
In den letzten zehn Jahren haben sich Deep Neural Networks (DNNs) zu einem hervorragenden Werkzeug für eine Reihe von KI-Aufgaben wie Bildklassifizierung, Spracherkennung und sogar Teilnahme an Spielen entwickelt. Als die Entwickler versuchten zu zeigen, was den Erfolg von DNN im Bereich der Bildklassifizierung verursacht hat, und Visualisierungstools (z. B. Deep Dream, Filter) erstellten, um zu verstehen, „was“ das DNN-Modell genau „studiert“, entstand eine neue interessante Anwendung : „Stil“ aus einem Bild extrahieren und auf einen anderen, anderen Inhalt anwenden. Dies wurde als "Bildstilübertragung" bezeichnet.
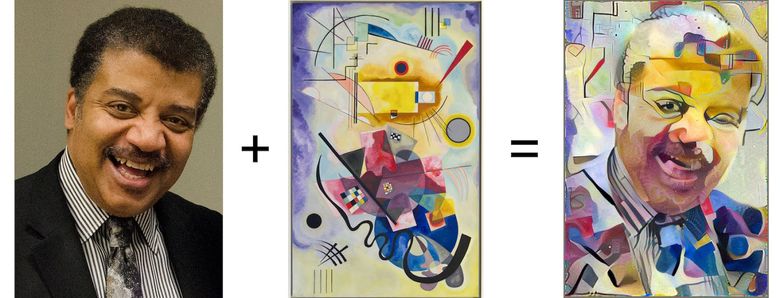
Links: Bild mit nützlichem Inhalt, in der Mitte: Bild mit Stil, rechts: Inhalt + Stil (Quelle: Google Research Blog )
Dies weckte nicht nur das Interesse vieler anderer Forscher (z. B. 1 und 2 ), sondern führte auch zur Entstehung mehrerer erfolgreicher mobiler Anwendungen. In den letzten Jahren haben sich diese visuellen Übertragungsmethoden erheblich verbessert.

Wrapping im Adobe-Stil (Quelle: Engadget )

Beispiel von der Prisma- Website
Eine kurze Einführung in solche Algorithmen:
Trotz der Fortschritte bei der Arbeit mit Bildern war die Anwendung dieser Techniken in anderen Bereichen, beispielsweise zur Verarbeitung von Musik, sehr begrenzt (siehe 3 und 4 ), und die Ergebnisse sind überhaupt nicht so beeindruckend wie bei Bildern. Dies deutet darauf hin, dass es viel schwieriger ist, Stil in der Musik zu übertragen. In diesem Artikel werden wir das Problem genauer untersuchen und einige mögliche Ansätze diskutieren.
Warum ist es so schwierig, Stil in der Musik zu übertragen?
Beantworten wir zunächst die Frage: Was ist "Stilübertragung" in der Musik ? Die Antwort ist nicht so offensichtlich. In Bildern sind die Konzepte „Inhalt“ und „Stil“ intuitiv. "Bildinhalt" beschreibt die dargestellten Objekte, z. B. Hunde, Häuser, Gesichter usw., und "Bildstil" bezieht sich auf Farben, Beleuchtung, Pinselstriche und Textur.
Musik ist jedoch semantisch abstrakt und mehrdimensionaler Natur. "Musikinhalt" kann in verschiedenen Kontexten unterschiedliche Bedeutungen haben. Oft ist der Inhalt der Musik mit einer Melodie verbunden und der Stil mit einem Arrangement oder einer Harmonisierung. Der Inhalt kann jedoch der Text sein, und verschiedene Melodien, die zum Singen verwendet werden, können als verschiedene Stile interpretiert werden. In der klassischen Musik kann der Inhalt als Partitur betrachtet werden (einschließlich Harmonisierung), während der Stil die Interpretation der Noten durch den Interpreten ist, der seinen eigenen Ausdruck einbringt (Variieren und Hinzufügen einiger Klänge von sich selbst). Schauen Sie sich einige dieser Videos an, um die Essenz der Stilübertragung in der Musik besser zu verstehen:
Im zweiten Video werden verschiedene Techniken des maschinellen Lernens verwendet.
Daher ist die Übertragung von Stil in der Musik per Definition schwer zu formalisieren. Es gibt andere Schlüsselfaktoren, die die Aufgabe erschweren:
- Maschinen BAD verstehen Musik ( vorerst ): Der Erfolg bei der Übertragung von Stil in Bildern beruht auf dem Erfolg von DNN bei Aufgaben im Zusammenhang mit dem Verständnis von Bildern, wie z. B. der Objekterkennung. Da DNNs Eigenschaften lernen können, die von Objekt zu Objekt unterschiedlich sind, können Backpropagation-Techniken verwendet werden, um das Zielbild so zu ändern, dass es den Eigenschaften des Inhalts entspricht. Obwohl wir erhebliche Fortschritte bei der Erstellung von DNN-basierten Modellen erzielt haben, die in der Lage sind, musikalische Aufgaben zu verstehen (z. B. das Transkribieren von Melodien, das Definieren eines Genres usw.), sind wir noch weit von den in der Bildverarbeitung erreichten Höhen entfernt. Dies ist ein ernstes Hindernis für die Übertragung von Stil in der Musik. Bestehende Modelle können einfach nicht die „hervorragenden“ Eigenschaften erlernen, mit denen Musik klassifiziert werden kann. Dies bedeutet, dass die direkte Anwendung von Stilübertragungsalgorithmen, die beim Arbeiten mit Bildern verwendet werden, nicht zum gleichen Ergebnis führt.
- Musik ist flüchtig : Es sind Daten, die dynamische Serien darstellen, dh ein musikalisches Fragment ändert sich mit der Zeit. Dies erschwert das Lernen. Obwohl wiederkehrende neuronale Netze und LSTM (Long Short-Term Memory) es Ihnen ermöglichen, mehr aus transienten Daten zu lernen, müssen wir dennoch zuverlässige Modelle erstellen, die lernen, wie die langfristige Struktur von Musik reproduziert werden kann (Hinweis: Dies ist ein aktuelles Forschungsgebiet, und Wissenschaftler des Google-Teams Magenta hat hier einige Erfolge erzielt.
- Musik ist diskret (zumindest auf symbolischer Ebene): Symbolisch oder auf Papier aufgenommene Musik ist diskreter Natur. In dem einheitlichen Temperament , dem heute beliebtesten Stimmsystem für Musikinstrumente, nehmen Klangtöne auf einer kontinuierlichen Frequenzskala diskrete Positionen ein. Gleichzeitig liegt die Dauer der Töne auch im diskreten Raum (normalerweise Vierteltöne, Volltöne usw.). Daher ist es sehr schwierig, die Pixel-Back-Propagation-Methoden (die zum Arbeiten mit Bildern verwendet werden) im Bereich der symbolischen Musik anzupassen.
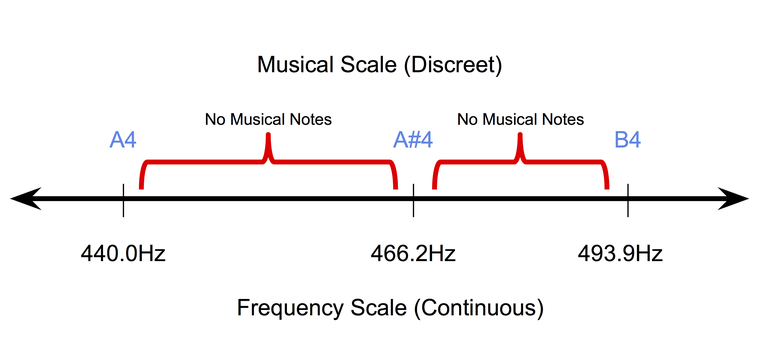
Die diskrete Natur von Noten in einem einheitlichen Temperament.
Daher sind die Techniken zur Übertragung des Stils in Bildern nicht direkt auf Musik anwendbar. Dazu müssen sie mit Schwerpunkt auf musikalischen Konzepten und Ideen verarbeitet werden.
Wofür ist die Übertragung von Stil in der Musik?
Warum müssen Sie dieses Problem lösen? Wie bei Bildern sind die möglichen Anwendungen der Stilübertragung in der Musik sehr interessant. Zum Beispiel die Entwicklung eines Tools zur Unterstützung von Komponisten . Zum Beispiel ist ein automatisches Instrument, das eine Melodie mithilfe von Arrangements aus verschiedenen Genres transformieren kann, für Komponisten äußerst nützlich, die schnell verschiedene Ideen ausprobieren müssen. DJs werden sich auch für solche Instrumente interessieren.
Ein indirektes Ergebnis dieser Forschung wird eine signifikante Verbesserung der Musikinformatik sein. Wie oben erläutert, müssen die von uns erstellten Modelle für die Übertragung des Stils auf die Arbeit in der Musik lernen, verschiedene Aspekte besser zu "verstehen" .
Vereinfachen Sie die Übertragung von Stilen in der Musik
Beginnen wir mit einer sehr einfachen Aufgabe, monophone Melodien in verschiedenen Genres zu analysieren. Monophone Melodien sind Notenfolgen, die jeweils durch Ton und Dauer bestimmt werden. Der Tonhöhenverlauf hängt größtenteils von der Tonleiter der Melodie ab, und der Verlauf der Dauer hängt vom Rhythmus ab. Zunächst werden wir " Tonhöheninhalt" und "rhythmischen Stil" klar als zwei Einheiten trennen , mit denen Sie die Aufgabe der Stilübertragung umformulieren können. Wenn wir mit monophonen Melodien arbeiten, vermeiden wir jetzt auch die Aufgaben, die mit Arrangement und Text verbunden sind.
In Ermangelung vorgefertigter Modelle, die erfolgreich zwischen Tonverläufen und Rhythmen monophoner Melodien unterscheiden können, greifen wir zunächst auf einen sehr einfachen Ansatz zur Stilübertragung zurück. Anstatt zu versuchen, den in der Zielmelodie erlernten Toninhalt durch den im Zielrhythmus erlernten rhythmischen Stil zu ändern, werden wir versuchen, Muster von Tönen und Dauern aus verschiedenen Genres einzeln zu unterrichten und sie dann zu kombinieren. Ungefähres Schema des Ansatzes:
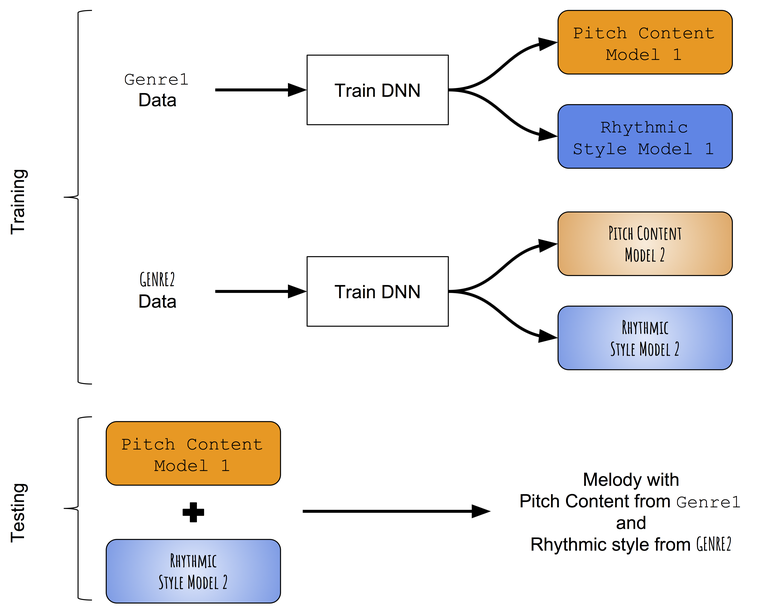
Schema der Methode des Intergenre-Style-Transfers.
Wir unterrichten getrennt Ton- und Rhythmusverläufe
Datenpräsentation
Wir werden monophone Melodien als eine Folge von Noten präsentieren, von denen jede einen Tonindex und eine Folge hat. Damit unser Präsentationsschlüssel unabhängig ist, verwenden wir die Präsentation anhand von Intervallen: Der Ton der nächsten Note wird als Abweichung (± Halbton) vom Ton der vorherigen Note dargestellt. Erstellen wir zwei Wörterbücher für Töne und Dauern, in denen jedem diskreten Zustand (für Ton: +1, -1, +2, -2 usw.; für Dauern: eine Viertelnote, eine vollständige Note, ein Viertel mit einem Punkt usw.) ein Index zugewiesen wird Wörterbuch.
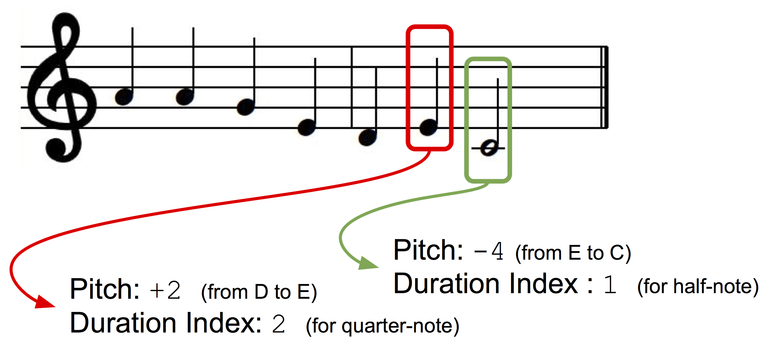
Präsentation von Daten.
Modellarchitektur
Wir werden dieselbe Architektur verwenden, die Colombo und Kollegen verwendet haben - sie haben gleichzeitig zwei neuronale LSTM-Netze demselben Musikgenre beigebracht: a) das Tonnetzwerk, das gelernt hat, den nächsten Ton basierend auf der vorherigen Note und der vorherigen Dauer vorherzusagen, b) das Dauer-Netzwerk, das gelernt hat, die nächste Dauer basierend auf der nächsten Note vorherzusagen und vorherige Dauer. Außerdem werden wir vor LSTM-Netzwerken Einbettungsebenen hinzufügen, um Eingangstonindizes und -dauern in gespeicherten Einbettungsräumen zu vergleichen. Die Architektur des neuronalen Netzwerks ist im Bild dargestellt:
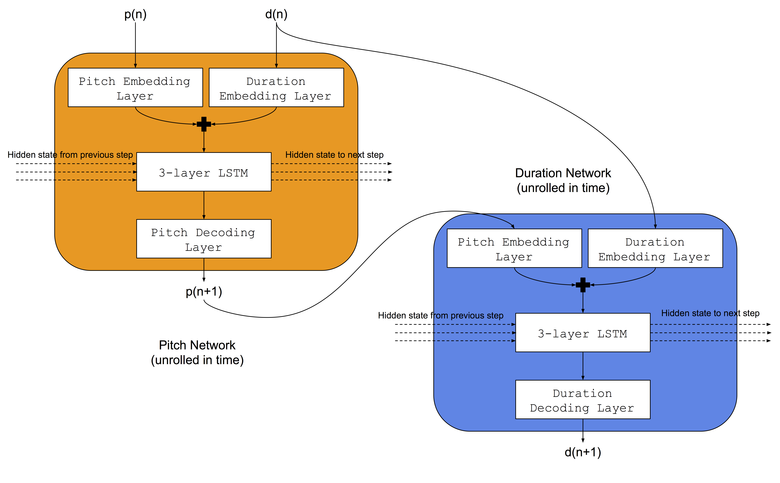
Trainingsverfahren
Für jedes Genre werden gleichzeitig Netzwerke trainiert, die für Töne und Dauer verantwortlich sind. Wir werden zwei Datensätze verwenden: a) Norbeck Folk Dataset , der ungefähr 2.000 irische und schwedische Volkslieder abdeckt, b) einen Jazzdatensatz (nicht öffentlich verfügbar), der ungefähr 500 Jazzmelodien abdeckt.
Zusammenführung trainierter Modelle
Während des Testens wird die Melodie zuerst unter Verwendung des Tonnetzwerks und des im ersten Genre trainierten Dauer-Netzwerks (z. B. Folk) erzeugt. Dann wird die Tonfolge aus der erzeugten Melodie am Eingang für ein Netzwerk von Sequenzen verwendet, die in einem anderen Genre (z. B. Jazz) trainiert wurden, und das Ergebnis ist eine neue Folge von Dauern. Daher hat eine Melodie, die unter Verwendung einer Kombination von zwei neuronalen Netzen erzeugt wird, eine Folge von Tönen, die dem ersten Genre (Folk) entsprechen, und eine Folge von Dauern, die dem zweiten Genre (Jazz) entsprechen.
Vorläufige Ergebnisse
Kurze Auszüge aus einigen der resultierenden Melodien:
Volkstöne und Volksdauern

Auszug aus der Notenschrift.
Volkstöne und Jazzdauern

Auszug aus der Notenschrift.
Jazz-Töne und Jazz-Sequenzen

Auszug aus der Notenschrift .
Jazz-Töne und Folk-Sequenzen

Auszug aus der Notenschrift.
Fazit
Obwohl der aktuelle Algorithmus zunächst nicht schlecht ist, weist er eine Reihe kritischer Nachteile auf:
- Es ist unmöglich, den Stil basierend auf einer bestimmten Zielmelodie zu übertragen . Modelle lernen Muster von Tönen und Dauern in einem Genre, was bedeutet, dass alle Transformationen vom Genre bestimmt werden. Es wäre ideal, ein Musikstück im Stil eines bestimmten Zielsongs oder -stücks zu modifizieren.
- Es ist nicht möglich, den Grad der Stiländerung zu steuern . Es wäre sehr interessant, einen „Griff“ zu bekommen, der diesen Aspekt regelt.
- Beim Zusammenführen von Genres ist es unmöglich, die musikalische Struktur in einer transformierten Melodie beizubehalten. Eine langfristige Struktur ist wichtig für die musikalische Bewertung im Allgemeinen, und damit die erzeugten Melodien musikalisch ästhetisch sind, muss die Struktur erhalten bleiben.
In den folgenden Artikeln werden Möglichkeiten zur Umgehung dieser Mängel untersucht.