
In einem Projekt zur Sicherheit von Linux-Systemen mussten Aufrufe wichtiger Funktionen im Kernel abgefangen werden (z. B. Öffnen von Dateien und Ausführen von Prozessen), um die Aktivität im System überwachen und die Aktivität verdächtiger Prozesse vorbeugend blockieren zu können.
Während des Entwicklungsprozesses ist es uns gelungen, einen ziemlich guten Ansatz zu erfinden, mit dem wir jede Funktion im Kernel bequem nach Namen abfangen und unseren Code um seine Aufrufe herum ausführen können. Der Interceptor kann von einem ladbaren GPL-Modul installiert werden, ohne den Kernel neu zu erstellen. Der Ansatz unterstützt Kernel Version 3.19+ für die x86_64-Architektur.
( Pinguinbild oben: © En3l with DeviantArt .)Bekannte Ansätze
Linux-Sicherheits-API
Am richtigsten wäre es, die
Linux-Sicherheits-API zu verwenden - eine spezielle Schnittstelle, die speziell für diese Zwecke erstellt wurde. An kritischen Stellen des Kernel-Codes befinden sich Aufrufe von Sicherheitsfunktionen, die wiederum die vom Sicherheitsmodul festgelegten Rückrufe aufrufen. Das Sicherheitsmodul kann den Kontext einer Operation untersuchen und entscheiden, ob sie zulässig oder abgelehnt ist.
Leider weist die Linux-Sicherheits-API einige wichtige Einschränkungen auf:
- Sicherheitsmodule können nicht dynamisch geladen werden, sind Teil des Kernels und müssen neu erstellt werden
- Es kann nur ein Sicherheitsmodul im System geben (mit wenigen Ausnahmen).
Wenn die Position der Kernelentwickler in Bezug auf die Vielzahl der Module nicht eindeutig ist, ist das Verbot des dynamischen Ladens von grundlegender Bedeutung: Das Sicherheitsmodul muss Teil des Kernels sein, um die Sicherheit ab dem Zeitpunkt des Ladens konstant zu gewährleisten.
Um die Sicherheits-API verwenden zu können, müssen Sie daher Ihre eigene Kernel-Assembly bereitstellen und das Add-On-Modul in SELinux oder AppArmor integrieren, die von gängigen Distributionen verwendet werden. Der Kunde wollte solche Verpflichtungen nicht abonnieren, daher wurde diese Route gesperrt.
Aus diesen Gründen passte die Sicherheits-API nicht zu uns, da sie sonst eine ideale Option wäre.
Änderung der Systemaufruftabelle
Die Überwachung war hauptsächlich für Aktionen erforderlich, die von Benutzeranwendungen ausgeführt wurden, damit sie im Prinzip auf der Ebene von Systemaufrufen implementiert werden konnte. Wie Sie wissen, speichert Linux alle Systemaufruf-Handler in der Tabelle
sys_call_table . Das Ersetzen von Werten in dieser Tabelle führt zu einer Änderung des Verhaltens des gesamten Systems. Wenn wir also die alten Werte des Handlers beibehalten und unseren eigenen Handler in der Tabelle ersetzen, können wir jeden Systemaufruf abfangen.
Dieser Ansatz hat bestimmte Vorteile:
- Volle Kontrolle über alle Systemaufrufe - die einzige Schnittstelle zum Kernel für Benutzeranwendungen. Mit dieser Funktion können wir sicher sein, dass wir keine wichtigen Aktionen des Benutzerprozesses verpassen.
- Minimaler Overhead. Bei der Aktualisierung der Systemaufruftabelle ist eine einmalige Kapitalinvestition erforderlich. Neben der unvermeidlichen Überwachungsnutzlast ist der einzige Aufwand ein zusätzlicher Funktionsaufruf (zum Aufrufen des ursprünglichen Systemaufruf-Handlers).
- Mindestanforderungen an den Kernel. Falls gewünscht, erfordert dieser Ansatz keine zusätzlichen Konfigurationsoptionen im Kernel, sodass theoretisch ein möglichst breites Systemspektrum unterstützt wird.
Er leidet jedoch auch an einigen Mängeln:
- Die technische Komplexität der Implementierung. Das Ersetzen von Zeigern in einer Tabelle ist an sich nicht schwierig. Verwandte Aufgaben erfordern jedoch nicht offensichtliche Lösungen und eine bestimmte Qualifikation:
- Aufruftabelle des Suchsystems
- Bypass zum Schutz vor Tabellenänderungen
- atomarer und sicherer Ersatz
Dies sind alles interessante Dinge, aber sie erfordern wertvolle Entwicklungszeit, zuerst für die Implementierung und dann für die Unterstützung und das Verständnis.
- Unfähigkeit, einige Handler abzufangen. In Kerneln vor Version 4.16 enthielt die Systemaufrufbehandlung für die x86_64-Architektur eine Reihe von Optimierungen. Einige von ihnen forderten, dass der Systemaufruf-Handler ein spezieller Adapter ist, der in Assembler implementiert ist. Dementsprechend sind solche Handler manchmal schwierig und manchmal sogar unmöglich durch Ihre eigenen zu ersetzen, geschrieben in C. Darüber hinaus werden in verschiedenen Versionen des Kernels unterschiedliche Optimierungen verwendet, was die technischen Schwierigkeiten des Sparschweins erhöht.
- Es werden nur Systemaufrufe abgefangen. Mit diesem Ansatz können Sie Systemaufruf-Handler ersetzen, wodurch die Einstiegspunkte auf nur diese beschränkt werden. Alle zusätzlichen Überprüfungen werden entweder am Anfang oder am Ende durchgeführt, und wir haben nur die Argumente des Systemaufrufs und seinen Rückgabewert. Manchmal führt dies dazu, dass doppelte Überprüfungen der Angemessenheit von Argumenten und Zugriffsprüfungen erforderlich sind. Manchmal verursacht es unnötigen Overhead, wenn Sie den Speicher des Benutzerprozesses zweimal kopieren müssen: Wenn das Argument über einen Zeiger übergeben wird, müssen wir es zuerst selbst kopieren, dann kopiert der ursprüngliche Handler das Argument erneut für sich. Darüber hinaus bieten Systemaufrufe in einigen Fällen eine zu geringe Granularität von Ereignissen, die zusätzlich nach Rauschen gefiltert werden müssen.
Zunächst haben wir diesen Ansatz gewählt und erfolgreich umgesetzt, um die Vorteile der Unterstützung der meisten Systeme zu nutzen. Zu diesem Zeitpunkt wussten wir jedoch noch nichts über die Funktionen von x86_64 und die Einschränkungen für abgefangene Anrufe. Später stellte sich heraus, dass es für uns von entscheidender Bedeutung ist, Systemaufrufe im Zusammenhang mit dem Starten neuer Prozesse - clone () und execve () - zu unterstützen, die nur etwas Besonderes sind. Dies führte uns zur Suche nach neuen Optionen.
Verwenden von kprobes
Eine der in Betracht
gezogenen Optionen war die Verwendung von
kprobes : eine spezialisierte API, die hauptsächlich zum Debuggen und Verfolgen des Kernels entwickelt wurde. Über diese Schnittstelle können Sie Vor- und Nachhandler für
alle Anweisungen im Kernel sowie Handler für die Eingabe und Rückgabe einer Funktion festlegen. Handler erhalten Zugriff auf Register und können diese ändern. Auf diese Weise könnten wir sowohl die Überwachung als auch die Fähigkeit erhalten, den weiteren Arbeitsablauf zu beeinflussen.
Vorteile der Verwendung von kprobes zum Abfangen:
- Reife API. Kprobes existieren und verbessern sich seit jeher (2002). Sie haben eine gut dokumentierte Oberfläche, die meisten Fallstricke wurden bereits gefunden, ihre Arbeit wurde so weit wie möglich optimiert und so weiter. Im Allgemeinen ein ganzer Berg von Vorteilen gegenüber experimentellen selbstgebauten Fahrrädern.
- Abfangen eines beliebigen Ortes im Kern. Kprobes werden mithilfe von Haltepunkten (int3-Anweisungen) implementiert, die in den ausführbaren Code des Kernels eingebettet sind. Auf diese Weise können Sie kprobes buchstäblich überall in jeder Funktion installieren, sofern bekannt. In ähnlicher Weise werden kretprobes durch Spoofing der Rücksprungadresse auf dem Stapel implementiert und ermöglichen es Ihnen, die Rückgabe von jeder Funktion abzufangen (mit Ausnahme derjenigen, die im Prinzip keine Kontrolle zurückgeben).
Nachteile von kprobes:
- Technische Schwierigkeit. Kprobes ist nur eine Möglichkeit, einen Haltepunkt irgendwo im Kernel festzulegen. Um die Argumente einer Funktion oder die Werte lokaler Variablen zu erhalten, müssen Sie wissen, in welchen Registern oder wo auf dem Stapel sie sich befinden, und sie unabhängig voneinander von dort extrahieren. Um einen Funktionsaufruf zu blockieren, müssen Sie den Status des Prozesses manuell ändern, sodass der Prozessor denkt, dass er bereits die Kontrolle über die Funktion zurückgegeben hat.
- Jprobes sind veraltet. Jprobes ist ein Add-On für kprobes, mit dem Sie Funktionsaufrufe bequem abfangen können. Es extrahiert unabhängig die Argumente der Funktion aus den Registern oder dem Stapel und ruft Ihren Handler auf, der dieselbe Signatur wie die Hook-Funktion haben sollte. Der Haken ist, dass J-Sonden veraltet sind und aus modernen Kerneln herausgeschnitten werden.
- Nicht trivialer Overhead. Haltepunkte sind teuer, aber einmalig. Haltepunkte wirken sich nicht auf andere Funktionen aus, ihre Verarbeitung ist jedoch relativ teuer. Glücklicherweise ist für die x86_64-Architektur eine Sprungoptimierung implementiert, die die Kosten für kprobes erheblich senkt, aber immer noch mehr bleibt als beispielsweise beim Ändern der Systemaufruftabelle.
- Einschränkungen von Kretsonden. Kretprobes werden implementiert, indem die Rücksprungadresse auf dem Stapel gefälscht wird. Dementsprechend müssen sie die ursprüngliche Adresse irgendwo speichern, um nach der Verarbeitung von kretprobe dorthin zurückzukehren. Adressen werden in einem Puffer fester Größe gespeichert. Im Falle eines Überlaufs überspringen kretprobes Operationen, wenn zu viele gleichzeitige Aufrufe der abgefangenen Funktion im System ausgeführt werden.
- Extrusion deaktiviert. Da kprobes auf Interrupts basiert und Prozessorregister jongliert, werden zur Synchronisation alle Handler mit deaktivierter Vorbelegung ausgeführt. Dies führt zu gewissen Einschränkungen für die Handler: Sie können nicht in ihnen warten - reservieren Sie viel Speicher, führen Sie E / A durch, schlafen Sie in Timern und Semaphoren und anderen bekannten Dingen.
Bei der Erforschung des Themas fielen unsere Augen auf das
ftrace- Framework, das jprobes ersetzen kann. Wie sich herausstellte, funktioniert es besser für unsere Anforderungen zum Abfangen von Funktionsaufrufen. Wenn Sie jedoch bestimmte Anweisungen innerhalb von Funktionen verfolgen müssen, sollten kprobes nicht rabattiert werden.
Spleißen
Der Vollständigkeit halber lohnt es sich auch, die klassische Methode zum Abfangen von Funktionen zu beschreiben, bei der die Anweisungen zu Beginn der Funktion durch einen bedingungslosen Übergang ersetzt werden, der zu unserem Handler führt. Die ursprünglichen Anweisungen werden an einen anderen Ort übertragen und ausgeführt, bevor zur abgefangenen Funktion zurückgekehrt wird. Mit Hilfe von zwei Übergängen binden wir unseren zusätzlichen Code in die Funktion ein (
spleißen ihn ein) , daher wird dieser Ansatz als
Spleißen bezeichnet .
So wird die Sprungoptimierung für kprobes implementiert. Mit dem Spleißen können Sie die gleichen Ergebnisse erzielen, jedoch ohne zusätzliche Kosten für k-Sonden und mit vollständiger Kontrolle über die Situation.
Die Vorteile des Spleißens liegen auf der Hand:
- Mindestanforderungen an den Kernel. Das Spleißen erfordert keine speziellen Optionen im Kernel und funktioniert zu Beginn einer Funktion. Sie müssen nur ihre Adresse kennen.
- Minimaler Overhead. Zwei bedingungslose Übergänge - das sind alle Aktionen, die der abgefangene Code ausführen muss, um die Kontrolle an den Handler zu übertragen und umgekehrt. Solche Übergänge werden vom Prozessor perfekt vorhergesagt und sind sehr billig.
Der Hauptnachteil dieses Ansatzes trübt jedoch das Bild ernsthaft:
- Technische Schwierigkeit. Sie dreht sich um. Sie können den Maschinencode nicht einfach übernehmen und neu schreiben. Hier ist eine kurze und unvollständige Liste der zu lösenden Aufgaben:
- Synchronisation der Installation und Entfernung des Abfangens (was ist, wenn die Funktion direkt beim Ersetzen ihrer Anweisungen aufgerufen wird?)
- Bypass des Schutzes bei Änderung von Speicherbereichen mit einem Code
- Ungültigmachung des CPU-Cache nach Ersetzen der Anweisungen
- Zerlegen austauschbarer Anweisungen, um sie vollständig zu kopieren
- Überprüfen Sie, ob im ersetzten Teil keine Übergänge vorhanden sind
- Überprüfen Sie, ob das ersetzte Teil an einen anderen Ort gebracht werden kann
Ja, Sie können kprobes ausspionieren und das intranukleäre Livepatch-Framework verwenden, aber die endgültige Lösung ist immer noch recht kompliziert. Es ist beängstigend, sich vorzustellen, wie viele Schlafprobleme in jeder neuen Implementierung auftreten werden.
Wenn Sie diesen Dämon aufrufen können, der nur den Eingeweihten untergeordnet ist und bereit ist, ihn in Ihrem Code zu ertragen, ist das Spleißen im Allgemeinen ein vollständig funktionierender Ansatz zum Abfangen von Funktionsaufrufen. Ich hatte eine negative Einstellung zum Schreiben von Fahrrädern, daher blieb diese Option ein Backup für uns, falls es bei vorgefertigten Lösungen überhaupt keine Fortschritte geben sollte.
Neuer Ansatz mit ftrace
Ftrace ist ein Kernel-Tracing-Framework auf Funktionsebene. Es wurde seit 2008 entwickelt und verfügt über eine fantastische Oberfläche für Benutzerprogramme. Mit Ftrace können Sie die Häufigkeit und Dauer von Funktionsaufrufen verfolgen, Anrufdiagramme anzeigen, interessierende Funktionen nach Vorlage filtern usw. Sie können
von hier aus über ftrace-Funktionen lesen und dann den Links und der offiziellen Dokumentation folgen.
Es implementiert ftrace basierend auf den Compiler-Schlüsseln
-pg und
-mfentry , die den Aufruf der speziellen Trace-Funktion mcount () oder __fentry __ () am Anfang jeder Funktion einfügen. In Benutzerprogrammen wird diese Compilerfunktion normalerweise von Profilern verwendet, um Aufrufe aller Funktionen zu verfolgen. Der Kernel verwendet diese Funktionen, um das ftrace-Framework zu implementieren.
Das Aufrufen von ftrace von
jeder Funktion ist natürlich nicht billig, daher ist eine Optimierung für gängige Architekturen verfügbar:
dynamisches ftrace . Das Fazit ist, dass der Kernel den Speicherort aller Aufrufe von mcount () oder __fentry __ () kennt und in den frühen Phasen des Ladens den Maschinencode durch
nop ersetzt - eine spezielle Anweisung, die nichts bewirkt. Wenn die Ablaufverfolgung in den erforderlichen Funktionen enthalten ist, werden ftrace-Aufrufe wieder hinzugefügt. Wenn also ftrace nicht verwendet wird, ist seine Auswirkung auf das System minimal.
Beschreibung der benötigten Funktionen
Jede abgefangene Funktion kann durch die folgende Struktur beschrieben werden:
struct ftrace_hook { const char *name; void *function; void *original; unsigned long address; struct ftrace_ops ops; };
Der Benutzer muss nur die ersten drei Felder ausfüllen: Name, Funktion, Original. Die verbleibenden Felder werden als Implementierungsdetail betrachtet. Die Beschreibung aller abgefangenen Funktionen kann in einem Array gesammelt werden, und Makros können verwendet werden, um die Kompaktheit des Codes zu erhöhen:
#define HOOK(_name, _function, _original) \ { \ .name = (_name), \ .function = (_function), \ .original = (_original), \ } static struct ftrace_hook hooked_functions[] = { HOOK("sys_clone", fh_sys_clone, &real_sys_clone), HOOK("sys_execve", fh_sys_execve, &real_sys_execve), };
Wrapper über abgefangene Funktionen sind wie folgt:
static asmlinkage long (*real_sys_execve)(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp); static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
Wie Sie sehen können, abgefangene Funktionen mit einem Minimum an zusätzlichem Code. Das einzige, was besondere Aufmerksamkeit erfordert, sind die Funktionssignaturen. Sie müssen eins zu eins passen. Ohne dies werden die Argumente natürlich falsch weitergegeben und alles wird bergab gehen. Um Systemaufrufe abzufangen, ist dies weniger wichtig, da ihre Handler sehr stabil sind und aus Effizienzgründen Argumente in derselben Reihenfolge annehmen, in der das System selbst aufruft. Wenn Sie jedoch andere Funktionen abfangen möchten, sollten Sie berücksichtigen, dass
im Kernel keine stabilen Schnittstellen vorhanden sind .
Ftrace-Initialisierung
Zuerst müssen wir die Adresse der Funktion finden und speichern, die wir abfangen werden. Mit Ftrace können Sie Funktionen nach Namen verfolgen, aber wir müssen noch die Adresse der ursprünglichen Funktion kennen, um sie aufrufen zu können.
Sie können die Adresse mit
kallsyms abrufen - einer Liste aller Zeichen im Kernel. Diese Liste enthält
alle Zeichen, die nicht nur für Module exportiert wurden. Das Abrufen der Adresse der Hook-Funktion sieht ungefähr so aus:
static int resolve_hook_address(struct ftrace_hook *hook) { hook->address = kallsyms_lookup_name(hook->name); if (!hook->address) { pr_debug("unresolved symbol: %s\n", hook->name); return -ENOENT; } *((unsigned long*) hook->original) = hook->address; return 0; }
Als nächstes müssen Sie die Struktur
ftrace_ops initialisieren. Es ist verbindlich
Das Feld ist nur
func und zeigt einen Rückruf an, aber wir brauchen es auch
Setzen Sie einige wichtige Flags:
int fh_install_hook(struct ftrace_hook *hook) { int err; err = resolve_hook_address(hook); if (err) return err; hook->ops.func = fh_ftrace_thunk; hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS | FTRACE_OPS_FL_IPMODIFY; }
fh_ftrace_thunk () ist unser Rückruf, den ftrace beim Verfolgen einer Funktion aufruft. Über ihn später. Die von uns gesetzten Flags sind erforderlich, um das Abfangen abzuschließen. Sie weisen ftrace an, Prozessorregister zu speichern und wiederherzustellen, deren Inhalt wir im Rückruf ändern können.
Jetzt sind wir bereit, das Abfangen zu ermöglichen. Dazu müssen Sie zuerst ftrace für die für uns interessante Funktion mit ftrace_set_filter_ip () aktivieren und dann ftrace erlauben, unseren Rückruf mit register_ftrace_function () aufzurufen:
int fh_install_hook(struct ftrace_hook *hook) { err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); return err; } err = register_ftrace_function(&hook->ops); if (err) { pr_debug("register_ftrace_function() failed: %d\n", err); ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); return err; } return 0; }
Das Abfangen wird auf ähnliche Weise nur in umgekehrter Reihenfolge deaktiviert:
void fh_remove_hook(struct ftrace_hook *hook) { int err; err = unregister_ftrace_function(&hook->ops); if (err) { pr_debug("unregister_ftrace_function() failed: %d\n", err); } err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); } }
Nachdem der Aufruf von unregister_ftrace_function () abgeschlossen ist, ist das Fehlen von Aktivierungen des im System installierten Rückrufs (und damit unserer Wrapper) garantiert. Daher können wir beispielsweise das Abfangmodul ruhig entladen, ohne befürchten zu müssen, dass irgendwo im System unsere Funktionen noch ausgeführt werden (denn wenn sie verschwinden, wird der Prozessor gestört).
Funktionshaken ausführen
Wie wird das Abfangen tatsächlich durchgeführt? Sehr einfach. Mit Ftrace können Sie den Status von Registern nach dem Beenden eines Rückrufs ändern. Durch Ändern des% rip-Registers - eines Zeigers auf die nächste ausführbare Anweisung - ändern wir die Anweisungen, die der Prozessor ausführt - das heißt, wir können ihn zwingen, einen bedingungslosen Übergang von der aktuellen Funktion zu unserer auszuführen. So übernehmen wir die Kontrolle.
Der Rückruf für ftrace lautet wie folgt:
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); regs->ip = (unsigned long) hook->function; }
Mit dem Makro container_of () erhalten wir die Adresse unserer
struct ftrace_hook an die Adresse der
struct ftrace_hook eingebetteten
struct ftrace_hook und ersetzen dann den% rip-Registerwert in der
struct pt_regs durch die Adresse unseres
struct pt_regs . Das ist alles. Für andere Architekturen als x86_64 kann dieses Register anders aufgerufen werden (wie IP oder PC), aber die Idee ist im Prinzip auf sie anwendbar.
Beachten Sie das für den Rückruf hinzugefügte
Notrace-Qualifikationsmerkmal . Sie können Features kennzeichnen, die mit ftrace nicht verfolgt werden dürfen. Auf diese Weise werden beispielsweise die Funktionen von ftrace selbst markiert, die am Traceprozess beteiligt sind. Dies verhindert, dass das System in einer Endlosschleife einfriert, wenn alle Funktionen im Kernel verfolgt werden (ftrace kann dies tun).
Der ftback-Rückruf ruft normalerweise mit deaktivierter Extrusion auf (wie kprobes). Es kann Ausnahmen geben, aber Sie sollten sich nicht auf sie verlassen. In unserem Fall ist diese Einschränkung jedoch nicht wichtig, sodass wir nur acht Bytes in der Struktur ersetzen.
Die Wrapper-Funktion, die später aufgerufen wird, wird im selben Kontext wie die ursprüngliche Funktion ausgeführt. Daher können Sie dort tun, was in der abgefangenen Funktion zulässig ist. Wenn Sie beispielsweise einen Interrupt-Handler abfangen, können Sie immer noch nicht in einem Wrapper schlafen.
Rekursiver Anrufschutz
Der obige Code enthält einen Haken: Wenn unser Wrapper die ursprüngliche Funktion aufruft, fällt er erneut in ftrace, wodurch unser Rückruf erneut aufgerufen wird, wodurch die Kontrolle wieder auf den Wrapper übertragen wird. Diese unendliche Rekursion muss irgendwie abgebrochen werden.Der eleganteste Weg, der uns gekommen ist, ist die Verwendung parent_ipeines der Argumente des ftrace-Rückrufs, der die Rücksprungadresse zu der Funktion enthält, die die verfolgte Funktion aufgerufen hat. Normalerweise wird dieses Argument verwendet, um ein Diagramm von Funktionsaufrufen zu erstellen. Wir können es verwenden, um den ersten Aufruf der abgefangenen Funktion von dem wiederholten zu unterscheiden.In der Tat, wenn Sie erneut anrufenparent_ipsollte in unseren Wrapper zeigen, während am ersten - irgendwo an einer anderen Stelle im Kernel. Die Steuerung sollte nur beim ersten Aufruf der Funktion übertragen werden, alle anderen sollten die ursprüngliche Funktion ausführen dürfen.Die Eingabeprüfung kann sehr effizient durchgeführt werden, indem die Adresse mit den Rändern des aktuellen Moduls (das alle unsere Funktionen enthält) verglichen wird. Dies funktioniert hervorragend, wenn im Modul nur der Wrapper die abgefangene Funktion aufruft. Andernfalls müssen Sie selektiver vorgehen.Insgesamt lautet der korrekte ftrace-Rückruf wie folgt: static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); if (!within_module(parent_ip, THIS_MODULE)) regs->ip = (unsigned long) hook->function; }
Besonderheiten / Vorteile dieses Ansatzes:- Geringer Overhead. Nur ein paar Subtraktionen und Vergleiche. Keine Spinlocks, Listenpässe und so weiter.
- . . , .
- . kretprobes , ( ). , .
Stellen Sie sich ein Beispiel vor: Sie haben den Befehl ls in das Terminal eingegeben , um eine Liste der Dateien im aktuellen Verzeichnis anzuzeigen. Die Shell (z. B. Bash) verwendet ein traditionelles Paar von fork () + execve () -Funktionen aus der C-Standardbibliothek , um einen neuen Prozess zu starten . Intern werden diese Funktionen über die Systemaufrufe clone () bzw. execve () implementiert . Angenommen, wir fangen den Systemaufruf execve () ab, um den Start neuer Prozesse zu steuern.In grafischer Form sieht das Abfangen der Handlerfunktion folgendermaßen aus: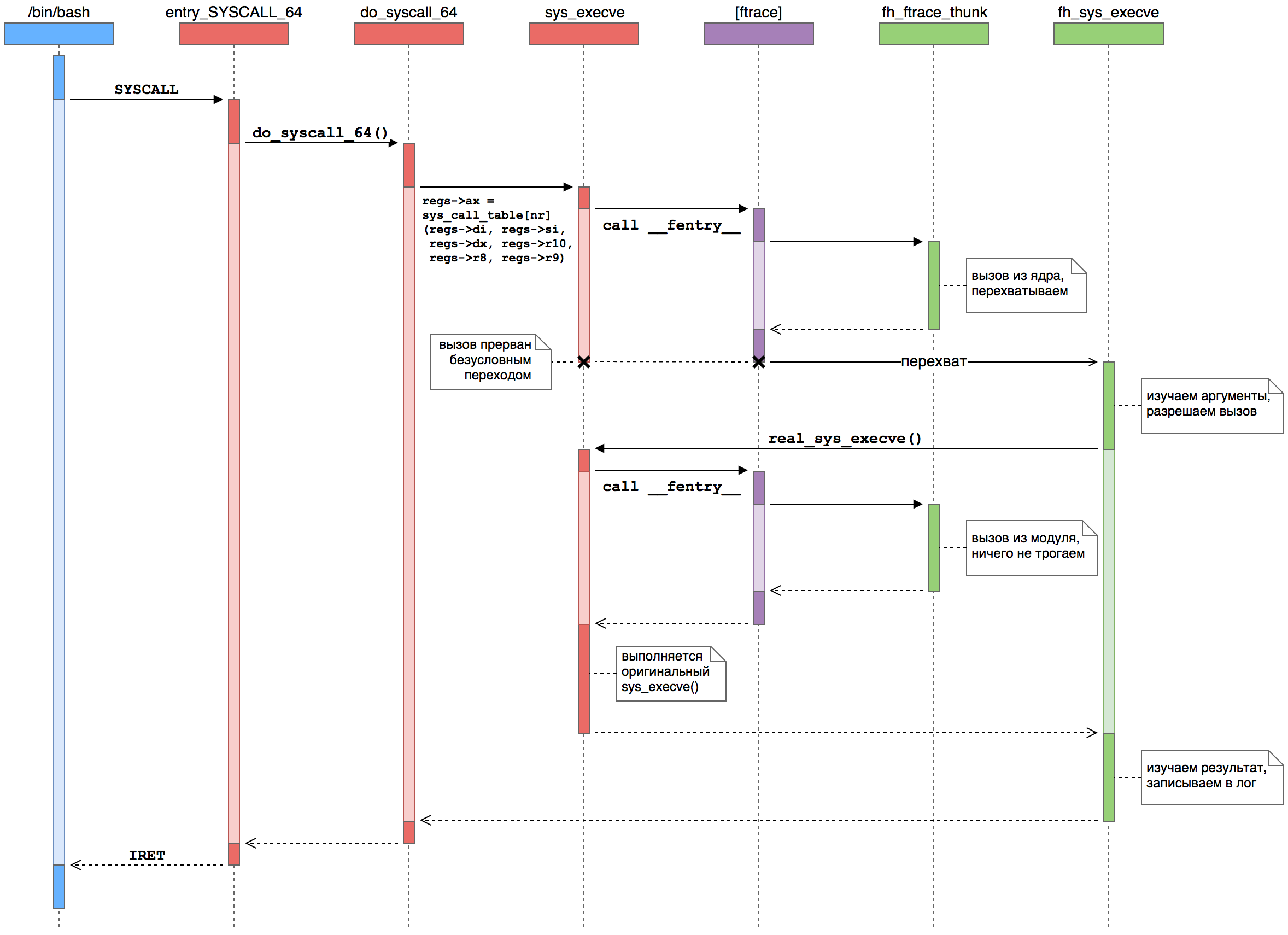 Hier sehen wir, wie der Benutzerprozess ( blau ) einen Systemaufruf an den Kernel ausführt ( rot)), wobei das ftrace-Framework ( lila ) Funktionen von unserem Modul ( grün ) aufruft .
Hier sehen wir, wie der Benutzerprozess ( blau ) einen Systemaufruf an den Kernel ausführt ( rot)), wobei das ftrace-Framework ( lila ) Funktionen von unserem Modul ( grün ) aufruft .- Der Benutzerprozess führt SYSCALL aus. Mit dieser Anweisung wird der Kernelmodus übertragen und die Steuerung an den Systemaufruf-Handler auf niedriger Ebene übertragen - entry_SYSCALL_64 (). Er ist verantwortlich für alle Systemaufrufe von 64-Bit-Programmen auf 64-Bit-Kerneln.
- . , , do_syscall_64 (), .
sys_call_table — sys_execve ().
- ftrace. __fentry__ (), ftrace. , , nop , sys_execve() .
- Ftrace . ftrace , . , %rip, .
- .
parent_ip , do_syscall_64() — sys_execve() — , %rip pt_regs .
- Ftrace . FTRACE_SAVE_REGS, ftrace
pt_regs . ftrace . %rip — — .
- -. - sys_execve() . fh_sys_execve (). , do_syscall_64().
- . . fh_sys_execve() ( ) . . — sys_execve() , real_sys_execve , .
- . sys_execve(), ftrace . , -…
- . sys_execve() fh_sys_execve(), do_syscall_64(). sys_execve() . : ftrace sys_execve() .
- . sys_execve() fh_sys_execve(). . , execve() , , , . .
- Das Management kehrt zum Kern zurück. Schließlich wird fh_sys_execve () abgeschlossen und die Steuerung an do_syscall_64 () übergeben, wodurch berücksichtigt wird, dass der Systemaufruf wie gewohnt abgeschlossen wurde. Der Kern setzt sein Nukleargeschäft fort.
- Das Management kehrt zum Benutzerprozess zurück. Schließlich führt der Kernel den IRET-Befehl (oder SYSRET, aber für execve () ist es immer IRET) aus, setzt Register für den neuen Benutzerprozess und versetzt den Zentralprozessor in den Benutzercode-Ausführungsmodus. Der Systemaufruf (und das Starten eines neuen Prozesses) ist abgeschlossen.
Vor- und Nachteile
Als Ergebnis erhalten wir eine sehr bequeme Möglichkeit, alle Funktionen im Kernel abzufangen, was die folgenden Vorteile bietet:- API . . , , . — -, .
- . . - , , , - . ( ), .
- Das Abfangen ist mit der Ablaufverfolgung kompatibel. Offensichtlich widerspricht diese Methode nicht ftrace, sodass Sie dem Kernel immer noch sehr nützliche Leistungsindikatoren entnehmen können. Die Verwendung von Sonden oder Spleißen kann die Verfolgungsmechanismen beeinträchtigen.
Was sind die Nachteile dieser Lösung?- Anforderungen an die Kernelkonfiguration. Um Funktions-Hooks mit ftrace erfolgreich ausführen zu können, muss der Kernel eine Reihe von Funktionen bereitstellen:
- Liste der Kallsyms-Zeichen, um nach Funktionen nach Namen zu suchen
- ftrace Framework im Allgemeinen für die Rückverfolgung
- Verfolgen Sie kritische Abfangoptionen
. , , , , . , - , .
- ftrace , kprobes ( ftrace ), , , . , ftrace — , «» ftrace .
- . , . , , ftrace . , , .
- Doppelter Anruf ftrace. Der oben beschriebene Ansatz der
parent_ipZeigeranalyse führt erneut zu einem ftrace-Aufruf für Hook-Funktionen. Dies erhöht den Overhead und kann andere Spuren zerstören, die doppelt so viele Anrufe sehen. Dieser Nachteil kann vermieden werden, indem ein wenig schwarze Magie angewendet wird: Der ftrace-Aufruf befindet sich am Anfang der Funktion. Wenn also die Adresse der ursprünglichen Funktion um 5 Byte (die Länge der Aufrufanweisung) vorwärts verschoben wird, können Sie durch ftrace springen.
Betrachten Sie einige der Nachteile genauer.Anforderungen an die Kernelkonfiguration
Für den Anfang muss der Kernel ftrace und kallsyms unterstützen. Dazu müssen folgende Optionen aktiviert sein:- CONFIG_FTRACE
- CONFIG_KALLSYMS
Dann sollte ftrace die dynamische Registermodifikation unterstützen. Die Option ist dafür verantwortlich.- CONFIG_DYNAMIC_FTRACE_WITH_REGS
Außerdem muss der verwendete Kernel auf Version 3.19 oder höher basieren , um auf das Flag FTRACE_OPS_FL_IPMODIFY zugreifen zu können. Frühere Versionen des Kernels können auch das% rip-Register ersetzen. Ab 3.19 sollte dies jedoch erst nach dem Setzen dieses Flags erfolgen. Das Vorhandensein eines Flags für alte Kernel führt zu einem Kompilierungsfehler, und das Fehlen für neue Kernel führt zu einem Leerlaufabfangen.Um das Abfangen durchzuführen, ist schließlich die Position des ftrace-Aufrufs innerhalb der Funktion kritisch: Der Aufruf muss ganz am Anfang vor dem Prolog der Funktion liegen (wobei Platz für lokale Variablen zugewiesen wird und ein Stapelrahmen gebildet wird). Diese Architekturfunktion wird von der Option berücksichtigtDie x86_64-Architektur unterstützt diese Option, der i386 jedoch nicht. Aufgrund von Einschränkungen der i386-Architektur kann der Compiler vor dem Funktionsprolog keinen ftrace-Aufruf einfügen. Daher ist der Funktionsstapel zum Zeitpunkt des Aufrufs von ftrace bereits geändert. In diesem Fall reicht es zum Abfangen nicht aus, nur den Wert des% eip-Registers zu ändern. Sie müssen dennoch alle im Prolog ausgeführten Aktionen umkehren, die sich von Funktion zu Funktion unterscheiden.Aus diesem Grund unterstützt ftrace Interception die x86 32-Bit-Architektur nicht. Im Prinzip könnte es mit Hilfe bestimmter schwarzer Magie (Erzeugung und Durchführung eines „Anti-Prologs“) implementiert werden, aber dann leidet die technische Einfachheit der Lösung, was einer der Vorteile der Verwendung von ftrace ist.Unverständliche Überraschungen
Beim Testen stießen wir auf eine interessante Funktion : Bei einigen Distributionen führten Hooking-Funktionen dazu, dass das System fest abstürzte. Dies geschah natürlich nur auf anderen Systemen als den von den Entwicklern verwendeten. Das Problem wurde auch nicht auf dem ursprünglichen Interception-Prototyp mit Distributionen und Kernel-Versionen reproduziert.Das Debuggen zeigte, dass der Hang innerhalb der abgefangenen Funktion auftritt. Aus irgendeinem mystischen Grund wurde beim Aufrufen der ursprünglichen Funktion innerhalb des ftrace-Rückrufs die Adresse parent_ipweiterhin im Kernelcode anstelle des Wrapper-Funktionscodes angegeben. Aus diesem Grund entstand eine Endlosschleife, da ftrace unseren Wrapper immer wieder aufrief, ohne nützliche Aktionen auszuführen.Glücklicherweise verfügten wir sowohl über funktionierenden als auch über fehlerhaften Code, sodass es nur eine Frage der Zeit war, die Unterschiede zu finden. Nachdem der Code vereinheitlicht und alles Unnötige verworfen worden war, wurden die Unterschiede zwischen den Versionen in einer Wrapper-Funktion lokalisiert.Diese Option hat funktioniert: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
aber dieser - hat das System aufgehängt: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_devel("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_devel("execve() returns: %ld\n", ret); return ret; }
Wie stellt sich heraus, dass die Protokollierungsstufe das Verhalten beeinflusst? Eine sorgfältige Untersuchung des Maschinencodes der beiden Funktionen verdeutlichte schnell die Situation und verursachte genau das Gefühl, als der Compiler schuld war. Normalerweise steht er irgendwo in der Nähe der kosmischen Strahlung auf der Verdächtigenliste, diesmal jedoch nicht.Wie sich herausstellte, werden Aufrufe von pr_devel () in die Leere erweitert. Diese Version des printk-Makros wird für die Protokollierung während der Entwicklung verwendet. Solche Protokolleinträge sind während des Betriebs nicht interessant, daher werden sie automatisch aus dem Code herausgeschnitten, wenn das DEBUG-Makro nicht deklariert wird. Danach wird die Funktion für den Compiler folgendermaßen: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { return real_sys_execve(filename, argv, envp); }
Und hier kommt die Optimierung ins Spiel. In diesem Fall ist es so genannte Optimierung Endrekursion (Tail Call - Optimierung). Es ermöglicht dem Compiler, einen ehrlichen Funktionsaufruf durch einen direkten Sprung zu seinem Körper zu ersetzen, wenn eine Funktion eine andere aufruft und sofort ihren Wert zurückgibt. Im Maschinencode sieht ein ehrlicher Anruf folgendermaßen aus: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: ff 15 00 00 00 00 callq *0x0(%rip) b: f3 c3 repz retq
und nicht arbeitend - so: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax c: ff e0 jmpq *%rax
Die erste CALL-Anweisung ist derselbe __fentry __ () -Aufruf, den der Compiler am Anfang aller Funktionen eingefügt hat. Im normalen Code können Sie jedoch den Aufruf von real_sys_execve (durch den Zeiger im Speicher) über die Anweisung CALL sehen und mit der Anweisung RET von fh_sys_execve () zurückkehren. Der fehlerhafte Code wird direkt über JMP an die Funktion real_sys_execve () übergeben.Durch die Optimierung von Tail-Aufrufen können Sie ein wenig Zeit bei der Bildung eines „bedeutungslosen“ Stapelrahmens sparen, der die durch den CALL-Befehl im Stapel gespeicherte Rücksprungadresse enthält. Für uns spielt jedoch die Richtigkeit der Absenderadresse eine entscheidende Rolle - wir verwenden sie parent_ip, um eine Entscheidung über das Abfangen zu treffen. Nach der Optimierung speichert die Funktion fh_sys_execve () nicht mehr die neue Rücksprungadresse auf dem Stapel, sondern die alte, die auf den Kernel zeigt. Deshalbparent_ipzeigt weiterhin in den Kern, was letztendlich zur Bildung einer Endlosschleife führt.Dies erklärt auch, warum das Problem nur bei einigen Distributionen reproduziert wurde. Beim Kompilieren von Modulen verwenden verschiedene Distributionen unterschiedliche Sätze von Kompilierungsflags. In notleidenden Distributionen war die Tail-Call-Optimierung standardmäßig aktiviert.Die Lösung für das Problem bestand für uns darin, die Tail-Call-Optimierung für die gesamte Datei mit Wrapper-Funktionen zu deaktivieren: #pragma GCC optimize("-fno-optimize-sibling-calls")
Fazit
Was kann ich noch sagen ... Das Entwickeln von Low-Level-Code für den Linux-Kernel macht Spaß. Ich hoffe, diese Veröffentlichung spart jemandem ein wenig Zeit bei der Auswahl, was er verwenden soll, um Ihr bestes Antivirenprogramm der Welt zu schreiben.Wenn Sie selbst mit dem Abfangen experimentieren möchten, finden Sie den vollständigen Code des Kernelmoduls auf Github .