Grüße an die angesehene Community!
Wiederholung ist die Mutter des Lernens, und das Verstehen des Parsens ist eine sehr nützliche Fähigkeit für jeden Programmierer. Deshalb möchte ich dieses Thema noch einmal ansprechen und dieses Mal über die Analyse rekursiver Abstammung (LL) sprechen, ohne zu viel Formalismus zu betreiben (Sie können sie später jederzeit verwenden komm zurück).
Wie der große D. Strogov schreibt: "Verstehen heißt vereinfachen." Um das Konzept des Parsens mit der rekursiven Abstiegsmethode (auch bekannt als LL-Parsing) zu verstehen, vereinfachen wir die Aufgabe so weit wie möglich und schreiben manuell einen Parser in einem JSON-ähnlichen, aber einfacheren Format (wenn Sie möchten, können Sie ihn dann zu einem vollwertigen JSON-Parser erweitern, wenn trainieren wollen). Schreiben wir es auf der Grundlage der Idee
, die Schnur zu schneiden .
In klassischen Büchern und Compiler-Design-Kursen beginnen sie normalerweise, das Thema Parsen und Interpretieren zu erklären, wobei mehrere Phasen hervorgehoben werden:
- Lexikalische Analyse: Aufteilen des Quelltextes in eine Reihe von Teilzeichenfolgen (Token oder Token)
- Parsing: Erstellen eines Parsing-Baums aus einer Reihe von Token
- Interpretation (oder Kompilierung): Durchlaufen des resultierenden Baums in der gewünschten (direkten oder umgekehrten) Reihenfolge und Ausführen einiger Interpretations- oder Codegenerierungsaktionen in einigen Schritten dieser Durchquerung
nicht wirklich soDa wir beim Parsen bereits eine Folge von Schritten erhalten, dh eine Folge von Besuchen von Baumknoten, existiert der Baum selbst in expliziter Form möglicherweise überhaupt nicht, aber wir werden noch nicht tief gehen. Für diejenigen, die tiefer gehen wollen, gibt es am Ende Links.
Jetzt möchte ich einen etwas anderen Ansatz für dasselbe Konzept (LL-Analyse) verwenden und zeigen, wie Sie einen LL-Analysator basierend auf der Idee des Schneidens einer Zeichenfolge erstellen können: Fragmente werden während der Analyse aus der ursprünglichen Zeichenfolge herausgeschnitten, sie wird kleiner und dann analysiert den Rest der Linie ausgesetzt. Infolgedessen kommen wir zu demselben Konzept des rekursiven Abstiegs, jedoch auf etwas andere Weise als gewöhnlich. Vielleicht ist dieser Weg bequemer, um das Wesentliche der Idee zu verstehen. Und wenn nicht, dann ist es immer noch eine Gelegenheit, einen rekursiven Abstieg aus einem anderen Blickwinkel zu betrachten.
Beginnen wir mit einer einfacheren Aufgabe: Es gibt eine Zeile mit Trennzeichen, und ich möchte eine Iteration über deren Werte schreiben. So etwas wie:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
Wie kann das gemacht werden? Die Standardmethode besteht darin, die begrenzte Zeichenfolge mit String.split (in Java) oder names.split (",") (in Javascript) in ein Array oder eine Liste zu konvertieren und das Array bereits zu durchlaufen. Stellen wir uns jedoch vor, wir möchten oder können die Konvertierung in ein Array nicht verwenden (zum Beispiel plötzlich, wenn wir in der Programmiersprache AVAJ ++ programmieren, in der es keine "Array" -Datenstruktur gibt). Sie können die Zeichenfolge weiterhin scannen und die Trennzeichen verfolgen, aber ich werde diese Methode auch nicht verwenden, da sie den Iterationsschleifencode umständlich macht und vor allem dem Konzept widerspricht, das ich zeigen möchte. Daher beziehen wir uns auf eine begrenzte Zeichenfolge genauso wie auf Listen in der funktionalen Programmierung. Und dort definieren sie immer die Funktionen head (das erste Element der Liste abrufen) und tail (den Rest der Liste abrufen). Ausgehend von den ersten Dialekten von Lisp, in denen diese Funktionen absolut schrecklich und unintuitiv genannt wurden: Auto und CDR (Auto = Inhalt des Adressregisters, CDR = Inhalt des Dekrementregisters. Die Legenden der alten Zeit sind tief, ja, eheheh.).
Unsere Linie ist eine begrenzte Linie. Markieren Sie die Trennwände in lila:
Und markieren Sie die Listenelemente in Gelb:

Wir nehmen an, dass unsere Zeile veränderlich ist (sie kann geändert werden) und schreiben eine Funktion:
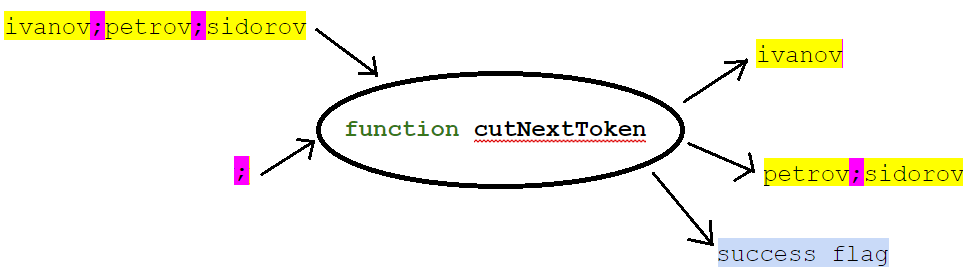
Ihre Unterschrift könnte zum Beispiel sein:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
Zur Eingabe der Funktion geben wir eine Liste (in Form einer Zeichenfolge mit Trennzeichen) und tatsächlich den Wert des Trennzeichens an. Am Ausgang gibt die Funktion das erste Element der Liste (Liniensegment zum ersten Trennzeichen), den Rest der Liste und das Vorzeichen zurück, ob das erste Element zurückgegeben wurde. In diesem Fall wird der Rest der Liste in dieselbe Variable wie die ursprüngliche Liste gestellt.
Als Ergebnis hatten wir die Möglichkeit, folgendermaßen zu schreiben:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
Ergebnisse wie erwartet:
ivanov
petrov
sidorov
Wir haben auf die Konvertierung in ArrayList verzichtet, aber die Variable names verwöhnt, und jetzt hat sie eine leere Zeichenfolge. Es sieht noch nicht sehr nützlich aus, als hätten sie die Ahle gegen Seife ausgetauscht. Aber gehen wir weiter. Dort werden wir sehen, warum es notwendig war und wohin es uns führen wird.
Lassen Sie uns nun etwas Interessanteres analysieren: eine Liste von Schlüssel-Wert-Paaren. Dies ist auch eine sehr häufige Aufgabe.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
Fazit:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
Auch erwartet. Und das Gleiche kann mit String.split erreicht werden, ohne die Linien zu schneiden.
Nehmen wir an, wir wollten jetzt unser Format komplizieren und von einem flachen Schlüsselwert zu einem verschachtelbaren Format übergehen, das an JSON erinnert. Jetzt wollen wir so etwas lesen:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
Welches Trennzeichen wird geteilt? Wenn es ein Komma ist, haben wir in einem der Token die Zeile
'birthdate':{'year':'1984'
Offensichtlich nicht das, was wir brauchen. Daher müssen wir auf die Struktur der Linie achten, die wir analysieren möchten.
Es beginnt mit einer geschweiften Klammer und endet mit einer geschweiften Klammer (gepaart damit, was wichtig ist). In diesen Klammern befindet sich eine Liste der Paare 'Schlüssel': 'Wert', wobei jedes Paar durch ein Komma vom nächsten Paar getrennt ist. Der Schlüssel und der Wert werden durch einen Doppelpunkt getrennt. Ein Schlüssel ist eine Buchstabenfolge, die in Apostrophen eingeschlossen ist. Der Wert kann eine Zeichenfolge sein, die in Apostrophen eingeschlossen ist, oder er kann dieselbe Struktur haben, die mit gepaarten geschweiften Klammern beginnt und endet. Wir nennen eine solche Struktur das Wort "Objekt", wie es in JSON üblich ist.
Wir haben nur informell die Grammatik unseres JSON-ähnlichen Formats beschrieben. Typischerweise werden Grammatiken in umgekehrter, formaler Form beschrieben, und die BNF-Notation oder ihre Variationen werden verwendet, um sie zu schreiben. Aber jetzt kann ich darauf verzichten, und wir werden sehen, wie Sie diese Zeile "ausschneiden" können, damit sie gemäß den Regeln dieser Grammatik analysiert werden kann.
Tatsächlich beginnt unser „Objekt“ mit einer öffnenden geschweiften Klammer und endet mit einem Paar, das es schließt. Was kann eine Funktion, die ein solches Format analysiert, tun? Höchstwahrscheinlich Folgendes:
- Stellen Sie sicher, dass die übergebene Zeichenfolge mit einer öffnenden Klammer beginnt
- Stellen Sie sicher, dass die übergebene Zeichenfolge mit einem Paar schließender Klammern endet
- Wenn beide Bedingungen erfüllt sind, schneiden Sie die öffnenden und schließenden Klammern ab und übergeben Sie die verbleibenden Funktionen an die Funktion, die die Liste der Paare 'key': 'value' analysiert.
Bitte beachten Sie: Die Wörter "Funktion zum Parsen dieses Formats" und "Funktion zum Parsen der Liste der Paare 'Schlüssel': 'Wert'" wurden angezeigt. Wir haben zwei Funktionen! Dies sind genau die Funktionen, die in der klassischen Beschreibung des rekursiven Abstiegsalgorithmus als "Analysefunktionen nichtterminaler Symbole" bezeichnet werden und die besagen, dass "für jedes nichtterminale Symbol eine eigene Analysefunktion erstellt wird". Was es tatsächlich analysiert. Wir könnten sie beispielsweise parseJsonObject und parseJsonPairList nennen.
Auch jetzt müssen wir darauf achten, dass wir zusätzlich zum Konzept des „Separators“ das Konzept der „Paarklammer“ haben. Wenn wir eine Zeile zum nächsten Trennzeichen schneiden möchten (ein Doppelpunkt zwischen einem Schlüssel und einem Wert, ein Komma zwischen den Paaren „Schlüssel: Wert“), hat uns die Funktion cutNextToken gereicht, da wir jetzt nicht nur eine Zeichenfolge, sondern auch ein Objekt verwenden können, das wir benötigen Funktion „Auf das nächste Klammerpaar schneiden“. So etwas wie das:

Diese Funktion schneidet ein Fragment von der Linie von der öffnenden Klammer zu dem Paar, das es schließt, unter Berücksichtigung der Klammern, falls vorhanden. Natürlich können Sie nicht auf Klammern beschränkt sein, sondern verwenden eine ähnliche Funktion, um verschiedene Blockstrukturen abzuschneiden, die verschachtelt werden können: Operatorblöcke beginnen..end, if..endif, for..endfor und ähnliche.
Lassen Sie uns grafisch zeichnen, was mit der Zeichenfolge passieren wird. Türkisfarbe - Dies bedeutet, dass wir die Linie vorwärts zu dem in Türkis hervorgehobenen Symbol scannen, um zu bestimmen, was als nächstes zu tun ist. Violett ist „was abgeschnitten werden soll. In diesem Fall schneiden wir die in Violett hervorgehobenen Fragmente von der Linie ab und analysieren weiter, was davon übrig bleibt.

Zum Vergleich die Ausgabe des Programms (der Programmtext ist im Anhang angegeben), das diese Zeile analysiert:
Demonstration der Analyse der JSON-ähnlichen Struktur
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
Wir wissen jederzeit, was wir in unserer Eingabezeile erwarten. Wenn wir die Funktion parseJsonObject eingegeben haben, erwarten wir, dass das Objekt dort an uns übergeben wurde, und wir können dies durch das Vorhandensein der öffnenden und schließenden Klammern am Anfang und am Ende überprüfen. Wenn wir die Funktion parseJsonPairList eingegeben haben, erwarten wir dort eine Liste von "Schlüssel: Wert" -Paaren, und nachdem wir den Schlüssel "abgebissen" haben (vor dem Trennzeichen ":"), erwarten wir, dass das nächste, was wir "abbeißen", ist Wert. Wir können uns das erste Zeichen des Werts ansehen und eine Schlussfolgerung über seinen Typ ziehen (wenn das Apostroph, dann ist der Wert vom Typ "Zeichenfolge", wenn die öffnende geschweifte Klammer der Wert vom Typ "Objekt" ist).
Wenn wir also Fragmente von der Zeichenfolge abschneiden, können wir sie mit der Methode der Top-Down-Analyse (rekursiver Abstieg) analysieren. Und wenn wir analysieren können, können wir das Format analysieren, das wir benötigen. Oder erstellen Sie Ihr eigenes Format, das für uns geeignet ist, und zerlegen Sie es. Oder erstellen Sie eine domänenspezifische Sprache (Domain Specific Language, DSL) für unseren speziellen Bereich und entwerfen Sie einen Dolmetscher dafür. Und um es richtig zu konstruieren, ohne gequälte Lösungen auf regulären Ausdrücken oder selbst erstellten Zustandsmaschinen, die für Programmierer entstehen, die versuchen, ein Problem zu lösen, das analysiert werden muss, aber das Material nicht ganz besitzen.
Hier. Herzlichen Glückwunsch an alle zum kommenden Sommer und alles Gute, Liebe und funktionale Parser :)
Zur weiteren Lektüre:
Ideologisch: ein paar lange, aber lesenswerte Artikel von Steve Yeegge:
Reichhaltiges ProgrammiereressenEin paar Zitate von dort:
Sie lernen entweder Compiler und beginnen, Ihre eigenen DSLs zu schreiben, oder Sie lernen eine bessere Sprache
Die erste große Phase der Kompilierungspipeline ist das Parsen
Das Pinocchio-ProblemZitat von dort:
Typumwandlungen, Eingrenzen und Erweitern von Konvertierungen, Friend-Funktionen zum Umgehen des Standardklassenschutzes, Füllen von Minisprachen in Zeichenfolgen und Parsen von Hand . Es gibt Dutzende von Möglichkeiten, die Typsysteme in Java und C ++ zu umgehen, und Programmierer verwenden sie ständig , weil sie (wenig wissen sie) tatsächlich versuchen, Software zu erstellen, nicht Hardware.
Technisch: zwei Artikel zum Parsen über den Unterschied zwischen LL- und LR-Ansätzen:
LL und LR Parsing entmystifiziertLL und LR im Kontext: Warum Parsing-Tools schwierig sindUnd noch tiefer in das Thema: Wie schreibe ich einen Lisp-Interpreter in C ++?
Lisp-Interpreter in 90 Zeilen C ++Anwendung. Beispielcode (Java), der den im Artikel beschriebenen Analysator implementiert: package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {