Am 28. Mai wurde auf der
RootConf 2018-Konferenz, die im Rahmen des RIT ++ 2018-
Festivals stattfand , im Abschnitt „Protokollierung und Überwachung“ ein Bericht „Überwachung und Kubernetes“ veröffentlicht. Es handelt von den Erfahrungen mit der Überwachung des Setups mit Prometheus, die Flant als Ergebnis des Betriebs von Dutzenden von Kubernetes-Projekten in der Produktion erhalten hat.

Aus Tradition freuen wir uns, ein
Video mit einem Bericht (ungefähr eine Stunde,
viel informativer
als der Artikel) und dem Hauptdruck in Textform zu präsentieren. Lass uns gehen!
Was ist Überwachung?
Es gibt viele Überwachungssysteme:

Es scheint, als würde man einen von ihnen nehmen und installieren - das ist alles, die Frage ist geschlossen. Die Praxis zeigt jedoch, dass dies nicht der Fall ist. Und hier ist warum:
- Tachometer zeigt Geschwindigkeit an . Wenn wir die Geschwindigkeit einmal pro Minute mit dem Tachometer messen, stimmt die Durchschnittsgeschwindigkeit, die wir auf der Grundlage dieser Daten berechnen, nicht mit den Kilometerzählerdaten überein. Und wenn dies bei einem Auto offensichtlich ist, dann vergessen wir es oft, wenn es um viele, viele Indikatoren für den Server geht.
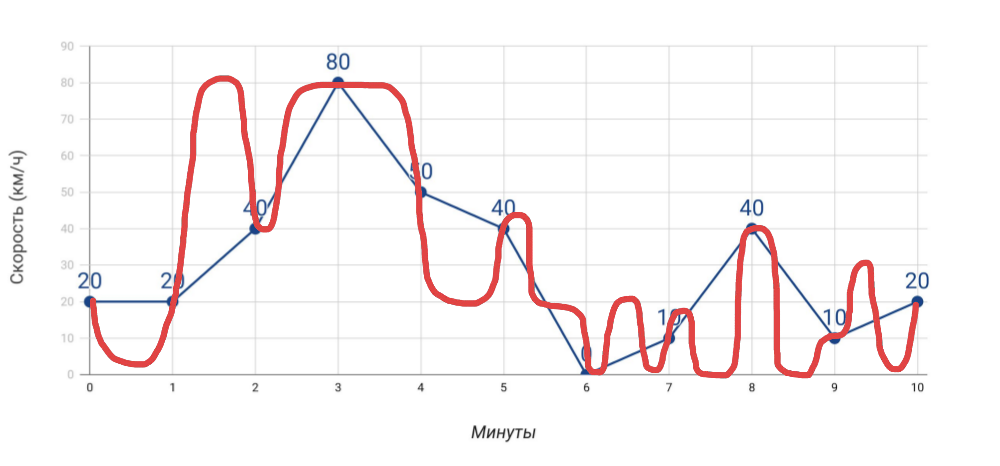
Was wir messen und wie wir tatsächlich gereist sind - Weitere Messungen . Je mehr verschiedene Indikatoren wir erhalten, desto genauer wird die Diagnose von Problemen sein ... aber nur unter der Bedingung, dass dies wirklich nützliche Indikatoren sind und nicht nur alles, was Sie gesammelt haben.
- Warnungen . Das Senden von Warnungen ist nicht kompliziert. Zwei typische Probleme: a) Fehlalarme treten so oft auf, dass wir nicht mehr auf Warnungen reagieren. B) Warnungen kommen zu einem Zeitpunkt, an dem es zu spät ist (alles ist bereits explodiert). Und bei der Überwachung zu erreichen, dass diese Probleme nicht aufgetreten sind, ist echte Kunst!
Die Überwachung besteht aus drei Ebenen, von denen jede von entscheidender Bedeutung ist:
- Zuallererst ist dies ein System, mit dem Sie Unfälle vorbeugen, über Unfälle informieren (wenn sie nicht verhindert werden konnten) und eine schnelle Diagnose von Problemen durchführen können.
- Was wird dafür benötigt? Genaue Daten , nützliche Diagramme (sehen Sie sie sich an und verstehen Sie, wo das Problem liegt), relevante Warnungen (treffen Sie zum richtigen Zeitpunkt ein und enthalten Sie klare Informationen).
- Damit dies funktioniert, ist ein Überwachungssystem erforderlich.
Die ordnungsgemäße Einrichtung eines Überwachungssystems, das wirklich funktioniert, ist keine leichte Aufgabe und erfordert auch ohne Kubernetes einen durchdachten Ansatz für die Implementierung. Aber was passiert mit seinem Aussehen?
Einzelheiten zur Überwachung von Kubernetes
Nr. 1. Größer und schneller
Kubernetes verändert sich stark, weil die Infrastruktur immer größer und schneller wird. Wenn früher bei gewöhnlichen Eisenservern ihre Anzahl sehr begrenzt war und der Additionsprozess sehr lang war (Tage oder Wochen dauerte), dann erhöhte sich bei virtuellen Maschinen die Anzahl der Entitäten erheblich und die Zeit ihrer Einführung in den Kampf wurde auf Sekunden reduziert.
Mit Kubernetes ist die Anzahl der Entitäten um eine Größenordnung gewachsen, ihre Hinzufügung ist vollständig automatisiert (Konfigurationsmanagement ist erforderlich, da ohne Beschreibung einfach kein neuer Pod erstellt werden kann), die gesamte Infrastruktur ist sehr dynamisch geworden (z. B. werden Pods jedes Mal gelöscht und freigegeben werden erneut erstellt).
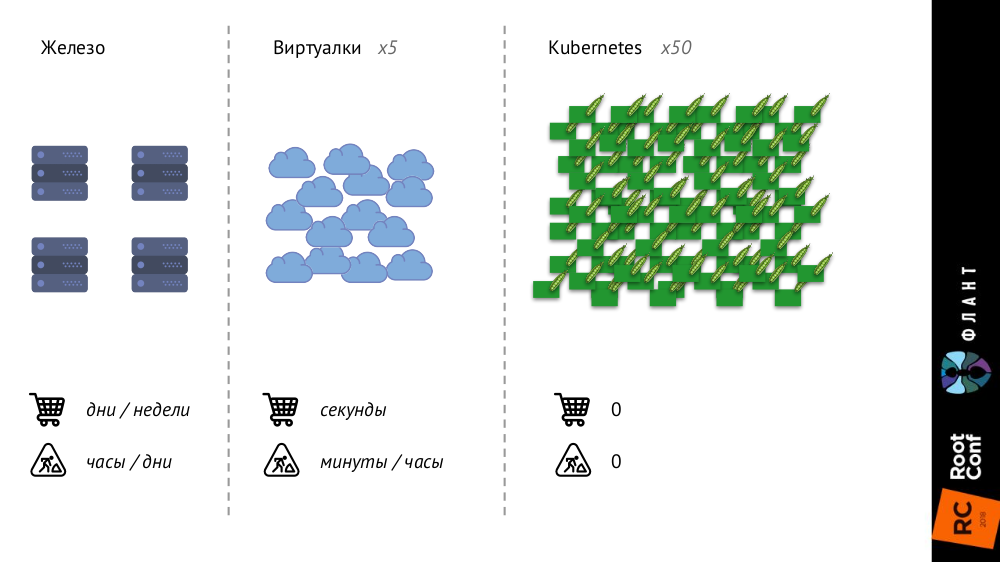
Was ändert sich daran?
- Grundsätzlich hören wir auf, einzelne Hülsen oder Behälter zu betrachten - jetzt interessieren wir uns nur noch für Gruppen von Objekten .
- Die Serviceerkennung wird unbedingt erforderlich , da die "Geschwindigkeiten" bereits so hoch sind, dass wir neue Entitäten im Prinzip nicht wie zuvor beim Kauf neuer Server manuell starten / löschen können.
- Die Datenmenge wächst erheblich . Wenn frühere Metriken von Servern oder virtuellen Maschinen erfasst wurden, jetzt von Pods, deren Anzahl viel größer ist.
- Die interessanteste Änderung, die ich als " Metadatenfluss " bezeichnet habe, und ich werde Ihnen mehr darüber erzählen.
Ich werde mit diesem Vergleich beginnen:
- Wenn Sie Ihr Kind in den Kindergarten schicken, erhält es eine persönliche Box, die ihm für das nächste Jahr (oder länger) zugewiesen wird und auf der sein Name angegeben ist.
- Wenn Sie zum Pool kommen, ist Ihr Schließfach nicht signiert und wird Ihnen für eine „Sitzung“ ausgestellt.
Klassische Überwachungssysteme denken also, dass sie ein Kindergarten sind , kein Pool: Sie gehen davon aus, dass das Überwachungsobjekt für immer oder lange zu ihnen gekommen ist, und geben ihnen entsprechend Schließfächer. Die Realitäten in Kubernetes sind jedoch anders: Ein Pod kam in den Pool (d. H. Wurde erstellt), schwamm darin (bis zu einer neuen Bereitstellung) und ging (wurde zerstört) - all dies geschieht schnell und regelmäßig. Das Überwachungssystem muss daher verstehen, dass die von ihm überwachten Objekte ein kurzes Leben führen und es zum richtigen Zeitpunkt vollständig vergessen können.
Nr. 2. Parallele Realität existiert
Ein weiterer wichtiger Punkt - mit dem Aufkommen von Kubernetes haben wir gleichzeitig zwei „Realitäten“:
- Kubernetes-Welt, in der es Namespaces, Bereitstellungen, Pods und Container gibt. Dies ist eine komplexe Welt, aber sie ist logisch und strukturiert.
- Die "physische" Welt, bestehend aus vielen (buchstäblich - Haufen) Containern auf jedem Knoten.
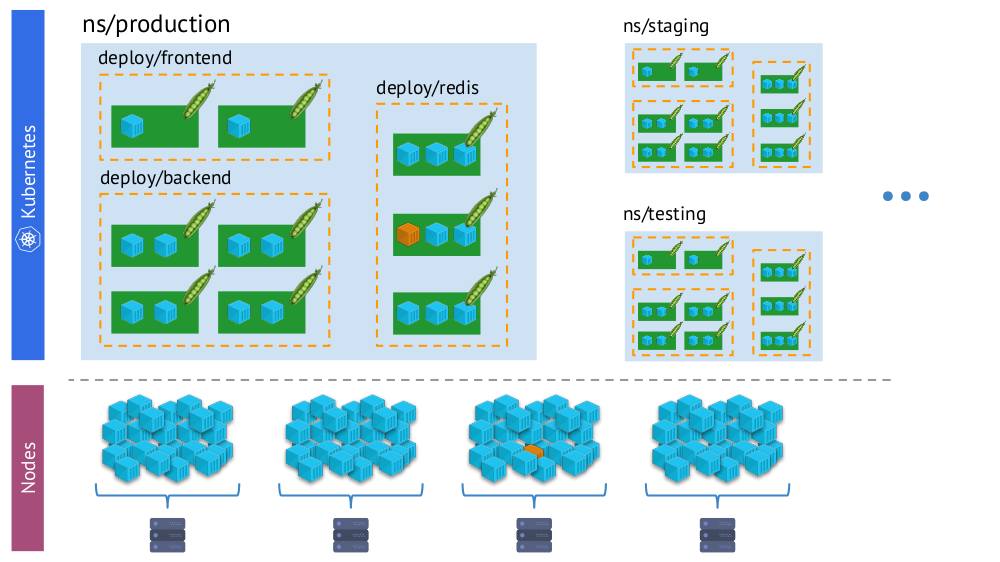 Ein und derselbe Container in Kubernetes „virtueller Realität“ (oben) und der physischen Welt der Knoten (unten)
Ein und derselbe Container in Kubernetes „virtueller Realität“ (oben) und der physischen Welt der Knoten (unten)Und während des Überwachungsprozesses müssen wir
die physische Welt der Container ständig
mit der Realität von Kubernetes vergleichen . Wenn wir uns beispielsweise einen Namespace ansehen, möchten wir wissen, wo sich alle seine Container (oder die Container eines seiner Herde) befinden. Ohne dies sind Warnungen nicht visuell und bequem zu verwenden, da es für uns wichtig ist, zu verstehen, welche Objekte sie melden.
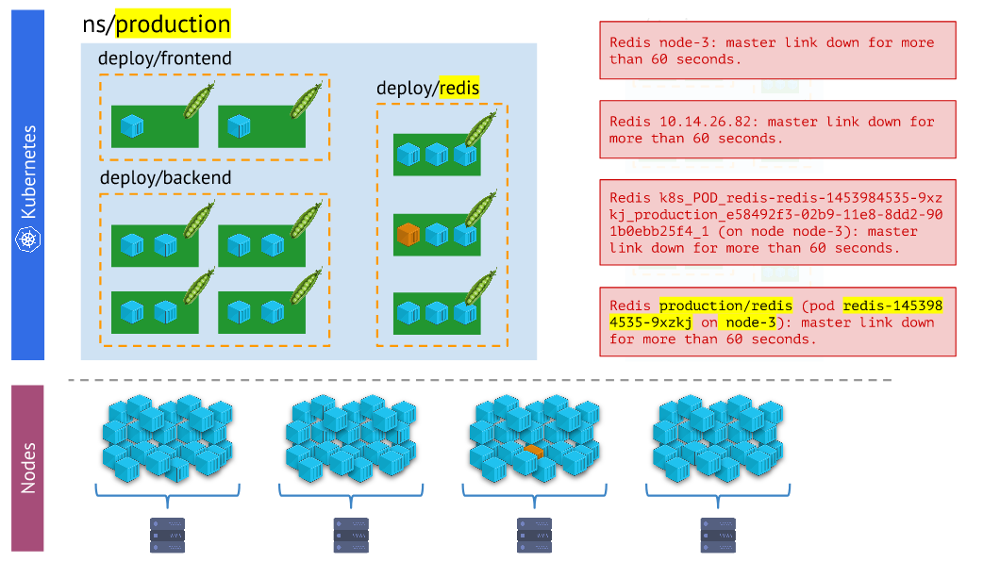 Verschiedene Arten von Warnungen - letztere sind visueller und bequemer bei der Arbeit als die anderenDie Schlussfolgerungen
Verschiedene Arten von Warnungen - letztere sind visueller und bequemer bei der Arbeit als die anderenDie Schlussfolgerungen hier sind:
- Das Überwachungssystem muss die in Kubernetes integrierten Grundelemente verwenden.
- Es gibt mehr als eine Realität: Oft treten Probleme nicht mit dem Herd auf, sondern mit einem bestimmten Knoten, und wir müssen ständig verstehen, in welcher Art von „Realität“ sie sich befinden.
- In einem Cluster gibt es in der Regel mehrere Umgebungen (neben der Produktion), was bedeutet, dass dies berücksichtigt werden muss (z. B. um nachts keine Warnungen über Probleme mit Entwicklern zu erhalten).
Wir haben also drei notwendige Bedingungen, damit alles funktioniert:
- Wir verstehen gut, was Überwachung ist.
- Wir kennen die Funktionen, die bei Kubernetes angezeigt werden.
- Wir adoptieren den Prometheus.
Und um wirklich zu trainieren, muss man sich nur noch
wirklich viel Mühe geben! Übrigens, warum genau Prometheus?
Prometheus
Es gibt zwei Möglichkeiten, die Frage nach der Wahl von Prometheus zu beantworten:
- Sehen Sie, wer und was im Allgemeinen zur Überwachung von Kubernetes verwendet wird.
- Betrachten Sie die technischen Vorteile.
Zum ersten habe ich die Umfragedaten aus The New Stack (aus
dem E-Book "
The State of the Kubernetes Ecosystem ") verwendet, wonach Prometheus zumindest beliebter ist als andere Lösungen (sowohl Open Source als auch SaaS), und wenn Sie sich das ansehen, hat es einen fünffachen statistischen Vorteil .
Lassen Sie uns nun sehen, wie Prometheus funktioniert, parallel dazu, wie sich seine Fähigkeiten mit Kubernetes kombinieren und damit verbundene Herausforderungen lösen.
Wie ist Prometheus aufgebaut?
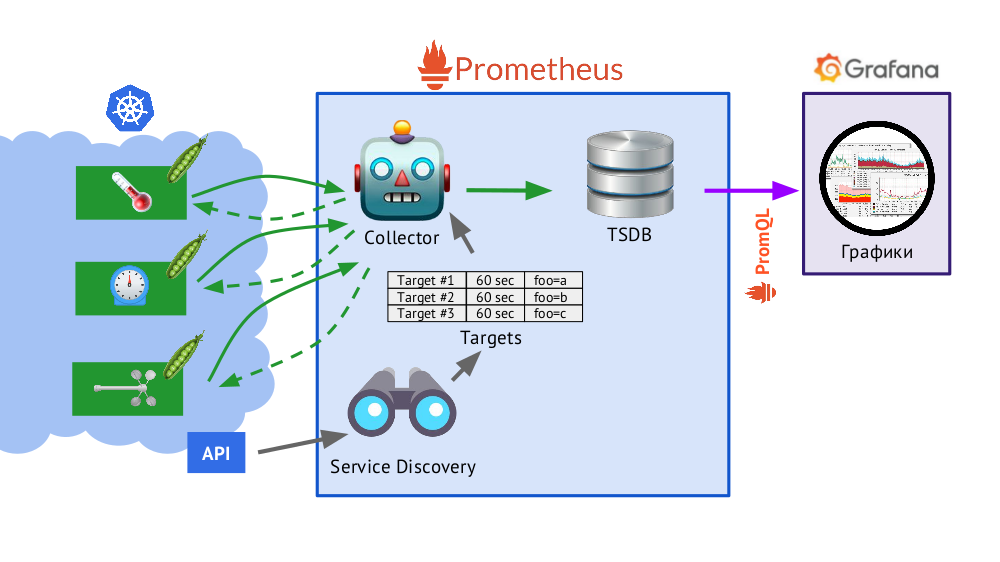
Prometheus ist in Go geschrieben und als einzelne Binärdatei verteilt, in die alles eingebaut ist. Der grundlegende Algorithmus für seine Funktionsweise lautet wie folgt:

- Der Kollektor liest die Zieltabelle , d.h. eine Liste der zu überwachenden Objekte und die Häufigkeit ihrer Abfrage (standardmäßig - 60 Sekunden).
- Danach sendet der Collector eine HTTP-Anfrage an jeden Pod, den Sie benötigen, und erhält eine Antwort mit einer Reihe von Metriken - es kann einhundert, eintausend, zehntausend sein ... Jede Metrik hat einen Namen, einen Wert und Beschriftungen .
- Die empfangene Antwort wird in der TSDB- Datenbank gespeichert, wo der Zeitstempel ihres Empfangs und die Beschriftungen des Objekts, von dem sie entnommen wurde, zu den empfangenen Metrikdaten hinzugefügt werden.
Kurz über TSDBTSDB - Zeitreihendatenbank (DB für Zeitreihen) on Go, mit der Sie Daten für eine bestimmte Anzahl von Tagen speichern können und dies sehr effizient (in Größe, Speicher und Eingabe / Ausgabe). Daten werden nur lokal gespeichert, ohne Clustering und Replikation, was ein Plus (es funktioniert einfach und garantiert) und ein Minus (es gibt keine horizontale Skalierung des Speichers) ist, aber im Fall von Prometheus ist das Sharding gut gemacht, Föderation - dazu später mehr.
- Service Discovery ist eine in Prometheus integrierte Service Discovery- Engine, mit der Sie Daten „aus der Box“ (über die Kubernetes-API) empfangen können, um eine Zieltabelle zu erstellen.
Wie sieht dieser Tisch aus? Für jeden Eintrag wird die URL gespeichert, die zum Abrufen von Metriken, der Häufigkeit von Anrufen und Beschriftungen verwendet wird.
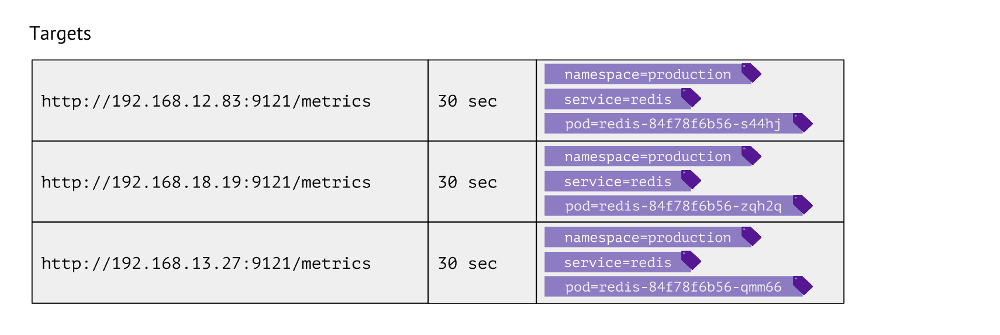
Etiketten werden verwendet, um die "Welten" von Kubernetes mit den physischen zu vergleichen. Um beispielsweise einen Pod mit Redis zu finden, müssen der Werte-Namespace, der Service (der aufgrund der technischen Funktionen für einen bestimmten Fall anstelle der Bereitstellung verwendet wird) und der tatsächliche Pod vorhanden sein. Dementsprechend werden diese 3 Bezeichnungen in Zieltabelleneinträgen für Redis-Metriken gespeichert.
Diese Einträge in der Tabelle werden auf der Grundlage der Prometheus-
scrape_configs in der die Überwachungsobjekte beschrieben werden:
scrape_configs Abschnitt
scrape_configs werden
scrape_configs definiert, die angeben, nach welchen Labels nach zu überwachenden Objekten gesucht werden soll, wie sie gefiltert werden sollen und welche Labels aufgezeichnet werden sollen.
Welche Daten sammelt Kubernetes?
- Erstens ist der Assistent in Kubernetes ziemlich kompliziert - und es ist wichtig, den Status seiner Arbeit zu überwachen (Kube-Apiserver, Kube-Controller-Manager, Kube-Scheduler, Kube-etcd3 ...). Außerdem ist er an den Clusterknoten gebunden.
- Zweitens ist es wichtig zu wissen, was in Kubernetes vor sich geht . Dazu erhalten wir Daten von:
- kubelet - Diese Kubernetes-Komponente wird auf jedem Knoten des Clusters ausgeführt (und stellt eine Verbindung zum K8s-Assistenten her). cAdvisor ist integriert (alle Metriken nach Containern) und speichert auch Informationen zu verbundenen persistenten Volumes.
- Kube-State-Metriken - Dies ist der Prometheus-Exporter für die Kubernetes-API (mit dem Sie Informationen zu Objekten abrufen können , die in Kubernetes gespeichert sind: Pods, Dienste, Bereitstellungen usw.; Behälter- oder Herdstatus);
- Node-Exporter - bietet Informationen über den Knoten selbst, grundlegende Metriken auf dem Linux-System (CPU, Diskstats, Meminfo usw. ).
- Als nächstes folgen Kubernetes-Komponenten wie kube-dns, kube-prometheus-operator und kube-prometheus, ingress-nginx-controller usw.
- Die nächste Kategorie von zu überwachenden Objekten ist die in Kubernetes gestartete Software . Dies sind typische Serverdienste wie nginx, php-fpm, Redis, MongoDB, RabbitMQ ... Wir tun dies selbst, sodass beim Hinzufügen bestimmter Labels zum Dienst automatisch die erforderlichen Daten erfasst werden, wodurch das aktuelle Dashboard in Grafana erstellt wird.
- Schließlich ist die Kategorie für alles andere benutzerdefiniert . Mit den Prometheus-Tools können Sie die Erfassung beliebiger Metriken (z. B. die Anzahl der Bestellungen) automatisieren, indem Sie der Servicebeschreibung einfach ein
prometheus-custom-target Label hinzufügen.

Grafiken
Die empfangenen Daten
(oben beschrieben) werden zum Senden von Warnungen und zum Erstellen von Diagrammen verwendet. Wir zeichnen Graphen mit
Grafana . Ein wichtiges „Detail“ ist hier
PromQL , die Prometheus-Abfragesprache, die sich perfekt in Grafana integrieren lässt.
Es ist für die meisten Aufgaben recht einfach und bequem
(aber zum Beispiel ist das Beitreten zu Joins bereits unpraktisch, aber Sie müssen es trotzdem tun) . Mit PromQL können Sie alle erforderlichen Aufgaben lösen: schnell die erforderlichen Metriken auswählen, Werte vergleichen, arithmetische Operationen ausführen, gruppieren, mit Zeitintervallen arbeiten und vieles mehr. Zum Beispiel:

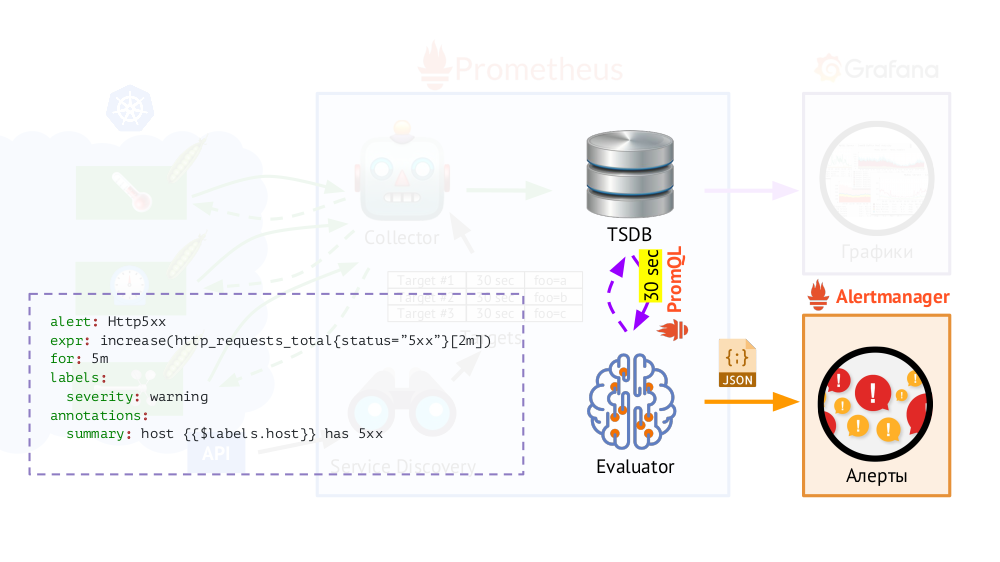
Darüber hinaus verfügt Prometheus über einen
Evaluator , der mit demselben PromQL mit der angegebenen Häufigkeit auf TSDB zugreifen kann. Warum ist das so? Beispiel: Beginnen Sie mit dem Senden von Warnungen in Fällen, in denen gemäß den verfügbaren Metriken in den letzten 5 Minuten ein Fehler von 500 auf dem Webserver aufgetreten ist. Zusätzlich zu den Beschriftungen, die in der Anforderung enthalten waren, fügt Evaluator den Daten für Warnungen zusätzliche (wie von uns konfiguriert)
hinzu .
Anschließend werden sie im JSON-Format an eine andere Prometheus-Komponente
gesendet -
Alertmanager .
Prometheus sendet regelmäßig (alle 30 Sekunden) Warnungen an Alertmanager, die diese deduplizieren (nach Erhalt der ersten Warnung wird diese gesendet und die nächsten werden nicht erneut gesendet).
 Hinweis : Wir verwenden Alertmanager nicht zu Hause, sondern senden Daten von Prometheus direkt an unser System, mit dem unsere Mitarbeiter arbeiten. Dies spielt jedoch im allgemeinen Schema keine Rolle.
Hinweis : Wir verwenden Alertmanager nicht zu Hause, sondern senden Daten von Prometheus direkt an unser System, mit dem unsere Mitarbeiter arbeiten. Dies spielt jedoch im allgemeinen Schema keine Rolle.Prometheus bei Kubernetes: Das große Ganze
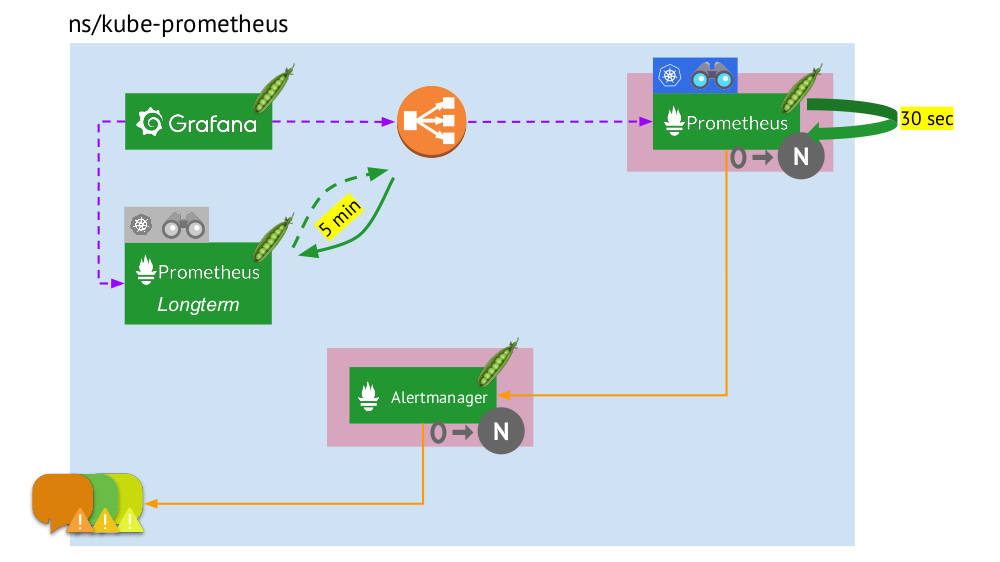
Lassen Sie uns nun sehen, wie dieses gesamte Prometheus-Bundle in Kubernetes funktioniert:
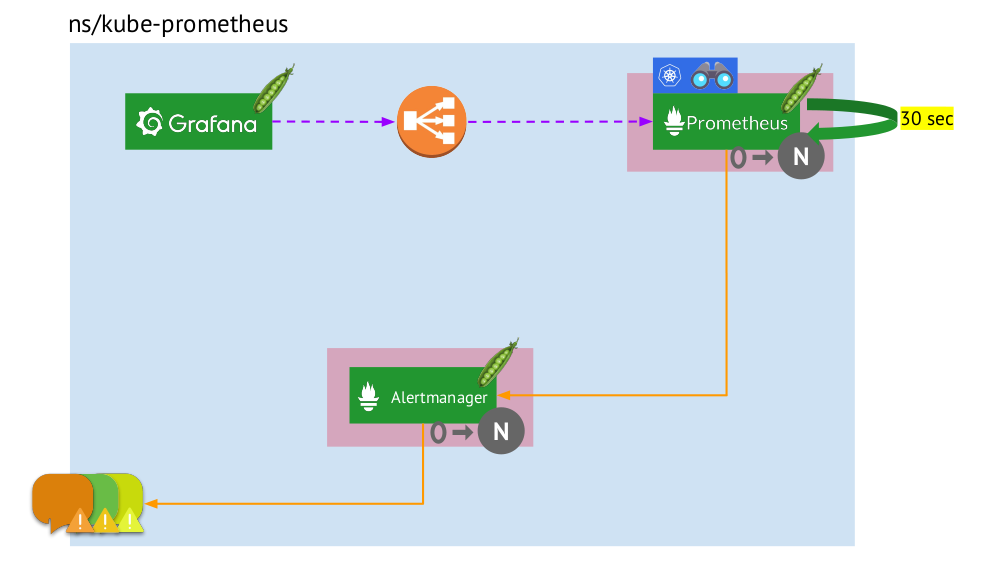
- Kubernetes hat einen eigenen Namespace für Prometheus (wir haben
kube-prometheus in der Abbildung) . - Dieser Namespace hostet den Pod mit der Prometheus-Installation, die alle 30 Sekunden Metriken von allen Zielen sammelt, die über Service Discovery im Cluster empfangen wurden.
- Es enthält auch einen Pod mit Alertmanager, der Daten von Prometheus empfängt und Warnungen sendet (an Mail, Slack, PagerDuty, WeChat, Integration von Drittanbietern usw. ) .
- Prometheus steht vor einem Load Balancer - einem regulären Dienst in Kubernetes - und Grafana greift über diesen auf Prometheus zu. Um Fehlertoleranz zu gewährleisten, verwendet Prometheus mehrere Pods mit Prometheus-Installationen, von denen jeder alle Daten sammelt und in seiner TSDB speichert. Durch den Balancer trifft Grafana einen von ihnen.
- Die Anzahl der Pods mit Prometheus wird durch die StatefulSet- Einstellung gesteuert. Normalerweise stellen wir nicht mehr als zwei Pods her, aber Sie können diese Anzahl erhöhen. In ähnlicher Weise wird über StatefulSet auch ein Alertmanager bereitgestellt, für dessen Fehlertoleranz mindestens 3 Pods erforderlich sind (da ein Quorum erforderlich ist, um Entscheidungen über das Senden von Alerts zu treffen).
Was fehlt hier? ..
Föderation für Prometheus
Wenn Daten alle 30 (oder 60) Sekunden erfasst werden, endet der Speicherort sehr schnell, und noch schlimmer, es sind viele Rechenressourcen erforderlich (beim Empfangen und Verarbeiten einer so großen Anzahl von Punkten von TSDB). Wir möchten jedoch Informationen für
große und e Zeitintervalle speichern und herunterladen können. Wie erreicht man das?
Es reicht aus, dem allgemeinen Schema, in dem Service Discovery deaktiviert ist,
eine weitere Installation von Prometheus (wir nennen es
langfristig ) hinzuzufügen, und in der Zieltabelle gibt es den einzigen statischen Datensatz, der zum Haupt-Prometheus (
main ) führt.
Dies ist dank des Verbunds möglich : Mit Prometheus können Sie die neuesten Werte aller Metriken in einer einzigen Abfrage zurückgeben. Somit funktioniert die erste Installation von Prometheus weiterhin (Zugriff alle 60 oder beispielsweise 30 Sekunden) auf alle Ziele im Kubernetes-Cluster, und die zweite - alle 5 Minuten - empfängt Daten von der ersten und speichert sie, um Daten für einen langen Zeitraum überwachen zu können ( aber ohne tiefes Detail).
 Für die zweite Prometheus-Installation ist keine Serviceerkennung erforderlich, und die Zieltabelle besteht aus einer Zeile
Für die zweite Prometheus-Installation ist keine Serviceerkennung erforderlich, und die Zieltabelle besteht aus einer Zeile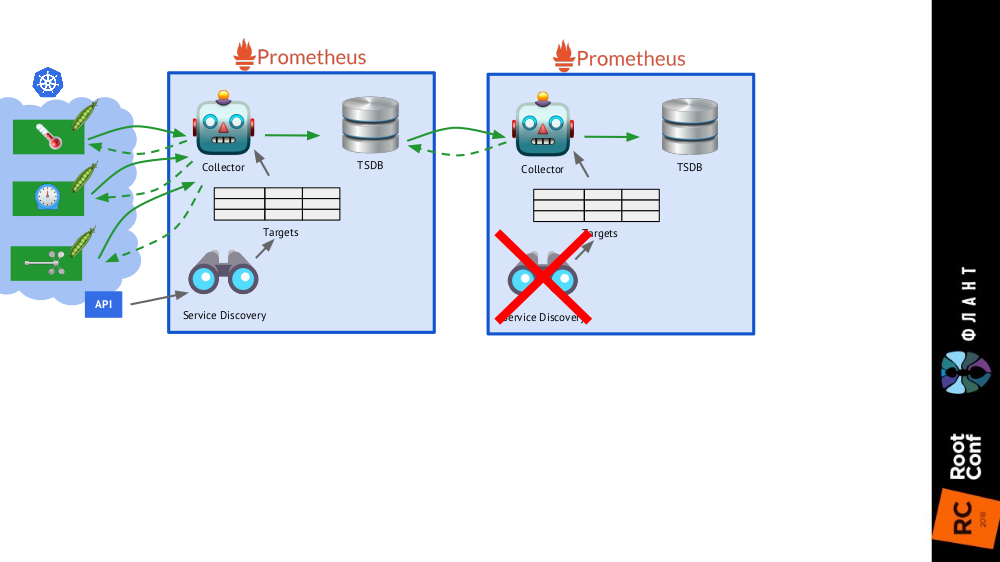 Das ganze Bild mit Prometheus-Installationen von zwei Arten: Haupt (oben) und Langzeit
Das ganze Bild mit Prometheus-Installationen von zwei Arten: Haupt (oben) und LangzeitDer letzte Schliff besteht darin
, Grafana mit beiden Prometheus-Installationen zu verbinden und auf besondere Weise Dashboards zu erstellen, damit Sie zwischen Datenquellen (
Haupt- oder
Langzeitdaten ) wechseln können. Ersetzen Sie dazu mithilfe der Vorlagen-Engine in allen Bedienfeldern die Variable
$prometheus anstelle der Datenquelle.
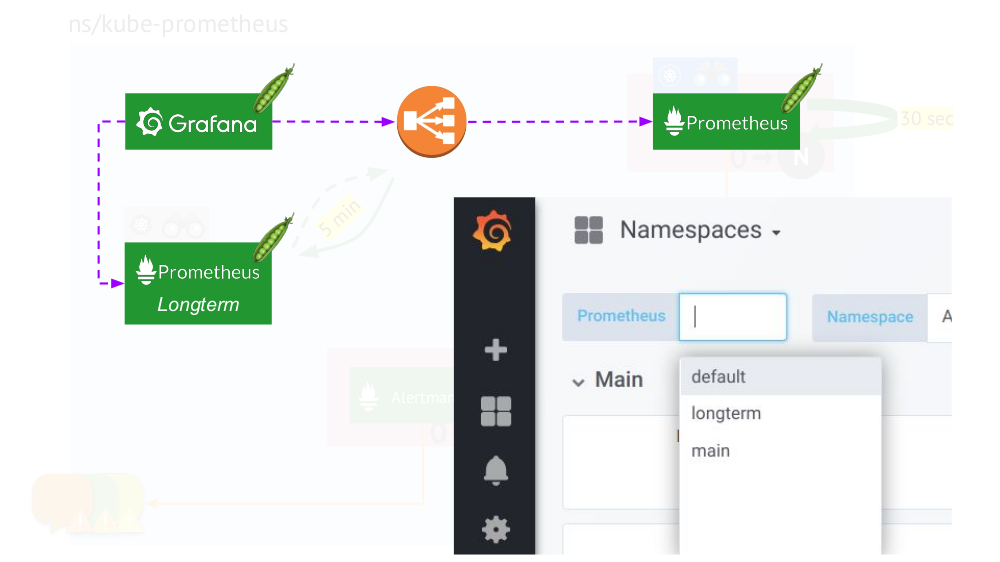
Was ist sonst noch in den Grafiken wichtig?
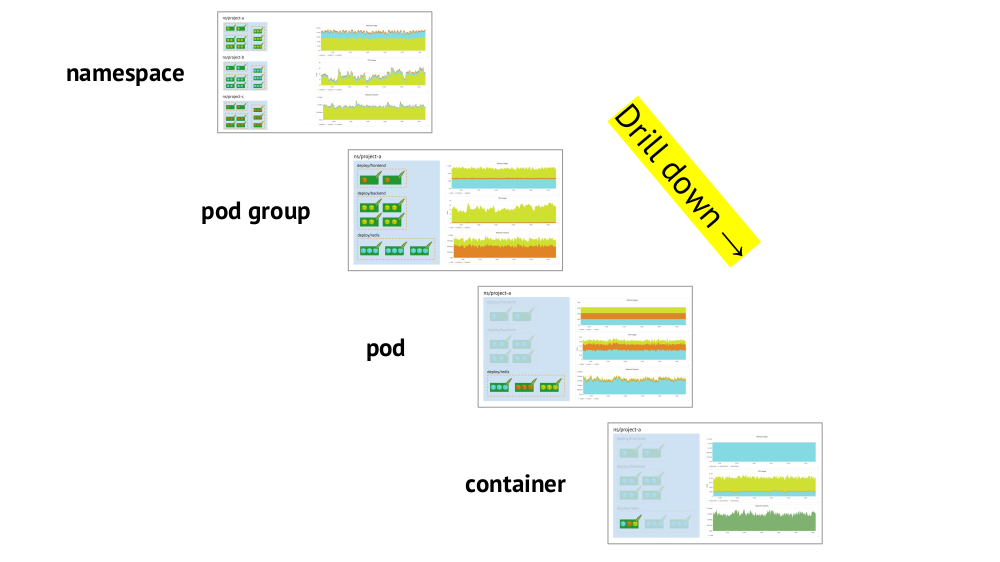
Zwei wichtige Punkte, die beim Organisieren von Zeitplänen berücksichtigt werden müssen, sind die Unterstützung von Kubernetes-Grundelementen und die Möglichkeit, schnell vom Gesamtbild (oder einer niedrigeren "Ansicht") zu einem bestimmten Dienst zu gelangen und umgekehrt.
Die Unterstützung für Grundelemente (Namespaces, Pods usw.) wurde bereits erwähnt - dies ist im Prinzip eine notwendige Voraussetzung für ein komfortables Arbeiten in der Realität von Kubernetes. Und hier ist ein Beispiel zum Drilldown:
- Wir betrachten die Diagramme des Ressourcenverbrauchs von drei Projekten (d. H. Drei Namespaces) - wir sehen, dass der Hauptteil der CPU (oder des Speichers oder des Netzwerks, ...) auf Projekt A fällt.
- Wir sehen uns die gleichen Grafiken an, aber bereits für die Dienste von Projekt A: Welche davon verbraucht die meiste CPU?
- Wir wenden uns den Diagrammen des gewünschten Dienstes zu: Welcher Pod ist „schuld“?
- Wir wenden uns den Diagrammen des gewünschten Pods zu: Welcher Container ist "schuld"? Das ist das gewünschte Ziel!
Zusammenfassung
- Geben Sie genau an, was Überwachung ist. (Lassen Sie sich von der „dreischichtigen Torte“ daran erinnern ... und daran, dass es auch ohne Kubernetes nicht einfach ist, sie kompetent zu backen!)
- Denken Sie daran, dass Kubernetes obligatorische Details hinzufügt: Zielgruppierung, Serviceerkennung, große Datenmengen, Metadatenfluss. Darüber hinaus:
- ja, einige von ihnen werden auf magische Weise ("out of the box") in Prometheus gelöst;
- Es bleibt jedoch noch ein weiterer Teil, der unabhängig und sorgfältig überwacht werden muss.
Und denken Sie daran, dass
Inhalte wichtiger sind als ein System , d. H. Richtige Diagramme und Warnungen sind primär und nicht Prometheus (oder eine andere ähnliche Software) als solche.

Videos und Folien
Video von der Aufführung (ca. eine Stunde):
Präsentation des Berichts:
PS
Weitere Berichte in unserem Blog:
Sie könnten auch an folgenden Veröffentlichungen interessiert sein: