Dieser Blog ist normalerweise der Kennzeichenerkennung gewidmet. Bei der Arbeit an dieser Aufgabe kamen wir jedoch zu einer interessanten Lösung, die leicht auf eine Vielzahl von Computer-Vision-Aufgaben angewendet werden kann. Wir werden jetzt darüber sprechen: Wie man ein Erkennungssystem erstellt, das Sie nicht im Stich lässt. Und wenn Sie versagen, können Sie ihr sagen, wo der Fehler liegt, sich weiterbilden und eine etwas zuverlässigere Lösung als zuvor finden. Willkommen bei Katze!

Was ist passiert?
Stellen Sie sich vor, Sie standen vor der Aufgabe, auf dem Foto Pizza zu finden und festzustellen, um welche Art von Pizza es sich handelt.
Lassen Sie uns kurz den Standardweg durchgehen, den wir oft gegangen sind. Warum? Um zu verstehen, wie es geht ... keine Notwendigkeit.
Schritt 1: Heben Sie die Basis auf
 Schritt 2:
Schritt 2: Für die Zuverlässigkeit der Erkennung kann festgestellt werden, dass es Pizza gibt und was der Hintergrund ist (daher werden wir ein neuronales Segmentierungsnetzwerk in das Erkennungsverfahren einbeziehen, aber es lohnt sich oft):
 Schritt 3:
Schritt 3: Wir bringen es in eine „normalisierte Form“ und klassifizieren es unter Verwendung eines anderen neuronalen Faltungsnetzwerks:

Großartig! Jetzt haben wir eine Trainingsbasis. Im Durchschnitt kann die Größe der Trainingsbasis mehrere tausend Bilder betragen.
Wir nehmen 2 Faltungsnetzwerke, zum Beispiel Unet und VGG. Das erste wird an den Eingabebildern trainiert, dann normalisieren wir das Bild und trainieren die VGG für die Klassifizierung. Es funktioniert großartig, wir übertragen es an den Kunden und betrachten ehrlich verdientes Geld.
So funktioniert das nicht!
Leider fast nie. Bei der Implementierung treten mehrere schwerwiegende Probleme auf:
- Variabilität der Eingabedaten. Wir haben an einem Beispiel studiert, in Wirklichkeit ist alles anders gelaufen. Ja, gerade während des Betriebs ist etwas schief gelaufen.
- Sehr oft bleibt die Erkennungsgenauigkeit unzureichend. Ich möchte 99,5%, aber an einem guten Tag geht es von 60% auf 90%. Aber sie wollten in der Regel eine Lösung automatisieren, die selbst funktioniert und sogar besser als Menschen!
- Solche Aufgaben werden häufig ausgelagert, was bedeutet, dass die Verträge bereits geschlossen sind, die Gesetze unterzeichnet sind und der Geschäftsinhaber entscheiden muss, ob er in die Überarbeitung investiert oder die Entscheidung ganz aufgibt.
- Ja, es beginnt sich mit der Zeit zu verschlechtern, wie in jedem komplexen System, wenn Sie keine Spezialisten einbeziehen, die an der Erstellung beteiligt waren, oder das gleiche Qualifikationsniveau.
Infolgedessen wird für viele, die all diese Mechanik mit den Händen berührt haben, klar, dass alles auf eine völlig andere Weise geschehen sollte. Ungefähr so:
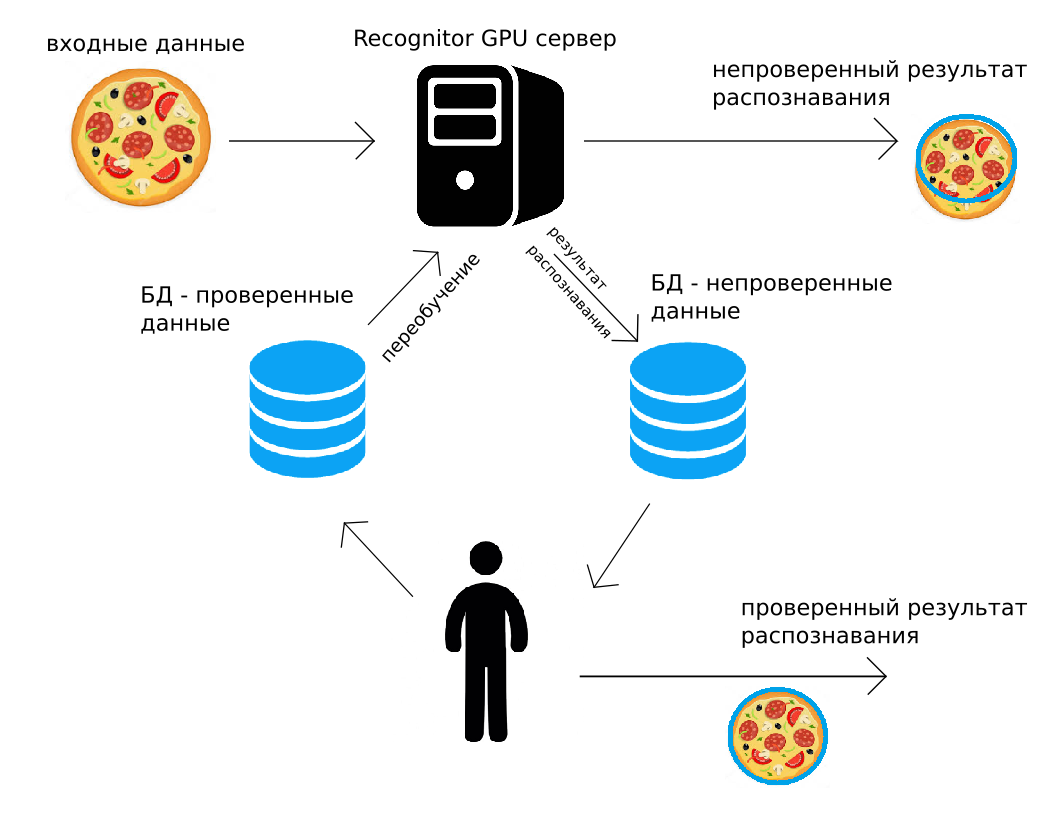
Daten werden an unseren Server gesendet (über http POST oder mithilfe der Python-API). Der GPU-Server erkennt sie "wie es könnte" und gibt das Ergebnis sofort zurück. Unterwegs wird das gleiche Erkennungsergebnis zusammen mit dem Bild zum Archiv hinzugefügt. Eine Person kontrolliert dann alle Daten oder einen zufälligen Teil davon und korrigiert sie. Das korrigierte Ergebnis wird in das zweite Archiv gestellt. Und wenn dies zweckmäßig ist (z. B. nachts), werden alle zur Erkennung verwendeten neuronalen Faltungsnetzwerke unter Verwendung der von der Person korrigierten Daten umgeschult.
Eine solche Erkennungsschaltung, menschliche Überwachung und Weiterbildung lösen viele der oben aufgeführten Probleme. Darüber hinaus kann in Lösungen, in denen eine hohe Genauigkeit erforderlich ist, eine vom Menschen verifizierte Ausgabe verwendet werden. Es scheint, dass diese Verwendung von vom Menschen verifizierten Daten zu kostspielig ist, aber wir werden weiter zeigen, dass sie fast immer wirtschaftlich sinnvoll ist.
Echtes Beispiel
Wir haben das beschriebene Prinzip umgesetzt und erfolgreich auf mehrere reale Aufgaben angewendet. Eine davon ist die Erkennung von Zahlen auf Bildern von Containern in Eisenbahnterminals, die von einem Tablet stammen. Es ist sehr praktisch - richten Sie das Tablet auf den Behälter, erhalten Sie die erkannte Nummer und arbeiten Sie damit im Tablet-Programm.
Ein typisches Schnappschuss-Beispiel:

Auf dem Bild ist die Zahl fast perfekt, nur viel visuelles Rauschen. Bei Aufnahmen treten jedoch scharfe Schatten, Schnee, unerwartete Beschriftungslayouts, ernsthafte Neigungen oder Perspektiven auf.
Und so sieht es aus wie eine Reihe von Webseiten, auf denen all die „Magie“ geschieht:
1) Hochladen der Datei auf den Server (dies kann natürlich nicht über die HTML-Seite erfolgen, sondern mit Python oder einer anderen Programmiersprache):
2) Der Server gibt das Erkennungsergebnis zurück:
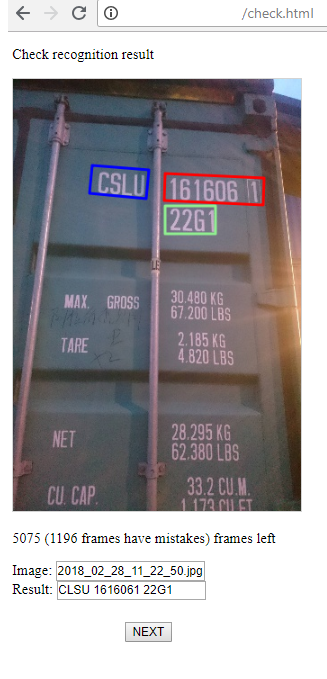
3) Und dies ist eine Seite für den Bediener, der den Erfolg der Erkennung überwacht und gegebenenfalls das Ergebnis korrigiert. Es gibt zwei Stufen: die Suche nach Bereichen von Symbolgruppen, deren Erkennung. Der Bediener kann dies alles korrigieren, wenn er einen Fehler sieht.
4) Hier ist eine einfache Seite, auf der Sie mit dem Training für jede der Erkennungsstufen beginnen und durch Ausführen den aktuellen Verlust anzeigen können.
Harter Minimalismus, aber es funktioniert großartig!
Wie kann dies von der Seite eines Unternehmens aussehen, das plant, den beschriebenen Ansatz (oder unsere Erfahrung und Recognitor-Server) zu verwenden?
- Es werden hochmoderne neuronale Netze ausgewählt. Wenn alles auf vorhandenen Debug-Lösungen basiert, können Sie den Server starten und das Markup in einer Woche konfigurieren.
- Auf dem Server ist ein Datenstrom (vorzugsweise endlos) organisiert, mehrere hundert Frames sind markiert.
- Das Training beginnt. Wenn alles „passt“, ist das Ergebnis 60-70% der erfolgreichen Erkennung, was bei der weiteren Kennzeichnung sehr hilfreich ist.
- Dann beginnt die systematische Arbeit, alle möglichen Situationen darzustellen, die Erkennungsergebnisse zu überprüfen, zu bearbeiten und umzuschulen. Wie Sie lernen, wird die Einbettung des Systems in einen Geschäftsprozess immer kostengünstiger.
Wer macht das noch?
Das Closed-Loop-Thema ist nicht neu. Viele Unternehmen bieten Datenverarbeitungssysteme der einen oder anderen Art an. Das Arbeitsparadigma kann jedoch auf ganz andere Weise aufgebaut werden:
- Nvidia Digits sind einige ziemlich gute und leistungsstarke Modelle, die in eine intuitive Benutzeroberfläche eingebunden sind, in der der Benutzer seine Bilder und JSON anhängen muss. Das Hauptplus - ein Minimum an Programmier- und Verwaltungskenntnissen bietet Ihnen eine gute Lösung. Minus - diese Lösung kann bei weitem nicht optimal sein (zum Beispiel ist es nicht möglich, über SSD gut nach Autonummern zu suchen). Und um zu verstehen, wie die Lösung optimiert werden kann, verfügt der Benutzer nicht über ausreichende Kenntnisse. Wenn er genug Wissen hat, braucht er keine Ziffern. Das zweite Minus: Sie benötigen Ihre eigene Ausrüstung, um alles zu konfigurieren und bereitzustellen.
- Markup-Services wie Mechanical Turk, Toloka, Supervise.ly. Die ersten beiden bieten Ihnen Markup-Tools sowie Personen, die die Daten markieren können. Letzteres bietet großartige Werkzeuge, aber ohne Menschen. Durch Services können Sie die menschliche Arbeit automatisieren, müssen jedoch ein Experte für die Festlegung der Aufgabe sein.
- Unternehmen, die bereits geschult sind und eine feste Lösung anbieten (Microsoft, Google, Amazon). Lesen Sie hier mehr darüber (https://habr.com/post/312714/). Ihre Entscheidungen sind nicht flexibel, nicht immer "unter der Haube" sind die besten Entscheidungen, die in Ihrem Fall notwendig sind. Im Allgemeinen hilft es fast immer nicht.
- Unternehmen, die speziell mit Ihren Daten arbeiten, z. B. ScaleAPI (https://www.scaleapi.com/). Sie haben eine großartige API, für den Kunden wird es eine Black Box sein. Eingabedaten - Ausgabeergebnis. Es ist sehr wahrscheinlich, dass sich im Inneren die besten Automatisierungslösungen befinden, aber das spielt für Sie keine Rolle. Ziemlich teure Lösungen in Bezug auf einen Frame, aber wenn Ihre Daten wirklich wertvoll sind - warum nicht?
- Unternehmen, die über die Werkzeuge verfügen, um einen fast vollständigen Zyklus mit ihren eigenen Händen durchzuführen. Zum Beispiel PowerAI von IBM . Es ist fast wie bei DIGITS, aber Sie müssen nur die Datensätze markieren. Außerdem optimiert niemand neuronale Netze und Lösungen. Aber viele Fälle wurden ausgearbeitet. Das resultierende neuronale Netzwerkmodell wird für Sie bereitgestellt und erhält http-Zugriff. Hier gibt es den gleichen Nachteil wie bei Digits - Sie müssen verstehen, was zu tun ist. Es ist Ihr Fall, der möglicherweise „nicht konvergiert“ oder einfach einen ungewöhnlichen Ansatz zur Erkennung erfordert. Im Allgemeinen ist die Lösung perfekt, wenn Sie eine ziemlich normale Aufgabe mit gut trennbaren Objekten haben, die klassifiziert werden müssen.
- Unternehmen, die mit ihren Tools genau Ihr Problem lösen. Es gibt nicht viele solcher Unternehmen. In Wirklichkeit würde ich nur CrowdFlower auf sie verweisen. Hier werden sie für angemessenes Geld Scribbler einsetzen, einen Manager zuweisen und ihre Server bereitstellen, auf denen Ihre Modelle gestartet werden. Und für mehr Geld können sie ihre Entscheidungen für Ihre Aufgabe ändern oder optimieren.
Große Unternehmen arbeiten mit ihnen zusammen - ebay, oracle, tesco, adobe. Gemessen an ihrer Offenheit interagieren sie erfolgreich mit kleinen Unternehmen.
Wie unterscheidet sich dies von der benutzerdefinierten Entwicklung, die beispielsweise EPAM durchführt? Dass hier alles fertig ist. 99% der Lösung wird nicht geschrieben, sondern aus vorgefertigten Modulen zusammengesetzt: Datenmarkup, Netzwerkauswahl, Schulung, Entwicklung. Unternehmen, die sich auf Bestellung entwickeln, verfügen nicht über eine solche Geschwindigkeit, die Dynamik der Lösungsentwicklung und die fertige Infrastruktur. Wir glauben, dass der von CrowdFlower identifizierte Trend und Ansatz wahr ist.
Für welche Aufgaben funktioniert das?
Möglicherweise werden 70% der Aufgaben auf diese Weise automatisiert. Die am besten geeigneten Aufgaben sind die vielfältige Erkennung von Bereichen, die Text enthalten. Zum Beispiel Autokennzeichen, über die wir
bereits gesprochen haben , Zugnummern (
hier ist unser Beispiel vor zwei Jahren ), Inschriften auf Containern.

In Fabriken werden viele symbolische technische Informationen erkannt, um Produkte und deren Qualität zu berücksichtigen.
Dieser Ansatz hilft sehr beim Erkennen von Produkten in Verkaufsregalen und Preisschildern, obwohl dort recht komplizierte Erkennungslösungen erstellt werden müssen.

Mit technischen Informationen können Sie sich jedoch den Aufgaben entziehen. Jede Semantik, sei es Instanzsegmentierung, mit der Erkennung von Autos, Argali, Elchen und Pelzrobben wird ebenfalls perfekt auf diesen Ansatz fallen.

Eine vielversprechende Richtung ist die Aufrechterhaltung der Kommunikation mit Personen in Sprach- und Text-Chat-Bots. Es wird eine eher ungewöhnliche Art der Kennzeichnung geben: Kontext, Art der Phrase, ihre „Füllung“. Das Prinzip ist jedoch dasselbe: Wir arbeiten in einem automatischen Modus, eine Person kontrolliert die Richtigkeit des Verstehens und der Antworten. Bei unzufriedenem oder irritiertem Ton des Kunden können Sie auf die Unterstützung des Bedieners zurückgreifen. Wenn sich Daten ansammeln, trainieren wir neu.
Wie arbeite ich mit Video?
Wenn Sie oder Ihr Unternehmen die erforderlichen Kompetenzen entwickelt haben (ein wenig Erfahrung im maschinellen Lernen, Arbeiten mit dem Zoo Framework, sowohl offline als auch online), gibt es keine Schwierigkeiten bei der Lösung einfacher Computer-Vision-Probleme: Segmentierung, Klassifizierung, Texterkennung und andere
Aber für das Video ist nicht alles so glatt. Wie markieren Sie diese endlosen Datenmengen? Beispielsweise kann sich herausstellen, dass alle paar Sekunden ein Objekt (oder mehrere Objekte) in dem Rahmen angezeigt wird, der markiert werden muss. Infolgedessen kann all dies zu einer Einzelbildanzeige werden und nimmt so viele Ressourcen in Anspruch, dass man nach dem Start einer Lösung nicht einmal über zusätzliche Kontrolle durch eine Person sprechen muss. Dies kann jedoch überwunden werden, wenn Sie das Video richtig präsentieren, um Bilder mit einem interessierenden Bereich hervorzuheben.
Zum Beispiel stießen wir auf riesige Videoserien, in denen ein bestimmtes Objekt hervorgehoben werden musste - die Kopplung der Bahnsteige. Und es war wirklich nicht einfach. Es stellte sich heraus, dass nicht alles so beängstigend ist. Wenn Sie den Monitor weiter nehmen, wählen Sie eine Bildrate, z. B. 10 fps, und platzieren Sie 256 Bilder auf einem Bild, d. H. 25,6 s in einem Bild:

Es sieht wahrscheinlich beängstigend aus. In der Realität dauert es jedoch ungefähr 15 Sekunden, bis Sie zu einem einzelnen Rahmen durchgeklickt sind und die Mitte der Fahrzeugkupplung auf dem Rahmen ausgewählt haben. Und selbst eine Person an ein oder zwei Tagen kann mindestens 10 Stunden Video markieren. Holen Sie sich mehr als 30.000 Beispiele für das Training. Darüber hinaus ist der Durchgang von Plattformen vor der Kamera in diesem Fall kein fortlaufender Prozess (aber eher selten, sollte angemerkt werden), es ist sogar in fast Echtzeit ziemlich realistisch, die Erkennungsmaschine zu korrigieren und die Trainingsbasis aufzufüllen! Und wenn die Erkennung in den meisten Fällen korrekt erfolgt, kann eine Stunde Video in wenigen Minuten überwunden werden. Und dann ist es wirtschaftlich nicht rentabel, die totale Kontrolle durch die Person zu vernachlässigen.
Es ist immer noch einfacher, wenn das Video mit „Ja / Nein“ markiert werden muss, anstatt das Objekt zu lokalisieren. Schließlich bleiben Ereignisse oft „zusammengeklebt“, und mit einem Mausklick können Sie bis zu 16 Bilder gleichzeitig markieren.
Das einzige, was Sie in der Regel bei der Analyse des Videos in zwei Schritten tun müssen: Suchen Sie nach „Frames oder Bereichen von Interesse“ und arbeiten Sie dann mit jedem solchen Frame (oder jeder Frame-Sequenz) nach anderen Algorithmen.
Maschinen-Mensch-Wirtschaft
Wie viel können die Kosten für die Verarbeitung visueller Daten optimiert werden? Auf die eine oder andere Weise ist es unbedingt erforderlich, eine Person zur Kontrolle der Datenerkennung zu haben. Wenn diese Kontrolle selektiv ist, sind die Kosten vernachlässigbar. Aber wenn wir über totale Kontrolle sprechen, wie viel kann es dann von Vorteil sein? Es stellt sich heraus, dass dies fast immer Sinn macht, wenn zuvor eine Person dieselbe Aufgabe ohne die Hilfe einer Maschine ausgeführt hat.
Nehmen wir ganz am Anfang das nicht beste Beispiel: Suche nach Pizza im Bild, Markup und Typauswahl (und in Wirklichkeit eine Reihe anderer Merkmale). Obwohl die Aufgabe nicht so synthetisch ist, wie es scheinen mag. Es gibt eine Kontrolle über das Erscheinungsbild von Franchise-Netzwerkprodukten in der Realität.
Angenommen, die Erkennung mit einem GPU-Server erfordert 0,5 Sekunden Maschinenzeit, damit eine Person einen Rahmen für etwa 10 Sekunden vollständig markiert (wählen Sie die Art der Pizza und ihre Qualität anhand einer Reihe von Parametern) und um zu überprüfen, ob alles vom Computer korrekt erkannt wird, benötigen Sie 2 Sekunden. Natürlich wird es eine Herausforderung sein, wie bequem es ist, diese Daten zu präsentieren, aber solche Zeiten sind mit unserer Praxis durchaus vergleichbar.
Wir benötigen mehr Input für die Kosten für das manuelle Layout und die Miete eines GPU-Servers. In der Regel müssen Sie sich nicht auf eine vollständige Serverlast verlassen. Ermöglichen Sie das Laden von 100.000 Frames pro Tag (60% der Verarbeitungsleistung einer GPU) mit geschätzten Kosten für eine monatliche Servermiete von 60.000 Rubel. Es ergeben sich 2 Cent für die Analyse eines Frames auf der GPU. Eine manuelle Analyse zu einem Preis von 30.000 R für 40 Stunden Arbeitszeit kostet 26 Kopeken pro Frame.
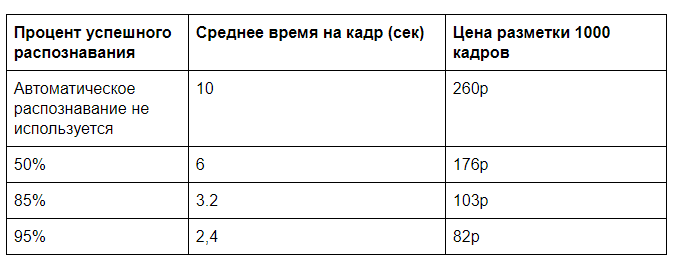
Wenn Sie anschließend die Gesamtsteuerung entfernen, können Sie einen Preis von fast 20 Rubel pro 1000 Frames erzielen. Wenn viele Eingabedaten vorhanden sind, ist es möglich, Erkennungsalgorithmen zu optimieren, an der Datenübertragung zu arbeiten und eine noch höhere Effizienz zu erzielen.
In der Praxis hat das Entladen einer Person, während das Erkennungssystem lernt, eine weitere wichtige Bedeutung: Es erleichtert die Skalierung Ihres Produkts erheblich. Durch eine deutliche Erhöhung der Datenmenge können Sie den Erkennungsserver besser trainieren und die Genauigkeit erhöhen. Und die Anzahl der am Datenverarbeitungsprozess beteiligten Mitarbeiter wird nicht proportional zum Datenvolumen zunehmen, was das Wachstum des Unternehmens aus organisatorischer Sicht erheblich vereinfachen wird.
Je mehr Text und Umrisse Sie manuell eingeben müssen, desto rentabler ist in der Regel die automatische Erkennung.
Und ändert sich alles?
Natürlich nicht alle. Aber jetzt sind einige Bereiche des Geschäfts nicht mehr so verrückt wie zuvor.
Möchten Sie einen Offline-Dienst ohne eine Person in der Einrichtung durchführen? Pflanzen Sie einen Bediener aus der Ferne und überwachen Sie ihn
auf Kameras für jeden Kunden? Es wird sich als etwas schlimmer herausstellen als eine lebende Person an Ort und Stelle. Ja, und die Betreiber brauchen fast mehr. Und wenn Sie den Bediener alle 5 Mal entladen? Dies kann ein Schönheitssalon ohne Empfang und Kontrolle in der Fabrik sowie Sicherheitssysteme sein. Eine 100% ige Genauigkeit ist nicht erforderlich - Sie können den Bediener vollständig von der Kette ausschließen.
Es ist möglich, recht komplexe Buchhaltungssysteme für vorhandene Dienste zu organisieren, um deren Effizienz zu steigern: Kontrolle von Fahrgästen, Fahrzeugen, Dienstzeiten, bei denen die Gefahr besteht, dass das Ticketbüro umgangen wird usw.
Wenn sich die Aufgabe auf dem aktuellen Entwicklungsstand von Computer Vision befindet und keine völlig neuen Lösungen erfordert, sind keine ernsthaften Investitionen in die Entwicklung erforderlich.