Hallo, Benutzername! Jeden Tag stehen wir vor der Suche nach verschiedenen Daten. Fast jede Website mit vielen Informationen hat jetzt eine Suche. Die Suche erfolgt in Heimcomputern, in Mobiltelefonen und in verschiedenen Arten von Software. Wenn Sie einen Entwickler nach der Suche nach Technologie fragen, fällt Ihnen natürlich sofort Elasticsearch, Lucene oder Sphinx ein. Heute möchte ich mit Ihnen „unter die Haube“ einer Volltextsuche schauen und anhand des Beispiels von hh.ru eine erste Annäherung an die Funktionsweise herausfinden.
 Haftungsausschluss: Dieser Artikel ist nicht die einzig wahre Sichtweise und dient nur als Einführungspunkt für eine erste Einführung in die Arbeit der Textsuche und einige Optionen für die Implementierung ihrer einzelnen Teile.
Haftungsausschluss: Dieser Artikel ist nicht die einzig wahre Sichtweise und dient nur als Einführungspunkt für eine erste Einführung in die Arbeit der Textsuche und einige Optionen für die Implementierung ihrer einzelnen Teile.Wenn Sie sich die Details der Suche ansehen, sehen Sie neben dem offensichtlichen Teil in Form einer Suchzeichenfolge noch viel mehr:
- Hinweis (sie schlägt vor)
- Suchergebniszähler (Zähler),
- verschiedene Arten der Sortierung (Sortierung),
- Facetten - gruppierte Merkmale von Dokumenten, z. B. die U-Bahn, in der sich eine freie Stelle befindet, die auch die Funktion von Filtern (Filtern) erfüllt;
- Synonyme
- Paginierung
- Snippet (Snippet) - eine kleine Beschreibung des Dokuments in der Ausstellung,
- usw.

Und all dies dient einem Zweck - dem Bedürfnis des Benutzers gerecht zu werden, die richtigen Informationen so schnell und relevant wie möglich zu finden. Zum Beispiel ist das Filtern wichtig, um die Suchergebnisse einzugrenzen. In unserem Fall kann es sich um ein Filter nach Erfahrung, Standort oder Beschäftigung des Bewerbers handeln. Facetten sind nützlich, um anzuzeigen, wie viele offene Stellen in jedem Gehaltsbereich vorhanden sind. Es ist auch wichtig, die Abfragen und Dokumente mit Synonymen zu ergänzen, damit sie auf Anfrage von "Java Developer" Dokumente von "Java Developer" finden können.
Neben der Suche selbst gibt es immer viele Komponenten, die dem Benutzer das Leben erleichtern: einen Vormund, der für die Behebung von Fehlern verantwortlich ist, oder einen Sajest, der bei der Interaktion mit der Suchleiste geeignetere Abfragen auffordert. In einigen Fällen ist es wichtig, die Anfrage neu formulieren zu können. Verschieben Sie beispielsweise einen Teil der Anforderung in Filter: Aus der Anforderung „Moskauer Programmierer“ kann Moskau nach Stadt in den Filter aufgenommen werden.
1. Grundlegend
Nun zum Punkt. Die Suche selbst ist in zwei große Phasen unterteilt:
- Indexierung (Bearbeitung von Dokumenten und Anordnung nach speziellen Indexstrukturen, damit Sie die Suche dann selbst schnell durchführen können),
- Suche (Anwenden von Filtern, Boolesche Suche, Ranking usw.).
1.1. Indizierung
Ein leichter lyrischer Exkurs. Weiter werde ich das Konzept des Begriffs einführen - wie es üblich ist, die minimale Einheit für Indizierung und Abfrage zu nennen. Dies ist genau die Einheit, die im Indexwörterbuch gespeichert wird. Es kann ein Wort sein, das auf seine normale Wortform oder Basis, Zahl, E-Mail, Buchstabe n-Gramm oder etwas anderes reduziert ist. In der Regel enthält ein Begriff ein Feld, in dem er indiziert ist oder in dem eine Suche durchgeführt wird.
Zunächst müssen Sie die Eingabedokumente in eine Reihe von Begriffen umwandeln und Stoppwörter herausfiltern. Sie können wie häufig vorkommende Wörter sein - Präpositionen, Konjunktionen, Interjektionen und andere Dinge, zum Beispiel Sonderzeichen, nach denen wir nicht suchen möchten. Damit die Suche mit verschiedenen Wortformen funktioniert, bringen wir während des Indizierungsprozesses normalerweise alle Wörter in einen Grundzustand. Normalerweise wird eines von zwei Verfahren angewendet: entweder Stemming - der Prozess des Isolierens der Basis eines Wortes (Entwicklung-> Entwicklung) oder Lemmatisierung - der Prozess des Bringens eines Wortes in die normale Form (Skills-> Skill).
1.2 Indexstrukturen
Die beliebteste Art, einen Index darzustellen, ist ein invertierter Index. Tatsächlich ist dies eine Art Hash-Tabelle, in der der Schlüssel ein Begriff ist und der Wert eine Liste von Dokumenten (normalerweise eine Liste von Dokument-IDs, die als Buchungsliste bezeichnet wird), in der dieser Begriff vorhanden ist. Normalerweise besteht ein invertierter Index aus zwei Teilen - einem Wörterbuch (Begriffswörterbuch) und einer Liste von Dokumenten für jeden Begriff (Buchungsliste):

Darüber hinaus kann der Index Informationen über die Positionen von Begriffen im Dokument enthalten (Positionsindex), die bei der Suche nach Begriffen in einer bestimmten Entfernung, insbesondere bei Phrasenabfragen, über die Häufigkeit von Begriffen hilfreich sind, um das Ranking und die Erstellung eines Abfrageplans zu erleichtern. Aber mehr dazu weiter unten.
1.2.1 Begriffswörterbuch
Das Wörterbuch speichert alle im Index vorhandenen Begriffe und dient zum schnellen Auffinden von Links zu einer Liste von Dokumenten. Es gibt verschiedene Möglichkeiten, ein Wörterbuch zu speichern:
- Eine Hash-Tabelle, in der der Begriff der Schlüssel ist und der Wert ein Link zu einer Liste von Dokumenten dieses Begriffs ist.
- Eine geordnete Liste, nach der Sie durch binäre Suche suchen können.
- Präfixbaum (trie).
Der optimalste Weg ist die letzte Option, weil Es hat mehrere Vorteile. Erstens belegt der Präfixbaum bei einer großen Anzahl von Begriffen viel weniger Speicher, da die wiederholten Teile der Präfixe nur einmal gespeichert werden. Zweitens erhalten wir sofort die Möglichkeit, Präfixanfragen zu stellen. Und drittens kann ein solcher Baum durch Kombinieren nicht verzweigter Teile komprimiert werden.
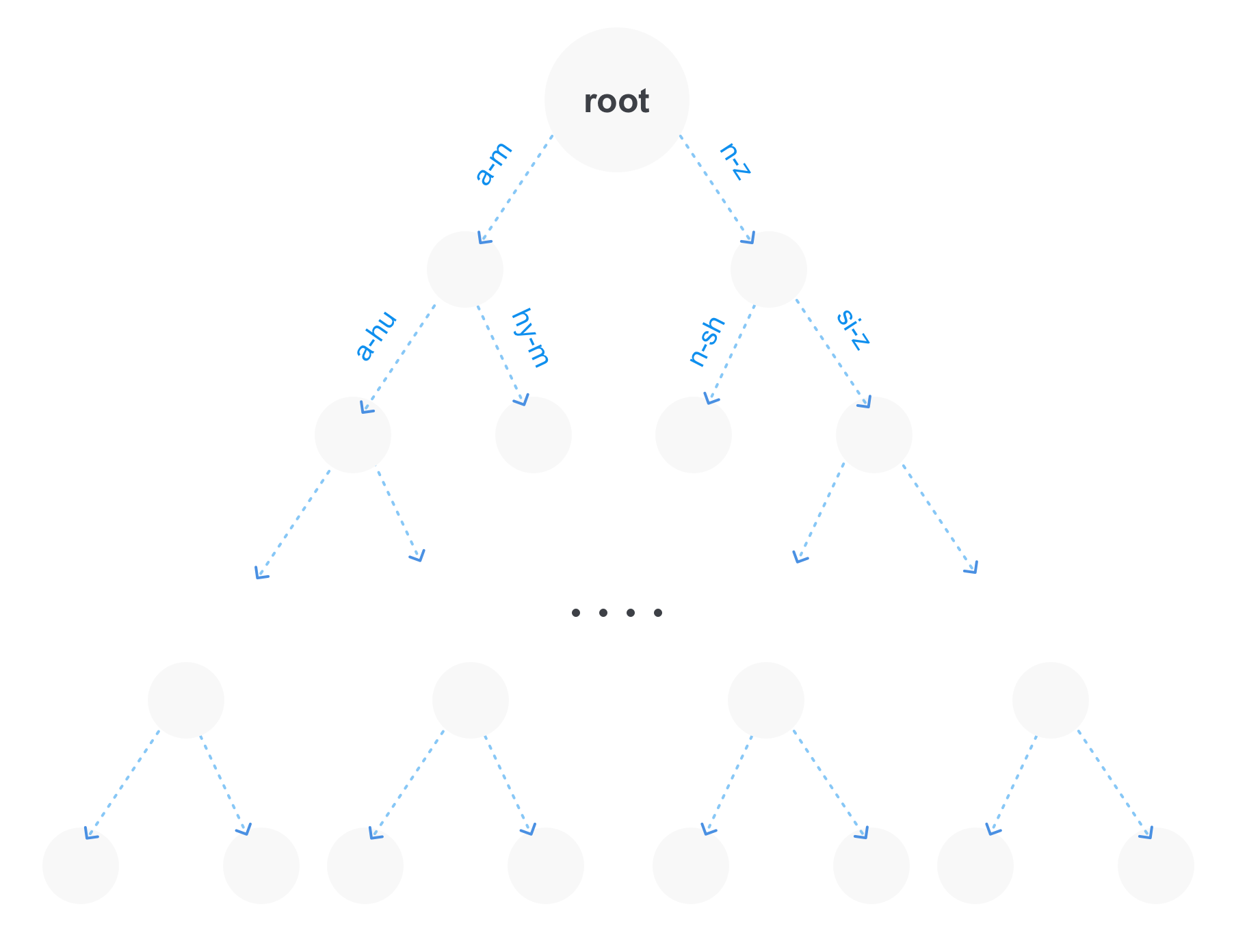
Natürlich ist ein Präfixbaum möglicherweise nicht die einzige Struktur zum Speichern von Begriffen in einem Index. Beispielsweise kann sich auch ein Suffixbaum in der Nähe befinden, was wiederum für Abfragen mit Jokern (Abfragen der Form po * sql) optimaler ist.
1.2.2 Buchungsliste
Die Liste der Dokumente ist eine geordnete Liste der Dokumentkennungen, mit denen einige Optimierungen vorgenommen werden können. Normalerweise speichert es in sich nicht nur eine Liste von Dokumenten, in denen der Begriff vorkommt, sondern auch die Positionen (Buchungen), an denen er vorkommt. Dies löst mehrere Probleme gleichzeitig: Wir wissen sofort, wie oft ein Wort in einem Dokument vorkommt, können Phrasen und Abfragen mit einem bestimmten Abstand zwischen Begriffen erstellen, mehrere Dokumentenlisten gleichzeitig kreuzen und die Positionen der Begriffe betrachten.

Zum Beispiel kommt in dieser Liste mit dem Begriff
scala im 6. Dokument im
Titel das Wort viermal an den Positionen 2, 15, 18 und 25 vor.
1.2.3 Dokumente mit mehreren Feldern
Der größte Teil des Dokuments besteht aus mehreren Feldern, zumindest aus dem Namen des Dokuments und seinem Hauptteil. Dies ist hilfreich, wenn Sie nach einzelnen Teilen des Dokuments suchen und wenn der Begriff beim Ranking von Bedeutung ist (z. B. kann der im Titel vorkommende Begriff als wichtiger angesehen werden).
Außerdem werden im Index normalerweise nicht nur Textfelder gespeichert, sondern auch Zeichen von Dokumenten, einige numerische Werte usw. können gespeichert werden. Die Speicherung im Index erfolgt normalerweise in Form von {Feldbegriff}.

Wenn Sie beispielsweise eine freie Stelle annehmen, werden mehrere Felder gleichzeitig angezeigt: Name, Beschreibung, Firma, Gehaltsabrechnung, Stadt und die erforderliche Erfahrung. Dies ist erforderlich, damit der Benutzer bequem nicht nur nach dem Namen und dem Text des Unternehmens suchen, sondern auch nach Gehalt und Erfahrung filtern, sehen kann, wie viele Stellen in seiner Stadt und in benachbarten Städten frei sind, oder sogar nach Stellen für ein bestimmtes Unternehmen suchen kann.
1.3 Indexkomprimierung und -optimierung
Die Arbeitsgeschwindigkeit ist wichtig für die Suche, daher werden die meisten Indexsuchvorgänge normalerweise im RAM ausgeführt. Zu diesem Zweck ist es sehr wichtig, eine Reihe von Optimierungen auf den Index anzuwenden, die ihn in eine begrenzte Speichergröße einpassen. Darüber hinaus werden in der Regel eine Reihe von Optimierungen angewendet, mit denen Sie sich bei der Suche mit höherer Geschwindigkeit im Index bewegen und unnötige Teile davon überspringen können.
1.3.1 Delta-Komprimierung
Da wir uns daran erinnern, dass die Liste der Dokumente nach Begriff (auch als Buchungsliste bezeichnet) sortiert ist, besteht die erste Idee zum Komprimieren darin, eine Liste mit den ID-Offsets der Dokumente anstelle der Liste mit ID-Dokumenten zu erstellen. Auf einer bestimmten Liste von 6 Bezeichnern sieht es folgendermaßen aus:

Wenn wir uns also durch die Liste bewegen, berechnen wir immer die aktuelle Kennung aus dem zuvor erhaltenen Wert. Zum zweiten Additiv 3 addieren wir beispielsweise den ersten Wert 2 und erhalten ID 5, zum dritten 4 addieren wir 5 und erhalten 9 und so weiter. Bei einer großen Anzahl von Dokumenten funktioniert dies sehr gut, insbesondere in Verbindung mit einer anderen Komprimierungsmethode - dem Aufzeichnen von Zahlen mit variablem Format.
1.3.2 VarByte und VarInt
Auf diese Weise können Sie jedes einzelne Listenelement so speichern, dass es möglichst wenig Speicherplatz beansprucht. Wenn beispielsweise die ersten drei Offsets in nur 1 Byte passen, müssen Sie nicht mehr nehmen. In Anbetracht der Tatsache, dass unsere Liste keine ID-Dokumente, sondern Deltas enthält, ist die Komprimierung sehr effektiv. Bei dieser Darstellung von Zahlen ist das erste Bit jedes Bytes das Flag, ob die Darstellung der aktuellen Zahl auf diesem Byte endet.

Wenn das erste Bit von Byte 0 das letzte Byte der Zahl ist, ist 1 nicht.
1.3.3 Liste überspringen / Sprungtabelle
Eine Überspringliste ist eine der Strukturen, um schnell durch eine Liste von Dokumenten eines bestimmten Begriffs zu blättern und einen unnötigen Teil der Liste zu überspringen. Die Idee ist, Links zu entfernten Elementen der Liste auf der Festplatte vor der Liste selbst zu speichern, da wir nach der Komprimierung nicht sagen können, wo genau sich das 100- oder 200-Dokument befindet. Dies ist beispielsweise praktisch, wenn zwei Begriffe abgefragt werden, wobei ein Begriff häufig vorkommt und der zweite im Gegenteil selten ist und die Liste der Dokumente nur mit der 200. Dokument-ID beginnt. Wenn es dann eine Liste mit Durchläufen für die erste Liste gibt, können wir beim Verschieben Zeit sparen und den unnötigen Block von Bezeichnern sofort überspringen.

1.4 Anfragen
1.4.0 Termabfrage
Die einfachste Art von Anfrage, bei der wir nur die entsprechende Liste von Dokumenten finden und Dokumente ausstellen müssen, die nach dem Ranking sortiert sind.
Auf diese Weise finden wir beispielsweise eine Liste von Positionen für
Java :

1.4.1 Boolesche Abfragen (und oder nicht)
Die boolesche Suche ist einer der wichtigsten Teile beim Abrufen von Informationen, die wir überall finden. Die gesamte boolesche Suche basiert auf einer Kombination aus AND, OR und NOT. Wenn wir beispielsweise nach einer Abfrage in zwei Wörtern suchen:
Java Android , wird sie bei einer einfachen Suche tatsächlich in
Java AND Android konvertiert. Und das bedeutet, dass wir alle Dokumente finden möchten, die beide Wörter enthalten.
Erwähnenswert ist sofort, wie Sie sich in der Liste der Dokumente bewegen. Da die Dokumentenlisten für jeden Begriff sortiert sind, gibt es normalerweise zwei Möglichkeiten, um durch die Listen zu navigieren: Sie können die Dokumente nacheinander durchlaufen, einzeln übergeben oder direkt zu einem bestimmten Dokument wechseln und die nicht benötigten Dokumente überspringen (z. B. wenn die erste Liste viel kleiner ist) und wir müssen nicht einen großen Block von Dokumenten in der zweiten Liste durchgehen). In diesem Fall verwenden wir zuerst den Zeiger aus den Sprungzeigern für die zweite Liste, um so nah wie möglich an die gewünschte Dokument-ID heranzukommen, und bewegen uns dann linear dorthin.
Zum Zeitpunkt der Suche geschieht Folgendes: Im Index für die Begriffe Java und Android befinden sich Listen von Dokumenten, auf die ein Schnittpunkt gesetzt wird. Das heißt, wir finden Dokumente, die beide Begriffe enthalten. Bei dieser Suche werden beide Methoden zum Durchlaufen von Listen für eine schnellere Überquerung verwendet.

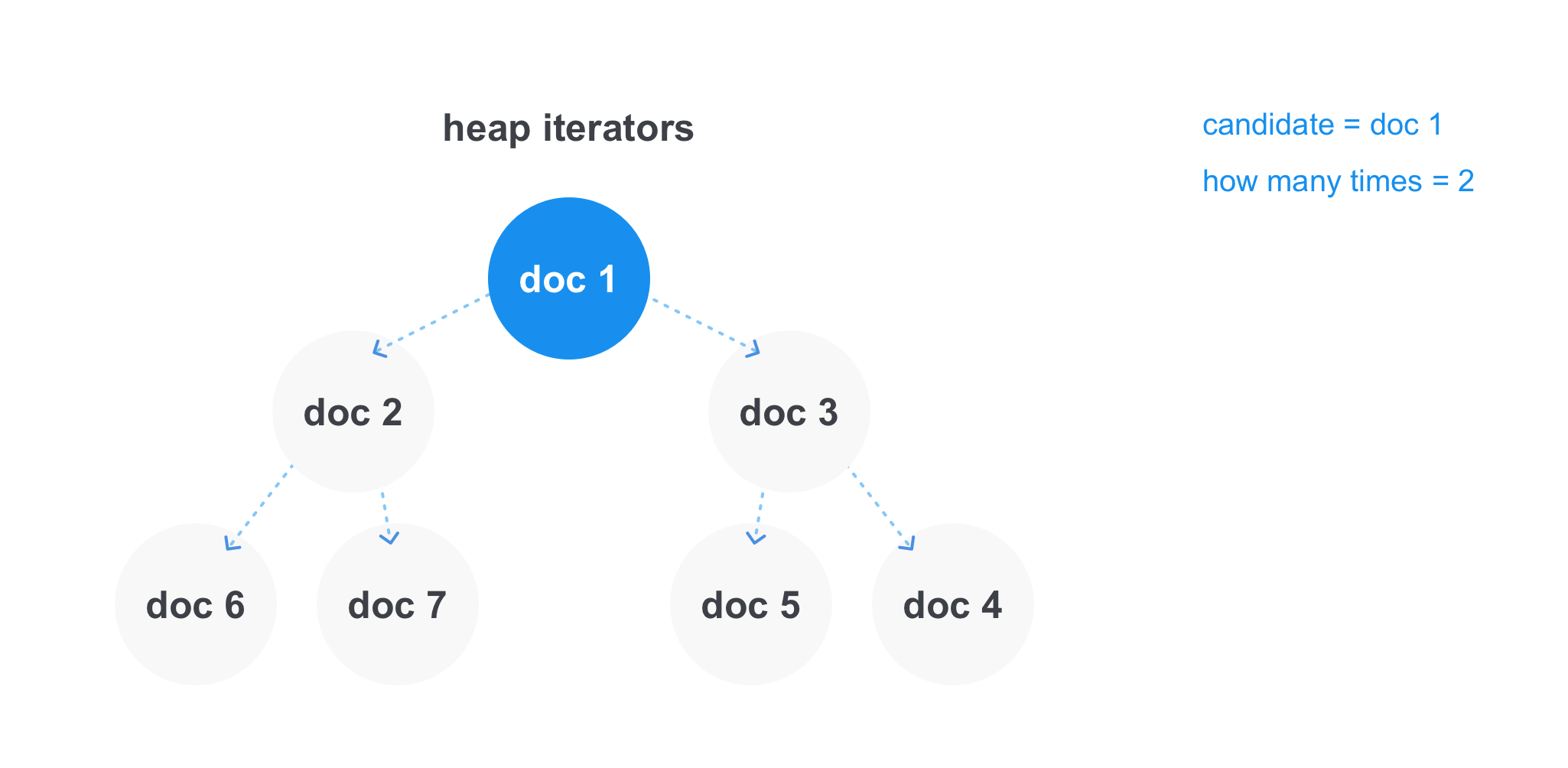
Bei OR-Abfragen des Formulars Java OR Scala, bei denen alle Dokumente gefunden werden müssen, die mindestens einen der Begriffe enthalten, ist die Situation anders. Hier muss der Begriff nicht in allen Dokumentenlisten gleichzeitig enthalten sein. Es gibt jedoch Abfragen mit mehreren ODER-Operatoren, und dann kann die Bedingung für eine Mindestanzahl von Übereinstimmungen auftreten. Beispielsweise kann eine Java- ODER Scala- oder Cotlin- oder Clojure-Abfrage mit mindestens zwei Übereinstimmungen vorliegen, und dann sollten alle Dokumente angezeigt werden, die mindestens zwei Wörter aus der Abfrage enthalten .
In diesem Fall arbeitet der Heap am effizientesten. Wir können darin Links zu Iteratoren jeder Liste speichern und das minimale Element für konstante Zeit erhalten. Nachdem wir das minimale Element genommen haben, entfernen wir den Iterator aus dem Heap, machen einen Schritt nach vorne und fügen ihn erneut dem Heap hinzu. Sie können den aktuellen Kandidaten, der dem Ergebnis und dem Zähler hinzugefügt werden soll, separat speichern, wie oft er sich getroffen hat und in dem Moment, in dem der Kandidat vom minimalen Element im Heap abweicht, prüfen, ob die minimale Anzahl von Übereinstimmungen in der Operation überschritten wird. Und entweder zur endgültigen Ergebnisliste hinzufügen oder das Dokument verwerfen.
1.4.2 Präfix / Joker
Manchmal möchten wir alle Dokumente finden, die ein Wort enthalten, das mit einem bestimmten Präfix beginnt. In solchen Fällen hilft uns die
Präfixanforderung , die wie
jav * aussieht . Eine Präfixanforderung funktioniert sehr gut, wenn das Wörterbuch in einem Präfixbaum implementiert ist. Dann gelangen wir einfach zur Verschachtelung des Präfixes und nehmen alle unten stehenden Begriffe.
1.4.3 Abfragen zu Phrasen und Beinahe-Abfragen
Es gibt Zeiten, in denen Sie die gesamte Phrase suchen müssen, z. B. "Java-Entwickler", oder Wörter suchen müssen, zwischen denen nicht mehr als ein paar Wörter stehen, z. B. "Java" und "Entwickler", zwischen denen nicht mehr als 2 Wörter stehen, damit Sie sie finden können Dokumente mit Java Android Kotlin Entwickler. Hierzu werden zusätzlich Listen von Wortpositionen in jedem Dokument verwendet.

Beim Überqueren der Dokumentenlisten ist alles dasselbe wie bei der UND-Operation. Nachdem das Dokument in beiden Listen gefunden wurde, wird zusätzlich überprüft, ob die Begriffe aufgrund der unterschiedlichen Position (Position) im richtigen Abstand voneinander stehen.
1.4.4 Plan anfordern
Normalerweise wird der Plan vor der Ausführung der Anforderung selbst erstellt. Dies geschieht, um die Ausführung der Anforderung zu optimieren und Optimierungen wie eine Liste mit Auslassungen für die Liste der Dokumente durchzuführen.
Der einfachste Weg, Ihre Abfrage zu optimieren, besteht darin, die Dokumentenlisten in der Reihenfolge ihrer zunehmenden Größe zu durchqueren. So verschwenden wir keine Dokumente aus großen Listen, die nicht in kleinen Listen enthalten sind.
Lassen Sie uns zum Beispiel die
Abfrage für Android AND Java AND SQL analysieren . Angenommen, die Android-Liste enthält 10 Dokumente, in SQL-20 und in Java-100. In diesem Fall ist es am besten, zuerst die kleinsten Listen zu kreuzen, und die optimierte Abfrage sieht aus wie
(Android UND SQL) UND Java .
Im Fall von OR ist es am einfachsten, die Anzahl der Dokumente an der Kreuzung als die Summe von zwei potenziell geschnittenen Listen zu zählen.
1.4.5 Abfrageerweiterung - Synonyme
Zusätzlich zu dem, was der Benutzer in die Suchleiste eingibt, versucht die Suche normalerweise, die Abfrage selbst zu erweitern, um relevantere Dokumente zu finden. Viel kann verwendet werden, um die Suche zu erweitern: der Abfrageverlauf des Benutzers, einige personalisierte Daten über ihn und mehr. Daneben gibt es aber auch eine universelle Möglichkeit, die Anfrage zu erweitern - Synonyme.
In diesem Fall wird beim Schreiben von Dokumenten in den Index der Begriff durch einen „Link“ im Synonymwörterbuch ersetzt:
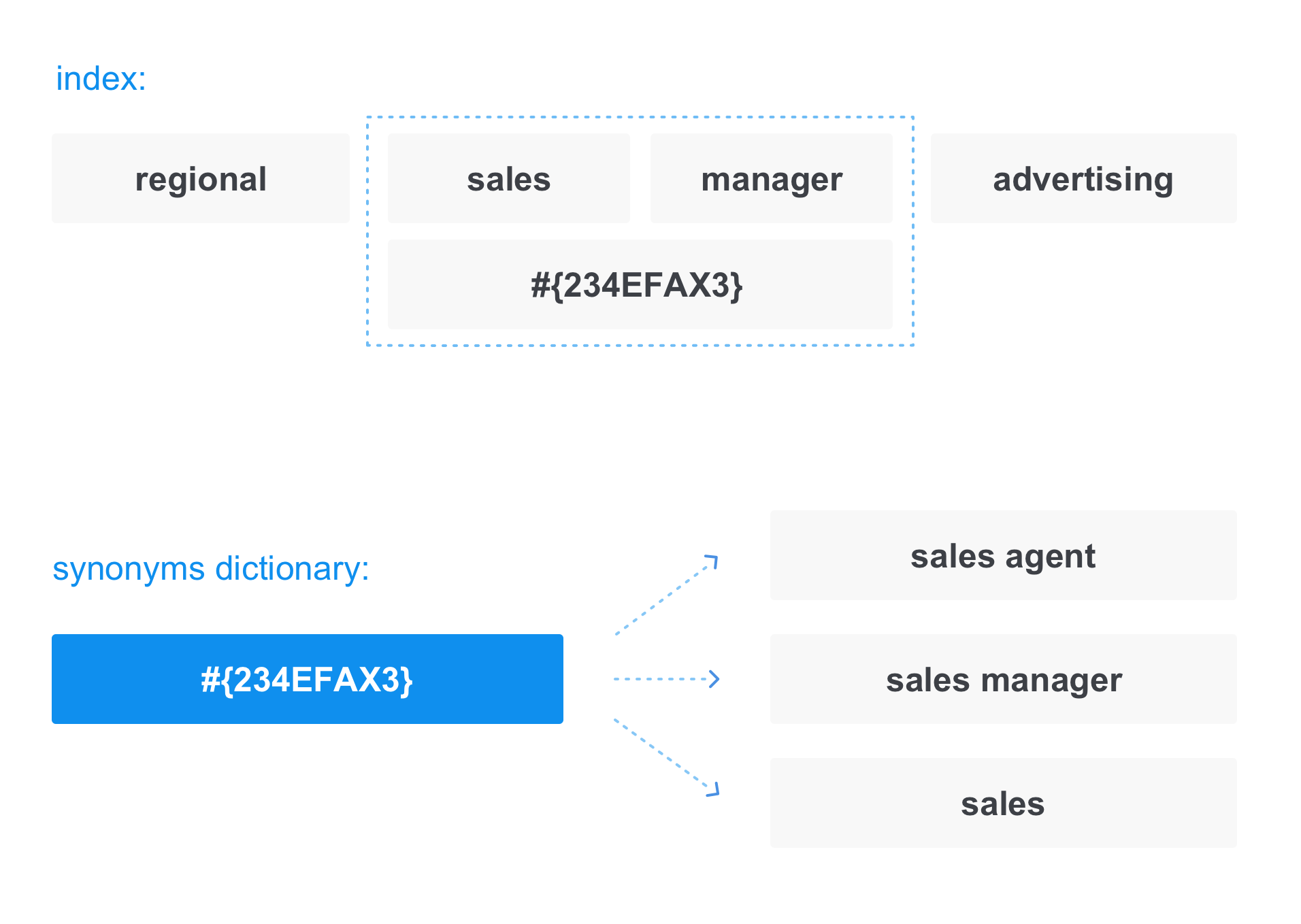
Das gleiche passiert beim Konvertieren einer Anfrage. Wenn wir beispielsweise einen
Verkaufsleiter anfordern, sieht die Anfrage tatsächlich so aus:

In der Antwort erhalten wir daher nicht nur die Dokumente, die den Vertriebsleiter enthalten, sondern auch die Dokumente, die den Vertriebsmitarbeiter und den Vertrieb enthalten.
1.5 Filtern
1.5.1 Schnellbereichsfilter
Manchmal wollen wir etwas nach einer Reihe von Werten filtern, zum Beispiel nach Erfahrung in Jahren. Angenommen, wir möchten alle offenen Stellen mit der erforderlichen Erfahrung von 3 bis 11 Jahren finden. Die erste Entscheidung besteht darin, eine Anfrage mit allen Optionen aus dem Bereich zu stellen und diese über OR zu kombinieren. Das Problem ist jedoch, dass möglicherweise zu viele Werte vorhanden sind. Eine Möglichkeit, dieses Problem zu lösen, besteht darin, den Wert mit mehreren Genauigkeiten gleichzeitig aufzuzeichnen:

In diesem Fall speichern wir 5 Genauigkeitswerte: ein Jahr (wir betrachten dies als den Anfangswert), zwei, vier, acht und sechzehn.
Bei der Aufzeichnung geschieht dann Folgendes: Wenn Sie beispielsweise ein Dokument mit einer Erfahrung von 6 Jahren aufnehmen, erfassen wir den Wert sofort mit aller Genauigkeit:

Beim Filtern von „von 3 bis 11 Jahren“ geschieht Folgendes: Wir wählen nur die Werte aus, die wir mit der erforderlichen Genauigkeit benötigen, und wir erhalten nur 3 statt 8 Werte und wir erhalten die Abfrage
(realer Wert == 3) ODER (Genauigkeit 4 == 4) ODER (Genauigkeit 4 == 8)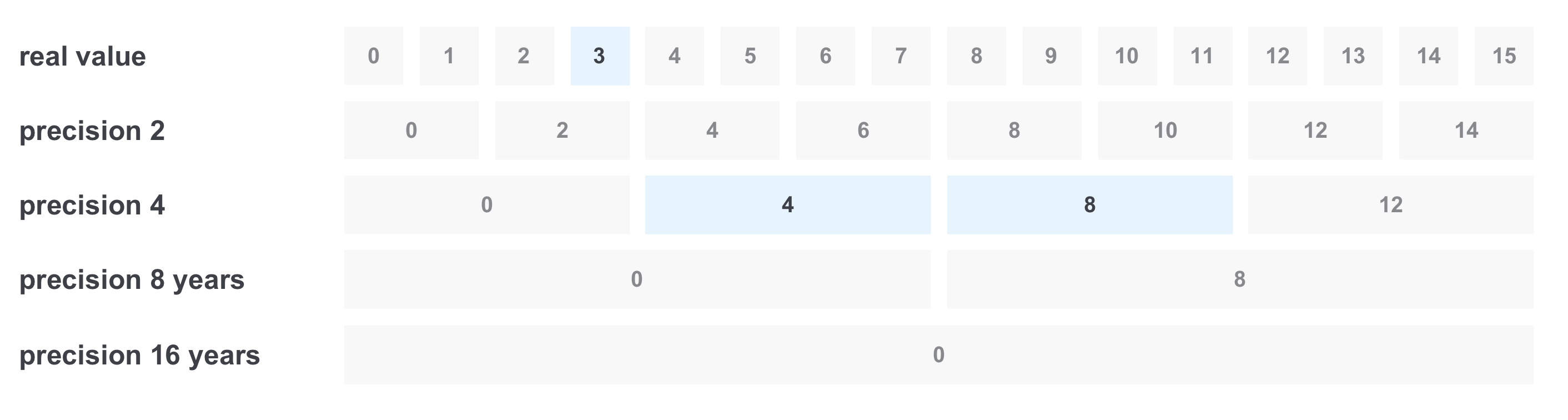
1.5.2 Bitmasken
Bitmasken sind ein wesentlicher Bestandteil eines Index. Die wichtigste Verwendung ist das Filtern gelöschter Dokumente. Wenn Sie ein Dokument aus dem Index löschen, erfolgt das physische Löschen nicht sofort. Neben dem Index wird eine spezielle Struktur geschrieben, in der jedes Bit die ID des Dokuments im Index bedeutet. Beim Löschen wird ein Bit ausgelöst. Bei der Suche werden diese Dokumente gefiltert und fallen nicht in die Ausgabe.
Sie können auch Bitmasken verwenden, um Berechtigungen für jeden Benutzer für bestimmte Dokumente festzulegen und einzelne beliebte Filter zwischenzuspeichern. Dann werden Bitmasken normalerweise getrennt vom Index gespeichert.
Zum Beispiel haben wir beliebte Filter: die Stadt Moskau, nur Teilzeit, ohne Berufserfahrung. Dann können wir vor der Anforderung die bereits gespeicherten Bitmasken für diese Dokumente abrufen, sie hinzufügen und die endgültige Bitmaske abrufen - welche Dokumente alle drei dieser Filter durchlaufen, wodurch Zeit beim Filtern gespart wird.

2. Rangliste
Wie wir uns erinnern, besteht die Hauptaufgabe der Suche darin, die relevantesten Informationen in kürzester Zeit zu erhalten. Dabei hilft uns die Rangfolge der Dokumente, nachdem wir die Dokumente per Textabfrage gefiltert und die erforderlichen Filter und Rechte angewendet haben.
Der einfachste und billigste Weg, ein Ranking durchzuführen, besteht darin, Dokumente einfach nach Datum zu sortieren. In einigen Systemen wurde dies zuvor beispielsweise in den Nachrichten oder in Immobilienankündigungen durchgeführt, sodass dem Benutzer zuerst die neuesten Dokumente angezeigt wurden.
Manchmal kann ein Rangmodell nach der Anzahl der in einem Dokument gefundenen Wörter verwendet werden, beispielsweise wenn nicht so viele Dokumente vorhanden sind und wir alle Dokumente suchen möchten, in denen mindestens eines der Abfragewörter gefunden wird. In diesem Fall sind die Dokumente relevanter, in denen alle oder mehrere Wörter aus der Abfrage enthalten sind.
Natürlich sind diese Methoden derzeit bereits irrelevant geworden, und sie können eher auf die Geschichte des Problems zurückgeführt werden.
2.1 TF-IDF
TF-IDF (Termhäufigkeit - inverse Dokumenthäufigkeit) ist eine der grundlegendsten und am häufigsten verwendeten Ranglistenformeln. Das Wesentliche der Formel besteht darin, die überall verwendeten Begriffe, z. B. Präpositionen und Interjektionen, zu verringern und aussagekräftigere Begriffe zu erstellen, die selten sind, wodurch erste Dokumente mit selteneren und aussagekräftigeren Begriffen aus der Abfrage angezeigt werden. Lassen Sie uns nun die Formel in Teile zerlegen:
TF (Termhäufigkeit) ist die Häufigkeit des im Dokument vorkommenden Terms. Es wird einfach berechnet:
TF-Begriff "Java" = Anzahl der Begriffe "Java" im Dokument / Anzahl aller Begriffe im Dokument
IDF (inverse Dokumenthäufigkeit) - die Umkehrung der Häufigkeit, mit der das Wort in der Dokumentensammlung vorkommt. Reduziert das Gewicht häufig verwendeter Wörter.
IDF (`java`) = log (Anzahl der Dokumente in der Sammlung / Anzahl der Dokumente, in denen der Begriff` java` vorkommt)Um die TF-IDF des Begriffs Java zu erhalten, müssen wir nur die erhaltenen TF- und IDF-Werte multiplizieren. , , . , , developer , , java developer .
2.2
, , . , , , .
2.3 BM25 BM*
BM25 (Okapi best match 25) TF-IDF . BM25F, ( ).
2.4
, :
- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5
, , . ,
.
2.6 Top k
, . , , .
, .
top k .
— . k, k
* . heap. n*log(n) k.
. , , , 10 12, score 10 score . , n — (n*page size) .
3.
3.1
— . , .
, : , , . , . . ( , ). (merge).
, , :

. , , , - .
3.2 (megre)
— . «» — . , , ( ).

, , , . :
4.
, , . , - (, . .). , , , .

4.1
(, hh , ), . .
, , . -, , . -, , , .
4.2
, . , .
, hh,
, , - :
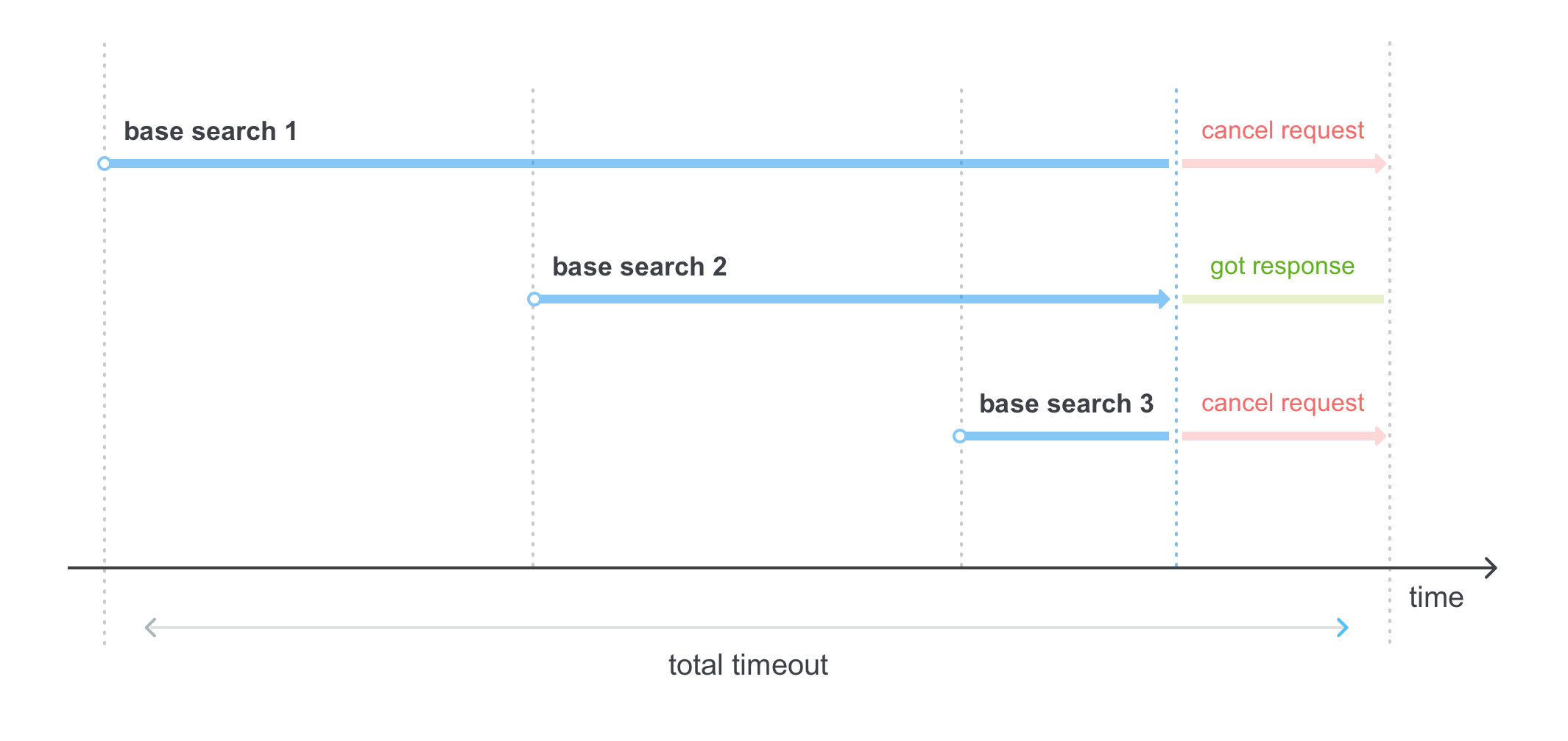
5. …
, , , . , : , , , , , (highlight), . , , , top k .
:
Das ist alles, ich danke Ihnen allen für Ihre Aufmerksamkeit. Es ist interessant, Ihre Kommentare und Fragen zu hören.PS
Ich möchte Gdanschin dafür danken, dass er mir beim Schreiben dieses Artikels geholfen hat .