
Netflix ist von der Verfügbarkeit von Diensten besessen. Wir haben es bereits mehr als einmal in unserem Blog überprüft und erklärt, wie wir es schaffen, unsere Ziele zu erreichen. Wir verwenden Leistungsschalter, Parallelitätslimits, Chaostests und mehr. Heute präsentieren wir Ihnen einen weiteren innovativen Ansatz, der die Stabilität der Anwendung unter extremen Belastungen erheblich verbessert und kaskadierende Servicefehler vermeidet - adaptive Grenzen für Parallelverbindungen. Es sind keine weiteren Anstrengungen erforderlich, um die Grenzen paralleler Verbindungen zu bestimmen, sodass das System eine kurze Reaktionszeit einhalten kann. Im Rahmen dieser Ankündigung veröffentlichen wir auch eine einfache Java-Bibliothek mit Integrationsfunktionen für Servlets, Steuerungsprogramme und gRPC.
Beginnen wir mit den Grundlagen
Die Grenze für parallele Verbindungen ist die maximale Anzahl von Anforderungen, die das System zu einem bestimmten Zeitpunkt verarbeiten kann. In der Regel hängt dieser Betrag von einer begrenzten Ressource ab, z. B. der Verarbeitungsleistung des Zentralprozessors. Normalerweise wird die Grenze der Parallelverbindungen eines Systems nach dem Littleschen Gesetz berechnet, das wie folgt lautet: Für ein stabiles System entspricht die maximale Anzahl der Parallelverbindungen dem Produkt aus der durchschnittlichen Zeit, die für die Verarbeitung der Anforderung aufgewendet wurde, und der durchschnittlichen Intensität eingehender Anforderungen (L = λW). Anforderungen, die das Parallelverbindungslimit überschreiten, können vom System nicht sofort verarbeitet werden, sodass sie in die Warteschlange gestellt oder abgelehnt werden. Das Einreihen in die Warteschlange ist eine wichtige Funktion, mit der Sie das System vollständig nutzen können, wenn Anforderungen ungleichmäßig empfangen werden und eine andere Bearbeitungszeit erforderlich ist.
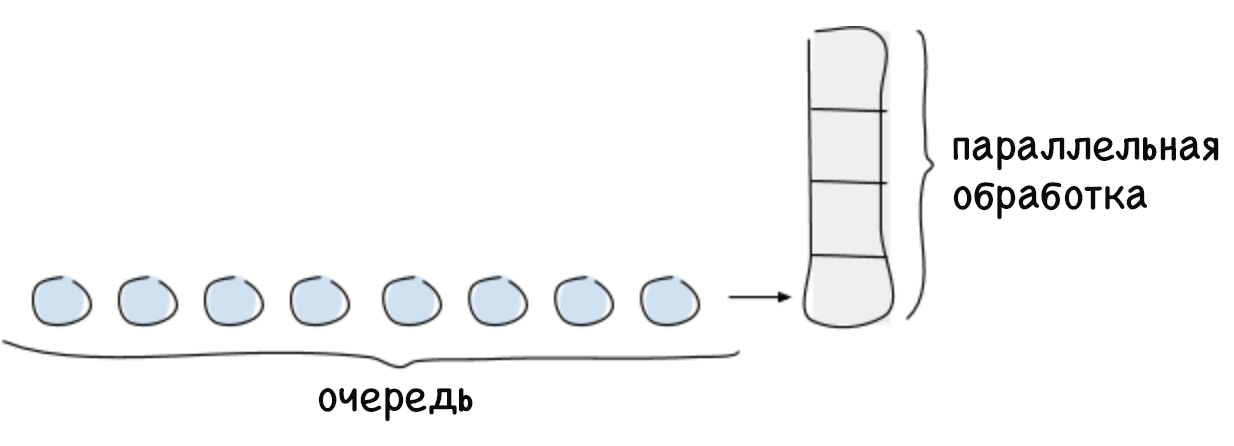
Wenn es keine Begrenzung für die Warteschlange gibt, kann ein Systemabsturz auftreten, beispielsweise wenn die Intensität von Anforderungen über einen längeren Zeitraum höher ist als die Geschwindigkeit ihrer Verarbeitung. Wenn die Warteschlange wächst, wächst auch die Verzögerung, was zu einer Überschreitung der Wartezeit für Anforderungen führt. Dies wird fortgesetzt, bis der freie Speicher aufgebraucht ist. Danach stürzt das System ab. Wenn Sie die zunehmende Verzögerungszeit nicht verfolgen, wirkt sich dies negativ auf die anrufenden Dienste aus und führt zu kaskadierenden Systemfehlern.

Die Verwendung von Parallelverbindungsgrenzen ist eine Standardpraxis, aber die Schwierigkeit besteht darin, sie für große dynamisch verteilte Systeme zu bestimmen, bei denen sich Parameter wie die Verzögerungszeit und die mögliche Anzahl von Parallelverbindungen ständig ändern. Das Wesentliche unserer Lösung ist die Fähigkeit, die Grenze paralleler Verbindungen dynamisch zu bestimmen. Diese Grenze kann als die Anzahl der eingehenden Anforderungen (parallel und in der Warteschlange ausgeführt) dargestellt werden, die das System verarbeiten kann, bis die Leistung abnimmt (und die Verzögerungszeit zunimmt).
Lösung
Zuvor haben Netflix-Mitarbeiter durch zeitaufwändige Leistungstests und Profilerstellung manuelle Grenzwerte für gleichzeitige Verbindungen festgelegt. Die resultierende Zahl war für einen bestimmten Zeitraum korrekt, aber bald begann sich die Topologie des Systems aufgrund von Teilfehlern, automatischer Skalierung oder der Einführung von zusätzlichem Code, der die Verzögerungszeit beeinflusste, zu ändern. Infolgedessen ist das Limit veraltet. Wir wussten, dass wir zu mehr fähig waren, dass es nicht mehr ausreichte, die Verbindungsgrenzen einfach statisch zu bestimmen. Wir brauchten eine Möglichkeit, die dem System selbst innewohnenden Grenzen automatisch zu bestimmen. Gleichzeitig wollten wir diese Methode:
- erforderte keine manuelle Arbeit;
- erforderte keine zentrale Koordinierung;
- könnte den Grenzwert ohne Informationen über die Hardware- oder Systemtopologie bestimmen;
- An Änderungen in der Systemtopologie angepasst;
- war einfach in Bezug auf die Implementierung und die notwendigen Berechnungen.
Um dieses Problem zu lösen, haben wir uns dem bewährten TCP-Algorithmus zur Verfolgung von Überlastungen zugewandt. Dieser Algorithmus bestimmt die Anzahl von Datenpaketen, die parallel übertragen werden können (d. H. Die Größe des Überlauffensters), ohne die Verzögerungszeit zu erhöhen oder die Wartezeit zu überschreiten. Diese Algorithmen verwenden verschiedene Indikatoren, um die Grenze der gleichzeitig übertragenen Pakete zu bestimmen und die Größe des Überlauffensters entsprechend zu ändern.

Die blaue Farbe im Bild zeigt die unbekannte Grenze für parallele Verbindungen zum System. Zuerst sendet der Client eine kleine Anzahl von gleichzeitigen Anforderungen und beginnt dann, das System regelmäßig zu überprüfen, um festzustellen, ob es mehr Anforderungen verarbeiten kann, indem das Überlauffenster vergrößert wird, bis dies zu einer Zunahme der Verzögerung führt. Wenn die Verzögerung immer noch zunimmt, entscheidet der Absender, dass er das Limit erreicht hat, und verringert erneut die Größe des Überlauffensters. Ein solches kontinuierliches Testen des Grenzwerts spiegelt sich in der Grafik wider, die Sie oben sehen.
Unser Algorithmus basiert auf dem TCP-Überlastungsverfolgungsalgorithmus, der die Beziehung zwischen der minimalen Verzögerungszeit (dem bestmöglichen Szenario, in dem die Warteschlange nicht verwendet wird) und der Verzögerungszeit berücksichtigt, die regelmäßig gemessen wird, wenn Anforderungen ausgeführt werden. Dieses Verhältnis ermöglicht es festzustellen, dass sich eine Warteschlange gebildet hat, die eine Zunahme der Verzögerung hervorruft. Dieses Verhältnis gibt den Gradienten oder die Größe der Verzögerungszeitänderung an:
Gradient = (RTTnoload / RTTactual) . Wenn der Wert gleich eins ist, verstehen wir, dass es keine Warteschlange gibt und das Limit erhöht werden kann. Ein Wert kleiner als eins zeigt an, dass die Warteschlange voll ist und das Limit reduziert werden muss. Bei jeder neuen Messung der Verzögerungszeit wird der Grenzwert basierend auf dem obigen Verhältnis angepasst, und damit ändert sich die zulässige Warteschlangengröße gemäß dieser einfachen Formel:
_ = _ × + _
Für mehrere Iterationen berechnet der Algorithmus einen Grenzwert, der es nicht nur ermöglicht, die Verzögerungszeit auf einem niedrigen Niveau zu halten, sondern auch die erforderliche Warteschlange für Anforderungen bei Aktivitätsausbrüchen zu bilden. Die gültige Warteschlangengröße kann konfiguriert werden. Es wird verwendet, um zu bestimmen, wie schnell sich das Parallelitätslimit erhöhen kann. Als Standardgröße haben wir die Quadratwurzel des aktuellen Grenzwerts gewählt. Diese Wahl ist auf die nützliche Eigenschaft der Quadratwurzel zurückzuführen: Bei kleinen Werten ist sie im Vergleich zur Grenze groß genug, um ein schnelles Wachstum zu gewährleisten, bei großen Werten hingegen ist ihr relativer Wert geringer, was die Stabilität des Systems erhöht.
Adaptive Grenzen in Aktion
Adaptive Limits auf der Serverseite lehnen übermäßige Anforderungen ab und behalten eine geringe Latenz bei, wodurch die Systeminstanz sich selbst und die Dienste, von denen sie abhängt, schützen kann. Früher, als es nicht möglich war, übermäßige Anforderungen abzulehnen, führte eine stetige Erhöhung der Anzahl der Anforderungen pro Sekunde oder der Verzögerungszeit zu einer noch stärkeren Erhöhung dieser Zeit und letztendlich zum Ausfall des gesamten Systems. Heutzutage können Dienste unnötige Workloads beseitigen und eine geringe Latenz aufrechterhalten, während sie mit anderen Stabilisierungstools wie der automatischen Skalierung arbeiten.
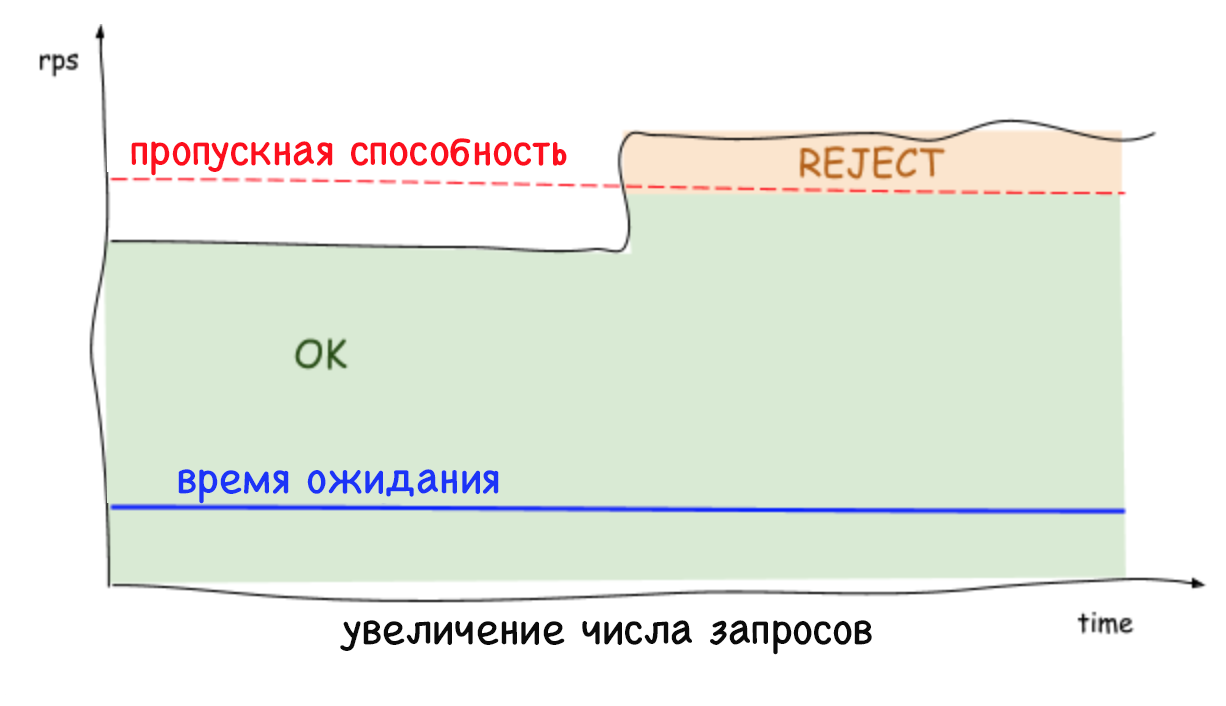
Es ist wichtig zu beachten, dass auf Serverebene (und ohne Koordination) Grenzwerte festgelegt werden, damit der Datenverkehr zu jedem Server stark sinken und zunehmen kann. Daher ist es nicht überraschend, dass das erkannte Limit und die Anzahl der gleichzeitigen Verbindungen je nach Server unterschiedlich sein können. Dies gilt insbesondere in einer Cloud-Umgebung mit mehreren Clients. Infolgedessen kann es zu einer Situation kommen, in der ein Server überlastet ist, der Rest ist jedoch frei. Gleichzeitig erreicht beim Ausgleich der Last auf der Clientseite in fast 100% der Fälle nur eine wiederholte Anforderung den Server mit freien Ressourcen. Und das ist noch nicht alles: Es gibt keinen Grund mehr zu befürchten, dass wiederholte Anforderungen einen DDOS-Angriff auslösen, da Dienste Datenverkehr mit minimalen Auswirkungen auf die Leistung schnell (in weniger als einer Millisekunde) ablehnen können.
Fazit
Durch die Verwendung adaptiver Grenzwerte für parallele Verbindungen muss nicht mehr manuell festgelegt werden, wie und in welchen Fällen unsere Dienste den Datenverkehr ablehnen sollen. Darüber hinaus erhöht es auch die allgemeine Zuverlässigkeit und Verfügbarkeit unseres gesamten Microservice-Ökosystems.
Wir freuen uns, Ihnen unsere Implementierungsmethoden und die Gesamtintegration dieser Lösung
mitteilen zu können, die Sie in der öffentlichen Bibliothek unter
github.com/Netflix/concurrency-limits finden . Wir hoffen, dass unser Code den Benutzern hilft, ihre Dienste vor kaskadierenden Fehlern und Problemen mit zunehmender Latenz zu schützen und ihre Verfügbarkeit zu erhöhen.