
Hallo Habr!
Mein Name ist Alexey Solodky, ich bin PHP-Entwickler bei Badoo. Und heute werde ich eine Textversion meines Vortrags für das erste Badoo PHP Meetup veröffentlichen. Ein Video dieses und anderer Berichte aus dem Mitap finden Sie
hier .
Jedes System, das aus mindestens zwei Komponenten besteht (und wenn Sie sowohl PHP als auch eine Datenbank haben, sind dies zwei Komponenten), ist bei der Interaktion zwischen diesen Komponenten einer ganzen Reihe von Risiken ausgesetzt.
Die Plattformabteilung, in der ich arbeite, integriert neue interne Services in unsere Anwendung. Und bei der Lösung dieser Probleme haben wir Erfahrungen gesammelt, die ich teilen möchte.
Unser Backend ist ein PHP-Monolith, der mit vielen Diensten interagiert (derzeit gibt es etwa 50 davon). Dienste interagieren selten miteinander. Die Probleme, über die ich in diesem Artikel spreche, sind aber auch für die Microservice-Architektur relevant. In diesem Fall interagieren die Dienste sehr aktiv miteinander. Je mehr Interaktion Sie haben, desto mehr Probleme haben Sie.
Überlegen Sie, was zu tun ist, wenn der Dienst abstürzt oder langweilig wird, wie die Erfassung von Metriken organisiert wird und was zu tun ist, wenn Sie durch all das nicht gerettet werden.
Service-Absturz
Früher oder später fällt der Server, auf dem Ihr Dienst installiert ist. Es wird sicher passieren, und Sie können sich nicht dagegen verteidigen - verringern Sie nur die Wahrscheinlichkeit. Sie können durch Hardware, Netzwerk, Code, erfolglose Bereitstellung enttäuscht werden - alles. Und je mehr Server Sie haben, desto häufiger wird dies passieren.
Wie können Sie Ihre Dienste in einer Welt überleben lassen, in der Server ständig abstürzen? Ein allgemeiner Ansatz zur Lösung dieser Problemklasse ist die Redundanz.
Redundanz wird überall auf verschiedenen Ebenen eingesetzt: von Eisen bis zu ganzen Rechenzentren. Zum Beispiel RAID1 zum Schutz vor Festplattenausfällen oder ein Backup-Netzteil für Ihren Server im Falle eines Ausfalls des ersten. Dieses Schema wird auch häufig auf Datenbanken angewendet. Hierfür können Sie beispielsweise Master-Slave verwenden.
Betrachten wir typische Redundanzprobleme am Beispiel des einfachsten Schemas:
Die Anwendung kommuniziert ausschließlich mit dem Master, während im Hintergrund asynchron Daten an den Slave übertragen werden. Wenn der Master abstürzt, wechseln wir zum Slave und arbeiten weiter.
Nachdem wir den Master wiederhergestellt haben, machen wir einfach einen neuen Slave daraus und der alte verwandelt sich in einen Master.
Das Schema ist einfach, weist aber auch viele Nuancen auf, die für redundante Schemata charakteristisch sind.
Laden
Nehmen wir an, ein Server aus dem obigen Beispiel kann ungefähr 100.000 RPS aushalten. Jetzt beträgt die Last 60k RPS und alles funktioniert wie eine Uhr.
Mit der Zeit steigt jedoch die Belastung der Anwendung und damit des Masters. Sie können es ausgleichen, indem Sie einen Teil des Messwerts auf einen Slave verschieben.
Sieht ziemlich gut aus. Hält die Last, der Server ist nicht mehr im Leerlauf. Aber das ist eine schlechte Idee. Es ist wichtig, sich daran zu erinnern, warum Sie den Slave ursprünglich angehoben haben - um bei Problemen mit dem Haupt-Slave darauf umzuschalten. Wenn Sie begonnen haben, beide Server zu laden, müssen Sie beim Absturz Ihres Masters - und früher oder später - den Hauptverkehr vom Master auf den Sicherungsserver umschalten, der bereits geladen ist. Eine solche Überlastung wird Ihr System entweder furchtbar langsam machen oder es vollständig deaktivieren.
Daten
Das Hauptproblem beim Hinzufügen einer Fehlertoleranz zu einem Dienst ist der lokale Status. Wenn Ihr Dienst zustandslos ist, d. H. Keine veränderlichen Daten speichert, stellt die Skalierung kein Problem dar. Wir erheben einfach so viele Instanzen, wie wir benötigen, und gleichen die Anforderungen zwischen ihnen aus.
Wenn der Dienst zustandsbehaftet ist, können wir dies nicht mehr tun. Sie müssen darüber nachdenken, wie Sie dieselben Daten auf allen Instanzen unseres Dienstes speichern können, damit sie konsistent bleiben.
Um dieses Problem zu lösen, wird einer von zwei Ansätzen verwendet: entweder synchrone oder asynchrone Replikation. Im Allgemeinen empfehle ich Ihnen, die asynchrone Option zu verwenden, da das Schreiben im Allgemeinen einfacher und schneller ist und Sie unter den gegebenen Umständen prüfen müssen, ob Sie auf synchron umschalten müssen.
Eine wichtige Nuance, die bei der Arbeit mit asynchroner Replikation berücksichtigt werden muss, ist die
eventuelle Konsistenz . Dies bedeutet, dass zu einem bestimmten Zeitpunkt auf verschiedenen Slaves Daten in unvorhersehbaren und unterschiedlichen Zeitintervallen hinter dem Master zurückbleiben können.
Dementsprechend können Sie nicht jedes Mal Daten von einem zufälligen Server lesen, da dann unterschiedliche Antworten auf dieselben Benutzeranforderungen kommen können. Um dieses Problem zu umgehen, wird der Mechanismus der
Sticky-Sessions verwendet , der sicherstellt, dass alle Anforderungen eines Benutzers an eine Instanz gehen.
Die Vorteile eines synchronen Ansatzes bestehen darin, dass sich die Daten immer in einem konsistenten Zustand befinden und das Risiko eines Datenverlusts geringer ist (da davon ausgegangen wird, dass sie erst aufgezeichnet werden, nachdem alle Server dies getan haben). Sie müssen dies jedoch mit der Schreibgeschwindigkeit und Komplexität des Systems selbst bezahlen (z. B. verschiedene Quorum-Algorithmen zum Schutz vor
Split-Brain ).
Schlussfolgerungen
- Reserve. Wenn die Daten selbst und die Verfügbarkeit eines bestimmten Dienstes wichtig sind, stellen Sie sicher, dass Ihr Dienst den Sturz eines bestimmten Computers überlebt.
- Berücksichtigen Sie bei der Berechnung der Last den Ausfall einiger Server. Wenn Ihr Cluster über vier Server verfügt, stellen Sie sicher, dass bei einem Ausfall die drei verbleibenden die Last ziehen.
- Wählen Sie den Replikationstyp abhängig von den Aufgaben.
- Legen Sie nicht alle Eier in einen Korb. Stellen Sie sicher, dass Sie weit genug voneinander entfernt sind. Abhängig von der Kritikalität der Serviceverfügbarkeit können sich Ihre Server in verschiedenen Racks in einem Rechenzentrum oder in verschiedenen Rechenzentren in verschiedenen Ländern befinden. Es hängt alles davon ab, wie viel globale Katastrophe Sie wollen und bereit sind zu überleben.
Stummschaltungsdienst
Irgendwann beginnt Ihr Dienst möglicherweise sehr langsam zu arbeiten. Dieses Problem kann aus vielen Gründen auftreten: übermäßige Auslastung, Netzwerkverzögerungen, Hardwareprobleme oder Codefehler. Es sieht aus wie ein nicht so schreckliches Problem, aber tatsächlich ist es heimtückischer als es scheint.
Stellen Sie sich vor: Ein Benutzer fordert eine Seite an. Wir greifen gleichzeitig und nacheinander auf die vier Dämonen zu, um sie zu zeichnen. Sie reagieren schnell, alles funktioniert gut.
Angenommen, dieser Fall wird mit nginx mit einer festen Anzahl von PHP-FPM-Workern (z. B. mit zehn) behandelt. Wenn jede Anfrage ungefähr 20 ms lang verarbeitet wird, kann mit Hilfe einfacher Berechnungen verstanden werden, dass unser System ungefähr fünfhundert Anfragen pro Sekunde verarbeiten kann.
Was passiert, wenn einer dieser vier Dienste stumpf wird und die Verarbeitung von Anforderungen an ihn von 20 ms auf ein Zeitlimit von 1000 ms ansteigt? Es ist wichtig zu bedenken, dass die Verzögerung bei der Arbeit mit dem Netzwerk unendlich groß sein kann. Daher müssen Sie immer ein Zeitlimit festlegen (in diesem Fall entspricht es einer Sekunde).
Es stellt sich heraus, dass das Backend gezwungen ist, auf das Ablaufzeitlimit zu warten und den Fehler vom Daemon zu empfangen und zu verarbeiten. Dies bedeutet, dass der Benutzer die Seite in einer Sekunde statt in zehn Millisekunden empfängt. Langsam, aber nicht tödlich.
Aber was ist hier das eigentliche Problem? Tatsache ist, dass der Durchsatz bei jeder pro Sekunde verarbeiteten Anfrage auf tragische Weise auf zehn Anfragen pro Sekunde sinkt. Und der elfte Benutzer kann keine Antwort mehr erhalten, selbst wenn er eine Seite angefordert hat, die in keiner Weise mit einem langweiligen Dienst verbunden ist. Nur weil alle zehn Mitarbeiter auf eine Zeitüberschreitung warten und keine neuen Anfragen bearbeiten können.
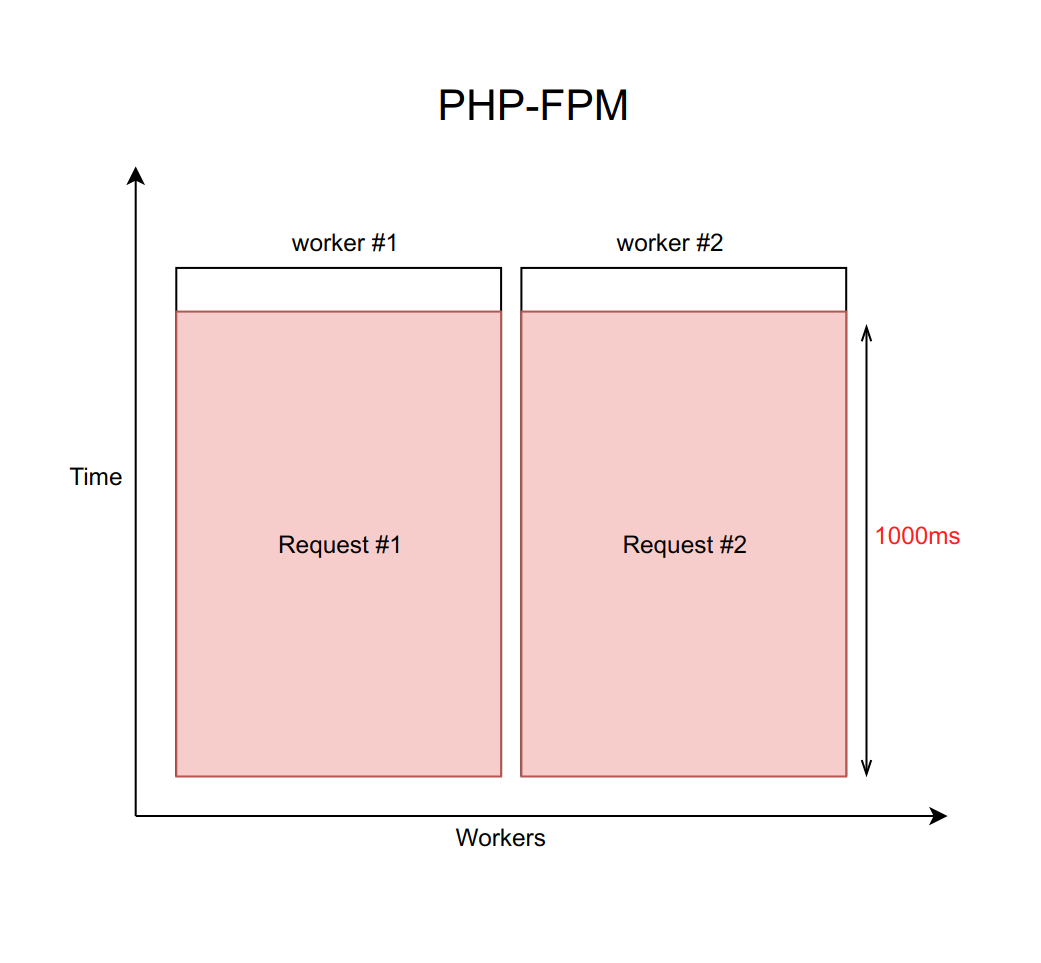
Es ist wichtig zu verstehen, dass dieses Problem nicht durch eine Erhöhung der Anzahl der Arbeitnehmer gelöst werden kann. Schließlich benötigt jeder Mitarbeiter eine bestimmte Menge an RAM für seine Arbeit, auch wenn er keine echte Arbeit ausführt, sondern nur in Erwartung einer Zeitüberschreitung hängt. Wenn Sie daher die Anzahl der Mitarbeiter nicht entsprechend den Funktionen Ihres Servers begrenzen, wird der gesamte Server durch das Erhöhen von immer mehr neuen Mitarbeitern belastet. Dieser Fall ist ein Beispiel für einen Kaskadenfehler, wenn der Ausfall eines Dienstes, auch wenn er für den Benutzer nicht kritisch ist, einen Ausfall des gesamten Systems verursacht.
Lösung
Es gibt ein Muster, das als
Leistungsschalter bezeichnet wird . Seine Aufgabe ist ganz einfach: Er muss irgendwann einen langweiligen Dienst einstellen. Hierzu wird ein Proxy zwischen dem Dienst und den Arbeitern platziert. Dies kann entweder PHP-Code mit Speicher oder ein Daemon auf dem lokalen Host sein. Es ist wichtig zu beachten, dass dieser Proxy bei mehreren Instanzen (Ihr Dienst wird repliziert) jede Instanz separat verfolgen muss.
Wir haben unsere Implementierung dieses Musters geschrieben. Aber nicht, weil wir gerne Code schreiben, sondern weil es bei der Lösung dieses Problems vor vielen Jahren keine vorgefertigten Lösungen gab.
Jetzt werde ich allgemein über unsere Implementierung und wie es hilft, dieses Problem zu vermeiden, skizzieren. Mehr über sie und ihre Unterschiede zu anderen Lösungen
erfahren Sie in einem Bericht von Mikhail Kurmaev über Highload Siberia Ende Juni. Das Protokoll seines Berichts wird auch in diesem Blog veröffentlicht.
Es sieht ungefähr so aus:
Es gibt einen abstrakten Sphinx-Dienst, dem ein Leistungsschalter gegenübersteht. Der Leistungsschalter speichert die Anzahl der aktiven Verbindungen zu einem bestimmten Dämon. Sobald dieser Wert den Schwellenwert erreicht, den wir als Prozentsatz der verfügbaren FPM-Mitarbeiter auf der Maschine festgelegt haben, glauben wir, dass der Service langsamer wurde. Bei Erreichen des ersten Schwellenwerts senden wir eine Benachrichtigung an die für den Service verantwortliche Person. Eine solche Situation ist entweder ein Zeichen dafür, dass Grenzen überprüft werden müssen, oder ein Vorbote von Problemen mit der Langeweile.
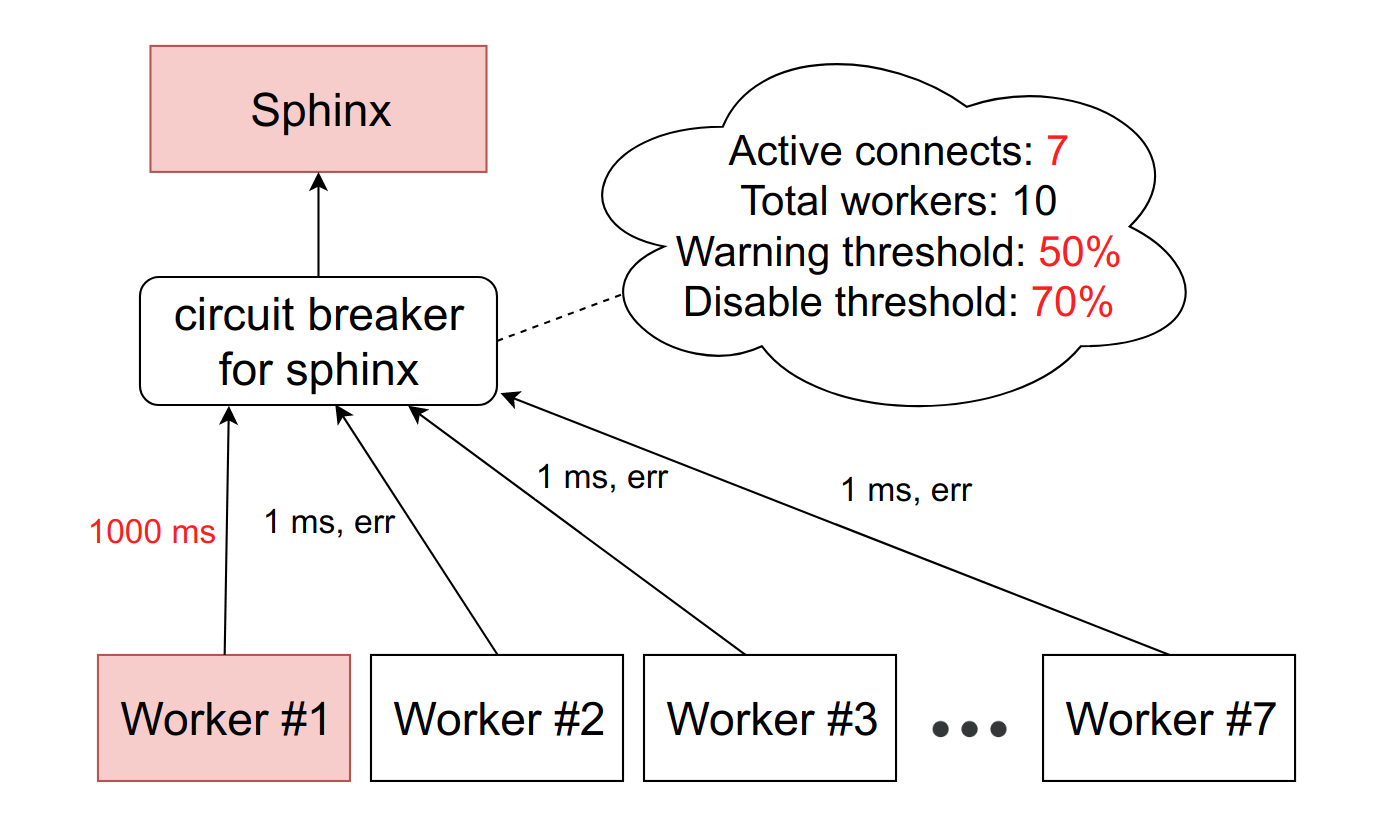
Wenn sich die Situation verschlechtert und die Anzahl der hemmenden Arbeitnehmer den zweiten Schwellenwert erreicht - in unserer Produktion sind es etwa 10% -, reduzieren wir diesen Wirt vollständig. Genauer gesagt funktioniert der Dienst tatsächlich weiter, aber wir senden keine Anfragen mehr an ihn. Der Circuit-Browser lehnt sie ab und gibt den Arbeitern sofort einen Fehler, als ob der Dienst gelogen hätte.
Von Zeit zu Zeit überspringen wir automatisch eine Anfrage eines Mitarbeiters, um festzustellen, ob der Service zum Leben erweckt wurde. Wenn er angemessen antwortet, nehmen wir ihn wieder in die Arbeit auf.
All dies geschieht, um die Situation auf das vorherige Replikationsschema zu reduzieren. Anstatt eine Sekunde zu warten, bevor wir feststellen, dass der Host nicht verfügbar ist, erhalten wir sofort eine Fehlermeldung und gehen zum Backup-Host.
Implementierungen
Glücklicherweise steht Open Source nicht still und heute können Sie eine schlüsselfertige Lösung für Github verwenden.
Es gibt zwei Hauptansätze für die Implementierung eines Leistungsschalters: eine Bibliothek auf Codeebene und einen eigenständigen Daemon, der Anforderungen über sich selbst weiterleitet.
Die Option mit der Bibliothek ist besser geeignet, wenn Sie einen Hauptmonolithen in PHP haben, der mit mehreren Diensten interagiert, und die Dienste fast nicht miteinander kommunizieren. Hier sind einige Implementierungen verfügbar:
Wenn Sie viele Dienste in verschiedenen Sprachen haben und alle miteinander interagieren, muss die Option auf Codeebene in allen diesen Sprachen dupliziert werden. Dies ist bei der Unterstützung unpraktisch und führt letztendlich zu Unterschieden bei den Implementierungen.
Das Einfügen eines Daemons ist in diesem Fall viel einfacher. In diesem Fall müssen Sie den Code nicht speziell bearbeiten. Der Dämon versucht, die Interaktion transparent zu machen. Diese Option ist
jedoch architektonisch viel komplizierter .
Hier sind einige Optionen (die Funktionalität ist dort umfangreicher, aber es gibt auch einen Leistungsschalter):
Schlussfolgerungen
- Verlassen Sie sich nicht auf das Netzwerk.
- Alle Netzwerkanforderungen müssen eine Zeitüberschreitung aufweisen, da das Netzwerk unendlich lange dauern kann.
- Verwenden Sie einen Leistungsschalter, wenn Sie kaskadierende Anwendungsabstürze vermeiden möchten, da ein kleiner Dienst langsamer wird.
Überwachung und Telemetrie
Was gibt es
- Vorhersehbarkeit. Es ist wichtig, vorherzusagen, wie hoch die Last ist und was in einem Monat sein wird, um die Anzahl der Dienstinstanzen rechtzeitig zu erhöhen. Dies gilt insbesondere dann, wenn Sie mit einer Eiseninfrastruktur zu tun haben, da die Bestellung neuer Server einige Zeit in Anspruch nimmt.
- Untersuchung von Vorfällen. Früher oder später wird sowieso etwas schief gehen, und Sie müssen es untersuchen. Und es ist wichtig, über genügend Daten zu verfügen, um das Problem zu verstehen und solche Situationen in Zukunft verhindern zu können.
- Unfallverhütung. Idealerweise sollten Sie verstehen, welche Muster zu Abstürzen führen. Es ist wichtig, diese Muster im Auge zu behalten und das Team rechtzeitig darüber zu informieren.
Was zu messen
IntegrationsmetrikenDa es sich um die Interaktion zwischen Diensten handelt, überwachen wir alles, was in Bezug auf die Kommunikation des Dienstes mit der Anwendung möglich ist. Zum Beispiel:
- Anzahl der Anfragen;
- Bearbeitungszeit für Anforderungen (einschließlich Perzentile);
- Anzahl der logischen Fehler;
- Anzahl der Systemfehler.
Es ist wichtig, Logikfehler von Systemfehlern zu unterscheiden. Wenn der Dienst ausfällt, ist dies eine normale Situation: Wir wechseln einfach zur zweiten. Aber es ist nicht so beängstigend. Wenn Sie einen logischen Fehler starten, z. B. seltsame Daten in den Dienst gelangen oder diesen verlassen, muss dies bereits untersucht werden. Höchstwahrscheinlich hängt der Fehler mit einem Fehler im Code zusammen. Sie selbst wird nicht bestehen.
Interne MetrikenStandardmäßig ist der Dienst eine Black Box, die ihre Arbeit unverständlich erledigt. Es ist immer noch wünschenswert, die maximalen Daten zu verstehen und zu sammeln, die der Dienst bereitstellen kann. Wenn es sich bei dem Dienst um eine spezialisierte Datenbank handelt, in der einige Daten Ihrer Geschäftslogik gespeichert sind, behalten Sie genau den Überblick über die Datenmenge, den Typ und andere Inhaltsmetriken. Wenn Sie eine asynchrone Interaktion haben, ist es auch wichtig, die Warteschlangen zu überwachen, über die Ihr Dienst kommuniziert: Ankunfts- und Abfluggeschwindigkeit, Zeit in verschiedenen Phasen (wenn Sie mehrere Zwischenpunkte haben), die Anzahl der Ereignisse in der Warteschlange.
Lassen Sie uns sehen, welche Metriken am Beispiel von memcached erfasst werden können:
- Treffer / Miss-Verhältnis;
- Reaktionszeit für verschiedene Operationen;
- RPS verschiedener Operationen;
- Aufschlüsselung der gleichen Daten auf verschiedenen Schlüsseln;
- oben geladene Schlüssel;
- Alle internen Metriken, die vom Befehl stats angegeben werden.
Wie es geht
Wenn Sie ein kleines Unternehmen, ein kleines Projekt und wenige Server haben, ist es eine gute Lösung, eine Art SaaS zum Sammeln und Anzeigen anzuschließen - es ist einfacher und billiger. In diesem Fall verfügt SaaS normalerweise über umfangreiche Funktionen und muss sich nicht um viele Dinge kümmern. Beispiele für solche Dienste:
Alternativ können Sie Zabbix, Grafana oder eine andere selbst gehostete Lösung jederzeit auf Ihrem eigenen Computer installieren.
Schlussfolgerungen
- Sammeln Sie alle Metriken, die Sie können. Daten sind nicht überflüssig. Wenn Sie etwas untersuchen müssen, werden Sie sich für Ihre Voraussicht bedanken.
- Vergessen Sie nicht die asynchrone Interaktion. Wenn Sie Linien haben, die allmählich erreichen, ist es wichtig zu verstehen, wie schnell sie erreichen und was mit Ihren Ereignissen an der Kreuzung zwischen den Diensten passiert.
- Wenn Sie Ihren Dienst schreiben, bringen Sie ihm bei, Statistiken über die Arbeit zu erstellen. Ein Teil der Daten kann auf der Integrationsschicht gemessen werden, wenn wir mit diesem Service kommunizieren. Der Rest des Dienstes sollte in der Lage sein, Statistiken gemäß dem bedingten Befehl zu geben. Beispielsweise ist diese Funktionalität in allen unseren Diensten für unterwegs Standard.
- Passen Sie die Trigger an. Diagramme sind gut, aber nur, wenn Sie sie betrachten. Es ist wichtig, dass Sie ein angepasstes System haben, das Sie informiert, wenn etwas schief geht.
Memento mori
Und jetzt ein bisschen über traurige Dinge. Möglicherweise haben Sie das Gefühl, dass das oben Genannte ein Allheilmittel ist, und jetzt wird nichts mehr fallen. Aber selbst wenn Sie alles anwenden, was oben beschrieben wurde, wird jemals etwas fallen. Es ist wichtig, dies zu berücksichtigen.
Die Gründe für den Sturz sind vielfältig. Beispielsweise könnten Sie ein unzureichend paranoides Replikationsschema auswählen. Ein Meteorit ist in Ihr Rechenzentrum gefallen und dann in das zweite. Oder Sie haben den Code nur mit einem kniffligen Fehler bereitgestellt, der unerwartet aufgetreten ist.
In Badoo gibt es beispielsweise die Seite "Personen in der Nähe". Dort suchen Benutzer nach anderen Personen in der Nähe, um mit ihnen zu chatten.

Um die Seite zu rendern, ruft das Backend etwa sieben Dienste synchron auf. Reduzieren Sie diese Zahl aus Gründen der Übersichtlichkeit auf zwei. Ein Dienst ist für das Rendern des zentralen Blocks mit Fotos verantwortlich. Der zweite ist für den Werbeblock unten links. Wer sichtbarer werden will, kann dorthin gelangen. Wenn wir einen Dienst haben, der diese Werbung anzeigt, verschwindet der Block einfach.

Die meisten Benutzer wissen nicht einmal davon: Unser Team reagiert schnell und bald wird der Block einfach wieder angezeigt.
Aber nicht jede Funktionalität können wir leise entfernen. Wenn wir den Dienst verlieren, der für den zentralen Teil der Seite verantwortlich ist, funktioniert dies nicht, um ihn auszublenden. Daher ist es wichtig, dem Benutzer in seiner Sprache mitzuteilen, was gerade passiert.

Es ist auch wünschenswert, dass der Ausfall eines Dienstes nicht zu einem Kaskadenfehler führt. Für jeden Dienst muss Code geschrieben werden, der den Fall behandelt, da sonst die Anwendung insgesamt abstürzen kann.
Das ist aber noch nicht alles. Manchmal fällt etwas, ohne das man in keiner Weise leben kann. Zum Beispiel eine zentrale Datenbank oder ein Sitzungsdienst. Es ist wichtig, es richtig auszuarbeiten und dem Benutzer etwas Angemessenes zu zeigen, ihn irgendwie zu unterhalten, um zu sagen, dass alles unter Kontrolle ist. Gleichzeitig ist es wichtig, dass wirklich alles unter Kontrolle ist und die Monitore über das Problem informiert werden.
So richtig zu sterben
- Mach dich bereit für den Herbst. Es gibt keine Silberkugel, also legen Sie immer Strohhalme, falls der Service vollständig ausfällt, auch wenn Sie Redundanz verwenden.
- Vermeiden Sie kaskadierende Fehler, wenn Probleme mit einem der Dienste die gesamte Anwendung zum Erliegen bringen.
- Deaktivieren Sie nicht kritische Benutzerfunktionen. Es ist in Ordnung. Viele Dienste werden nur für interne Anforderungen verwendet und haben keinen Einfluss auf die bereitgestellten Funktionen. Zum Beispiel ein Statistikdienst. Für den Benutzer spielt es keine Rolle, ob Statistiken von Ihnen gesammelt werden oder nicht. Für ihn ist es wichtig, dass die Seite funktioniert.
Zusammenfassung
Um den neuen Service zuverlässig in das System zu integrieren, schreiben wir in Badoo eine spezielle Wrapper-API darum, die folgende Aufgaben übernimmt:
- Lastausgleich;
- Zeitüberschreitungen;
- logisches Failover;
- Leistungsschalter;
- Überwachung und Telemetrie;
- Autorisierungslogik;
- Serialisierung und Deserialisierung von Daten.
Stellen Sie besser sicher, dass alle diese Elemente auch in Ihrer Integrationsschicht enthalten sind. Insbesondere, wenn Sie einen vorgefertigten Open-Source-API-Client verwenden. Es ist wichtig zu beachten, dass die Integrationsschicht ein erhöhtes Risiko für einen Kaskadenfehler Ihrer Anwendung darstellt.
Vielen Dank für Ihre Aufmerksamkeit!
Literatur