Der NoSQL-Trend ist fast 10 Jahre alt, und Sie können sicher Schlussfolgerungen und Verallgemeinerungen ziehen. Wir werden dies tun und über die Entwicklung von NoSQL sprechen.
Erinnern Sie sich daran, wie NoSQL geboren wurde. Mal sehen, was gut und was schlecht daran ist und was den Test der Zeit bestanden hat. Lassen Sie uns die Funktionen analysieren, die bereits in SQL vorhanden sind und jetzt in NoSQL DBMS angezeigt werden. Wir heben die einzigartigen Werte von NoSQL hervor und schauen ein wenig voraus, was morgen auf dem Markt passieren wird.
Und Konstantin Osipov (
@kostja ), der Entwickler und Architekt des Tarantool DBMS, der in seinem Bericht auf der RIT ++ 2017 über NewSQL-Trends sprach, wird uns dabei helfen, denn der Architekt soll zumindest verstehen, was in der Datenbankwelt passiert das Rad neu erfinden.
Über den Sprecher : Jetzt arbeitet Konstantin Osipov an Tarantool, war aber zuvor an der Entwicklung von MySQL beteiligt. Als Konstantin anfing, an einer neuen Datenbank zu arbeiten, war er sehr verwirrt, warum dies überhaupt getan werden sollte und warum die nächste Datenbank benötigt wurde. Insbesondere die Einstellung zu NoSQL war in Bezug auf „Under-SQL“ sehr skeptisch.
Die Entwicklung geht jedoch weiter, einige der ursprünglichen Prinzipien sterben aus, und gleichzeitig übernehmen NoSQL-Datenbanken die Funktionen von klassischem SQL. Basierend auf den Ergebnissen dieser mehrjährigen schnellen Transformation ist es durchaus möglich, Zwischenergebnisse zu ziehen und sich mehrere Vorhersagen für die Zukunft zu machen.
Planen
- Hintergrund . Erinnern Sie sich daran, wie NoSQL geboren wurde, was gut und was schlecht daran ist.
- Mal sehen, was mit NoSQL den Test der Zeit bestanden hat .
- NoSQL SQL : N1QL und CQL. Lassen Sie uns die Funktionen analysieren, die bereits in SQL vorhanden sind und jetzt in NoSQL DBMS angezeigt werden.
- NoSQL ist bereits tot und NewSQL ist noch nicht geboren: Wie warm sich Tube SQL von SQL in NoSQL unterscheidet.
- Eindeutige Werte von NoSQL . Wir werden sehen, was in 10 Jahren Anstrengung gut passiert ist und was als nächstes passieren wird.
- Multi-Model-Datenbanken und NewSQL . Schauen wir uns ein wenig an, was morgen auf dem Markt sein wird.
NoSQL-Grundsätze
Viele Leute versuchen jetzt, sich an den NoSQL-Begriff zu halten, aber er wurde 2009 weitgehend übernommen, als das Hashtag
#nosql erschien. Der Entwickler von Last.FM hat dieses Tag für die verteilten Datenbanken mitap erfunden.
Danach wurde das Tag auf Twitter immer beliebter und NoSQL wurde zu einem Abflussbehälter oder Trichter für Frustration, wie ich es nenne - Frustration, die sich über viele Jahre der Arbeit mit traditionellen Datenbanken angesammelt hat.
NoSQL ist ein Ausweg für Frustration, ein Tag, das sich jeder, der nicht über genügend SQL-Funktionen verfügt, angeeignet hat.
Diese Frustration muss irgendwie strukturiert und bestimmt sein, was die meisten Menschen in traditionellen DBMS nicht mochten. Wir können 3 große Aufgabenblöcke unterscheiden, für deren Lösung NoSQL erstellt wurde:
- horizontale Skalierung;
- neue Datenmodelle;
- neue Modelle der Konsistenz.
Mal sehen, was diese Blöcke sind. Nehmen Sie zum Beispiel Schlüsselwertdatenbanken. Die Hauptidee des Schlüsselwertdatenmodells besteht darin, dass die Datenbank einfach, aber skalierbar ist. Eine große Anzahl von Problemen liegt auf den Schultern des Entwicklers, aber er hat eine strikte Garantie dafür, dass seine Datenbank
unendlich skalierbar ist . Aber unendliche Skalierbarkeit ist keine Magie. Garantien für Skalierbarkeit werden aufgrund der
extrem einfachen Semantik der unterstützten Operationen erreicht: In einer Schlüsselwertdatenbank wirkt sich jede Operation ausschließlich auf einen Clusterknoten aus.
Anfänglich war es für die Community sehr schwierig, Datenmodelle von Skalenmodellen zu trennen. Wenn Sie sich dieselbe Cassandra ansehen, wurde ihr Datenmodell in den frühen Versionen als Wide Column Store bezeichnet - eine breite Spaltendatenbank. Wenn der Schlüsselwert des DBMS einen Index nach Schlüssel enthält, werden im breiten Spaltenspeicher immer zwei Indizes automatisch erstellt: nach Schlüssel und nach Spaltenfamilie.
Darüber hinaus ist der Index nach Schlüssel zerlegbar, und der Index nach Spaltenfamilie ist lokal für einen bestimmten Datenknoten. Aus diesem Grund haben wir eine horizontale Skalierung erreicht, aber gleichzeitig die Möglichkeit erhalten, lokale Abfragen für die Spaltenfamilie durchzuführen. Oldtimer erinnern sich, dass eine ähnliche Funktion in Oracle unter Beibehaltung des relationalen Modells implementiert und als verknüpfte Tabelle bezeichnet wurde. Diese Funktion ermöglichte es, den physischen Speicherort der beiden Tabellen im verbundenen Formular anzugeben. Breiter Spaltenspeicher in Cassandra - Implementiert eine verknüpfte Tabelle mit automatischer Verteilung über den Cluster.
Die Zusammenführung des Datenmodells und des Skalenmodells ist genau das Problem, das mit dem relationalen Modell gelöst wurde. Willkommen in den 70ern.
Zusätzlich zu neuen Datenmodellen hat NoSQL neue Konsistenzmodelle implementiert. Ja, ja, wieder dieses berühmte
CAP-Theorem . Über das CAP-Theorem zu sprechen, amüsiert mich die ganze Zeit - wer braucht es überhaupt? Da es keinen Stör der zweiten Frische gibt, gibt es keine andere Antwort auf die Frage nach der Konsistenz von Daten als eine:
Die Datenbank muss diese Konsistenz garantieren . Daher sind neue Konsistenzmodelle meiner Meinung nach auch ein aussterbender Trend.
NoSQL heute
Die These, die ich zuallererst ausdrücken möchte, ist die der gesamten überlebenden NoSQL-Bewegung:
- horizontale Skalierung;
neue Datenmodelle dokumentieren und grafische Datenmodelle;neue Modelle der Konsistenz.
Von den Thesen über neue Datenmodelle haben fast eineinhalb überlebt, und die These über Konsistenzmodelle ist vollständig gestorben.
Todesmütze
Warum haben einige Konsistenzmodelle nicht überlebt?
●
Eventuelle Konsistenz: LaufzeitinflationWer verwendet eine Datenbank mit einer funktionierenden Vektoruhr und die Geschäftslogik der Anwendung ist darauf ausgerichtet? - Niemand. Wer verwendet Datenbanken mit CRDT (konfliktfreie replizierte Datentypen)? Wer benutzt Riak? - Niemand. Was benutzen die Leute? Häufiger PostgreSQL, seltener andere Basen, zum Beispiel MongoDB.
●
MongoDB: Atomic wird durch isoliert ersetzt, Transaktionen werden in 3.xx hinzugefügtDiese Datenbank verfügt über eine asynchrone Replikation. Dies ist sehr einfach zu verstehen, obwohl es tatsächlich
vier Arten der asynchronen Replikation gibt . Die Replikation von Transaktionsdaten kann erfolgen, nachdem eine Transaktion lokal festgeschrieben wurde. bevor die Transaktion lokal festgeschrieben wird.
Das heißt, der Festschreibungspunkt für die Hauptdatenbank kann auch auf verschiedene Weise mit dem Festschreibungspunkt für das Replikat korreliert werden.
Ein Eintrag in das lokale Protokoll wurde bereits vorgenommen, es wurde jedoch noch nicht zum Replikat geflogen. Angenommen, Sie möchten warten, bis sie zumindest zu einer Replik wegfliegt. Weggeflogen - heißt nicht geflogen. Angekommen - dies bedeutet nicht, dass es in das lokale Journal auf dem Replikat geschrieben wurde.
Anfangs hatte MongoDB einen Modus: Die Anfrage kam auf dem Server an, die Datenbank antwortete mit OK - sie ist noch nicht einmal auf der Festplatte oder im Logbuch angekommen - sie ging nirgendwo hin. Aus diesem Grund funktioniert alles sehr schnell, aber dann haben sie begonnen, MongoDB dafür zu kritisieren, und standardmäßig wurde in späteren Versionen 3+ die Transaktion zunächst in das Journal geschrieben und erst danach eine Bestätigung an den Client gesendet.
Das heißt, selbst die asynchrone Replikation ist ein Abgrund semantischer Modelle. Daher sind
Konsistenzmodelle für einen großen Kreis von Entwicklern zu kompliziert, um sie zu verstehen, und Transaktionen und synchrone Replikation ersetzen das Sortiment exotischer Modelle .
Vor dem Hintergrund des Todes des Konsistenzmodells gibt es immer noch einen interessanten Trend bei der Entwicklung einer tatsächlich strengeren Konsistenz. Es gibt Transaktionen in Redis, obwohl ich sie nicht als Transaktionen bezeichnen würde, aber auf Kosten einer echten Transaktion gibt es Kontroversen ohne diese.
Schauen wir uns die Geschichte der Transaktionen in NoSQL an. Zunächst implementierte MongoDB die Atomizität auf Dokumentebene. Dann wurde ein isolierter Ausführungsmodus hinzugefügt, damit Entwickler, wenn sie es wirklich wollen, mehrere Dokumente atomar aktualisieren können.
●
Transaktionen erneut bearbeitenZu Beginn von NoSQL wurde dem Entwickler angeboten, den gesamten Business Case in einem Korbdokument zusammenzufassen. Es erscheint ein ganzer Fluss, der als domänengesteuertes Design bezeichnet wird, wodurch diese Perversion auf den Rang eines Entwurfsmusters angehoben wird. Wenn alles in einem Dokument gespeichert ist, wird die Atomizität einfach erreicht: Sie haben eine Transaktion, einen Geschäftsprozess und eine atomare Änderung in einem Dokument vorgenommen.
Aber es stellt sich heraus, dass dies nicht funktioniert. Daten müssen normalisiert werden, um Speicherredundanz zu vermeiden. Sie müssen für analytische Abfragen normalisiert werden. Am Ende entwickelt sich das Datenmodell weiter - und das Dokument, in dem gestern alle für ein Geschäftsszenario heute erforderlichen Informationen gespeichert werden konnten, muss erweitert und ergänzt werden.
Zeigen Atomaritätsprobleme? Wie eng Datenmodelle mit Konsistenzmodellen zusammenhängen - das Aufkommen von Transaktionen und die synchrone Replikation machen die meisten Modelle in NoSQL unnötig.
Datenmodelle
Lassen Sie uns nun über die nächste Geschichte sprechen - die Geschichte mit Datenmodellen.
Nach SQL erfundene Gruppen von Datenmodellen:
- Schlüsselwert
- Dokumentarfilm
- Wide Column Store;
- Datenstruktur-Server (für Redis);
- Diagrammdatenbanken.
Cool! Wir haben so viele Datenmodelle! Und wie gut skalieren sie?
Dies ist eine These, die sich hauptsächlich auf die sogenannte Hyperkonvergenz bezieht, wenn alle modernen Projekte billige Einzelserver-Server verwenden und Unternehmen aufhören, vertikal skalierbare Maschinen zu kaufen.
Hyperkonvergenz ist so gründlich in unser Leben getreten, dass es heute sogar in vertikal skalierten Maschinen, falls vorhanden, bereits horizontal skalierbare Software gibt - sehen Sie sich an, wie PureStorage funktioniert, oder, wenn Sie sich erinnern, bei Nacht Nutanix. Natürlich verkaufen sie Schränke an Menschen, aber diese Schränke sind wie normale Regale bei einem Hosting-Anbieter angeordnet.
Das heißt, die horizontale Skalierung ist ein Trend, der Druck auf alle ausübt, einschließlich der Erfinder neuer Datenmodelle. Welche Datenmodelle eignen sich für die horizontale Skalierung und welche sind schlecht?
Ist es gut oder schlecht für die horizontale Skalierung? Die Antwort ist in der Tat ziemlich kontrovers, wir werden später darauf zurückkommen.
Redis
Als Redis den Redis-Cluster hinzufügte, stellte sich heraus, dass nicht alle Datenmodelloperationen normal horizontal skaliert werden.

Dies ist ein Zitat aus der Dokumentation, in der sie schreiben, dass auf einem bestimmten Shard etwas für sie funktioniert und etwas wirklich wie in einem echten Cluster.
Das grundlegende Problem dieses Ansatzes ist das gleiche wie bei MySQL, das wir aufgegriffen und uns die Hand geschüttelt haben. Das heißt, der Entwickler hat zwei Datenmodelle:
- Zum einen denkt er im Rahmen der relationalen Algebra.
- Wenn er dann über unabhängiges Sharding nachdenkt, denkt er im Datenmodell der Shard-relationalen Algebra.
Ein gutes Datenmodell sollte universell sein . Was ist schön an der relationalen Algebra - das Ergebnis einer Projektion ist eine Beziehung, das Ergebnis eines Operators ist eine Beziehung. Und sobald wir manuell damit beginnen, MySQL auf den Cluster zu übertragen, verlieren wir das.
Redis fügt jedoch einen Redis-Cluster hinzu, da
jeder horizontal skalieren möchte .
Diagrammdatenbanken
Graphendatenbanken sind ein gutes Beispiel,
um die Konzepte der horizontalen Skalierung von Computer und Speicher zu
trennen . Informationen können immer durch eine beliebige Anzahl von Knoten geteilt werden. Wenn die Datenbank jedoch von Natur aus darauf ausgelegt ist, die von ihr gespeicherten Daten zu verarbeiten, und diese Berechnungen nicht horizontal skaliert werden, tritt das Problem einer effektiven horizontalen Speicherung auf, mit der die Berechnungen funktionieren können.
Betrachten wir das Problem der Skalierung von Diagramm-DBMS - SQL-DBMS sind mit sehr ähnlichen Skalierungsbarrieren konfrontiert.
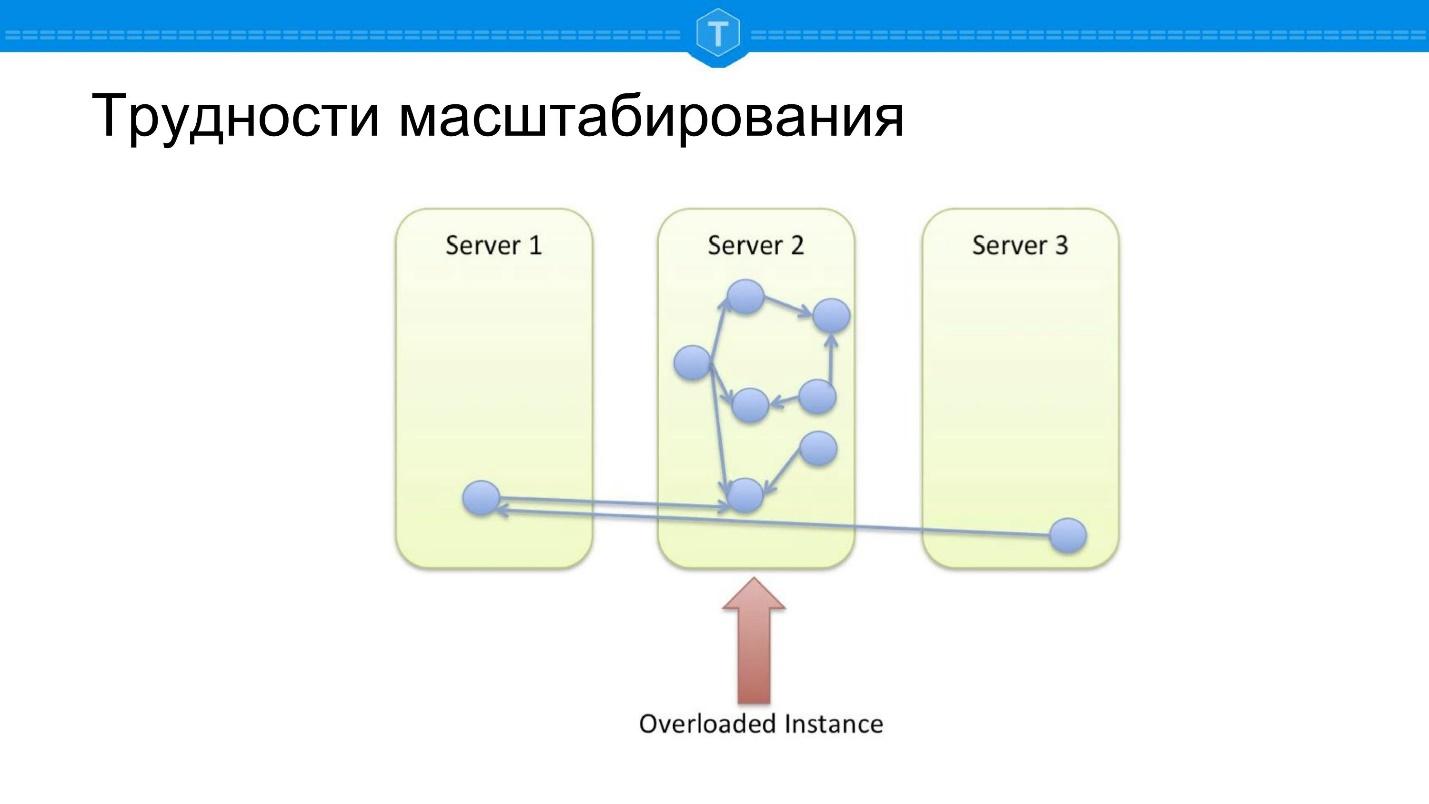
Nehmen Sie die lokale Datenbank, in der das Diagramm gespeichert ist. Früher oder später wird ein Knoten gefüllt, und wir beginnen, andere Knoten zu verwenden. Sobald wir mehr als einen Knoten verwenden, wird der zentrale Knoten überlastet, da die Lokalität der Anforderungen verloren geht. Einige Abfragen im Diagramm müssen mehrere physische Knoten durchlaufen, dh es treten Netzwerkverzögerungen auf.
Angenommen, wir haben etwas anderes gemacht - sie haben alles mit einer guten Splitterfunktion genommen und zerstört. Wir berechnen einen bestimmten Hash, indem wir alle Daten in unserem Cluster zufällig verteilen - und wir bekommen ein weiteres Problem.

Wenn im vorherigen Schema zumindest einige Abfragen einwandfrei funktioniert haben, sind
100% der Abfragen hier dumm , da die meisten Datenbankabfragen mit der Diagrammdurchquerung verbunden sind. Jeder Umweg vom Knoten muss irgendwohin führen, und meistens müssen Sie zur Berechnung der Anforderung zu einem anderen Knoten gehen.

Die Idee entsteht, ungefähr zu shardieren, wie in der obigen Abbildung gezeigt: Finden Sie Cluster und platzieren Sie sie auf Ihren Knoten: Eng verbundene Teilmengen werden zusammen platziert, schwach verbundene Teilmengen werden beabstandet.
Dies ist eine ideale Option, aber die
ideale Option existiert nur in der Theorie . Live-Daten eignen sich nicht für die statische Partitionierung. Um diesen Ansatz zu implementieren, müssen wir Cluster auf einer sich dynamisch ändernden Menge automatisch erkennen und Knoten abhängig von entstehenden und verschwindenden Bindungen ständig verschieben.
Daher sind Neo4j im Großen und Ganzen jetzt wie klassische SQL-Datenbanken skaliert. Sie arbeiten schon seit einiger Zeit am Sharding und versuchen, die beschriebenen Probleme zu lösen.
Die These, die ich vorgebracht habe, ist, dass die
horizontale Skalierung Druck auf alle ausübt und alle Datenmodelle früher oder später gezwungen sein werden, sie zu implementieren. Einige Modelle bleiben jedoch bei uns, andere nicht.
Wenn wir zum Beispiel die Schlüsselwert- und Dokumentdatenbanken in reiner Form betrachten, ist meine Aussage, dass dies nicht der Fall sein wird. Wenn Sie sich Diagrammdatenbanken ansehen, nehmen diese bereits ein bedeutendes Segment ein, stehen jedoch unter dem Druck der horizontalen Skalierung.
Werden Graphendatenbanken verschwinden? Es ist wahrscheinlicher, dass
Spalten wie Dokumente in allen Produkten enthalten sind . Dieser Trend wird als Multi-Modell-Datenbank bezeichnet. Später im Bericht werde ich ein Beispiel geben, wie dies in der Praxis funktionieren kann. Schauen wir uns zunächst JSON an, um den Trend der Datenbanken mit mehreren Modellen zu veranschaulichen.
Json
Im Folgenden finden Sie ein Beispiel dafür, wie ein Trend, der sich zu einem umfassenden Trend entwickelt, funktioniert.
Ich behaupte, dass jede Datenbank, die JSON in irgendeiner Weise unterstützen kann, JSON unterstützt.
Möglicherweise unterstützen einige Datenbanken für Matrix-Computing JSON nicht. Aber höchstwahrscheinlich wird es dort nützlich sein. Und der Rest wird definitiv sein.
| MySQL
| PostgreSQL
| Redis
| Couchbase
| Cassandra
| Neo4j
|
JSON-Speicher
| Ja
| Ja
| Ja
| Ja
| Ja
| Ja!
|
JSON-Feldoperationen
| Ja
| Ja
| Ja
| Ja
| Nein
| Nein
|
Json-Abfrage
| Ja
| Ja
| Nein
| Ja
| Ja
| Nein
|
JSON-Sekundärindex
| Ja
| Ja
| Nein
| Ja
| Nein
| Nein
|
In dieser Tabelle können Sie visuell sehen, was mit Datenmodellen geschieht. Relationale Datenbanken in ihrer Unterstützung für JSON liegen sogar vor nicht relationalen Datenbanken derselben Cassandra. Es gibt keine Sekundärschlüssel für JSON-Felder. Und sogar Grafikdatenbanken beginnen, JSON einzuschließen, da
jeder JSON benötigt .
Datenbanken mit mehreren Modellen und insbesondere JSON als Datentyp, der in fast allen Produkten zu finden ist, werden daher ernsthaft und für lange Zeit von NoSQL übrig bleiben.
Aber wenn alle Datenbanken JSON unterstützen, warum benötigen Sie überhaupt NoSQL-Datenbanken?Es gibt nur noch eine Geschichte - die horizontale Skalierung. Wir möchten horizontal skalieren und verwenden daher etwas anderes als MySQL oder PostgreSQL.

Dies ist die Keynote von Thomas Ulin, VP MySQL Engineering bei Oracle, der über die Zukunft von MySQL spricht. Das gleiche passiert in der Postgres-Community und anderen relationalen Produkten. Der Druck der horizontalen Skalierung wirkt sich aufgrund des Übergangs zu Hyperkonvergenz und Cloud Computing auf 100% der Produkte aus.
Laut Thomas ist ihre Vision ein Produkt mit sofortiger Hochverfügbarkeit und Skalierbarkeit. Wir sprechen über Hochverfügbarkeit in erster Linie InnoDB Cluster, dies ist Gruppenreplikation + InnoDB. Eine solche Datenbank stirbt nie, selbst wenn sie mit einem Hammer getroffen wird.
Dann schreibt Thomas "
Skalierungsfunktionen eingebrannt " - "Wir haben alle diese Funktionen gebacken". Der Punkt ist, dass sie durch x-Releases (ich denke, dass x = 2, 3) MySQL Cluster in seiner reinen Form erhalten, die SQL auf dem Cluster, JSON-Speicher im Cluster, unterstützt.
Bereits heute
verfügt MySQL über ein X-Protokoll, das MongoDB sehr ähnlich ist und für die Arbeit mit JSON ausgelegt ist.
SQL in NoSQL
Schauen wir uns nun die Bewegung von der anderen Seite an. Um den Tod festzustellen, müssen Sie nicht nur untersuchen, wie SQL die Prinzipien von NoSQL übernimmt, sondern auch umgekehrt.
| Mongodb
| Couchbase
| Cassandra
| Redis
|
Datenschema
| Ja *
| Nein
| Ja
| Nein
|
NULL / Abwesende Werte
| Ja *
| Ja
| Ja
| Nein
|
Tritt bei
| Ja
| Ja
| Nein
| Nein
|
Sekundärschlüssel
| Ja *
| Ja
| Ja, aber ...
| Nein
|
GRUPPE VON
| Ja *
| Ja
| Nein
| Nein
|
JDBC / ODBC
| Nein
| Ja
| Nein
| Nein
|
Hier gibt es tatsächlich auch interessante Einblicke. Ich habe meiner Meinung nach die Führer genommen. Ich bin damit einverstanden, dass nicht alles hier ist, zum Beispiel ist Elastic auch ein NoSQL-Führer. Da Elastic jedoch immer noch in erster Linie eine Lösung für die Volltextsuche ist, habe ich es nicht in die Tabelle aufgenommen.
Times Series-Datenbanken als Trend, den ich nicht berühre. Es gibt eine These unter den Zeitreihen von Bewegungen, dass dies eine separate Nische ist, ähnlich wie bei Graphendatenbanken, aber wenn Sie tiefer graben, sitzt Postgres unter der Haube.
Couchbase
Meiner Meinung nach bietet Couchbase die unterschiedlichsten Möglichkeiten aus der SQL-Welt. Jeder weiß, dass
Couchbase Memcached ist . Dormando (
Alan Kasindorf ), einer der Entwickler von Memcached, hatte eine völlig andere Produktvision, die keine horizontale Skalierung beinhaltete. Daher gabelte sich Memcache, um horizontal zu skalieren. Es lief gut und begann Geschäfte zu machen, dann fusionierte es mit CouchDB und so weiter und so fort.
Couchbase sagt sich zunächst, dass es sich um eine
schemenlose Datenbank handelt . Memcache ist ursprünglich ein sehr einfacher Schlüsselwert. Nun wollen wir sehen, wie sich diese Selbstidentifikation im Laufe der Zeit ändert.
Zum Beispiel hat Couchbase Sekundärschlüssel, und
Sekundärschlüssel sind eigentlich der Anfang des Schemas . Wenn Sie sagen, dass Sie einige Felder haben, anhand derer Sie den Index erstellen, sprechen Sie bereits über das Schema der von Ihnen gespeicherten Datendokumente.
Da Couchbase heute nach und nach die gesamte Geschichte über die Vergangenheit von Memcache aus der Dokumentation herausschneidet, wird morgen auch die Geschichte über die eventuelle Konsistenz herausgeschnitten, obwohl es heute noch viele Geschichten über die mangelnde Lesekonsistenz gibt - Sekundärschlüssel sind schließlich konsistent.
Aber der Haken ist, dass Couchbase JDBC / ODBC hat. , Tableau ClickView — , CQL SQL.
— SQL., .

, - , , , - — , SQL.
, IS MISSING — , IS NULL?
JDBC, ODBC SQL ? 30-40 , SQL- SQL , , : look-in, , ..
, .
, , ., Couchbase JDBC/ODBC — . , — .
Secondary keys
, NoSQL — , — , . OrientDB, , , .
SQL- , ( , ), NoSQL, .
NoSQL- secondary keys. secondary keys?
( — ):
- , , . , range-, SQL . range- map/reduce .
- . index notes, . range- .., .
, , , , , . , .
. , NoSQL- SQL, , , .
: CockroachDB? :
, . , MySQL — legacy. , , ..
, NoSQL- legacy 10 . , , . SQL- , PostgreSQL, , MySQL Couchbase , True NewSQL.
, secondary keys. MongoDB SQL, . , JOINs, , .
Redis No, . Redis , — . , , , .
, Redis — , - . , Redis-, SQL. , Redis SQLite, — storage — Redis', in memory.
NoSQL , , ?
, NoSQL . , , , SQL . SQL .
schemaless , , , waterfall : agile, - . , , CREATE TABLE, .
, online alter table. Oracle , .
SQL , .
MongoDB — , .
MongoDB , schemaless. . , , strict. validation level validation action. Validation level , .
, , - . , , . validation action reject, warn: warning, validation action.
. , MongoDB ( Tarantool), .
Cassandra JSON, . — , . , , NoSQL, .
-, NoSQL SQL .

eventually consistent , , ,
. , — . .
?
, , . BigQuery , , Vertica, .
NoSQL . , SELECT LTP, LTP - Key-value.
, NoSQL- .
SELECT JOIN , , ,
— ..
NoSQL:
,
, , .
domain-specific languages .
NoSQL DSL. —
RethinkDB ReQL . , — domen specific language. Python, JavaScript .. — . SQL , .
ReQL, . ReQL , , — . RethinkDB, , , , , .
:
- Elasticsearch Query Language:
- MIN/MAX/AVG;
- derivative/percentiles/histogram/cumulative sum/serial diff;
- JSONIQ;
- GraphQL;
- SparQL;
- Pregel.
, , SQL, .
- SQL!SQL — OLTP , GROUP BY, Window Functions, (recursive). SQL , . ! , , .
, , . , , , , .
, , Pregel — . : , / . - , . , , .
- SQL, , , .
, ,
, , . .
-
, , . .

ArangoDB, - : , , ( ), , .

, , . . : , .
, , . , , , , . .
. , , relations. , relation , , relations ..
UPSERT:
Hier geht es nicht nur um NoSQL, aber dies ist ein Trend, der mir sehr wichtig erscheint - dies ist
schreiboptimierter Speicher - der meiner Meinung nach ernsthaft und für lange Zeit bei uns bleiben wird.
Weder SQL noch NoSQL haben Anweisungen, die nur von Natur aus geschrieben werden. Sogar absert, das in MongoDB enthalten ist, liest in einigen Fällen auch Daten. Einfügen ist auch ein Lesevorgang. Wenn im Dokument bereits eine ID definiert ist, müssen Sie überprüfen, ob keine solche ID vorhanden ist.
Sie sagen - wenn es Indizes gibt, müssen wir lesen. Aber
selbst wenn es Indizes gibt, ist das Lesen nicht immer notwendig . Die Idee ist folgende: Sie möchten auf keinen Fall lesen, Sie müssen dies nicht tun, Sie kümmern sich nicht um das Ergebnis des Lesens. Sie möchten der Datenbank Daten hinzufügen, falls diese dort noch nicht vorhanden sind. Wenn sie vorhanden sind, nehmen wir an, Sie ersetzen ihre alte Version durch eine neue oder führen einen Zusammenführungsbefehl aus. Das heißt, Sie müssen eine
neue Semantik erfinden, um nicht lesen zu können.
Meiner Meinung nach bietet dies derzeit keine einzige Datenbank, aber die Attraktivität schreiboptimierter Algorithmen ist so groß, dass ich diese Möglichkeit wirklich möchte. Denn dank schreiboptimiertem Speicher ist die Schreibleistung von LSM-Bäumen (RocksDB, LevelDB und andere)
ohne Lesen um 2 Größenordnungen höher als die Schreibleistung mit Lesen . Anstelle von 10 Tausend Anfragen pro Sekunde kann es eine Million auf einem Knoten geben.
Aus diesem Grund gewinnt die Zeitreihendatenbank jetzt, weil ihnen diese semantische Lücke fehlt. Der in ihnen ankommende Datenstrom ist klar als Zeitreihe definiert und wird insbesondere sehr schnell und kompakt in die Datenbank geschrieben. weil Sie die Eindeutigkeit nicht überprüfen müssen. Dies ist eine Größenordnung schneller, einfach weil es in herkömmlichen Datenbanken keine solche semantische Operation gibt, die nur geschrieben werden würde.
Ich denke es wird erscheinen.

Wohin geht das alles als nächstes? Wenn Sie sehr weit wegschauen, hört die Innovation nicht bei NoSQL und NewSQL auf. Unser Verständnis von Informationen entwickelt sich ständig weiter.
Einer der wichtigsten Trends der Zukunft ist meiner Meinung nach, dass wir Informationen immer weniger löschen werden.
Hierfür entsteht eine ganze Reihe von Produkten, die als temporale Datenbanken bezeichnet werden.
Nach NewSQL: Zeitdatenbank
Unten finden Sie Screenshots von Microsoft SQL Server. Dies ist eine Datenbank, mit der Sie Fragen zu einem bestimmten Zeitpunkt stellen können: Es gibt SELECT für den aktuellen Status, es ist jedoch weiterhin möglich, SELECT für ein Datum in der Vergangenheit festzulegen.

Dies führt zu einer Reihe neuer Datenbankanwendungen. Zunächst können Sie den Verlauf eines Objekts verfolgen. Zweitens können Sie automatisch Gruppen und Berichte nach Zeitraum berechnen. Sie müssen hierfür keine separaten Tabellen erstellen - Sie haben eine natürliche Darstellung in einer Tabelle: eine Entität - eine Tabelle.
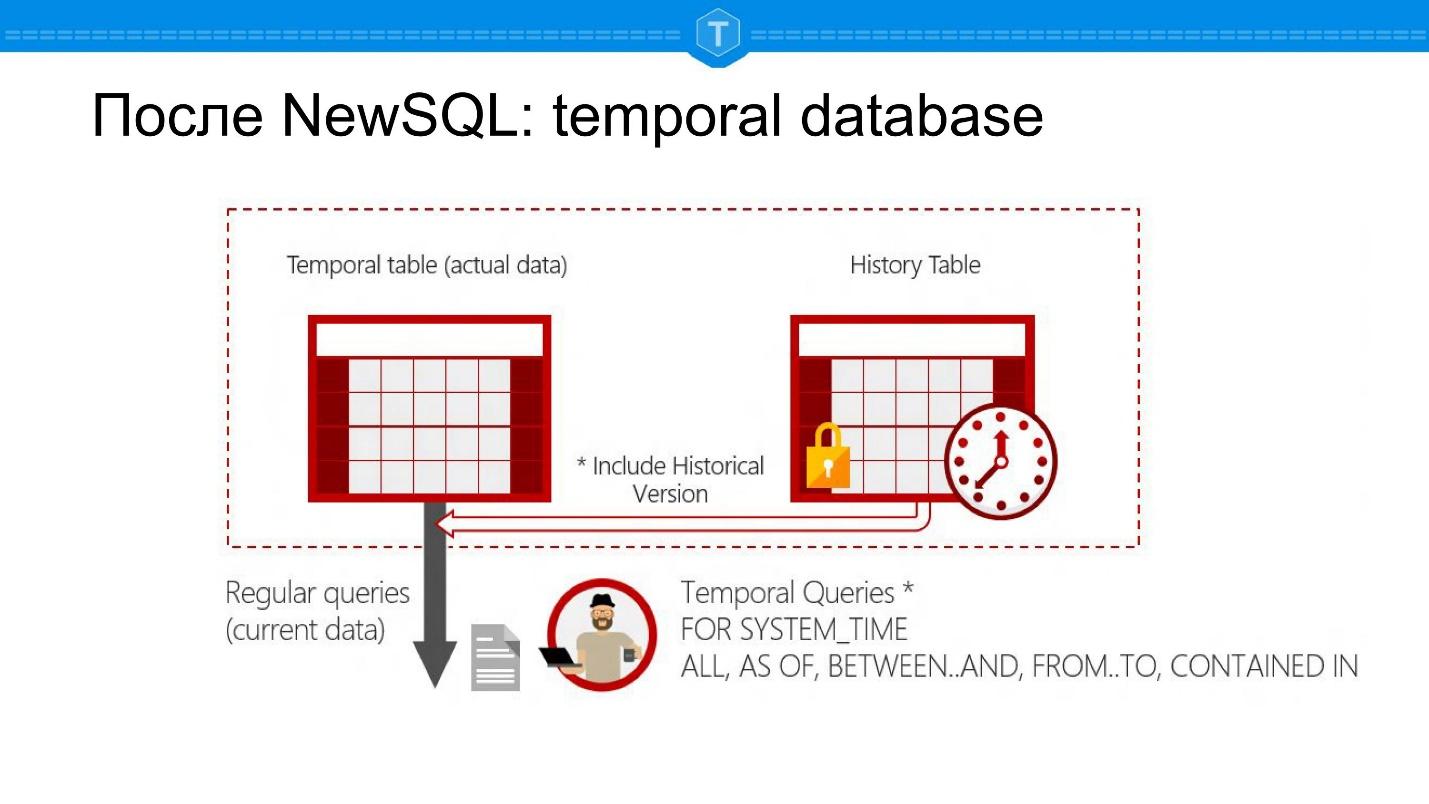
Aus Sicht der internen Struktur ist dies eigentlich die Haupttabelle und die Tabelle mit dem Verlauf. Jede Leitung ist zwei dem System bekannten Zeiten zugeordnet. Dies sind nicht nur zwei Spalten, die Sie hinzugefügt haben, sondern Daten, die das System automatisch unterstützt:
- die Zeit, zu der der Datensatz zur Datenbank hinzugefügt wurde,
- Ereigniszeit.
Es sind verschiedene Zeiten, egal wie amüsant.
Angenommen, Iwan Iwanowitsch ist am 17. November gestorben, und dieser Datensatz wurde am 20. November in die Datenbank eingegeben - beide Zeiten werden in solchen Datenbanken gespeichert.
Dies ist meiner Meinung nach auch einer der grundlegenden Trends. Warum denke ich so? Wenn wir zu den Sekundärschlüsseln und der eventuellen Konsistenz zurückkehren, können Sie dieses Problem nur speichern, indem Sie absolut alles speichern.
Wenn wir nie etwas aus der Datenbank löschen müssen, ist unsere Datenbank immer konsistent - eine so interessante Geschichte!
Nützliche Links
FAQ- Gibt es Entwicklungen beim Erstellen einer neuen Datenbank, die nicht für MySQL, PostgreSQL, MongoDB usw. gelten?
Die Frage ist auf gute Weise: Wird es neue Datenbanken und Startups geben? Ich denke, sie werden immer weniger erscheinen. Der Sturm hat nachgelassen, und jetzt werden wir eher den Abflug als die Ankunft sehen. CockroachDB war einer der letzten, die ankamen.
Kommen wir zum Punkt. Mein Professor an der Universität sagte, dass DBMS eine ewig grüne Fläche ist. Deshalb werden wir immer eine Art Bewegung sehen. Aber ich denke, dass in naher Zukunft grundsätzlich andere Produkte nicht auftauchen werden, es wird Konvergenz geben, keinen Boom.
- Keine Frage, sondern eine Ergänzung: SQL versucht häufig, Deckungsindizes zu erstellen, damit das Ergebnis der SQL-Abfrage nicht die Speicherebene betrifft, sondern sofort aus dem Index abgerufen wird. Der Index selbst ist eigentlich ein Sonderfall des Graphen. Vielleicht geht der Trend also dahin, dass die gesamte Datenbank allmählich in einen steilen Graphenindex übergeht?
Dies ist eine wunderbare Geschichte, die alle Vertreter von Grafikdatenbanken ihren Kunden gerne erzählen - sie funktioniert nicht! Weil es viele Möglichkeiten gibt, Indizes zu aktualisieren, und es gibt viele Indizierungsoptionen, aber nicht jeder hat ein Diagramm! Beruhigen wir uns - so wie nicht alles relational ist, ist nicht jeder ein Graph.
- Wohin gehen Ihrer Meinung nach Elastic und dergleichen? Ich spreche von der Tatsache, dass er anfängt, sehr seltsame Probleme zu lösen - er versucht, Zeitreihen und eine analytische Basis für die Arbeit mit Protokollen vorzutäuschen. Es scheint, dass niemand es für die Textsuche verwendet.
Elastic muss sich nirgendwo bewegen, weil Elastic sich großartig anfühlt. Es löst ein bestimmtes Geschäftsproblem - es ist eine effektive Suche und alles, was mit diesem Ökosystem zu tun hat.
Ich denke, dass alles in erster Linie von der Tatsache herrührt, dass Elastic versucht, alles zu sein. Aber hier ist die Frage von der Aufgabe, die elastische Aufgabe ist den Zeitreihenaufgaben sehr ähnlich, daher ist sie gerechtfertigt. Elastic eignet sich gut zum Durchsuchen großer Arrays derselben Protokolle usw.
Es gibt einen engeren Fall - es ist nur eine Volltextsuche, aber Sie werden nicht viel daraus machen. Es muss mehr getan werden, um sich überhaupt von den Wettbewerbern abzuheben. Daher geschieht dies alles.
Ich glaube jedoch nicht, dass Elastic morgen Bankgeschäfte abwickeln wird. Alles geht bis zu dem Punkt, an dem Couchbase zum Beispiel sein wird - wenn nicht Bankgeschäfte, aber etwas so schnelles.
Nachrichten
Sehr bald, am 21. Juni, wird die Tarantool-Konferenz in Moskau stattfinden - oder kurz T + Conf - eine Konferenz nicht nur über Tarantool selbst, sondern auch über den Einsatz von In-Memory-Computing im Allgemeinen .
- Konstantin Osipov plant, einen Bericht zu erstellen, in dem er die Vinyl-Architektur, ihre Funktionen und vor allem die für diese Engine spezifischen Optimierungs- und Leistungsüberwachungsmechanismen so konsistent und detailliert wie möglich untersuchen wird.
- Vladimir Perepelitsa möchte in einem Tutorial-Format zeigen, dass Tarantool eine Datenbank ist, die ein großes Potenzial für die Verwendung als Anwendungsserver hat.
- Vladislav Zaitsev wird sich diesem Thema nicht von seiner Seite nähern - von der Seite des Internets der Dinge - und insbesondere erklären, warum das IoT-Steuerungssystem.