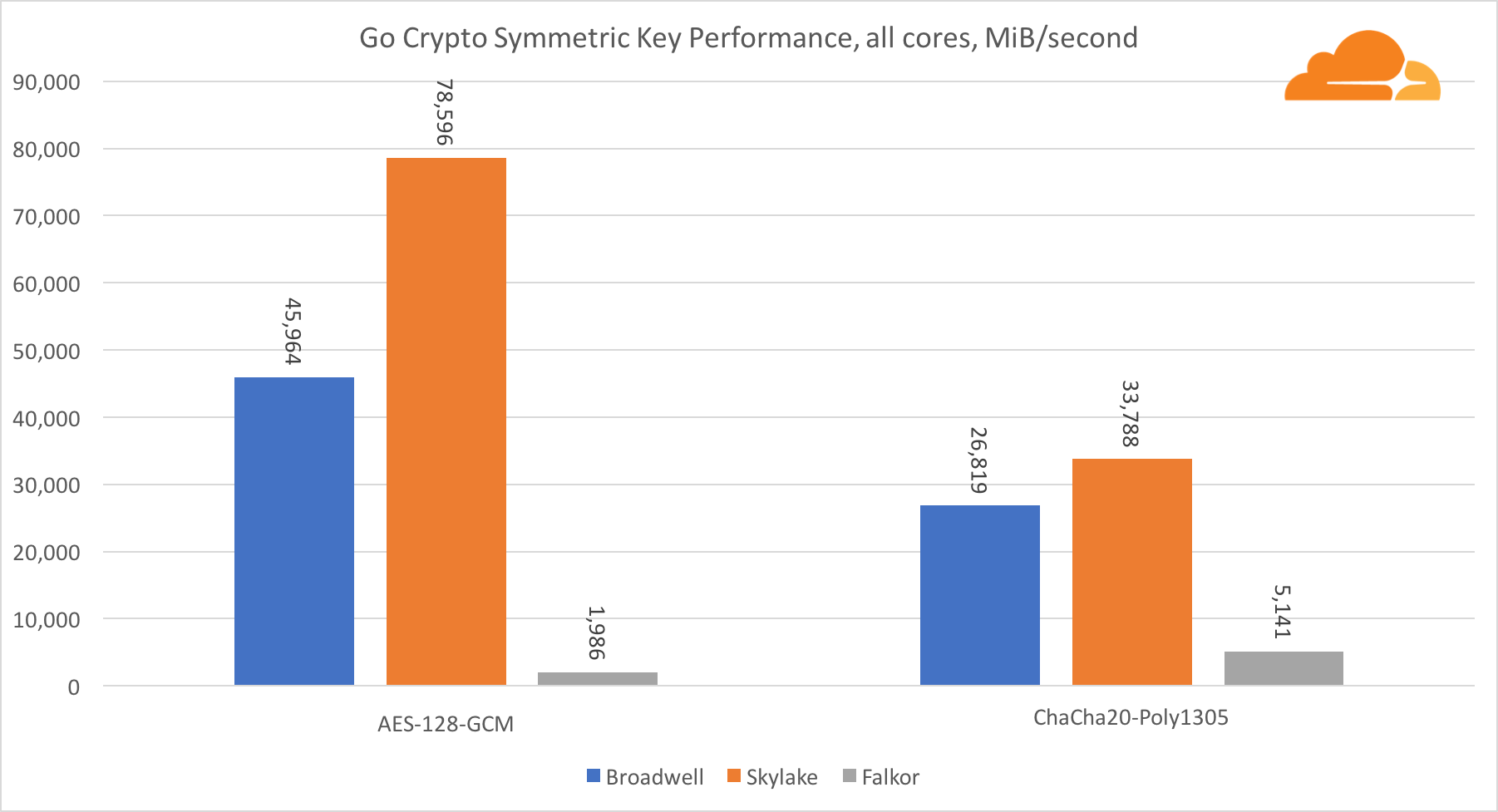
AES-GCM verwendet eine Kombination spezieller Hardwareanweisungen, um AES und CLMUL zu beschleunigen. Intel hat diese Anweisungen bereits 2010 mit seinem Westmere-Prozessor eingeführt und mit jeder Generation ihre Leistung verbessert. ARM hat kürzlich eine Reihe ähnlicher Befehle mit ihrem 64-Bit-Befehlssatz als optionale Ergänzung eingeführt. Glücklicherweise hat jeder mir bekannte Ausrüstungslieferant sie implementiert. Es ist sehr wahrscheinlich, dass Qualcomm die Leistung kryptografischer Anweisungen in zukünftigen Generationen verbessern wird.
ChaCha20-Poly1305 ist ein allgemeinerer Algorithmus, der so konzipiert ist, dass breite SIMD-Module besser genutzt werden können. Qualcomm verfügt nur über 128-Bit-NEON-SIMD, Broadwell über 256-Bit-AVX2 und Skylake über 512-Bit-AVX-512. Dies erklärt, warum Skylake mit einem solchen Vorsprung bei der Bewertung der Arbeit mit einem einzigen Kern an der Spitze blieb. Beim Test aller Kerne wurde gleichzeitig der Abstand von Skylake zum Rest verringert, da die Taktfrequenz bei der Ausführung von AVX-512-Workloads verringert werden sollte. Wenn der AVX-512 auf allen Kernen ausgeführt wird, verringert sich die Grundfrequenz auf 1,4 GHz. Denken Sie daran, wenn Sie AVX-512 und anderen Code mischen.
Die Schlussfolgerung bezüglich der symmetrischen Kryptographie lautet, dass Broadwell und Falkor, obwohl Skylake führend ist, sehr gute Ergebnisse zeigten und in realen Fällen eine recht hohe Leistung zeigten, da RSA auf unserer Seite mehr Prozessorzeit verbraucht als alle anderen kryptografischen Algorithmen zusammen .
Komprimierung (Komprimierung)
Der nächste Test, den ich machen wollte, war die Komprimierung. Aus zwei Gründen. Erstens ist dies eine wichtige Arbeitslast, denn je besser die Komprimierung ist, desto weniger Lücken in der Fähigkeit und dies ermöglicht eine schnellere Bereitstellung von Inhalten an den Client. Zweitens ist dies eine sehr anspruchsvolle Arbeitsbelastung bei der Vorhersage von Hochfrequenzzweigen.
Offensichtlich wird der erste Test die beliebte zlib-Bibliothek sein. Bei Cloudflare verwenden wir eine verbesserte Version der Bibliothek, die für Intel 64-Bit-Prozessoren optimiert ist. Obwohl sie hauptsächlich in C geschrieben ist, werden einige Intel-spezifische integrierte Funktionen verwendet. Es wäre unfair, diese optimierte Version mit der ursprünglichen zlib zu vergleichen. Aber keine Sorge, mit ein wenig Aufwand habe ich die Bibliothek so angepasst, dass sie mit den Eigenschaften NEON und CRC32 auf der ARMv8-Architektur funktioniert. Darüber hinaus ist die Geschwindigkeit bei einigen Dateien doppelt so hoch wie beim Original.
Der zweite Test ist die neue brotli-Bibliothek, die in C geschrieben ist und die Verwendung gleicher Bedingungen für alle Plattformen ermöglicht.
Alle Tests wurden auf HTML blog.cloudflare.com im Speicher durchgeführt, ähnlich wie NGINX die Streaming-Komprimierung durchführt. Es sei denn, die spezifische Version der HTML-Datei ist 29329 Byte, was ein guter Indikator ist, da sie der Größe der meisten von uns komprimierten Dateien entspricht. Der parallele Komprimierungstest ist die parallele Komprimierung mehrerer Dateien gleichzeitig. Die einzelne Komprimierung ist die Komprimierung einer Datei in mehrere Streams, ähnlich wie NGINX.
gzip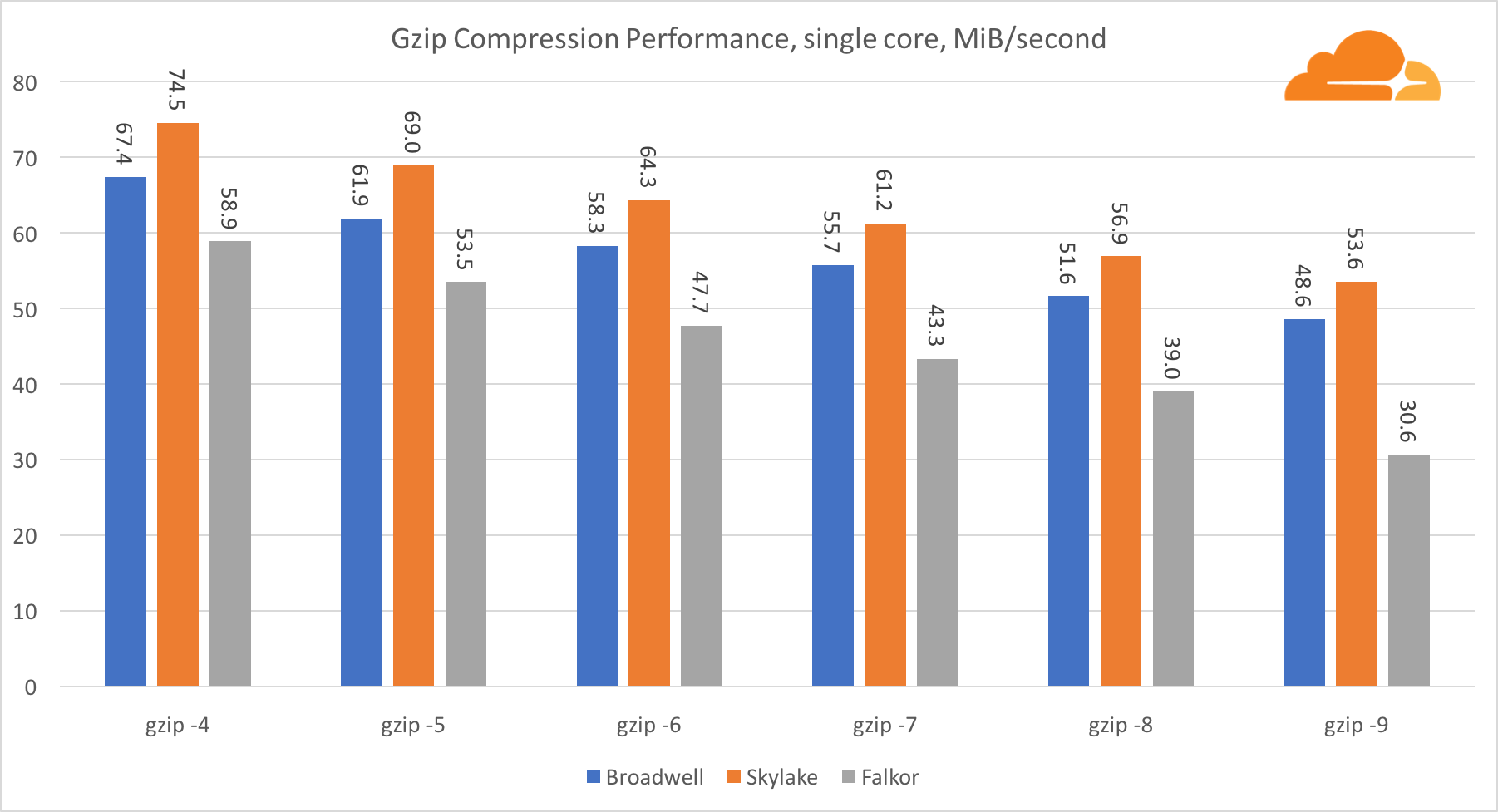
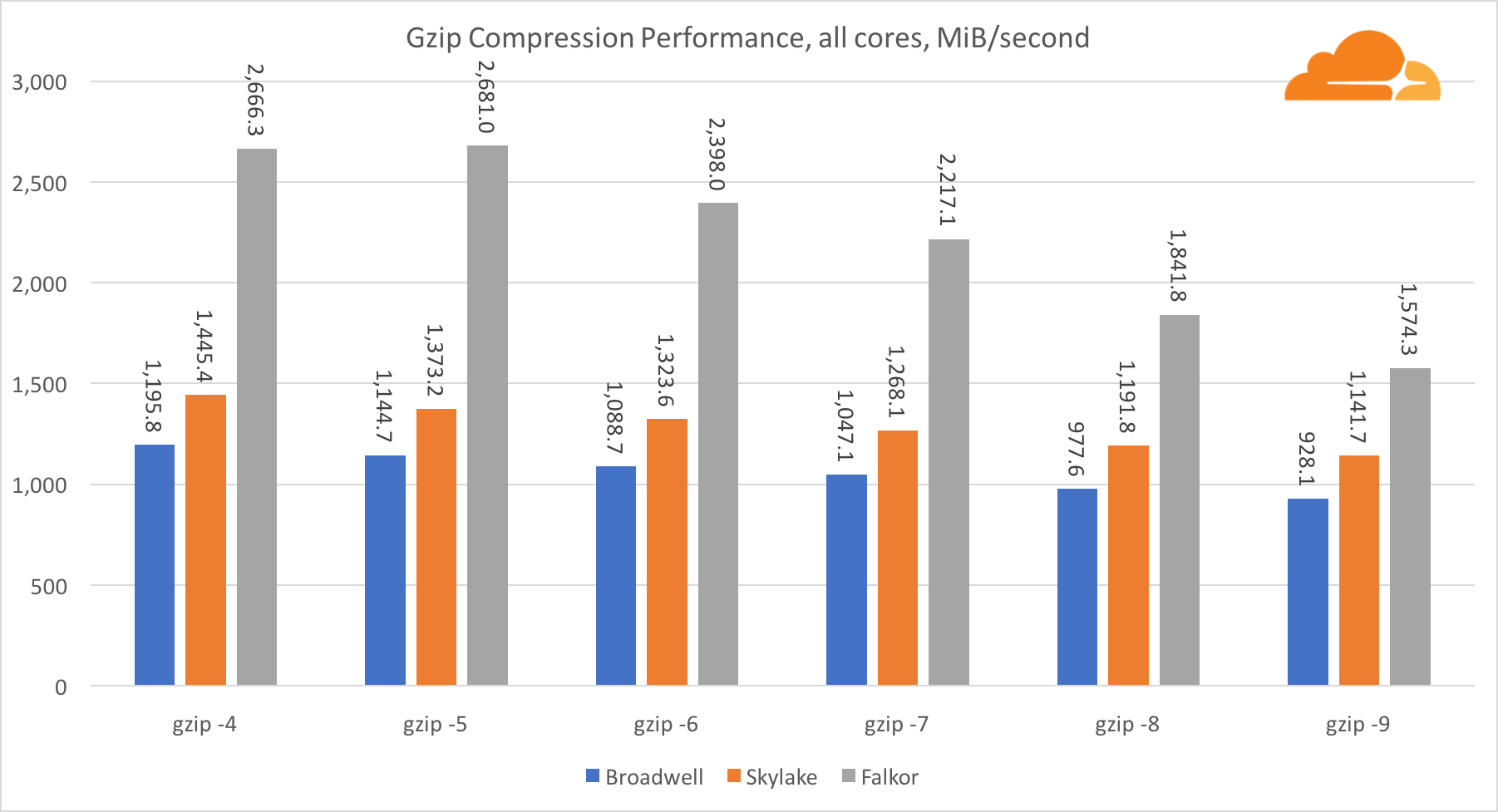
Mit gzip auf der Single-Core-Ebene gewinnt Skylake zweifellos. Mit einer niedrigeren Frequenz als Broadwell profitiert Skylake von einer geringeren Exposition gegenüber Fehlvorhersagen für Zweige. Der Falkor-Kern ist nicht weit dahinter. Auf Systemebene bietet Falkor mit mehr Kernen eine viel bessere Leistung. Beachten Sie, wie sich gzip über mehrere Kerne hinweg gut skalieren lässt.
BrotliMit brotli auf einem Kern ist die Situation ähnlich wie auf dem vorherigen. Skylake ist der schnellste, aber Falkor ist nicht weit dahinter. Und auf Standard 9 ist Falkor noch schneller. Standard 4 Brotli ist gzip Level 5 sehr ähnlich, während die tatsächliche Komprimierung immer noch besser ist (8010B gegenüber 8187B).
Beim Komprimieren auf mehreren Kernen wird die Situation etwas verwirrend. Für die Stufen 4, 5 und 6 skaliert brotli sehr gut. Auf Stufe 7 und 8 beginnt es produktiv auf den Kern zu fallen und sinkt auf Stufe 9 auf den Boden, wo wir dreimal weniger Produktivität aller Kerne erhalten als auf einen.
Meiner Meinung nach liegt dies daran, dass brotli mit jedem Level mehr Speicher verbraucht und den Cache zum Absturz bringt. Die Indikatoren beginnen sich bereits auf den Ebenen 10 und 11 zu erholen.
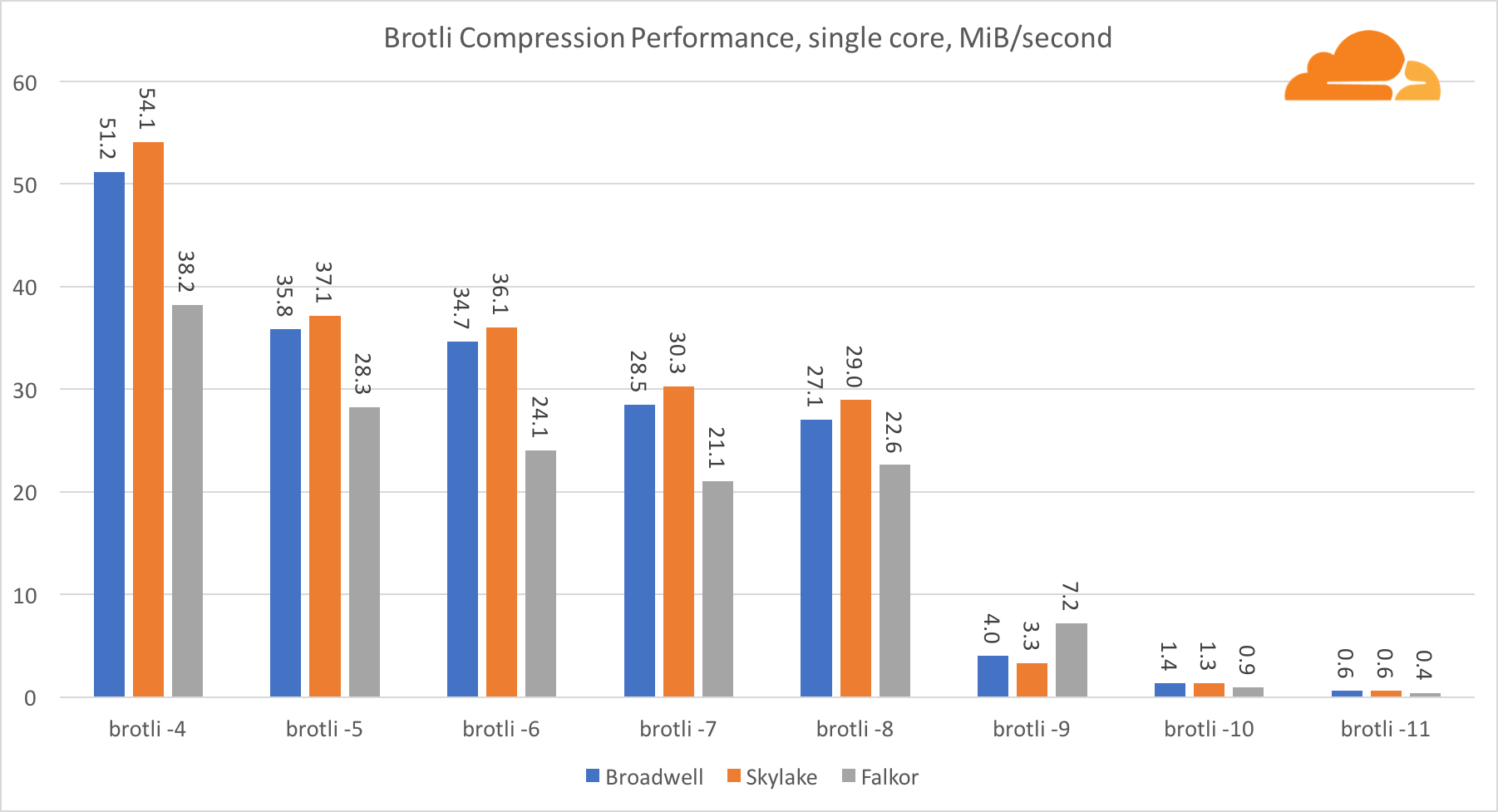
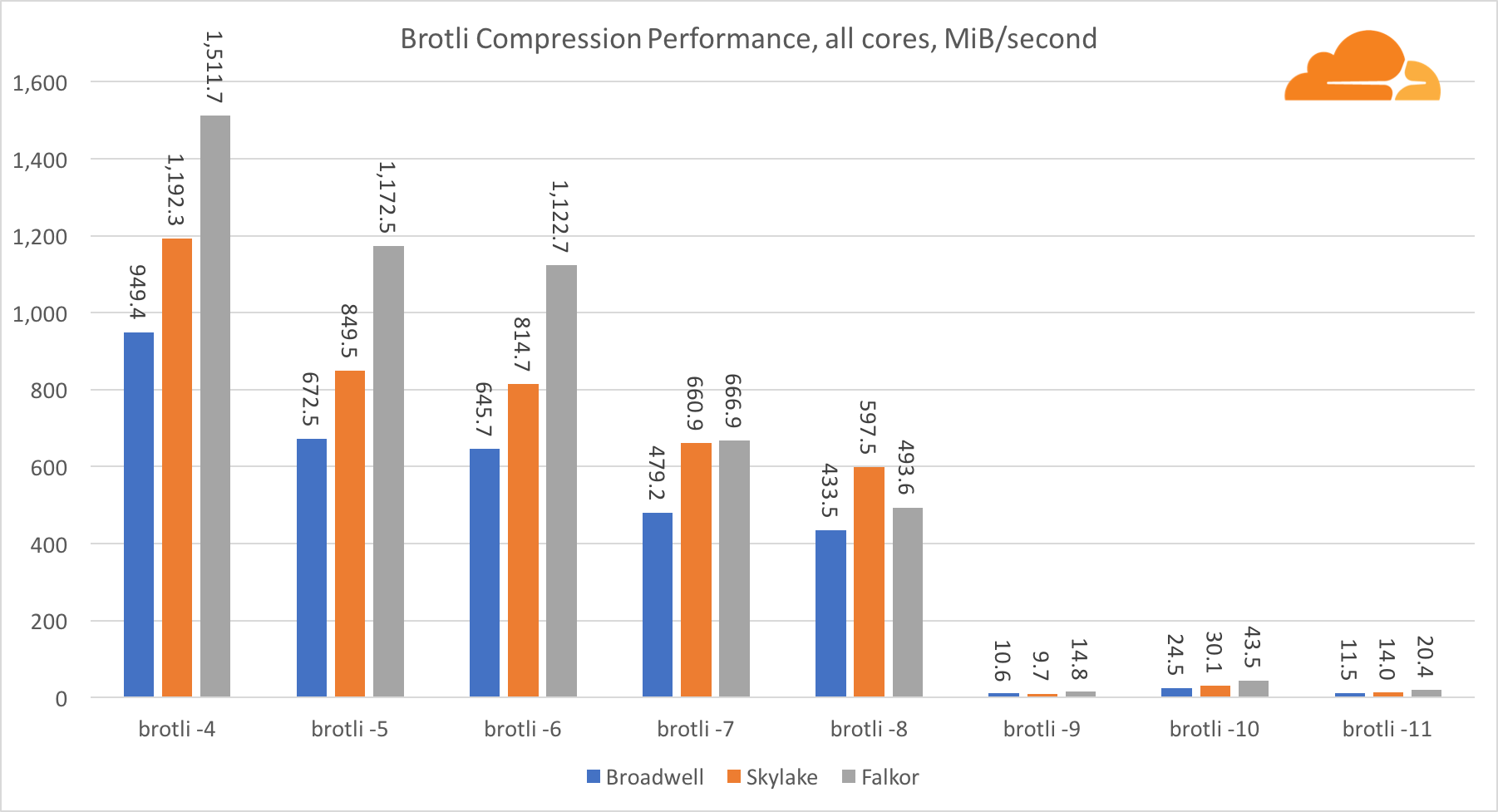
Als Fazit gewann Falkor, da die dynamische Komprimierung nicht über Level 7 hinausgeht.
Golang
Golang ist eine weitere sehr wichtige Sprache für Cloudflare. Es ist auch eine der ersten Sprachen, die ARMv8 unterstützt, sodass Sie eine gute Leistung erwarten können. Ich habe einige eingebaute Tests verwendet, diese jedoch für mehrere Goroutinen geändert.
Gehen Sie KryptoIch möchte mit Tests der Verschlüsselungsleistung beginnen. Dank OpenSSL verfügen wir über hervorragende Quelldaten, und es wird sehr interessant sein zu sehen, wie gut die Go-Bibliothek ist.
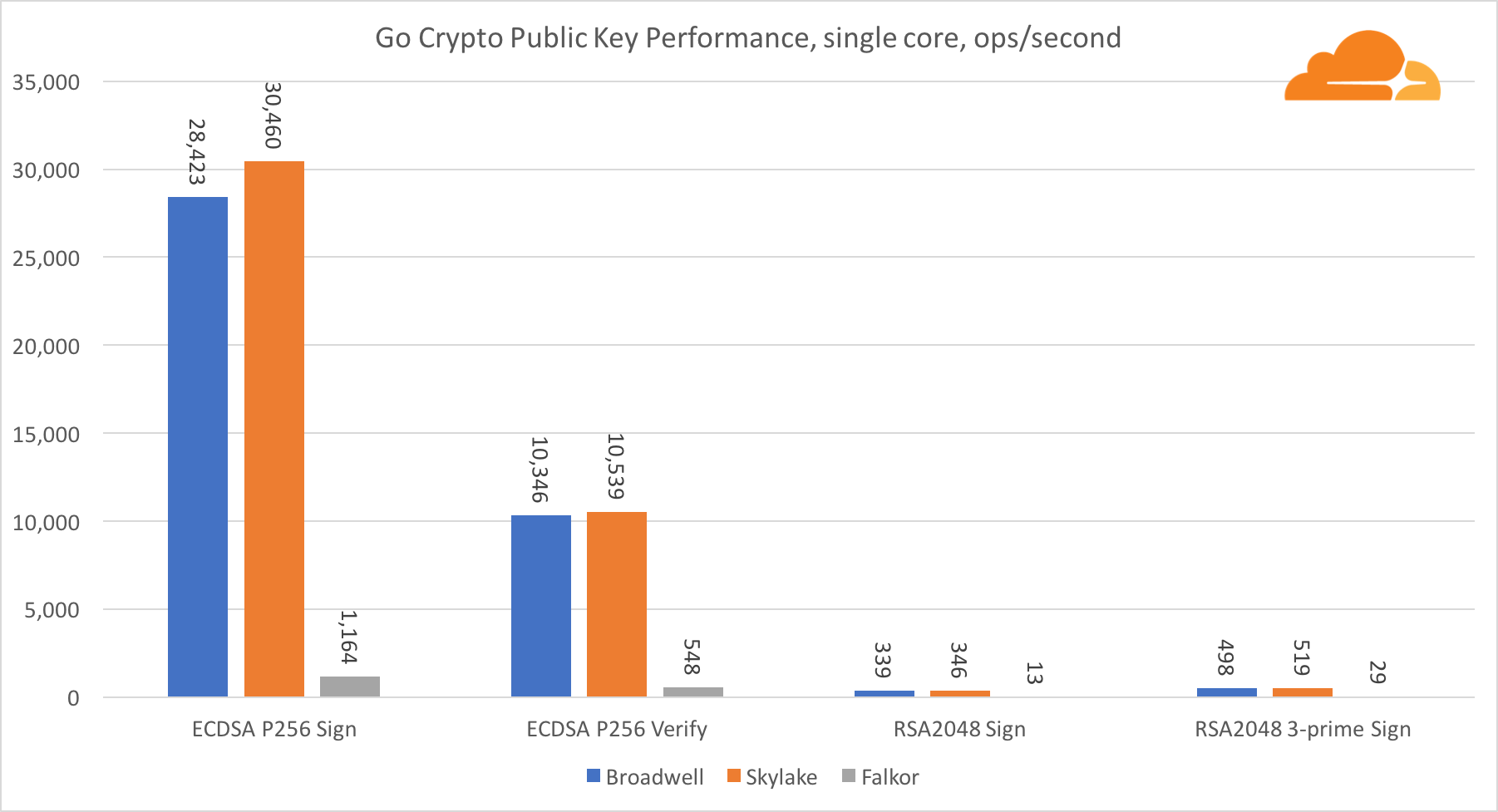
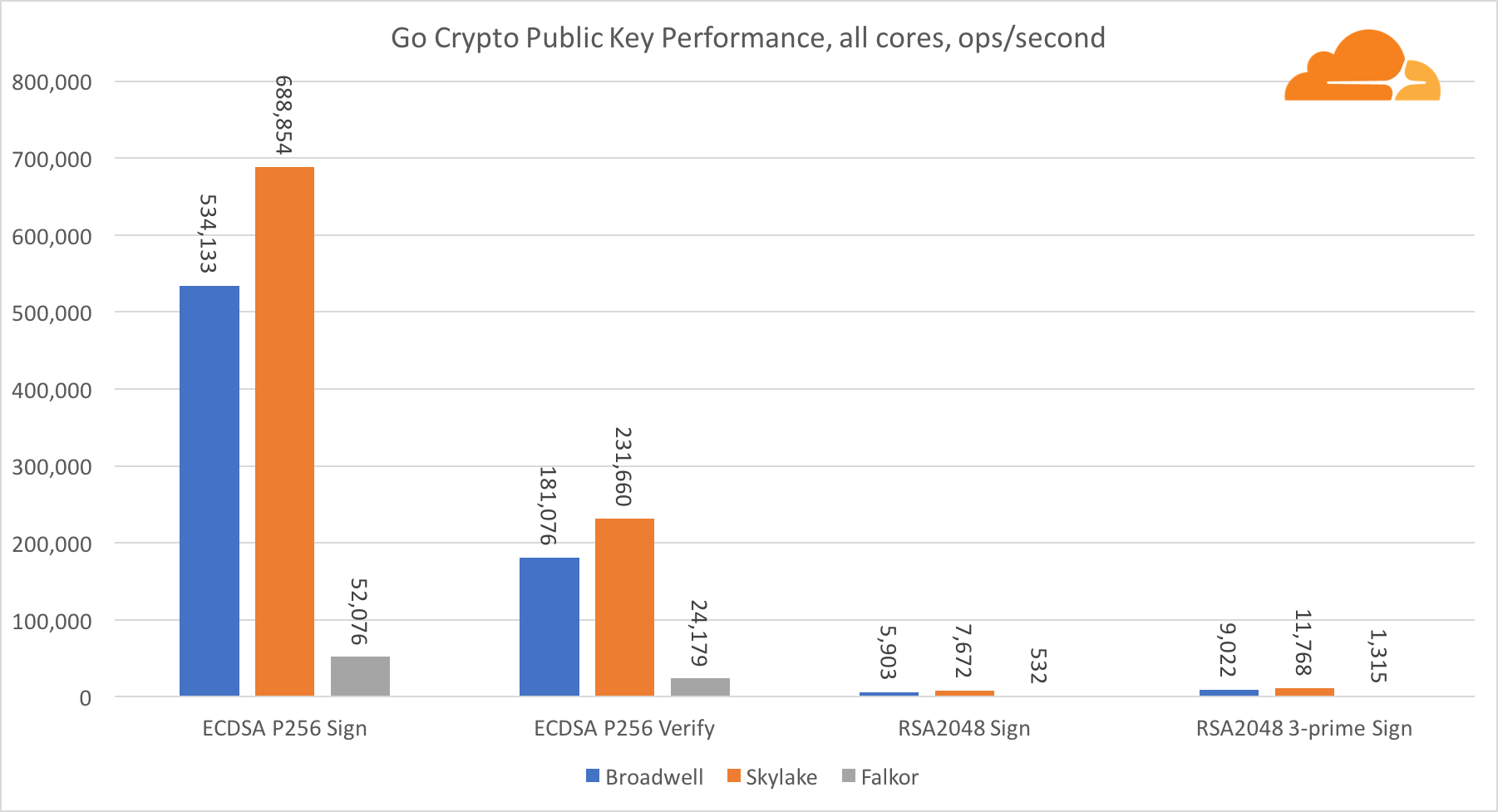
In Bezug auf Go-Krypto gehören ARM und Intel nicht einmal zur gleichen Gewichtsklasse. Go verfügt über einen hochoptimierten Assembler-Code für ECDSA, AES-GCM und Chacha20-Poly1305 unter Intel. Es gibt auch optimierte mathematische Funktionen, die in RSA-Berechnungen verwendet werden. ARMv8 verfügt nicht über all dies, was es in eine sehr nachteilige Position bringt.
Trotzdem kann die Lücke mit relativ geringem Aufwand verringert werden, und wir wissen, dass bei richtiger Optimierung die Leistung mit OpenSSL gleichwertig sein kann. Selbst geringfügige Änderungen, wie die Implementierung der Funktion addMulVVW in der Assembly, führen zu einer Verzehnfachung der RSA-Leistung, wodurch Falkor (mit einer Punktzahl von 8009) sowohl über Broadwell als auch über Skylake liegt.
Eine weitere interessante Sache ist erwähnenswert: Bei Skylake funktioniert der Go Chacha20-Poly1305-Code, der AVX2 verwendet, ähnlich wie der OpenSSL AVX512-Code. Dies liegt wiederum an der Tatsache, dass der AVX2 bei höheren Taktfrequenzen arbeitet.
Gehen Sie gzipSchauen wir uns nun die Go-Leistung von gzip an. Es gibt auch eine großartige Anleitung für ziemlich gut optimierten Code, und wir können ihn mit Go vergleichen. Bei der gzip-Bibliothek gibt es keine spezifischen Optimierungen für Intel.
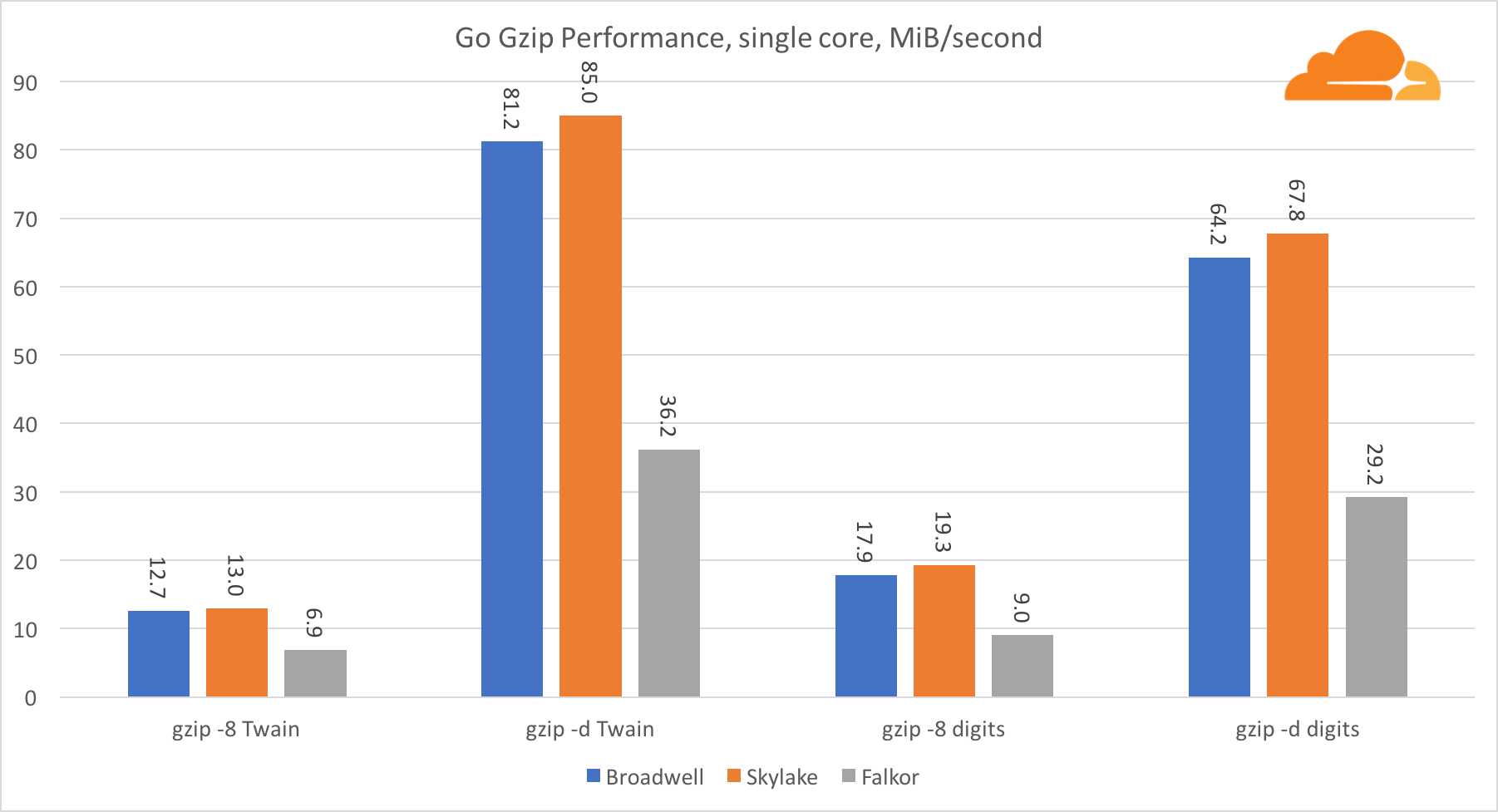

Die Gzip-Leistung ist ziemlich gut. Die Leistung auf einem Single-Core-Falkor liegt deutlich hinter beiden Intel-Prozessoren zurück, aber auf Systemebene gelang es ihm, Broadwell zu schlagen und sich unter Skylake zu befinden. Da wir bereits wissen, dass Falkor den beiden anderen Prozessoren überlegen ist, wenn C ausgeführt wird. Dies kann nur eines bedeuten: Das Go-Backend für ARMv8 ist im Vergleich zu gcc noch nicht abgeschlossen.
Gehen Sie regexpRegexp wird häufig für eine Vielzahl von Aufgaben eingesetzt, da seine Leistung ebenfalls äußerst wichtig ist. Ich habe integrierte Tests für 32-KB-Streams durchgeführt.
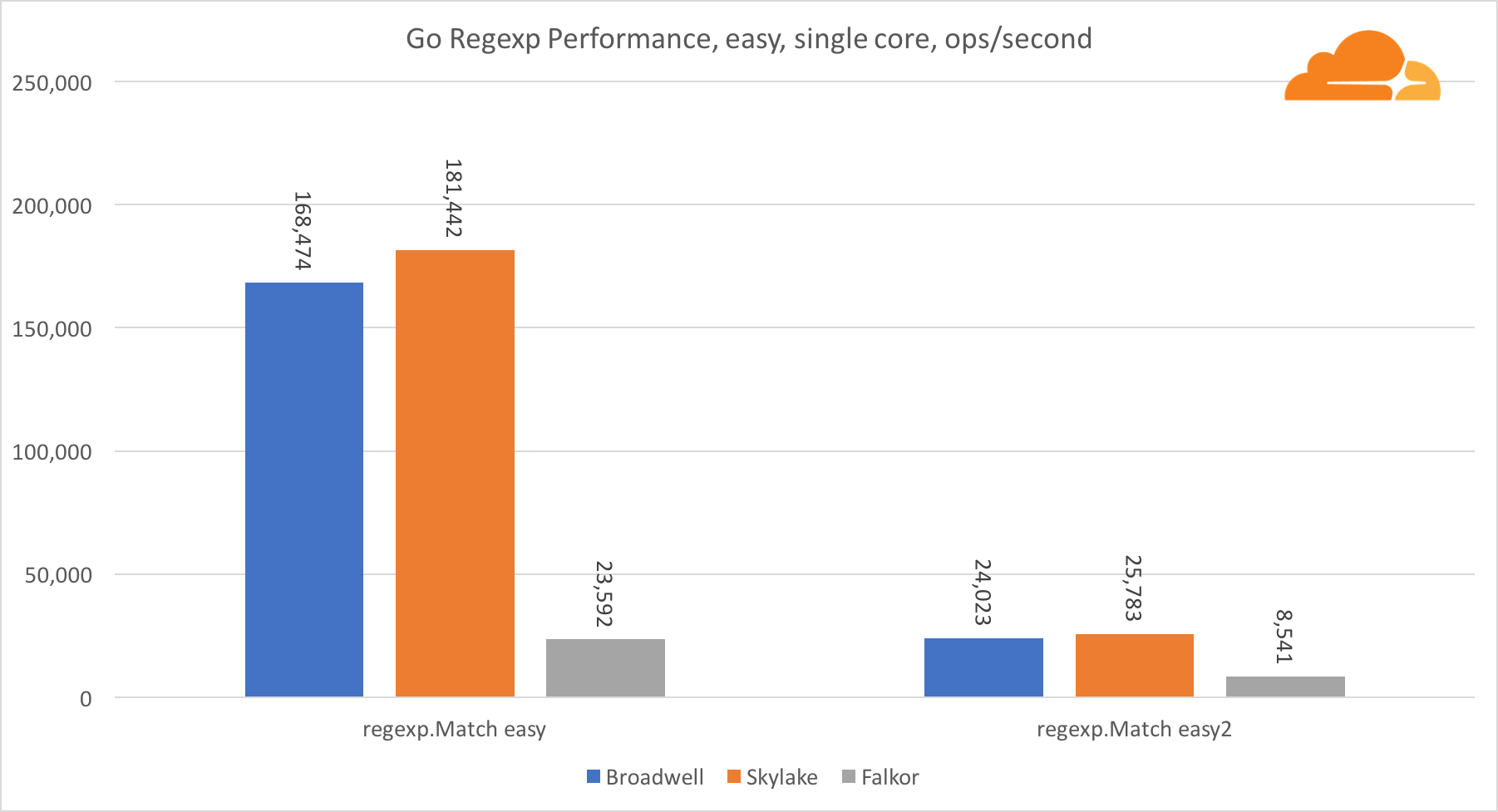
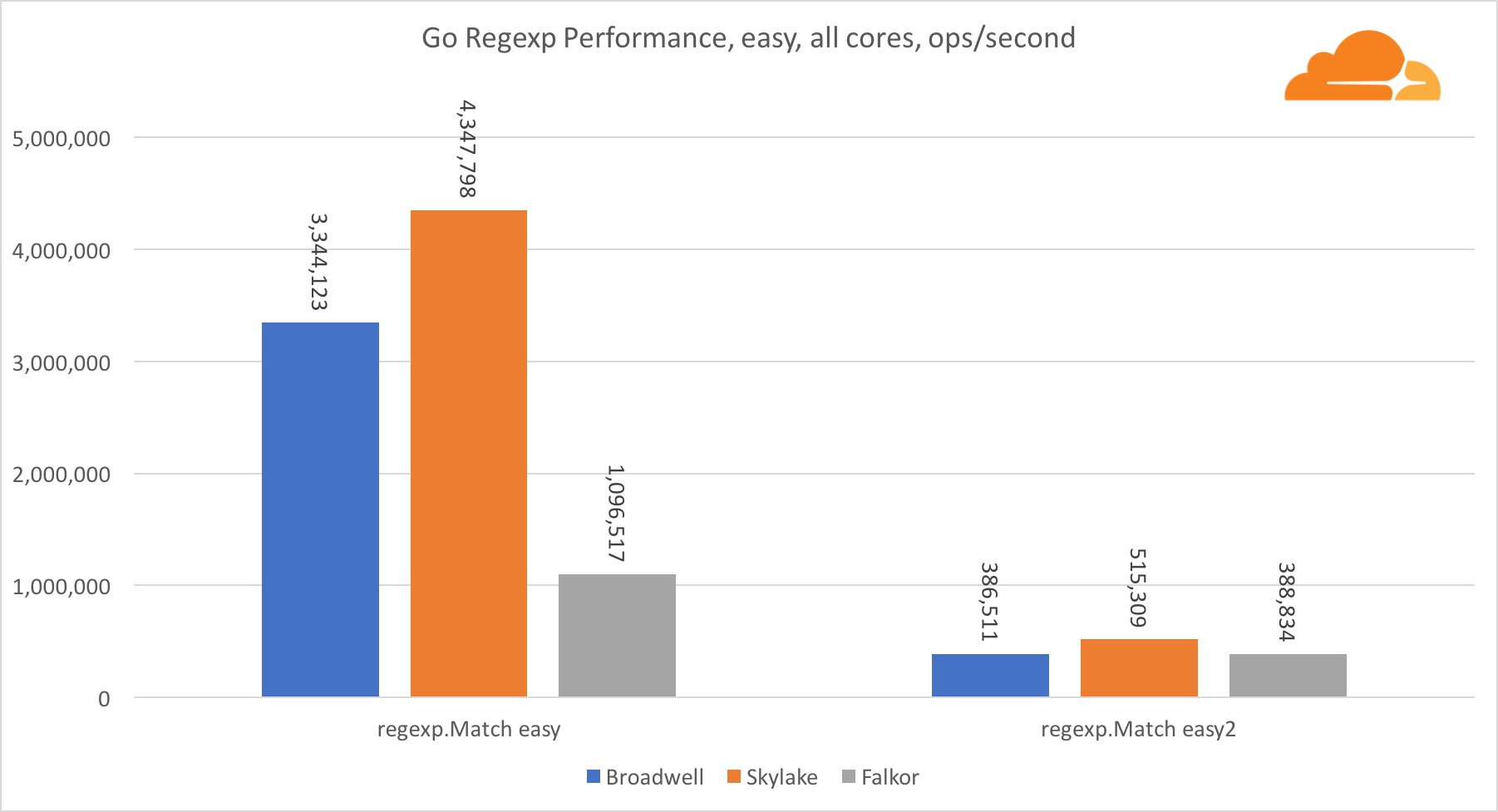
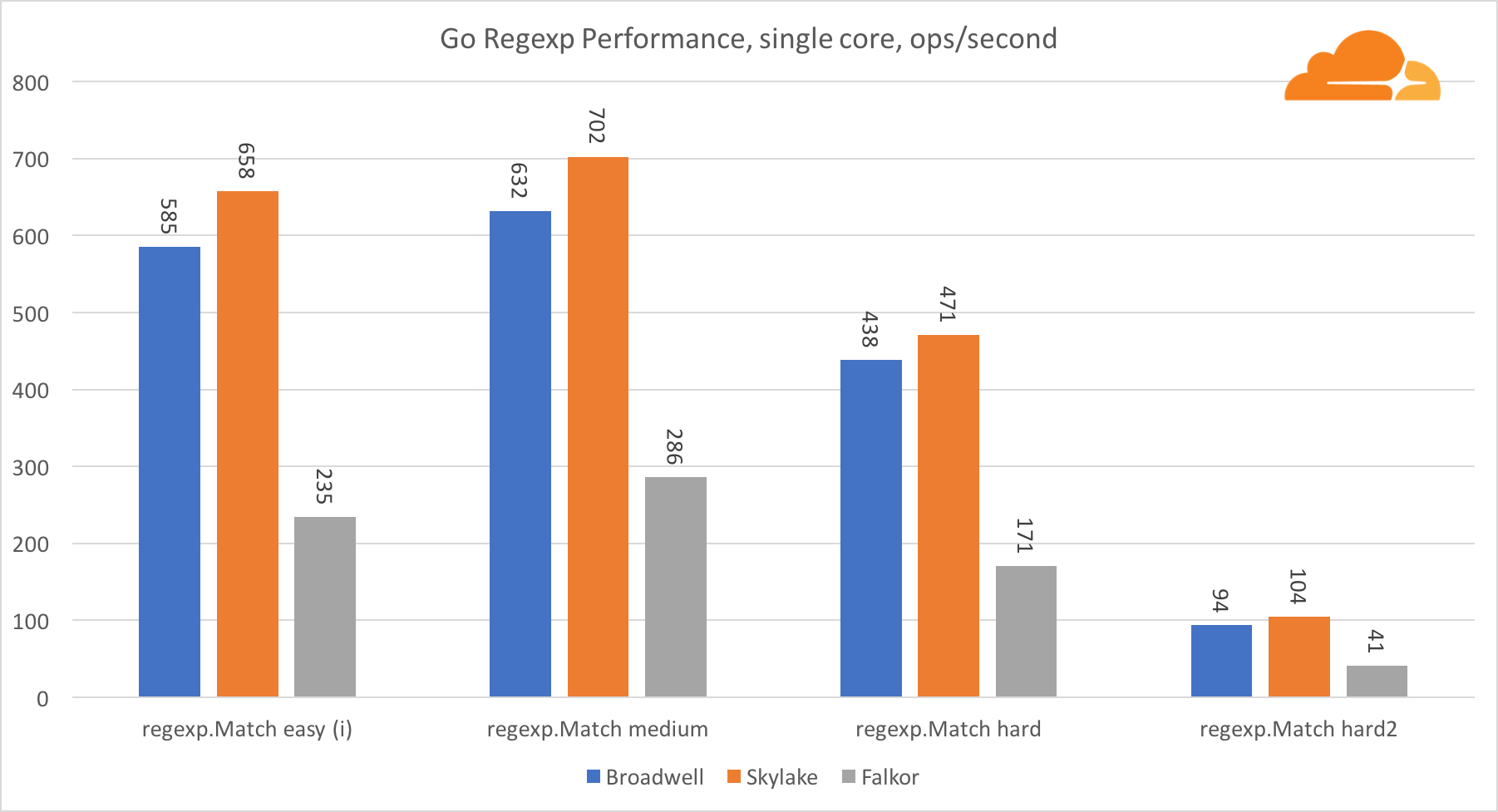
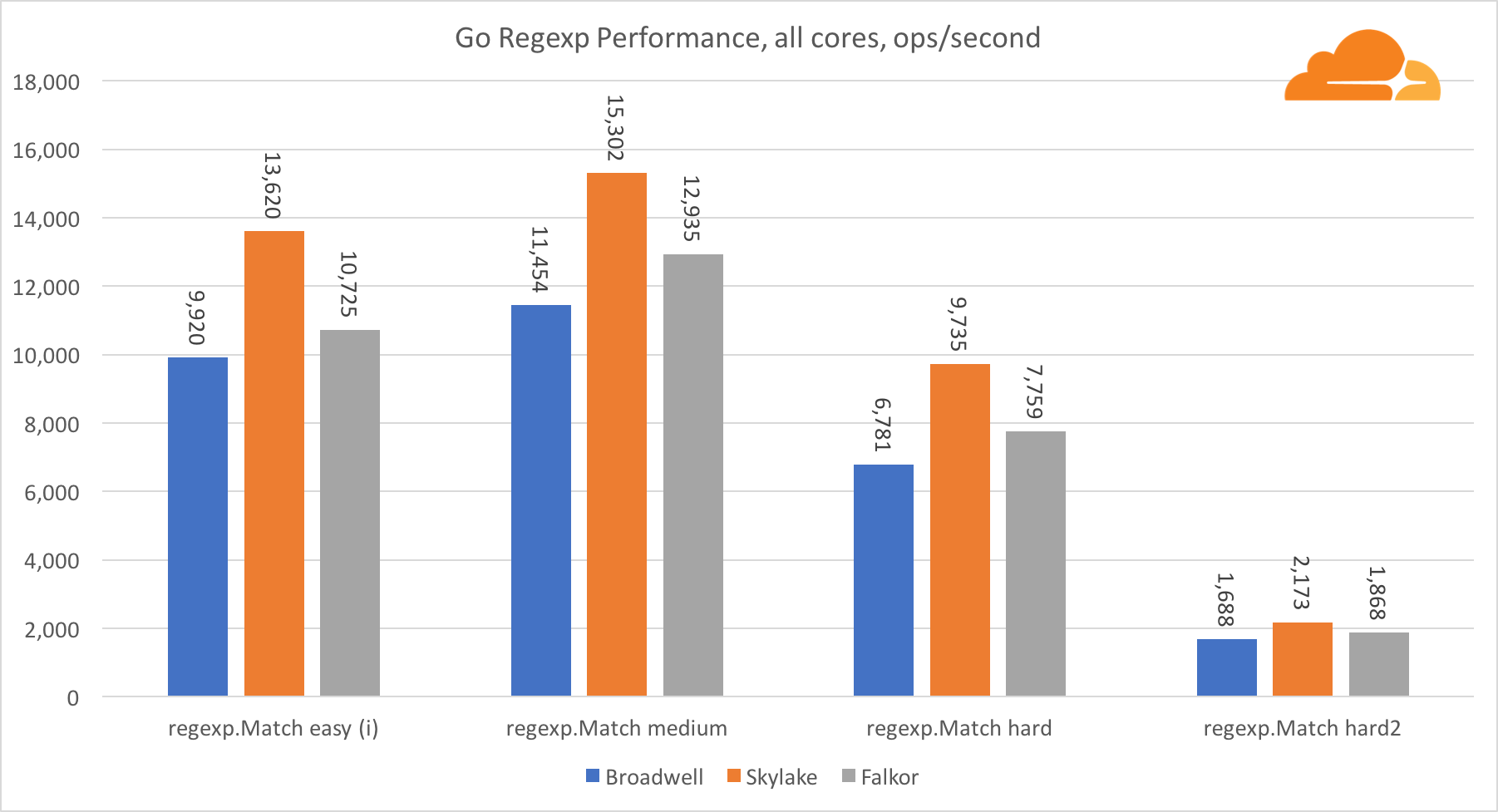
Auf Falkor ist die Leistung von Go regexp nicht sehr gut. Dank einer größeren Anzahl von Kernen belegt er bei mittleren und komplexen Tests den zweiten Platz, aber Skylake ist dennoch viel schneller.
Ein genauerer Blick auf den Prozess zeigt, dass viel Zeit für die Funktion bytes.IndexByte aufgewendet wird. Diese Funktion verfügt über eine Assembler-Implementierung für amd64 (runtime.indexbytebody), die Hauptimplementierung ist jedoch für Go. Bei leichten Tests hat regexp noch mehr Zeit mit dieser Funktion verbracht, was die größere Lücke erklärt.
Gehen Sie SaitenEine weitere wichtige Bibliothek für den Webserver sind Go-Strings. Ich habe nur die Haupt-Replacer-Klasse getestet.
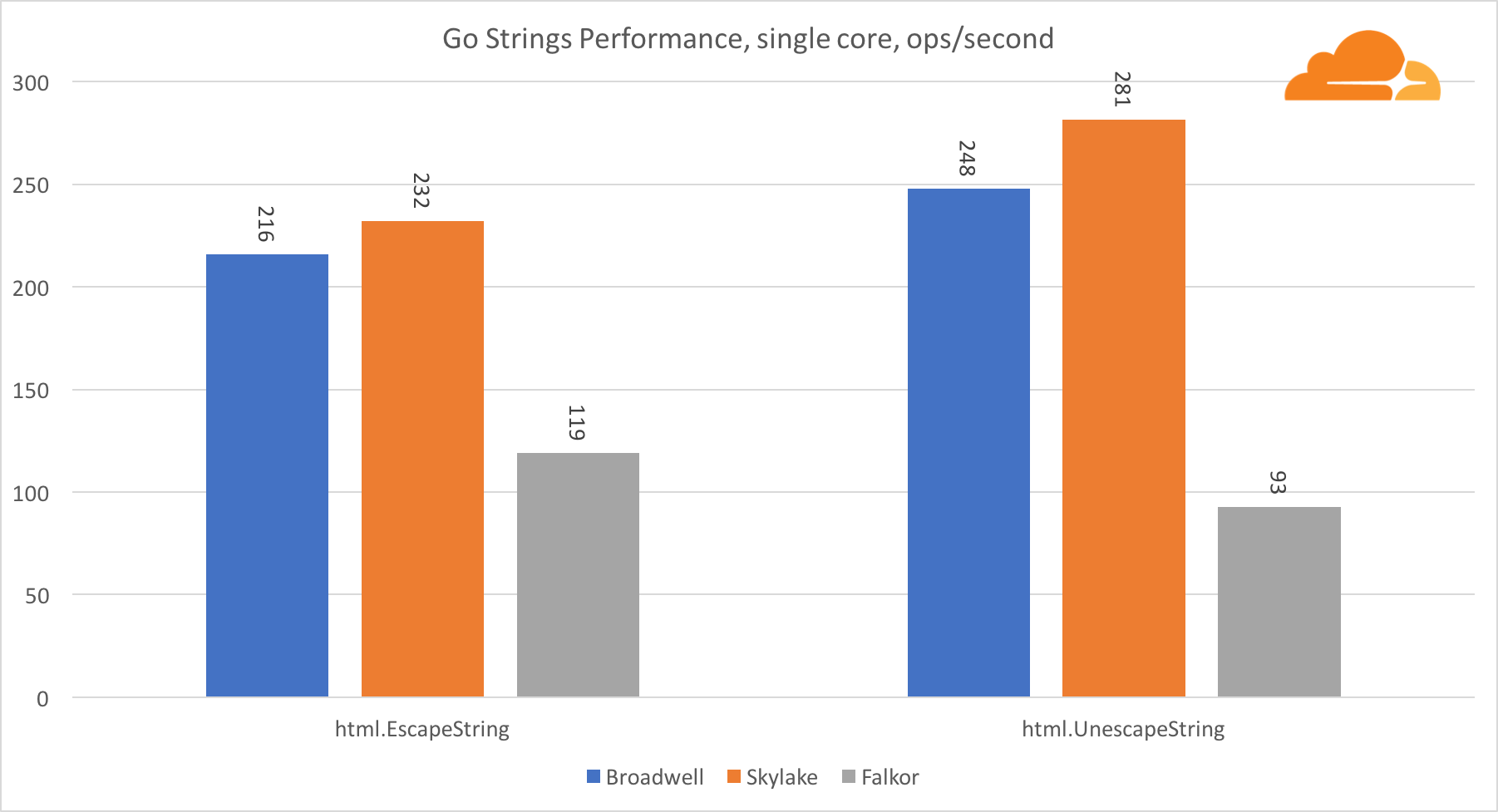
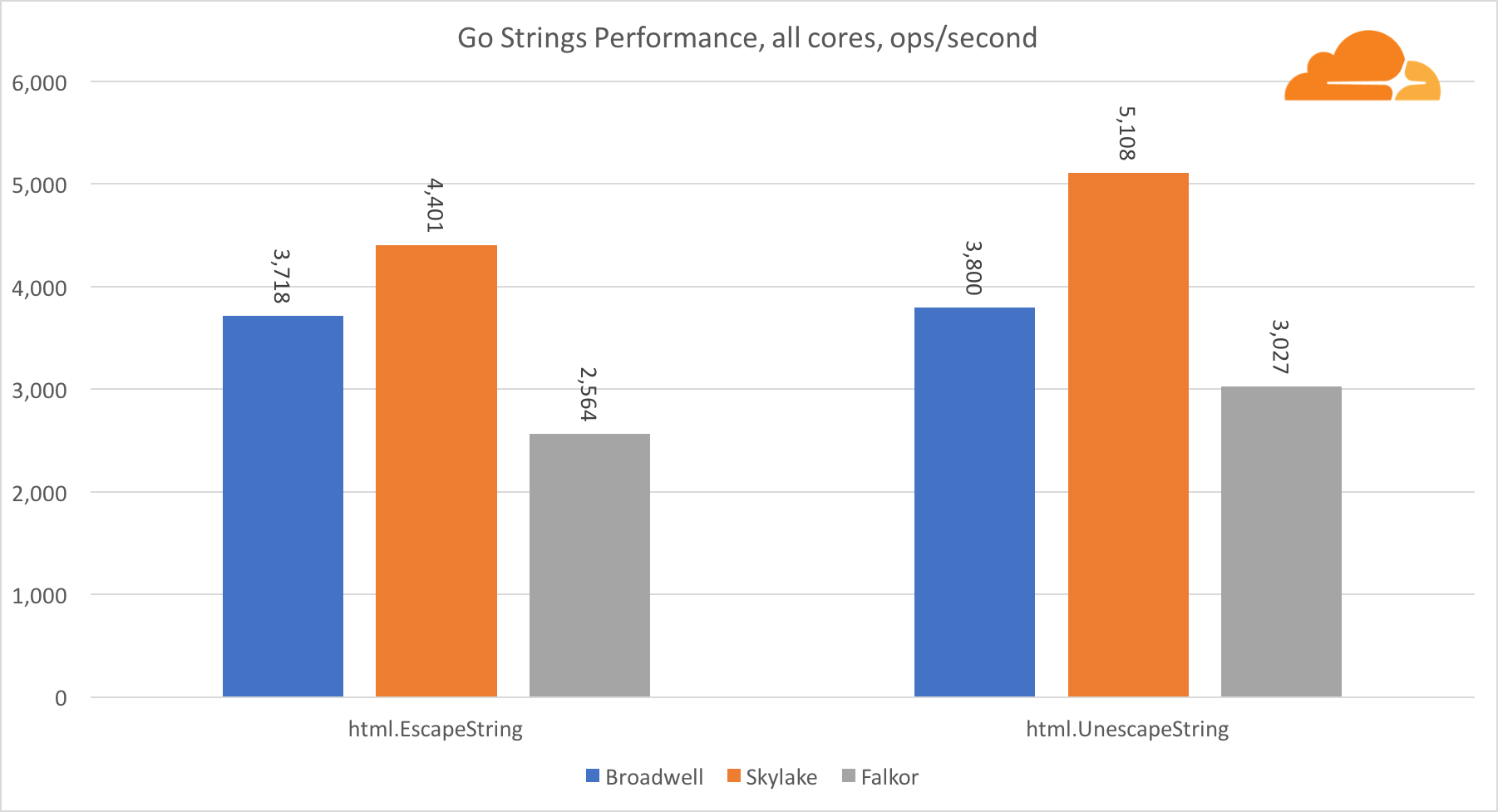
In diesem Test bleibt Falkor sogar hinter Broadwell zurück. Ein genauerer Blick zeigt einen langen Aufenthalt in der Funktion runtime.memmove. Weißt du was? Sie hat einen perfekt optimierten Assembler-Code für amd64, der AVX2 verwendet, aber nur den einfachsten Assembler, der jeweils 8 Bytes kopiert. Durch Ändern von 3 Zeilen in diesem Code und Verwenden der LDP / STP-Anweisungen (Laden von Paaren / Speichern von Paaren) können Sie jeweils 16 Byte kopieren, wodurch die Memmove-Leistung um 30% erhöht wird, was wiederum EscapeString und UnescapeString um 20% beschleunigt. Und das ist nur die Spitze des Eisbergs.
Gehen Sie zum SchlussDie Unterstützung von aarch64 ist ziemlich enttäuschend. Ich freue mich, Ihnen mitteilen zu können, dass alles einwandfrei kompiliert und funktioniert hat, aber auf der Leistungsseite könnte es besser sein. Man hat den Eindruck, dass der größte Teil des Aufwands für das Compiler-Backend aufgewendet wurde und die Bibliothek fast unberührt blieb. Es gibt viele Optimierungen auf niedriger Ebene, zum Beispiel meinen Fix addMulVVW, der 20 Minuten dauerte. Qualcomm und andere ARMv8-Anbieter beabsichtigen, erhebliche technische Ressourcen zur Behebung der Situation aufzuwenden, aber jeder kann tatsächlich zu Go beitragen. Wenn Sie also Ihre Spuren in der Geschichte hinterlassen möchten, ist jetzt die richtige Zeit dafür.
Luajit
Lua ist der Klebstoff, der Cloudflare zusammenhält.
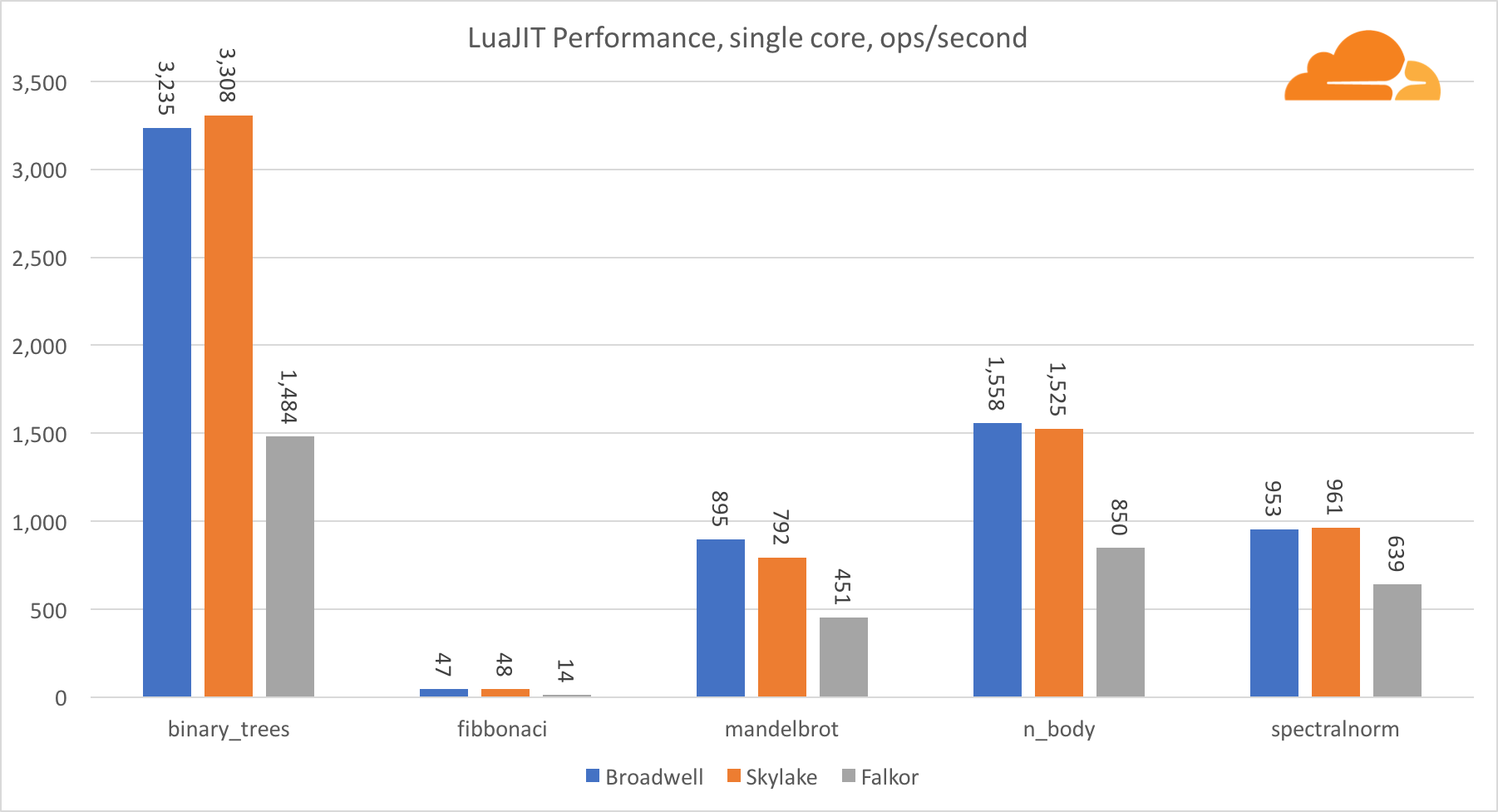
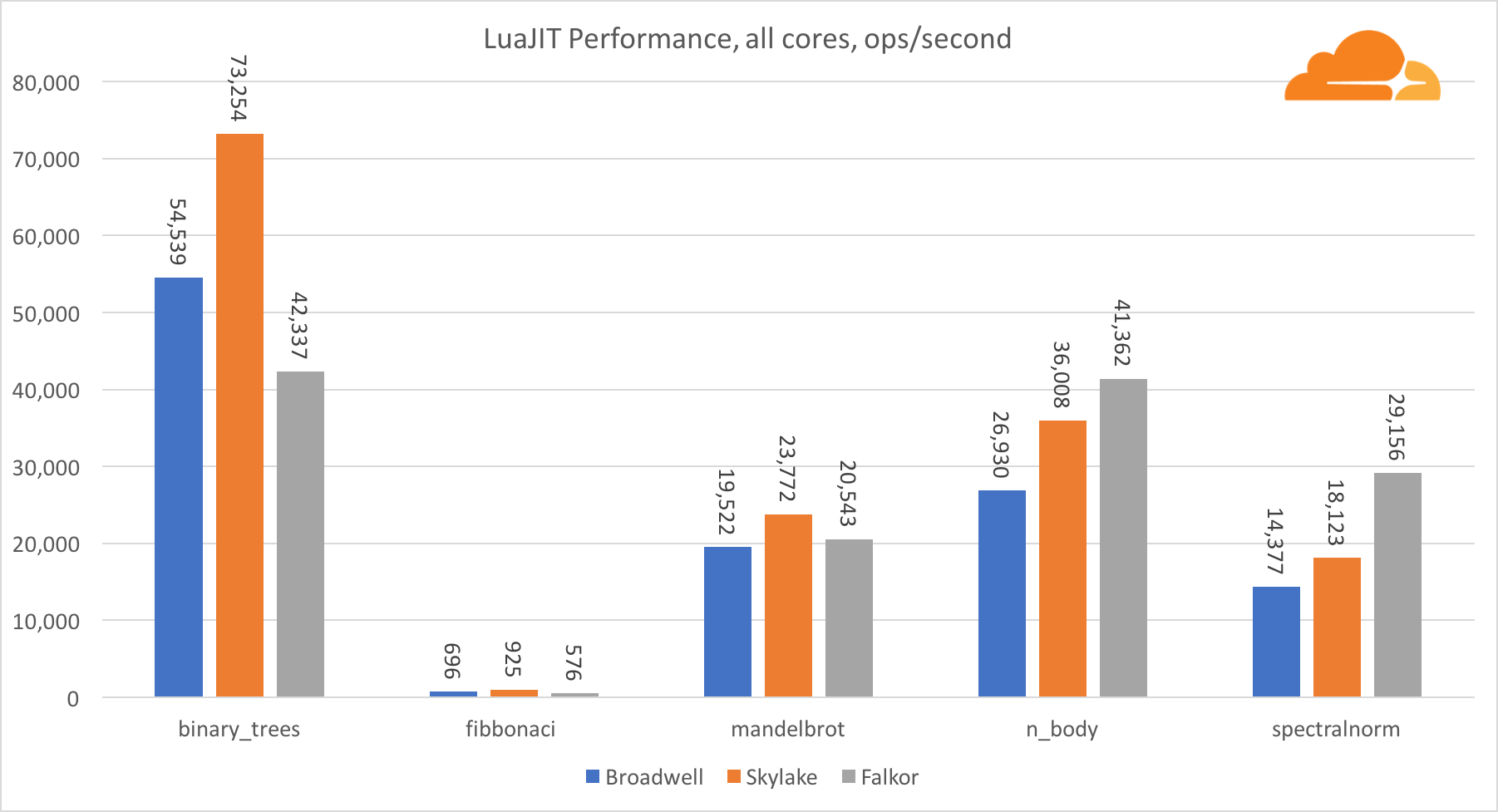
Mit Ausnahme des binary_trees-Tests ist die LuaJIT-Leistung auf ARM sehr wettbewerbsfähig. Er gewinnt zwei Tests und der dritte geht Nase an Nase mit den Konkurrenten.
Es ist erwähnenswert, dass der Test binary_trees äußerst wichtig ist, da er viele Zyklen der Speicherzuweisung und Speicherbereinigung umfasst. Dies erfordert in Zukunft eine genauere Prüfung.
Nginx
Als NGINX-Workload habe ich beschlossen, eine zu erstellen, die dem tatsächlichen Server ähnelt.
Ich habe einen Server konfiguriert, der die im gzip-Test verwendete HTML-Datei über https mit der Verschlüsselungssuite ECDHE-ECDSA-AES128-GCM-SHA256 bereitstellt.
Außerdem wird LuaJIT verwendet, um die eingehende Anforderung umzuleiten, alle Zeilenumbrüche und zusätzlichen Leerzeichen aus der HTML-Datei zu entfernen, wenn ein Zeitstempel hinzugefügt wird. HTML wird dann mit brotli 5 komprimiert.
Jeder Server wurde so konfiguriert, dass er mit so vielen Benutzern wie virtuellen Prozessoren funktioniert. 40 für Broadwell, 48 für Skylake und 46 für Falkor.
Als Client für diesen Test habe ich das Programm hey verwendet, das auf 3 Broadwell-Servern ausgeführt wird.
Gleichzeitig mit dem Test haben wir die Stromwerte von den entsprechenden BMC-Blöcken jedes Servers abgelesen.
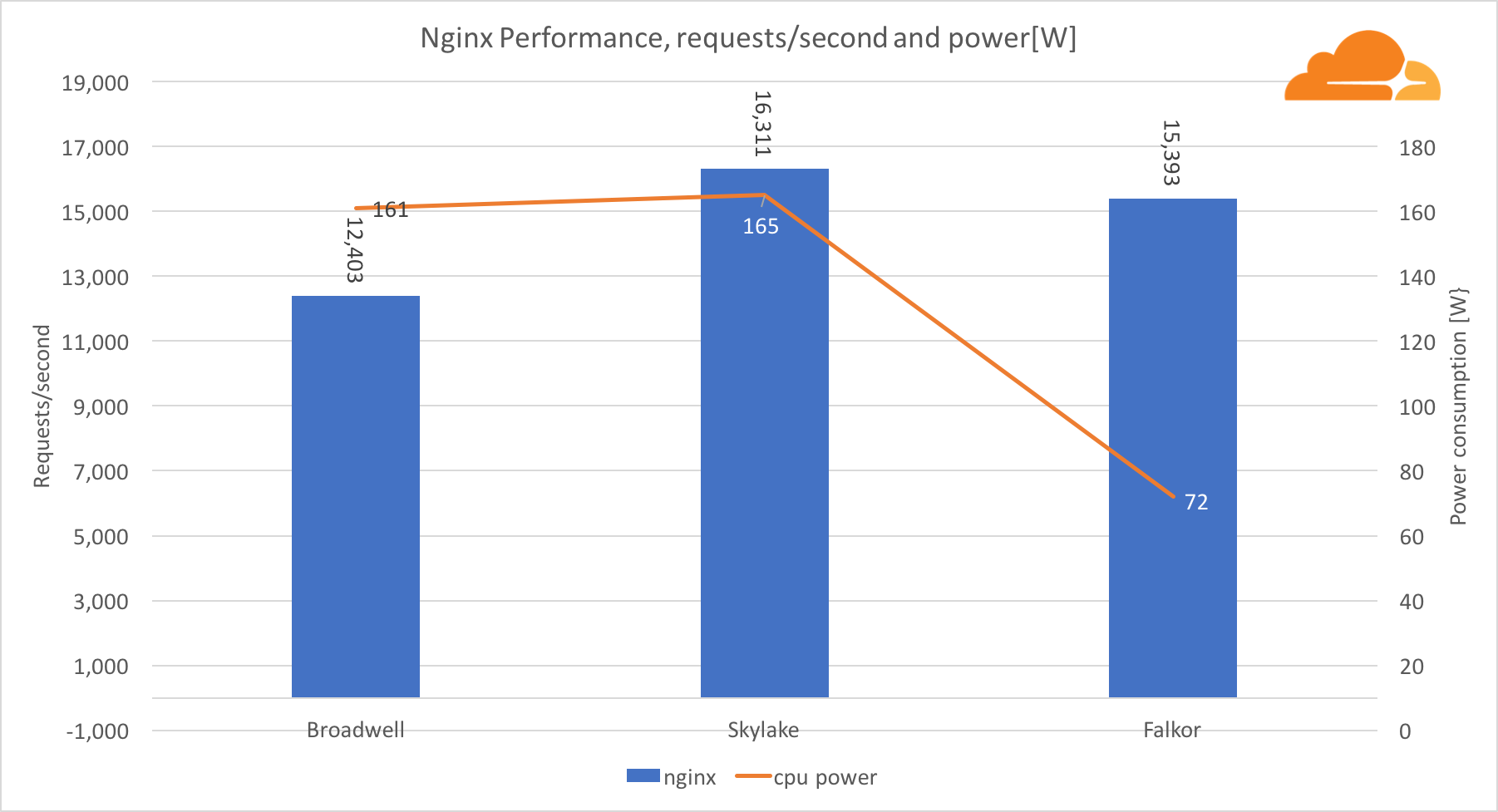
Mit der Arbeitslast behandelte NGINX Falkor fast die gleiche Anzahl von Anfragen wie der Skylake-Server, und beide waren Broadwell deutlich voraus. Die aus dem BMC entnommenen Leistungswerte zeigen, dass dies geschah, wenn der Stromverbrauch halb so hoch war wie bei anderen Prozessoren. Dies bedeutet, dass Falkor 214 Anfragen / W, Skylake - 99 Anfragen / W und Broadwell - 77 Anfragen / W erhalten hat.
Ich war überrascht, dass Skylake und Broadwell ungefähr die gleiche Menge an Energie verbrauchen, da sie auf die gleiche Weise hergestellt werden und Skylake mehr Kerne hat.
Der geringe Stromverbrauch von Falkor ist nicht überraschend, da Qualcomm-Prozessoren für ihre hohe Energieeffizienz bekannt sind, die es ihnen ermöglichte, eine beherrschende Stellung auf dem Markt für Prozessoren für mobile Geräte einzunehmen.
Fazit
Das Falkor-Beispiel, das wir bekommen haben, hat mich wirklich beeindruckt. Dies ist eine enorme Verbesserung gegenüber früheren Versuchen mit ARM-basierten Servern. Wenn man den Kern mit dem Kern vergleicht, ist Intel Skylake natürlich viel besser, aber wenn wir uns die Systemebene ansehen, wird die Leistung sehr attraktiv.
Die Serienversion von Centriq SoC wird 48 Falkor-Kerne enthalten, die mit Frequenzen bis zu 2,6 GHz arbeiten, was eine potenzielle Leistungssteigerung von 8% ergibt.
Natürlich ist der von uns getestete Skylake mit seinen 28 Kernen kein Flaggschiff wie Platinum, aber diese 28 Kerne kosten viel und verbrauchen 200 W, während wir versuchen, unsere Kosten zu optimieren und die Leistung um 1 Watt zu steigern.
Im Moment bin ich am meisten besorgt über die schlechte Leistung der Go-Sprache, aber dies wird sich ändern, sobald ARM-basierte Server ihre Marktnische besetzen.
Performance C und LuaJIT sind sehr wettbewerbsfähig und in vielen Fällen Skylake überlegen. In fast allen Tests erwies sich Falkor als würdiger Ersatz für Broadwell.
Das größte Plus für Falkor ist derzeit der geringe Stromverbrauch. Obwohl die TDP 120 W beträgt, hat diese Zahl während meiner Tests 89 W nie überschritten (für Go-Tests). Zum Vergleich: Skylake und Broadwell haben 160 W überschritten, während ihre TDP 170 W beträgt.
Als Werbung. Dies sind nicht nur virtuelle Server! Dies sind VPS (KVM) mit dedizierten Laufwerken, die nicht schlechter als dedizierte Server sein können, und in den meisten Fällen - besser!
Wir haben VPS (KVM) mit dedizierten Laufwerken in den Niederlanden und den USA (Konfigurationen von VPS (KVM) - E5-2650v4 (6 Kerne) / 10 GB DDR4 / 240 GB SSD oder 4 TB HDD / 1 Gbit / s 10 TB zu einem einzigartig niedrigen Preis - ab 29 USD / Monat verfügbar gemacht (Optionen mit RAID1 und RAID10 sind verfügbar) , verpassen Sie nicht die Gelegenheit, eine Bestellung für einen neuen virtuellen Servertyp
aufzugeben , bei dem alle Ressourcen Ihnen gehören, wie bei einem dedizierten Server, und der Preis mit einer viel produktiveren Hardware viel niedriger ist!
Wie man die Infrastruktur des Gebäudes baut. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent? Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA!