
Unser Tag beginnt mit dem Satz "Guten Morgen!". Tagsüber sprechen wir mit Kollegen, Verwandten, Freunden und sogar Fremden, die nach dem Weg zur nächsten U-Bahn fragen. Wir sprechen auch dann, wenn niemand um uns herum ist, um unsere eigenen Überlegungen besser wahrzunehmen. All dies ist unsere Rede - ein Geschenk, das mit vielen anderen Möglichkeiten des menschlichen Körpers wirklich unvergleichlich ist. Die Sprache ermöglicht es uns, soziale Verbindungen herzustellen, Gedanken und Emotionen auszudrücken und uns beispielsweise in Liedern auszudrücken.
Und so tauchten intelligente Autos im Leben der Menschen auf. Eine Person, entweder aus Neugier oder aus Durst nach neuen Errungenschaften, versucht, der Maschine das Sprechen beizubringen. Aber um sprechen zu können, müssen Sie hören und zuhören. Heutzutage ist es schwierig, mit einem Programm (zum Beispiel Siri) zu überraschen, das Sprache erkennen, ein Restaurant auf der Karte finden, Mutter anrufen und sogar einen Witz erzählen kann. Sie versteht viel, natürlich nicht alles, aber viel. Aber das war natürlich nicht immer so. Vor Jahrzehnten war es zum Glück, wenn eine Maschine mindestens ein Dutzend Wörter verstehen konnte.
Heute werden wir in die Geschichte eintauchen, wie die Menschheit mit der Maschine sprechen konnte. Die Durchbrüche im Laufe der Jahrhunderte in diesem Bereich haben als Impuls für die Entwicklung der Spracherkennungstechnologie gedient. Wir untersuchen auch, wie moderne Geräte unsere Stimmen wahrnehmen und verarbeiten. Lass uns gehen.
Die Ursprünge der Spracherkennung
Was ist Sprache? Grob gesagt ist das gesund. Um Sprache zu erkennen, müssen Sie zuerst den Ton erkennen und aufnehmen.
Jetzt haben wir iPods, MP3-Player, bevor es Tonbandgeräte gab, noch frühere Grammophone und Grammophone. Dies sind alles Geräte zum Abspielen von Sounds. Aber wer war der Stammvater von allen?
 Thomas Edison mit seiner Erfindung. 1878 Jahre
Thomas Edison mit seiner Erfindung. 1878 JahreEs war ein Phonograph. 29. November 1877 Der große Erfinder Thomas Edison demonstrierte seine neue Kreation, die Klänge aufnehmen und wiedergeben kann. Es war ein Durchbruch, der das größte Interesse der Gesellschaft weckte.
Das Prinzip des Phonographen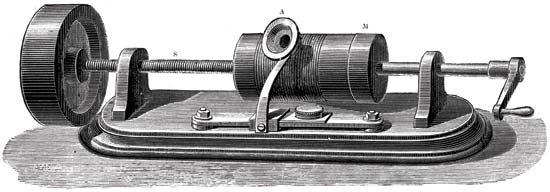
Die Hauptteile des Schallaufzeichnungsmechanismus waren ein mit Folie beschichteter Zylinder und eine Schneidnadel. Die Nadel bewegte sich entlang eines sich drehenden Zylinders. Mechanische Schwingungen wurden mit einer Mikrofonmembran erfasst. Infolgedessen hinterließ die Nadel Markierungen auf der Folie. Als Ergebnis erhielten wir einen Zylinder mit einem Rekord. Um es zu reproduzieren, wurde ursprünglich der gleiche Zylinder wie bei der Aufnahme verwendet. Aber die Folie war zu zerbrechlich und schnell abgenutzt, weil die Aufzeichnungen nur von kurzer Dauer waren. Dann fingen sie an, Wachs aufzutragen, das den Zylinder bedeckte. Um die Existenz der Aufzeichnungen zu verlängern, begannen sie mit dem Galvanisieren zu kopieren. Durch die Verwendung härterer Materialien hielten die Kopien viel länger.
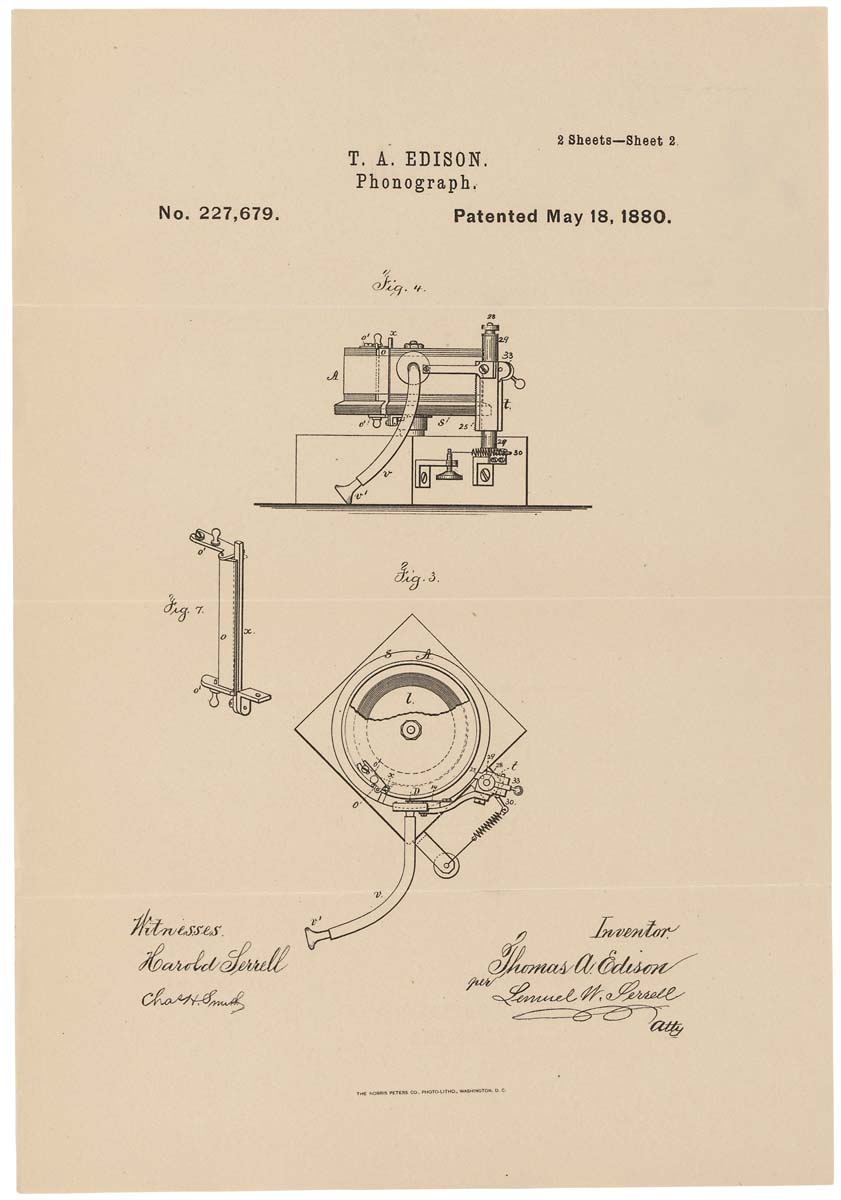 Schematische Darstellung eines Phonographen auf einem Patent. 1880, 18. Mai
Schematische Darstellung eines Phonographen auf einem Patent. 1880, 18. MaiAngesichts der oben genannten Nachteile war der Phonograph zwar eine interessante Maschine, wurde aber nicht aus den Regalen gewischt. Erst mit dem Aufkommen des Plattenphonographen - besser bekannt als das Grammophon - kam die öffentliche Anerkennung. Die Neuheit ermöglichte längere Aufnahmen (der erste Phonograph konnte nur ein paar Minuten aufnehmen), was lange Zeit diente. Und das Grammophon selbst war mit einem Lautsprecher ausgestattet, der die Wiedergabelautstärke erhöhte.
Thomas Edison hat den Phonographen ursprünglich als Gerät zur Aufzeichnung von Telefongesprächen konzipiert, beispielsweise als moderne Diktiergeräte. Seine Kreation hat jedoch bei der Reproduktion von Musikwerken große Popularität erlangt. Als Beginn für die Bildung der Aufnahmeindustrie gedient.
Rede "Orgel"
Bell Labs ist berühmt für seine Erfindungen auf dem Gebiet der Telekommunikation. Eine solche Erfindung war Voder.
Bereits 1928 begann Homer Dudley mit der Arbeit an einem Vocoder, einem Gerät, das Sprache synthetisieren kann. Wir werden später über ihn sprechen. Jetzt werden wir seinen Teil betrachten - den Vader.
 Schematische Darstellung eines Vaders
Schematische Darstellung eines VadersDas Grundprinzip des Vaders bestand darin, die menschliche Sprache in akustische Komponenten zu zerlegen. Die Maschine war äußerst komplex und konnte nur von einem geschulten Bediener bedient werden.
Vader ahmte die Auswirkungen des menschlichen Stimmapparates nach. Es gab 2 Hauptgeräusche, die der Bediener mit seinem Handgelenk auswählen konnte. Fußpedale wurden verwendet, um den Generator für diskontinuierliche Schwingungen (Summgeräusche) zu steuern, die stimmhafte Vokale und Nasengeräusche erzeugten. Eine Gasentladungsröhre (Zischen) erzeugte Zischlaute (Reibungskonsonanten). Alle diese Sounds wurden durch einen der 10 Filter geleitet, der mit den Tasten ausgewählt wurde. Es gab auch spezielle Tasten für Klänge wie "p" oder "d" und für die Affrikate "j" im Wort "Kiefer" und "ch" im Wort "Käse".
Dieser kleine Auszug aus der Präsentation des Vaders zeigt deutlich das Prinzip seiner Bedienung und BedieneraktionenEin Bediener kann erst nach mehreren Monaten intensiven Trainings und Trainings eine gültige Sprache wiedergeben.
Zum ersten Mal wurde der Träger 1939 auf einer Ausstellung in New York vorgeführt.
Speichern durch Sprachsynthese
Stellen Sie sich nun einen Vocoder vor, zu dem auch der oben genannte Fahrer gehörte.
 Eines der Vocoder-Modelle: HY-2 (1961)
Eines der Vocoder-Modelle: HY-2 (1961)Der Vocoder sollte ursprünglich die Frequenzressourcen von Funkverbindungen beim Übertragen von Sprachnachrichten sparen. Anstelle der Stimme selbst wurden die Werte ihrer spezifischen Parameter übertragen, die vom Sprachsynthesizer am Ausgang verarbeitet wurden.
Die Basis des Vocoders waren drei Haupteigenschaften:
- Geräuschgenerator (Konsonantentöne);
- Tongenerator (Vokale);
- formale Filter (Wiederherstellung der individuellen Eigenschaften des Sprechers).
Trotz seines ernsthaften Zwecks zog der Vocoder die Aufmerksamkeit elektronischer Musiker auf sich. Durch die Umwandlung des Quellensignals und die Wiedergabe auf einem anderen Gerät konnten verschiedene Effekte erzielt werden, beispielsweise der Effekt eines Musikinstruments, das mit einer „menschlichen Stimme“ singt.
Zählmaschine
Bereits 1952 waren die Technologien nicht so fortschrittlich wie heute. Dies hinderte die begeisterten Wissenschaftler jedoch nicht daran, sich nach Ansicht vieler unmögliche Aufgaben zu stellen. Die Herren Stephen Balashek (S. Balashek), Ralon Biddulf (R. Biddulph) und K.Kh. Davis (KH Davis) beschloss, der Maschine beizubringen, ihre Sprache zu verstehen. Der Idee folgend entstand Audreys Auto. Ihre Fähigkeiten waren sehr begrenzt - sie konnte nur Zahlen von 0 bis 9 erkennen. Dies reichte jedoch bereits aus, um einen Durchbruch in der Computertechnologie sicher zu erklären.
 Audrey mit einem seiner Schöpfer (laut Internet korrigieren Sie mich, wenn es nicht ist)
Audrey mit einem seiner Schöpfer (laut Internet korrigieren Sie mich, wenn es nicht ist)Trotz seiner geringen Fähigkeiten konnte sich Audrey nicht der gleichen Dimensionen rühmen. Sie war ein ziemlich großes „Mädchen“ - der Relaisschrank war fast 2 Meter hoch und alle Elemente besetzten einen kleinen Raum. Was für Computer dieser Zeit nicht überraschend ist.
Das Verfahren der Interaktion zwischen dem Bediener und Audrey hatte auch einige Bedingungen. Der Bediener sprach die Wörter (in diesem Fall Zahlen) in das Mobilteil eines normalen Telefons. Achten Sie darauf, dass zwischen den einzelnen Wörtern eine Pause von 350 Millisekunden eingehalten wird. Audrey akzeptierte die Informationen, übersetzte sie in ein elektronisches Format und schaltete eine bestimmte Glühbirne ein, die einer bestimmten Ziffer entsprach. Ganz zu schweigen von der Tatsache, dass nicht jeder Bediener eine genaue Antwort erhalten konnte. Um eine Genauigkeit von 97% zu erreichen, musste der Bediener eine Person sein, die lange Zeit mit Audrey „Geschwätz“ geübt hatte. Mit anderen Worten, Audrey verstand nur ihre Schöpfer.
Selbst unter Berücksichtigung aller Mängel von Audrey, die nicht mit Konstruktionsfehlern, sondern mit den Einschränkungen der damaligen Technologie verbunden sind, wurde sie der erste Stern am Horizont von Maschinen, die die menschliche Stimme verstehen.
Die Zukunft im Schuhkarton
1961 wurde im IBM Advanced Systems Development Laboratory ein neues Wundergerät entwickelt - die Shoebox, die 16 Wörter (ausschließlich auf Englisch) und Zahlen von 0 bis 9 erkennen kann. Der Autor dieses Computers war William C. Dersch.
 Schuhkarton von IBM
Schuhkarton von IBMDer ungewöhnliche Name entsprach dem Aussehen der Maschine, sie hatte Größe und Form wie ein Schuhkarton. Das einzige, was mir aufgefallen ist, war das Mikrofon, das an die drei Audiofilter angeschlossen war, die zur Erkennung von hohen, mittleren und niedrigen Tönen erforderlich sind. Die Filter wurden mit einem Logikdecoder (Diodentransistor-Logikschaltung) und einem Lichtschaltermechanismus verbunden.
Der Bediener nahm das Mikrofon an den Mund und sprach ein Wort aus (z. B. Nummer 7). Die Maschine wandelte akustische Daten in elektronische Signale um. Das Ergebnis des Verständnisses war die Aufnahme einer Glühbirne mit der Signatur "7". Shoebox versteht nicht nur einzelne Wörter, sondern kann auch einfache Rechenprobleme (wie 5 + 6 oder 7-3) verstehen und die richtige Antwort geben.
Shoebox wurde 1962 von seinem Schöpfer auf der Seattle World Expo vorgestellt.
Telefongespräch mit dem Auto
Im Jahr 1971 beschloss IBM, bekannt für seine Liebe zu innovativen Erfindungen und Technologien, die Spracherkennung in die Praxis umzusetzen. Das automatische Anrufidentifizierungssystem ermöglichte es einem Techniker in den USA, einen Computer in Raleigh, North Carolina, anzurufen. Der Anrufer könnte eine Frage stellen und eine Sprachantwort darauf erhalten. Die Einzigartigkeit dieses Systems bestand darin, die vielen Stimmen aufgrund ihrer Tonalität, Betonung, Sprachlautstärke usw. zu verstehen.
Harpyie schwebt hoch
Das Büro für fortgeschrittene Forschungsprojekte des Verteidigungsministeriums (kurz DARPA) kündigte 1971 den Start eines Entwicklungs- und Forschungsprogramms zur Spracherkennung an, mit dem eine Maschine geschaffen werden soll, die 1.000 Wörter erkennen kann. Ein mutiges Projekt angesichts der Erfolge seines Vorgängers in zehn Worten. Dem menschlichen Einfallsreichtum sind jedoch keine Grenzen gesetzt. 1976 demonstriert die Carnegie Mellon University die Harpyie, die 1011 Wörter erkennen kann.
Harpyie-VideodemonstrationDie Universität hat bereits Spracherkennungssysteme entwickelt - Hearsay-1 und Dragon. Sie wurden als Grundlage für die Implementierung von Harpyie verwendet.
In Hearsay-1 wird Wissen (d. H. Ein Maschinenwörterbuch) in Form von Prozeduren und in Dragon in Form eines Markov-Netzwerks mit einem a priori probabilistischen Übergang dargestellt. Bei Harpy wurde beschlossen, das neueste Modell zu verwenden, jedoch ohne diesen Übergang.
In diesem Video wird das Funktionsprinzip genauer beschrieben.
Einfach ausgedrückt, können Sie ein Netzwerk darstellen - eine Folge von Wörtern und deren Kombinationen sowie Töne mit einem einzigen Wort, damit die Maschine die unterschiedliche Aussprache desselben Wortes versteht.
Harpyie verstand 5 Bediener, darunter drei Männer und zwei Frauen. Das sprach für die größeren Rechenkapazitäten dieser Maschine. Die Spracherkennungsgenauigkeit betrug ungefähr 95%.
Tangora von IBM
In den frühen 1980er Jahren beschloss IBM, ein System zu entwickeln, das bis Mitte des Jahrzehnts mehr als 20.000 Wörter erkennen kann. So wurde Tangora geboren, in dessen Arbeit versteckte Markov-Modelle verwendet wurden. Trotz des ziemlich beeindruckenden Wortschatzes benötigte das System nicht mehr als 20 Minuten Zusammenarbeit mit dem neuen Bediener (der sprechenden Person), um zu lernen, wie man seine Sprache erkennt.
Lebende Puppe
1987 veröffentlichte die Spielzeugfirma Worlds of Wonder eine revolutionäre Neuheit - eine sprechende Puppe namens Julie. Das beeindruckendste Merkmal des dänischen Spielzeugs war die Fähigkeit, es zu trainieren, um die Rede des Besitzers zu erkennen. Julie konnte ziemlich gut sprechen. Darüber hinaus war die Puppe mit vielen Sensoren ausgestattet, dank derer sie reagierte, wenn sie aufgenommen, gekitzelt oder von einem dunklen in einen hellen Raum gebracht wurde.
Worlds of Wonder-Werbespot Julie zeigt seine FunktionenIhre Augen und Lippen waren beweglich, was ein noch lebendigeres Bild erzeugte. Neben der Puppe selbst konnte ein Buch gekauft werden, in dem Bilder und Wörter in Form von speziellen Aufklebern gemacht wurden. Wenn Sie die Puppen mit den Fingern über sie halten, spricht sie an, was sie sich bei Berührung „anfühlt“. Doll Julie war das erste Gerät mit einer Spracherkennungsfunktion, die jedem zur Verfügung stand.
Die erste Diktiersoftware

1990 veröffentlichte Dragon Systems mit DragonDictate die erste auf Spracherkennung basierende Personal Computer-Software. Das Programm funktionierte ausschließlich unter Windows. Der Benutzer musste zwischen jedem Wort kleine Pausen einlegen, damit das Programm sie analysieren konnte. In Zukunft wurde eine perfektere Version veröffentlicht, mit der Sie kontinuierlich sprechen können - Dragon NaturallySpeaking (es ist jetzt verfügbar, während das ursprüngliche DragonDictate seit Windows 98 nicht mehr aktualisiert wird). Trotz seiner „Langsamkeit“ hat DragonDictate bei PC-Benutzern, insbesondere bei Menschen mit Behinderungen, große Popularität erlangt.
Nicht ägyptische Sphinx
Die Carnegie Mellon University, die bereits früher "beleuchtet" wurde, ist der Geburtsort eines anderen historisch wichtigen Spracherkennungssystems - Sphinx 2.
 Schöpfer der Sphinx Xuedong Huang
Schöpfer der Sphinx Xuedong HuangDer direkte Autor des Systems war Xuedong Huang. Sphinx 2 unterschied sich von seinem Vorgänger durch seine Geschwindigkeit. Das System konzentrierte sich auf die Spracherkennung in Echtzeit für Programme, die gesprochene (alltägliche) Sprache verwenden. Zu den Merkmalen von Sphinx 2 gehörten: Hypothesenbildung, dynamisches Umschalten zwischen Sprachmodellen, Erkennung von Äquivalenten usw.
Sphinx 2-Code wurde in vielen kommerziellen Produkten verwendet. Und im Jahr 2000 veröffentlichte Kevin Lenzo auf der SourceForge-Website den Quellcode des Systems zur allgemeinen Anzeige. Diejenigen, die den Quellcode von Sphinx 2 und seinen anderen Variationen studieren möchten, können dem
Link folgen.
Medizinisches Diktat
1996 brachte IBM MedSpeak auf den Markt, das erste kommerzielle Produkt mit Spracherkennung. Es sollte dieses Programm bei Ärzten verwenden, um medizinische Aufzeichnungen zusammenzustellen. Zum Beispiel äußerte eine Radiologe, die die Bilder der Patientin untersuchte, ihre Kommentare, die das MedSpeak-System in Text übersetzte.
Bevor wir zu den bekanntesten Vertretern von Programmen mit Spracherkennung übergehen, wollen wir kurz auf einige weitere historische Ereignisse im Zusammenhang mit dieser Technologie eingehen.
Historischer Blitz
- 2002 - Microsoft integriert die Spracherkennung in alle Office-Produkte.
- 2006 - Die US National Security Agency beginnt mit der Verwendung von Spracherkennungsprogrammen, um Grenzwertschlüsselwörter in Konversationsaufzeichnungen zu identifizieren.
- 2007 (30. Januar) - Microsoft veröffentlicht Windows Vista - das erste Betriebssystem mit Spracherkennung;
- 2007 - Google führt toget-411 ein - ein Telefonweiterleitungssystem (eine Person ruft eine Nummer an, gibt an, welche Organisation oder Person sie benötigt, und das System verbindet sie). Das System funktionierte in den USA und Kanada.
- 2008 (14. November) - Google startet die Sprachsuche auf iPhone-Mobilgeräten. Dies war der erste Einsatz der Spracherkennungstechnologie in Mobiltelefonen.
Und jetzt kommen wir zu einer Zeit, in der viele Menschen auf Spracherkennungstechnologie gestoßen sind.
Damen streiten sich nicht
Am 4. Oktober 2011 kündigte Apple Siri an, dessen Dekodierung für sich selbst spricht - die Schnittstelle für Sprachinterpretation und Spracherkennung (d. H. Die Schnittstelle für Interpretation und Spracherkennung).

Die Geschichte der Siri-Entwicklung ist sehr lang (tatsächlich hat sie 40 Jahre Arbeit) und interessant. Die Tatsache seiner Existenz und seiner umfangreichen Funktionalität ist die gemeinsame Arbeit vieler Unternehmen und Universitäten. Wir werden uns jedoch nicht auf dieses Produkt konzentrieren, da es in dem Artikel nicht um Siri geht, sondern um die Spracherkennung im Allgemeinen.
Microsoft wollte nicht den Rücken streifen, weil sie 2014 (2. April) ihren virtuellen digitalen Assistenten Cortana ankündigten.

Die Funktionalität von Cortana ähnelt der seines Konkurrenten Siri, mit Ausnahme eines flexibleren Systems zum Festlegen des Zugriffs auf Informationen.
Debatte über Cortana oder Siri. Wer ist besser? " durchgeführt seit ihrem Erscheinen auf dem Markt. Wie im Allgemeinen und der Kampf zwischen Benutzern von iOS und Android. Das ist aber gut Konkurrierende Produkte, die versuchen, besser als ihre Konkurrenten zu wirken, bieten immer mehr neue Möglichkeiten, entwickeln und verwenden fortschrittlichere Technologien und Techniken auf demselben Gebiet der Spracherkennung. Mit nur einem Vertreter in einem Bereich der Verbrauchertechnologie besteht keine Notwendigkeit, über deren rasche Entwicklung zu sprechen.
Ein kleines lustiges Video des Gesprächs zwischen Siri und Cortana (offensichtlich gebaut, aber nicht weniger lustig). Achtung !: In diesem Video gibt es Obszönitäten.
Gespräch mit Autos. Wie verstehen sie uns?
Wie ich bereits erwähnt habe, ist Sprache grob gesagt gesund. Und was ist der Sound für das Auto? Dies sind Änderungen (Schwankungen) des Luftdrucks, d.h. Schallwellen. Damit das Gerät (Computer oder Telefon) Sprache erkennen kann, müssen Sie zuerst diese Schwankungen berücksichtigen. Die Messfrequenz sollte mindestens 8.000 Mal pro Sekunde betragen (noch besser - 44.100 Mal pro Sekunde). Wenn die Messungen mit großen Zeitunterbrechungen durchgeführt werden, erhalten wir einen ungenauen Ton, was unleserliche Sprache bedeutet. Der oben beschriebene Prozess wird als 8-kHz- oder 44,1-kHz-Digitalisierung bezeichnet.
Wenn Daten über die Schwingungen von Schallwellen gesammelt werden, müssen diese sortiert werden. Da wir im allgemeinen Haufen sowohl Sprach- als auch Sekundärgeräusche haben (Maschinengeräusche, raschelndes Papier, Geräusche eines funktionierenden Computers usw.). Durch die Durchführung mathematischer Operationen können wir genau unsere Sprache aussortieren, die erkannt werden muss.
Als nächstes folgt die Analyse der ausgewählten Schallwellensprache. Da es aus vielen separaten Komponenten besteht, die bestimmte Klänge bilden (zum Beispiel "ah" oder "ee"). Durch Hervorheben dieser Funktionen und Konvertieren in numerische Entsprechungen können Sie bestimmte Wörter definieren.
Die englische Sprache besteht zum Beispiel aus mehr als 40 Phonemen (44, um genau zu sein, und nach einigen Theorien gibt es mehr als 100), d.h. Sprachlaute. Die Maschine bestimmt sie alle, da im Verlauf ihrer Entwicklung Trainingstests durchgeführt wurden, bei denen verschiedene Personen dieselben Wörter und Sätze aussprachen. So könnte die Maschine die Ähnlichkeiten und Unterschiede bestimmen und einen Algorithmus zur Bestimmung von Geräuschen bilden. Es ist zu berücksichtigen, dass das „Aussehen“ eines Klangs nicht nur von einer Person (oder vielmehr von ihrer Aussprache, seinem Akzent, dem Timbre der Stimme usw.) beeinflusst wird, sondern auch von einer Kombination verschiedener Phoneme in einem Wort. Zum Beispiel sehen "t" in "sTar" und "t" in "ciTy" für ein Auto völlig anders aus.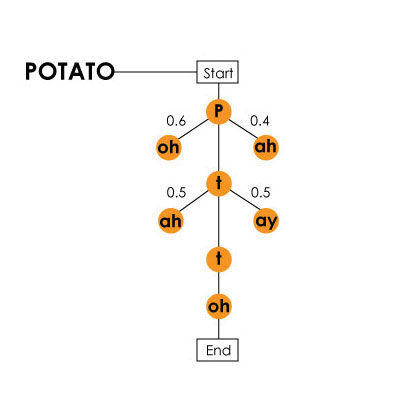 Markov-Modell mit dem Wort "Kartoffel" (Kartell) als Beispiel / ist im Video über das Harpyie-System vorhanden
Markov-Modell mit dem Wort "Kartoffel" (Kartell) als Beispiel / ist im Video über das Harpyie-System vorhanden, , . , «hang ten», — «hey, ngten», «ngten».
, , . , (), , №2 №1. «What do cats like for breakfast?» «water gaslight four brick vast?». , . . , , , . .
, . , , .
Nachwort
, . . - , ( , ), . . , , , . , -, , .
. 25% 3 6 !
! VPS (KVM) , , — !
VPS (KVM) c ( VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD 4TB HDD / 1Gbps 10TB — $29 / , RAID1 RAID10) , , , , , «»!
. c Dell R730xd 5-2650 v4 9000 ? Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 !