Am 29. Mai fand
eine weitere Konferenz 2018 statt - die jährliche und größte Yandex-Konferenz. Auf der diesjährigen YaC gab es drei Bereiche: Marketingtechnologien, Smart City und Informationssicherheit. In der Verfolgung veröffentlichen wir einen der wichtigsten Berichte des dritten Abschnitts - von Yuri Leonovich
tracer0tong von der japanischen Firma Rakuten.
Wie authentifizieren wir uns? In unserem Fall gibt es nichts Außergewöhnliches, aber ich möchte eine Methode erwähnen. Zusätzlich zu herkömmlichen Typen - Captcha und Einmalkennwörter - verwenden wir Proof of Work, PoW. Nein, wir bauen keine Bitcoins auf den Computern der Benutzer ab. Wir verwenden PoW, um den Angreifer zu verlangsamen und manchmal sogar vollständig zu blockieren, was ihn dazu zwingt, eine sehr schwierige Aufgabe zu lösen, für die er viel Zeit aufwenden wird.
- Ich arbeite für die Rakuten International Corporation. Ich möchte über verschiedene Dinge sprechen: ein wenig über mich selbst, über unser Unternehmen, darüber, wie man die Kosten von Angriffen bewertet und versteht, ob Sie überhaupt Betrugsprävention betreiben müssen. Ich möchte Ihnen sagen, wie wir unsere Betrugsprävention gesammelt haben und welche Modelle wir verwendet haben, um in der Praxis gute Ergebnisse zu erzielen, wie sie funktioniert haben und was getan werden kann, um Betrugsangriffe zu verhindern.

Über mich kurz. Er arbeitete bei Yandex, war an der Sicherheit von Webanwendungen beteiligt und hat bei Yandex auch einmal ein System zur Verhinderung von Betrugsangriffen entwickelt. Ich bin in der Lage, verteilte Dienste zu entwickeln. Ich habe einen mathematischen Hintergrund, der beim Einsatz von maschinellem Lernen in der Praxis hilft.
Rakuten ist in der Russischen Föderation nicht sehr bekannt, aber ich denke, Sie alle wissen es aus zwei Gründen. Von den mehr als 70 unserer Dienstleistungen in Russland ist Rakuten Viber bekannt, und wenn es hier Fußballfans gibt, wissen Sie vielleicht, dass unser Unternehmen der allgemeine Sponsor des Fußballclubs von Barcelona ist.
Da wir so viele Dienste haben, unsere eigenen Zahlungssysteme, unsere eigenen Kreditkarten und viele Prämienprogramme, sind wir ständig Angriffen von Cyberkriminellen ausgesetzt. Und natürlich haben wir immer eine Anfrage des Unternehmens nach Betrugsschutzsystemen.
Wenn ein Unternehmen uns auffordert, ein Betrugsschutzsystem einzurichten, stehen wir immer vor einem Dilemma. Einerseits besteht die Anforderung, dass es eine hohe Conversion-Rate geben sollte, damit sich der Benutzer bequem bei Diensten authentifizieren und Einkäufe tätigen kann. Und unsererseits, seitens der Sicherheitskräfte, möchte ich weniger Beschwerden, weniger gehackte Konten. Und wir für unseren Teil wollen den Angriffspreis hoch machen.
Wenn Sie ein Betrugspräventionssystem kaufen oder versuchen, es selbst zu tun, müssen Sie zuerst die Kosten bewerten.

Brauchen wir unserer Meinung nach Betrugsprävention? Wir haben uns auf die Tatsache verlassen, dass wir einige Arten von finanziellen Verlusten durch Betrug haben. Dies sind direkte Verluste - das Geld, das Sie Ihren Kunden zurückgeben, wenn sie von Eindringlingen gestohlen wurden. Dies sind die Kosten für einen technischen Support, der mit Benutzern kommuniziert und Konflikte löst. Dies ist eine Rücksendung von Waren, die häufig an gefälschte Adressen geliefert werden. Und es gibt direkte Kosten für die Entwicklung des Systems. Wenn Sie ein System zum Schutz vor Betrug erstellt und auf einigen Servern bereitgestellt haben, zahlen Sie für die Infrastruktur und die Softwareentwicklung. Und es gibt einen dritten sehr wichtigen Aspekt des Schadens durch Angreifer - entgangenen Gewinn. Es besteht aus mehreren Komponenten.
Nach unseren Berechnungen gibt es einen sehr wichtigen Parameter - den Lebenszeitwert LTV, dh das Geld, das der Benutzer für unsere Dienste ausgibt, wird erheblich reduziert. Denn in der Hälfte der Betrugsfälle verlassen Benutzer einfach Ihren Dienst und kehren nicht zurück.
Wir zahlen auch Geld für Werbung, und wenn der Benutzer geht, gehen sie verloren. Dies sind die Kundenakquisitionskosten (CAC). Und wenn wir viele automatisierte Benutzer haben, die keine echten Menschen sind, haben wir gefälschte monatlich aktive Benutzer, MAU-Zahlen, die sich auch auf das Geschäft auswirken.
Schauen wir von der anderen Seite, von den Angreifern.
Einige Redner sagten, dass Angreifer Botnets aktiv nutzen. Aber egal welche Methode sie verwenden, sie müssen immer noch Geld investieren, für den Angriff bezahlen, sie geben auch etwas Geld aus. Unsere Aufgabe bei der Schaffung eines Betrugspräventionssystems ist es, ein solches Gleichgewicht zu finden, dass der Angreifer zu viel Geld ausgibt und wir weniger ausgeben. Dies macht einen Angriff auf uns unrentabel und Angreifer gehen einfach weg, um einen anderen Dienst zu unterbrechen.

Für unsere Schadensdienste haben wir Angriffe in vier Arten unterteilt. Dies ist gezielt, wenn versucht wird, ein Konto, ein Konto zu hacken. Angriffe eines Benutzers oder einer kleinen Gruppe von Personen. Oder Angriffe, die für uns gefährlicher sind, massiv und nicht zielgerichtet, wenn Angreifer viele Konten, Kreditkarten, Telefonnummern usw. angreifen.

Ich werde dir sagen, was passiert, wie sie uns angreifen. Die offensichtlichste Art von Angriff, die jeder kennt, ist das Knacken von Passwörtern. In unserem Fall versuchen die Angreifer, Telefonnummern zu sortieren und Kreditkartennummern zu validieren. Etwas Abwechslung ist vorhanden.
Massenregistrierung von Konten, für uns ist es offensichtlich schädlich. Ich werde später ein Beispiel geben.
Was wird aufgezeichnet? Gefälschte Konten, einige nicht vorhandene Produkte, versuchen, Feedback-Nachrichten zu spammen. Ich denke, dass dies für viele Handelsunternehmen relevant und ähnlich ist.
Es gibt immer noch Probleme, die für den E-Commerce nicht offensichtlich sind, für Yandex jedoch offensichtlich - Angriffe auf das Werbebudget, Klickbetrug. Oder einfach nur der Diebstahl personenbezogener Daten.

Ich werde ein Beispiel geben. Wir hatten einen ziemlich interessanten Angriff auf einen Dienst, der elektronische Bücher verkauft. Jeder Benutzer hatte die Möglichkeit, sich zu registrieren und mit dem Verkauf seiner elektronischen Werke zu beginnen. Dies war eine Gelegenheit, unerfahrene Autoren zu unterstützen.
Der Angreifer registrierte ein legales Hauptkonto und mehrere tausend gefälschte Minion-Konten. Und er schuf ein falsches Buch, nur aus zufälligen Sätzen, es hatte keinen Sinn. Er brachte es auf den Markt, und wir hatten eine Marketingfirma, jeder Diener hatte bedingt 1 Dollar, den er für ein Buch ausgeben konnte. Und dieses gefälschte Buch kostet 1 Dollar.
Ein Überfall von Schergen wurde organisiert - gefälschte Konten. Sie alle kauften dieses Buch, das Buch sprang in die Bewertungen, wurde ein Bestseller, ein Angreifer erhöhte den Preis auf bedingte 10 Dollar. Und da das Buch zum Bestseller wurde, begannen gewöhnliche Leute, es zu kaufen, und es fielen Beschwerden auf, dass wir einige minderwertige Waren verkauften, ein Buch mit bedeutungslosen Worten. Der Angreifer erhielt einen Gewinn.
Es gibt keinen neunten Punkt, er wurde später von der Polizei festgenommen. Der Gewinn ging also nicht in die Zukunft.
Das Hauptziel aller Angreifer in unserem Fall ist es, so wenig wie möglich von ihrem Geld auszugeben und so viel wie möglich von uns zu nehmen.

Es gibt Angreifer, eine Person, die einfach versucht, die Geschäftslogik zu umgehen. Ich stelle jedoch fest, dass wir solche Angriffe nicht als Priorität betrachten, da sie im Verhältnis der Anzahl der gehackten Konten und des gestohlenen Geldes ein geringes Risiko für uns darstellen. Das Hauptproblem für uns sind jedoch die Botnetze.

Dies sind massive verteilte Systeme, die unsere Dienste von überall auf der Welt und von verschiedenen Kontinenten aus angreifen, aber einige Funktionen haben, die den Umgang mit ihnen erleichtern. Wie in jedem großen verteilten System führen Botnetzknoten mehr oder weniger dieselben Aufgaben aus.
Eine weitere wichtige Sache - jetzt, wie viele Kollegen bemerkten, werden Botnets auf allen Arten von Smart-Geräten, Heimroutern, Smart-Lautsprechern usw. verteilt. Diese Geräte haben jedoch niedrige Hardwarespezifikationen und können keine komplexen Skripte ausführen.
Auf der anderen Seite ist es für einen Angreifer recht günstig, ein Botnetz für einfaches DDoS zu mieten, und es ist auch erforderlich, Passwörter nach Konten zu durchsuchen. Wenn Sie jedoch eine Geschäftslogik speziell für Ihre Anwendung oder Ihren Dienst implementieren müssen, wird die Entwicklung und Unterstützung eines Botnetzes sehr teuer. Normalerweise mietet ein Angreifer einfach einen Teil eines fertigen Botnetzes.
Ich verbinde immer einen Botnet-Angriff mit der Pikachu-Parade in Yokohama. Wir haben 95% des böswilligen Datenverkehrs von Botnetzen.
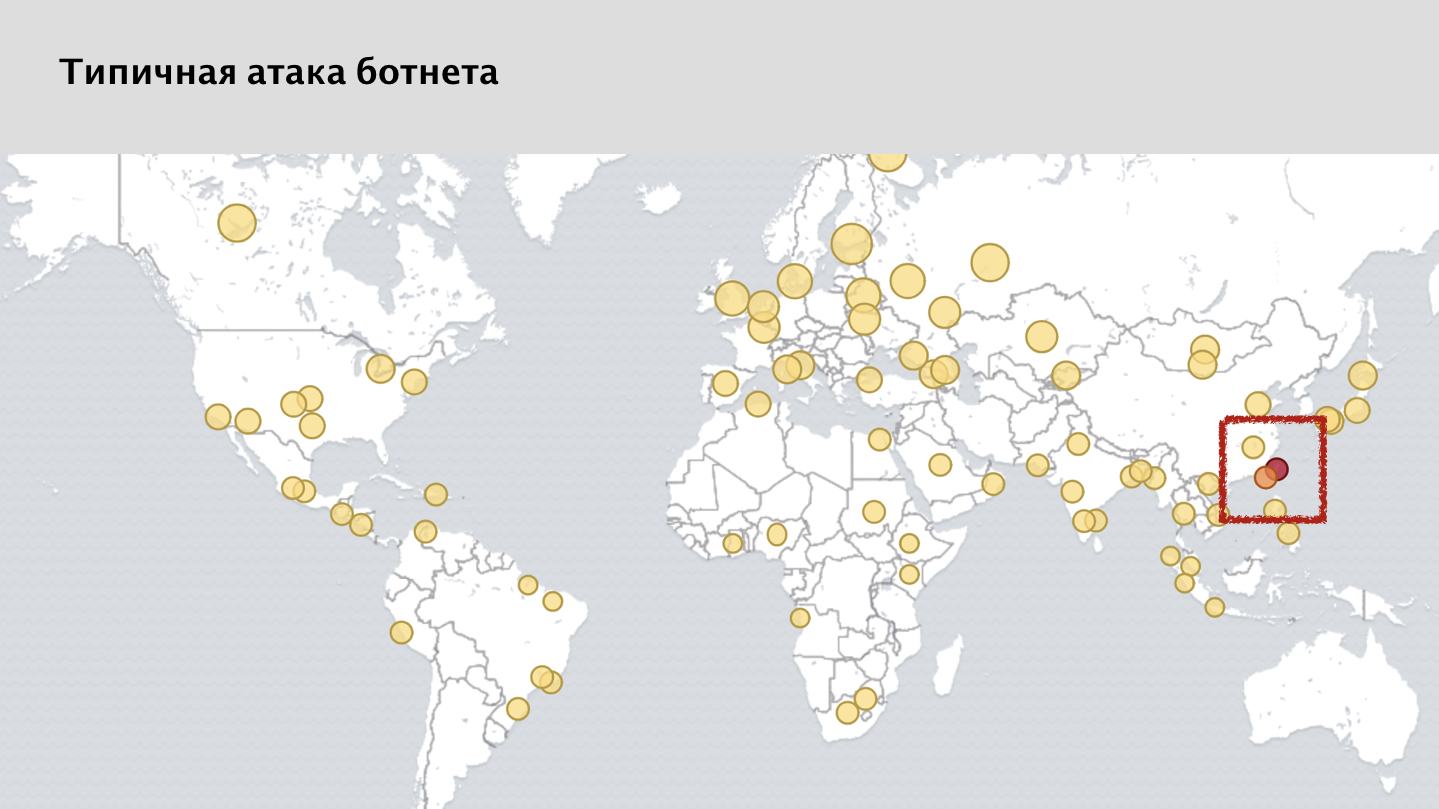
Wenn Sie sich den Screenshot unseres Überwachungssystems ansehen, sehen Sie viele gelbe Flecken - dies sind blockierte Anforderungen von verschiedenen Knoten. Und hier kann eine aufmerksame Person bemerken, dass ich irgendwie gesagt habe, dass der Angriff gleichmäßig auf der ganzen Welt verteilt ist. Aber es gibt eine deutliche Anomalie auf der Karte, einen roten Fleck in der Region Taiwan. Dies ist ein ziemlich merkwürdiger Fall.
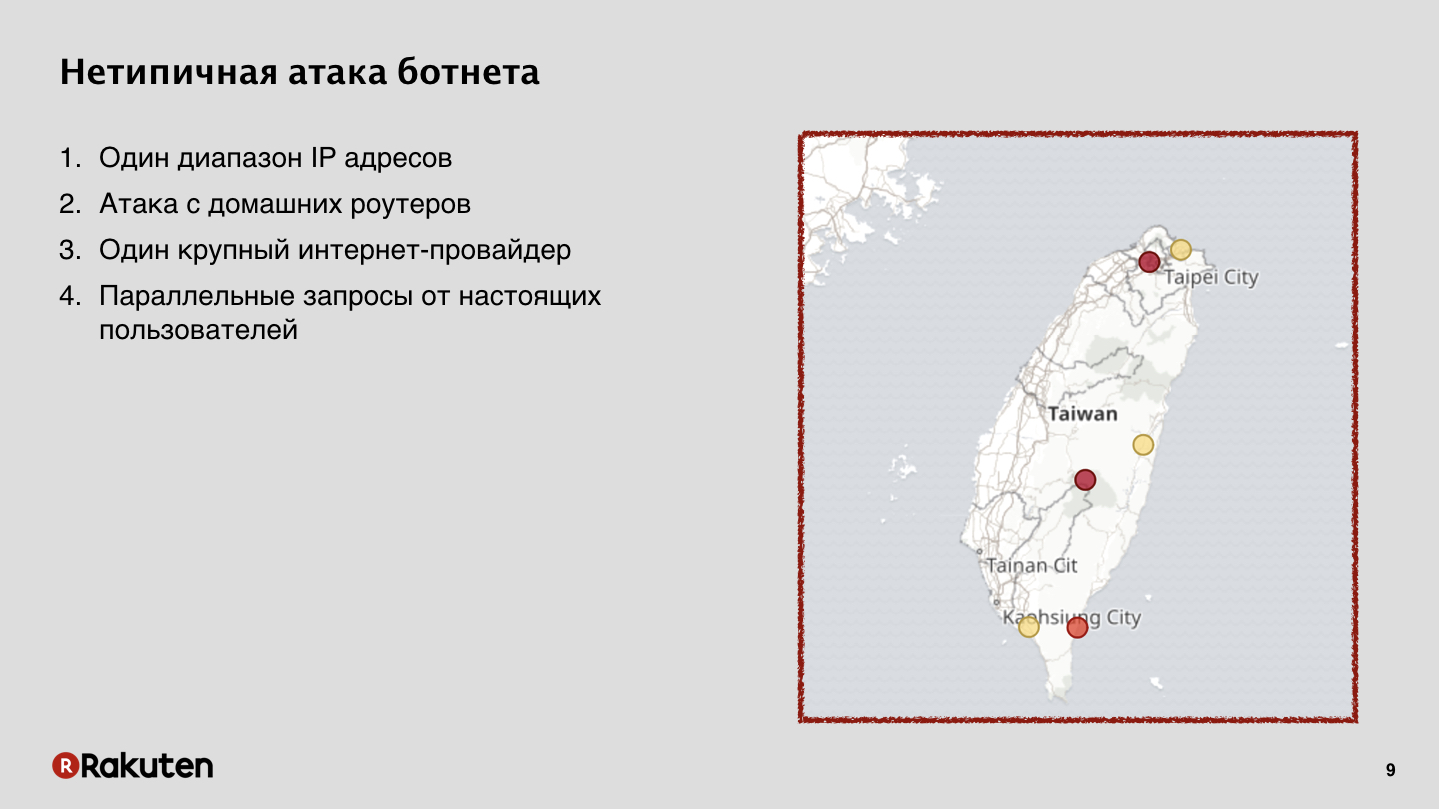
Dieser Angriff kam von Heimroutern. In Taiwan wurde ein großer Internetdienstanbieter gehackt, der den meisten Inselbewohnern das Internet zur Verfügung stellte. Und für uns war es ein sehr großes Problem, das damit zusammenhängt, dass viele legale Benutzer zur gleichen Zeit, als der Angriff stattfand, von denselben IP-Adressen gingen und mit unseren Diensten arbeiteten. Wir haben diesen Angriff erfolgreich gestoppt, aber es war sehr schwierig.
Wenn wir über Umfang sprechen, über die Oberfläche, über das, was wir schützen. Wenn Sie eine kleine E-Commerce-Website oder einen kleinen regionalen Dienst haben, haben Sie keine besonderen Probleme. Sie haben einen Server, möglicherweise mehrere oder virtuelle Maschinen in der Cloud. Nun, Benutzer, schlecht, gut, die zu Ihnen kommen. Es gibt kein besonderes Problem zu schützen.
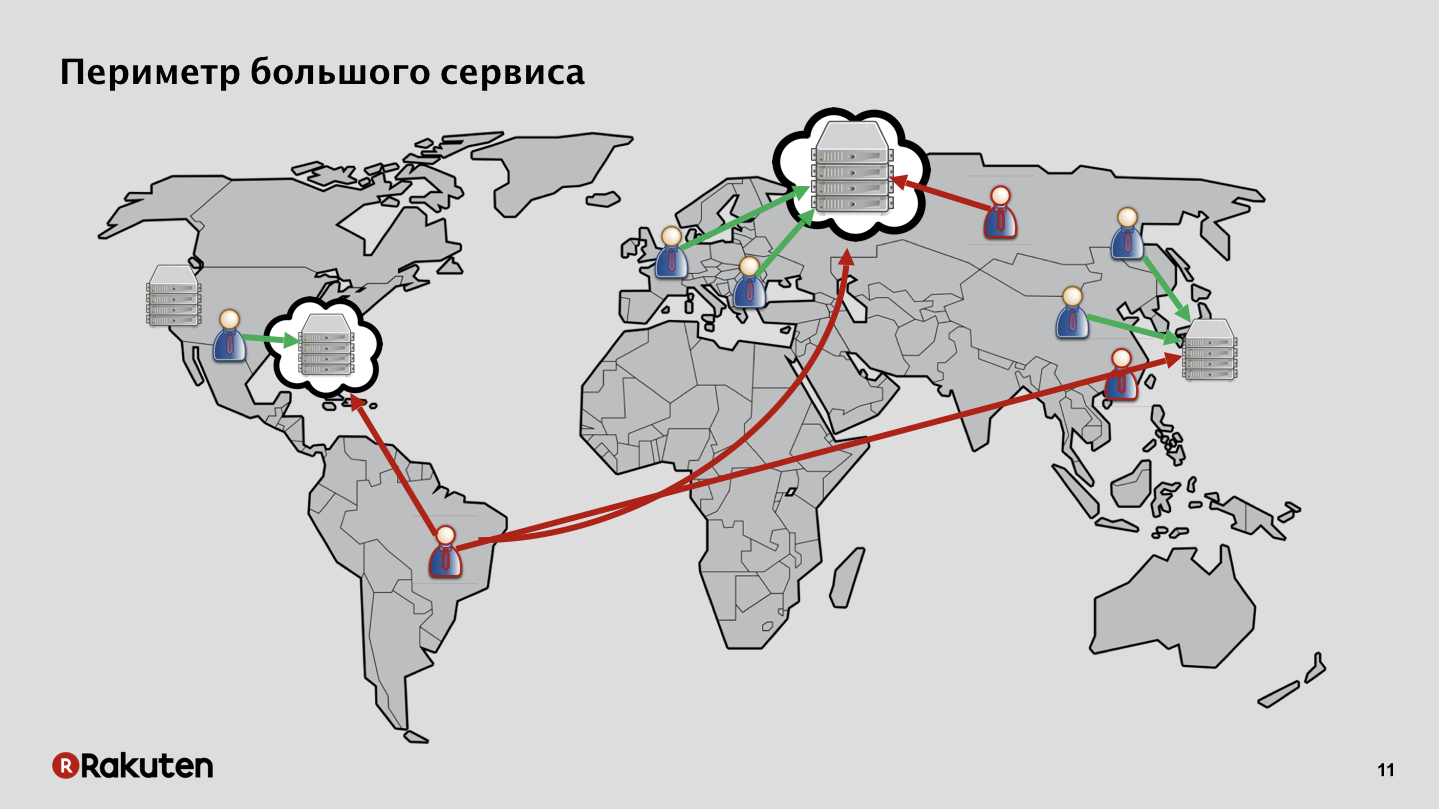
In unserem Fall ist alles komplizierter, die Angriffsfläche ist riesig. Wir haben Services in unseren eigenen Rechenzentren in Europa, Südostasien und den USA bereitgestellt. Wir haben auch Benutzer auf verschiedenen Kontinenten, sowohl gut als auch schlecht. Außerdem werden einige Dienste in der Cloud-Infrastruktur bereitgestellt und nicht unsere eigenen.
Bei so vielen Diensten und einer so umfangreichen Infrastruktur ist es sehr schwierig, sich zu verteidigen. Darüber hinaus unterstützen viele unserer Services verschiedene Arten von Clientanwendungen und -schnittstellen. Zum Beispiel haben wir einen Rakuten-TV-Dienst, der auf Smart-TVs funktioniert, und der Schutz ist dafür etwas ganz Besonderes.

Um das Problem zusammenzufassen: Eine große Anzahl von Benutzern zirkuliert in Ihrem System, z. B. Personen in einem Geschäft an der Kreuzung in Shibuya. Und unter diesen vielen Menschen ist es notwendig, die Angreifer zu identifizieren und zu fangen. Gleichzeitig gibt es in Ihrem Geschäft viele Türen und noch mehr Menschen.
Woraus und wie haben wir unser System zusammengebaut?
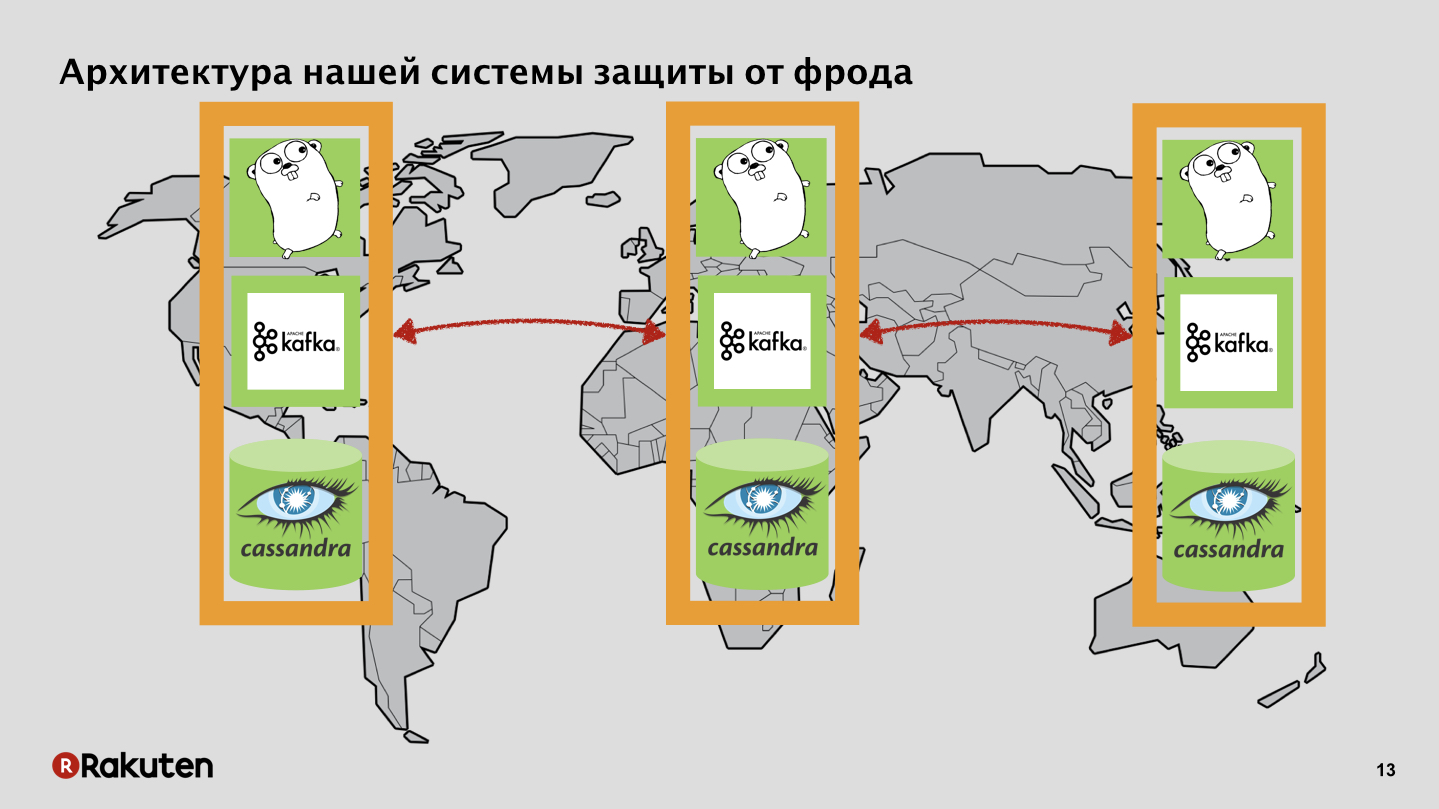
Wir konnten nur Open-Source-Komponenten verwenden, es war billig genug. Hat die Kraft vieler "Gophers" genutzt. Ein wesentlicher Teil der Software wurde in der Sprache Golang geschrieben. Verwendete Nachrichtenwarteschlangen und Datenbanken. Warum brauchten wir das? Wir hatten zwei Ziele: Sammeln von Daten zum Benutzerverhalten und Berechnen der Reputation, Ergreifen einiger Maßnahmen, um festzustellen, ob ein Benutzer gut oder schlecht ist.
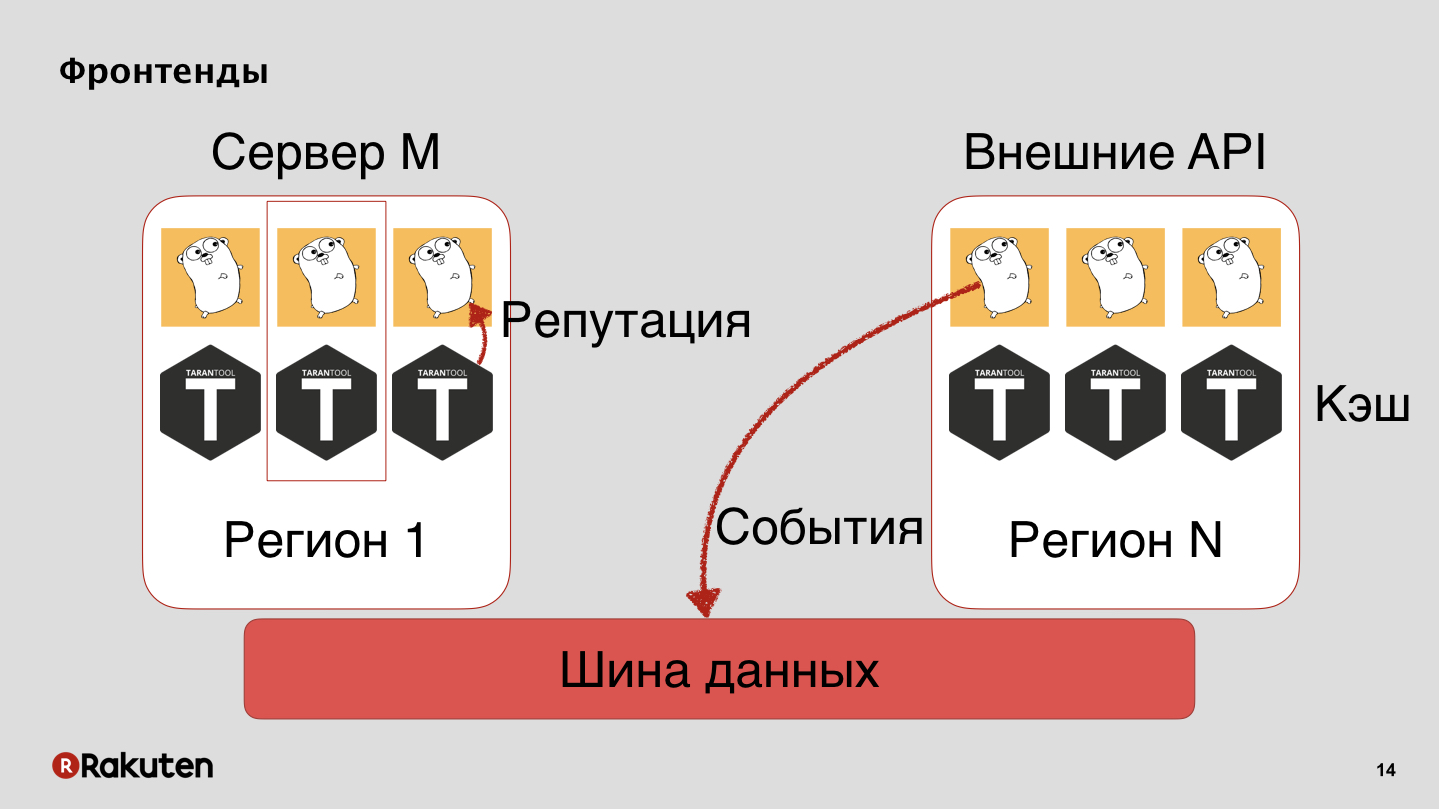
Wir haben viele Ebenen im System, wir verwenden die in Golang geschriebenen Frontends und Tarantool als Caching-Basis. Unser System wird in allen Regionen eingesetzt, in denen sich unsere Unternehmen befinden. Wir übertragen Ereignisse über den Datenbus und erhalten dadurch einen guten Ruf.
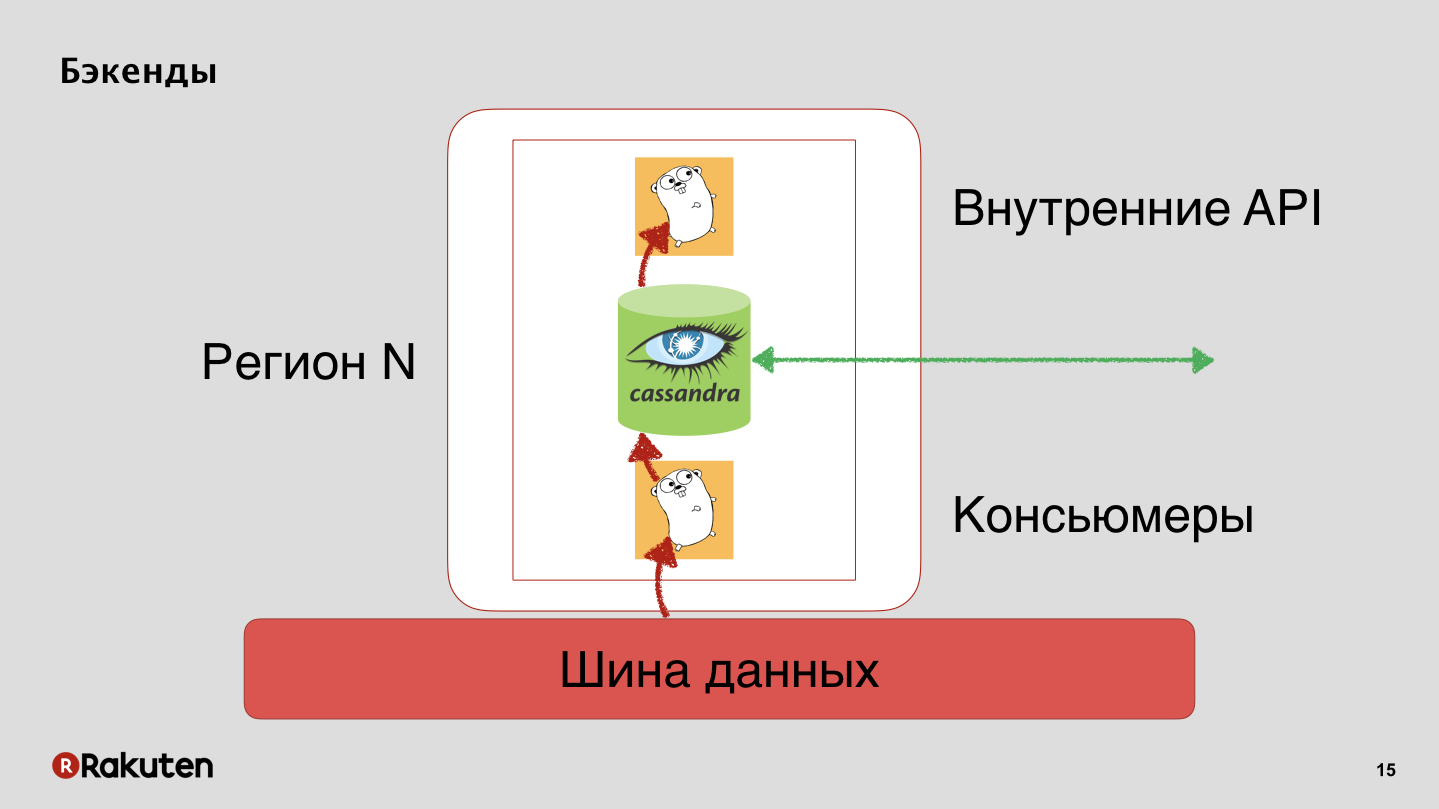
Wir haben Backends, die auch den Status der Benutzerreputation mit Cassandra replizieren.
Datenbus, nichts Geheimnisvolles, Apache Kafka.
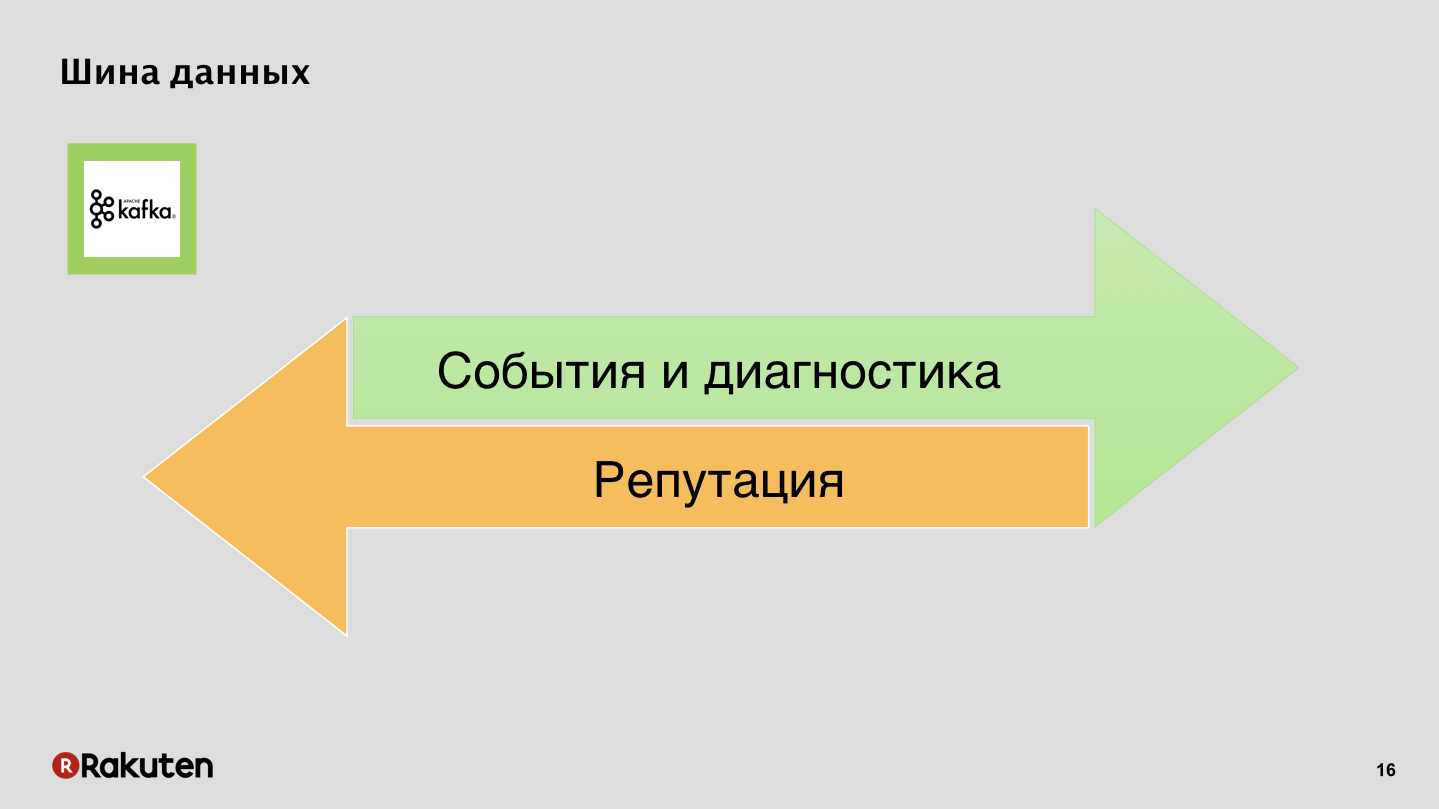
Ereignisse und Protokolle in die eine Richtung, Ruf in die andere.
Und natürlich hat das System ein Gehirn, das denkt, ob der Benutzer schlecht oder gut ist, ob die Aktivität schlecht oder gut ist. Das Gehirn baut auf Apache Storm auf, und der lustige Teil ist, was im Inneren passiert.
Aber zuerst werde ich Ihnen sagen, wie wir Daten sammeln und wie Eindringlinge blockiert werden.
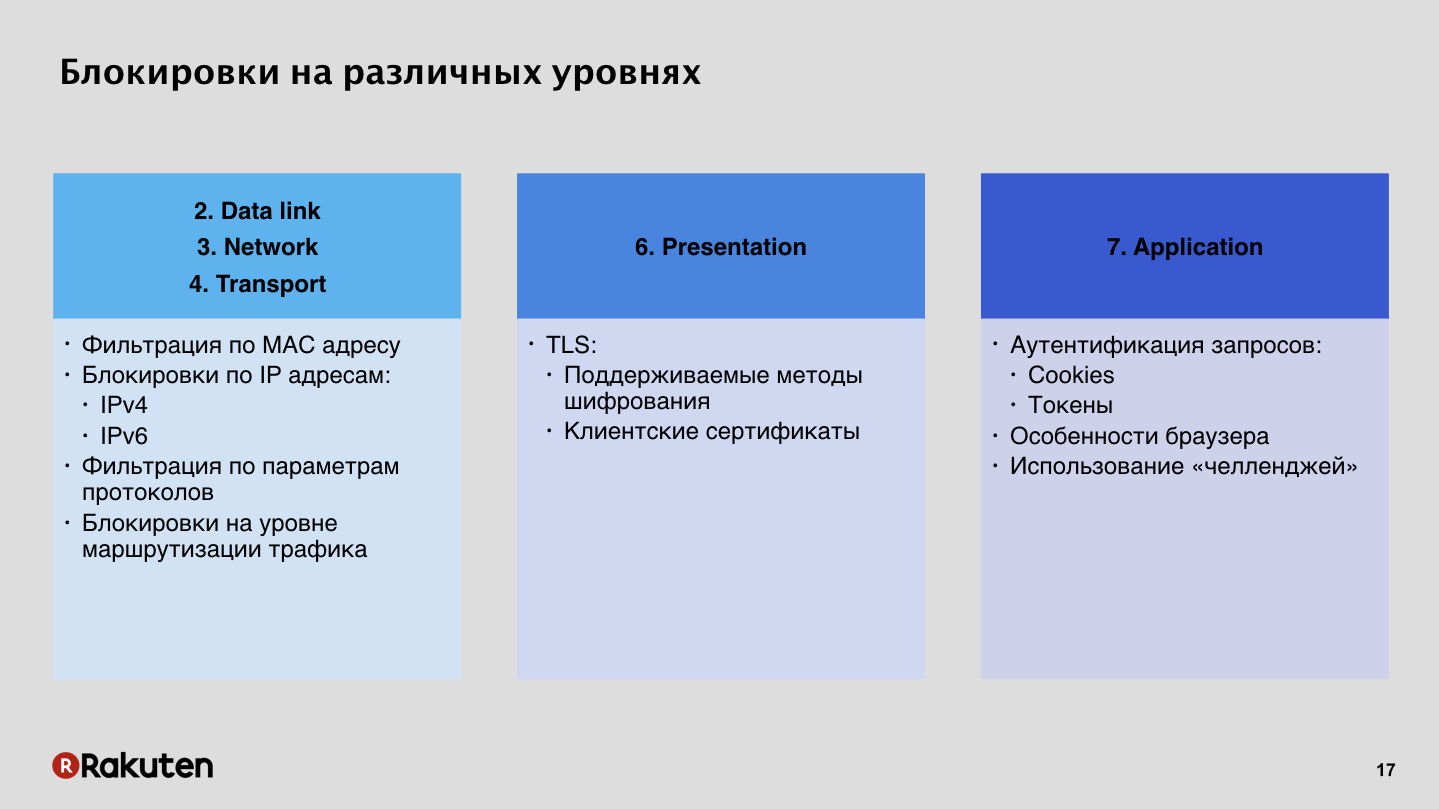
Es gibt viele Ansätze. Einige von ihnen wurden bereits von Kollegen von Yandex in ihrem ersten Bericht erwähnt. Wie blockiere ich Eindringlinge? Anton Karpov sagte, dass Firewalls schlecht sind, wir mögen sie nicht. Es kann zwar durch IP-Adressen blockiert werden, das Thema für Russland ist sehr relevant, aber diese Methode passt überhaupt nicht zu uns. Wir bevorzugen die Verwendung von Sperren auf höherer Ebene auf der siebten Ebene auf Anwendungsebene, wobei die Authentifizierung von Anforderungen mithilfe von Token und Sitzungscookies verwendet wird.
Warum? Schauen wir uns zuerst die niedrigen Schlösser an.
Dies ist ein billiger Weg, jeder weiß, wie man es benutzt, jeder hat Firewalls auf den Servern. Eine Reihe von Anweisungen im Internet, es gibt keine Probleme, den Benutzer durch IP zu blockieren. Wenn Sie den Benutzer jedoch auf einer niedrigen Ebene blockieren, kann er Ihr Schutzsystem nicht umgehen, wenn dies falsch positiv war. Moderne Browser versuchen mehr oder weniger, dem Benutzer eine schöne Fehlermeldung anzuzeigen, aber dennoch kann eine Person Ihr System in keiner Weise umgehen, da ein gewöhnlicher Benutzer seine IP-Adressen nicht willkürlich ändern kann. Daher glauben wir, dass diese Methode nicht sehr gut und unfreundlich ist. Und wenn sich IPv6 um den Planeten bewegt, wenn Tabellen blockiert sind, dauert es nach einiger Zeit sehr lange, nach Adressen in solchen Tabellen zu suchen, und es gibt keine Zukunft für solche Sperren.

Unsere Methode sind Sperren auf oberster Ebene. Wir bevorzugen die Authentifizierung von Anfragen, da dies für uns eine Möglichkeit ist, uns sehr flexibel an die Geschäftslogik unserer Anwendungen anzupassen. Solche Verfahren haben Vor- und Nachteile. Der Nachteil sind die hohen Entwicklungskosten, die große Menge an Ressourcen, die Sie in die Infrastruktur investieren müssen, und die Architektur solcher Systeme mit all ihrer scheinbaren Einfachheit ist immer noch kompliziert.
Sie haben in früheren Berichten über verschiedene Methoden gehört, die auf Biometrie und Datenerfassung basieren. Natürlich denken wir auch darüber nach, aber hier ist es sehr leicht, die Privatsphäre des Benutzers zu verletzen, indem die falschen Daten gesammelt werden, die der Benutzer Ihnen anvertrauen möchte.
Wie authentifizieren wir uns? In unserem Fall gibt es nichts Außergewöhnliches, aber ich möchte eine Methode erwähnen. Zusätzlich zu herkömmlichen Typen - Captcha und Einmalkennwörter - verwenden wir Proof of Work, PoW. Nein, wir bauen keine Bitcoins auf den Computern der Benutzer ab. Wir verwenden PoW, um den Angreifer zu verlangsamen und manchmal sogar vollständig zu blockieren, was ihn dazu zwingt, eine sehr schwierige Aufgabe zu lösen, für die er viel Zeit aufwenden wird.
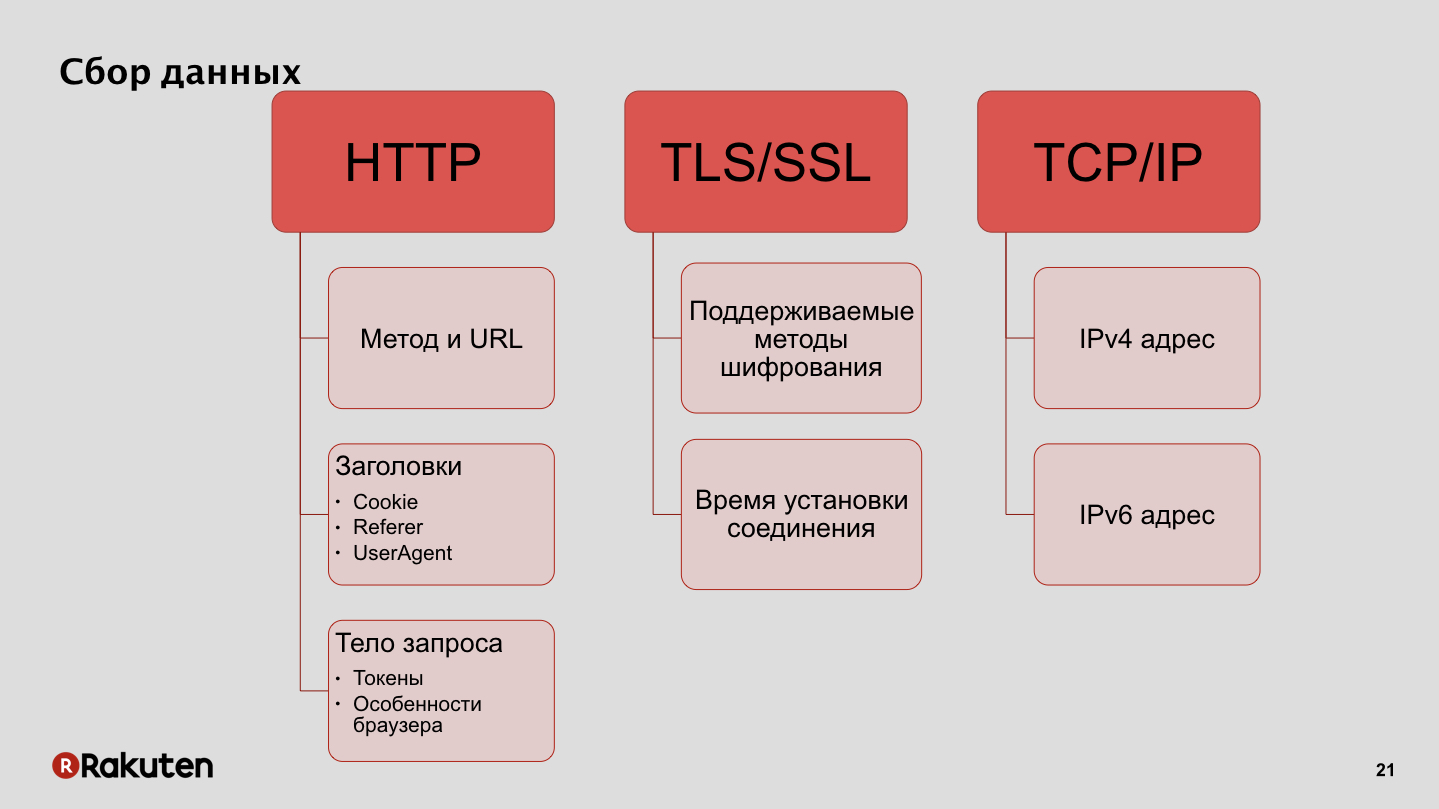
Wie sammeln wir Daten? Wir verwenden IP-Adressen als eine der Funktionen. Eine der Datenquellen für uns sind die von Clients unterstützten Verschlüsselungsprotokolle und die Verbindungsaufbauzeit. Außerdem die Daten, die wir von Benutzerbrowsern sammeln, die Funktionen dieser Browser und die Token, die wir zur Authentifizierung von Anforderungen verwenden.
Wie erkennt man Eindringlinge? Sie erwarten wahrscheinlich von mir, dass wir sagen, dass wir ein riesiges neuronales Netzwerk aufgebaut und sofort alle gefangen haben. Nicht wirklich. Wir haben einen mehrstufigen Ansatz verwendet. Dies liegt an der Tatsache, dass wir viele Dienste haben, sehr große Verkehrsmengen, und wenn Sie versuchen, ein komplexes Computersystem auf solche Verkehrsmengen zu setzen, wird dies höchstwahrscheinlich sehr teuer sein und die Dienste verlangsamen. Aus diesem Grund haben wir mit einer einfachen banalen Methode begonnen: Wir haben gezählt, wie viele Anfragen von verschiedenen Adressen und Browsern stammen.

Diese Methode ist sehr primitiv, aber Sie können dumme massive Angriffe wie DDoS herausfiltern, wenn im Verkehr ausgeprägte Anomalien auftreten. In diesem Fall sind Sie absolut sicher, dass dies ein Angreifer ist, und Sie können ihn blockieren. Diese Methode ist jedoch nur auf der Anfangsebene geeignet, da sie nur die gröbsten Angriffe verhindert.
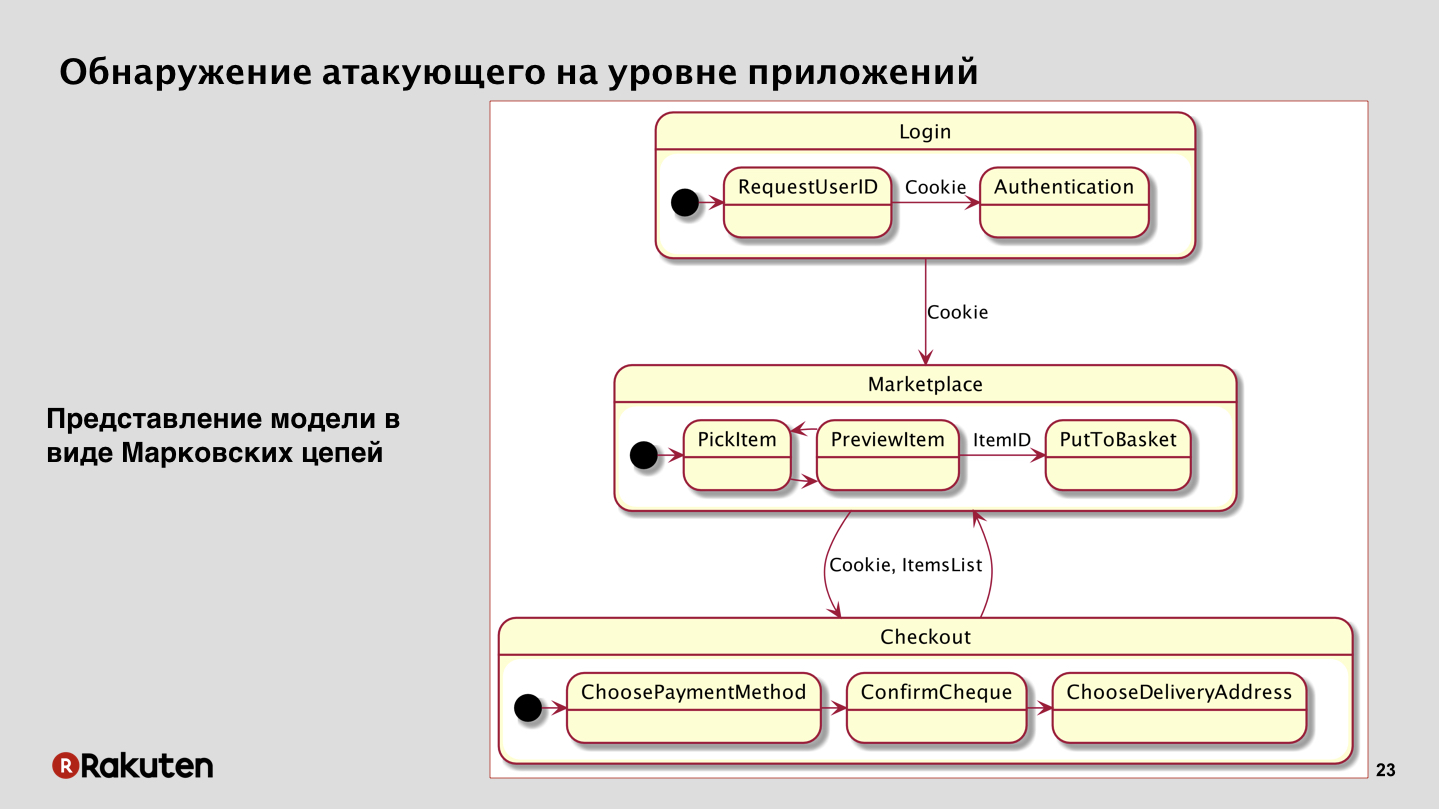
Danach kamen wir zur nächsten Methode. Wir haben uns entschlossen, uns auf die Tatsache zu konzentrieren, dass wir eine Geschäftslogik von Anwendungen haben und ein Angreifer niemals einfach zu Ihrem Dienst kommen und Geld stehlen kann. Wenn er es nicht geknackt hat, natürlich. In unserem Fall sehen Sie, wenn Sie sich das einfachste Schema eines abstrakten Marktplatzes ansehen, dass sich der Benutzer zuerst anmelden, seine Anmeldeinformationen vorlegen, Sitzungscookies erhalten, dann zum Marktplatz gehen, dort nach Waren suchen und diese in den Warenkorb legen muss. Danach bezahlt er den Kauf, wählt die Adresse und die Zahlungsmethode aus und klickt am Ende auf „Bezahlen“. Schließlich erfolgt der Kauf der Waren.
Sie sehen, ein Angreifer muss viele Schritte unternehmen. Und diese Übergänge zwischen Zuständen, zwischen Diensten ähneln einem mathematischen Modell - dies sind Markov-Ketten, die auch hier verwendet werden können. In unserem Fall zeigten sie im Prinzip sehr gute Ergebnisse.

Ich kann ein vereinfachtes Beispiel geben. Grob gesagt gibt es einen Moment, in dem sich ein Benutzer authentifiziert, Einkäufe auswählt und eine Zahlung vornimmt. Beispielsweise ist es offensichtlich, wie sich ein Angreifer abnormal verhalten kann. Er kann versuchen, sich mehrmals mit verschiedenen Konten anzumelden. Oder er legt die falschen Produkte in den Warenkorb, den normale Benutzer kaufen. Oder führt eine ungewöhnlich große Anzahl von Aktionen aus.
Markov-Ketten berücksichtigen normalerweise Zustände. Wir haben uns auch entschlossen, diesen Staaten Zeit für uns selbst hinzuzufügen. Angreifer und normale Benutzer verhalten sich zeitlich sehr unterschiedlich, was auch dazu beiträgt, sie zu trennen.
Markov-Ketten sind ein ziemlich einfaches mathematisches Modell. Sie sind im Handumdrehen sehr einfach zu zählen, sodass Sie eine weitere Schutzstufe hinzufügen und einen anderen Teil des Verkehrs aussortieren können.
Die nächste Stufe. Wir haben die dummen Angreifer gefangen, die bösen Angreifer. Jetzt sind die klügsten übrig. Für knifflige Angreifer werden zusätzliche Funktionen benötigt. Was können wir tun?
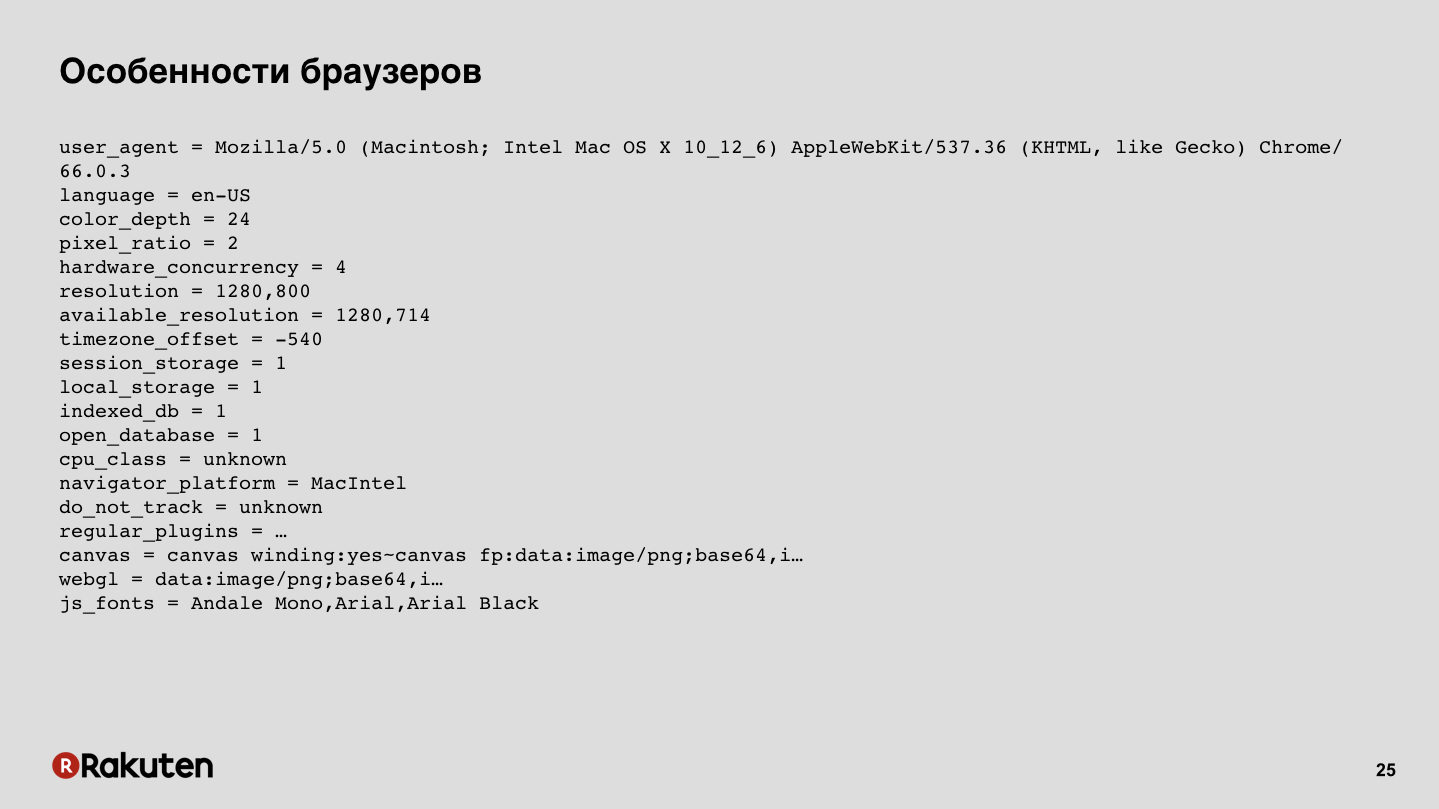
Wir können einige Fingerabdrücke von Browsern sammeln. Jetzt sind Browser recht komplexe Systeme, sie haben viele unterstützte Funktionen, sie führen JS aus, sie haben verschiedene Funktionen auf niedriger Ebene, und all dies kann gesammelt werden, all diese Daten. Auf der Folie finden Sie ein Beispiel für die Ausgabe einer der Open Source-Bibliotheken.
Außerdem können Sie Daten darüber sammeln, wie der Benutzer mit Ihrem Dienst interagiert, wie er die Maus bewegt, wie er ein mobiles Gerät berührt und wie er den Bildschirm scrollt. Solche Dinge werden zum Beispiel von Yandex.Metrica gesammelt. , , .
, . ? , , , , . , . machine learning, decision tree, . Decision tree if-else, , . , . - , - — , , .
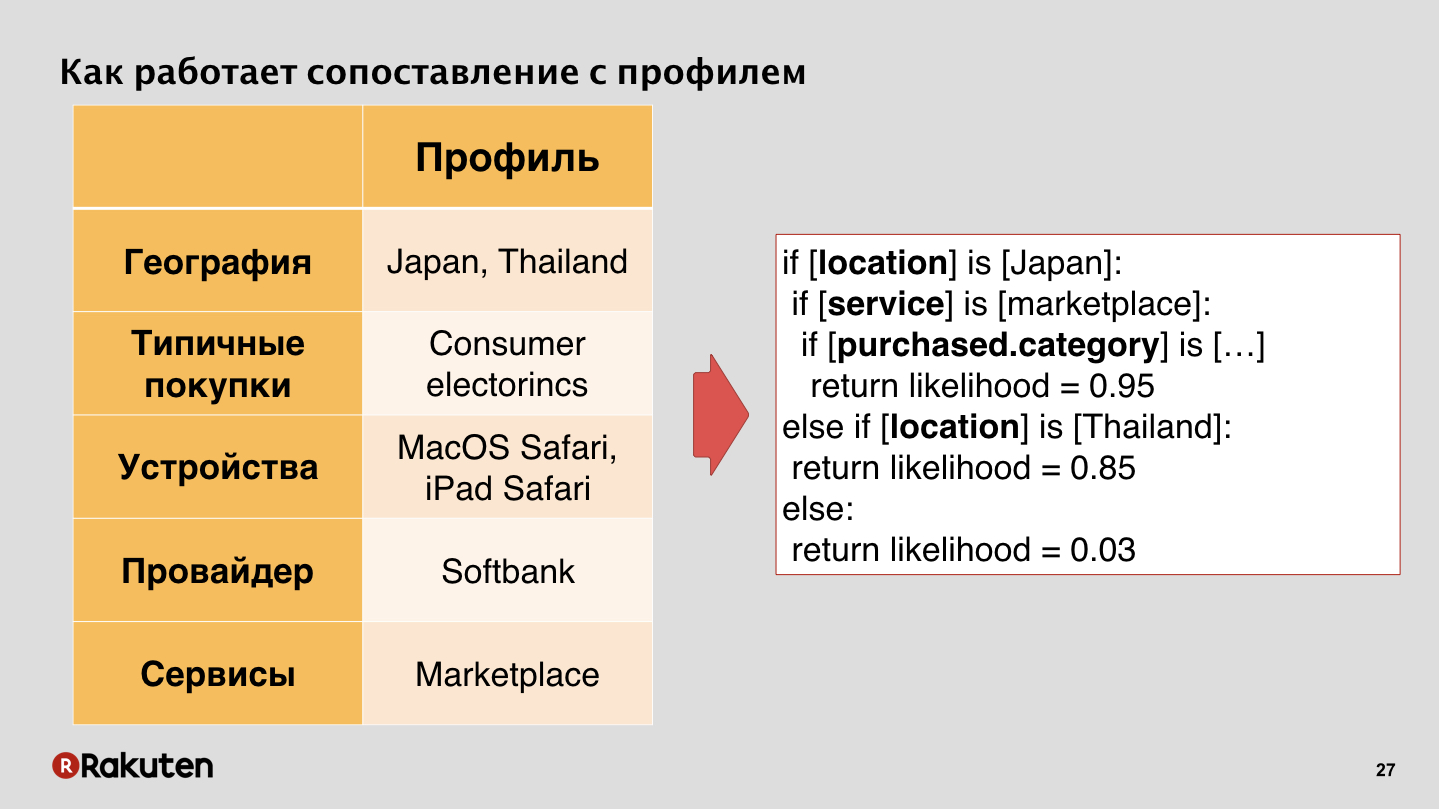
, , , - , , , Softbank, . , , . - , , , .
, , iTunes — , - , .
, , , .

. , ? , . , , , . , .
. , . . : . , .