Kolumnisierte DBMS haben sich in den Nulljahren aktiv entwickelt. Derzeit haben sie ihre Nische gefunden und konkurrieren praktisch nicht mit herkömmlichen Kleinbuchstaben. Unter dem Schnitt versteht der Autor, ob eine universelle Lösung möglich ist und wie praktisch sie ist.
"Es gibt Fortschritte in allem. ... hab keine Angst, dass sie dich ins Büro rufen und sagen:" Wir haben uns hier beraten, und morgen wirst du nach deiner Wahl geviertelt oder verbrannt. "Es wäre eine schwierige Wahl. Ich denke, er würde von vielen von uns verblüfft sein. “
Jaroslaw Hasek. Abenteuer des tapferen Soldaten Schweik.
Hintergrund
Wie viele Datenbanken existieren, so viel ist diese ideologische Konfrontation. Aus Neugier fand der Autor 1975 ein Buch von J. Martin von IBM [1] in den Behältern und stieß sofort auf die Worte (S. 183): „Binäre Beziehungen werden in Werken [...] verwendet, d.h. Beziehungen von nur zwei Domänen. Es ist bekannt, dass binäre Beziehungen der Basis die größte Flexibilität verleihen. Bei kommerziellen Aufgaben sind jedoch Beziehungen in unterschiedlichem Maße bequem. “ Beziehungen werden hier als relationale Beziehungen verstanden. Und die genannten Werke sind datiert 1967 ... 1970.
Lassen Sie Sybase IQ das erste industriell verwendete Spalten-DBMS sein, aber zumindest auf der Ebene der Ideen wurde 25 Jahre zuvor alles ausgesprochen.
Gegenwärtig werden die folgenden DBMS in Spalten oder bis zu dem einen oder anderen Grad unterstützt (dies wird hauptsächlich
hier verwendet ):
Kommerziell
Free & Open Source
Unterschiede
Eine relationale Beziehung ist eine Sammlung von Tupeln, im Wesentlichen eine zweidimensionale Tabelle. Dementsprechend gibt es zwei Speicheroptionen - zeilenweise oder spaltenweise. Trennung ist ein bisschen künstlich, logisch. Datenbankentwickler haben lange aufgehört,
Drum- und Track-Records zu planen. Es ist die Aufgabe von DBMS-Administratoren, DBMS-Daten optimal in ein oder mehrere Dateisysteme zu zerlegen. Wie Dateisysteme Daten auf physischen Datenträgern anordnen, ist jedoch hauptsächlich Dateisystementwicklern bekannt.
Es wäre logisch, das DBMS entscheiden zu lassen, in welcher Reihenfolge die Daten gespeichert werden sollen. Hier geht es um ein hypothetisches DBMS, das beide Optionen zum Organisieren der Datenspeicherung unterstützt und jedem von ihnen eine Tabelle zuweisen kann. Wir betrachten keine sehr beliebte Option zur Unterstützung von zwei Datenbanken - eine für die Arbeit, die zweite für Analysen / Berichte. Sowie Spaltenindizes a la Microsoft SQL Server. Nicht weil es schlecht ist, sondern um die Hypothese zu testen, dass es einen eleganteren Weg gibt.
Leider kann kein hypothetisches DBMS den besten Weg zum Speichern von Daten wählen. Weil hat kein Verständnis dafür, wie wir diese Daten verwenden werden. Und ohne dies ist es unmöglich, eine Wahl zu treffen, obwohl es sehr wichtig ist.
Die wertvollste Qualität eines DBMS ist die Fähigkeit, Daten schnell zu verarbeiten (und natürlich die
ACID- Anforderungen). Die Geschwindigkeit des DBMS wird hauptsächlich durch die Anzahl der Plattenoperationen bestimmt. Daraus ergeben sich zwei Extremfälle:
- Daten werden schnell geändert / hinzugefügt, Sie müssen Zeit zum Schreiben haben. Die offensichtliche Lösung - eine Zeile (Tupel) befindet sich, wenn möglich, auf einer Seite. Dies kann nicht schneller erfolgen.
- Daten ändern sich extrem selten oder überhaupt nicht, wir lesen die Daten oft und es ist jeweils nur eine kleine Anzahl von Spalten beteiligt. In dieser Situation ist es logisch, eine spaltenweise Speichervariante zu verwenden. Beim Lesen steigt dann die minimal mögliche Anzahl von Seiten.
Aber das sind Extremfälle, im Leben ist nicht alles so offensichtlich.
- Wenn Sie die gesamte Tabelle lesen möchten, sind die Daten unter dem Gesichtspunkt der Anzahl der Seiten zeilenweise oder spaltenweise nicht wichtig. Das heißt, es gibt natürlich einen Unterschied in der spaltenweisen Version, wir haben die Möglichkeit, die Informationen besser zu komprimieren, aber im Moment ist dies nicht wichtig.
- Aber in Bezug auf die Leistung gibt es einen Unterschied, weil Bei der zeilenweisen Aufzeichnung erfolgt das Lesen von der Festplatte linearer. Weniger Festplattenköpfe bewegen sich merklich schneller vorwärts. Durch ein besser vorhersehbares Lesen von Dateien während der zeilenweisen Aufzeichnung kann das Betriebssystem den Festplatten-Cache effizienter nutzen. Dies ist auch für SSD-Laufwerke wichtig, da das Laden nach Annahme ( Vorauslesen ) häufig zum Erfolg führt.
- Das Update ändert nicht immer den gesamten Datensatz. Angenommen, ein häufiger Fall ist eine Änderung in zwei Spalten. Dann ist es gut, wenn sich die Daten dieser Spalten auf einer Seite befinden, da Sie nur eine Seitensperre pro Datensatz anstelle von zwei benötigen. Wenn die Daten hingegen über mehrere Seiten verteilt sind, können verschiedene Transaktionen die Daten einer Zeile ohne Konflikte ändern.
Hier ist ein genauerer Blick. Eine hypothetische Wahl besteht darin, die Tabelle in Kleinbuchstaben oder Spalten zu setzen, die das DBMS zum Zeitpunkt seiner Erstellung treffen muss. Aber um diese Wahl zu treffen, wäre es schön zu wissen, wie wir diese Tabelle ändern werden. Vielleicht solltest du eine Münze werfen?
- Angenommen, wir verwenden eine Baumstruktur (z. B. Clustered Index) für die Speicherung. In diesem Fall kann das Hinzufügen oder sogar Ändern von Daten zu einem Neuausgleich des Baums oder seines Teils führen. Im Zeilenspeicher gibt es (mindestens eine) Schreibsperre, die einen wesentlichen Teil der Tabelle betreffen kann. In der säulenförmigen Version kommen solche Geschichten viel häufiger vor, richten aber viel weniger Schaden an, weil betreffen nur eine bestimmte Spalte.
- Betrachten Sie das Filtern nach Index. Angenommen, die Probe ist ausreichend dünn. Dann wird die zeilenweise Aufzeichnung bevorzugt, da in diesem Fall das Verhältnis von nützlichen Informationen zum Lesen für das Unternehmen besser ist.
- Wenn die Filtration einen dichteren Fluss ergibt und nur ein kleiner Teil der Säulen benötigt wird, wird die säulenweise Version billiger. Wo ist die Kluft zwischen diesen Fällen, wie kann man sie bestimmen?
Mit anderen Worten, unser hypothetisches DBMS übernimmt unter keinen Umständen die Verantwortung für die Auswahl zwischen zeilenweisen und spaltenweisen Speicheroptionen. Dies sollte vom Datenbankdesigner durchgeführt werden.
In Anbetracht des oben Gesagten wird der Datenbankdesigner jedoch auch eine sehr schwierige Wahl treffen. Er würde viele von uns verblüffen.
Was wäre wenn
Im Wesentlichen schneiden sowohl spaltenweise als auch zeilenweise Varianten - die Extremfälle einer Idee - die Tabelle in „Bänder“ und speichern Daten zeilenweise in jedem Band. Nur in einem Fall ist das Band eins, in dem anderen degeneriert das Band zu einer Spalte.
Warum also keine Zwischenoptionen zulassen - wenn die Daten einiger Spalten zusammenkommen / gelesen werden, auch wenn sie sich auf demselben Band befinden. Und wenn das Band keine Daten (NULL) enthält, muss nichts gespeichert werden. Gleichzeitig wird das Problem der maximalen Zeilengröße behoben. Sie können die Tabelle aufteilen, wenn das Risiko besteht, dass die Zeile nicht auf eine Seite passt.
Diese Idee ist nicht so originell, der Autor hatte die Möglichkeit, sie zu sehen und selbst anzuwenden. Das Neuheitselement besteht darin, dem Datenbankdesigner zu ermöglichen, zu bestimmen, wie seine Tabelle in Teile unterteilt wird und in welcher Form die Daten auf die Festplatte übertragen werden.
Wir haben es wie folgt für uns gemacht:
- Beim Erstellen einer Tabelle werden Informationen zu unseren Einstellungen mithilfe von Pragmas an den SQL-Prozessor übergeben
- Beim Erstellen einer Tabelle wird zunächst davon ausgegangen, dass sich die gesamte Zeile auf einer Seite des B-Baums befindet
- Sie können jedoch - - #pragma page_break verwenden
um dem SQL-Prozessor mitzuteilen, dass sich die folgenden Spalten auf einer anderen Seite befinden (in einem anderen Baum) - Verwendung - - #pragma column_based
erlaubt uns kurz zu sagen, dass die Spalten, die weiter gehen, sich jeweils auf einem eigenen Baum befinden - - - #pragma row_based
bricht die spaltenbasierte Aktion ab - Somit besteht die Tabelle aus einem oder mehreren B-Bäumen, deren erstes Schlüsselelement ein verstecktes IDENTITY- Feld ist. Es wird angenommen, dass die Reihenfolge, in der Datensätze erstellt werden (möglicherweise mit der Reihenfolge korreliert, in der Datensätze gelesen werden), ebenfalls von Bedeutung ist und nicht vernachlässigt werden sollte. Der Primärschlüssel ist ein separater Baum, dies gilt jedoch nicht für das Thema.
Wie kann das in der Praxis aussehen?
Zum Beispiel so:
CREATE TABLE twomass_psc ( ra double precision, decl double precision, …
Zum Beispiel wird die Haupttabelle des Atlas
2MASS genommen, die Legende
hier und
hier .
J ,
H ,
K - Infrarot-Teilbänder, es ist sinnvoll, Daten über sie zusammen zu speichern, da sie in der Forschung zusammen verarbeitet werden. Hier
zum Beispiel :
Das erste Bild, das rüberkam.
Oder
hier noch schöner:
Es ist Zeit zu bestätigen, dass dies praktisch sinnvoll ist.
Ergebnisse
Unten wird vorgestellt:
- Phasendiagramm (X-Nummer der aufgezeichneten Seite, Y-Nummer der zuletzt aufgezeichneten Seite) des Verfahrens zum Schreiben von Seiten (logischen Nummern) auf die Festplatte beim Erstellen einer Tabelle in zwei Versionen
- In einer Spalte wird es als by_1 bezeichnet
- und für eine in 16 Spalten geschnittene Tabelle wird sie als by_16 bezeichnet
- Gesamtspalten 181

Schauen wir uns genauer an, wie es funktioniert:
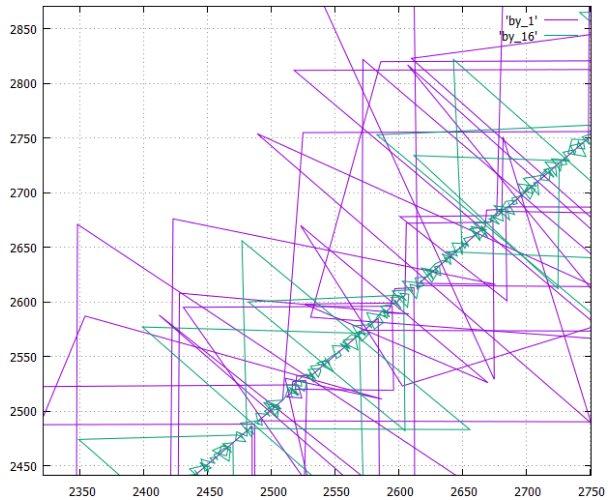
- Die Option by_16 ist deutlich kompakter, was logisch ist - die Linienoption würde nur eine gerade Linie (mit Ausreißern) ergeben.
- Dreieckige Ausreißer - zeichnen Sie Zwischenseiten von B-Bäumen auf.
- Der Datensatz wird offensichtlich angezeigt, der Messwert sieht ungefähr so aus.
- Es wurde oben gesagt, dass alle Optionen die gleiche Menge an Informationen aufzeichnen und der Strom, der subtrahiert werden muss, ungefähr gleich ist (± Komprimierungseffizienz).
Hier wird jedoch sehr deutlich gezeigt, dass in einer spaltenweisen Version die Bäume aufgrund der Besonderheiten der Daten mit unterschiedlichen Geschwindigkeiten wachsen (in einer Spalte wiederholen und komprimieren sie sich häufig sehr gut, in der anderen Spalte - Rauschen aus Sicht des Kompressors). Infolgedessen laufen einige Bäume voraus, andere kommen zu spät, und beim Lesen erhalten wir objektiv einen "zerrissenen" Lesemodus, der für das Dateisystem sehr unangenehm ist. - By_16 ist also zum Lesen viel vorzuziehen als spaltenweise, es ist fast gleich komfortabel wie zeilenweise.
- Gleichzeitig bietet die Variante by_16 die Hauptvorteile einer spaltenweisen Variante für den Fall, dass eine geringe Anzahl von Spalten erforderlich ist. Vor allem, wenn Sie den Tisch nicht mechanisch in 16 Teile teilen, sondern nach Analyse der Wahrscheinlichkeiten ihrer gemeinsamen Verwendung sinnvoll.
Quellen
[1] J. Martin. Organisation von Datenbanken in Computersystemen. Die Welt, 1978
[2]
Spaltenindizes, Verwendungsmerkmale[3] Daniel J. Abadi, Samuel Madden und Nabil Hachem.
ColumnStores vs. RowStores: Wie unterschiedlich sind sie wirklich? , Tagungsband der ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Kanada, Juni 2008
[4] Michael Stonebraker, Uğur Çetintemel.
"One Size Fits All": Eine Idee, deren Zeit gekommen und vergangen ist , 2005