
Instagram verfügt über eine der größten Apache Cassandra-Datenbanken der Welt. Das Projekt begann 2012 mit Cassandra, um Redis zu ersetzen und die Implementierung von Anwendungsfunktionen wie einem Betrugserkennungssystem, Tape und Direct zu unterstützen. Zuerst arbeiteten Cassandra-Cluster in AWS, später migrierten die Ingenieure sie zusammen mit allen anderen Instagram-Systemen auf die Facebook-Infrastruktur. Cassandra schnitt in Bezug auf Zuverlässigkeit und Fehlertoleranz sehr gut ab. Gleichzeitig könnten die Latenzmetriken beim Lesen von Daten deutlich verbessert werden.
Im vergangenen Jahr begann das Instagram-Support-Team von Cassandra mit der Arbeit an einem Projekt, das darauf abzielte, die Latenz beim Lesen von Daten in Cassandra, das von den Ingenieuren Rocksandra genannt wurde, erheblich zu reduzieren. In diesem Artikel erklärt der Autor, was das Team zur Implementierung dieses Projekts veranlasst hat, welche Schwierigkeiten überwunden werden mussten und welche Leistungsmetriken Ingenieure sowohl in der internen als auch in der externen Cloud-Umgebung verwenden.
Gründe für den Übergang
Instagram nutzt Apache Cassandra aktiv und in großem Umfang als Schlüsselwertspeicherdienst. Die meisten Instagram-Anfragen erfolgen online. Um Hunderten von Millionen von Instagram-Nutzern eine zuverlässige und angenehme Benutzererfahrung zu bieten, stellen SLAs hohe Anforderungen an die Leistung des Systems.
Instagram hält sich an eine Zuverlässigkeitsbewertung von fünf bis neun. Dies bedeutet, dass die Anzahl der Fehler zu einem bestimmten Zeitpunkt 0,001% nicht überschreiten darf. Um die Leistung zu verbessern, überwachen die Ingenieure aktiv die Bandbreite und Latenzen verschiedener Cassandra-Cluster und stellen sicher, dass 99% aller Anforderungen in einen bestimmten Indikator passen (Verzögerung P99).
Unten sehen Sie eine Grafik, die die clientseitige Verzögerung von eins für einen der Cassandra-Kampfcluster zeigt. Blau zeigt die durchschnittliche Lesegeschwindigkeit (5 ms) an und Orange zeigt die Lesegeschwindigkeit für 99% im Bereich von 25 bis 60 ms an. Die Änderungen hängen stark vom Client-Verkehr ab.
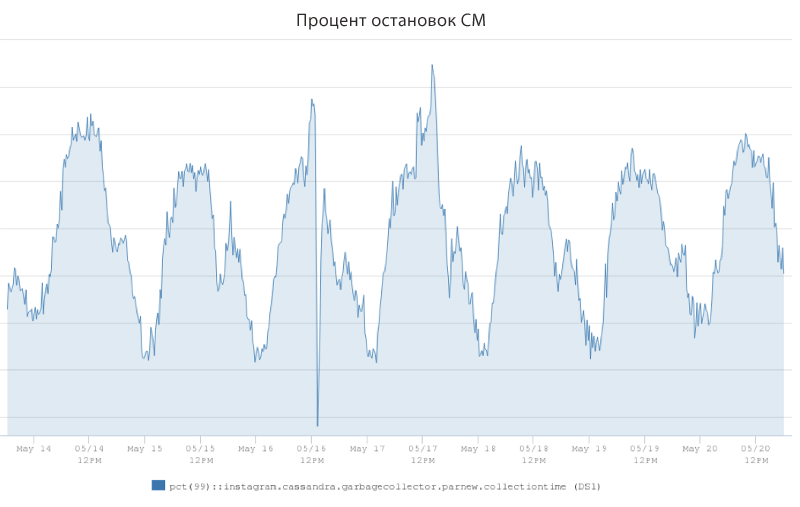

Die Studie ergab, dass die starken Verzögerungsschübe größtenteils auf den JVM-Garbage Collector zurückzuführen sind. Die Ingenieure führten eine Metrik mit dem Namen "Prozentsatz der Stopps des CM" ein, um den Prozentsatz der Zeit zu messen, die der Cassandra-Server für das "Stoppen der Welt" aufgewendet hat, und die von einer Ablehnung von Kundenanfragen begleitet wurde. Die obige Tabelle zeigt die Zeit (in Prozent), die für die SM-Stopps benötigt wurde, am Beispiel eines der Cassandra-Kampfserver. Der Indikator reichte von 1,25% zu Zeiten des kleinsten Verkehrs bis zu 2,5% zu Zeiten der Spitzenlast.
Die Grafik zeigt, dass diese Cassandra-Serverinstanz 2,5% ihrer Zeit damit verbringen könnte, Müll zu sammeln, anstatt Client-Anforderungen zu bearbeiten. Die vorbeugenden Operationen des Kollektors hatten offensichtlich einen signifikanten Einfluss auf die P99-Verzögerung, und daher wurde klar, dass die Ingenieure die P99-Verzögerungsrate signifikant reduzieren könnten, wenn wir die CM-Stopprate reduzieren könnten.
Lösung
Apache Cassandra ist eine Java-basierte verteilte Datenbank mit einer eigenen Datenspeicher-Engine, die auf LSM-Bäumen basiert. Ingenieure stellten fest, dass Engine-Komponenten wie eine Speichertabelle, ein Komprimierungswerkzeug, Lese- / Schreibpfade und einige andere viele Objekte im dynamischen Java-Speicher erstellten, was dazu führte, dass die JVM viele zusätzliche Overhead-Operationen ausführen musste. Um die Auswirkungen von Speichermechanismen auf die Arbeit des Garbage Collectors zu verringern, hat das Support-Team verschiedene Ansätze in Betracht gezogen und schließlich beschlossen, eine C ++ - Engine zu entwickeln und die vorhandene durch diese zu ersetzen.
Die Ingenieure wollten nicht alles von Grund auf neu machen und entschieden sich daher für RocksDB.
RocksDB ist eine leistungsstarke eingebettete Open-Source-Datenbank für die Speicherung von Schlüsselwerten. Es ist in C ++ geschrieben und seine API verfügt über offizielle Sprachbindungen für C ++, C und Java. RocksDB ist für hohe Leistung optimiert, insbesondere auf schnellen Laufwerken wie SSDs. Es wird in der Branche häufig als Speicher-Engine für MySQL, MongoDB und andere beliebte Datenbanken verwendet.
Schwierigkeiten
Bei der Implementierung der neuen Speicher-Engine in RocksDB standen die Ingenieure vor drei schwierigen Aufgaben und lösten sie.
Die erste Schwierigkeit bestand darin, dass Cassandra immer noch keine Architektur fehlt, mit der Datenprozessoren von Drittanbietern verbunden werden können. Dies bedeutet, dass die Arbeit der vorhandenen Engine ziemlich eng mit anderen Datenbankkomponenten verbunden ist. Um ein Gleichgewicht zwischen umfangreichem Refactoring und schnellen Iterationen zu finden, haben die Ingenieure die API der neuen Engine definiert, einschließlich der gängigsten Lese-, Schreib- und Stream-Schnittstellen. Auf diese Weise konnte das Support-Team neue Datenverarbeitungsmechanismen für die API implementieren und diese in die entsprechenden Codeausführungspfade in Cassandra einfügen.
Die zweite Schwierigkeit bestand darin, dass Cassandra strukturierte Datentypen und Tabellenschemata unterstützte, während RocksDB nur Schlüsselwertschnittstellen bereitstellte. Die Ingenieure haben die Codierungs- und Decodierungsalgorithmen sorgfältig definiert, um das Cassandra-Datenmodell als Teil der RocksDB-Datenstrukturen zu unterstützen, und die Kontinuität der Semantik ähnlicher Abfragen zwischen den beiden Datenbanken sichergestellt.
Die dritte Schwierigkeit war mit einer so wichtigen Komponente für jede verteilte Datenbankkomponente verbunden, wie das Arbeiten mit Datenströmen. Wenn ein Knoten zu einem Cassandra-Cluster hinzugefügt oder daraus entfernt wird, muss er die Daten korrekt auf verschiedene Knoten verteilen, um die Last innerhalb des Clusters auszugleichen. Bestehende Implementierungen dieser Mechanismen basierten auf dem Abrufen detaillierter Daten von der vorhandenen Datenbank-Engine. Daher mussten die Ingenieure sie voneinander trennen, eine Abstraktionsschicht erstellen und eine neue Option für die Verarbeitung von Flüssen mithilfe der RocksDB-API implementieren. Um einen hohen Durchsatz von Streams zu erzielen, verteilt das Support-Team die Daten zunächst an temporäre sst-Dateien und verwendet dann die spezielle RocksDB-API, um die Dateien zu „schlucken“, sodass sie gleichzeitig in die RocksDB-Instanz geladen werden können.
Leistungsindikatoren
Nach fast einem Jahr der Entwicklung und Erprobung haben die Ingenieure die erste Version der Implementierung fertiggestellt und sie erfolgreich auf mehreren Instagram Instagram Cassandra-Clustern „eingeführt“. In einem der Kampfcluster sank die P99-Verzögerung von 60 ms auf 20 ms. Beobachtungen zeigten auch, dass SM-Stopps in diesem Cluster von 2,5% auf 0,3% fielen, dh fast 10-mal!
Die Ingenieure wollten auch prüfen, ob Rocksandra in einer öffentlichen Cloud-Umgebung eine gute Leistung erbringen kann. Das Support-Team richtete in AWS einen Cassandra-Cluster mit drei i3.8 xlarge EC2-Instanzen mit jeweils einem 32-Core-Prozessor, 244 GB RAM und einem Null-Raid von vier NVMe-Flash-Laufwerken ein.
Für Vergleichstests haben wir
NDBench und das Standardtabellenschema für das Framework verwendet.
TABLE emp ( emp_uname text PRIMARY KEY, emp_dept text, emp_first text, emp_last text )
Die Ingenieure haben 250 Millionen 6 Zeilen mit jeweils 6 KB vorinstalliert (auf jedem Server werden ca. 500 GB Daten gespeichert). Richten Sie als Nächstes 128 Leser und Schreiber in NDBench ein.
Das Support-Team testete verschiedene Lasten und maß die durchschnittlichen Lese- und Schreiblatenzen / P99 / P999. Die folgenden Grafiken zeigen, dass Rocksandra signifikant geringere und stabilere Lese- und Schreiblatenzen aufwies.


Die Ingenieure überprüften die Last auch im Lesemodus ohne zu schreiben und stellten fest, dass Rocksandra mit derselben P99-Leseverzögerung (2 ms) die Informationslesegeschwindigkeit mehr als verzehnfachen kann (300 K / s für Rocksandra gegenüber 30 K / s für C. * 3.0).


Zukunftspläne
Das Instagram-Support-Team hat den
Rocksandra- Code und das
Framework zur Bewertung der Leistung geöffnet. Sie können sie von Github herunterladen und in Ihrer eigenen Umgebung ausprobieren. Sagen Sie uns unbedingt, was daraus geworden ist!
Als nächsten Schritt arbeitet das Team aktiv daran, eine breitere Unterstützung für C * -Funktionalitäten wie Sekundärindizes, Fixes und mehr hinzuzufügen. Außerdem entwickeln Ingenieure die
Architektur der Plug-in-Datenbank-Engine in C *, um diese Entwicklungen weiter auf die Apache Cassandra-Community zu übertragen.
