AttnGAN-Betriebsbeispiel. In der oberen Reihe befinden sich mehrere Bilder mit unterschiedlichen Auflösungen, die von einem neuronalen Netzwerk erzeugt werden. Die zweite und dritte Zeile zeigen die Verarbeitung der fünf am besten geeigneten Wörter durch zwei Modelle der Aufmerksamkeit des neuronalen Netzwerks, um die relevantesten Abschnitte zu zeichnenDas automatische Erstellen von Bildern aus Textbeschreibungen in einer natürlichen Sprache ist ein grundlegendes Problem für viele Anwendungen, z. B. Kunstgenerierung und Computerdesign. Dieses Problem stimuliert auch den Fortschritt im Bereich des multimodalen KI-Trainings mit einer Beziehung zwischen Vision und Sprache.
Neuere Forschungen von Forschern auf diesem Gebiet basieren auf generativen kontradiktorischen Netzwerken (GANs). Der allgemeine Ansatz besteht darin, die gesamte Textbeschreibung in den globalen Satzvektor zu übersetzen. Dieser Ansatz zeigt eine Reihe beeindruckender Ergebnisse, hat jedoch die Hauptnachteile: das Fehlen klarer Details auf Wortebene und die Unfähigkeit, hochauflösende Bilder zu erzeugen. Ein Entwicklerteam der Lichai University, der Rutgers University, der Duke University (alle USA) und von Microsoft schlug eine
eigene Lösung für das Problem vor: Das neue neuronale Netzwerk
Attentional Generative Adversarial Network (AttnGAN) stellt eine Verbesserung des traditionellen Ansatzes dar und ermöglicht eine mehrstufige Änderung des generierten Bildes, wobei einzelne Wörter im Text geändert werden Beschreibung.
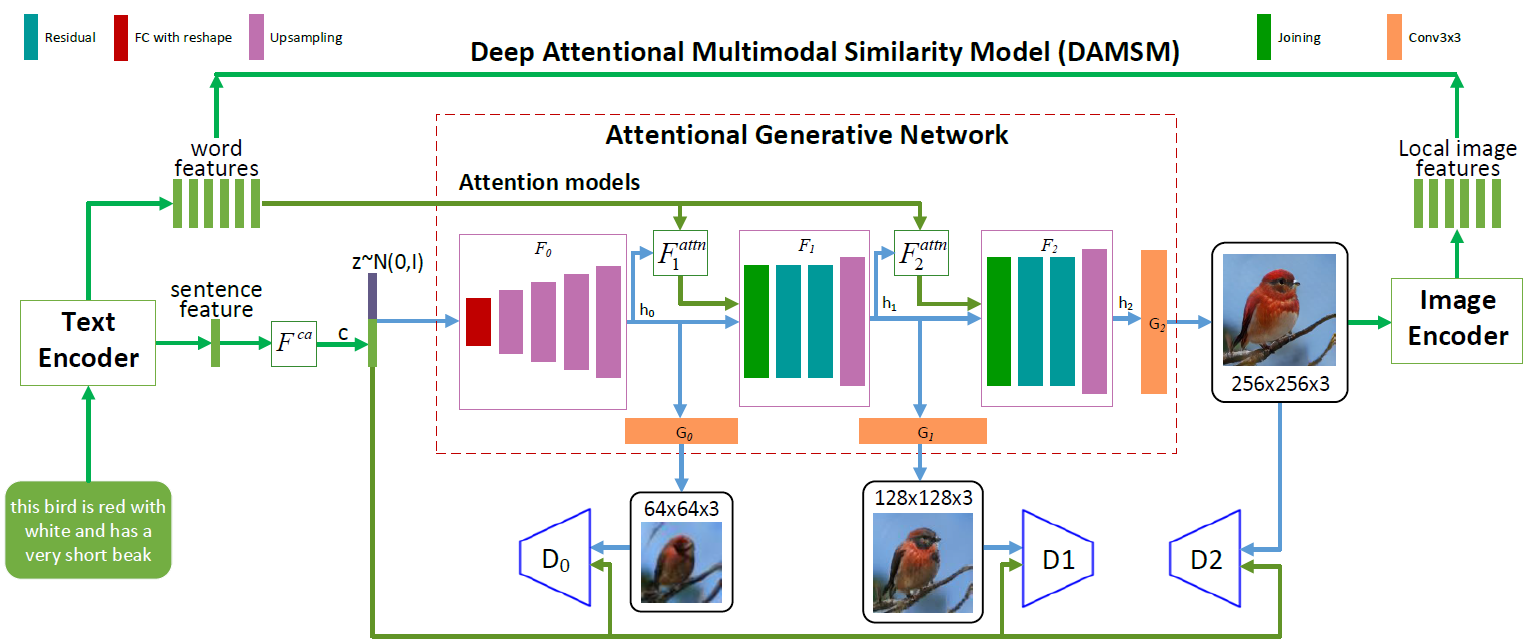 AttnGAN neuronale Netzwerkarchitektur. Jedes Aufmerksamkeitsmodell empfängt automatisch Bedingungen (d. H. Entsprechende Vokabularvektoren) zum Erzeugen verschiedener Bereiche des Bildes. Das DAMSM-Modul bietet zusätzliche Granularität für die Konformitätsverlustfunktion bei der Übersetzung von Bild zu Text im generativen Netzwerk
AttnGAN neuronale Netzwerkarchitektur. Jedes Aufmerksamkeitsmodell empfängt automatisch Bedingungen (d. H. Entsprechende Vokabularvektoren) zum Erzeugen verschiedener Bereiche des Bildes. Das DAMSM-Modul bietet zusätzliche Granularität für die Konformitätsverlustfunktion bei der Übersetzung von Bild zu Text im generativen NetzwerkWie Sie in der Abbildung sehen können, die die Architektur des neuronalen Netzwerks darstellt, weist das AttnGAN-Modell im Vergleich zu herkömmlichen Ansätzen zwei Neuerungen auf.
Erstens handelt es sich um ein kontradiktorisches Netzwerk, das die Aufmerksamkeit als Lernfaktor bezeichnet (Attentional Generative Adversarial Network). Das heißt, es implementiert den Aufmerksamkeitsmechanismus, der die Wörter bestimmt, die am besten zum Erzeugen der entsprechenden Teile des Bildes geeignet sind. Mit anderen Worten, zusätzlich zur Codierung der gesamten Textbeschreibung im globalen Vektorraum von Sätzen wird jedes einzelne Wort auch als Textvektor codiert. In der ersten Stufe verwendet das generative neuronale Netzwerk den globalen Vektorraum von Sätzen, um ein Bild mit niedriger Auflösung zu rendern. In den folgenden Schritten verwendet sie den Bildvektor in jeder Region, um Wörterbuchvektoren abzufragen, wobei die Aufmerksamkeitsebene verwendet wird, um den Wortkontextvektor zu bilden. Dann wird der regionale Bildvektor mit dem entsprechenden Wortkontextvektor kombiniert, um einen multimodalen Kontextvektor zu bilden, auf dessen Grundlage das Modell neue Bildmerkmale in den jeweiligen Regionen erzeugt. Auf diese Weise können Sie die Auflösung des gesamten Bilds effektiv erhöhen, da in jeder Phase mehr und mehr Details vorhanden sind.
Die zweite Innovation von Microsoft für neuronale Netze ist das DAMSM-Modul (Deep Attentional Multimodal Similarity Model). Unter Verwendung des Aufmerksamkeitsmechanismus berechnet dieses Modul den Ähnlichkeitsgrad zwischen dem erzeugten Bild und dem Textsatz, wobei sowohl Informationen aus der Ebene des Vektorraums von Sätzen als auch eine detaillierte Ebene von Wörterbuchvektoren verwendet werden. Somit bietet DAMSM eine zusätzliche Granularität für den Verlust der Anpassungsfunktion bei der Übersetzung von Bild zu Text beim Training des Generators.
Dank dieser beiden Innovationen zeigt das neuronale AttnGAN-Netzwerk deutlich bessere Ergebnisse als die besten herkömmlichen GAN-Systeme, schreiben Entwickler. Insbesondere wurde der maximale bekannte Anfangswert für vorhandene neuronale Netze im CUB-Datensatz um 14,14% (von 3,82 auf 4,36) und um bis zu 170,25% (von 9,58 auf 25,89) verbessert. auf dem anspruchsvolleren COCO-Datensatz.
Die Bedeutung dieser Entwicklung ist schwer zu überschätzen. Das neuronale AttnGAN-Netzwerk zeigte zum ersten Mal, dass ein mehrschichtiges generativ-kontradiktorisches Netzwerk, das die Aufmerksamkeit als Lernfaktor bezeichnet, automatisch Bedingungen auf Wortebene für die Erzeugung einzelner Teile eines Bildes bestimmen kann.
Der wissenschaftliche Artikel wurde am 28. November 2017 auf der Preprint-Site arXiv.org (arXiv: 1711.10485v1) veröffentlicht.