... und lernen Sie anhand eines realen Beispiels, mit Ethereum-Entwicklertools zu arbeiten.
Teil Null: Das Objekt kam in Sicht
Ich habe gerade meine Vorlesungen über den Full-Stack-Kurs zur Entwicklung dezentraler Ethereum-basierter Anwendungen in Solidity auf Chinesisch beendet. Ich habe es in meiner Freizeit gegeben, um den Wissensstand der chinesischen Entwicklergemeinschaft über Blockchain und intelligente Verträge zu verbessern. Während meiner Arbeit habe ich mich mit ein paar Studenten angefreundet.
Und gerade am Ende des Kurses waren wir plötzlich von diesen Kreaturen umgeben:
 Bild von cryptokitties.co
Bild von cryptokitties.coWie die meisten Menschen, die auf dieses Phänomen gestoßen sind, konnten auch wir diesen niedlichen Kryptokreationen nicht widerstehen und wurden schnell spielsüchtig. Wir brachten gerne neue Katzen heraus und ersetzten sogar
die Entleinmethode durch die Kryptokatzenmethode . Ich glaube, dass Spielsucht schlecht ist, aber nicht in diesem Fall, weil die Leidenschaft für die Zucht von Kätzchen uns schnell zu der Frage führte:
Wie bekommen bestimmte Kryptokatzen ihre Gene?
Wir haben uns entschlossen, am Samstagabend die Antwort darauf zu finden, und wir glauben, dass wir einige Fortschritte bei der Entwicklung von Software erzielt haben, mit der wir die genetische Mutation neugeborener Kryptokätzchen bestimmen können, bevor sie geboren werden. Mit anderen Worten, dieses Programm kann Ihnen helfen, den geeigneten Zeitpunkt für die Befruchtung der Katzenmutter zu überprüfen und zu bestimmen und dadurch die interessanteste der möglichen Mutationen zu erhalten.
Wir veröffentlichen dieses Material in der Hoffnung, dass es allen als Einführungsartikel dient, um sich mit sehr nützlichen Ethereum-Entwicklungstools vertraut zu machen, so wie die Kryptokätzchen selbst vielen mit der Blockchain nicht vertrauten Personen erlaubt haben, sich den Reihen der Kryptowährungsbenutzer anzuschließen.
Teil eins: Die Logik auf hoher Ebene, kleine Kätzchen zu erzeugen
Zunächst haben wir uns gefragt: Wie ist die Geburt von Kryptokätzchen?
Um diese Frage zu beantworten, haben wir den hervorragenden Etherscan-Blockchain-Leiter verwendet, mit dem wir viel mehr als nur „die Parameter und Inhalte der Blöcke untersuchen“ können. Also haben wir den Quellcode für den CryptoKittiesCore-Vertrag entdeckt:
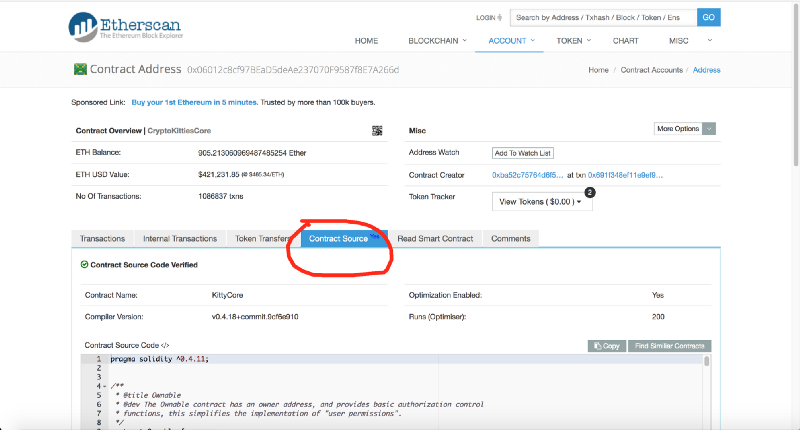 https://etherscan.io/address/0x06012c8cf97bead5deae237070f9587f8e7a266d#code
https://etherscan.io/address/0x06012c8cf97bead5deae237070f9587f8e7a266d#codeBitte beachten Sie, dass sich der erweiterte Vertrag tatsächlich geringfügig von dem im Kopfgeldprogramm verwendeten unterscheidet. Nach diesem Code wird ein Babykätzchen in zwei Schritten gebildet: 1) Die Mutterkatze wird von der Katze befruchtet. 2) Wenig später, wenn die Reifezeit des Fötus zu Ende ist, wird die Funktion giveBirth aufgerufen. Diese Funktion wird normalerweise von einem bestimmten Prozessdämon aufgerufen. Um jedoch später interessante Mutationen zu erhalten, müssen Sie den Block, in dem Ihr Kätzchen geboren wurde, korrekt auswählen.
function giveBirth(uint256 _matronId) external whenNotPaused returns(uint256) { Kitty storage matron = kitties[_matronId];
Im obigen Code können Sie deutlich sehen, dass die Gene eines neugeborenen Kätzchens direkt zum Zeitpunkt der Geburt bestimmt werden, indem Sie die mixGenes-Funktion aus dem externen Smart-Vertrag von geneScience aufrufen. Diese Funktion verwendet drei Parameter: das Muttergen, das Vatergen und die Blocknummer, in der die Katze zur Geburt bereit ist.
Sie werden wahrscheinlich eine logische Frage haben, warum Gene zum Zeitpunkt der Empfängnis nicht bestimmt werden, wie dies in der realen Welt der Fall ist. Wie Sie im Verlauf der nachfolgenden Erzählung sehen werden, können Sie sich auf diese Weise elegant gegen Versuche verteidigen, Gene vorherzusagen und zu entschlüsseln. Dieser Ansatz eliminiert die Möglichkeit einer 100% genauen Vorhersage von Kätzchengenen, bevor die Tatsache der Katzen-Mutter-Schwangerschaft in der Blockchain aufgezeichnet wird. Und selbst wenn Sie den genauen Code herausfinden könnten, der für das Mischen der Gene verantwortlich ist, würde dies Ihnen keinen Vorteil bringen.
Wie dem auch sei, am Anfang wussten wir das noch nicht, also fahren wir fort. Jetzt müssen wir die Adresse des geneScience-Vertrags herausfinden. Verwenden Sie dazu MyEtherWallet:
 GeneScience-Vertragsadresse
GeneScience-VertragsadresseSo sieht der Vertragsbytecode aus:
0x60606040526004361061006c5763ffffffff7c01000000000000000000000000000000000000000000000000000000006000350416630d9f5aed81146100715780631597ee441461009f57806354c15b82146100ee57806361a769001461011557806377a74a201461017e575b600080fd5b341561007c57600080fd5b61008d6004356024356044356101cd565b604051908152602001604051809........
An seinem Aussehen kann man nicht sagen, dass auf allem etwas so Süßes wie ein Kätzchen auf allem erscheint, aber wir sind sehr glücklich, dass dies eine öffentliche Adresse ist, und wir müssen nicht im Repository danach suchen. Tatsächlich glauben wir, dass es nicht so leicht zugänglich gemacht werden sollte. Wenn die Entwickler wirklich sicherstellen möchten, dass die Adresse des Vertrags korrekt ist, sollten sie die Funktion checkScienceAddress verwenden, aber wir werden nicht gestört.
Teil zwei: Der Zusammenbruch einer einfachen Hypothese
Was wollen wir also am Ende erreichen? Es versteht sich, dass wir uns nicht das Ziel gesetzt haben, den Bytecode vollständig zu kompilieren und ihn in einen für Menschen lesbaren Soliditätscode umzuwandeln. Wir brauchen eine billige Methode (ohne für Transaktionen in der Kampfblockkette bezahlen zu müssen) zur Bestimmung von Kätzchengenen, vorausgesetzt wir wissen, wer seine Eltern sind. Das werden wir tun.
Verwenden Sie zunächst das Etherscan-
Opcode-Tool für eine schnelle Analyse. Es sieht so aus:
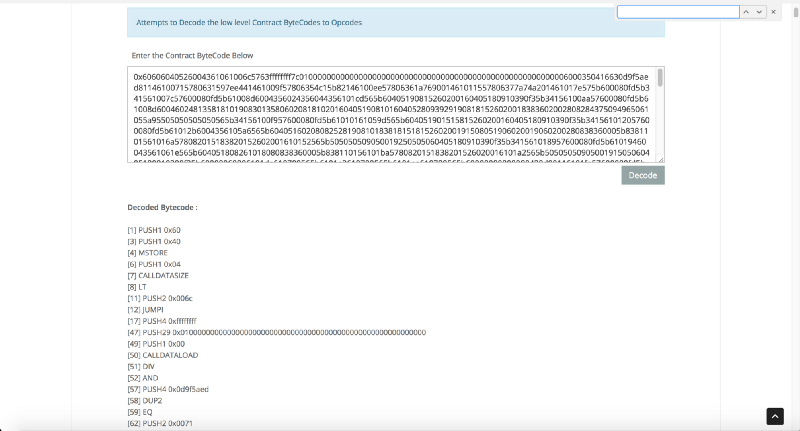 Viel klarer
Viel klarerWir folgen der goldenen Regel der Dekodierung des Assembler-Codes: Wir beginnen mit einer einfachen und kühnen Hypothese über das Verhalten des Programms und konzentrieren uns, anstatt zu versuchen, seine Arbeit als Ganzes zu verstehen, darauf, die getroffene Annahme zu bestätigen. Wir werden den Bytecode durchgehen, um einige Fragen zu beantworten:
- Verwendet es Zeitstempel? Nein, da der TIMESTAMP-Opcode fehlt. Wenn es einen einfachen Unfall gibt, dann ist seine Quelle definitiv ein anderer Opcode.
- Wird ein Block-Hash verwendet? Ja, BLOCKHASH tritt zweimal auf. Daher kann sich aus ihren Opcodes eine etwaige Zufälligkeit ergeben, über die wir uns jedoch noch nicht sicher sind.
- Werden überhaupt Hashes verwendet? Ja, da ist SHA3. Es ist jedoch nicht klar, was er tut.
- Wird msg.sender verwendet? Nein, da der CALLER-Opcode fehlt. Daher wird keine Zugriffskontrolle auf den Vertrag angewendet.
- Wird ein externer Vertrag verwendet? Nein, es gibt keinen CALL-Opcode.
- Wird COINBASE verwendet? Nein, und daher schließen wir eine andere mögliche Quelle der Zufälligkeit aus.
Nachdem wir die Antwort auf diese Fragen erhalten haben, stellen wir eine einfache Hypothese auf und beabsichtigen sie zu testen: Das Ergebnis von mixGene wird durch drei und nur drei Eingabeparameter dieser Funktion bestimmt. Wenn ja, könnten wir diesen Vertrag einfach lokal bereitstellen, diese Funktion weiterhin mit den Parametern aufrufen, an denen wir interessiert sind, und dann könnten wir vielleicht ein Kit mit Kätzchengenen erhalten, noch bevor die Katzenmutter befruchtet wird.
Um diese Annahme zu überprüfen, rufen wir die mixGene-Funktion im Hauptnetzwerk mit drei zufälligen Parametern auf: 1111115, 80, 40 und erhalten ein Ergebnis X. Als nächstes stellen Sie diesen Bytecode mit
Trüffel und testrpc bereit . Unsere Faulheit führte also zu einer etwas ungewöhnlichen Art, Trüffel zu verwenden.
contract GeneScienceSkeleton { function mixGenes(uint256 genes1, uint256 genes2, uint256 targetBlock) public returns (uint256) {} }
Wir beginnen mit dem Vertragsskelett, fügen es in die Ordnerstruktur des Trüffel-Frameworks ein und führen die Trüffel-Kompilierung aus. Anstatt diesen leeren Vertrag direkt nach testrpc zu migrieren, ersetzen wir den Vertragsbytecode im Build-Ordner durch den tatsächlich erweiterten Bytecode und den geneScience-Vertragsbytecode. Dies ist ein atypischer, aber schneller Weg, wenn Sie einen Vertrag nur mit Bytecode und einer eingeschränkten offenen Schnittstelle für lokale Tests bereitstellen möchten. Danach rufen wir Mixgenes direkt mit den Parametern 1111115, 80, 40 auf und erhalten leider einen Fehler, wenn die Antwort als Antwort zurückgesetzt wird. Ok, schau tiefer. Wie wir wissen, lautet die Signatur der mixGene-Funktionen 0x0d9f5aed. Daher nehmen wir einen Stift und Papier und verfolgen die Bytecode-Ausführung, beginnend mit dem Einstiegspunkt dieser Funktion, um Änderungen im Stapel und im Speicher zu berücksichtigen. Nach ein paar Sprüngen befinden wir uns hier:
[497] DUP1 [498] NUMBER [499] DUP14 [500] SWAP1 [501] GT [504] PUSH2 0x01fe [505] JUMPI [507] PUSH1 0x00 [508] DUP1 [509] 'fd'(Unknown Opcode)
Nach dem Inhalt dieser Zeilen zu urteilen, wird revert () aufgerufen, wenn die Nummer des aktuellen Blocks kleiner als der dritte Parameter ist. Nun, das ist ein ziemlich vernünftiges Verhalten: Es ist unmöglich, eine echte Funktion in einem Spiel mit einer Blocknummer aus der Zukunft aufzurufen, und das ist logisch.
Diese Eingabeüberprüfung ist leicht zu umgehen: Wir bauen nur ein paar Blöcke auf testrpc ab und rufen die Funktion erneut auf. Dieses Mal gibt die Funktion erfolgreich Y zurück.
Aber leider X! = Y.
Schade. Dies bedeutet, dass das Ergebnis der Funktionsausführung nicht nur von den Eingabeparametern abhängt, sondern auch vom Status der Blockchain des Hauptnetzwerks, der sich natürlich vom Status des gefälschten Blockchain-Testrpc unterscheidet.
Teil drei: Krempeln Sie die Ärmel hoch und graben Sie in den Stapel
Okay. Es ist also Zeit, die Ärmel hochzukrempeln. Papier ist nicht mehr zur Verfolgung des Stapelstatus geeignet. Für ernstere Arbeiten werden wir einen sehr nützlichen EVM-Disassembler namens
evmdis starten .
Im Vergleich zu Papier und Stift ist dies ein greifbarer Fortschritt. Fahren wir mit dem fort, bei dem wir im letzten Kapitel stehen geblieben sind. Das Folgende ist eine ermutigende Schlussfolgerung mit evmdis:
............. :label22 # Stack: [@0x70E @0x70E @0x70E 0x0 0x0 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x1EB PUSH(0x0) 0x1ED DUP1 0x1EE DUP1 0x1EF DUP1 0x1F0 DUP1 0x1F1 DUP1 0x1F3 DUP13 0x1F9 JUMPI(:label23, NUMBER() > POP()) # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 0x0 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x1FA PUSH(0x0) 0x1FC DUP1 0x1FD REVERT() :label23 # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 0x0 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x1FF DUP13 0x200 PUSH(BLOCKHASH(POP())) 0x201 SWAP11 0x202 POP() 0x203 DUP11 0x209 JUMPI(:label25, !!POP()) # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 @0x200 0x0 @0x88 @0x85 @0x82 :label3 @0x34] 0x20C DUP13 0x213 PUSH((NUMBER() & ~0xFF) + (POP() & 0xFF)) 0x214 SWAP13 0x215 POP() 0x217 DUP13 0x21E JUMPI(:label24, !!(POP() < NUMBER())) # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 @0x200 0x0 @0x213 @0x85 @0x82 :label3 @0x34] 0x222 DUP13 0x223 PUSH(POP() - 0x100) 0x224 SWAP13 0x225 POP() :label24 # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 @0x200 0x0 [@0x223 | @0x213] @0x85 @0x82 :label3 @0x34] 0x227 DUP13 0x228 PUSH(BLOCKHASH(POP())) 0x229 SWAP11 0x22A POP() :label25 # Stack: [0x0 0x0 0x0 0x0 0x0 0x0 @0x70E @0x70E @0x70E 0x0 [@0x200 | @0x228] 0x0 [@0x88 | @0x223 | @0x213] @0x85 @0x82 :label3 @0x34] 0x22C DUP11 0x22D DUP16 0x22E DUP16 ...........
Wofür evmdis wirklich gut ist, ist seine Nützlichkeit für die Analyse von JUMPDEST in die richtigen Labels, die nicht überschätzt werden können.
Nachdem wir die anfängliche Anforderung erfüllt haben, befinden wir uns auf Etikett 23. Wir sehen DUP13 und erinnern uns aus dem vorherigen Kapitel, dass die Nummer 13 auf dem Stapel unser dritter Parameter ist. Wir versuchen also, den BLOCKHASH unseres dritten Parameters zu erhalten. Die Aktion von BLOCKHASH ist jedoch auf 256 Blöcke beschränkt. Aus diesem Grund folgt JUMPI (dies ist ein if-Konstrukt). Wenn wir die Logik der Opcodes in die Sprache des Pseudocodes übersetzen, erhalten wir ungefähr Folgendes:
func blockhash(p) { if (currentBlockNumber - p < 256) return hash(p); return 0; } var bhash = blockhash(thrid); if (bhash == 0) { thirdProjection = (currentBlockNumber & ~0xff) + (thridParam & 0xff); if (thirdProjection > currentBlockNumber) { thirdProjection -= 256; } thirdParam = thirdProjection; bhash = blockhash(thirdProjection); } label 25 and beyond ..... some more stuff related to thirdParam and bhash
einige weitere Dinge im Zusammenhang mit ThirdParam und Bhash - anderer Code in Bezug auf ThirdParam und Block-Hash
Jetzt glauben wir, dass wir einen Grund gefunden haben, warum sich unsere Ergebnisse von denen unterscheiden, die wir im Hauptnetzwerk beobachten. Noch wichtiger ist, dass wir offenbar die Quelle des Zufalls entdeckt haben. Das heißt, der Block-Hash wird basierend auf dem dritten Parameter oder der
Vorhersage des dritten Parameters berechnet. Es ist wichtig zu beachten, dass im Stapel auch der dritte Parameter durch diese vorhergesagte Blocknummer ersetzt wird.
Offensichtlich haben wir während der lokalen Ausführung außerhalb des Hauptnetzwerks keine einfache Option, um eine BLOCKHASH-Rückgabe zu erzwingen, die den Werten des Hauptnetzwerks entspricht. Wie auch immer, da wir alle drei Parameter kennen, können wir das Hauptnetzwerk leicht überwachen und den Hash von Block H für den dritten Parameter sowie den Hash des vorhergesagten Blocks erhalten.
Als nächstes können wir diesen Hash direkt in den Bytecode in unserer lokalen Testumgebung einfügen. Wenn alles nach Plan verläuft, erhalten wir endlich den richtigen Satz von Genen.
Es gibt jedoch einen Haken: DUP13 und BLOCKHASH sind nur 2 Bytes im Code, und wenn wir sie nur durch 33 Byte PUSH32 0x * Hash * ersetzen, ändert sich der Programmzähler vollständig und wir müssen jeden JUMP und JUMPI reparieren. Oder wir müssen JUMP am Ende des Codes erstellen und die Anweisungen für den bereitgestellten Code ersetzen, und so weiter.
Nun, da wir so weit gekommen sind, werden wir ein bisschen mehr schnüffeln. Da wir den 32-Byte-Hash ungleich Null in den if-Zweig verschieben, ist die Bedingung immer wahr, und daher kann alles, was im else-Teil geschrieben ist, einfach weggeworfen werden, um Platz für unseren 32-Byte-Hash zu schaffen. Im Allgemeinen haben wir Folgendes getan:
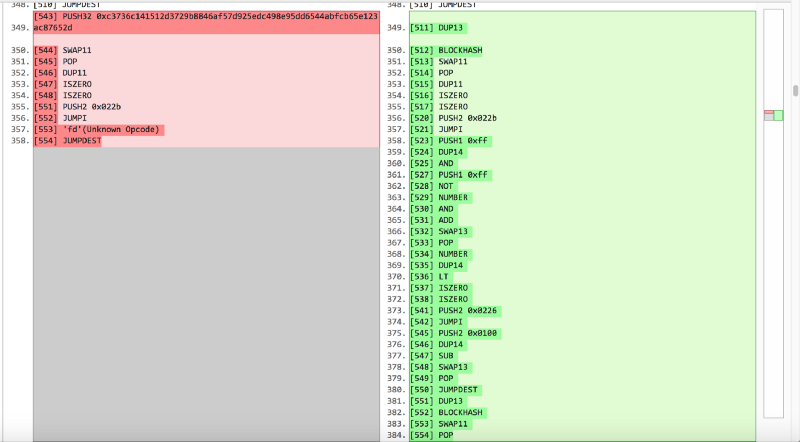
Der entscheidende Punkt ist, dass wir, da wir den else-Teil der Bedingung aufgegeben haben, den dritten Eingabeparameter der mixGene-Funktion durch die Vorhersage des dritten Parameters ersetzen müssen, bevor wir ihn aufrufen.
Dies ist bis zu dem Punkt, an dem Sie versuchen, das Ergebnis einer Operation zu erhalten
mixGene (X, Y, Z), wobei currentBlockNumber Z <256 ist, müssen Sie nur den PUSH32-Hash durch den Hash des Z-Blocks ersetzen.
Wenn Sie jedoch Folgendes beabsichtigen
mixGene (X, Y, Z), wobei currentBlockNumber Z ≥ 256 ist, müssen Sie den PUSH32-Hash durch den Hash des proj_Z-Blocks ersetzen, wobei proj_Z wie folgt definiert ist:
proj_Z = (currentBlockNumber & ~0xff) + (Z & 0xff); if (proj_Z > currentBlockNumber) { proj_Z -= 256; } <b> Z proj_Z , mixGene(X, Y, proj_Z).</b>
Beachten Sie, dass proj_Z in einem bestimmten Bereich von Blöcken unverändert bleibt. Wenn beispielsweise Z & 0xff = 128 ist, ändert sich proj_Z nur für jeden Null- und 128. Block.
Um diese Hypothese zu bestätigen und zu überprüfen, ob noch Fallstricke
vorliegen , haben wir den Bytecode geändert und ein anderes cooles Dienstprogramm namens
hevm verwendet .
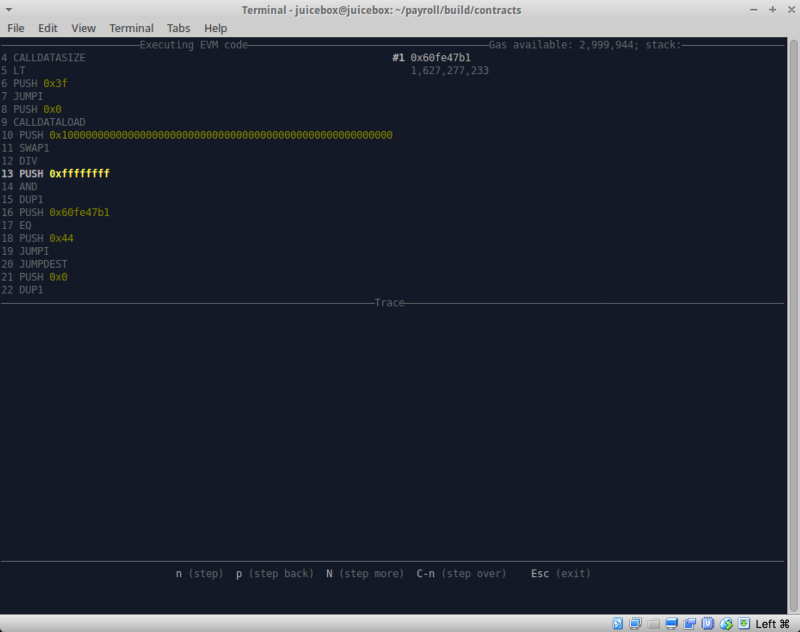
Wenn Sie hevm noch nie benutzt haben, empfehle ich Ihnen, es zu versuchen. Das Tool ist zusammen mit einem eigenen Framework verfügbar, aber vor allem in seinem Set sollte es als unverzichtbar nützlich angesehen werden, wie ein interaktiver Stack-Debugger.
Usage: hevm exec --code TEXT [--calldata TEXT] [--address ADDR] [--caller ADDR] [--origin ADDR] [--coinbase ADDR] [--value W256] [--gas W256] [--number W256] [--timestamp W256] [--gaslimit W256] [--gasprice W256] [--difficulty W256] [--debug] [--state STRING] Available options: -h,--help
Oben sind die Startoptionen aufgeführt. Mit dem Dienstprogramm können Sie verschiedene Parameter angeben. Darunter befindet sich --debug, mit dem Sie interaktiv debuggen können.
Daher haben wir hier mehrere Aufrufe an den in der Hauptnetzwerk-Blockchain bereitgestellten geneScience-Vertrag getätigt und die Ergebnisse aufgezeichnet. Dann haben wir hevm verwendet, um unseren defekten Bytecode mit Daten auszuführen, die unter Berücksichtigung der oben beschriebenen Regeln und ...
Die Ergebnisse sind die gleichen!
Das letzte Kapitel: Abschluss und Fortsetzung der Arbeit (?)
Was konnten wir also erreichen?
Mit unserer Hack-Software können Sie ein 256-Bit-Gen für ein neugeborenes Kätzchen mit einer Wahrscheinlichkeit von 100% vorhersagen, wenn es im Bereich von Blöcken geboren wird [coolDownEndBlock (wenn das Baby zum Erscheinen bereit ist), der aktuelle Block ist + 256 (ungefähr)]. Sie können dies folgendermaßen begründen: Wenn sich das Baby im Mutterleib der Mutterkatze befindet, mutieren seine Gene im Laufe der Zeit aufgrund der Entropiequelle in Form eines Hash des vorhergesagten coolDownEndBlock-Blocks, der sich ebenfalls im Laufe der Zeit ändert. Daher können Sie mit diesem Programm überprüfen, wie das Gen des Babys aussehen wird, wenn es gerade geboren wurde. Und wenn Ihnen dieses Gen nicht gefällt, können Sie (durchschnittlich) weitere 256 Blöcke warten und das neue Gen überprüfen.
Jemand könnte sagen, dass dies nicht ausreicht, da nur eine 100% ige Genauigkeit der Vorhersage bereits vor der Schwangerschaft einer Mutter-Katze als idealer Hack angesehen werden kann. Dies ist jedoch nicht möglich, da das Gen des Kätzchens nicht nur durch die Gene seiner Eltern bestimmt wird, sondern auch durch den vorhergesagten Hash des Blocks als Mutationsfaktor, der vor der Befruchtung einfach nicht bekannt sein kann.
Was kann verbessert werden und was sind die Nuancen hier?
Wir haben die Änderungen, die im realen logischen Teil des Smart-Vertrags (Label 25 und alles danach) auf dem Stack auftreten, schnell durchgesehen und sind der Ansicht, dass dieser vorhersehbare Teil des mixGene-Codes einer Analyse und Untersuchung unterliegt. Wir hoffen, dass der Block-Hash als Mutationsfaktor auch eine gewisse physikalische Bedeutung hat, um beispielsweise zu bestimmen, welches Gen mutiert werden soll. Wenn wir das herausfinden, erhalten wir das ursprüngliche Gen ohne Mutationen. Dies ist nützlich, denn wenn Sie kein gutes Quellgen haben, reicht möglicherweise nicht einmal die beste Mutation aus.
Wir haben auch die Korrelation zwischen dem 256-Bit-Gen und den Kätzchenmerkmalen (Augenfarbe, Schwanztyp usw.) nicht gemessen, aber wir glauben, dass dies mit Hilfe eines Hochleistungsbot und eines einfachen Klassifikators durchaus möglich ist.
Im Allgemeinen verstehen wir die Absicht des CryptoKitties-Entwicklungsteams, die Mutation über einen kurzen Zeitraum zu stabilisieren. Die Kehrseite dieses Ansatzes ist jedoch die Fähigkeit, eine Analyse wie wir durchzuführen.
Wir möchten uns auch bei der wunderbaren Ethereum-Community für die Entwicklung von Tools wie Etherscan, Hevm, Evmdis, Trüffel, Testrpc, Myetherwallet und Solidity bedanken. Dies ist eine sehr coole Community und wir freuen uns, ein Teil davon zu sein.
Und schließlich der geänderte Code
https://github.com/modong/GeneScienceCracked/Denken Sie daran, $ CONSTBLOCKHASH $ in den Hash des vorhergesagten Blocks zu ändern.
