Das
Anti-Plagiat-System ist eine spezialisierte Suchmaschine. Wie es sich für eine Suchmaschine gehört, mit eigener Suchmaschine und eigenen Suchindizes. Unser größter Index in Bezug auf die Anzahl der Quellen ist natürlich das russischsprachige Internet. Vor langer Zeit haben wir beschlossen, alles in diesen Index aufzunehmen, was Text (und kein Bild, Musik oder Video) ist, auf Russisch geschrieben ist, eine Größe von mehr als 1 KB hat und kein „fast Duplikat“ von etwas ist, das bereits im Index.
Dieser Ansatz ist insofern gut, als er keine komplexen Vorbehandlungen erfordert und das Risiko minimiert, dass das Baby mit Wasser bespritzt wird. Dabei wird ein Dokument übersprungen, aus dem der Text möglicherweise ausgeliehen werden kann. Andererseits wissen wir daher wenig darüber, welche Dokumente letztendlich im Index enthalten sind.
Während der Internetindex wächst - und jetzt sind es für eine Sekunde bereits mehr als 300 Millionen Dokumente nur
in russischer Sprache - stellt sich eine ganz natürliche Frage: Gibt es in diesem Dump viele wirklich nützliche Dokumente?
Und da wir (
yury_chekhovich und
Andrey_Khazov ) diese Überlegungen aufgegriffen haben, warum beantworten wir dann nicht gleichzeitig noch ein paar Fragen. Wie viele wissenschaftliche Dokumente sind indexiert und wie viele unwissenschaftlich? Wie hoch ist der Anteil wissenschaftlicher Artikel an Diplomen, Artikeln und Abstracts? Wie ist die Verteilung der Dokumente nach Themen?

Da es sich um Hunderte Millionen Dokumente handelt, müssen Mittel zur automatischen Datenanalyse verwendet werden, insbesondere die Technologie des maschinellen Lernens. Natürlich ist in den meisten Fällen die Qualität der Expertenbewertung den Maschinenmethoden überlegen, aber es wäre zu teuer, Personal für die Lösung einer derart umfangreichen Aufgabe zu gewinnen.
Wir müssen also zwei Probleme lösen:
- Erstellen Sie einen „wissenschaftlichen“ Filter, mit dem Sie einerseits Dokumente, die nicht in Struktur und Inhalt enthalten sind, automatisch verwerfen und andererseits die Art des wissenschaftlichen Dokuments bestimmen können. Machen Sie sofort einen Vorbehalt, der sich unter "wissenschaftlich" in keiner Weise auf die wissenschaftliche Bedeutung oder Zuverlässigkeit der Ergebnisse bezieht. Die Aufgabe des Filters besteht darin, Dokumente in Form eines wissenschaftlichen Artikels, einer Dissertation, eines Diploms usw. zu trennen. aus anderen Arten von Texten, nämlich Belletristik, journalistischen Artikeln, Nachrichtenartikeln usw.;
- Implementieren Sie ein Tool zum Rubriken wissenschaftlicher Dokumente, das das Dokument mit einem der wissenschaftlichen Fachgebiete verknüpft (z. B. Physik und Mathematik , Wirtschaft , Architektur , Kulturwissenschaften usw.).
Gleichzeitig müssen wir diese Probleme lösen, indem wir ausschließlich mit der Textsicherung von Dokumenten arbeiten und nicht deren Metadaten, Informationen über die Position von Textblöcken und Bildern in Dokumenten verwenden.
Lassen Sie uns anhand eines Beispiels veranschaulichen. Schon ein flüchtiger Blick genügt, um einen
wissenschaftlichen Artikel zu unterscheiden

aus zum Beispiel einem
Kindermärchen .

Wenn es jedoch nur eine Textebene gibt (für dieselben Beispiele), müssen Sie den Inhalt lesen.
Wissenschaftlicher Filter und Sortierung nach Typ
Wir lösen die Aufgaben nacheinander:
- In der ersten Phase filtern wir nichtwissenschaftliche Dokumente heraus.
- In der zweiten Phase werden alle Dokumente, die als wissenschaftlich identifiziert wurden, nach Typ klassifiziert: Artikel, Dissertation, Doktorarbeit, Diplom usw.
Es sieht ungefähr so aus:
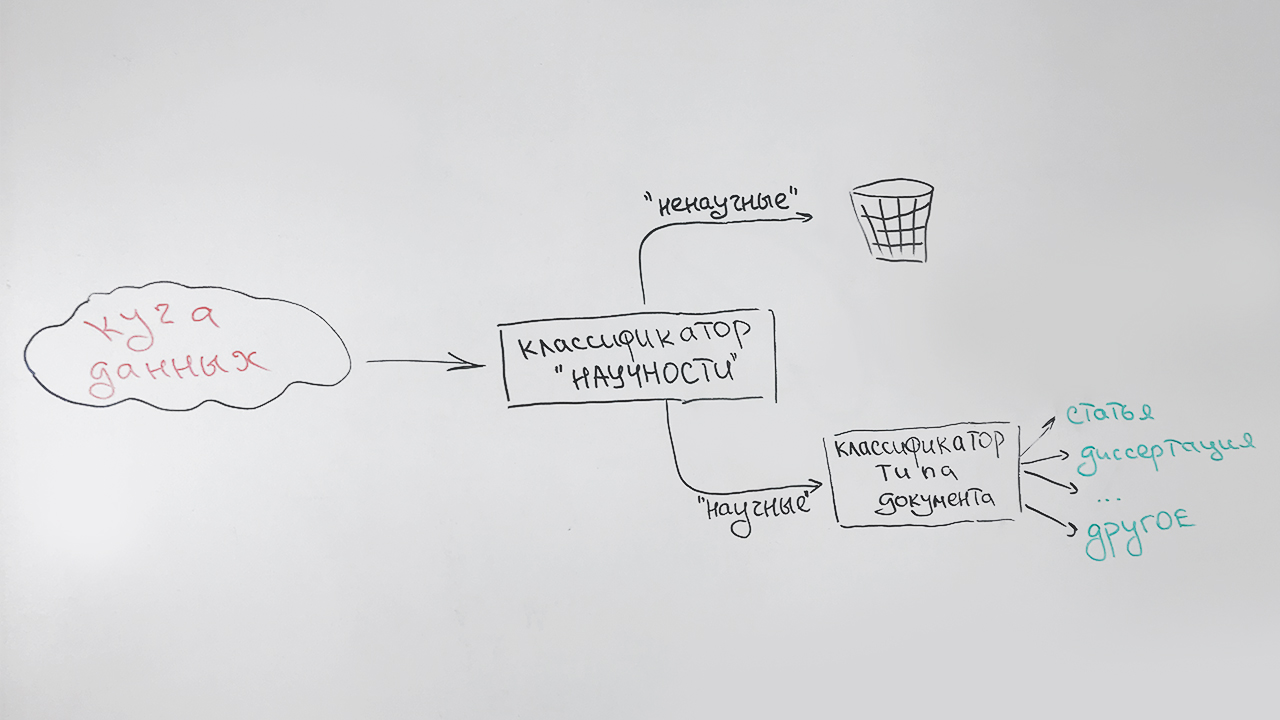
Ein spezieller Typ (undefiniert) wird Dokumenten zugewiesen, die keinem Typ zuverlässig zugeordnet werden können (dies sind hauptsächlich kurze Dokumente - Seiten wissenschaftlicher Websites, Abstracts von Abstracts). Zum Beispiel wird diese Veröffentlichung diesem Typ zugeordnet, der einige Anzeichen von Wissenschaftlichkeit aufweist, aber keinem der oben genannten ähnlich ist.
Es gibt einen anderen Umstand, der berücksichtigt werden muss. Dies ist eine hohe Geschwindigkeit des Algorithmus und ein geringer Ressourcenbedarf - dennoch ist unsere Aufgabe eine Hilfsaufgabe. Daher verwenden wir eine sehr kleine indikative Beschreibung der Dokumente:
- durchschnittliche Länge eines Satzes in einem Text;
- Anteil der Stoppwörter in Bezug auf alle Wörter des Textes;
- Lesbarkeitsindex ;
- Prozentsatz der Satzzeichen in Bezug auf alle Zeichen des Textes;
- die Anzahl der Wörter aus der Liste ("Zusammenfassung", "Dissertation", "Diplom", "Zertifizierung", "Spezialität", "Monographie" usw.) im ersten Teil des Textes (das Attribut ist für die Titelseite verantwortlich);
- die Anzahl der Wörter aus der Liste ("Liste", "Literatur", "bibliografisch" usw.) im letzten Teil des Textes (das Attribut ist für die Liste der Literatur verantwortlich);
- der Anteil der Buchstaben im Text;
- durchschnittliche Wortlänge;
- die Anzahl der eindeutigen Wörter im Text.
Alle diese Zeichen sind insofern gut, als sie schnell berechnet werden. Als Klassifikator verwenden wir den Random Forest-Algorithmus (
Random Forest ), eine beliebte Klassifizierungsmethode beim maschinellen Lernen.
Bei Qualitätsbewertungen ohne eine von Experten markierte Stichprobe ist es schwierig, daher lassen wir den Klassifikator in die Sammlung von Artikeln der wissenschaftlichen elektronischen Bibliothek
Elibrary.ru ein . Wir gehen davon aus, dass alle Artikel als wissenschaftlich gekennzeichnet werden.
100% Ergebnis? Nichts dergleichen - nur 70%. Vielleicht haben wir einen schlechten Algorithmus erstellt? Wir schauen uns die gefilterten Artikel an. Es stellt sich heraus, dass viele unwissenschaftliche Texte in wissenschaftlichen Fachzeitschriften veröffentlicht werden: Leitartikel, Glückwünsche zu Jubiläen, Todesanzeigen, Rezepten und sogar Horoskopen. Die selektive Betrachtung von Artikeln, die der Klassifikator als wissenschaftlich betrachtet, zeigt keine Fehler. Daher erkennen wir den Klassifikator als geeignet an.
Jetzt übernehmen wir die zweite Aufgabe. Hier kann man nicht auf Qualitätsmaterial für das Training verzichten. Wir bitten die Prüfer, eine Probe vorzubereiten. Wir erhalten etwas mehr als 3,5 Tausend Dokumente mit folgender Verteilung:
| Dokumenttyp | Die Anzahl der Dokumente in der Stichprobe |
|---|
| Artikel | 679 |
| Doktorarbeiten | 250 |
| Abstracts von Doktorarbeiten | 714 |
| Sammlungen wissenschaftlicher Konferenzen | 75 |
| Dissertationen | 159 |
| Abstracts von Dissertationen | 189 |
| Monographien | 107 |
| Studienführer | 403 |
| Thesen | 664 |
| Undefinierter Typ | 514 |
Um das Problem der Klassifizierung mehrerer Klassen zu lösen, verwenden wir dieselbe zufällige Gesamtstruktur und dieselben Funktionen, um nichts Besonderes zu berechnen.
Wir erhalten folgende Klassifizierungsqualität:
| Genauigkeit | Vollständigkeit | F-Maß |
|---|
| 81% | 76% | 79% |
Die Ergebnisse der Anwendung des trainierten Algorithmus auf indizierte Daten sind in den folgenden Diagrammen dargestellt. Abbildung 1 zeigt, dass mehr als die Hälfte der Sammlung aus wissenschaftlichen Dokumenten besteht und unter diesen wiederum mehr als die Hälfte der Dokumente Artikel sind.
 Abb. 1. Verteilung von Dokumenten durch "wissenschaftliche"
Abb. 1. Verteilung von Dokumenten durch "wissenschaftliche"Abbildung 2 zeigt die Verteilung der wissenschaftlichen Dokumente nach Typ, mit Ausnahme des Typs „Artikel“. Es ist ersichtlich, dass der zweitbeliebteste Typ eines wissenschaftlichen Dokuments ein Lehrbuch ist und der seltenste Typ eine Doktorarbeit.
 Abb. 2. Verteilung anderer wissenschaftlicher Dokumente nach Typ
Abb. 2. Verteilung anderer wissenschaftlicher Dokumente nach TypIm Allgemeinen entsprechen die Ergebnisse den Erwartungen. Vom schnellen "groben" Klassifikator brauchen wir nicht mehr.
Thema eines Dokuments definieren
So kam es, dass noch kein einheitlicher, allgemein anerkannter Klassifikator für wissenschaftliche Arbeiten geschaffen wurde. Am beliebtesten sind heute die Überschriften
VAK ,
GRNTI ,
UDC . Für alle Fälle haben wir uns entschlossen, Dokumente thematisch in jede dieser Kategorien einzuteilen.
Um einen thematischen Klassifikator zu erstellen, verwenden wir einen Ansatz, der auf der
Themenmodellierung basiert, einer statistischen Methode zum Erstellen eines Modells für eine Sammlung von Textdokumenten, bei der für jedes Dokument die Wahrscheinlichkeit bestimmt wird, zu bestimmten Themen zu gehören. Als Werkzeug zum
Erstellen eines thematischen Modells verwenden wir die offene
BigARTM- Bibliothek. Wir haben diese Bibliothek bereits zuvor verwendet und wissen, dass sie sich hervorragend für die thematische Modellierung großer Sammlungen von Textdokumenten eignet.
Es gibt jedoch eine Schwierigkeit. Bei der thematischen Modellierung ist die Bestimmung der Zusammensetzung und Struktur von Themen das Ergebnis der Lösung eines Optimierungsproblems in Bezug auf eine bestimmte Sammlung von Dokumenten. Wir können sie nicht direkt beeinflussen. Natürlich entsprechen die Themen, die sich aus der Abstimmung auf unsere Sammlung ergeben, keinem der Zielklassifikatoren.
Um den endgültigen unbekannten Wert des Rubrikators eines bestimmten Anforderungsdokuments zu erhalten, müssen wir daher eine weitere Konvertierung durchführen. Zu diesem Zweck suchen wir im BigARTM-Themenbereich unter Verwendung des Nearest-Neighbour-Algorithmus (
k-NN ) nach mehreren Dokumenten, die der Abfrage mit bekannten Rubrikatoren am ähnlichsten sind, und weisen dem Abfragedokument auf dieser Grundlage die relevanteste Klasse zu.
In vereinfachter Form ist der Algorithmus in der Abbildung dargestellt:

Um das Modell zu trainieren, verwenden wir Dokumente aus offenen Quellen sowie Daten von Elibrary.ru mit bekannten Fachgebieten der Higher Attestation Commission, SRSTI, UDC. Wir entfernen aus der Sammlung Dokumente, die an sehr allgemeine Positionen von Rubrikatoren gebunden sind, z. B.
allgemeine und komplexe Probleme der Natur- und exakten Wissenschaften , da solche Dokumente die endgültige Klassifizierung stark beeinträchtigen.
Die endgültige Sammlung enthielt ungefähr 280.000 Dokumente für die Schulung und 6.000 Dokumente zum Testen für jede der Rubriken.
Für unsere Zwecke reicht es aus, die Werte der Überschriften der ersten Ebene vorherzusagen. Für einen Text mit einem GRNTI-Wert von
27.27.24: Harmonische Funktionen und ihre Verallgemeinerungen ist beispielsweise die Vorhersage von Abschnitt
27: Mathematik korrekt.
Um die Qualität des entwickelten Algorithmus zu verbessern, fügen wir einige Ansätze hinzu, die auf dem guten alten
Naive Bayes- Klassifikator basieren. Als Zeichen wird die Häufigkeit der Wörter verwendet, die für jedes der Dokumente mit einem bestimmten Wert der HAC-Überschrift am charakteristischsten sind.
Warum so schwer? Infolgedessen nehmen wir die Vorhersagen beider Algorithmen, gewichten sie und erstellen für jede Anforderung eine durchschnittliche Vorhersage. Diese Technik des maschinellen Lernens wird als
Ensemble bezeichnet . Ein solcher Ansatz führt zu einer spürbaren Qualitätssteigerung. Beispielsweise betrug für die SRSTI-Spezifikation die Genauigkeit des ursprünglichen Algorithmus 73%, die Genauigkeit des naiven Bayes-Klassifikators 65% und ihre Assoziationen 77%.
Als Ergebnis erhalten wir ein solches Schema unseres Klassifikators:
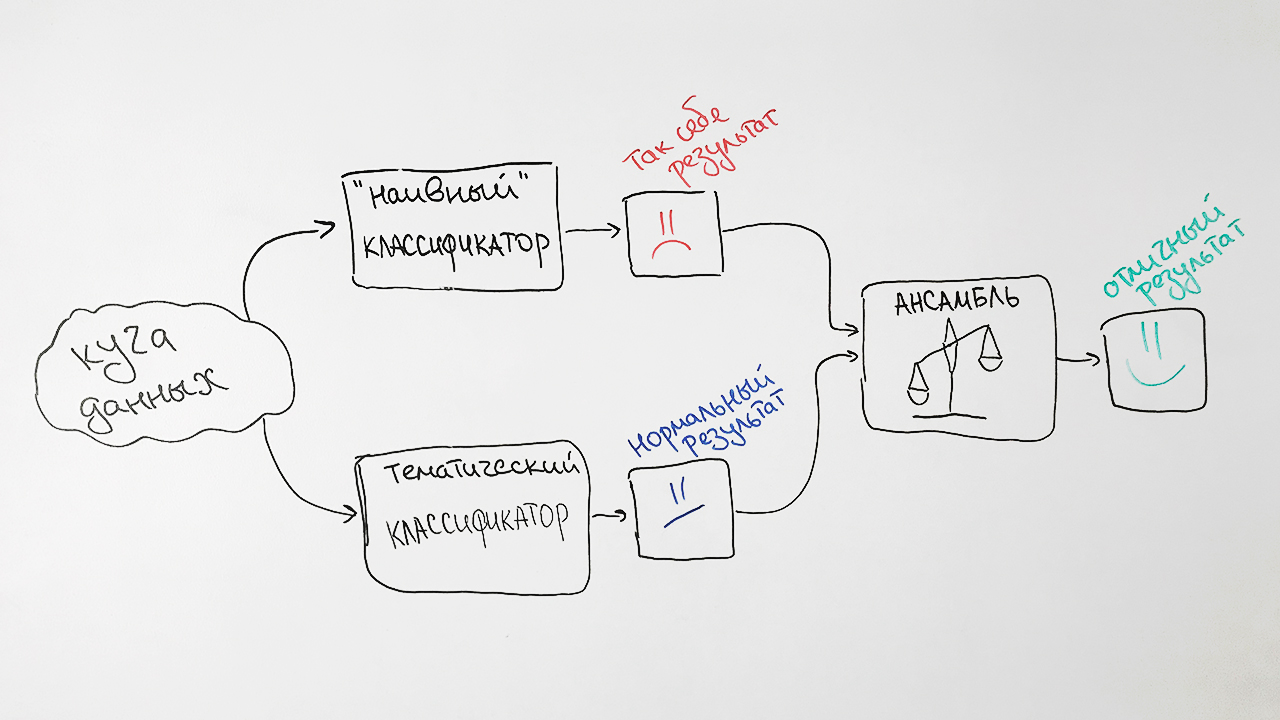
Wir stellen zwei Faktoren fest, die die Ergebnisse des Klassifikators beeinflussen. Erstens kann jedem Dokument mehr als ein Rubrikatorwert gleichzeitig zugewiesen werden. Zum Beispiel die Werte der Überschriften der Higher Attestation Commission 25.00.24 und 08.00.14 (
wirtschaftliche ,
soziale und politische Geographie und
Weltwirtschaft ). Und das wird kein Fehler sein.
Zweitens werden in der Praxis die Werte der Rubriken fachmännisch, dh subjektiv, platziert. Ein eindrucksvolles Beispiel sind scheinbar unterschiedliche Themen wie
Maschinenbau, Land- und Forstwirtschaft . Unser Algorithmus klassifizierte die Artikel mit dem Titel
„Maschinen zum Ausdünnen des Waldes“ und
„Voraussetzungen für die Entwicklung einer Traktorserie in Standardgröße für die Bedingungen der nordwestlichen Zone“ dem Maschinenbau und bezog sich gemäß der ursprünglichen Anordnung genau auf die Landwirtschaft.
Aus diesem Grund haben wir uns entschlossen, die drei wahrscheinlichsten Werte für jede der Kategorien anzuzeigen. Für den Artikel
„Professionelle Lehrertoleranz (am Beispiel der Tätigkeit eines Russischlehrers einer multiethnischen Schule)“ lauteten
die Wahrscheinlichkeiten für die Werte der Überschrift der Kommission für höhere Bescheinigungen wie folgt:
| Wert der Rubrik | Wahrscheinlichkeit |
|---|
| Pädagogische Wissenschaften | 47% |
| Psychologische Wissenschaften | 33% |
| Kulturwissenschaften | 20% |
Die Genauigkeit der resultierenden Algorithmen war:
| Rubricator | Top 3 Genauigkeit |
|---|
| SRSTI | 93% |
| VAK | 92% |
| UDC | 94% |
Die Diagramme zeigen die Ergebnisse einer Studie zur Verteilung von Dokumentthemen im russischsprachigen Internetindex für alle (Abbildung 3) und nur für wissenschaftliche (Abbildung 4) Dokumente. Es ist ersichtlich, dass sich die meisten Dokumente auf die Geisteswissenschaften beziehen: Die häufigsten Spezifikationen sind Wirtschaft, Recht und Pädagogik. Darüber hinaus ist ihr Anteil unter nur wissenschaftlichen Dokumenten noch größer.
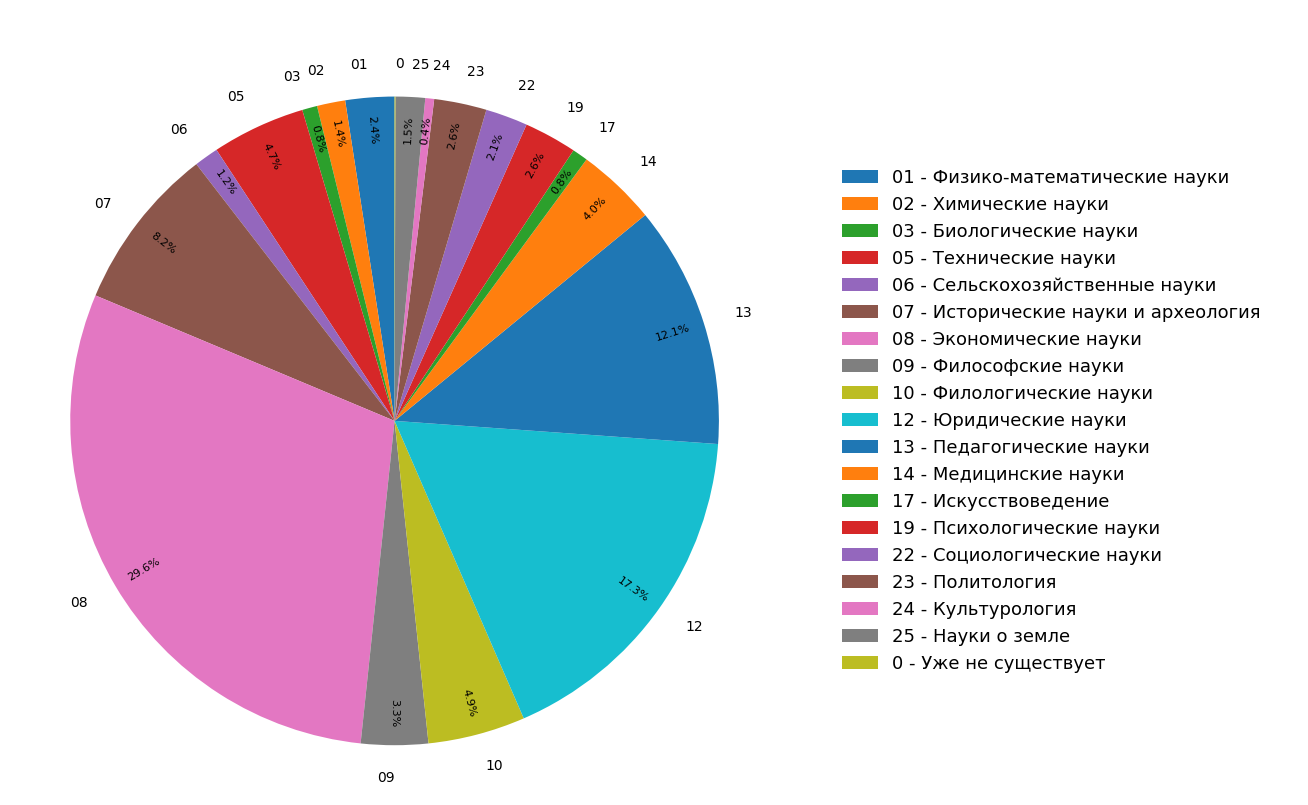 Abb. 3. Verteilung der Themen im Suchmodul
Abb. 3. Verteilung der Themen im Suchmodul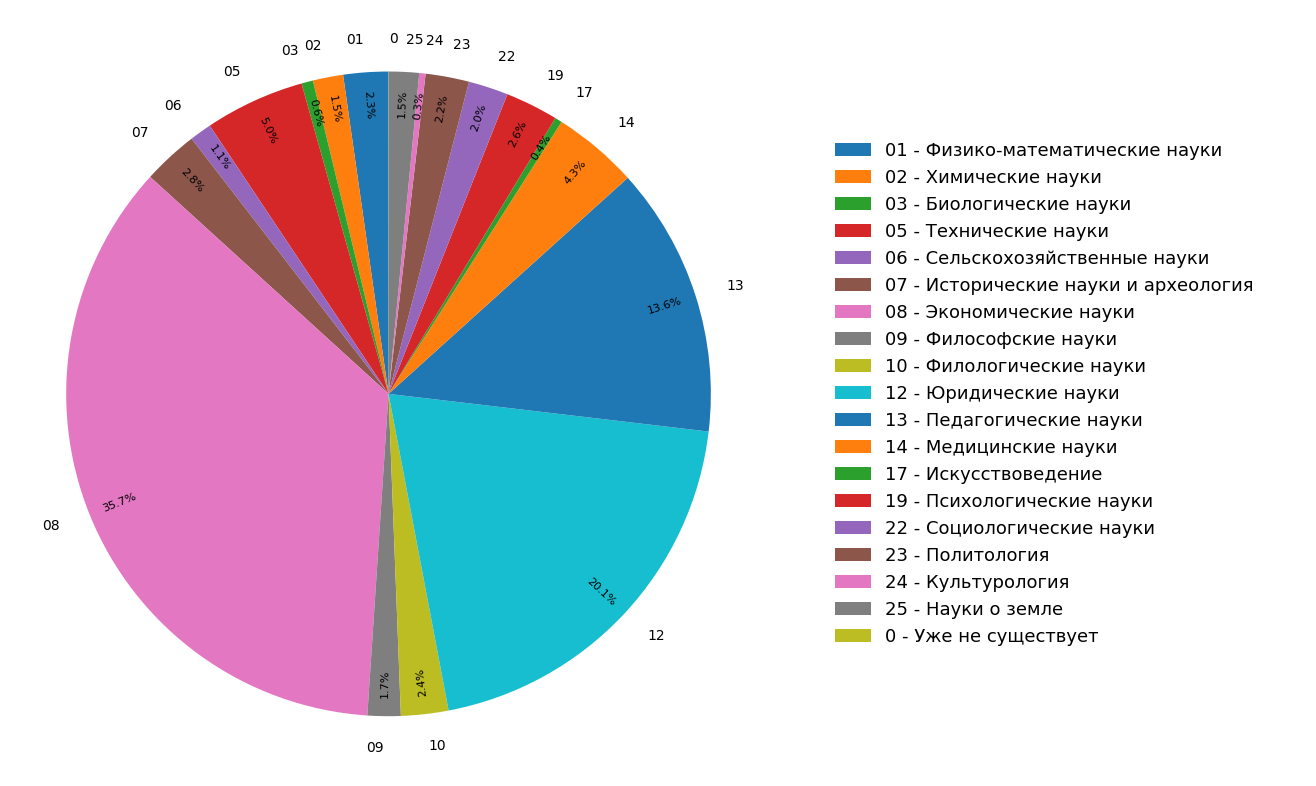 Abb. 4. Die Verteilung von Themen wissenschaftlicher Dokumente.
Abb. 4. Die Verteilung von Themen wissenschaftlicher Dokumente.Infolgedessen haben wir aus den vorliegenden Materialien buchstäblich nicht nur die thematische Struktur des indizierten Internets gelernt, sondern auch zusätzliche Funktionen entwickelt, mit denen Sie einen Artikel oder ein anderes wissenschaftliches Dokument gleichzeitig in drei thematische Kategorien „klassifizieren“ können.

Die oben beschriebene Funktionalität wird jetzt aktiv im Anti-Plagiat-System implementiert und wird den Benutzern bald zur Verfügung stehen.