Hallo Habr! Schließlich warteten wir auf einen weiteren Teil der Materialreihe des Absolventen unseres
Big Data Specialist- und
Deep Learning- Programms, Cyril Danilyuk, über die Verwendung von Mask R-CNN, den derzeit beliebten neuronalen Netzen, als Teil eines Systems zur Klassifizierung von Bildern, nämlich Beurteilung der Qualität eines zubereiteten Gerichts anhand eines Datensatzes von Sensoren.
Nachdem wir den Spielzeugdatensatz untersucht haben, der im
vorherigen Artikel aus Bildern von Verkehrszeichen besteht, können wir nun das Problem lösen, mit dem ich im wirklichen Leben konfrontiert war:
„Ist es möglich, den Deep-Learning-Algorithmus zu implementieren, mit dem hochwertige Gerichte nacheinander von schlechten Gerichten unterschieden werden können? Fotos? " . Kurz gesagt, das Unternehmen wollte Folgendes:
Was ein Unternehmen darstellt, wenn es über maschinelles Lernen nachdenkt:Dies ist ein Beispiel für ein falsch gestelltes Problem: In diesem Fall kann nicht festgestellt werden, ob eine Lösung vorhanden ist, ob sie eindeutig und stabil ist. Darüber hinaus ist die Erklärung des Problems selbst sehr vage, ganz zu schweigen von der Umsetzung seiner Lösung. Natürlich ist dieser Artikel nicht der Effektivität der Kommunikation oder des Projektmanagements gewidmet, aber es ist wichtig zu beachten:
Nehmen Sie
niemals Projekte an, bei denen das Endergebnis nicht definiert und in der Arbeitserklärung festgehalten ist. Eine der zuverlässigsten Möglichkeiten, mit dieser Unsicherheit umzugehen, besteht darin, zuerst einen Prototyp zu erstellen und dann mit neuem Wissen den Rest der Aufgabe zu strukturieren. Das haben wir getan.
Erklärung des Problems
In meinem Prototyp habe ich mich auf ein Gericht aus dem Menü konzentriert - ein Omelett - und eine skalierbare Pipeline erstellt, die die "Qualität" des Omeletts am Ausgang bestimmt. Dies kann detaillierter wie folgt beschrieben werden:
- Problemtyp: Mehrklassenklassifizierung mit 6 diskreten Qualitätsklassen: gut (gut), gebrochenes Eigelb (mit Eigelb), überröstet (verkocht), zwei Eier (zwei Eier), vier Eier (vier Eier), verlegte Stücke (mit auf einem Teller verstreuten Stücken) .
- Datensatz: 351 manuell gesammelte Fotos verschiedener Omeletts. Trainings- / Validierungs- / Testmuster: 139/32/180 gemischte Fotos.
- Klassenetiketten: Jedes Foto entspricht einem Klassenetikett, das einer subjektiven Beurteilung der Qualität des Omeletts entspricht.
- Metrik: kategoriale Kreuzentropie.
- Minimales Domänenwissen: Ein Omelett von „Qualität“ sollte so aussehen: Es besteht aus drei Eiern, einer kleinen Menge Speck, einem Petersilienblatt in der Mitte, hat kein Eigelb und keine verkochten Stücke. Außerdem sollte die Gesamtzusammensetzung „gut aussehen“, dh die Teile sollten nicht über die gesamte Platte verteilt sein.
- Abschlusskriterium: Der beste Wert der Kreuzentropie in der Testprobe unter allen möglichen nach zweiwöchiger Entwicklung des Prototyps.
- Die Methode der endgültigen Visualisierung: t-SNE auf dem Datenraum einer kleineren Dimension.
 Bilder eingeben
Bilder eingebenDas Hauptziel der Pipeline besteht darin, zu lernen, verschiedene Arten von Signalen zu kombinieren (z. B. Bilder aus verschiedenen Winkeln, eine Heatmap usw.), nachdem eine vorkomprimierte Darstellung von jedem von ihnen erhalten wurde und diese Merkmale für die endgültige Vorhersage durch den neuronalen Netzwerkklassifizierer geleitet werden. So können wir unseren Prototyp realisieren und für weitere Arbeiten praktisch anwendbar machen. Im Folgenden sind einige der im Prototyp verwendeten Signale aufgeführt:
- Masken der Hauptbestandteile (Maske R-CNN): Signal Nr. 1 .
- Die Anzahl der Hauptbestandteile auf dem Rahmen., Signal Nummer 2 .
- RGB-Ernte von Platten mit Omelett ohne Hintergrund. Der Einfachheit halber habe ich beschlossen, sie noch nicht zum Modell hinzuzufügen, obwohl sie das offensichtlichste Signal sind: In Zukunft können Sie das Faltungsnetzwerk für die Klassifizierung mit einer geeigneten Triplettverlustfunktion trainieren, Bildeinbettungen berechnen und den L2-Abstand vom Strom abschneiden Bilder zu perfektionieren. Leider hatte ich keine Gelegenheit, diese Hypothese zu testen, da die Testprobe nur aus 139 Objekten bestand.
Gesamtansicht der Pipeline
Ich stelle fest, dass ich einige wichtige Schritte überspringen muss, z. B. die explorative Datenanalyse, das Erstellen eines grundlegenden Klassifikators und die aktive Kennzeichnung (mein vorgeschlagener Begriff, dh halbautomatische Annotation von Objekten, inspiriert vom
Polygon-RNN-Demovideo ) für Mask R-CNN (mehr dazu) dies in den nächsten Beiträgen).
Schauen Sie sich die gesamte Pipeline im Allgemeinen an:
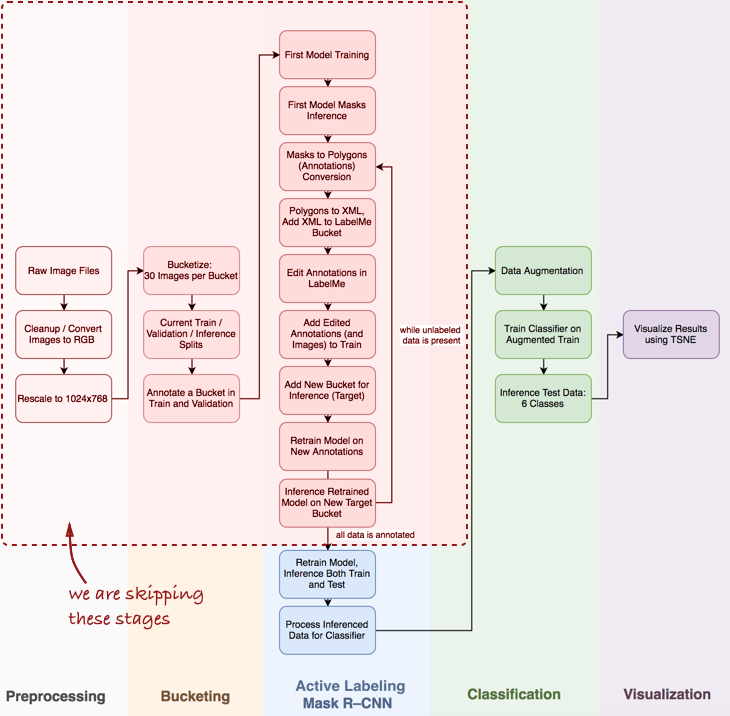 In diesem Artikel interessieren uns die Phasen von Mask R-CNN und die Klassifizierung innerhalb der Pipeline.
In diesem Artikel interessieren uns die Phasen von Mask R-CNN und die Klassifizierung innerhalb der Pipeline.Als nächstes betrachten wir drei Stufen: 1) Verwenden der Maske R-CNN zum Erstellen von Masken aus Omelettbestandteilen; 2) ConvNet-Klassifikator basierend auf Keras; 3) Visualisierung der Ergebnisse mit t-SNE.
Stufe 1: Maske R-CNN und Gebäudemasken
Die Maske R-CNN (MRCNN) war kürzlich auf dem Höhepunkt ihrer Popularität. Ausgehend vom ursprünglichen
Facebook-Artikel und endend mit dem
Data Science Bowl 2018 bei Kaggle hat sich Mask R-CNN als leistungsstarke Architektur für beispielsweise die Segmentierung (d. H. Nicht nur die pixelweise Bildsegmentierung, sondern auch die Trennung mehrerer Objekte derselben Klasse) etabliert ) Darüber hinaus ist es eine Freude, mit der
Implementierung von MRCNN von Matterport in Keras zu arbeiten. Der Code ist gut strukturiert, gut dokumentiert und funktioniert sofort, wenn auch langsamer als erwartet.
In der Praxis ist es insbesondere bei der Entwicklung eines Prototyps wichtig, über ein vorab trainiertes neuronales Faltungsnetzwerk zu verfügen. In den meisten Fällen ist der mit Tags versehene Datensatz des Datenwissenschaftlers sehr begrenzt oder gar nicht, während ConvNet viele mit Tags versehene Daten benötigt, um Konvergenz zu erreichen (beispielsweise enthält der ImageNet-Datensatz 1,2 Millionen mit Tags versehene Bilder). Hier hilft das
Transferlernen : Wir können das Gewicht der Faltungsschichten festlegen und nur den Klassifikator neu trainieren. Das Fixieren von Faltungsschichten ist wichtig für kleine Datensätze, da diese Technik eine Umschulung verhindert.
Folgendes habe ich nach der ersten Ära der Umschulung erhalten:
 Ergebnis der Objektsegmentierung: Alle wichtigen Inhaltsstoffe werden erkannt
Ergebnis der Objektsegmentierung: Alle wichtigen Inhaltsstoffe werden erkanntIn der nächsten Phase der Pipeline (
Process Inferenced Data for Classifier ) müssen Sie den Teil des Bildes ausschneiden, der die Platte enthält, und die zweidimensionale Binärmaske für jeden Bestandteil auf dieser Platte extrahieren:
 Beschnittenes Bild mit Hauptbestandteilen in Form von binären Masken.
Beschnittenes Bild mit Hauptbestandteilen in Form von binären Masken.Diese binären Masken werden dann zu einem 8-Kanal-Bild kombiniert (da ich 8 Maskenklassen für MRCNN definiert habe), und wir erhalten das
Signal Nr. 1 :
 Signal Nr. 1 : 8-Kanal-Bild bestehend aus Binärmasken. In Farbe zur besseren Visualisierung.
Signal Nr. 1 : 8-Kanal-Bild bestehend aus Binärmasken. In Farbe zur besseren Visualisierung.Um das
Signal Nr. 2 zu erhalten , habe ich gezählt, wie oft jede Zutat auf dem Erntegut der Platte gefunden wurde, und einen Satz von Merkmalsvektoren erhalten, von denen jeder seinem Erntegut entspricht.
Stufe 2: ConvNet-Klassifizierer in Keras
Der CNN-Klassifikator wurde mit Keras von Grund auf neu implementiert. Ich wollte mehrere Signale kombinieren (
Signal Nr. 1 und
Signal Nr. 2 sowie die mögliche Hinzufügung von Daten in der Zukunft) und die neuronalen Netze diese verwenden lassen, um Vorhersagen über die Qualität des Gerichts zu treffen. Die unten dargestellte Architektur ist erprobt und alles andere als ideal:

Ein paar Worte zur Architektur des Klassifikators:
- Multiskalen-Faltungsmodul : Ich habe anfangs einen 5x5-Filter für Faltungsschichten gewählt, aber dies führte nur zu einem zufriedenstellenden Ergebnis. Verbesserungen wurden erzielt, indem AveragePooling2D auf mehrere Ebenen mit unterschiedlichen Filtern angewendet wurde : 3x3, 5x5, 7x7, 11x11. Vor jeder der Schichten wurde eine zusätzliche 1 × 1-Faltungsschicht hinzugefügt, um die Abmessung zu verringern. Diese Komponente ähnelt einem Inception-Modul , obwohl ich nicht vorhatte, ein zu tiefes Netzwerk aufzubauen.
- Größere Filter : Ich habe größere Filter verwendet, da sie dazu beitragen, größere Zeichen leicht aus dem Eingabebild zu extrahieren (das selbst im Wesentlichen eine Aktivierungsschicht mit 8 Filtern ist - die Maske jedes Inhaltsstoffs kann als separater Filter betrachtet werden).
- Kombinieren von Signalen : In meiner naiven Implementierung wurde nur eine Schicht verwendet, die zwei Sätze von Attributen verband: verarbeitete binäre Masken ( Signal Nr. 1 ) und gezählte Zutaten ( Signal Nr. 2 ). Trotz seiner Einfachheit ermöglichte die Hinzufügung des Signals Nr. 2 die Reduzierung der Kreuzentropiemetrik von 0,8 auf [0,7, 0,72] .
- Logits : In Bezug auf TensorFlow ist Logit eine Ebene, auf der tf.nn.softmax_cross_entropy_with_logits angewendet wird, um den Stapelverlust zu berechnen.
Stufe 3: Visualisierung der Ergebnisse mit t-SNE
Um die Ergebnisse des Klassifikators anhand von Testdaten zu visualisieren, habe ich t-SNE verwendet - einen Algorithmus, mit dem Sie die Quelldaten in einen Raum niedrigerer Dimension übertragen können (um das Prinzip des Algorithmus zu verstehen, empfehle ich,
den Originalartikel zu lesen, er ist äußerst informativ und gut geschrieben).
Vor der Visualisierung habe ich Testbilder aufgenommen, die Logit-Schicht des Klassifikators extrahiert und den t-SNE-Algorithmus auf diesen Datensatz angewendet. Obwohl ich nicht verschiedene Werte des Ratlosigkeitsparameters ausprobiert habe, sieht das Ergebnis immer noch ziemlich gut aus:
 Das Ergebnis von t-SNE auf Testdaten mit Klassifikatorvorhersagen
Das Ergebnis von t-SNE auf Testdaten mit KlassifikatorvorhersagenNatürlich ist dieser Ansatz nicht perfekt, aber er funktioniert. Es kann einige mögliche Verbesserungen geben:
- Weitere Daten. Faltungsnetzwerke erfordern viele Daten, und ich hatte nur 139 Bilder für das Training. Techniken wie die Datenerweiterung funktionieren einwandfrei (ich habe D4 oder die symmetrische Diedererweiterung verwendet , was zu mehr als zweitausend Bildern führte), aber es ist immer noch äußerst wichtig, mehr reale Daten zu haben.
- Besser geeignete Verlustfunktion. Der Einfachheit halber habe ich kategoriale Kreuzentropie verwendet, was gut ist, weil es sofort funktioniert. Die beste Option wäre die Verwendung der Verlustfunktion, die Abweichungen innerhalb von Klassen berücksichtigt, z. B. die Triplettverlustfunktion (siehe den FaceNet-Artikel ).
- Verbesserung der Klassifikatorarchitektur. Der aktuelle Klassifikator ist im Wesentlichen ein Prototyp, dessen einziger Zweck darin besteht, binäre Masken zu erstellen und mehrere Merkmalssätze zu einer einzigen Pipeline zu kombinieren.
- Verbessertes Bildlayout. Ich war sehr schlampig beim manuellen Markieren von Bildern: Der Klassifikator hat diesen Job bei einem Dutzend Testbildern besser gemacht als ich.
Fazit Es muss endlich erkannt werden, dass das Unternehmen weder Daten noch Erklärungen noch eine klarere Aufgabe hat, die gelöst werden muss. Und das ist gut (sonst, warum brauchen sie Sie?), Weil Ihre Aufgabe darin besteht, verschiedene Tools, Multi-Core-Prozessoren, vorab geschulte Modelle und eine Mischung aus technischem und geschäftlichem Know-how zu verwenden, um zusätzlichen Wert im Unternehmen zu schaffen.
Fangen Sie klein an: Ein funktionierender Prototyp kann aus mehreren Codeblöcken erstellt werden und erhöht die Produktivität weiterer Gespräche mit der Unternehmensleitung erheblich. Dies ist die Arbeit eines Datenwissenschaftlers - um Unternehmen neue Ansätze und Ideen anzubieten.
Am 20. September 2018 startet der
„Big Data Specialist 9.0“ , in dem Sie unter anderem lernen, wie Sie Daten visualisieren und die Geschäftslogik hinter dieser oder jener Aufgabe verstehen, um Kollegen und Management die Ergebnisse Ihrer Arbeit effektiver zu präsentieren.