Google Brain-Entwickler haben bewiesen, dass "widersprüchliche" Bilder sowohl eine Person als auch einen Computer enthalten können. und die möglichen Folgen sind erschreckend.
Im Bild oben - links ist ohne Zweifel eine Katze. Aber können Sie sicher sagen, ob die Katze rechts ist oder nur ein Hund, der ihm ähnlich sieht? Der Unterschied zwischen den beiden besteht darin, dass der richtige unter Verwendung eines speziellen Algorithmus hergestellt wird, der keine Computermodelle liefert, die als "Faltungs-Neuronale Netze" (CNNs, Faltungs-Neuronales Netz, im Folgenden als SNA bezeichnet) bezeichnet werden, um dies im Bild eindeutig zu schließen. In diesem Fall glaubt der SNS, dass dies eher ein Hund als eine Katze ist, aber am interessantesten - die meisten Menschen denken genauso.
Dies ist ein Beispiel für ein sogenanntes „widersprüchliches Bild“ (im Folgenden als KARP bezeichnet): Es wurde speziell modifiziert, um die SNA zu täuschen und zu verhindern, dass der Inhalt korrekt identifiziert wird. Die Forscher von Google Brain wollten verstehen, ob es möglich ist, dass biologische neuronale Netze in unseren Köpfen auf die gleiche Weise versagen, und haben daher Optionen entwickelt, die Autos und Menschen gleichermaßen betreffen und sie glauben lassen, dass sie etwas suchen, das nicht wirklich.
Was sind widersprüchliche Bilder?
Fast überall werden zur Erkennung in der SNA visuelle Klassifizierungsalgorithmen verwendet. Indem Sie dem Programm eine große Anzahl verschiedener Illustrationen mit Pandas „zeigen“, können Sie es darin trainieren, Pandas zu erkennen, da es durch Vergleich lernt, um ein gemeinsames Merkmal für den gesamten Satz herauszustellen. Sobald der SNA (auch als
"Klassifikatoren" bezeichnet ) eine ausreichende Anzahl von "Panda-Zeichen" in den Trainingsdaten sammelt, kann er den Panda in allen neuen Bildern erkennen, die er bereitstellt.
Wir erkennen Pandas an ihren abstrakten Eigenschaften: kleine schwarze Ohren, große weiße Köpfe, schwarze Augen, Fell und all dieser Jazz. Die SNA tut etwas anderes, was nicht überraschend ist, da die Menge an Informationen über die Umgebung, die Menschen jede Minute interpretieren, viel größer ist. Unter Berücksichtigung der Besonderheiten der Modelle ist es daher möglich, die Bilder so zu beeinflussen, dass sie durch Mischen mit sorgfältig berechneten Daten „inkonsistent“ werden. Danach sieht das Ergebnis für eine Person fast wie das Original aus, für den
Klassifikator jedoch völlig anders, was bei der Ermittlung zu Fehlern führt Inhalt.
Hier ist ein Panda-Beispiel:
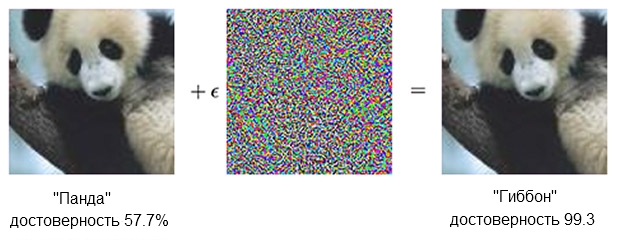 Das Bild eines Pandas, kombiniert mit Empörung, kann den Klassifikator davon überzeugen, dass es sich tatsächlich um einen Gibbon handelt.Quelle: OpenAIDer
Das Bild eines Pandas, kombiniert mit Empörung, kann den Klassifikator davon überzeugen, dass es sich tatsächlich um einen Gibbon handelt.Quelle: OpenAIDer auf der SNA basierende
Klassifikator ist sicher, dass der Panda auf der linken Seite etwa 60% beträgt. Wenn Sie jedoch die Quelle leicht ergänzen ("Empörung erzeugen"), indem Sie etwas hinzufügen, das wie chaotisches Rauschen aussieht, ist derselbe Klassifikator zu 99,3 Prozent sicher, dass er jetzt den Gibbon betrachtet. Kleine Änderungen, die nicht einmal klar erkennbar sind, führen zu einem sehr erfolgreichen Angriff, funktionieren jedoch nur auf einem bestimmten Computermodell und führen nicht diejenigen aus, die auf etwas anderem „gelernt“ werden könnten.
Um Inhalte zu erstellen, die bei einer großen und vielfältigen Anzahl künstlicher Analysten die falsche Reaktion hervorrufen, sollte man gröber handeln - winzige Korrekturen wirken sich nicht aus. Was zuverlässig funktioniert, kann mit "kleinen Mitteln" nicht erreicht werden. Mit anderen Worten, wenn Sie Inhalte aus allen Winkeln und Entfernungen zum Laufen bringen möchten, müssen Sie deutlicher eingreifen oder, wie eine Person sagen würde, offensichtlicher eingreifen.
In den Augen - ein Mann
Hier sind zwei Beispiele für unhöfliche Karpfen, bei denen eine Person Störungen leicht erkennen kann.
 Quelle: Öffnen Sie AI links und Google Brain rechts
Quelle: Öffnen Sie AI links und Google Brain rechtsDas Bild der Katze links, das der SNS als Computer definiert, wurde mit "gebrochener Geometrie" aufgenommen. Wenn Sie genauer hinschauen (oder auch nicht zu genau), werden Sie feststellen, dass es mehrere eckige und kastenförmige Strukturen gibt, die der Form einer Systemeinheit ähneln können. Und das Bild der Banane auf der rechten Seite, das als Toaster anerkannt ist, gibt in jeder Hinsicht ein falsches Positiv ab. Die Leute werden im Moment hier eine Banane finden, aber eine seltsame Erfindung daneben hat einige Anzeichen eines Toasters - und das macht die Technologie zum Narren.
Wenn Sie ein garantiert geeignetes „widersprüchliches“ Bild erstellen, das Sie benötigen, um ein ganzes Unternehmen der Modellerkennung zu schlagen, führt dies sehr oft zum Auftreten eines „menschlichen Faktors“. Mit anderen Worten, was ein einzelnes neuronales Netzwerk verwirrt, wird möglicherweise überhaupt nicht als Problem wahrgenommen, und wenn Sie versuchen, einen Rebus zu erhalten, der definitiv dazu geeignet ist, fünf oder zehn gleichzeitig zu betrügen, stellt sich heraus, dass er auf der Grundlage von Mechanismen funktioniert, die, wenn Menschen sind völlig nutzlos.
Infolgedessen besteht absolut keine Notwendigkeit, eine Person zu zwingen, zu glauben, dass eine eckige Katze ein Computergehäuse ist, und die Summe aus einer Banane und einem seltsamen Fleck sieht aus wie ein Toaster. Bei der Erstellung von CARPs, die für Sie und mich entwickelt wurden, ist es viel besser, sich sofort darauf zu konzentrieren, Modelle zu verwenden, die die Welt so wahrnehmen, wie Menschen es tun.
Das Auge (und das Gehirn) austricksen
Die SNA mit tiefem Training und menschlichem Sehen sind etwas ähnlich, aber im Grunde "betrachtet" das neuronale Netzwerk die Dinge "auf computerähnliche Weise". Wenn ihr beispielsweise ein Bild zugeführt wird, „sieht“ sie gleichzeitig ein statisches Raster aus rechteckigen Pixeln. Das Auge arbeitet anders, eine Person nimmt in einem Sektor von etwa fünf Grad auf jeder Seite der Sichtlinie hohe Details wahr, aber außerhalb dieser Zone nimmt die Liebe zum Detail linear ab.
Im Gegensatz zu einer Maschine funktioniert das Verwischen der Bildränder beispielsweise bei einer Person nicht und bleibt einfach unbemerkt. Die Forscher konnten dieses Merkmal simulieren, indem sie eine „Netzhautschicht“ hinzufügten, die die von der SNA gelieferten Daten so änderte, wie sie für das Auge aussehen würden, mit dem Ziel, das neuronale Netzwerk auf den gleichen Rahmen wie das normale Sehen zu beschränken.
Es sollte beachtet werden, dass eine Person mit ihren Wahrnehmungsmängeln fertig wird, indem der Blick nicht auf einen Punkt gerichtet ist, sondern sich ständig bewegt, das gesamte Bild untersucht, aber es war auch möglich, die Bedingungen des Experiments zu kompensieren und die Unterschiede zwischen der SNA und den Menschen auszugleichen.
Anmerkung aus der Arbeit selbst:
Jedes Experiment begann mit einem Installationskreuz, das 500-1000 Millisekunden lang in der Mitte des Bildschirms erschien, und jeder Proband wurde angewiesen, seinen Blick auf das Fadenkreuz zu richten.Die Verwendung der „Netzhautschicht“ war der letzte Schritt, der im Rahmen einer „dünnen Anpassung“ des maschinellen Lernens für „menschliche Merkmale“ unternommen werden musste. Während der Erzeugung der Proben wurden sie durch zehn verschiedene Modelle gefahren, von denen jedes eindeutig eine Katze, zum Beispiel einen Hund, hätte nennen sollen. Wenn das Ergebnis "10 von 10 waren falsch" war, wurde das Material zum Testen am Menschen eingereicht.
Funktioniert das
An dem Experiment waren drei Gruppen von Bildern beteiligt: „Haustiere“ (Katzen und Hunde), „Gemüse“ (Zucchini und Brokkoli) und „Bedrohungen“ (Spinnen und Schlangen, obwohl ich als Besitzer der Schlange einen anderen Begriff für die Bewertung vorschlagen würde). Für jede Gruppe wurde der Erfolg gezählt, wenn die Testperson das Falsche auswählte - den Hund als Katze bezeichnet und umgekehrt. Die Teilnehmer saßen vor einem Monitor, auf dem etwa 60 oder 70 Millisekunden lang ein Bild angezeigt wurde, und mussten eine der beiden Tasten drücken, um das Objekt anzuzeigen. Da das Bild nur für eine sehr kurze Zeit gezeigt wurde, wurde der Unterschied zwischen der Wahrnehmung der Welt durch Menschen und neuronale Netze ausgeglichen. Die Illustration im Titel fällt übrigens durch ihre Fehlerhaftigkeit auf.
Was die Probanden zeigten, konnte ein unverändertes Bild (Bild), ein "gewöhnliches" CarP (adv), ein "invertiertes" (Flip) CarP sein, auf dem das Rauschen vor dem Auftragen auf den Kopf gestellt wurde, oder ein "falsches" CarP, auf dem eine Schicht mit Rauschen wurde auf ein Bild angewendet, das keinem der Typen in der Gruppe angehört (false). Die letzten beiden Optionen wurden verwendet, um die Art der Störung zu steuern (wirkt sich die Geräuschstruktur auf den Kopf oder einfach auf „Nein“?). Außerdem konnten sie nachvollziehen, ob die Störung die Menschen vollständig täuscht oder die Genauigkeit nur geringfügig verringert.
Anmerkung aus der Arbeit selbst:
Falsch: Es wurde eine Bedingung hinzugefügt, um das Subjekt zu einem Fehler zu zwingen. Wir haben es hinzugefügt, denn wenn die anfänglichen Änderungen die Genauigkeit des Betrachters verringern, kann dies auf eine Abnahme der direkten Bildqualität zurückzuführen sein. Um zu zeigen, dass die CARPs tatsächlich in jeder Klasse funktionieren, haben wir Optionen eingeführt, bei denen keine Auswahl korrekt sein konnte und deren Genauigkeit 0 war, und wir haben genau beobachtet, was die „richtige“ Antwort in diesem Fall war. Wir haben beliebige Bilder aus ImageNet gezeigt, die von der einen oder anderen Klasse in der Gruppe betroffen waren, aber zu keiner von ihnen passten. Der Versuchsteilnehmer musste feststellen, was sich vor ihm befand. Zum Beispiel könnten wir ein Bild eines Flugzeugs zeigen, das durch das Anwenden von "Hunde" -Geräuschen verzerrt wurde, obwohl das Subjekt während des Experiments nur eine Katze oder einen Hund hätte erkennen sollen.Hier ist ein Beispiel, das einen Prozentsatz der Anzahl der Personen zeigt, die ein Bild eindeutig als Hund identifizieren konnten, abhängig davon, wie das Geräusch verwendet wurde. Ich möchte Sie daran erinnern, dass es nur 60-70 Millisekunden dauerte, um einen Blick darauf zu werfen und eine Entscheidung zu treffen.
 Quelle: Google Brain
Quelle: Google Brain
Originalbild mit einem Hund; Karpfen mit einem Hund, der sowohl von einem Mann als auch von einem Computer als Katze akzeptiert wird; Kontrollbild mit einer auf den Kopf gestellten Rauschschicht.Und hier sind die Endergebnisse:
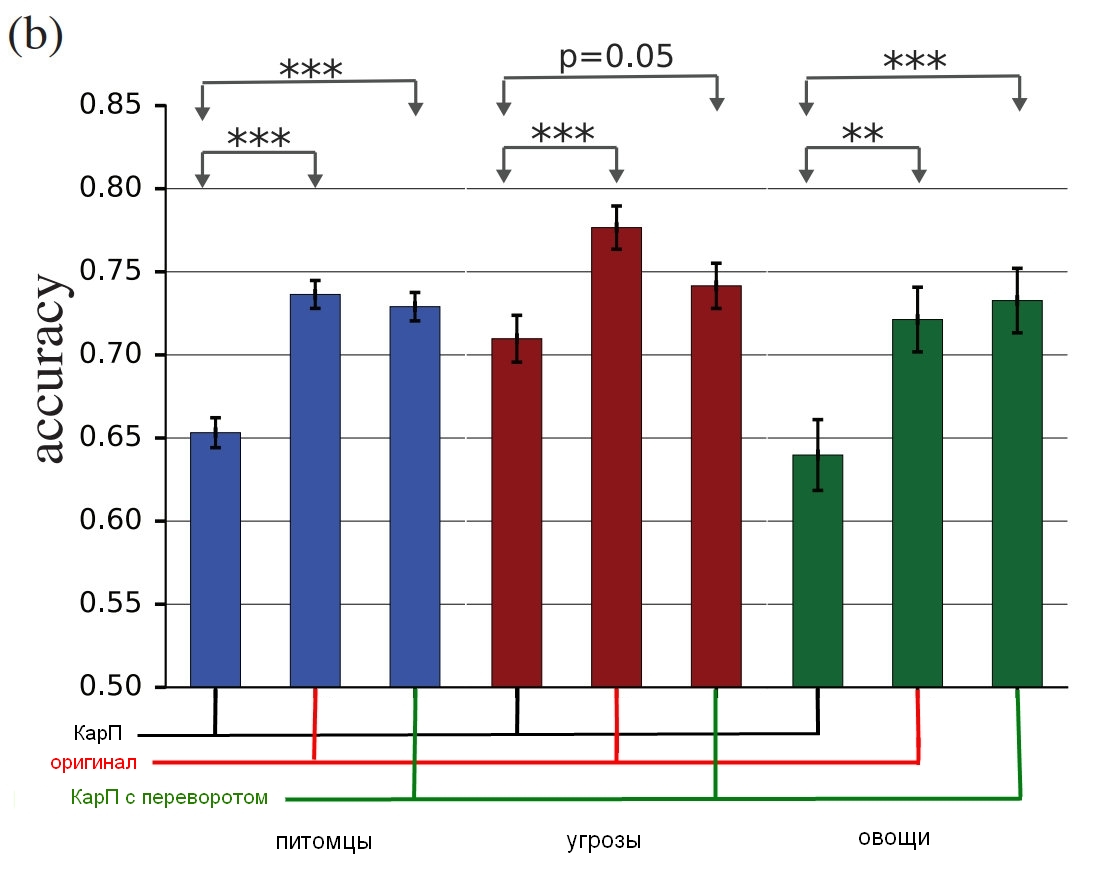 Quelle: Google Brain
Quelle: Google Brain
Die Ergebnisse der Studie, wie wahre Menschen diese Bilder im Vergleich zu verzerrten identifizieren.Die Tabelle zeigt die Genauigkeit der Übereinstimmung. Wenn Sie eine Katze wählen und es sich wirklich um eine Katze handelt, erhöht sich die Genauigkeit. Wenn Sie eine Katze auswählen, es sich aber tatsächlich um einen Hund handelt, der durch Lärm in eine Art Katze verwandelt wird, wird die Genauigkeit verringert.
Wie Sie sehen können, sind Menschen bei der Auswahl von nicht korrigierten Bildern oder mit invertierten Rauschschichten viel korrekter als bei der Auswahl von "inkonsistenten" Bildern. Dies beweist, dass das Prinzip des Angriffs auf die Wahrnehmung von Computern auf uns übertragen werden kann.
Die Auswirkungen sind nicht nur unbestreitbar wirksam, sie sind auch dünner als erwartet - keine Boxcats oder Pseudo-Toaster oder ähnliches. Da wir vor und nach der Verarbeitung beide Ebenen mit Rauschen und Bildern gesehen haben, müssen wir herausfinden, was uns dabei genau verwirrt. Obwohl die Forscher vorsichtig sind und behaupten, dass "unsere Beispiele speziell dafür gemacht sind, den Kopf zum Narren zu halten, sollten Sie vorsichtig sein, wenn Sie Menschen als Experiment verwenden, um den Effekt zu untersuchen."
In Zukunft wird das Team versuchen, einige allgemeine Regeln für bestimmte Modifikationskategorien abzuleiten, darunter „
Zerstörung der Kanten eines Objekts , insbesondere durch mäßige Stöße senkrecht zur Kantenlinie,
Korrektur von Randbereichen durch Erhöhung des Kontrasts während der Texturierung des Randes,
Änderung der Textur ,
Verwendung dunkler Teile "Bilder, bei denen der Einfluss auf die Wahrnehmung trotz winziger Störungen hoch ist." Das Folgende sind Beispiele, in denen rot eingekreiste Bereiche, in denen die beschriebenen Methoden am besten zu sehen sind.
 Quelle: Google Brain
Quelle: Google Brain
Beispiele für Bilder mit unterschiedlichen VerzerrungsprinzipienWas ist das Ergebnis?
Das Fazit ist, dass dies mehr, viel mehr als nur ein kluger Trick ist. Die Jungs von Google Brain haben bestätigt, dass sie eine effektive Technik der Täuschung entwickeln können, aber sie verstehen nicht ganz, warum dies funktioniert, wenn man die Abstraktionsebene berücksichtigt, und es ist möglich, dass dies buchstäblich eine grundlegende Ebene der Realität ist:
Unser Projekt wirft grundlegende Fragen zur Funktionsweise von CARPs, zur Funktionsweise neuronaler Netze und zum Gehirn auf. Haben Sie es geschafft, Angriffe von der SNA auf das Gehirn zu übertragen, weil die semantischen Darstellungen der darin enthaltenen Informationen ähnlich sind? Oder weil diese beiden Darstellungen einem bestimmten allgemeinen semantischen Modell entsprechen, das natürlich in der umgebenden Welt existiert?
Wenn Sie wirklich ein wenig paranoid werden möchten, tun Ihnen die Forscher gerne einen Gefallen und weisen darauf hin, dass „die visuelle Erkennung von Objekten ... schwierig ist, eine objektive Bewertung abzugeben. Ist „Abb. 1“ objektiv ein Hund oder eine objektive Katze, die die Leute glauben lässt, es sei ein Hund? “ Mit anderen Worten, verwandelt sich das Bild wirklich in ein Objekt oder lässt Sie nur anders denken?
Es ist hier gruselig (und ich sage ernsthaft "gruselig"), dass man am Ende Möglichkeiten bekommt, Fakten zu beeinflussen, weil der Abstand zwischen der Manipulation der SNA und der Manipulation einer Person offensichtlich nicht zu groß ist. Dementsprechend können Technologien für maschinelles Lernen möglicherweise verwendet werden, um Bilder oder Videos auf die richtige Weise zu verzerren, was unsere Wahrnehmung (und die entsprechende Reaktion) ersetzt, und wir werden nicht einmal verstehen, was passiert ist. Aus dem Bericht:
Zum Beispiel kann eine Gruppe von Modellen mit eingehender Schulung darin geschult werden, wie Menschen das Vertrauen in bestimmte Arten von Personen, Merkmalen und Ausdrücken einschätzen. Es wird möglich sein, "widersprüchliche" Empörungen zu erzeugen, die das Gefühl der "Glaubwürdigkeit" erhöhen oder verringern, und solche "optimierten" Materialien können in Nachrichtenclips oder politischer Werbung verwendet werden.
Zu den theoretischen Risiken gehört in Zukunft die Möglichkeit, sensorische Stimulationen zu erzeugen, die auf vielfältige Weise und mit sehr hoher Effizienz in das Gehirn eindringen. Wie Sie wissen, werden viele Tiere als anfällig für Stimulationen über der Schwelle angesehen. Nehmen wir an, Kuckucke können gleichzeitig so tun, als wären sie hilflos und klagen klagend, was in Kombination dazu führt, dass Vögel anderer Rassen Kuckucksküken vor ihren eigenen Nachkommen füttern. "Widersprüchliche" Proben können als eine solche besondere Form der Überschwellenstimulation für neuronale Netze angesehen werden. Und die Tatsache, dass übermäßige Reize, die theoretisch viel wahrscheinlicher eine Person betreffen, als sie nur dazu bringen, ein Etikett „eine Katze“ an das Bild eines Hundes zu hängen, erhebliche Bedenken hervorrufen, können mit einer Maschine erzeugt und dann auf Menschen übertragen werden.
Natürlich können solche Methoden „zum Guten“ eingesetzt werden, und es wurden bereits eine Reihe von Optionen vorgeschlagen, wie beispielsweise „die charakteristischen Merkmale der Bilder schärfen, um die Konzentration zu erhöhen, beispielsweise bei der Steuerung der Luftsituation oder der Analyse von Röntgenbildern, da diese Arbeit eintönig ist und die Folgen Nachlässigkeit kann schrecklich sein. " "Benutzeroberflächendesigner können Störungen verwenden, um intuitivere Benutzeroberflächen zu entwickeln." Hmmm. Es ist auf jeden Fall großartig, aber ich mache mir irgendwie mehr Sorgen darüber, mein Gehirn zu hacken und das Vertrauen in die Menschen zu stärken, weißt du?
Einige der gestellten Fragen werden Gegenstand künftiger Forschungen sein - es kann herausgefunden werden, was genau bestimmte Bilder besser geeignet macht, um einer Person einen Fehler zu vermitteln, und dies kann neue Hinweise für das Verständnis der Prinzipien des Gehirns liefern. Dies wiederum wird dazu beitragen, fortschrittlichere neuronale Netze zu schaffen, die schneller und besser lernen. Aber wir sollten vorsichtig sein und uns daran erinnern, dass es wie bei Computern manchmal nicht so schwierig ist, uns zu täuschen.
Das Projekt
" Widersprüchliche Beispiele, die sowohl das menschliche als auch das computergestützte Sehen täuschen" von Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow und Jascha Sohl-Dickstein von Google Brain kann von
arXiv heruntergeladen werden. Und wenn Sie kontroversere Bilder benötigen, die an Menschen arbeiten, dann ist das unterstützende Material
hier .