 Montezumas Revenge Atari-Spiellevel
Montezumas Revenge Atari-SpiellevelDeepMind
demonstrierte den Prozess des Lernens der KI (ihrer schwachen Form) für das Weitergeben von Spielen auf Atari. Das Training wurde durchgeführt, indem das Videospiel-Passing-System von YouTube demonstriert wurde. Diese Methode wird von vielen menschlichen Spielern verwendet, die aus dem einen oder anderen Grund nicht durch ein Spiel kommen konnten.
Um dieses Problem zu lösen, ist es normalerweise erforderlich, die sogenannte
Verstärkungslernmethode zu verwenden. Diese Technik ist sehr beliebt, da Sie damit Bots trainieren können, um verschiedene spezifische Aufgaben auszuführen. Sobald das System ein Ergebnis erzielt, erhält es eine kleine Belohnung.
Entwickler erstellen Algorithmen und Modelle, mit denen die Spielumgebung bewertet werden kann, einschließlich möglicher Belohnungen für das Abschließen (Punkte, Boni usw.). Solche Systeme lernen das Spiel Schritt für Schritt und gelangen schrittweise zum Finale.
Die in DeepMind entwickelte neue Methode unterscheidet sich von allen anderen. Die Spezialisten des Unternehmens konnten KI trainieren, um Spiele unter Atari wie Montezumas Revenge, Pitfall und Private Eye zu spielen. Gleichzeitig wurde nicht auf Punkte und Preise Wert gelegt - das Training wurde anhand von Tutorials von YouTube durchgeführt. Dadurch konnten wir ungewöhnliche Ergebnisse für die KI erzielen.
Tatsache ist, dass Spiele wie das gleiche Montezumas Revenge für Maschinen schwer zu „verstehen“ sind. Es gibt keine klare Aufgabe, es ist nicht klar, wohin es gehen soll, welche Gegenstände gesammelt werden sollen und was in Zukunft damit zu tun ist. Die Maschine geht einfach verloren, weil sie im Aufstiegsprozess keine Belohnungen erhält und das Training mit Verstärkungen hier nutzlos oder fast nutzlos wird.
In dem fraglichen Spiel musst du einen Charakter namens Panama Joe kontrollieren. Am Ende muss er zur Schatzkammer im alten Tempel gelangen. Der Legende nach gehören diese Schätze Montezuma. Zuerst müssen Sie den ersten kritischen Gegenstand finden, um das Spiel zu bestehen - den goldenen Schlüssel. Um es zu erkennen, müssen Sie ungefähr 100 Schritte durchlaufen. Aber das ist, wenn Sie wissen, was zu tun ist. Wenn nicht, gibt es eine Vielzahl von Möglichkeiten 100 der
18 ersten Aktionen. Dies ist zu viel für jede vom Menschen geschaffene KI. Nun, Sie werden hier keine Belohnung erhalten, alles ist sehr, sehr spezifisch.
Eine Möglichkeit, den Computer wissen zu lassen, was zu tun ist, besteht darin, die Szenarien der Passage zu demonstrieren. Tatsächlich lernen nicht nur Autos, sondern auch Menschen, anhand von Beispielen verschiedene Aufgaben zu erledigen. Tanzen, die Aktionen des Künstlers, Löten - all dies ist am besten einmal zu sehen und nicht 100 Mal, um zu hören, wie es geht.
DeepMind kam zu dem Schluss, dass dies der beste Weg ist, dem Computer zu zeigen, wie eine Aufgabe mit einem impliziten Ergebnis ausgeführt werden kann. Die von Experten entwickelte Technologie hat wirklich geholfen. Für das Lehren des Beispiels wurden zwei Methoden verwendet: TDC (zeitliche Entfernungsklassifizierung) und CDC (crossmodale zeitliche Entfernungsklassifizierung).
Im ersten Fall werden AIs trainiert, um die Entfernung in der Spielumgebung zu bestimmen und den Unterschied zwischen zwei verschiedenen Frames festzustellen. AI „versteht“ auch, was getan werden muss, um von einem Ort zum anderen zu gelangen. Für das Training auf YouTube werden Videos Bildpaare in zufälliger Reihenfolge zugewiesen.
Im zweiten Fall wird auch das „Verständnis“ der Klangbegleitung hinzugefügt. Sounds in fast allen Spielen entsprechen der Leistung bestimmter Aktionen. Zum Beispiel springen, Gegenstände holen usw. Auf diese Weise wird der Computer darauf trainiert, Geräusche als wichtige Spielelemente wahrzunehmen. Mit Video + Sound kann der Computer beim Übergeben des Spiels ziemlich gut abschneiden.
Hier sind die Aktionen der trainierten KI in Montezumas Rache. Die Passage der beiden anderen Spiele, die ganz am Anfang erwähnt wurden, ist
hier .
Zwar war es nicht möglich, die Rolle der Belohnungen vollständig aufzugeben - bis jetzt hängt die KI von denselben Punkten ab. Die übliche Methode des Lehrens des Systems, die früher angewendet wurde, erlaubte es jedoch nicht, zumindest den goldenen Schlüssel zu erreichen, für den die ersten hundert Punkte vergeben werden. Also stocherte AI wie ein blindes Kätzchen in alle Richtungen und verstand nicht, was zu tun war. Das "Verstärkungssystem" wurde zwar ebenfalls modifiziert.
Beim Übergeben jedes 16. Video-Frames des AI-Game-Passing-Datensatzes wird es mit den Frames des Videos verglichen, das das Spiel von Personen passiert. Wenn der Vergleich einen hohen Grad an Ähnlichkeit zeigt, erhält die KI eine Belohnung. Im Laufe der Zeit beginnt die KI, dieselbe Abfolge von Aktionen wie eine Person auszuführen, um einen ähnlichen Rahmen zu erhalten.
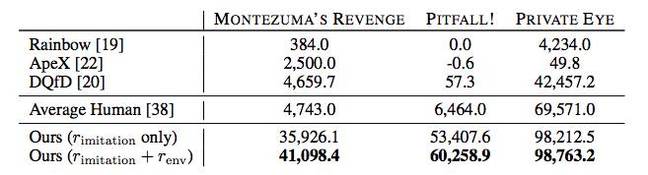
Darüber hinaus zeigt AI in vielen Fällen bessere Ergebnisse als menschliche Spieler oder andere Passing-Algorithmen, einschließlich Rainbow, ApeX und DQfD.
Im Prinzip ist das alles beeindruckend, aber bisher sind die praktischen Vorteile der Erfolge von DeepMind unklar. Ist es möglich, die vom Unternehmen vorgeschlagene Methode des KI-Unterrichts anderswo anzuwenden, als alte Spiele zu bestehen? Wenn man jedoch die Errungenschaften von DeepMind auf dem Gebiet der KI kennt, besteht kein Zweifel daran, dass all dies auf die eine oder andere Weise für praktische Zwecke genutzt werden kann - es ist unwahrscheinlich, dass Experten aus Gründen des "Spaßes" mit der Arbeit an dem Thema beginnen.