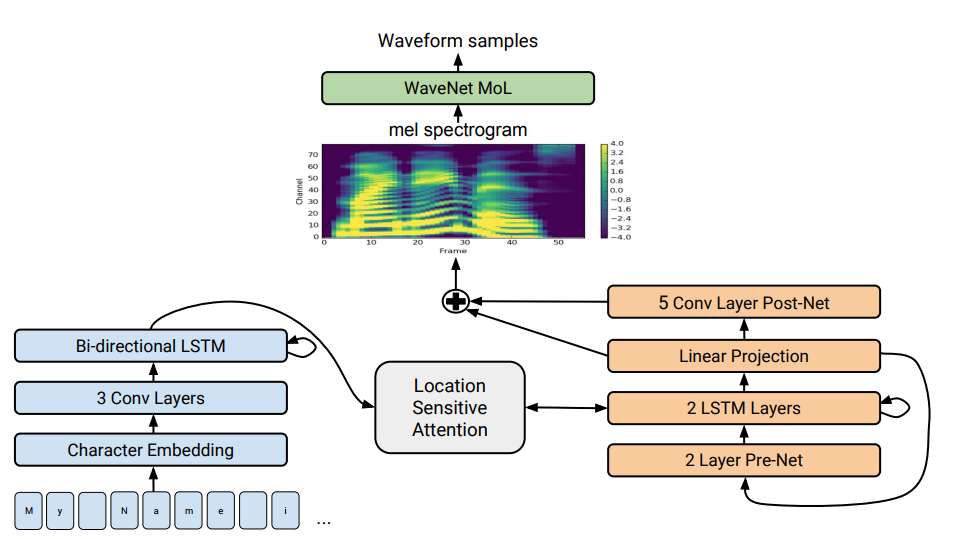
 Tacotron 2-Architektur. Am Ende der Abbildung werden Angebotsmodelle gezeigt, die eine Folge von Buchstaben in eine Folge von Attributen im 80-dimensionalen Raum übersetzen. Eine technische Beschreibung finden Sie in einem wissenschaftlichen Artikel.
Tacotron 2-Architektur. Am Ende der Abbildung werden Angebotsmodelle gezeigt, die eine Folge von Buchstaben in eine Folge von Attributen im 80-dimensionalen Raum übersetzen. Eine technische Beschreibung finden Sie in einem wissenschaftlichen Artikel.Die Sprachsynthese - die künstliche Reproduktion menschlicher Sprache aus einem Text - wird traditionell als eine der Komponenten der künstlichen Intelligenz angesehen. Früher waren solche Systeme nur in Science-Fiction-Filmen zu sehen, jetzt funktionieren sie buchstäblich in jedem Smartphone: Dies sind Siri, Alice und dergleichen. Aber sie sind keine sehr realistischen Äußerungen: leblose Stimme, Wörter sind voneinander getrennt.
Google hat
einen fortschrittlichen Sprachsynthesizer der nächsten Generation entwickelt. Es heißt Tacotron 2 und basiert auf einem neuronalen Netzwerk. Um seine Fähigkeiten zu demonstrieren, veröffentlichte das Unternehmen
Beispiele für die Synthese . Am Ende der Seite mit Beispielen können Sie einen Test durchführen und versuchen festzustellen, wo der Text vom Sprachsynthesizer geliefert wird und wo sich die Person befindet. Es ist fast unmöglich, den Unterschied zu bestimmen.
Trotz jahrzehntelanger Forschung bleibt die Sprachsynthese eine dringende Aufgabe für die wissenschaftliche Gemeinschaft. In den letzten Jahren haben sich in diesem Bereich verschiedene Techniken durchgesetzt: In jüngster Zeit wurde die verkettete Synthese mit der Auswahl von Fragmenten als am weitesten fortgeschritten angesehen - der Prozess der Kombination kleiner aufgezeichneter Klangfragmente sowie die statistische parametrische Sprachsynthese, bei der der Vocoder glatte Aussprachepfade synthetisierte. Die zweite Methode löste viele Probleme der verketteten Synthese mit Artefakten an den Grenzen zwischen Fragmenten. In beiden Fällen klang der synthetisierte Klang jedoch im Vergleich zur menschlichen Sprache verschwommen und unnatürlich.
Dann kam die WaveNet-Sound-Engine (ein generatives Modell von Wellenformen im Zeitbereich), die zum ersten Mal eine mit dem Menschen vergleichbare Klangqualität zeigen konnte. Es wird jetzt im Sprachsynthesesystem
Deep Voice 3 verwendet.
Anfang 2017 führte Google die
Tacotron -Angebotsarchitektur ein. Es erzeugt Spektrogramme von Amplituden aus einer Folge von Zeichen. Tacotron vereinfacht den herkömmlichen Audio-Engine-Förderer. Hier werden sprachliche und akustische Merkmale von einem einzigen neuronalen Netzwerk erzeugt, das nur auf Daten trainiert wird. Der Ausdruck "Satz zu Satz" bedeutet, dass das neuronale Netzwerk eine Entsprechung zwischen einer Folge von Buchstaben und einer Folge von Attributen zum Codieren von Ton herstellt. Zeichen werden in einem 80-dimensionalen Audiospektrogramm mit Bildern von 12,5 Millisekunden erzeugt.
Das neuronale Netzwerk lernt nicht nur die Aussprache von Wörtern, sondern auch bestimmte Sprachmerkmale wie Lautstärke, Geschwindigkeit und Intonation.
Dann werden Schallwellen direkt unter Verwendung des Griffin-Lim-Algorithmus (zur Phasenschätzung) und der inversen Kurzzeit-Fourier-Transformation erzeugt. Wie die Autoren feststellten, war dies eine vorübergehende Lösung, um die Fähigkeiten des neuronalen Netzwerks zu demonstrieren. Tatsächlich erzeugen die WaveNet-Engine und dergleichen einen besseren Klang als der Griffin-Lim-Algorithmus und ohne Artefakte.
Im modifizierten Tacotron 2-System haben Spezialisten von Google den WaveNet-Vocoder weiterhin mit dem neuronalen Netzwerk verbunden. Somit erzeugt das neuronale Netzwerk Spektrogramme, und dann erzeugt eine modifizierte Version von WaveNet Schall bei 24 kHz.
Das neuronale Netzwerk lernt unabhängig (Ende-zu-Ende) den Klang einer menschlichen Stimme, die von Text begleitet wird. Ein gut ausgebildetes neuronales Netzwerk liest dann die Texte so, dass es fast unmöglich ist, vom Klang menschlicher Sprache zu unterscheiden, wie an
realen Beispielen zu sehen ist.
Die Forscher stellen fest, dass das Deep Voice 3-System einen ähnlichen Ansatz verwendet, die Qualität seiner Synthese jedoch immer noch nicht mit der menschlichen Sprache verglichen werden kann. Tacotron 2 kann jedoch die Testergebnisse des Mean Opinion Score (MOS) in der Tabelle anzeigen.
Es gibt einen anderen Sprachsynthesizer, der auch in einem neuronalen Netzwerk funktioniert - dies ist
Char2Wav , aber es hat eine völlig andere Architektur.
Wissenschaftler sagen, dass das neuronale Netzwerk im Allgemeinen gut funktioniert, aber immer noch Schwierigkeiten hat, einige komplexe Wörter (wie
Anstand oder
Merlot ) auszusprechen. Und manchmal erzeugt es zufällig seltsame Geräusche - die Gründe dafür werden jetzt geklärt. Darüber hinaus ist das System nicht in der Lage, in Echtzeit zu arbeiten, und die Autoren waren noch nicht in der Lage, die Kontrolle über den Motor zu übernehmen, dh die gewünschte Intonation dafür einzustellen, beispielsweise eine fröhliche oder traurige Stimme. Jedes dieser Probleme ist für sich interessant, schreiben sie.
Der wissenschaftliche Artikel wurde am 16. Dezember 2017 auf der Preprint-Website arXiv.org (arXiv: 1712.05884v1) veröffentlicht.