
Was ist der Unterschied zwischen maschinellem Lernen und Datenanalyse, wer in Odnoklassniki sitzt und wie Sie Ihre Reise in maschinelles Lernen beginnen können? Wir sprechen darüber in der zwölften Ausgabe von Talkshows für Programmierer.
Video auf dem Kanal TechnostreamGastgeber des Programms ist Pavel Shcherbinin, technischer Direktor für Medienprojekte, und Gast ist Dmitry Bugaychenko, Analyst bei Odnoklassniki.
00:56 Dmitry Bugaychenko: Vom Outsourcing zum OK und zur wissenschaftlichen Tätigkeit
02:42 Warum Arbeit an der Universität und in einem großen Unternehmen kombinieren
?02:57 Wo maschinelles Lernen in OK angewendet wird
03:49 Maschinelles Lernen und Datenanalyse - was ist der Unterschied?
05:08 Screencast „Wir analysieren das Publikum OK mit Hilfe der Datenanalyse“
22:34 Sind Klassenkameraden ein Dating-Service?
24:07 Wo soll ich anfangen, maschinelles Lernen zu lernen?
25:33 Soll ich an Meisterschaften des maschinellen Lernens teilnehmen?
26:53 Wie man in OK zum Üben kommt
28:18 Handbuch für maschinelles Lernen
30:28 Maschinelles Lernen
32:48 Wie ist die
Datenpipeline in OK angeordnet (auf der Tafel
anzeigen)?43:42 Blitzumfrage
Erzähl ein wenig über dich.Wir können davon ausgehen, dass mein Karriereweg 1999 begann, als ich in die Mathematik eintrat. Fünf Jahre lang studierte er aktiv Mathematik, Programmierung und verschiedene verwandte Disziplinen. Dann arbeitete er ziemlich lange in einem Outsourcing-Unternehmen. Outsourcing ist eine sehr interessante Erfahrung. Ich habe es geschafft, in einer Vielzahl von Projekten zu arbeiten, vom Schreiben eines Treibers für einen Kühlschrank bis zur Erstellung verteilter Unternehmenssysteme.
Während dieser ganzen Zeit unterrichtete ich neben der Hauptarbeit an der Universität, um den Kontakt zur akademischen Gemeinschaft aufrechtzuerhalten, was ziemlich schwierig war. Als ich 2011 nach Odnoklassniki eingeladen wurde, um mich mit Empfehlungssystemen zu beschäftigen, war dies eine sehr gute Chance, die ich genutzt habe. Hier ist es möglich, sowohl die mathematische Vorbereitung der Universität als auch die praktische Erfahrung des Programmierens zu kombinieren. Ich unterrichte jedoch weiterhin an der Universität.
Nimmt der Unterricht viel Zeit in Anspruch?1,5 Tage die Woche geht zur Universität, aber es lohnt sich, denn wir haben bereits drei meiner ehemaligen Studenten im Personal. Das heißt, die Universität arbeitet auch als Personalschmiede.
Beziehen Sie sich bei der Arbeit ruhig auf die Tatsache, dass Sie 1,5 Tage weg sind?Zurückgetreten. Jeder versteht, was Profit davon ist, deshalb stoße ich auf keinen Widerspruch.
Sagen Sie mir, wo maschinelles Lernen in Odnoklassniki verwendet wird.Wir haben viele Anwendungen. Historisch gesehen war das erste maschinelle Lernsystem die Musikempfehlung. Alles begann im Jahr 2011. Dann gab es einfach ein explosives Wachstum: Die Empfehlung der Communitys, die Empfehlung von Freunden, "Vielleicht kennen Sie sich", versucht, den Inhalt im Feed der Person zu bewerten. Jetzt entwickeln sich viele Projekte. Unabhängig davon, welchen Teil von Odnoklassniki Sie verwenden, gibt es Komponenten, die entweder mit maschinellem Lernen oder mit Datenanalyse zusammenhängen.
Helfen Sie unseren Lesern, diese beiden Konzepte zu trennen: maschinelles Lernen und Datenanalyse.Die Daten werden von einer Person analysiert, um einige Muster und Zusammenhänge zu finden und einige Hypothesen zu testen. Hierzu werden verschiedene Mittel der mathematischen Statistik verwendet. Maschinelles Lernen ist eine fortgeschrittenere Methode zur Suche nach Mustern, wobei Techniken verwendet werden, die normalerweise auf einem großen, komplexen Modell mit einer großen Anzahl von Parametern basieren.
Wir versuchen, die Parameter dieses Modells so auszuwählen, dass es das von uns benötigte Phänomen gut beschreibt. Es gibt viele verschiedene Algorithmen, Methoden zum Aufzählen von Parametern, aber all dies geschieht, um eine gewisse Regelmäßigkeit zu finden. Bewerten Sie beispielsweise anhand von Daten zu einem Beitrag in einem sozialen Netzwerk die Wahrscheinlichkeit, dass eine bestimmte Person diesem Beitrag eine „Klasse“ zuweist. Das heißt, maschinelles Lernen ist ein Werkzeug zur Datenanalyse.
Könnten Sie und ich einen der Mythen über Odnoklassniki entlarven, wonach dieses Publikum ein sehr altes Publikum hat?Kein Problem. Dies ist eine Karte, die in Echtzeit die Anmeldungen jedes einzelnen Benutzers widerspiegelt. Das heißt, jeder Punkt ist eine Person, die sich angemeldet hat und etwas in Odnoklassniki tut.
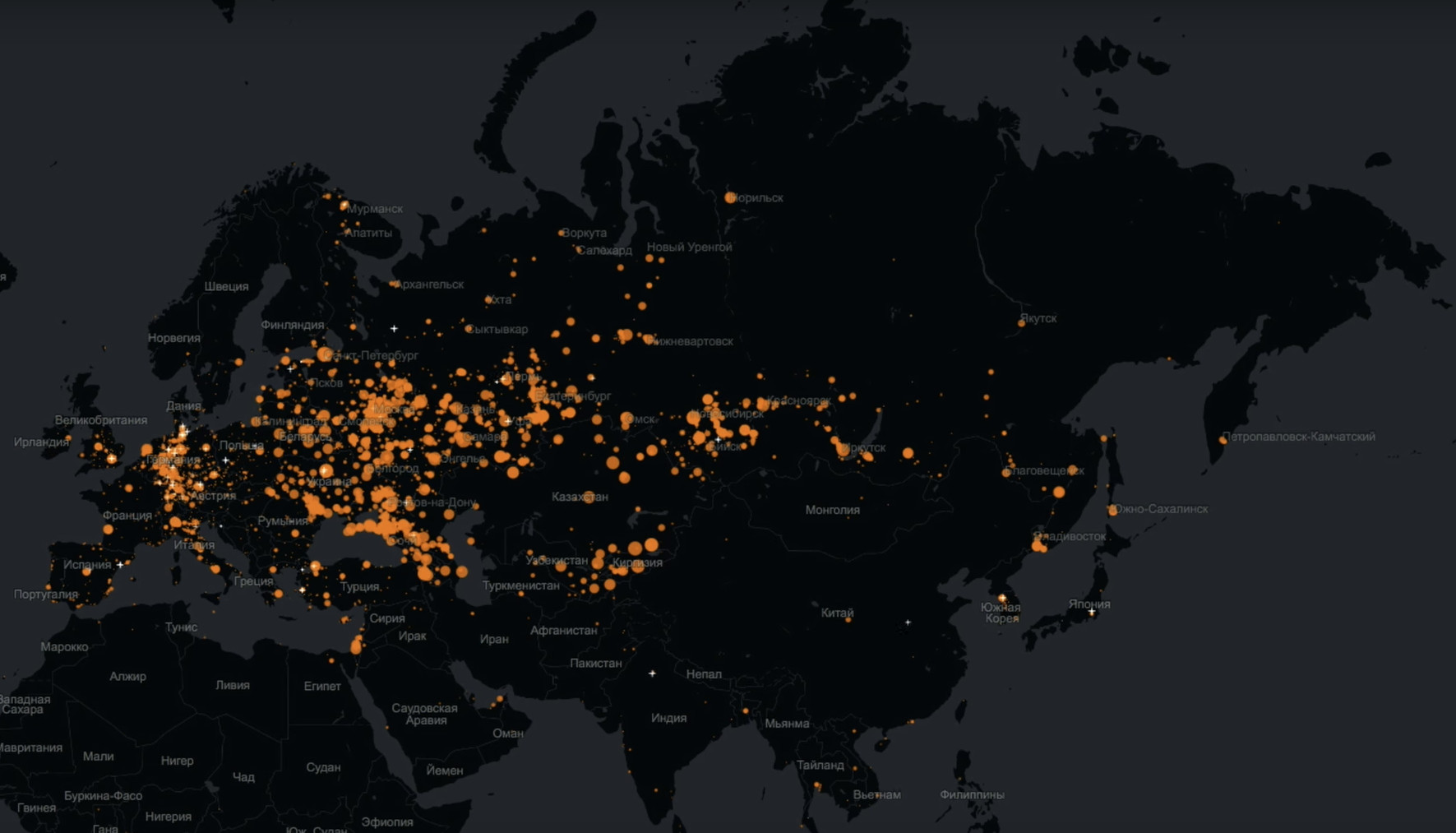
Große rote Kreise sind Städte, aus denen viele Benutzer zu uns gekommen sind. Hier ist sehr deutlich zu sehen, dass Odnoklassniki nicht nur lebt, sondern fast ganz Eurasien abdeckt.
Berechnen wir, wie viele Benutzer gestern "Klasse" in Odnoklassniki eingegeben haben, und sehen wir uns die Altersverteilung an.
Wo beginnt die Codierung? Natürlich vom Importieren verschiedener nützlicher Daten für zukünftige aggregierte Berechnungen. Unser Hauptwerkzeug ist
Spark , für dessen Zugriff wir die
Zeppelin- Webfront verwenden. Grundsätzlich kommen die Daten über
Apache Kafka , werden verpackt und in verschiedene Blöcke aufgeteilt. In diesem Fall interessiert uns der Block, der die Benutzeraktivität von gestern beschreibt, insbesondere Klassen. Es gibt ein Feld, in dem demografische Daten der Benutzer gespeichert werden, einschließlich Geburtstage.

Die Ausgabe ist das Geburtsjahr der ersten zehn Datensätze. Versuchen wir nun, daraus ein Aggregat zu erstellen. Wir möchten die Anzahl der eindeutigen Benutzer zählen. Wir benötigen ID und Geburtsjahr, gruppieren nach Jahr und berechnen die Anzahl der eindeutigen Benutzer. Und lassen Sie es uns ein bisschen spielen: Es wird sicherlich Menschen geben, deren Geburtsjahr nicht angegeben ist, also werden wir sie herausfiltern, damit sie kein Rauschen in der Grafik erzeugen.
Um die Berechnung durchzuführen, muss das System etwa 1 TB Daten schaufeln. Wir erhalten das Ergebnis und präsentieren es grafisch:

Die Altersspitze fällt auf 1983 - 35 Jahre. Das sind ziemlich alte Benutzer für sich.
Um die Situation besser darzustellen, gibt es nicht genügend Informationen aus einer Hand. Wenn wir über Benutzerdemografie sprechen, dann ist die interessanteste Vergleichsquelle die Statistik über die Bevölkerung Russlands. Von der Website von
Rosstat habe ich die Daten zu den Geburtsjahren der Russen heruntergeladen, die 2016 gesammelt wurden.
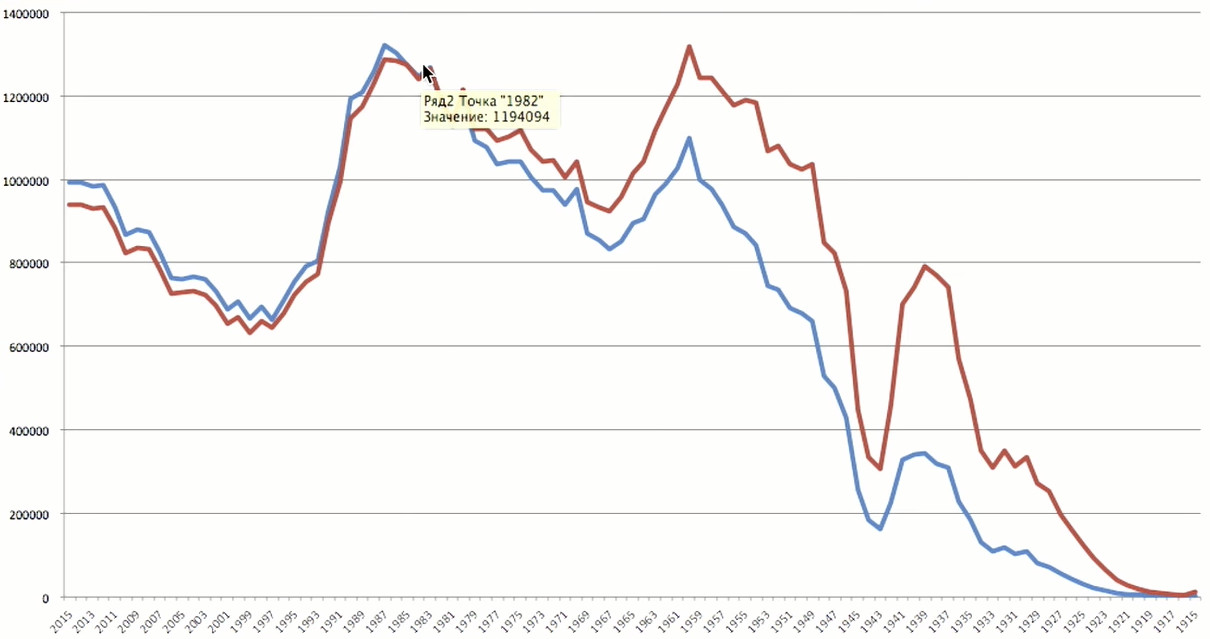
Der Spitzenwert in der Statistik liegt laut Odnoklassniki sehr nahe am Spitzenwert - wir haben Benutzer, die 1983 geboren wurden, und Rosstat - 1987. Was mich beeindruckt hat, waren zwei große Fehler. Die Grube der frühen 1940er Jahre ist der Große Vaterländische Krieg. Der Krieg hat uns nicht nur mehr als 20 Millionen Tote gekostet, sondern auch Millionen ungeborener Menschen. Dies ist die demografische Grube, die immer noch zu spüren ist. Die zweite Grube - die 1990er Jahre. Und wir haben uns nicht vollständig von dieser Krise erholt. Wir sehen das gleiche Bild in den Daten von Odnoklassniki: Nach 1990 gab es einen starken Rückgang. Wir können immer noch keine Menschen haben, die im Jahr 2015 geboren wurden, da das Mindestalter für die Registrierung 5 Jahre beträgt.
Fügen Sie das Attribut gender unserer Stichprobe und Gruppe nicht nur nach Jahr, sondern auch nach Geschlecht hinzu.
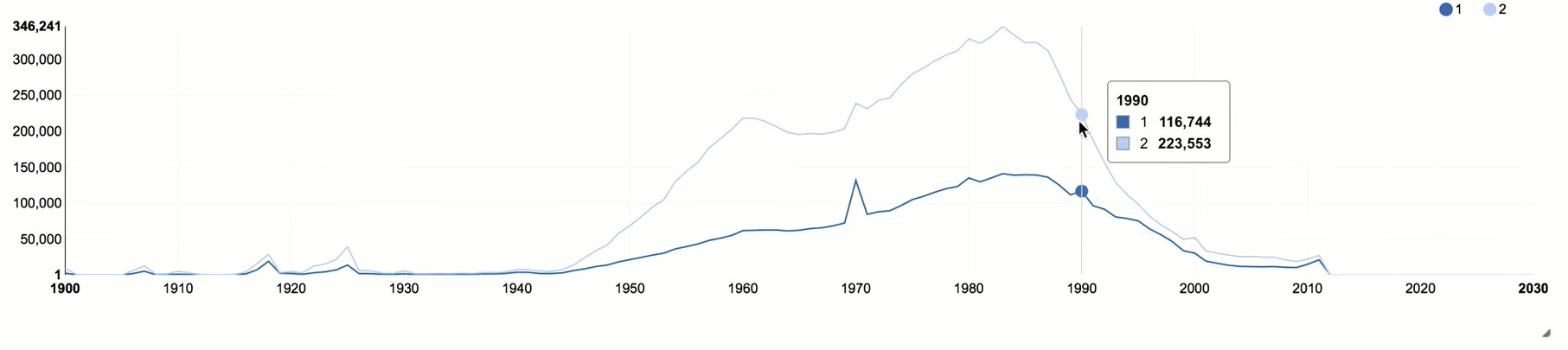
Nach 1990 ist ein starker Rückgang zu verzeichnen, der mit der allgemeinen Alterssituation in Russland korreliert. Frauen setzen die „Klasse“ viel aktiver ein, fast doppelt so viel wie Männer. Dies ist ein ziemlich typisches Bild für soziale Netzwerke, da Frauen sozial aktiver sind als Männer.
Sie können auch auf mehrere Spitzen achten, die mit den „runden“ Jahren korrelieren. Anhand dieser Peaks kann der Einfluss von Bots oder Personen beurteilt werden, die ihr Alter absichtlich verzerren, da sie in solchen Fällen normalerweise runde Daten angeben.
Wir sind auch an der geografischen Verteilung unserer Benutzer interessiert. Wir benötigen eine Benutzer-ID, um eindeutige Besucher zu zählen, und die in den Profilen angegebenen Wohnadressen. Nach Stadt gruppieren und Einheit berechnen. Sortieren Sie nach der Anzahl der Benutzer in absteigender Reihenfolge und lassen Sie nur die ersten 200 Städte. Aggregation ausführen:

Dies ist die Top-Stadt in Bezug auf die Anzahl der Klassenkameraden, die die Klassenkameraden eingestellt haben. Moskau liegt natürlich an der Spitze. Der Süden Russlands ist viel besser vertreten als der Nordwesten. Wir haben Benutzer in den USA, Kanada, viel in Deutschland, viel in Israel. Interessante Tatsache: 36.000 Menschen aus Juschno-Sachalinins mochten jeden Tag. Insgesamt leben laut Wikipedia 180.000 Menschen in der Stadt. 20% der Bevölkerung von Juschno-Sachalinsk gingen nach Odnoklassniki und stellten eine „Klasse“ auf.

Zoomen Sie hinein und sehen Sie, was in Moskau und der Region Moskau passiert.

Zentralasiatische Republiken, Moldawien, Ukraine sind in Odnoklassniki sehr gut vertreten.

Sie können sofort sehen, wo sie versucht haben, den Zugriff auf unser soziales Netzwerk zu blockieren, und wo nicht.
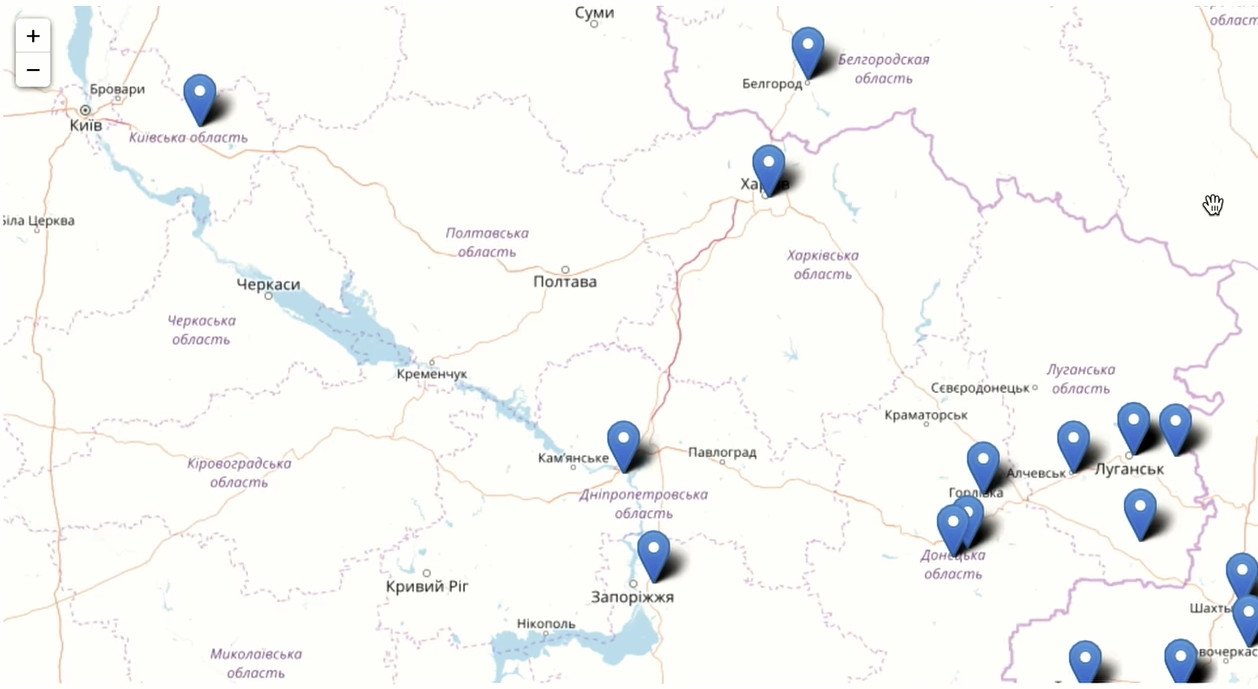
Wie Sie sehen können, ist Odnoklassniki ein lebendiges, dynamisches Produkt, das sowohl von jungen als auch von älteren Menschen auf der ganzen Welt verwendet wird, manchmal sogar dort, wo Sie es nicht erwarten. Unter allen Altersklassen haben wir die meisten 30-Jährigen.
Soziale Netzwerke bauen auf Gemeinschaften auf. Es kommt häufig vor, dass eine Community, die ein bestimmtes soziales Netzwerk betreten hat, nur sehr wenig über andere soziale Netzwerke weiß. So könnte beispielsweise die professionelle Gemeinschaft von Journalisten die Illusion haben, dass Odnoklassniki hauptsächlich ein älteres Publikum ist. In der Tat ist dies die subjektive Meinung einer Gemeinschaft. Wir haben Benutzer im Alter von 50-60 Jahren und älter, es gibt Schulkinder, es gibt 20-jährige Jugendliche, es gibt reife, reife Menschen im Alter von 30-35 Jahren.
Die Odnoklassniki-Abdeckung umfasst alle Regionen Russlands, der Nachbarländer, der Ukraine, Weißrusslands und Zentralasiens. Wir haben Diaspora sehr gut vertreten, zum Beispiel die deutsche Diaspora russischer Auswanderer, die amerikanische Diaspora und die israelische. Sie kommunizieren sehr aktiv mit ihren Verwandten, die in Russland und den ehemaligen Sowjetrepubliken geblieben sind. Unter diesem Gesichtspunkt trägt Odnoklassniki sehr gut zur Umsetzung der Grundfunktion eines sozialen Netzwerks bei - um Kontakte zwischen Menschen aufrechtzuerhalten, die weit voneinander entfernt leben.
Es gibt eine Meinung, dass Odnoklassniki für viele so attraktiv ist, weil es eine einfache Möglichkeit ist, Freunde und Bekannte Ihrer Freunde und Verwandten zu treffen. Das heißt, Odnoklassniki wird als Dating-Service präsentiert. Wie sehr ist diese Art der Datierung gefragt und Teil der Ideologie von Odnoklassniki?Die Notwendigkeit, andere Menschen, einschließlich des anderen Geschlechts, zu treffen, ist ein grundlegendes menschliches Bedürfnis. Natürlich kommt es in jedem sozialen Netzwerk zum Ausdruck. Aber in Odnoklassniki wird es nicht mehr und nicht weniger ausgedrückt als in anderen sozialen Netzwerken. Wir haben keinen Schwerpunkt auf Dating-Services. Die Ideologie der Entwicklung unseres sozialen Netzwerks basiert auf einem gemeinsamen Wert wie der Kommunikation zwischen Menschen. Für uns ist es nicht so wichtig, ob es Klassenkameraden sind, die sich in verschiedene Städte zerstreut haben, oder Menschen, die einen Partner suchen. Beide Optionen passen perfekt zu uns. Wir freuen uns, dass sich Menschen gefunden und kommuniziert haben. Aber nichts weiter
Sie lernen viel maschinell. Dieses Thema begeistert jetzt viele. Wo soll ich anfangen, wie komme ich in diesen Beruf?Zuerst müssen Sie etwas Wissen bekommen. Es gibt keine Probleme damit, es gibt wunderbare Kurse bei
Coursera , bei
Stepik und in einigen Universitätsprogrammen, die sehr gute Grundkenntnisse über maschinelles Lernen vermitteln. Um sich dieser Sphäre wirklich anzuschließen, benötigen Sie ein Ziel und ein Verständnis, wo Sie es anwenden können. Denn nur das Hören eines abstrakten Kurses ist bei weitem nicht so effektiv, als ob Sie ein Problem oder eine Frage wirklich lösen würden.
Die ideale Option für Studierende sind Hausarbeiten und Dissertationen. Und selbst in diesem Fall versuche ich, die Aufgabe nicht von oben herunterzulassen, sondern den Ideen der Schüler zu helfen, dann werden sie viel mehr Motivation haben.
Das heißt, nachdem Sie sich ein Ziel gesetzt haben, hören Sie sich Online-Kurse an und versuchen Sie dann, Wissen anzuwenden. Und alles wird sich herausstellen.
Es scheint mir, dass es heute genug Aufgaben gibt. Auf dem Kegel finden zahlreiche Wettbewerbe von Sberbank, Tinkoff und vielen anderen Unternehmen statt.Natürlich. Sie konzentrieren sich aber vor allem auf diejenigen, die sich bereits intensiv mit maschinellem Lernen beschäftigen. Darüber hinaus kann man bei solchen Wettbewerben sehr oft nicht maschinelles Lernen beobachten, sondern Kappenhass. Die Modelle, die auf dem Kegel trainiert werden, helfen nicht bei der Lösung praktischer Probleme, da sie zu viele Parameter steuern. Infolgedessen sind die Modelle speziell auf bestimmte Wettkämpfe auf dem Kegel spezialisiert, und nur in ihnen werden Ergebnisse erzielt. Und wenn Sie diese Modelle in die reale Welt übertragen, funktionieren sie nicht.
Best Practice ist Übung. Wie kommst du mit deinem Team zum Üben?Es gibt so viele Möglichkeiten. Wenn wir über Forschungsteams sprechen, haben wir ein Projekt namens OK Data Science Lab, in dem wir Menschen, die ihre Ideen in Bezug auf maschinelles Lernen und Datenanalyse entwickeln möchten, Computerressourcen, Daten, unser Wissen und unsere Erfahrung zur Verfügung stellen. Und nicht unbedingt für ein soziales Netzwerk. Zum Beispiel haben wir eine Studie, in der der Autor versucht zu verstehen, was für moderne Schulkinder am interessantesten ist.
Wenn Sie ein Spezialist sind und Arbeit suchen, haben wir immer viele offene Stellen im Zusammenhang mit maschinellem Lernen. Besuchen Sie uns für ein Interview.
Gibt es ein Buch, einen Leser für maschinelles Lernen?Dies ist ein sich so schnell änderndes Gebiet, dass das Schreiben eines Buches oder Lesers für maschinelles Lernen zu ehrgeizig ist. Ich kann die klassische Arbeit „
Elemente des statistischen Lernens “ empfehlen. Hier geht es um die grundlegendsten Methoden des maschinellen Lernens, die ihren Ursprung in der Statistik haben.
Sergey Nikolenko veröffentlichte ein Buch über tiefes maschinelles Lernen.Meiner Meinung nach ist Deep Learning nicht der Ausgangspunkt. Wenn Sie bereits klassisches maschinelles Lernen besitzen, ist dies eine gute Option. Wenn Sie die klassischen Techniken jedoch noch nicht kennen, ist es falsch, sofort mit tiefem Lernen zu beginnen, da dies den Forscher häufig vom Problem abhält. Dies ist ein sehr leistungsfähiges Werkzeug. Bevor Sie es anwenden, müssen Sie das Problem auf einfachere Weise "manuell" analysieren. Und erst dann, wenn Sie den Themenbereich verstanden haben, können Sie tief lernen. Andernfalls wird Ihr Modell lernen, Sie jedoch nicht. Wenn Sie dümmer werden als Ihr Modell, ist es, gelinde gesagt, unwirksam. Sie können das Modell nicht weiterentwickeln, und dies ist eine Sackgasse. Daher ist es besser, sich zuerst mit klassischer ML vertraut zu machen. Dies bedeutet nicht, dass Sie Jahre verbringen müssen, es ist durchaus möglich, in einer angemessenen Zeit zu meistern.
Haben Sie Veranstaltungen zum maschinellen Lernen?Wir haben eine Reihe von
SNA Hackathon Hackathons. Bisher sind zwei Mal vergangen. Zum ersten Mal widmete sich der Hackathon der Analyse des Textes und dem Versuch, vorherzusagen, wie viele „Klassen“ ein bestimmter Beitrag gewinnen würde. Der zweite Hackathon fand vor einem Jahr statt und war der Analyse von Grafiken gewidmet. Es gab viele interessante Ereignisse. Wir haben Informationen über die "Freundschaften" einiger unserer Benutzer bereitgestellt, anscheinend ein kleines Datenelement über 1 GB. Aber als die Teilnehmer, die ihre Prognosen senden wollten, versuchten, mit ihm zu arbeiten, gelang es fast niemandem, selbst auf Maschinen mit 16 und 32 GB Speicher fiel alles aus, flog in den Austausch, wollte nicht arbeiten. Wir mussten sogar eilig erklären, wie man mit Daten arbeitet und wie man nicht.
Es stellte sich heraus, dass viele, selbst fortgeschrittene Spezialisten für maschinelles Lernen, von den Wurzeln abgekommen waren und die Grundprinzipien der Programmierung vergessen hatten. Vergessen Sie, was Boxen ist, wie Hash-Tabellen strukturiert sind, wie viel Speicheraufwand entstehen kann, wenn Sie Hash-Tabellen verwenden. Wenn Sie nicht über all dies nachdenken und es direkt in Python, Java oder Scala tun, werden die beschriebenen Probleme beschrieben. Wir haben eine Demo in Python gemacht, der gleiche Rake ist in anderen Sprachen. Ein Diagramm mit 40 Millionen Links, das in 200 MB Speicher passen könnte, explodiert bei 20 GB scharf, einfach weil Sie vergessen haben, wie die grundlegenden Datenstrukturen angeordnet sind. Es war damals sehr beeindruckend. Auch wenn Sie ein Spezialist für maschinelles Lernen sind, sollten Sie die Grundlagen der Programmierung nicht vergessen.
Wie ist Ihr Datenverarbeitungs-Workflow aufgebaut?Benutzer interagieren mit einem gesamten Ökosystem unserer Produkte. Wir können bedingt zwei Ebenen unterscheiden: Front-End-Anwendungen (mobile Anwendungen, Portal, mobile Version, verschiedene zusätzliche Anwendungen) und Geschäftslogik. Fronten interagieren häufig mit Benutzern und haben Zugriff auf eine sehr begrenzte Anzahl von Servern. Daher gibt es in der Geschäftslogik einige spezielle Methoden, mit denen Fronten Daten protokollieren können.
Diese Daten fallen in den Apache Kafka Single Data Bus. Dies ist die Wende, die zu einem Industriestandard geworden ist, der zum Sammeln von Rohdaten verwendet wird. Natürlich ist es schwierig, Rohdaten in Kafka zu analysieren, daher werden sie regelmäßig an den großen und dicken Hadoop übertragen. Jemand könnte sagen, dass Hadoop das letzte Jahrhundert ist, jetzt regiert Spark. Aber Hadoop ist eine Plattform, auf der Sie viele Tools ausführen können. Wir haben verschiedene Analysetools, die auf Hadoop aufbauen. Ich greife oft auf diese Klassifizierung zurück:
- Der Stil der Dateneingabe .
- Stapelverarbeitung. Es gibt einige Datenmengen, die Sie irgendwie verarbeiten.
- Stream-Verarbeitung. Sie arbeiten mit Echtzeitdaten, die direkt aus Streams stammen, in diesem Fall von unserem Kafka.
Wenn es während der Stapelverarbeitung zu schwerwiegenden Verzögerungen kommen kann - wir haben tagsüber Statistiken gesammelt und Sie trainieren das Modell nachts -, werden bei der Streaming-Verarbeitung Verzögerungen in Sekundeneinheiten zwischen dem Empfang der Daten und ihrer Verarbeitung gemessen.
- Betriebsanalyse . Dies ist Prozesssteuerung und -überwachung. Dient der Produktion, sollte es selbst funktionieren, ohne menschliches Eingreifen.
- Interaktive Analyse . Was eine Person tut. Die Geschwindigkeit der Reaktion ist hier wichtig: Sie haben etwas getan, das Ergebnis erzielt.
In jeder dieser Nischen haben wir unser eigenes Produktökosystem. Bei der Stapelbetriebsanalyse werden beispielsweise hauptsächlich das klassische MapReduce, Apache Tez und ein bisschen Spark verwendet. Wenn es sich um interaktive Batch-Analysen handelt, sind dies Spark SQL und die Skriptsprachen Pig und Hive.
Natürlich gibt es keine klare Linie, da einige interaktive Sprachen häufig für die operative Stapelanalyse verwendet werden. Apache Samza. LinkedIn. 2014 . , Spark Streaming, -.
- production, . , Kafka, . Kafka — , , . , Kafka , Streaming Index. Kafka : Casandra , SMC.
, , 99 %. - Streaming Index, . , , , «» , . , .
, , -. ?Mac.
IDE?Idea.
: ?.
Warum?, .
, IT- 10 ?, .
?: , . , , , .
?, . . , , . , , .
, . «»?Das gleiche wie die Journalisten: Wie viele Menschen bleiben in Odnoklassniki?Welcher Superheld würdest du gerne sein?Wahrscheinlich Tony Stark.Iron Man?Ja
Warum?Technologie.