 Gepostet von Igor Masternaya, Senior Developer, Community Leader von DataArt Java
Gepostet von Igor Masternaya, Senior Developer, Community Leader von DataArt JavaVom 18. bis 19. Mai fand in Kiew die JEEonf statt, eine der am meisten erwarteten Veranstaltungen für die gesamte osteuropäische Java-Community. DataArt war Partner der Konferenz. Referenten aus der ganzen Welt sprachen auf vier Bühnen: Volker Simonis, SAP-Vertreter bei
JCP und OpenJDK-Mitarbeiter, Jürgen Höller, Pivotal Chief Engineer, Vater des geliebten Spring Framework, Klaus Ibsen, Erfinder von Apache Camel, und Hugh McKee, Evangelist bei Lightbend.
Der Zeitplan war sehr voll: an zwei Tagen mehr als 50 Vorstellungen, jeweils 45 Minuten. 10 Minuten Pause - und zu einem neuen Bericht laufen. Es wird lange dauern, bis alle Videos im Netzwerk angezeigt werden. Daher werde ich kurz die Berichte beschreiben, die ich am interessantesten fand und die ich persönlich besuchte.
15 Jahre Frühling
Die Konferenz wurde von Jürgen Höller eröffnet. Er sprach über die 15-jährige (!) Geschichte des Spring Frameworks, von den „bevorzugten“ XML-Konfigurationen in Version 0.9 bis zum reaktiven Spring WebFlux, der aus Forschungsprojekten hervorging, die vom
Reactive Manifesto beeinflusst wurden. Jürgen sprach über die Koexistenz von Spring MVC und Spring WebFlux im Frühjahr WEB und erklärte, warum sie beschlossen, sie nicht zu integrieren. Der Punkt ist, dass die Hauptabstraktion von Spring MVC Servlet API 3.0 und blockierende E / A ist, während Spring WebFlux die Abstraktion von reaktiven Streams und nicht blockierenden E / A verwendet. Sie können Ihren Dienst unter SpringWebFlux auf jedem Server ausführen, der nicht blockierende E / A unterstützt: Netty, neue Versionen von Tomcat (> 8.5), Jetty. Das Erstellen reaktiver WebFlux-Controller unterscheidet sich nicht wesentlich vom Erstellen mit Spring MVC, es gibt jedoch immer noch Unterschiede. Der reaktive Controller verarbeitet eine Benutzeranforderung nicht im üblichen Sinne, sondern erstellt eine Pipeline zur Verarbeitung der Anforderung. Der Dispatcher ruft die Controller-Methode auf, die eine Pipeline erstellt und diese sofort als Publisher-Stream bereitstellt. Der Publisher-Stream in Reactive Spring wird als zwei Abstraktionen dargestellt: Flux / Mono. Flux gibt einen Strom von Objekten zurück, während Mono immer ein einzelnes Objekt zurückgibt.
Jürgen erwähnte auch die Bequemlichkeit der Verwendung von Java 8-Stil bei der Arbeit mit Spring 5.0 und versprach einen Release-Kandidaten Spring 5.1 im Juli 2018 und ein Release im September, das Java 11 unterstützen und an der Feinabstimmung der neuen Spring 5.0-Funktionen arbeiten wird
Python / Java-Integration
Es gab viele Berichte, und es war schwierig, den interessantesten im nächsten Slot auszuwählen. Die Beschreibungen waren ebenso interessant, also vertraute ich meinen Instinkten und beschloss, Tamas Rozman, dem Vizepräsidenten von BlackRock aus Ungarn, zuzuhören. Aber es wäre besser, wenn ich noch einmal über Events Sourcing und CQRS hören würde. Nach der Beschreibung ist das Unternehmen in Data Science für einen großen Investmentfonds tätig. Der Bericht sollte zeigen, wie sie ein skalierbares, stabiles System erstellt haben, das sowohl für Datenanalysten mit ihrem Python als auch für Java-Entwickler des Hauptsystems geeignet ist. Es schien mir jedoch zweifelhaft, dass sich das konstruierte System wirklich als praktisch herausstellte. Um sich mit Python und Java anzufreunden, hatten die Ingenieure von BlackRock die Idee, einen Python-Interpreter als Prozess aus einer Java-Anwendung heraus zu starten. Sie kamen aus mehreren Gründen dazu:
- Jython (Python in der JVM) passte aufgrund veralteter Codebasis 2.7 gegenüber CPython 3.6 nicht.
- Sie betrachteten die Option, die Logik von Data Science in Java neu zu schreiben, als zu langen Prozess.
- Apache Spark hat beschlossen, es nicht zu verwenden, da Sie, wie der Redner erklärte, keine in Java und Python geschriebenen Workloads mischen können. Obwohl nicht klar ist, warum UDF und UDFA nicht passten [ 2 ]. Außerdem passte Spark nicht, weil sie bereits einen Jobrahmen hatten und nicht wirklich einen neuen einführen wollten. Wie sich herausstellte, verfügen sie auch nicht über Big Data, und die gesamte Verarbeitung erfolgt über Statistiken zu erbärmlichen 100-MB-Dateien.
Die Kommunikation von Java mit dem Python-Prozess wurde mithilfe von Speicherzuordnungsdateien (eine Datei wird als Eingabedatendatei verwendet) und Befehlen (die zweite Datei ist die Ausgabe des Python-Prozesses) organisiert. Kommunikation war also etwas in Form von:
Java: calcExr | 1 + javaFunc (sqrt (36))
Python: 1 + javaFunct | 6
Java: 1 + Erfolg | 64
Python: Erfolg | 65
Die Hauptprobleme einer solchen Integration nannte Tamas den Overhead während der Serialisierung und Deserialisierung von Eingabe- / Ausgabeparametern.

Java 10 App CDS
Nach einer Präsentation über die Feinheiten des Ausführens von Python wollte ich unbedingt etwas zutiefst Technisches aus der Java-Welt hören. Also ging ich zu dem Bericht von Volker Simonis, in dem er über die Datenfreigabefunktion der Anwendungsklasse von
Java 10+ sprach. In der modernen Welt, die auf Microservices in Docker basiert, beschleunigt die gemeinsame Nutzung von Java Codecache und Metaspace den Start der Anwendung und spart Speicherplatz. Das Bild zeigt die Ergebnisse des Starts von Docker-Tomaten mit einem gemeinsam genutzten Archiv von Tomcat-Klassen. Wie Sie sehen können, sind beim zweiten Prozess einige Seiten im Speicher bereits als shared_clean markiert. Dies bedeutet, dass der aktuelle und mindestens ein Prozess (der zweite laufende Tomcat) auf sie verweist.

Details zum Spielen mit CDS in OpenJDK 10 finden Sie unter:
App CDS . Neben der Aufteilung der Anwendungsklassen auf Prozesse ist in Zukunft geplant, internierte Zeichenfolgen im
JEP-250 gemeinsam zu nutzen .
Hauptbeschränkungen von AppCDS:
Funktioniert nicht mit Klassen bis 1.5.
- Sie können keine aus Dateien geladenen Klassen verwenden (nur .jar-Archive).
- Vom Klassenladeprogramm geänderte Klassen können nicht verwendet werden.
- Von mehreren Klassenladeprogrammen geladene Klassen können nur einmal wiederverwendet werden.
- Das Umschreiben von Bytecode funktioniert nicht, was zu Leistungseinbußen von bis zu 2% führen kann. JDK-8074345

Pipeline zur Verarbeitung natürlicher Sprache mit Apache Spark
Der Bericht über NLP und Apache Spark wurde von Vitaliy Kotlyarenko - Ingenieur von Grammarly - präsentiert. Vitaliy zeigte, wie Grammatik-Prototypen NLP-Jobs auf Apache Zeppelin. Ein Beispiel war der Aufbau einer einfachen Pipeline für die thematische Modellierung basierend auf dem
LDA- Algorithmus des
gemeinsamen Crawling- Internetarchivs. Die Ergebnisse der Themenmodellierung wurden verwendet, um Websites mit unangemessenem Inhalt als Beispiel für die Kindersicherungsfunktion zu filtern. Zum Erstellen der Pipeline haben wir Terraform-Skripts und
AWS EMR Spark-Cluster verwendet, mit denen Sie Spark-Cluster mit YARN in Amazon bereitstellen können. Schematisch sieht die Pipeline folgendermaßen aus:
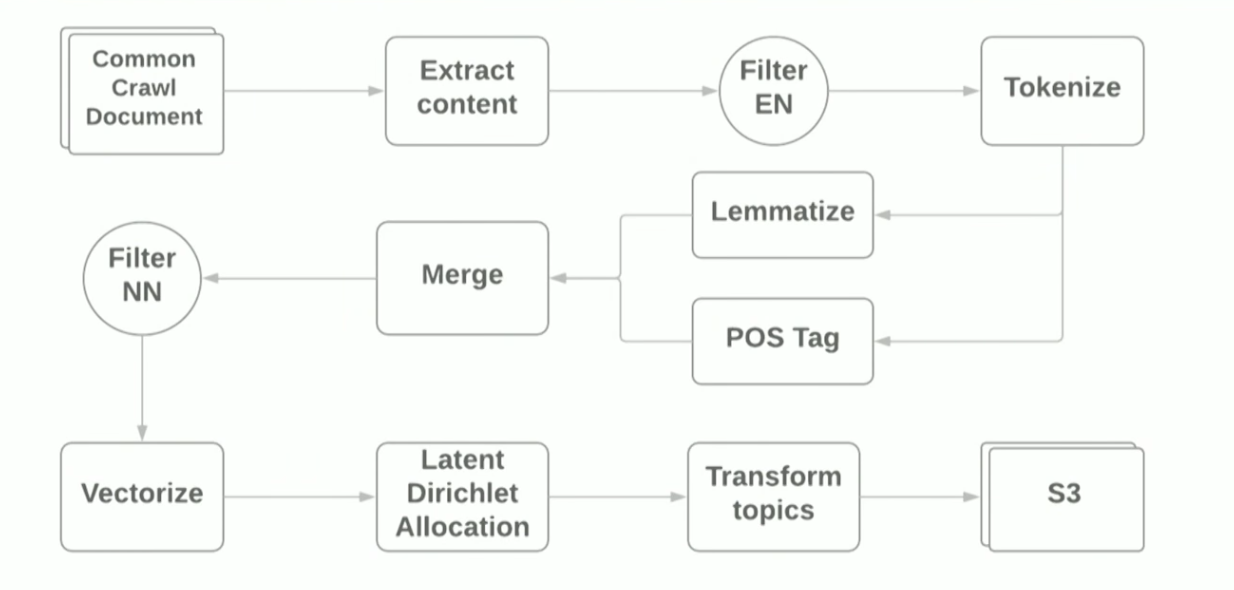
Der Zweck des Berichts war es zu zeigen, dass die Verwendung moderner Frameworks zur Erstellung eines Prototyps für ML-Aufgaben recht einfach ist. Bei Verwendung von Standardbibliotheken treten jedoch immer noch Schwierigkeiten auf. Zum Beispiel:
- Beim ersten Schritt des Lesens von WARC-Dateien mithilfe der HadoopInputFormat- Bibliothek stürzten IllegalStateExceptions manchmal aufgrund falscher Dateikopfzeilen ab. Die Bibliothek musste neu geschrieben und falsche Dateien übersprungen werden.
- Die Abhängigkeiten von Guave - der Sprachdefinitionsbibliothek - kollidierten mit den Abhängigkeiten, die Spark auf sich selbst zieht. Java 8 half, mit dessen Hilfe es möglich war, Abhängigkeiten von Guave in die verwendete Bibliothek zu werfen.
Während der Demo haben wir die Ausführung des Jobs mithilfe der Standard-Spark-Benutzeroberfläche und des Überwachungssubsystems
Ganglia überwacht, das bei der Bereitstellung in AWS EMR automatisch verfügbar ist. Der Autor konzentrierte sich auf die Heatmap-Server-Lastverteilung, die die Lastverteilung zwischen den Knoten im Cluster zeigt, und gab allgemeine Ratschläge zur Optimierung der Arbeit von Spark Job: Erhöhen der Anzahl der Partitionen, Optimieren der Datenserialisierung, Analysieren von GC-Protokollen. Weitere Informationen zur Optimierung von Spark-Jobs finden Sie
hier . Die Quelldateien für die Demo finden Sie im
Github des Autors des Berichts.
Graal, Trüffel, SubstrateVM und andere Vorteile: Was sind das und warum brauchen Sie sie?
Am meisten erwartet wurde für mich ein Bericht von Oleg Chirukhin von JUG.ru. Er erzählte, wie man den fertigen Code mit dem Gral optimiert. Was ist der Gral? Grail ist eine Marke von
Oracle Labs , die den JIT-Compiler (Just-in-Time), das Framework zum Schreiben von DSL-Sprachen - Truffle - und die spezielle JVM (
SubstrateVM ) - eine universelle virtuelle Maschine mit
geschlossener Welt , für die Sie in JavaScript schreiben können. Ruby, Python, Java, Scala. Der Bericht konzentrierte sich auf den JIT-Compiler und seine Tests in der Produktion.
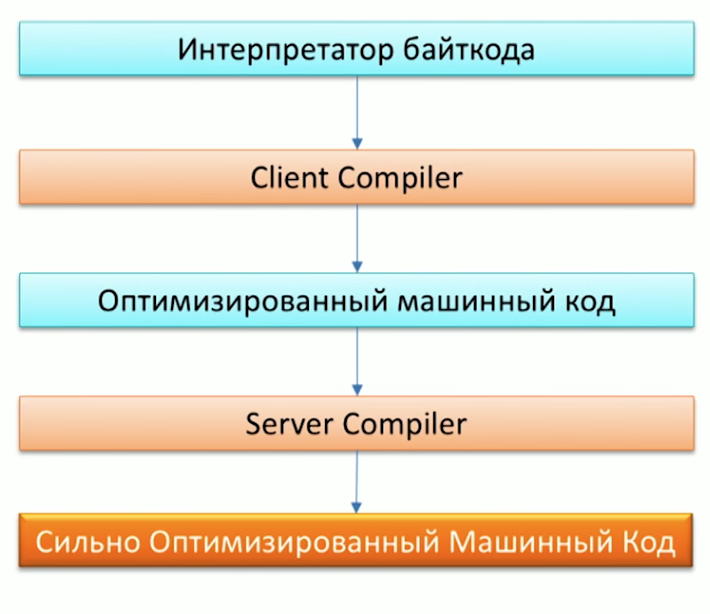
Erinnern Sie sich zunächst an den Prozess der Ausführung von Code auf dem Java-Computer und beachten Sie, dass Java bereits zwei Compiler hat: C1 (Client-Compiler) und C2 (Server-Compiler). Grail kann als C2-Compiler verwendet werden.
Auf die Frage, warum wir einen anderen Compiler benötigen, antwortete einer der Mitarbeiter von Oracle Labs, Dr. Chris Seaton, im Artikel „
Verstehen, wie Graal funktioniert“ sehr gut. Kurz gesagt, die ursprüngliche Idee des Graal-Projekts sowie des
Metropolis- Projekts besteht darin, Teile des in C ++ in Java geschriebenen JVM-Codes neu zu schreiben. Dies wird es in Zukunft ermöglichen, den Code bequem zu ergänzen. Eine der Optimierungen - P
artial Escape Analysis - befindet sich beispielsweise bereits im Grail, jedoch nicht im Hotspot,
da das Erweitern des Grail-Codes viel einfacher ist als der C2-Code .
Das hört sich toll an, aber wie wird das in meinem Projekt in der Praxis funktionieren, fragen Sie? Gral eignet sich für Projekte:
- Welche viel Müll, viele kleine Objekte schaffen.
- Geschrieben im Stil von Java 8, mit einer Reihe von Streams und Lambdas.
- Verwendung verschiedener Sprachen: Ruby, Java, R.
Als einer der ersten in der Produktion wurde der Gral auf Twitter verwendet. Mehr dazu lesen Sie in einem auf Habré veröffentlichten Interview mit Christian Talinger (
interview_1 und
interview_2 ). Dort erklärt er, dass Twitter durch das Ersetzen von C2 durch Graal etwa 8% der CPU-Auslastung einsparte, was angesichts der Größe des Unternehmens ziemlich gut ist.
Auf der Konferenz konnten wir auch die Geschwindigkeit von Graal überprüfen, indem wir einen der Scala-Benchmarks darunter starteten -
Scala DaCapo . Infolgedessen bestand der Benchmark auf Graal in ~ 7000 ms und auf einer regulären JVM in ~ 14000 ms! Warum dies passiert ist, können Sie anhand der gclog-Tests sehen. Die Anzahl der Zuordnungsfehler bei Verwendung von Graal ist erheblich geringer als die von Hotspot. Sie können jedoch immer noch nicht sagen, dass der Grail die Lösung für die Leistungsprobleme Ihrer Java-Anwendung sein wird. Oleg zeigte in seinem Bericht auch eine Fehlergeschichte, in der er die Arbeit von
Apache Ignite unter dem Gral und ohne sie verglich - es gab keine merkliche Leistungsänderung.

Entwerfen fehlertoleranter Microservices
Ein weiterer Bericht über die ausfallsichere Microservice-Architektur wurde von Orkhan Gasimov von AppsFlyer gelesen. Er führte beliebte Entwurfsmuster für die Erstellung verteilter Anwendungen ein. Wir kennen vielleicht viele von ihnen, aber herumlaufen und sich an jeden von ihnen erinnern, wird überhaupt nicht schaden.
Die Hauptprobleme der Fehlertoleranz von Diensten, mit denen die im Bericht beschriebenen Muster bekämpft werden sollen, sind: Netzwerk, Spitzenlasten, RPC-Kommunikationsmechanismen zwischen Diensten.
Um Probleme mit dem Netzwerk zu lösen, wenn einer der Dienste nicht mehr verfügbar ist, müssen wir ihn schnell durch einen anderen ersetzen können. In der Praxis kann dies mit mehreren Instanzen desselben Dienstes und einer Beschreibung alternativer Pfade zu diesen Instanzen erreicht werden, bei denen es sich um ein Diensterkennungsmuster handelt. Die Teilnahme an
Heartbeat- Diensten und die Registrierung neuer Dienste erfolgt in einer separaten Instanz - der Dienstregistrierung. Es ist üblich, den bekannten
Zookeeper oder
Konsul als Serviceregistrierung zu verwenden. Die wiederum einen verteilten Charakter haben und die Fehlertoleranz unterstützen.
Nachdem wir die Probleme mit dem Netzwerk gelöst haben, wenden wir uns dem Problem der Spitzenlasten zu, wenn einige Dienste unter Last stehen und Anforderungen viel langsamer verarbeiten als im regulären Modus. Um dies zu lösen, können Sie das
automatische Skalierungsmuster verwenden . Er wird nicht nur die Aufgabe übernehmen, hoch ausgelastete Dienste automatisch zu skalieren, sondern auch die Instanzen nach der Spitzenlastzeit zu stoppen.
Das letzte Kapitel des Berichts des Autors war eine Beschreibung möglicher Probleme der internen RPC-Kommunikation zwischen Diensten. Urahan widmete der These "Der Benutzer sollte nicht lange auf eine Fehlermeldung warten" besondere Aufmerksamkeit. Eine solche Situation kann auftreten, wenn seine Anfrage von der Servicekette verarbeitet wird und das Problem am Ende der Kette liegt: Dementsprechend kann der Benutzer warten, bis die Anfrage von jedem der Services in der Kette verarbeitet wird, und erhält erst in der letzten Phase einen Fehler. Am schlimmsten ist es, wenn der Enddienst überlastet ist und der Client nach langem Warten einen bedeutungslosen HTTP-FEHLER erhält: 500.
Um solchen Situationen entgegenzuwirken, können Sie Timeouts verwenden. Anforderungen, die noch korrekt verarbeitet werden können, können jedoch in das Timeout fallen. Dazu kann die Timeout-Logik kompliziert sein und ein spezieller Schwellenwert für die Anzahl der Servicefehler pro Zeitintervall hinzugefügt werden. Wenn die Anzahl der Fehler den Schwellenwert überschreitet, verstehen wir, dass der Dienst unter Last steht, und betrachten ihn als nicht verfügbar, sodass er die erforderliche Zeit hat, um aktuelle Aufgaben zu erledigen. Dieser Ansatz beschreibt das Leistungsschaltermuster. Sie können CircuitBreaker.html "> Circuit Beaker auch als zusätzliche Messgröße für die Überwachung verwenden, mit der Sie schnell auf mögliche Probleme reagieren und klar erkennen können, bei welchen Serviceketten sie auftreten. Dazu muss jeder Serviceabruf in Circuit Breaker eingeschlossen werden.
In dem Bericht erinnerte der Autor auch an das
N-Modular-Redundanzmuster , mit dem „Anforderungen nach Möglichkeit schneller verarbeitet werden sollen“, und lieferte ein schönes Beispiel für die Verwendung zur Validierung der Adresse eines Kunden. Die Anfrage in ihrem System über den Adresscache wurde sofort an mehrere Geo Map-Anbieter gesendet, wodurch die schnellste Antwort gewonnen wurde.
Zusätzlich zu den beschriebenen Mustern wurden folgende erwähnt:
- Fast Path- Muster , das beispielsweise beim Zwischenspeichern von Abfrageergebnissen angewendet werden kann. Dann ist der Cache-Zugriff ein schneller Weg.
- Fehlerkernmuster - Ein Muster aus der Welt von Akka, bei dem eine Aufgabe in Unteraufgaben unterteilt und Unteraufgaben an nachgeschaltete Akteure delegiert werden. Auf diese Weise wird die Flexibilität der Verarbeitung von Ausführungsfehlern für Unteraufgaben erreicht.
- Instanzheiler , der die Existenz eines speziellen Dienstes voraussetzt - ein Supervisor, der andere Dienste verwaltet und auf Änderungen in ihrem Status reagiert. Beispielsweise kann der Supervisor bei Fehlern im Dienst den Problemdienst neu starten.

Clustered Event Sourcing und CQRS mit Akka und Java
Der letzte Bericht, auf den ich Sie aufmerksam machen möchte, wurde von einem der Lightbend-Evangelisten und Architekten Hugh McKee gelesen. Lightbend (früher Typesafe) ist so etwas wie Oracle, aber für die Scala-Sprache. Das Unternehmen entwickelt außerdem aktiv das
Akka.io- Framework. In einem Bericht sprach Hugh über die Implementierung des beliebten
CQRS- Ansatzes (Command Query Responsibility Commands / SEGREGATION) für das Akka-Framework. Schematisch sieht die Architektur des CQRS-Systems folgendermaßen aus:
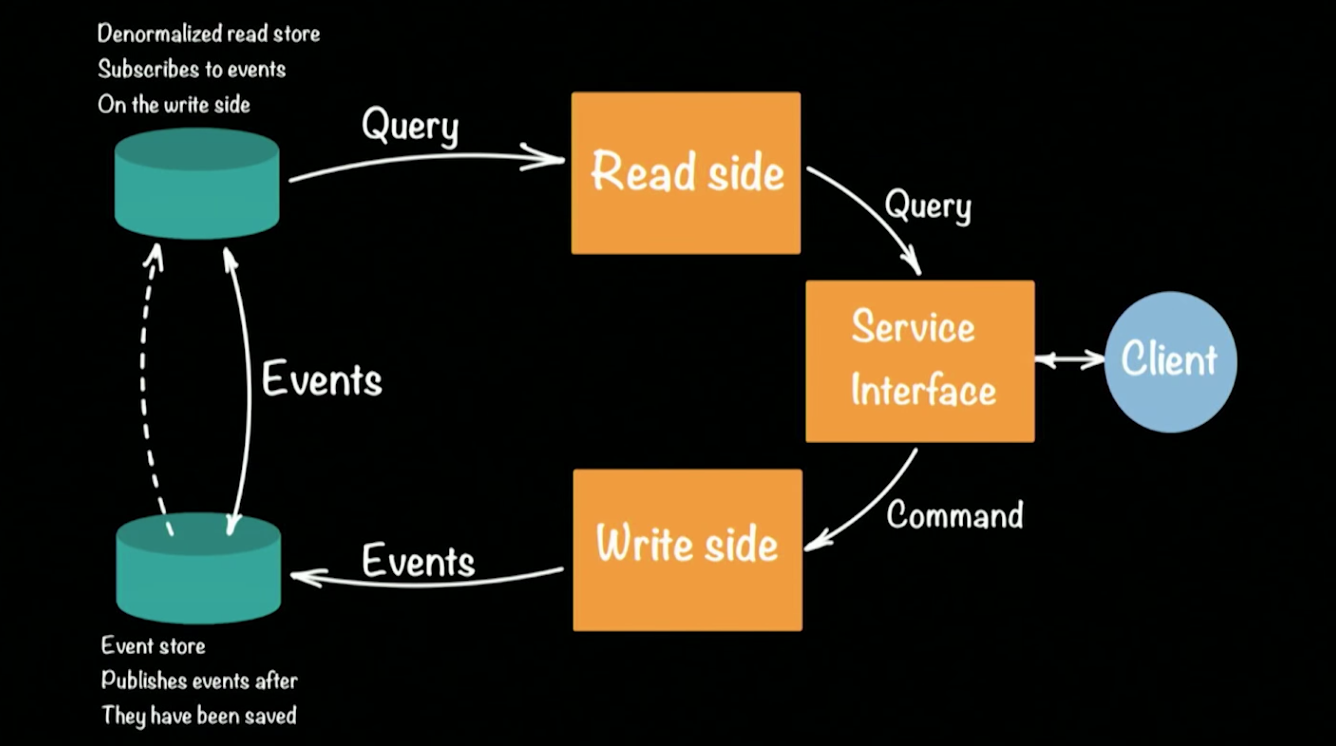
Hugh nahm einen Prototyp einer Bank als Beispiel für ein funktionierendes System. Ein Client in der CQRS-Architektur führt zwei Operationen aus: Abfrage, Befehl. Jedes Team (z. B. eine Banküberweisung, die Geld von einem Konto auf ein anderes überweist) generiert ein Ereignis (eine vollendete Tatsache), das im EventStore aufgezeichnet wird (z. B. Cassandra). Die Aggregation der Kette (Geld auf ein Konto einzahlen, von Konto zu Konto überweisen, an einem Geldautomaten abheben) von Ereignissen bildet den aktuellen Status des Kunden, seinen Geldbetrag auf dem Konto. Anforderungen für den aktuellen Status werden an ein separates Repository gesendet, eine Momentaufnahme des Ereignis-Repositorys, da es keinen Sinn macht, den vollständigen Verlauf eines Bankkontos zu führen. Es reicht aus, die Statusumwandlung für jeden Benutzer regelmäßig zu aktualisieren.
Dieser Ansatz ermöglicht die automatische Wiederherstellung, wenn Fehler auftreten. Dazu müssen wir die letzte Umwandlung des Benutzerstatus abrufen und alle Ereignisse anwenden, die vor dem Auftreten des Fehlers aufgetreten sind. Aufgrund des Vorhandenseins von zwei Speichern toleriert die CQRS-Architektur die auftretenden Spitzenlasten (Spikes) gut. Eine große Anzahl von Ereignissen lädt den Ereignisspeicher, wirkt sich jedoch nicht auf den Lesespeicher aus, und Benutzer können weiterhin Abfragen an die Datenbank ausführen.
Kehren wir zum Prototyping des Bankensystems auf Akka und CQRS zurück. Jeder Kunde der Bank / des Kontos / des möglichen Teams im System wird von einem (!)
Akteur vertreten . Eine große Bank kann Hunderttausende von Konten unterstützen, und dies wird für Akka kein Problem sein. Das Out-of-the-Box-Framework unterstützt Clustering und kann auf Hunderten von JVMs ausgeführt werden. Wenn einer der Computer im Cluster ausfällt, bietet Akka spezielle Mechanismen, die automatisch auf solche Situationen reagieren: In unserem Fall kann der Akteur des Clients auf jedem verfügbaren Computer im Cluster erneut erstellt werden, und sein Status wird erneut aus dem Repository gelesen.
Für einen Akteur wird kein separater Thread erstellt. Dadurch können Zehntausende von Akteuren innerhalb einer einzelnen JVM unterstützt werden. Gleichzeitig garantiert der Akteur, dass jede Anfrage separat (!) In der Reihenfolge des Eingangs der Anfragen bearbeitet wird. Diese Garantie eliminiert automatisch mögliche Rennbedingungen bei der Bearbeitung von Anfragen. Sie können den Prototyp des Systems genauer verstehen, indem Sie den Code über die Links in GitHub öffnen. Jedes Teilprojekt zeigt die Implementierung der komplexesten Phasen der Erstellung eines Prototyps:
Wespen.
Die Aufzeichnungen aller Berichte werden innerhalb weniger Wochen online angezeigt. Ich hoffe, dass dieser Artikel Ihnen dabei hilft, die Anzeigereihenfolge zu bestimmen, zumal ich denke, dass es sich lohnt, die Aufführungen anzusehen.