
Im vergangenen Sommer endete der
Wettbewerb am Kaggle-Standort, der der Klassifizierung von Satellitenbildern der Amazonaswälder gewidmet war. Unser Team belegte von über 900 Teilnehmern den 7. Platz. Trotz der Tatsache, dass der Wettbewerb vor langer Zeit beendet wurde, sind fast alle Methoden unserer Lösung immer noch anwendbar, und zwar nicht nur für Wettbewerbe, sondern auch für das Training neuronaler Netze zum Verkauf. Für Details unter Kat.
tldr.pyimport kaggle from ods import albu, alno, kostia, n01z3, nizhib, romul, ternaus from dataset import x_train, y_train, x_test oof_train, oof_test = [], [] for member in [albu, alno, kostia, n01z3, nizhib, romul, ternaus]: for model in member.models: model.fit_10folds(x_train, y_train, config=member.fit_config) oof_train.append(model.predict_oof_tta(x_train, config=member.tta_config)) oof_test.append(model.predict_oof_tta(x_test, config=member.tta_config)) for model in albu.second_level: model.fit(oof_train) y_test = model.predict_proba(oof_test) y_test = kostia.bayes_f2_opt(y_test) kaggle.submit(y_test)
Aufgabenbeschreibung
Planet hat eine Reihe von Satellitenbildern in zwei Formaten erstellt:
- TIF - 16 Bit RGB + N, wobei N - Near Infrarot
- JPG - 8-Bit-RGB, die von TIF abgeleitet sind und bereitgestellt wurden, um den Schwellenwert für die Eingabe der Aufgabe zu verringern und die Visualisierung zu vereinfachen. Beim vorherigen Wettbewerb bei Kaggle war es notwendig, mit multispektralen Bildern zu arbeiten. Nicht visuell, dh Infrarot, sowie Kanäle mit einer längeren Wellenlänge verbesserten die Vorhersagequalität sowohl bei Netzwerk- als auch bei unbeaufsichtigten Methoden erheblich.
Geografisch wurden Daten aus dem Gebiet des Amazonasbeckens und aus den Gebieten der Länder Brasilien, Peru, Uruguay, Kolumbien, Venezuela, Guyana, Bolivien und Ecuador entnommen, in denen interessante Flächen ausgewählt wurden, deren Bilder den Teilnehmern angeboten wurden.
Nach dem Erstellen von JPG aus TIF wurden alle Szenen in kleine Stücke der Größe 256 x 256 geschnitten. Und laut jpg, das Planet-Mitarbeiter aus den Büros in Berlin und San Francisco sowie über die Crowd Flower-Plattform erhalten haben, wurde eine Kennzeichnung durchgeführt.
Die Teilnehmer wurden beauftragt, für jede 256x256-Kachel eine der sich gegenseitig ausschließenden Wettermarken vorherzusagen:
Bewölkt, teilweise bewölkt, Dunst, klar
Und auch 0 oder mehr schlechtes Wetter: Landwirtschaft, Primär, selektiver Holzeinschlag, Wohnen, Wasser, Straßen, wechselnder Anbau, Blühen, konventioneller Bergbau
Insgesamt 4 Wetter- und 13 Nichtwetter-Wetterbedingungen, die sich gegenseitig ausschließen, aber kein Wetter. Wenn das Bild jedoch bewölkt ist, sollten keine anderen Tags vorhanden sein.

Die Genauigkeit des Modells wurde anhand der F2-Metrik geschätzt:
Darüber hinaus hatten alle Etiketten das gleiche Gewicht und zuerst wurde F2 für jedes Bild berechnet, und dann gab es eine allgemeine Mittelung. Normalerweise machen sie es etwas anders, das heißt, für jede Klasse wird eine bestimmte Metrik berechnet und dann gemittelt. Die Logik ist, dass die letztere Option besser interpretierbar ist, da Sie damit die Frage beantworten können, wie sich das Modell für jede bestimmte Klasse verhält. In diesem Fall entschieden sich die Organisatoren für die erste Option, die offenbar mit den Besonderheiten ihres Geschäfts zusammenhängt.
Es gibt 40k Proben im Zug. Im Test 40k. Aufgrund der geringen Größe des Datensatzes, aber der großen Größe der Bilder können wir sagen, dass dies "MNIST bei Steroiden" ist.
Lyrischer ExkursWie Sie der Beschreibung entnehmen können, ist die Aufgabe durchaus verständlich und die Lösung ist kein Raketensinn: Sie müssen nur das Raster ablegen. Und unter Berücksichtigung der Besonderheiten des Cuggles können Sie auch eine Reihe von Modellen darauf stapeln. Um jedoch eine Goldmedaille zu erhalten, müssen Sie nicht nur irgendwie eine Reihe von Modellen trainieren. Es ist unbedingt erforderlich, viele grundlegende Modelle zu haben, von denen jedes für sich ein herausragendes Ergebnis zeigt. Und bereits über diesen Modellen können Sie Stapel- und andere Hacks abwickeln.
| Mitglied | netto | 1 Ernte | Tta | diff,% |
|---|
| alno | densenet121 | 0,9278 | 0,9294 | 0,1736 |
| nizhib | densenet169 | 0,9243 | 0,9277 | 0,3733 |
| romul | vgg16 | 0,9266 | 0,9267 | 0,0186 |
| ternaus | densenet121 | 0,9232 | 0,9241 | 0,0921 |
| albu | densenet121 | 0,9294 | 0,9312 | 0,1933 |
| kostia | resnet50 | 0,9262 | 0,9271 | 0,0907 |
| n01z3 | resnext50 | 0,9281 | 0,9298 | 0,1896 |
Die Tabelle zeigt die F2-Bewertungsmodelle aller Teilnehmer für Einzelkulturen und TTA. Wie Sie sehen können, ist der Unterschied für den realen Gebrauch gering, aber für den Wettbewerbsmodus wichtig.
TeaminteraktionAlexander Buslaev
albuZum Zeitpunkt der Teilnahme am Wettbewerb leitete er die gesamte ml-Richtung bei Geoscan. Aber seitdem hat er eine Reihe von Wettbewerben geschleppt, wurde der Vater aller ODS in der semantischen Segmentierung und ging nach Minsk, um in Mapbox zu rudern, über das der
Artikel veröffentlicht wurdeAlexey Noskov
alnoUniversal ml Kämpfer. Arbeitete bei Evil Martians. Jetzt rollte zu Yandex.
Konstantin Lopukhin
kostialopuhinArbeitete und arbeitet weiterhin bei Scrapinghub. Seitdem gelang es Kostya, ein paar weitere Medaillen zu holen und ohne 5 Minuten Kaggle Grandmaster
Arthur Cousin
n01z3Zum Zeitpunkt der Teilnahme an diesem Wettbewerb habe ich bei Avito gearbeitet. Aber um das neue Jahr
herum rollte
Dbrains Startup Lead Data Scientist in die Blockchain. Ich hoffe, dass wir die Community bald mit unseren Wettbewerben mit Dockern und Lampenmarkierungen begeistern werden.
Evgeny Nizhibitsky
@nizhibLeitender Datenwissenschaftler bei Rambler & Co. Bei diesem Wettbewerb entdeckte Eugene die geheime Fähigkeit, Gesichter in Bildwettbewerben zu finden. Was ihm geholfen hat, ein paar Wettbewerbe auf die Topcoder-Plattform zu ziehen. Ich
habe über einen von ihnen gesprochen.
Ruslan
Baykulov romulVerfolgung von Sportereignissen in Constanta.
Vladimir Iglovikov
ternausMan könnte sich an einen actionreichen
Artikel über Belästigung durch britische Geheimdienste erinnern. Er arbeitete bei TrueAccord, rollte dann aber in die trendige Jugend Lyft. Wo funktioniert Computer Vision für selbstfahrende Autos? Zieht weiterhin Wettbewerbe und erhielt kürzlich den Kaggle-Großmeister.
Unsere Assoziation und unser Teilnahmeformat können als typisch bezeichnet werden. Die Entscheidung zur Vereinigung war auf die Tatsache zurückzuführen, dass wir alle enge Ergebnisse in der Rangliste hatten. Und jeder von uns hat seine eigene unabhängige Pipeline gesägt, die von Anfang bis Ende eine völlig autonome Lösung war. Nach dem Zusammenschluss waren mehrere Teilnehmer mit dem Stapeln beschäftigt.
Das erste, was wir gemacht haben, war, Falten zu teilen. Wir haben sichergestellt, dass die Verteilung der Klassen in jeder Falte dieselbe ist wie im gesamten Datensatz. Dafür wurde zuerst die seltenste Klasse ausgewählt, die von ihr geschichtet wurde, da die verbleibenden Bilder von der zweitbeliebtesten Klasse geschichtet wurden, und so weiter, bis keine Bilder mehr übrig waren.
Histogramm der Faltklassen:
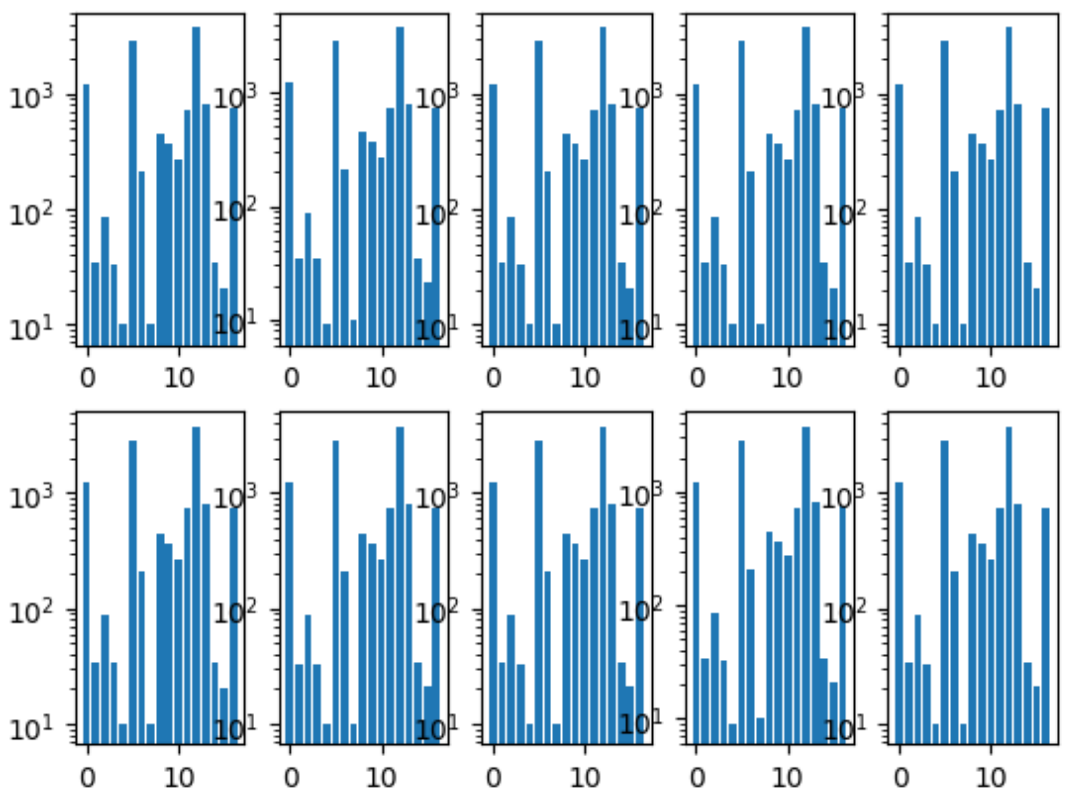
Wir hatten auch ein gemeinsames Repository, in dem jedes Teammitglied seinen eigenen Ordner hatte, in dem er den Code nach seinen Wünschen organisierte.
Wir haben uns auch auf das Format der Vorhersagen geeinigt, da dies der einzige Interaktionspunkt für die Kombination unserer Modelle war.
Neuronales NetzwerktrainingDa jeder von uns eine unabhängige Pipeline hatte, waren wir eine Stichprobe des optimalen Lernprozesses, der von Menschen parallelisiert wurde.
Allgemeiner Ansatz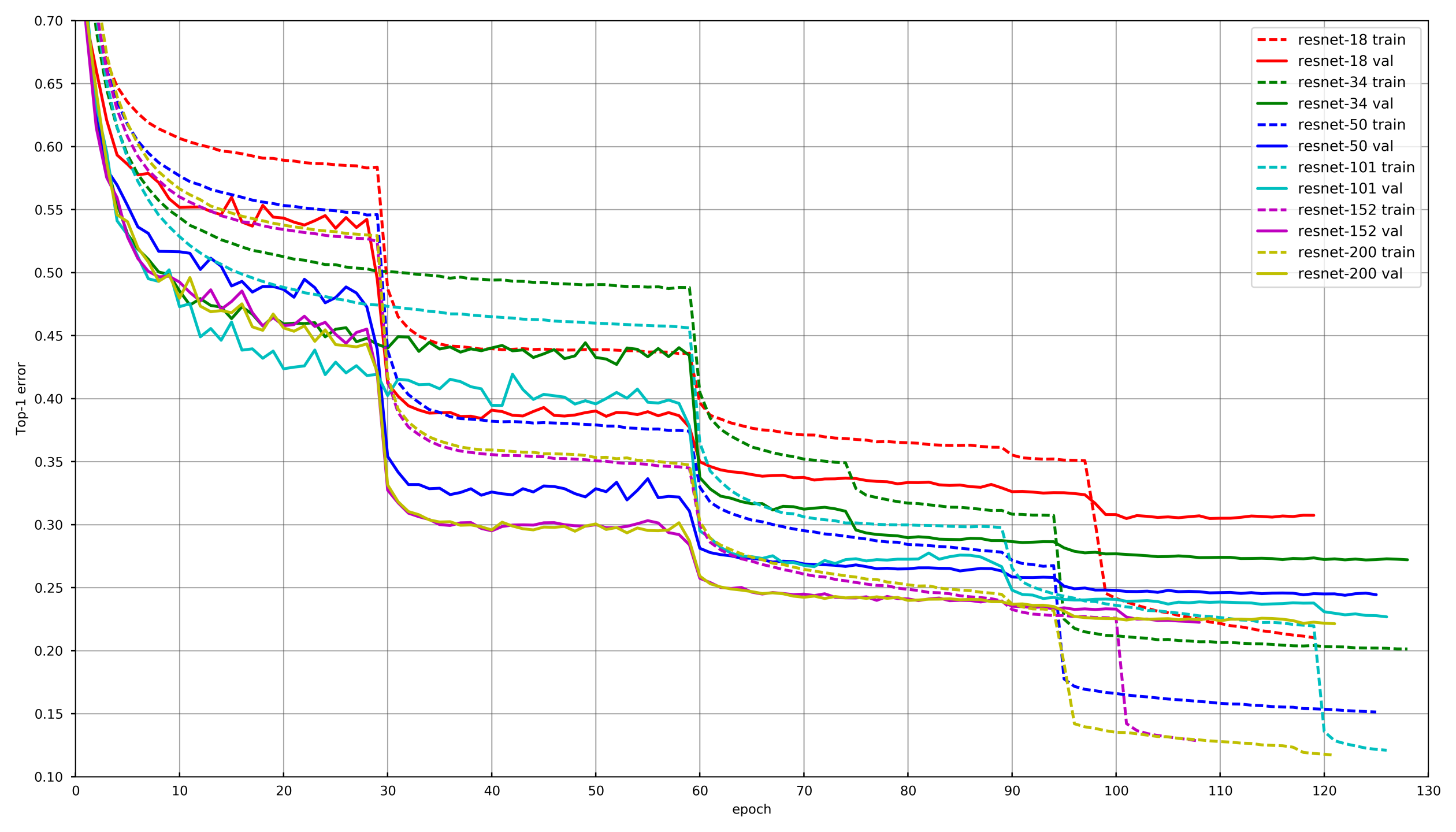
Bild von
github.com/tornadomeet/ResNetEin typischer Lernprozess wird im Trainingsplan von Resnet-Neuronalen Netzen auf Imagenet vorgestellt. Sie beginnen mit zufällig initialisierten Gewichten mit SGD (lr 0,1 Nesterov Momentum 0,0001 WD 0,9) und senken dann nach 30 Löschungen die Lernrate um das 10-fache.
Konzeptionell verwendete jeder von uns den gleichen Ansatz. Um jedoch nicht alt zu werden, während jedes Netzwerk trainiert wird, trat eine Abnahme der LR auf, wenn die Validierung den Verlust für 3-5 Epochen hintereinander nicht senkte. Oder einige Teilnehmer reduzierten einfach die Anzahl der Epochen für jeden LR-Schaden und senkten sie gemäß dem Zeitplan.
AugmentationDie Auswahl der richtigen Erweiterungen ist beim Training neuronaler Netze sehr wichtig. Augmentationen sollten die Variabilität der Art der Daten widerspiegeln. Herkömmlicherweise können Erweiterungen in zwei Typen unterteilt werden: diejenigen, die zu Verzerrungen in den Daten führen, und diejenigen, die dies nicht tun. Unter Voreingenommenheit kann man verschiedene Statistiken auf niedriger Ebene verstehen, wie z. B. Farbhistogramme oder charakteristische Größen. In dieser Hinsicht führen HSV-Erweiterungen und -Skalen beispielsweise einen Versatz ein, eine zufällige Ernte jedoch nicht.
In den ersten Phasen des Trainings des Netzwerks können Sie mit Erweiterungen zu weit gehen und einen sehr harten Satz verwenden. Gegen Ende des Trainings müssen Sie jedoch entweder die Augmentationen deaktivieren oder nur diejenigen belassen, die keine Verzerrung hervorrufen. Dies ermöglicht es dem neuronalen Netzwerk, sich etwas unter den Zug zu passen und bei der Validierung ein etwas besseres Ergebnis zu erzielen.
Schicht einfrierenBei den allermeisten Aufgaben macht es keinen Sinn, ein neuronales Netzwerk von Grund auf neu zu trainieren. Es ist viel effizienter, mit vorab trainierten Netzwerken zu spielen, beispielsweise mit Imagenet. Sie können jedoch noch weiter gehen und nicht nur die vollständig verbundene Ebene unter der Ebene mit der gewünschten Anzahl von Klassen ändern, sondern sie zuerst trainieren, indem Sie alle Windungen einfrieren. Wenn Sie die Windungen nicht einfrieren und das gesamte Netzwerk sofort mit zufällig initialisierten Gewichten der vollständig verbundenen Schicht trainieren, werden die Gewichte der Windungen verfälscht und die endgültige Leistung des neuronalen Netzwerks wird geringer. Bei dieser Aufgabe machte sich dies insbesondere aufgrund der geringen Größe der Trainingsstichprobe bemerkbar. Bei anderen Wettbewerben mit einer großen Datenmenge wie cdiscount war es möglich, nicht das gesamte neuronale Netzwerk einzufrieren, sondern Gruppen von Windungen vom Ende. Auf diese Weise konnte das Training erheblich beschleunigt werden, da Gradienten für gefrorene Schichten nicht berücksichtigt wurden.
Zyklisches GlühenDieser Prozess sieht so aus. Nach Abschluss des Grundtrainingsprozesses des neuronalen Netzes werden die besten Gewichte genommen und der Trainingsprozess wiederholt. Aber es beginnt mit einer niedrigeren Lernrate und tritt in kurzer Zeit auf, sagen wir 3-5 Epochen. Dies ermöglicht es dem neuronalen Netzwerk, auf ein niedrigeres lokales Minimum abzusinken und eine bessere Leistung zu zeigen. Diese stabile Kampagne verbessert das Ergebnis in einer ziemlich großen Anzahl von Wettbewerben.
Im Detail über zwei Empfänge
hierTestzeiterweiterungenDa dies ein Wettbewerb ist und wir keine formelle Einschränkung für die Inferenzzeit haben, können Sie während des Tests Augmentationen verwenden. Es sieht so aus, als ob das Bild genauso verzerrt ist wie während des Trainings. Angenommen, es wird vertikal, horizontal reflektiert, um einen Winkel gedreht usw. Jede Erweiterung gibt ein neues Bild, aus dem wir Vorhersagen erhalten. Dann werden die Vorhersagen solcher Verzerrungen eines Bildes gemittelt (in der Regel mit geometrischen Mitteln). Es gibt auch einen Gewinn. Bei anderen Wettbewerben habe ich auch mit zufälligen Erweiterungen experimentiert. Angenommen, Sie können nicht einzeln anwenden, sondern einfach die Amplitude für zufällige Windungen, Kontraste und Farbvergrößerungen um die Hälfte reduzieren, den Samen fixieren und mehrere solcher zufällig verzerrten Bilder erstellen. Dies gab auch einen Anstieg.
Snapshot Ensembling (Multicheckpoint TTA)Die Idee des Glühens kann weiterentwickelt werden. In jeder Phase des Temperns fliegt das neuronale Netzwerk in leicht unterschiedliche lokale Minima. Dies bedeutet, dass es sich im Wesentlichen um geringfügig unterschiedliche Modelle handelt, die gemittelt werden können. Während der Vorhersagen des Tests können Sie also die drei besten Kontrollpunkte nehmen und ihre Vorhersagen mitteln. Ich habe auch versucht, nicht die drei besten, sondern die drei verschiedensten der Top-10-Checkpoints zu nehmen - es war schlimmer. Nun, für die Produktion ist ein solcher Trick nicht anwendbar und ich habe versucht, das Gewicht der Modelle zu mitteln. Dies ergab einen sehr unbedeutenden, aber stetigen Anstieg.
 Ansätze jedes Teammitglieds
Ansätze jedes TeammitgliedsDementsprechend verwendete jedes Mitglied unseres Teams bis zu dem einen oder anderen Grad eine andere Kombination der oben genannten Techniken.
| Nick | Conv einfrieren,
Epoche | Optimierer | Strategie | Augs | Tta |
|---|
| albu | 3 | SGD | 15 Epoche LR Zerfall,
Kreis 13 Epochen | D4,
Skala,
Offset
Verzerrung
Kontrast
Unschärfe | D4 |
|---|
| alno | 3 | SGD | Lr Zerfall | D4,
Skala,
Offset
Verzerrung
Kontrast
Unschärfe
Schere
Kanalvervielfacher | D4 |
|---|
| n01z3 | 2 | SGD | Drop LR, Patient 10 | D4,
Skala,
Verzerrung
Kontrast
Unschärfe | D4, 3 Kontrollpunkt |
|---|
| ternaus | - - | Adam | Cyclisches LR (1e-3: 1e-6) | D4,
Skala,
Kanal hinzufügen
Kontrast | D4,
zufällige Ernte |
|---|
| nizhib | - - | Adam | StepLR, 60 Epochen, 20 pro Zerfall | D4,
RandomSizedCrop | D4,
4 Ecken,
Mitte
Skala |
|---|
| kostia | 1 | Adam | | D4,
Skala,
Verzerrung
Kontrast
Unschärfe | D4 |
|---|
| romul | - - | SGD | base_lr: 0,01 - 0,02
lr = base_lr * (0,33 ** (Epoche / 30))
Epoche: 50 | D4, Skala | D4, Mittelfrucht,
Eckkulturen |
|---|
Stapeln und HackenWir haben jedes Modell mit jedem Parametersatz auf 10 Falten trainiert. Und dann haben wir anhand der OOF-Vorhersagen (Out-of-Fold) Modelle der zweiten Ebene unterrichtet: Extra Trees, Linear Regression, Neural Network und einfach Mittelungsmodelle.
Und bereits bei OOF nahmen die Vorhersagen der Modelle der zweiten Ebene Gewichte zum Mischen auf. Weitere Informationen zum Stapeln finden Sie
hier und
hier .
Seltsamerweise findet dieser Ansatz auch in der realen Produktion statt. Zum Beispiel, wenn multimodale Daten (Bilder, Text, Kategorien usw.) vorhanden sind und Sie die Vorhersagen der Modelle kombinieren möchten. Sie können die Wahrscheinlichkeiten einfach mitteln, aber das Training eines Modells der zweiten Ebene liefert das beste Ergebnis.
Baes-Optimierung F2Außerdem wurden die endgültigen Vorhersagen mithilfe der Bayes'schen Optimierung etwas verbessert. Angenommen, wir haben ideale Wahrscheinlichkeiten, dann wird F2 mit der besten Erwartungsmatte (d. H. Vom optimalen Typ) durch die folgende Formel erhalten:
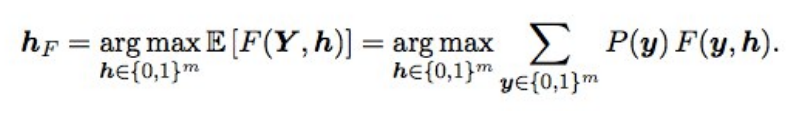
Was bedeutet das? Wir müssen alle Kombinationen sortieren (d. H. Für jedes Etikett 0 und 1), die Wahrscheinlichkeit jeder Kombination berechnen und mit F2 multiplizieren - wir erhalten das erwartete F2. Für welche Kombination ist es besser und ergibt das optimale F2. Wahrscheinlichkeiten wurden einfach als Multiplikation der Wahrscheinlichkeiten einzelner Labels betrachtet (wenn das Label 0 ist, nehmen wir 1 - p), und um 2 nicht in 17 Optionen zu sortieren, wurden nur Labels mit einer Wahrscheinlichkeit von 0,05 bis 0,5 gestaffelt - es gab 3-7 von ihnen in einer Reihe, also die Optionen ein bisschen (Einreichung war in ein paar Minuten erledigt). Theoretisch wäre es cool, die Wahrscheinlichkeit einer Kombination von Labels zu ermitteln und nicht nur einzelne Wahrscheinlichkeiten zu multiplizieren (da Labels nicht unabhängig sind), aber es hat nicht funktioniert.
Was hat es gegeben? Als die Modelle gut wurden, funktionierte die Auswahl der Schwellenwerte, nachdem das Ensemble aufgehört hatte, und diese Sache führte zu einem kleinen, aber stabilen Anstieg sowohl der Validierung als auch der öffentlichen / privaten.
NachwortAls Ergebnis haben wir 48 verschiedene Modelle trainiert, jedes mit 10 Falten, d.h. 480 Modelle der ersten Stufe. Eine solche menschliche Gridchurch ermöglichte es mir, verschiedene Techniken auszuprobieren, wenn ich tiefe Faltungs-Neuronale Netze trainierte, die ich immer noch in der Arbeit und bei Wettbewerben verwende.
War es möglich, weniger Modelle zu trainieren und das gleiche oder ein besseres Ergebnis zu erzielen? Ja ganz. Unsere Landsleute vom 3. Platz, Stanislav
stasg7 Semenov und Roman
ZFTurbo Soloviev, kosten eine geringere Anzahl von Modellen der ersten Ebene und versetzen mehr als 250 Modelle der zweiten Ebene. Über die Lösung können Sie
die Analyse sehen und
den Beitrag
lesen .
Der erste Platz ging an die mysteriöse Bestfitting. Im Allgemeinen ist dieser Typ sehr cool und jetzt ist er die Top1 Keggle-Wertung geworden, nachdem er viele Bildwettbewerbe gewonnen hat. Er blieb lange Zeit anonym, bis Nvidia das Cover durch ein
Interview mit ihm durchbrach. In dem er zugab, dass 200 Untergebene ihm Bericht erstatten würden ... Es gibt auch einen
Beitrag über die Entscheidung.
Ein weiterer interessanter: In engen Kreisen weithin bekannter
Jeremy Howard , Vater
Fastai, beendete 22 m. Und wenn Sie dachten, dass er nur ein paar Beiträge für seinen Fan gesendet hat, haben Sie es nicht erraten. Er nahm am Team teil und schickte 111 Pakete.
Außerdem beendeten Stanford-Absolventen, die zu dieser Zeit den legendären CS231n-Kurs belegten und diese Aufgabe als Kursprojekt nutzen durften, das gesamte Team in der Mitte der Rangliste.
Als Bonus habe ich bei Mail.ru mit dem Material dieses Beitrags gesprochen und hier ist eine weitere
Präsentation von Vladimir Iglovikov von einem Treffen im Tal.