Hinzugefügt von: gute Diskussion über Hacker NewsDavid Yu auf GitHub hat einen
interessanten Leistungstest für Funktionsaufrufe über verschiedene externe Schnittstellen (Foreign Function Interfaces,
FFI ) entwickelt.
Er erstellte eine gemeinsam genutzte Objektdatei (
.so ) mit einer einfachen C-Funktion. Dann schrieb er Code, um diese Funktion wiederholt über jedes FFI mit einer Zeitdimension aufzurufen.
Für C „FFI“ verwendete er die standardmäßige dynamische Verknüpfung, nicht
dlopen() . Dieser Unterschied ist sehr wichtig, da er die Testergebnisse wirklich beeinflusst. Sie können argumentieren, wie ehrlich dieser Vergleich mit dem tatsächlichen FFI ist, aber es ist immer noch interessant zu messen.
Das überraschendste Benchmark-Ergebnis ist, dass
der FFI von
LuaJIT deutlich schneller ist als C. Es ist ungefähr 25% schneller als ein nativer C-Aufruf für eine gemeinsam genutzte Objektfunktion. Wie könnte eine schwach und dynamisch typisierte Skriptsprache in Benchmark C überholen? Ist das Ergebnis korrekt?
In der Tat ist dies ziemlich logisch. Der Test läuft unter Linux, daher stammt die Verzögerung aus der Procedure Linkage Table (PLT). Ich habe ein wirklich einfaches Experiment vorbereitet, um den Effekt in einfachem alten C zu demonstrieren:
https://github.com/skeeto/dynamic-function-benchmarkHier sind die Ergebnisse des Intel i7-6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/callEs gibt drei verschiedene Arten von Funktionsaufrufen:
- Über PLT.
- Indirekter Funktionsaufruf (via
dlsym(3) ) - Direkter Funktionsaufruf (über eine JIT-kompilierte Funktion)
Wie Sie sehen können, ist letzteres das schnellste. Es wird normalerweise nicht in C-Programmen verwendet, ist jedoch eine natürliche Option, wenn ein JIT-Compiler vorhanden ist, einschließlich natürlich LuaJIT.
In meinem Benchmark heißt die Funktion
empty() :
void empty(void) { }
Kompilieren Sie zu einem freigegebenen Objekt:
$ cc -shared -fPIC -Os -o empty.so empty.c
Wie im vorherigen
PRNG-Vergleich ruft der Benchmark diese Funktion so oft wie möglich auf, bevor der Alarm ausgelöst wird.
Prozedur Layout-Tabellen
Wenn ein Programm oder eine Bibliothek eine Funktion in einem anderen gemeinsam genutzten Objekt aufruft, kann der Compiler nicht wissen, wo sich diese Funktion im Speicher befindet. Informationen werden nur zur Laufzeit ermittelt, wenn das Programm und seine Abhängigkeiten in den Speicher geladen werden. Normalerweise befindet sich die Funktion an zufälligen Stellen, beispielsweise gemäß der Randomisierung des Adressraums (Address Space Layout Randomization, ASLR).
Wie kann man ein solches Problem lösen? Nun, es gibt mehrere Möglichkeiten.
Eine davon besteht darin, jeden Aufruf in binären Metadaten zu markieren. Der Builder für dynamische Laufzeit
fügt dann bei jedem Aufruf
die richtige Adresse ein. Der spezifische Mechanismus hängt vom
Codemodell ab , das während der Kompilierung verwendet wurde.
Der Nachteil dieses Ansatzes besteht darin, dass er das Laden verlangsamt, die Größe von Binärdateien erhöht und den
Austausch von Codepages zwischen verschiedenen Prozessen verringert. Das Herunterladen wird verlangsamt, da alle Peers mit dynamischer Wahl vor dem Starten des Programms mit der richtigen Adresse gepatcht werden müssen. Die Binärdatei ist aufgebläht, da jeder Eintrag einen Platz in der Tabelle benötigt. Und das Fehlen einer Freigabe ist mit einer Änderung der Codepages verbunden.
Auf der anderen Seite kann der Aufwand für das Aufrufen dynamischer Funktionen entfallen, was zu einer JIT-ähnlichen Leistung führt, wie im Benchmark gezeigt.
Die zweite Option besteht darin, alle dynamischen Anrufe über eine Tabelle weiterzuleiten. Der ursprüngliche Dial Peer bezieht sich auf den Stub in dieser Tabelle und von dort auf die eigentliche dynamische Funktion. Bei diesem Ansatz muss der Code nicht gepatcht werden, was zu einem
trivialen Austausch zwischen Prozessen führt. Für jede dynamische Funktion müssen Sie nur einen Datensatz in der Tabelle patchen. Darüber hinaus können diese Korrekturen beim ersten Aufruf der Funktion
träge vorgenommen werden, was das Laden noch weiter beschleunigt.
Auf ELF-Binärsystemen wird diese Tabelle als Procedure Linkage Table (PLT) bezeichnet. PLT selbst wird nicht wirklich korrigiert - es wird für den Rest des Codes als schreibgeschützt angezeigt. Stattdessen wird die Global Offset Table (GOT) korrigiert. Der PLT-Stub ruft die Adresse einer dynamischen Funktion vom GOT ab und springt
indirekt zu dieser Adresse. Um Funktionsadressen träge zu laden, werden diese GOT-Einträge mit der Adresse der Funktion initialisiert, die das Zielzeichen findet, die GOT mit dieser Adresse aktualisiert und dann mit der Funktion fortfährt. Nachfolgende Anrufe verwenden eine träge erkannte Adresse.
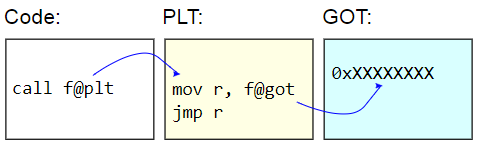
Der Nachteil von PLT ist der zusätzliche Aufwand für das Aufrufen einer dynamischen Funktion, wie er im Benchmark angegeben wurde. Da der Benchmark
nur Funktionsaufrufe misst, scheint der Unterschied ziemlich signifikant zu sein, in der Praxis liegt er jedoch normalerweise nahe bei Null.
Hier ist der Benchmark:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
Da sich
empty() in einem gemeinsam genutzten Objekt befindet, durchläuft der Aufruf die PLT.
Indirekte dynamische Anrufe
Eine andere Möglichkeit, Funktionen dynamisch aufzurufen, besteht darin, die PLT zu durchlaufen und die Adresse der Zielfunktion im Programm beispielsweise über
dlsym(3) .
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
Wenn die Funktionsadresse empfangen wird, sind die Kosten geringer als die Funktionsaufrufe über PLT. Es gibt keine Zwischenfunktion für Stub und Zugriff auf GOT. (Achtung: Wenn das Programm einen PLT-Datensatz für diese Funktion hat, kann
dlsym(3) tatsächlich eine Stub-Adresse zurückgeben.)
Dies ist jedoch immer noch eine
indirekte Herausforderung. Bei herkömmlichen Architekturen erhalten
direkte Funktionsaufrufe ihre unmittelbare relative Adresse. Das heißt, der Zweck des Anrufs ist ein fest codierter Versatz vom Anrufpunkt. Die CPU kann viel früher herausfinden, wohin der Anruf führen wird.
Indirekte Anrufe haben mehr Overhead. Zunächst muss die Adresse irgendwo gespeichert werden. Selbst wenn es sich nur um ein Register handelt, erhöht seine Verwendung das Registerdefizit. Zweitens provozieren indirekte Aufrufe einen Verzweigungsprädiktor in der CPU, wodurch der Prozessor zusätzlich belastet wird. Im schlimmsten Fall kann ein Aufruf sogar dazu führen, dass die Pipeline gestoppt wird.
Hier ist der Benchmark:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
Die an diesen Benchmark übergebene Funktion wird mit
dlsym(3) extrahiert, sodass der Compiler keine
schwierigen dlsym(3) kann, z. B. die Konvertierung dieses indirekten
dlsym(3) in einen direkten Aufruf.
Wenn der Schleifenkörper komplex genug ist, um ein Registerdefizit zu verursachen und damit dem Stapel die Adresse zu geben, kann dieser Benchmark auch nicht ehrlich mit dem PLT-Benchmark verglichen werden.
Direkte Funktionsaufrufe
Die ersten beiden Arten von dynamischen Funktionsaufrufen sind einfach und benutzerfreundlich.
Direkte Aufrufe für dynamische Funktionen sind schwieriger zu organisieren, da sie während der Ausführung Codeänderungen erfordern. In meinem Benchmark habe ich einen
kleinen JIT-Compiler zusammengestellt , um einen direkten Aufruf zu generieren.
Der Trick besteht darin, dass bei x86-64 explizite Übergänge aufgrund des 32-Bit-Operanden mit Vorzeichen (sofort signiert) auf einen Bereich von 2 GB beschränkt sind. Dies bedeutet, dass der JIT-Code fast neben der Zielfunktion
empty() . Wenn der JIT-Code zwei verschiedene dynamische Funktionen aufrufen muss, die durch mehr als 2 GB geteilt werden, ist es unmöglich, zwei direkte Anrufe zu tätigen.
Um die Situation zu vereinfachen, ist mein Benchmark nicht besorgt über die genaue oder sehr sorgfältige Auswahl der Adresse des JIT-Codes. Nach dem Empfang der Adresse der Zielfunktion werden einfach 4 MB subtrahiert, auf die nächste Seite gerundet, ein wenig Speicher zugewiesen und Code darauf geschrieben. Wenn alles so gemacht wird, wie es sollte, müssen Sie zur Suche nach einem Ort Ihre eigenen Darstellungen des Programms im Speicher überprüfen. Dies kann nicht auf saubere, tragbare Weise erfolgen. Linux
erfordert das Parsen virtueller Dateien unter / proc .
So sieht meine JIT-Speicherzuordnung aus. Es wird ein
angemessenes Verhalten für das Casting von uintptr_t vorausgesetzt :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
Hier stechen zwei Seiten hervor: eine zum Schreiben und die andere mit nicht beschreibbarem Code. Wie in meiner
Bibliothek für Schließungen ist hier die untere Seite beschreibbar und enthält eine
running Variable, die auf Alarm zurückgesetzt wird. Diese Seite sollte sich neben dem JIT-Code befinden, um einen effektiven Zugriff auf RIP als Funktion in den beiden anderen Benchmarks zu ermöglichen. Die obere Seite enthält diesen Assemblycode:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty ist die einzige dynamisch generierte Anweisung. Die relative Adresse muss korrekt eingegeben werden (minus 5 wird relativ zum
Ende der Anweisung angezeigt):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
Befindet sich die Funktion
empty() nicht im allgemeinen Objekt, sondern in derselben Binärdatei, handelt es sich im Wesentlichen um einen direkten Aufruf, den der Compiler für
plt_benchmark() generiert, sofern er aus irgendeinem Grund nicht
empty() eingebaut hat.
Ironischerweise erfordert das Aufrufen eines JIT-kompilierten Codes einen indirekten Aufruf (z. B. über einen Funktionszeiger), und daran führt kein Weg vorbei. Was kann ich hier tun, JIT-kompilieren Sie eine andere Funktion für einen direkten Aufruf? Glücklicherweise spielt dies keine Rolle, da nur ein direkter Anruf in einer Schleife gemessen wird.
Kein Geheimnis
Angesichts dieser Ergebnisse wird deutlich, warum LuaJIT effizientere Aufrufe dynamischer Funktionen als PLT generiert,
auch wenn diese indirekte Aufrufe bleiben . In meinem Benchmark waren indirekte Anrufe ohne PLT 28% schneller als mit PLT und direkte Anrufe ohne PLT waren 43% schneller als mit PLT. Dieser kleine Vorteil von JIT-Programmen gegenüber einfachen alten nativen Programmen wird durch die absolute Ablehnung des Codeaustauschs zwischen Prozessen erreicht.