Jeder von uns erledigt eine Hausarbeit. Jeder schreibt Boilerplate-Code. Warum? Ist es nicht besser, diesen Prozess zu automatisieren und nur an interessanten Aufgaben zu arbeiten? Lesen Sie diesen Artikel, wenn der Computer solche Arbeiten für Sie ausführen soll.
 Dieser Artikel basiert auf einer Abschrift eines Berichts von Zack Sweers, einem Entwickler von Uber Mobile Apps, der 2017 auf der MBLT DEV- Konferenz sprach.
Dieser Artikel basiert auf einer Abschrift eines Berichts von Zack Sweers, einem Entwickler von Uber Mobile Apps, der 2017 auf der MBLT DEV- Konferenz sprach.
Uber hat rund 300 Entwickler von mobilen Apps. Ich arbeite in einem Team namens "Mobile Platform". Die Arbeit meines Teams besteht darin, den Prozess der Entwicklung mobiler Anwendungen so weit wie möglich zu vereinfachen und zu verbessern. Wir arbeiten hauptsächlich an internen Frameworks, Bibliotheken, Architekturen usw. Aufgrund des großen Personals müssen wir Großprojekte durchführen, die unsere Ingenieure in Zukunft benötigen werden. Es kann morgen sein oder vielleicht nächsten Monat oder sogar ein Jahr.
Codegenerierung zur Automatisierung
Ich möchte den Wert des Codegenerierungsprozesses demonstrieren und einige praktische Beispiele betrachten. Der Prozess selbst sieht ungefähr so aus:
FileSpec.builder("", "Presentation") .addComment("Code generating your way to happiness.") .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", "Zac Sweers") .useSiteTarget(FILE) .build()) .build()
Dies ist ein Beispiel für die Verwendung von Kotlin Poet. Kotlin Poet ist eine Bibliothek mit einer guten API, die Kotlin-Code generiert. Was sehen wir hier?
- FileSpec.builder erstellt eine Datei mit dem Namen " Präsentation ".
- .addComment () - Fügt dem generierten Code einen Kommentar hinzu.
- .addAnnotation () - Fügt eine Anmerkung vom Typ Autor hinzu .
- .addMember () - fügt eine Variable " name " mit einem Parameter hinzu, in unserem Fall " Zac Sweers ". % S - Parametertyp.
- .useSiteTarget () - Installiert SiteTarget.
- .build () - Vervollständigt die Beschreibung des Codes, der generiert wird.
Nach der Codegenerierung wird Folgendes erhalten:
Presentation.kt // Code generating your way to happiness. @file:Author(name = "Zac Sweers")
Das Ergebnis der Codegenerierung ist eine Datei mit dem Namen, dem Kommentar, der Anmerkung und dem Namen des Autors. Es stellt sich sofort die Frage: "Warum muss ich diesen Code generieren, wenn ich dies in ein paar einfachen Schritten tun kann?" Ja, Sie haben Recht, aber was ist, wenn ich tausend dieser Dateien mit unterschiedlichen Konfigurationsoptionen benötige? Was passiert, wenn wir die Werte in diesem Code ändern? Was ist, wenn wir viele Präsentationen haben? Was ist, wenn wir viele Konferenzen haben?
conferences .flatMap { it.presentations } .onEach { (presentationName, comment, author) -> FileSpec.builder("", presentationName) .addComment(comment) .addAnnotation(AnnotationSpec.builder(Author::class) .addMember("name", "%S", author) .useSiteTarget(FILE) .build()) .build() }
Infolgedessen werden wir zu dem Schluss kommen, dass es einfach unmöglich ist, eine solche Anzahl von Dateien manuell zu verwalten - es ist notwendig, zu automatisieren. Daher besteht der erste Vorteil der Codegenerierung darin, Routinearbeiten zu vermeiden.
Fehlerfreie Codegenerierung
Der zweite wichtige Vorteil der Automatisierung ist der fehlerfreie Betrieb. Alle Menschen machen Fehler. Dies passiert besonders oft, wenn wir dasselbe tun. Computer hingegen machen einen solchen Job perfekt.
Betrachten Sie ein einfaches Beispiel. Es gibt eine Personenklasse:
class Person(val firstName: String, val lastName: String)
Angenommen, wir möchten die Serialisierung in JSON hinzufügen. Wir werden dies mit der
Moshi- Bibliothek tun, da diese recht einfach ist und sich hervorragend zur Demonstration eignet. Erstellen Sie einen PersonJsonAdapter und erben Sie von JsonAdapter mit einem Parameter vom Typ Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { }
Als nächstes implementieren wir die fromJson-Methode. Es bietet einen Leser zum Lesen von Informationen, die schließlich an Person zurückgegeben werden. Dann füllen wir die Felder mit dem Vor- und Nachnamen aus und erhalten den neuen Wert Person:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String return Person(firstName, lastName) } }
Als nächstes betrachten wir die Daten im JSON-Format, überprüfen sie und geben sie in die erforderlichen Felder ein:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() } } return Person(firstName, lastName) } }
Wird das funktionieren? Ja, aber es gibt eine Nuance: Die Objekte, die wir lesen, müssen in JSON enthalten sein. Fügen Sie eine weitere Codezeile hinzu, um überschüssige Daten herauszufiltern, die möglicherweise vom Server stammen:
class Person(val firstName: String, val lastName: String) class PersonJsonAdapter : JsonAdapter<Person>() { override fun fromJson(reader: JsonReader): Person? { lateinit var firstName: String lateinit var lastName: String while (reader.hasNext()) { when (reader.nextName()) { "firstName" -> firstName = reader.nextString() "lastName" -> lastName = reader.nextString() else -> reader.skipValue() } } return Person(firstName, lastName) } }
Zu diesem Zeitpunkt umgehen wir erfolgreich den Bereich des Routinecodes. In diesem Beispiel nur zwei Wertefelder. Dieser Code enthält jedoch eine Reihe verschiedener Abschnitte, in denen Sie plötzlich abstürzen können. Plötzlich haben wir einen Fehler im Code gemacht?
Betrachten Sie ein anderes Beispiel:
class Person(val firstName: String, val lastName: String) class City(val name: String, val country: String) class Vehicle(val licensePlate: String) class Restaurant(val type: String, val address: Address) class Payment(val cardNumber: String, val type: String) class TipAmount(val value: Double) class Rating(val numStars: Int) class Correctness(val confidence: Double)
Wenn Sie mindestens alle 10 Modelle ein Problem haben, bedeutet dies, dass Sie in diesem Bereich definitiv Schwierigkeiten haben werden. Und dies ist der Fall, wenn die Codegenerierung Ihnen wirklich helfen kann. Wenn es viele Klassen gibt, können Sie ohne Automatisierung nicht arbeiten, da alle Personen Tippfehler zulassen. Bei der Codegenerierung werden alle Aufgaben automatisch und fehlerfrei ausgeführt.
Die Codegenerierung bietet weitere Vorteile. Zum Beispiel gibt es Informationen über den Code aus oder sagt Ihnen, wenn etwas schief geht. Die Codegenerierung ist während der Testphase hilfreich. Wenn Sie den generierten Code verwenden, können Sie sehen, wie der Arbeitscode wirklich aussehen wird. Sie können sogar die Codegenerierung während der Tests ausführen, um Ihre Arbeit zu vereinfachen.
Fazit: Es lohnt sich, die Codegenerierung als mögliche Lösung in Betracht zu ziehen, um Fehler zu beseitigen.
Schauen wir uns nun Software-Tools an, die bei der Codegenerierung helfen.
Die Werkzeuge
- Die JavaPoet- und KotlinPoet-Bibliotheken für Java bzw. Kotlin. Dies sind die Standards für die Codegenerierung.
- Musterung. Ein beliebtes Beispiel für Vorlagen für Java ist Apache Velocity und für iOS- Lenker .
- SPI - Service Processor Interface. Es ist in Java integriert und ermöglicht es Ihnen, eine Schnittstelle zu erstellen, anzuwenden und anschließend in einer JAR zu deklarieren. Wenn das Programm ausgeführt wird, können Sie alle vorgefertigten Implementierungen der Schnittstelle erhalten.
- Compile Testing ist eine Bibliothek von Google, die beim Testen der Kompilierung hilft. In Bezug auf die Codegenerierung bedeutet dies: "Hier ist, was ich erwartet habe, aber hier ist, was ich schließlich bekommen habe." Die Kompilierung wird im Speicher gestartet, und das System teilt Ihnen mit, ob dieser Vorgang abgeschlossen wurde oder welche Fehler aufgetreten sind. Wenn die Kompilierung abgeschlossen ist, werden Sie aufgefordert, das Ergebnis mit Ihren Erwartungen zu vergleichen. Der Vergleich basiert auf kompiliertem Code. Machen Sie sich also keine Gedanken über Codeformatierungen oder andere Dinge.
Code-Build-Tools
Es gibt zwei Hauptwerkzeuge zum Erstellen von Code:
- Anmerkungsverarbeitung - Sie können Anmerkungen in den Code schreiben und das Programm um zusätzliche Informationen bitten. Der Compiler gibt Informationen aus, noch bevor er mit dem Quellcode fertig ist.
- Gradle ist ein Anwendungsassemblierungssystem mit vielen Hooks (Hook-Interception von Funktionsaufrufen) in seinem Code-Assembly-Lebenszyklus. Es ist weit verbreitet in der Android-Entwicklung. Außerdem können Sie die Codegenerierung auf den Quellcode anwenden, der von der aktuellen Quelle unabhängig ist.
Betrachten Sie nun einige Beispiele.
Buttermesser
Butter Knife ist eine von Jake Wharton entwickelte Bibliothek. Er ist eine bekannte Persönlichkeit in der Entwicklergemeinde. Die Bibliothek ist bei Android-Entwicklern sehr beliebt, da sie dazu beiträgt, die große Menge an Routinearbeit zu vermeiden, mit der fast jeder konfrontiert ist.
Normalerweise initialisieren wir die Ansicht folgendermaßen:
TextView title; ImageView icon; void onCreate(Bundle savedInstanceState) { title = findViewById(R.id.title); icon = findViewById(R.id.icon); }
Mit Butterknife sieht es so aus:
@BindView(R.id.title) TextView title; @BindView(R.id.icon) ImageView icon; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Und wir können problemlos eine beliebige Anzahl von Ansichten hinzufügen, während die onCreate-Methode den Boilerplate-Code nicht vergrößert:
@BindView(R.id.title) TextView title; @BindView(R.id.text) TextView text; @BindView(R.id.icon) ImageView icon; @BindView(R.id.button) Button button; @BindView(R.id.next) Button next; @BindView(R.id.back) Button back; @BindView(R.id.open) Button open; void onCreate(Bundle savedInstanceState) { ButterKnife.bind(this); }
Anstatt diese Bindung jedes Mal manuell durchzuführen, fügen Sie diesen Feldern einfach @ BondView-Anmerkungen sowie Bezeichner (IDs) hinzu, denen sie zugewiesen sind.
Das Coole an Butter Knife ist, dass es den Code analysiert und alle ähnlichen Abschnitte für Sie generiert. Es hat auch eine hervorragende Skalierbarkeit für neue Daten. Wenn neue Daten angezeigt werden, müssen Sie onCreate daher nicht erneut anwenden oder manuell verfolgen. Diese Bibliothek eignet sich auch hervorragend zum Löschen von Daten.
Wie sieht dieses System von innen aus? Die Ansicht wird durch Codeerkennung durchsucht, und dieser Prozess wird in der Annotationsverarbeitungsphase ausgeführt.
Wir haben dieses Feld:
@BindView(R.id.title) TextView title;
Nach diesen Daten zu urteilen, werden sie in einer bestimmten FooActivity verwendet:
Sie hat ihre eigene Bedeutung (R.id.title), die als Ziel fungiert. Bitte beachten Sie, dass dieses Objekt während der Datenverarbeitung innerhalb des Systems zu einem konstanten Wert wird:
Es ist in Ordnung. Darauf sollte Butter Knife sowieso Zugriff haben. Es gibt eine TextView-Komponente als Typ. Das Feld selbst heißt Titel. Wenn wir zum Beispiel aus diesen Daten eine Containerklasse erstellen, erhalten wir ungefähr Folgendes:
ViewBinding( target = "FooActivity", id = 2131361859, name = "title", type = "field", viewType = TextView.class )
So können alle diese Daten während ihrer Verarbeitung leicht erhalten werden. Es ist auch sehr ähnlich zu dem, was Butter Knife im System macht.
Infolgedessen wird diese Klasse hier generiert:
public final class FooActivity_ViewBinding implements Unbinder { private FooActivity target; @UiThread public FooActivity_ViewBinding(FooActivity target, View source) { this.target = target; target.title = Utils.findRequiredViewAsType(source, 2131361859,
Hier sehen wir, dass all diese Daten zusammengetragen werden. Als Ergebnis haben wir die ViewBinding-Zielklasse aus der Java-Bibliothek Underscore. Im Inneren ist dieses System so angeordnet, dass jedes Mal, wenn Sie eine Instanz der Klasse erstellen, die gesamte Bindung an die von Ihnen generierten Informationen (Code) sofort ausgeführt wird. Und all dies wurde zuvor statisch während der Verarbeitung von Anmerkungen generiert, was bedeutet, dass es technisch korrekt ist.
Kehren wir zu unserer Software-Pipeline zurück:
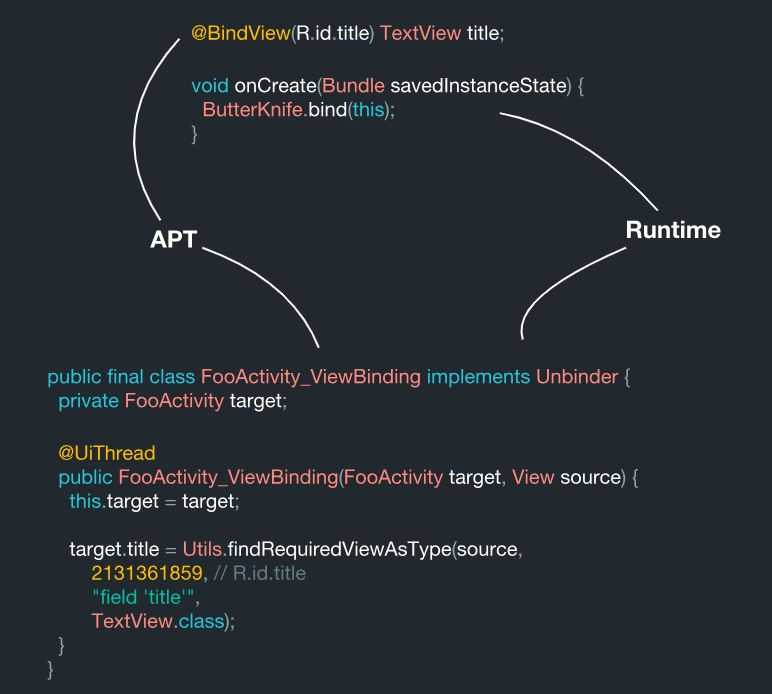
Während der Annotationsverarbeitung liest das System diese Annotationen und generiert die ViewBinding-Klasse. Und dann führen wir während der Bindemethode auf einfache Weise eine identische Suche nach derselben Klasse durch: Wir nehmen ihren Namen und hängen die ViewBinding am Ende an. Ein Abschnitt mit einer ViewBinding während der Verarbeitung wird im angegebenen Bereich mit JavaPoet überschrieben.
Rxbindings
RxBindings allein ist nicht für die Codegenerierung verantwortlich. Es verarbeitet keine Anmerkungen und ist kein Gradle-Plugin. Dies ist eine gewöhnliche Bibliothek. Es bietet statische Fabriken, die auf dem Prinzip der reaktiven Programmierung für die Android-API basieren. Dies bedeutet, dass beispielsweise, wenn Sie setOnClickListener haben, eine Klickmethode angezeigt wird, die einen Stream von (beobachtbaren) Ereignissen zurückgibt. Es fungiert als Brücke (Entwurfsmuster).
Tatsächlich gibt es in RxBinding jedoch Codegenerierung:
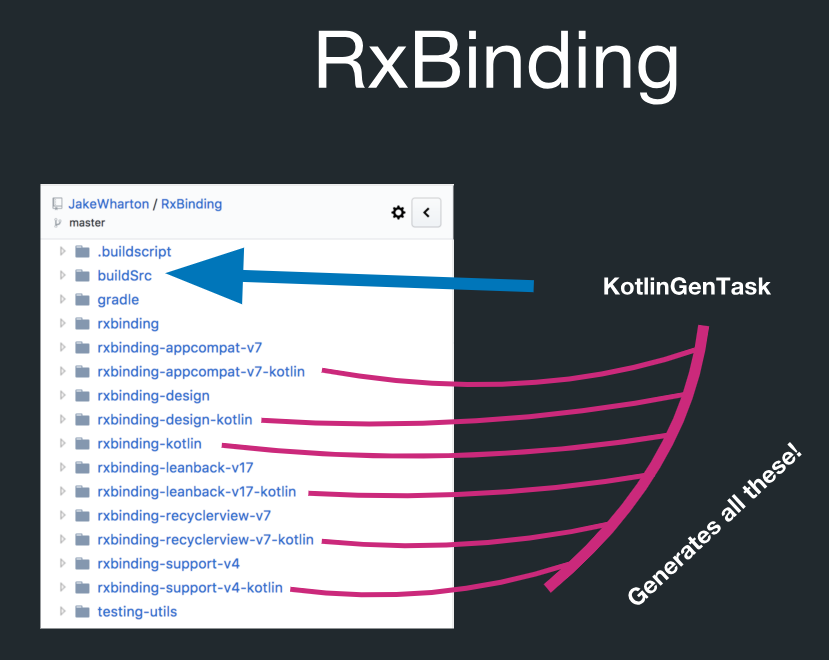
In diesem Verzeichnis namens buildSrc gibt es eine Gradle-Task namens KotlinGenTask. Dies bedeutet, dass all dies tatsächlich durch Codegenerierung erstellt wird. RxBinding verfügt über Java-Implementierungen. Sie hat auch Kotlin-Artefakte, die Erweiterungsfunktionen für alle Zieltypen enthalten. Und das alles unterliegt sehr streng den Regeln. Sie können beispielsweise alle Kotlin-Erweiterungsfunktionen generieren und müssen diese nicht einzeln steuern.
Wie sieht es wirklich aus?
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Hier ist eine völlig klassische RxBinding-Methode. Beobachtbare Objekte werden hier zurückgegeben. Die Methode heißt Klicks. Die Arbeit mit Klickereignissen findet „unter der Haube“ statt. Wir lassen die zusätzlichen Codefragmente weg, um die Lesbarkeit des Beispiels zu gewährleisten. In Kotlin sieht es so aus:
fun View.clicks(): Observable<Object> = RxView.clicks(this)
Diese Erweiterungsfunktion gibt Observable-Objekte zurück. In der internen Struktur des Programms ruft es direkt die für uns übliche Java-Schnittstelle auf. In Kotlin müssen Sie dies in Einheitentyp ändern:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Das heißt, in Java sieht es so aus:
public static Observable<Object> clicks(View view) { return new ViewClickObservable(view); }
Und so ist der Kotlin-Code:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Wir haben eine RxView-Klasse, die diese Methode enthält. Wir können die entsprechenden Daten im Zielattribut, im Namensattribut durch den Namen der Methode und in dem Typ, den wir erweitern, sowie im Typ des Rückgabewerts ersetzen. All diese Informationen reichen aus, um diese Methoden zu schreiben:
BindingMethod( target = "RxView", name = "clicks", type = View.class, returnType = "Observable<Unit>" )
Jetzt können wir diese Fragmente direkt in den generierten Kotlin-Code innerhalb des Programms einsetzen. Hier ist das Ergebnis:
fun View.clicks(): Observable<Unit> = RxView.clicks(this)
Service gen
Wir arbeiten bei Uber an Service Gen. Wenn Sie in einem Unternehmen arbeiten und sich mit allgemeinen Merkmalen und einer gemeinsamen Softwareschnittstelle sowohl für das Backend als auch für die Client-Seite befassen, ist es unabhängig davon, ob Sie Android-, iOS- oder Webanwendungen entwickeln, nicht sinnvoll, Modelle und Dienste manuell zu erstellen für die Teamarbeit.
Wir verwenden die
AutoValue- Bibliothek von Google für Objektmodelle. Es verarbeitet Anmerkungen, analysiert Daten und generiert einen zweizeiligen Hashcode, die equals () -Methode und andere Implementierungen. Sie ist auch für die Unterstützung von Erweiterungen verantwortlich.
Wir haben ein Objekt vom Typ Rider:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Wir haben Zeilen mit ID, Vorname, Nachname und Adresse. Um mit dem Netzwerk zu arbeiten, verwenden wir die Bibliotheken Retrofit und OkHttp sowie JSON als Datenformat. Wir verwenden RxJava auch für die reaktive Programmierung. So sieht unser generierter API-Service aus:
interface UberService { @GET("/rider") Rider getRider() }
Wir können dies alles manuell schreiben, wenn wir dies wünschen. Und das haben wir lange Zeit getan. Aber es braucht viel Zeit. Am Ende kostet es viel Zeit und Geld.
Was und wie macht Uber heute?
Die letzte Aufgabe meines Teams ist es, einen Texteditor von Grund auf neu zu erstellen. Wir haben uns entschieden, keinen Code mehr manuell zu schreiben, der anschließend ins Netzwerk
gelangt , und verwenden daher
Thrift . Es ist so etwas wie eine Programmiersprache und ein Protokoll zugleich. Uber verwendet Thrift als Sprache für technische Spezifikationen.
struct Rider { 1: required string uuid; 2: required string firstName; 3: required string lastName; 4: optional Address address; }
In Thrift definieren wir API-Verträge zwischen dem Backend und der Client-Seite und generieren dann einfach den entsprechenden Code. Wir verwenden die
Thrifty- Bibliothek zum Parsen von Daten und JavaPoet zum Generieren von Code. Am Ende generieren wir Implementierungen mit AutoValue:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); }
Wir erledigen die ganze Arbeit in JSON. Es gibt eine Erweiterung namens
AutoValue Moshi , die mit der statischen jsonAdapter-Methode zu AutoValue-Klassen hinzugefügt werden kann:
@AutoValue abstract class Rider { abstract String uuid(); abstract String firstName(); abstract String lastName(); abstract Address address(); static JsonAdapter<Rider> jsonAdapter(Moshi moshi) { return new AutoValue_Rider.JsonAdapter(moshi); } }
Sparsamkeit hilft auch bei der Entwicklung von Dienstleistungen:
service UberService { Rider getRider() }
Wir müssen hier auch einige Metadaten hinzufügen, um uns mitzuteilen, welches Endergebnis wir erzielen möchten:
service UberService { Rider getRider() (path="/rider") }
Nach der Codegenerierung erhalten wir unseren Service:
interface UberService { @GET("/rider") Single<Rider> getRider(); }
Dies ist jedoch nur eines der möglichen Ergebnisse. Ein Modell. Wie wir aus Erfahrung wissen, hat noch niemand nur ein Modell verwendet. Wir haben viele Modelle, die Code für unsere Dienste generieren:
struct Rider struct City struct Vehicle struct Restaurant struct Payment struct TipAmount struct Rating
Im Moment haben wir ungefähr 5-6 Bewerbungen. Und sie haben viele Dienste. Und jeder durchläuft dieselbe Software-Pipeline. Das alles von Hand zu schreiben wäre verrückt.
Bei der Serialisierung in JSON muss der „Adapter“ nicht in Moshi registriert sein. Wenn Sie JSON verwenden, müssen Sie sich nicht in JSON registrieren. Es ist auch zweifelhaft, Mitarbeitern vorzuschlagen, eine Deserialisierung durchzuführen, indem Code über ein DI-Diagramm neu geschrieben wird.
Wir arbeiten jedoch mit Java, sodass wir das Factory-Muster verwenden können, das wir über die
Fractory- Bibliothek generieren. Wir können dies generieren, da wir diese Typen kennen, bevor die Kompilierung stattgefunden hat. Fractory generiert einen Adapter wie folgt:
class ModelsAdapterFactory implements JsonAdapter.Factory { @Override public JsonAdapter<?> create(Type type, Set<? extends Annotation> annotations, Moshi moshi) { Class<?> rawType = Types.getRawType(type); if (rawType.isAssignableFrom(Rider.class)) { return Rider.adapter(moshi); } else if (rawType.isAssignableFrom(City.class)) { return City.adapter(moshi); } else if (rawType.isAssignableFrom(Vehicle.class)) { return Vehicle.adapter(moshi); }
Der generierte Code sieht nicht sehr gut aus. Wenn es das Auge verletzt, kann es manuell umgeschrieben werden.
Hier sehen Sie die zuvor genannten Typen mit den Namen der Dienste. Das System ermittelt automatisch, welche Adapter ausgewählt und aufgerufen werden sollen. Aber hier stehen wir vor einem anderen Problem. Wir haben 6000 dieser Adapter. Selbst wenn Sie sie innerhalb derselben Vorlage untereinander aufteilen, fällt das Modell „Eats“ oder „Driver“ in das Modell „Rider“ oder befindet sich in seiner Anwendung. Der Code wird gedehnt. Ab einem bestimmten Punkt kann es nicht einmal mehr in eine .dex-Datei passen. Daher müssen Sie die Adapter irgendwie trennen:

Letztendlich werden wir den Code im Voraus analysieren und ein funktionierendes Teilprojekt dafür erstellen, wie in Gradle:

In der internen Struktur werden diese Abhängigkeiten zu Gradle-Abhängigkeiten. Elemente, die die Rider-Anwendung verwenden, hängen jetzt davon ab. Damit bilden sie die Modelle, die sie brauchen. Infolgedessen wird unsere Aufgabe gelöst und all dies wird durch das Code-Assemblierungssystem innerhalb des Programms geregelt.
Aber hier stehen wir vor einem anderen Problem: Jetzt haben wir eine n-Anzahl von Fabrikmodellen. Alle von ihnen sind in verschiedene Objekte kompiliert:
class RiderModelFactory class GiftCardModelFactory class PricingModelFactory class DriverModelFactory class EATSModelFactory class PaymentsModelFactory
Während der Verarbeitung von Annotationen ist es nicht möglich, nur Annotationen zu externen Abhängigkeiten zu lesen und zusätzliche Codegenerierung nur für diese durchzuführen.
Lösung: Wir haben Unterstützung in der Fractory-Bibliothek, die uns auf eine schwierige Weise hilft. Es ist im Datenbindungsprozess enthalten. Wir führen Metadaten mit dem Parameter classpath im Java-Archiv für ihre weitere Speicherung ein:
class RiderModelFactory // -> json // -> ridermodelfactory-fractory.bin class MyAppGlobalFactory // Delegates to all discovered fractories
Gehen Sie jetzt jedes Mal, wenn Sie sie in der Anwendung verwenden müssen, zum Filter des Klassenpfadverzeichnisses mit diesen Dateien und extrahieren Sie sie von dort im JSON-Format, um herauszufinden, welche der Abhängigkeiten verfügbar sind.
Wie alles zusammen passt
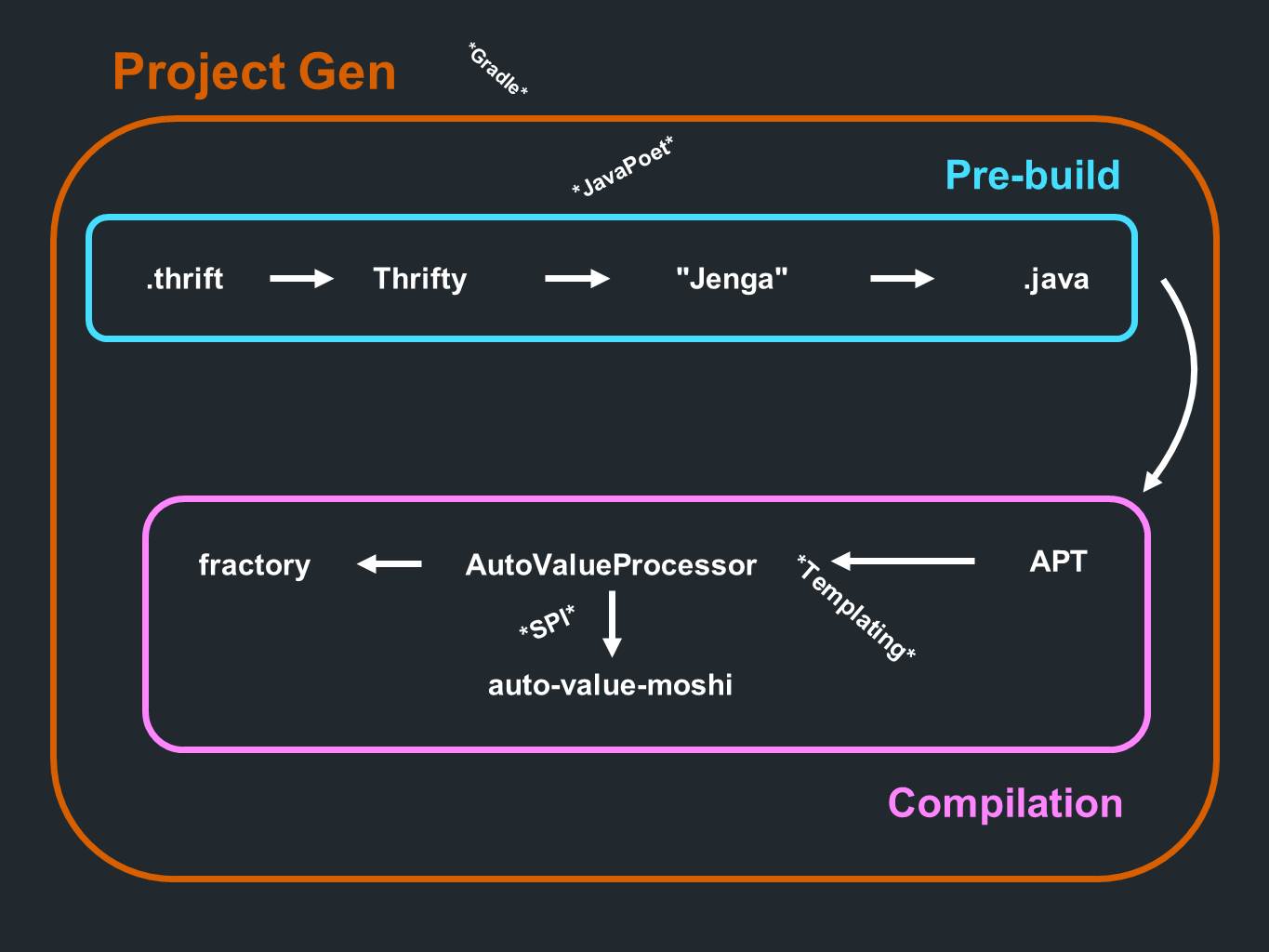
Wir haben eine
Sparsamkeit . Die Daten von dort gehen an
Thrifty und werden analysiert. Sie durchlaufen dann ein Codegenerierungsprogramm, das wir
Jenga nennen. Es werden Dateien im Java-Format erstellt. All dies geschieht bereits vor der Vorstufe der Verarbeitung oder vor der Kompilierung. Während des Kompilierungsprozesses werden Anmerkungen verarbeitet. Es ist an
AutoValue, eine Implementierung
zu generieren. Außerdem wird
AutoValue Moshi aufgerufen , um JSON-Unterstützung bereitzustellen.
Fractory ist ebenfalls
beteiligt . Alles passiert während des Kompilierungsprozesses. Dem Prozess geht eine Komponente zum Erstellen des Projekts selbst voraus, die hauptsächlich
Gradle- Teilprojekte generiert.
Nachdem Sie das vollständige Bild gesehen haben, bemerken Sie die zuvor erwähnten Tools. So gibt es beispielsweise Gradle, der Vorlagen erstellt, AutoValue und JavaPoet für die Codegenerierung. Alle Werkzeuge sind nicht nur für sich allein nützlich, sondern auch in Kombination miteinander.Nachteile der Codegenerierung
Es ist notwendig, über Fallstricke zu berichten. Das offensichtlichste Minus ist, den Code aufzublähen und die Kontrolle darüber zu verlieren. Zum Beispiel nimmt Dolch ungefähr 10% des gesamten Codes in der Anwendung ein. Modelle nehmen mit rund 25% einen deutlich größeren Anteil ein.Bei Uber versuchen wir, das Problem zu lösen, indem wir unnötigen Code wegwerfen. Wir müssen eine statistische Analyse des Codes durchführen und verstehen, welche Bereiche wirklich an der Arbeit beteiligt sind. Wenn wir es herausfinden, können wir einige Transformationen vornehmen und sehen, was passiert.Wir gehen davon aus, dass wir die Anzahl der generierten Modelle um ca. 40% reduzieren können. Dies beschleunigt die Installation und den Betrieb von Anwendungen und spart uns Geld.Wie sich die Codegenerierung auf die Zeitpläne für die Projektentwicklung auswirkt
Die Codegenerierung beschleunigt natürlich die Entwicklung, aber das Timing hängt von den Tools ab, die das Team verwendet. Wenn Sie beispielsweise in Gradle arbeiten, tun Sie dies höchstwahrscheinlich in einem gemessenen Tempo. Tatsache ist, dass Gradle einmal am Tag Modelle generiert und nicht, wenn der Entwickler dies wünscht.Erfahren Sie mehr über die Entwicklung bei Uber und anderen Top-Unternehmen.
Am 28. September startet in Moskau die 5. Internationale Konferenz der mobilen Entwickler MBLT DEV . 800 Teilnehmer, Top-Sprecher, Quiz und Rätsel für diejenigen, die an der Entwicklung von Android und iOS interessiert sind. Die Organisatoren der Konferenz sind e-Legion und RAEC. Sie können Teilnehmer oder Partner von MBLT DEV 2018 auf der Konferenzwebsite werden .
Video melden