Im Laufe der Jahrzehnte ihres Bestehens haben Rechenzentren einen langen Weg von kleinen Computerräumen zu Rechenzentren, Rechenzentren, Cloud- und verteilten Rechenzentren zurückgelegt. Wofür sind verteilte Rechenzentren gedacht? Die bekannten Cisco-Systeme identifizieren die folgenden Ziele für ihre Erstellung:
- Katastrophenschutz
- Kontinuität der Datenverarbeitung
- Anwendungsmobilität
- Systemmigration
- Kapazität / Kapazitätsaufbau
- Verteilte Dienste
- Geografisch lokalisierte Dienste
Mittelständische Unternehmen verfügen häufig über ein zentrales Modell, wenn alle Daten, Dienste und Anwendungen in einem Rechenzentrum konzentriert sind, was ein garantiertes Maß an Datenverfügbarkeit und -sicherheit bietet. Oft besteht jedoch ein Bedarf an einem Backup-Rechenzentrum,
das mit dem Hauptdatenzentrum kombiniert wird und Hochgeschwindigkeitskommunikationskanäle in einem einzigen Computerkomplex verwendet.

Ein System verteilter Rechenzentren (das Hauptrechenzentrum und mehrere regionale), die die Funktionen zum Sammeln, Speichern, Verarbeiten und Bereitstellen von Daten zur Unterstützung von Unternehmensprozessen ausführen, kann die beste Lösung für große geografisch verteilte Organisationen sein. Regionale Rechenzentren können auch als Backup-Standorte verwendet, bei Spitzenlast verwendet oder eine Disaster-Proof-Lösung (DR) implementiert werden. Es stellt die Kontinuität der Geschäftsprozesse sicher, auch wenn ein erheblicher Teil der IT-Ressourcen oder Kommunikationskanäle ausfällt.
Das Erstellen eines eigenen Rechenzentrums ist jedoch ein teures Projekt. Bei der Berechnung der Kosten für den Aufbau eines Backup-Rechenzentrums müssen die Kosten für IT-Infrastruktur und Softwarelizenzen / -support berücksichtigt werden.
Nach einigen Schätzungen sind dies mehr als 60% der Gesamtkosten für die Erstellung eines Rechenzentrums.
In den meisten Fällen ist es sinnvoll, sich an Dienstleister für Rechenzentren zu wenden, anstatt viel in den Aufbau und die Wartung Ihrer eigenen Site zu investieren. Es ist kein Zufall, dass in den letzten schwierigen Jahren in Russland große Einzelhandelsunternehmen, soziale Netzwerke und einige IT-Unternehmen
die Anzahl der Projekte zur Übertragung der IT-Infrastruktur auf das Outsourcing
erhöht haben . Das Mieten einer IT-Infrastruktur ist kostengünstiger und bietet dem Unternehmen zusätzliche Flexibilität. Sie können neue Services einführen und vorhandene Produkte ohne Kapitalkosten entwickeln.
Anwendungsfälle
Verteilte Rechenzentren minimieren verschiedene Risiken, und die kürzlich erfolgte Blockierung von Websites und Subnetzen durch Roskomnadzor, die insbesondere zu Unterbrechungen der Arbeit vieler Cloud-Dienste führte, zeigt, dass Überraschungen möglich sind. Einige Unternehmen sehen einen Ausweg aus dieser Situation, indem sie einen Server im Ausland erwerben, auf dem sie ihr VPN organisieren und alle erforderlichen Cloud-Dienste über dieses starten können.
Bei Redundanz und einigen Diensten ist die Geschwindigkeit des Zugriffs auf die Site von entscheidender Bedeutung, und die Anbieter berücksichtigen dies. Das eigene Rechenzentrum von RUVDS RUCLOUD in Korolev verfügt beispielsweise über drei Internetkanäle mit 5 Gbit / s, die eine garantierte hohe Geschwindigkeit garantieren. Die Kanäle sind mit den größten Kommunikationszentren M-9 (MMTS-9) und M-10 verbunden. Kunden können Geräte an jedem Standort auswählen. Aufgrund dessen erhält der Benutzer eine Geschwindigkeit von mindestens 250 Mbit / s mit Zugriff auf Russland, wodurch er bequem mit seinem virtuellen Server (VPS / VDS) arbeiten kann.
Beispielsweise ist das RUCLOUD-Rechenzentrum über einen direkten Kommunikationskanal mit einer Bandbreite von 10 Gbit / s mit dem Kommunikations-Backbone im M-9-Rechenzentrum verbunden. Auf diese Weise können Kunden einen schnellen Datenverkehr zwischen virtuellen Servern in verschiedenen Rechenzentren gewährleisten.
Darüber hinaus können Anbieter die Effizienz von Backup-Rechenzentren steigern, indem sie den Einsatz von IT-Infrastrukturressourcen maximieren (Skaleneffekte sind in den meisten Rechenzentren von Unternehmen nicht verfügbar).
In einem typischen verteilten Rechenzentrumslayout sind lokale Netzwerke (LANs) und Speicherbereichsnetzwerke (SANs) von Standorten miteinander verbunden. Die Segmente der lokalen Netzwerke, mit denen die Server verbunden sind, werden zu L2-Domänen zusammengefasst. Auf diese Weise können Anwendungen die IP-Adressen von Servern transparent zwischen Standorten verschieben. Dank der Kombination von SAN-Servern können Speicherressourcen verschiedener Standorte verwendet werden.
Aus Sicht der Verwaltung und des Betriebs können geografisch verteilte Rechenzentren (und es gibt vier Arten solcher Rechenzentren) für den Benutzer wie ein einziges System aussehen. Wenn ein verteiltes Rechenzentrum Dienste für externe Benutzer bereitstellt, steht eine einzige Dienst- und Supportschnittstelle zur Verfügung.
Klassifizierung verteilter Rechenzentren nach Entfernung zwischen Standorten.Verteilte Rechenzentren
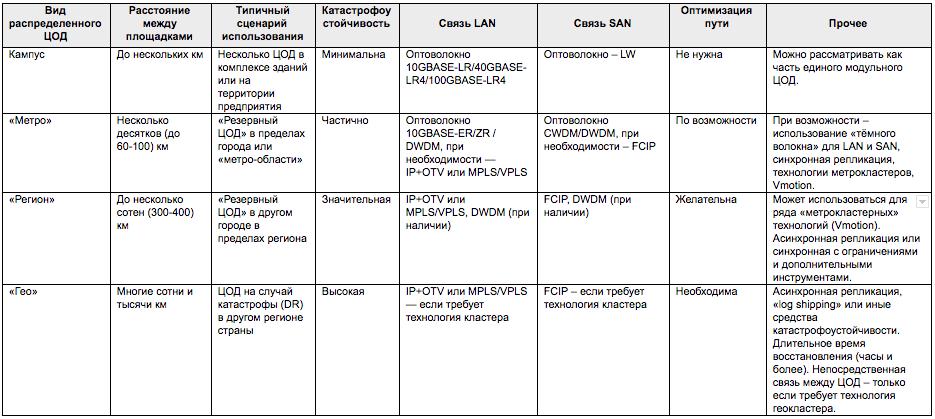
Was gibt es?
Was bieten verteilte Rechenzentren einem Anbieter und seinen Kunden noch? Für das Anbieterunternehmen bedeutet dies die Möglichkeit, den Tätigkeitsbereich zu erweitern, neue Märkte zu erschließen und den Kunden die Möglichkeit zu geben, neue Präsenzpunkte und größere Auswahlmöglichkeiten anzubieten. Geografisch verteilte internationale Rechenzentren bieten die besten Bedingungen für verschiedene Parameter. Darüber hinaus verfügen solche Anbieter in der Regel über eine flexible Preispolitik, die es ihnen ermöglicht, die beste Option für die Platzierung von IT-Geräten und -Tarifen unter Berücksichtigung individueller Anforderungen auszuwählen.
Insbesondere für den Kunden ist es:
- Möglichkeit zum Erstellen verschiedener Disaster Recovery- Konfigurationen (Disaster Recovery) mit festgelegten Disaster Recovery-Optionen. Das Backup-Rechenzentrum kann auch zum Hosten der IT-Infrastruktur verwendet werden, um eine hohe Verfügbarkeit von Unternehmensanwendungen sicherzustellen. Zum Beispiel wirkte sich die Blockierung „zusätzlicher“ IP-Adressen durch Roskomnadzor negativ auf viele Internetdienste und Websites aus, die nicht mit Telegramm in Verbindung standen. Im Falle einer ähnlichen Sperrung von IP-Adressen in einem Land wird ein Teil der Infrastruktur in einem anderen Land zur Rettung kommen.
- Die Fähigkeit, die Arbeit so nah wie möglich an den gewünschten Zielmärkten zu organisieren und die Latenz im Netzwerk aufgrund der "Annäherung des Dienstes an die Benutzer" zu minimieren. Beispielsweise werden die Schweiz und England häufig von Händlern ausgewählt , die auf europäischen Websites handeln und Eigentümer von Online-Shops sind.
- Fähigkeit, in mehreren Gerichtsbarkeiten zu arbeiten und dabei die örtlichen Gesetze zu beachten, z. B. die Anforderung, Kundendaten auf dem Gebiet der Russischen Föderation, der EU und Großbritanniens zu verarbeiten.
- Die Möglichkeit, einfach auf eine neue Site zu migrieren, indem Daten und sogar Geld auf dem Konto gespeichert werden. Wenn ein Kunde beispielsweise Server in der Russischen Föderation verwendet und sich entscheidet, Daten nach London zu übertragen, muss er nur einen Support-Service anfordern, und nach kurzer Zeit werden seine Daten in die britische Hauptstadt „verschoben“.
- Verteilte Cloud-Rechenzentren gelten auch als die beste Lösung für die Bereitstellung von IaaS-Diensten.
Katastrophenverträglichkeit und hohe Verfügbarkeit
Wie oben erwähnt, kann durch die Platzierung von IT-Systemen in mehreren Rechenzentren deren Katastrophenverträglichkeit und hohe Verfügbarkeit sichergestellt werden. Jedes Rechenzentrum spielt dabei eine Rolle, aber im Allgemeinen ist die unabhängige Implementierung und Unterstützung einer solchen Architektur normalerweise keine triviale Aufgabe. Darüber hinaus hängt das Konzept der Hochverfügbarkeit von den Besonderheiten des Unternehmens ab. Um eine solche Topologie mit mehreren Rechenzentren nutzen zu können, ist eine entsprechende Implementierung der Architektur von Rechenzentren, der darin ausgeführten Anwendungen und Prozesse erforderlich.
Katastrophenschutz und hohe Verfügbarkeit von IT-Systemen können erreicht werden, indem sie in mehreren Rechenzentren platziert werden.Das Disaster-Resistant Data Center (DR) wird zum Hosten der IT-Infrastruktur geschäftskritischer Anwendungen verwendet, um IT-Services im Katastrophenfall oder im Hauptdatenzentrum zu unterstützen. In diesem Fall ist es erforderlich, im Notfall ein akzeptables Maß an Verlusten während der Migration vom Hauptdatenzentrum sicherzustellen.
Abhängig von:
- Die Kritikalität von Systemen für das Kerngeschäft des Unternehmens.
- Risiken und potenzielle Verluste durch Ausfallzeiten von IT-Systemen.
- Leistungs- und Zuverlässigkeitsanforderungen für IT-Systeme.
- Eine Reihe von Systemen, die Redundanz und hohe Verfügbarkeit erfordern.
- Die Kosten für die Organisation eines Backup-Rechenzentrums.
- Topologie des Zieldatenzentrums.
Eine öffentliche Cloud kann einige der Funktionen eines Backup-Rechenzentrums übernehmen. Das Hosten von Anwendungen in öffentlichen Clouds zur Erhöhung der Flexibilität und Optimierung der IT-Infrastrukturkosten ist häufig die intelligenteste Lösung. Langfristig ist es daher möglich, die Anzahl der Rechenzentren durch die Nutzung öffentlicher Cloud-Dienste zu reduzieren.
Die Katastrophentoleranz setzt die Einhaltung der erforderlichen Parameter des RPO / RTO-Wiederherstellungspunkts (Wiederherstellungspunktziel, RPO) und der Wiederherstellungszeit (Wiederherstellungszeitziel, RTO) voraus. Je niedriger der RPO / RTO ist, desto teurer ist die Lösung. In diesem Fall werden normalerweise Datenreplikations- und Hot-Standby-Systeme verwendet. Mit einem größeren RPO / RTO können Sie Backups auf Band oder in der Cloud sowie Cold-Backups durchführen.
Geografisch verteilte Failovercluster können verwendet werden, um die Geschäftskontinuität sicherzustellen. Cluster-Systeme erfordern normalerweise das "Strecken" des L2-VLAN zwischen den Rechenzentren, obwohl einige Anwendungen das Clustering über das L3-Netzwerk unterstützen.
Die Mobilität virtueller Dienste bedeutet die Möglichkeit, virtuelle Maschinen zwischen Rechenzentren zu verschieben. Dies erfordert das Erweitern des VLAN und den kontinuierlichen Zugriff auf die LUN-Volumes. Eine solche Lösung kann zur Grundlage für das Cloud-Lastmanagement, dessen Ausgleich und Lastmigration zwischen Standorten werden.
Gleichzeitig ist die Entfernung zwischen den Standorten ein Schlüsselfaktor. Mit einer geringen Entfernung gibt es weniger Latenz, höhere Leistung und einfachere Kommunikation. Sie können die synchrone Replikation verwenden.
Hermozona in London
Die Bereitstellung von Katastrophenschutz und Hochverfügbarkeit für kritische Anwendungen durch einen Anbieter ist eines der beliebtesten Szenarien. Eine weitere Option ist die lokale Redundanz. Beispielsweise organisierte RUVDS, ein Unternehmen, das virtuelle Serverdienste (VPS / VDS) bereitstellt, auf Kundenwunsch eine Sicherung seiner virtuellen Infrastruktur im Hauptdatenzentrum, wenn Client-Server auf verschiedenen physischen Maschinen, in verschiedenen Druckzonen und gleichzeitig mit verschiedenen Netzwerkinfrastrukturen dupliziert wurden. Dann wurde die Möglichkeit hinzugefügt,
Server in der Schweiz und jetzt in England zu duplizieren (oder als Hauptserver zu verwenden).
Bei einer solchen Vielfalt von Standorten besteht natürlich das Problem einer begrenzten Datenübertragungsgeschwindigkeit zwischen Ländern. Es reicht jedoch aus, eine zusätzliche Reservierung kritischer Ressourcen zu organisieren. Auf Kundenwunsch ist auch die Mobilität virtueller Dienste möglich (Verschieben von VMs zwischen Rechenzentren).
Nach der Eröffnung des zweiten
Standorts in Moskau startete RUVDS
einen neuen Luftraum in London, der Finanzhauptstadt Europas. Die Germozone befindet sich im Rechenzentrum
Equinix LD8 - einem der größten Rechenzentren im Equinix-Netzwerk. Das LD8-Rechenzentrum hat eine lange Geschichte und gilt als eines der wichtigsten Rechenzentren außerhalb des Telehouse-Campus. Im Jahr 2016 kaufte Equinix Telecity für 2,6 Milliarden Pfund und beide Gebäude wurden in Equinix LD8 umbenannt.
Redundantes Rechenzentrum Equinix LD8 - N + 1, das die TIER3-Anforderungen und -Spezifikationen für die Standards OHSAS 18001, PCI-DSS, ISO 14001, ISO 27001, ISO 9001, ISO 50001 und PCI-DSS vollständig erfüllt (letzteres ist für Zahlungssysteme wichtig).Equinix bedient Kunden aus aller Welt und 175 Rechenzentren in 22 Ländern. Das Rechenzentrum Equinix LD8 befindet sich nur wenige Kilometer vom Londoner Finanzzentrum entfernt und ist über einen direkten Zugang zu Internet-Austauschern in Frankfurt (DE-CIX) und Amsterdam (AMS-IX) verbunden. Es ist eines der besten nicht nur in Großbritannien, sondern auch in Europa .
In diesem Rechenzentrum erhalten Kunden Zugriff auf verschiedene Finanzdienstleistungen, Internetanbieter, Cloud-Dienste und IT-Dienste, Dienste für Unternehmen mit unterschiedlichen Profilen, z. B. Inhaltsentwickler und Unternehmen für digitale Medien.
Das Rechenzentrum verfügt über ein ISO 27001-Zertifikat für Informationssicherheit, ein ISO 50001-Energiemanagementzertifikat, ein ISO 9000-Qualitätsstandardzertifikat, ein ISO 14000-Umweltmanagementzertifikat, ein OHSAS 18001-Industriemanagementzertifikat und ein PCI DSS-Zahlungskarten-Datensicherheitszertifikat. Die gesamte Infrastruktur des Rechenzentrums ist gemäß dem N + 1-Schema reserviert.
Das Partnerschaftsabkommen wird es RUVDS ermöglichen, nicht nur die operativen Fähigkeiten zu erweitern und die Qualität der angebotenen Dienste zu verbessern, sondern auch einer der sich am dynamischsten entwickelnden Hosting-Anbieter im gesamten postsowjetischen Raum zu bleiben. Die Hermozone in London wird nun zu einem eigenen Rechenzentrum in Korolev hinzugefügt, das von der hermetischen Zone RUVDS im Schweizer Rechenzentrum Deltalis gemietet wird.
Eine isolierte Druckzone stellt sicher, dass niemand anderes als RUVDS-Clients die ihr zugewiesene Netzwerkinfrastruktur verwendet. Diese Platzierungsoption ist in Bezug auf Preis-Qualitäts-Zuverlässigkeitsindikatoren am korrektesten.
Die Hermozone ist mit einer Zweikreis-Kühlung (heiße und kalte Korridore) ausgestattet. Es verwendet Geräte der Enterprise-Klasse von Huawei. Hohe Produktionsqualität, Zuverlässigkeit und Garantieservice zu einem angemessenen Preis ermöglichen es uns, unseren Kunden dedizierte VDS / VPS-Dienste (Virtual Server Rental) für neue Hochleistungsgeräte zu attraktiven Kosten anzubieten.
Huawei RH2288H V3 Server der Enterprise-Klasse mit hoher Dichte. Diese zuverlässigen und kostengünstigen Serverplattformen helfen dem Anbieter, die Kosten der für Kunden bereitgestellten Dienste zu optimieren.Huawei ist seit 2016
strategischer Partner des russischen Hosting-Anbieters RUVDS. Insbesondere im Rahmen eines gemeinsamen Projekts stattet Huawei das
RUVDS-Rechenzentrum in der Region Moskau mit seiner Ausrüstung aus. Dies garantiert einen schnelleren und stabileren Betrieb virtueller Server und ermöglicht es Ihnen, Kunden noch bessere und modernere Dienste anzubieten.
Plattform basierend auf MMTS-9
RUVDS eröffnet auch eine neue Site basierend auf MMTS-9 (
M9 ). Derzeit ist
MMTS-9 die größte technologische Plattform in Moskau für das Zusammenspiel von Moskauer, russischen und internationalen Telekommunikationsbetreibern bei der Bereitstellung von lokaler, internationaler Fernkommunikation, Datenübertragung, Internetzugang und anderen Telekommunikationsdiensten. Darüber hinaus ist MMTS-9 der größte Punkt für den Austausch von Internetverkehr zwischen Betreibern in Russland.
An allen drei RUVDS-Standorten sind die
Preise für Kunden gleich - ab 130 Rubel pro Monat.
Das Gebäude der MMTS-9-Station ist mit einer modernen technischen Infrastruktur ausgestattet, einschließlich unterbrechungsfreier Stromversorgungssysteme, Klimatisierung, Gasfeuerlöschung, Überwachung und Videoüberwachung. Das Vorhandensein einer High-Tech-Engineering-Infrastruktur ermöglicht es MMTS-9, die Organisation eines fehlertoleranten Präsenzpunkts mit den erforderlichen Betriebsbedingungen für Server und Telekommunikationsgeräte von Telekommunikationsbetreibern sicherzustellen.