„Researching the Analyst Vacancies Market“ war die sehr reale Aufgabe eines sehr realen führenden Analysten eines großen oder kleinen Unternehmens. Der Parser parzelliert Dutzende von Stellenbeschreibungen manuell mit hh, verteilt sie entsprechend den angeforderten Fähigkeiten und erhöht den Zähler in der entsprechenden Tabellenkalkulationsspalte.
Ich sah in dieser Aufgabe ein gutes Feld für die Automatisierung und beschloss, einfach und unkompliziert mit weniger Blut fertig zu werden.
Ich war an folgenden Themen interessiert, die in dieser Studie aufgeworfen wurden:
- Durchschnittsgehalt für Geschäfts- und Systemanalysten,
- die am meisten geforderten Fähigkeiten und persönlichen Qualitäten in dieser Position,
- Abhängigkeiten (falls vorhanden) zwischen bestimmten Fähigkeiten und der Höhe des Gehalts.
Spoiler: Es hat nicht einfach geklappt.
Datenaufbereitung
Wenn wir viele Daten über offene Stellen sammeln möchten, ist es logisch, dass hh nicht beschränkt ist. Jedoch für Experiment Reinheit Einfachheit, wir beginnen mit dieser Ressource.
Sammlung
Um Daten zu sammeln, verwenden wir die Jobsuche über die hh-API.
Ich suche mit der einfachen Textabfrage "Systemanalyst", "Geschäftsanalyst" und "Product Owner", da sich die Aktivitäten und Verantwortungsbereiche an diesen Positionen in der Regel überschneiden.
Erstellen Sie dazu eine Anforderung des Formulars https://api.hh.ru/vacancies?text="systems+analyst" und analysieren Sie den empfangenen JSON.
Um die relevantesten Stellen in der Stichprobe auszuwählen, suchen wir nur in den search_field=name indem search_field=name der Abfrage den Parameter search_field=name hinzufügen.
Hier können Sie sehen, welche offenen Felder für diese Anfrage zurückgegeben werden. Ich habe folgendes gewählt:
- Berufsbezeichnung
- Stadt
- Veröffentlichungsdatum
- Gehalt - Ober- und Untergrenze
- Währung, in der das Gehalt angegeben ist
- brutto - T / F.
- das Unternehmen
- Verantwortlichkeiten
- Anforderungen an den Kandidaten
Darüber hinaus möchte ich die im Abschnitt "Schlüsselkompetenzen" angegebenen Fähigkeiten weiter analysieren. Dieser Abschnitt ist jedoch nur in der vollständigen Stellenbeschreibung verfügbar. Daher werde ich auch Links zu den gefundenen Stellen behalten, um anschließend eine Liste der Fähigkeiten für jede von ihnen zu erhalten.
Code anzeigen # :) library(jsonlite) library(curl) library(dplyr) library(ggplot2) library(RColorBrewer) library(plotly) hh.getjobs <- function(query, paid = FALSE) { # Makes a call to hh API and gets the list of vacancies based on the given search queries df <- data.frame( query = character() # , URL = character() # , id = numeric() # id , Name = character() # , City = character() , Published = character() , Currency = character() , From = numeric() # . , To = numeric() # . , Gross = character() , Company = character() , Responsibility = character() , Requerement = character() , stringsAsFactors = FALSE ) for (q in query) { for (pageNum in 0:99) { try( { data <- fromJSON(paste0("https://api.hh.ru/vacancies?search_field=name&text=\"" , q , "\"&search_field=name" , "&only_with_salary=", paid ,"&page=" , pageNum)) df <- rbind(df, data.frame( q, data$items$url, as.numeric(data$items$id), data$items$name, data$items$area$name, data$items$published_at, data$items$salary$currency, data$items$salary$from, data$items$salary$to, data$items$salary$gross, data$items$employer$name, data$items$snippet$responsibility, data$items$snippet$requirement, stringsAsFactors = FALSE)) }) print(paste0("Downloading page:", pageNum + 1, "; query = \"", q, "\"")) } } names <- c("query", "URL", "id", "Name", "City", "Published", "Currency", "From", "To", "Gross", "Company", "Responsibility", "Requirement") colnames(df) <- names return(df) }
In der Funktion hh.getjobs() erhält die Eingabe einen Vektor von Suchanfragen, die für uns von Interesse und Verfeinerung sind. Wir sind nur an offenen Stellen mit einem bestimmten Gehalt oder allen in einer Reihe interessiert (standardmäßig verwenden wir die zweite Option). Ein leerer Dafa-Frame wird erstellt, und dann wird die fromJSON() -Funktion des fromJSON() Pakets jsonlite , die die Eingabe-URL verwendet und eine strukturierte Liste zurückgibt. Als nächstes erhalten wir von den Knoten in dieser Liste die Daten, an denen wir interessiert sind, und füllen die entsprechenden Datenrahmenfelder aus.
Standardmäßig werden Daten Seite für Seite mit 20 Elementen auf jeder Seite angegeben. Für maximal 2.000 offene Stellen. Alle Daten, die wir erhalten, werden in df aufgezeichnet.
Life Hack 1: Es ist keineswegs eine Tatsache, dass auf unsere Anfrage hin 2.000 Stellen frei werden, und ab einem bestimmten Zeitpunkt erhalten wir leere Seiten. In diesem Fall schwört R und springt aus der Schleife. Daher wickeln wir den Inhalt der inneren Schleife sorgfältig in try() .
Life Hack 2: Es ist auch sinnvoll, die Ausgabe des aktuellen Datenerfassungsstatus zur Konsole in der internen Schleife hinzuzufügen, da dies kein schnelles Geschäft ist. Ich habe das gemacht:
print(paste0("Downloading page:", pageNum + 1, "; query = \"", query, "\""))
Nach dem Ausfüllen der Daten werden die Spalten umbenannt, damit Sie bequem mit ihnen arbeiten können, und der resultierende Datenrahmen wird zurückgegeben.
Ich werde diese und andere Hilfsfunktionen in einer separaten Datei functions.R speichern, um das Hauptskript, das bisher so aussieht, nicht zu überladen:
source("functions.R") # Step 1 - get data # 1.1 get vacancies (short info) jobdf <- hh.getjobs(query = c("business+analyst" , "systems+analyst" , "product+owner"), paid = FALSE)
Jetzt erhalten wir experience und key_skills aus der vollständigen Stellenbeschreibung .
hh.getxp übergeben den hh.getxp an die Funktion hh.getxp , gehen die gespeicherten Links zu offenen Stellen durch und erhalten aus der vollständigen Beschreibung den Wert der erforderlichen Berufserfahrung. Der resultierende Wert wird in einer neuen Spalte gespeichert.
Code anzeigen hh.getxp <- function(df) { df$experience <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) df[df$URL == myURL, "experience"] <- data$experience$name } ) print(paste0("Filling in ", which(df$URL == myURL, arr.ind = TRUE), "from ", nrow(df))) } return(df) }
Die Beschreibung der neuen Hilfsfunktion wird an functions.R gesendet, und das Hauptskript greift jetzt darauf zu:
# s.1.2 get experience (from full info) jobdf <- hh.getxp(jobdf) # 1.3 get skills (from full info) all.skills <- hh.getskills(jobdf$URL)
Im obigen Fragment bilden wir auch einen neuen all.skills Form "Job-ID - Skill":
Code anzeigen hh.getskills <- function(allurls) { analyst.skills <- data.frame( id = character(), # id skill = character() # ) for (myURL in allurls) { data <- fromJSON(myURL) if (length(data$key_skills) > 0) analyst.skills <- rbind(analyst.skills, cbind(data$id, data$key_skills)) print(paste0("Filling in " , which(allurls == myURL, arr.ind = TRUE) , " out of " , length(allurls))) } names(analyst.skills) <- c("id", "skill") analyst.skills$skill <- tolower(analyst.skills$skill) return(analyst.skills) }
Vorverarbeitung
Mal sehen, wie viele Daten wir gesammelt haben:
> length(unique(jobdf$id)) [1] 1478 > length(jobdf$id) [1] 1498
Fast anderthalb tausend Jobs! Es sieht gut aus. Und anscheinend wurden mehrere Stellen zweimal in die Suchergebnisse aufgenommen - für unterschiedliche Anfragen. Daher besteht der erste Schritt darin, nur eindeutige Einträge zu jobdf <- jobdf[unique(jobdf$id),] : jobdf <- jobdf[unique(jobdf$id),] .
Um die Gehälter von Arbeitsmarktanalysten vergleichen zu können, brauche ich
1) Stellen Sie sicher, dass alle verfügbaren Daten zu Gehältern in einer einheitlichen Währung dargestellt werden.
2) Wählen Sie in einem separaten Datenrahmen die offenen Stellen aus, für die das Gehalt angegeben ist.
Wir betrachten jede der Unteraufgaben genauer. Zuvor können Sie anhand der table(jobdf$Currency) herausfinden, welche Währungen im Prinzip in unseren Daten enthalten sind. In meinem Fall erschienen neben Rubel auch Dollar, Euro, Griwna, kasachische Tenge und sogar usbekische Beträge.
Um Gehaltswerte in Rubel umzurechnen, müssen Sie den aktuellen Wechselkurs ermitteln. Wir werden von der Zentralbank erfahren:
Code anzeigen quotations.update <- function(currencies) { # Parses the most up-to-date qutations data provided by the Central Bank of Russia # and returns a table with currency rate against RUR doc <- XML::xmlParse("http://www.cbr.ru/scripts/XML_daily.asp") quotationsdf <- XML::xmlToDataFrame(doc, stringsAsFactors = FALSE) quotationsdf <- select(quotationsdf, -Name) quotationsdf$NumCode <- as.numeric(quotationsdf$NumCode) quotationsdf$Nominal <- as.numeric(quotationsdf$Nominal) quotationsdf$Value <- as.numeric(sub(",", ".", quotationsdf$Value)) quotationsdf$Value <- quotationsdf$Value / quotationsdf$Nominal quotationsdf <- quotationsdf %>% select(CharCode, Value) return(quotationsdf) }
Um sicherzustellen, dass Kurse in R korrekt verarbeitet werden, müssen Sie sicherstellen, dass der Dezimalteil durch einen Punkt getrennt ist. Außerdem sollten Sie auf die Nominal-Spalte achten: irgendwo ist es 1, irgendwo 10 oder 100. Dies bedeutet, dass ein Pfund Sterling ~ 85 Rubel kostet, und für hundert armenische Drams können Sie ~ 13 Rubel kaufen. Zur Vereinfachung der weiteren Verarbeitung habe ich die Werte auf einen Nennwert von 1 relativ zum Rubel reduziert.
Jetzt können Sie übersetzen. Unser Skript verwendet dazu die Funktion convert.currency() . Der aktuelle Wechselkurs ist der quotations entnommen, in der wir Daten aus XML gespeichert haben, die von der Zentralbank bereitgestellt wurden. Außerdem akzeptiert die Eingabefunktion die Zielwährung für die Umrechnung (standardmäßig RUR) und eine Tabelle mit offenen Stellen, die Werte der Gehaltsgabeln, in denen zu einer einheitlichen Währung geführt werden muss. Die Funktion gibt eine Tabelle mit aktualisierten Gehaltsziffern zurück (bereits ohne die Spalte Währung, falls nicht erforderlich).
Ich musste an belarussischen Rubeln basteln: Nachdem ich in mehreren Ansätzen sehr seltsame Daten erhalten hatte, führte ich eine kleine Untersuchung durch und fand heraus, dass seit 2016 in Belarus eine neue Währung verwendet wird, die sich nicht nur im Wechselkurs, sondern auch in der Abkürzung unterscheidet (jetzt nicht BYR, sondern BYN). . In hh- Verzeichnissen wird weiterhin die Abkürzung BYR verwendet, über die XML von der Zentralbank nichts weiß. Daher wird in der Funktion convert.currency() I. nicht auf die eleganteste Weise Zuerst ersetze ich die Abkürzung durch die aktuelle und gehe erst dann direkt zur Konvertierung.
Es sieht so aus:
Code anzeigen convert.currency <- function(targetCurrency = "RUR", df, quotationsdf) { cond <- (!is.na(df$Currency) & df$Currency == "BYR") df[cond, "Currency"] <- "BYN" currencies <- unique(na.omit(df$Currency[df$Currency != targetCurrency])) # ( ) if (!is.null(df$From)) { for (currency in currencies) { condition <- (!is.na(df$From) & df$Currency == currency) try( df$From[condition] <- df$From[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } # ( ) if (!is.null(df$To)) { for (currency in currencies) { condition <- !is.na(df$To) & df$Currency == currency try( df$To[condition] <- df$To[condition] * quotationsdf$Value[quotationsdf$CharCode == currency] ) } } return(df %>% select(-Currency)) }
Sie können auch berücksichtigen, dass einige Daten zu Gehältern in Bruttowerten dargestellt werden, dh der Mitarbeiter erhält etwas weniger zur Verfügung. Um das Nettogehalt für Einwohner der Russischen Föderation zu berechnen, müssen 13% von diesen Zahlen abgezogen werden (30% werden für Nicht-Einwohner abgezogen).
Code anzeigen gross.to.net <- function(df, resident = TRUE) { if (resident == TRUE) coef <- 0.87 else coef <- 0.7 if (!is.null(df$Gross)) { if (!is.null(df$From)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$From) & df$Gross == TRUE,]))) df$From[index] <- df$From[index] * coef } if (!is.null(df$To)) # ( ) { index <- na.omit(as.numeric(rownames(df[!is.na(df$To) & df$Gross == TRUE,]))) df$To[index] <- df$To[index] * coef } df <- df %>% select(-Gross) } return(df) }
Natürlich werde ich dies nicht tun, da es sich in diesem Fall lohnt, Steuern in verschiedenen Ländern und nicht nur in Russland zu berücksichtigen oder in der anfänglichen Suchabfrage einen Filter nach Ländern hinzuzufügen.
Der letzte Schritt vor der Analyse besteht darin, die gefundenen Stellen in drei Kategorien zu unterteilen: Juni, Mittel und Senior, und die erhaltenen Stellen in eine neue Spalte zu schreiben. Die Führungspositionen umfassen diejenigen, in deren Namen das Wort "Senior" und seine Synonyme vorhanden sind. In ähnlicher Weise finden wir die Startpositionen für die Schlüsselwörter "junior" und Synonyme, und unter den Mitten schließen wir alle zwischen ein:
get.positions <- function(df) { df$lvl <- NA df[grep(pattern = "lead|senior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "senior" df[grep(pattern = "junior|||", x = df$Name, ignore.case = TRUE), "lvl"] <- "junior" df[is.na(df$lvl), "lvl"] <- "middle" return(df) }
Fügen Sie den Datenaufbereitungsblock zum Hauptskript hinzu.
Hinzugefügt # Step 2 - prepare data # 2.1. Convert all currencies to target currency # 2.1.1 get up-to-date currency rates quotations <- quotations.update() # 2.1.2 convert to RUR jobdf <- convert.currency(df = jobdf, quotationsdf = quotations) # 2.2 convert Gross to Net # jobdf <- gross.to.net(df = jobdf) # 2.3 define segments jobdf <- get.positions(jobdf)
Analyse
Wie oben erwähnt, werde ich die folgenden Aspekte der erhaltenen Daten analysieren:
- Durchschnittsgehalt BA / SA,
- die am meisten geforderten Fähigkeiten und persönlichen Qualitäten in dieser Position,
- Abhängigkeiten (falls vorhanden) zwischen bestimmten Fähigkeiten und der Höhe des Gehalts.
Durchschnittliches BA / SA-Einkommen
Wie sich herausstellte, zögern Unternehmen, eine obere oder untere Gehaltsgrenze anzugeben.
In unserer jobdf diese Werte in den Spalten An bzw. Von. Ich möchte die Durchschnittswerte finden und in eine neue Gehaltsspalte schreiben.
In Fällen, in denen das Gehalt vollständig angegeben ist, kann dies einfach mit der Funktion mean() , wobei alle anderen Datensätze herausgefiltert werden, bei denen die Daten auf dem Stecker ganz oder teilweise fehlen. In diesem Fall würden jedoch weniger als 10% von unserer ursprünglichen Stichprobe übrig bleiben, die bereits klein ist. Deshalb berechne ich den Koeffizienten Podgoniana Hier erfahren Sie, um wie viel sich die To- und From-Werte im Durchschnitt in offenen Stellen unterscheiden, in denen die volle Gabelung angezeigt wird, und mit ihrer Hilfe fülle ich die fehlenden Daten aus, wenn nur ein Wert fehlt.
Code anzeigen select.paid <- function(df, suggest = TRUE) { # Returns a data frame with average salaries between To and From # optionally, can suggest To or From value in case only one is specified if (suggest == TRUE) { df <- df %>% filter(!is.na(From) | !is.na(To)) magic.coefficient <- # shows the average difference between max and min salary round(mean(df$To/df$From, na.rm = TRUE), 1) df[is.na(df$To),]$To <- df[is.na(df$To),]$From * magic.coefficient df[is.na(df$From),]$From <- df[is.na(df$From),]$To / magic.coefficient } else { df <- na.omit(df) } df$salary <- rowMeans(x = df %>% select(From, To)) df$salary <- ceiling(df$salary / 10000) * 10000 return(df %>% select(-From, -To)) }
Dies ist eine "weiche" Datenfilterung, die in der Funktion select.paid() mit dem Parameter suggest = TRUE wird. Alternativ können wir beim Aufrufen der Funktion suggest = FALSE angeben und einfach alle Zeilen ausschneiden, in denen die Gehaltsdaten zumindest teilweise fehlen. Mit der weichen Filterung und einem magischen Koeffizienten konnte ich jedoch fast ein Viertel des ursprünglichen Datensatzes in der Stichprobe speichern.
Wir gehen zum visuellen Teil über:

In dieser Grafik können Sie die Verteilungsdichte der BA / SA-Gehälter in zwei Hauptstädten und in Regionen visuell beurteilen. Aber was ist, wenn wir die Anfrage spezifizieren und vergleichen, wie viel die mittleren und älteren Männer in den Hauptstädten bekommen?
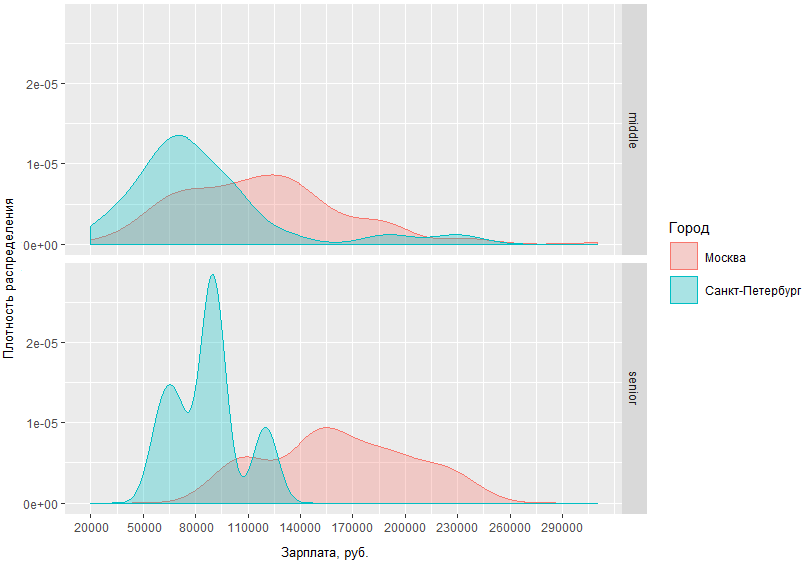
Aus der erhaltenen Grafik geht hervor, dass der Unterschied in den Gehaltssituationen zwischen mittleren und älteren Männern in Moskau und St. Petersburg nicht allzu unterschiedlich ist. In St. Petersburg liegen die Mittelwerte in der Regel im Bereich von 70 tr, während in Moskau der Dichtespitzenwert auf ~ 120 tr fällt und die Einkommensunterschiede von hochrangigen Spezialisten in Moskau und St. Petersburg unterscheidet sich um durchschnittlich 60 Tausend.
Wir können zum Beispiel auch die Moskauer Gehälter von Analysten nach Position betrachten:

Es kann gefolgert werden, dass a) heute in Moskau eine viel größere Nachfrage nach Einstiegsanalysten besteht und b) gleichzeitig die obere Gehaltsschwelle für solche Spezialisten viel begrenzter ist als die für Mittel- und Senioren.
Eine weitere Beobachtung: Der durchschnittliche sn von Moskauer Spezialisten mittleren und hohen Niveaus hat eine ziemlich große Kreuzungsfläche. Dies könnte darauf hinweisen, dass der Markt eine ziemlich verschwommene Grenze zwischen diesen beiden Schritten hat.
Vollständiger Code für Diagramme unter dem Schnitt.
Anzeigen # Step 3 - analyze salaries # 3.1 get paid jobs (with salaries specified) jobs.paid <- select.paid(jobdf) # 3.2 plot salaries density by region ggplotly(ggplot(jobs.paid, aes(salary, fill = region, colour = region)) + geom_density(alpha=.3) + scale_fill_discrete(guide = guide_legend(reverse=FALSE)) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10))) # 3.3 compare salaries for middle / senior in capitals ggplot(jobs.paid %>% filter(region %in% c("", "-"), lvl %in% c("senior", "middle")), aes(salary, fill = region, colour = region)) + facet_grid(lvl ~ .) + geom_density(alpha = .3) + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + scale_y_continuous(name = " ") + scale_fill_discrete(name = "") + scale_color_discrete(name = "") + guides(fill=guide_legend( keywidth=0.1, keyheight=0.1, default.unit="inch") ) + theme(legend.spacing = unit(1,"inch"), axis.title = element_text(size=10)) # 3.4 plot salaries in Moscow by position ggplotly(ggplot(jobs.paid %>% filter(region == ""), aes(salary, fill = lvl, color = lvl)) + geom_density(alpha=.4) + scale_fill_brewer(palette = "Set2") + scale_color_brewer(palette = "Set2") + theme_light() + scale_y_continuous(name = " ") + scale_x_continuous(labels = function(x) format(x, scientific = FALSE), name = ", .", breaks = round(seq(min(jobs.paid$salary), max(jobs.paid$salary), by = 30000),1)) + theme(axis.text.x = element_text(size=9), axis.title = element_text(size=10)))
Analyse der Schlüsselkompetenzen
Wir gehen weiter zum Hauptziel der Studie - die gefragtesten Fähigkeiten für BA / SA zu identifizieren. Zu diesem Zweck analysieren wir die Daten, die im speziellen Bereich der Vakanz - Schlüsselkompetenzen explizit angegeben sind.
Beliebteste Fähigkeiten
Zuvor erhielten wir einen separaten all.skills , in dem wir die Paare „Job-ID - Skill“ aufzeichneten. Mit der Funktion table() ist es einfach, die häufigsten Fähigkeiten zu finden:
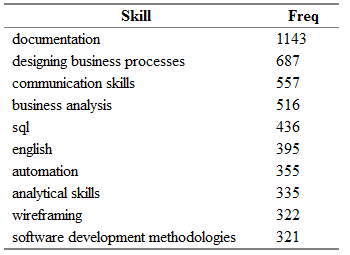
tmp <- as.data.frame(table(all.skills$skill), col.names = c("Skill", "Freq")) htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),]), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
Sie erhalten ungefähr Folgendes:

Hier ist Freq die Anzahl der offenen Stellen im Feld "key_skills", für die die entsprechende Fähigkeit aus der Spalte "Fähigkeit" angegeben ist.
„Aber das ist noch nicht alles!“ (C) Es ist ziemlich offensichtlich, dass die gleichen Fähigkeiten auch in verschiedenen Stellen leicht zu finden sind.
Ich habe ein kleines Wörterbuch mit Synonymen für die Namen der Fähigkeiten zusammengestellt und sie in Kategorien unterteilt.
Das Wörterbuch ist eine CSV-Datei mit Kategoriespalten - eine der folgenden: Aktivitäten, Tools, Kenntnisse, Standards und Persönliches; Fähigkeit - der Hauptname der Fähigkeit, den ich anstelle aller gefundenen Synonyme verwenden werde; syn1, syn2, ... syn13 - tatsächlich mögliche Variationen für jede Fertigkeit. Einige Zeilen enthalten möglicherweise leere Spalten mit Synonymen.
category;skill;syn1;syn2;syn3;syn4;syn5;syn6;syn7;syn8;syn9;syn10;syn11;syn12;syn13 tools;axure;;;;;;;;;;;;; tools;lucidchart;;;;;;;;;;;;; standards;archimate;;;;;;;;;;;;; standards;uml;activity diagram;use case diagram;ucd;class diagram;;;;;;;;; personal;teamwork;team player; ;;;;;;;;;;; activities;wireframing;mockup;mock-up;;-;wireframe;;ui;ux/;/ux;;;;
Importieren Sie zuerst das Wörterbuch und verteilen Sie die Fähigkeiten dann erneut basierend auf den vorhandenen Äquivalenzen:
# Analyze skills # 4.1 import dictionary dict <- read.csv(file = "competencies.csv", header = TRUE, stringsAsFactors = FALSE, sep = ";", na.strings = "", encoding = "UTF-8") # 4.2 match skills with dictionary all.skills <- categorize.skills(all.skills, dict)
Unter dem Schnitt sehen Sie die Füllung der Funktion categorize.skills() .
diese Eingeweide! categorize.skills <- function(analyst_skills, dictionary) { analyst_skills$skill.group <- NA analyst_skills$category <- NA for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) mypattern <- paste0(c(myskill, mypattern), collapse = "|") else mypattern <- myskill try( { analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"skill.group"] <- myskill analyst_skills[grep(x = analyst_skills$skill, pattern = mypattern),"category"] <- category } ) } return(analyst_skills) }
Ich füge die Kategorie- und Skillspalte dem ursprünglichen Skills-Datenrahmen hinzu. Gruppe - für die Kategorie bzw. den allgemeinen Namen der Fertigkeit. Dann gehe ich das importierte Wörterbuch durch und erstelle aus jeder Synonymzeile ein Muster für die Funktion grep() . Indem ich jeden nicht leeren Spaltenwert zur Zeile hinzufüge, trenne ich sie mit einem Bindestrich, um eine "oder" -Bedingung zu erhalten. Für alle Fähigkeiten aus der uml|activity diagram|use case diagram|ucd|class diagram , die das uml|activity diagram|use case diagram|ucd|class diagram , schreibe ich den Wert "uml" in die Spalte "ability.group ". Und so wird es mit jedem sein! .. Geschicklichkeit aus dem ursprünglichen Datenrahmen.
Wenn Sie die Spitze der beliebtesten Fertigkeiten erneut anfordern, können Sie feststellen, dass sich die Ausrichtung der Kräfte etwas geändert hat:
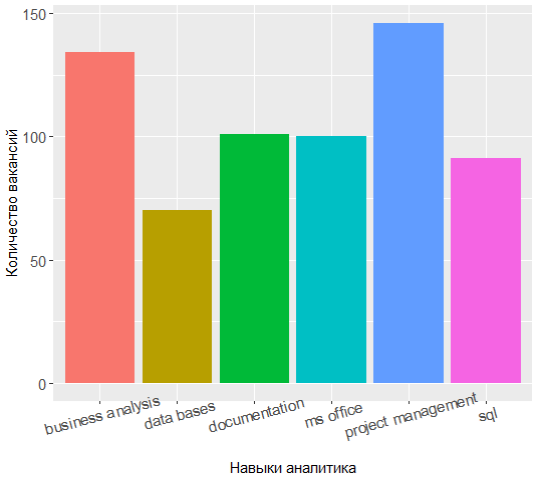
Die drei Führungskräfte verfügen nun über Projektmanagement, Geschäftsanalyse und Dokumentation, und das Wissen über UML hat sich von den Top 7 verschoben.
Es ist sehr interessant, die Kategorien durchzugehen und herauszufinden, welche Fähigkeiten in den einzelnen Kategorien am gefragtesten sind.
Für die Kategorie "Wissen" lautet dies beispielsweise wie folgt:
Code anzeigen tmp <- merge(x = all.skills, y = jobdf %>% select(id, lvl), by = "id", sort = FALSE) tmp <- na.omit(tmp) ggplot(as.data.frame(table(tmp %>% filter(category == "knowledge") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = reorder(Var1, -Freq))) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

Die Grafik zeigt, dass der größte Bedarf an Wissen im Bereich Datenbanken, Softwareentwicklungsmethoden und 1C besteht. Als nächstes folgen die Kenntnisse im Bereich CRM, ERP-Systeme und Programmiergrundlagen.
In Bezug auf Standards sind Kenntnisse in SQL und UML sehr gefragt, die ARIS-Notation folgt ihnen, aber GOSTs belegen nur den sechsten Platz.
Hier ist der Code ggplot(as.data.frame(table(tmp %>% filter(category == "standards") %>% select(skill.group)))) + geom_bar(colour = "#666666", stat = "identity", aes(x = reorder(Var1, Freq), y = Freq, fill = Var1)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()

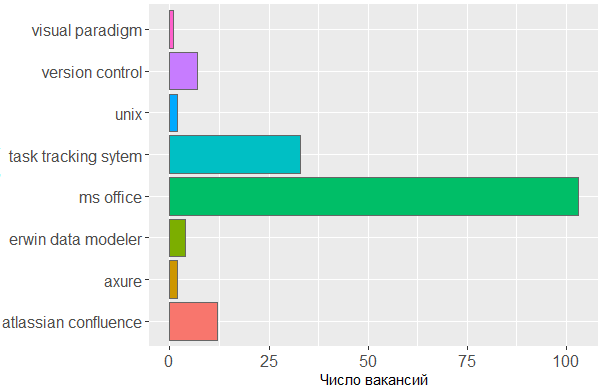
Bei den verwendeten Tools sehen wir erneut die Bestätigung, dass der Kopf das Hauptwerkzeug des Analytikers ist. Auf die MS Office-Linien- und Aufgabenverfolgungssysteme kann nicht verzichtet werden, aber der Rest ist für den Editor, in dem der Analyst seine eigenen Schemata erstellt oder Schnittstellenmodelle skizziert, von geringer Bedeutung.
Hier ist der Code ggplot(tmp %>% filter(category == "tools")) + geom_histogram(colour = "#666666", stat = "count", aes(skill.group, fill = skill.group)) + scale_y_continuous(name = " ") + theme(legend.position = "none", axis.text = element_text(size = 12)) + coord_flip()
Der Einfluss von Fähigkeiten auf das Einkommen
, , . , , , .
jobs.paid all.skills , data frame.
# 4.4 vizualize paid skills tmp <- na.omit(merge(x = all.skills, y = jobs.paid %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
:
> head(tmp) id skill skill.group category salary lvl City 2 25781585 android mobile os knowledge 90000 middle 3 25781585 project management activities 90000 middle 5 25781585 project management activities 90000 middle 6 25781585 ios mobile os knowledge 90000 middle 7 25750025 aris aris standards 70000 middle 8 25750025 - business analysis activities 70000 middle
, .. . :
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, salary)) + coord_flip() + geom_count(aes(size = ..n.., color = City)) + scale_fill_discrete(name = "") + scale_y_continuous(name = ", .") + scale_size_area(max_size = 11) + theme(legend.position = "bottom", axis.title = element_blank(), axis.text.y = element_text(size=10, angle=10)))

, BA/SA .
:
ggplot(tmp %>% filter(category == "personal", City %in% c("", "-")), aes(tools::toTitleCase(skill), salary)) + coord_flip() + geom_count(aes(size = ..n.., color = skill.group)) + scale_y_continuous(breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 20000),1), name = ", .") + scale_size_area(max_size = 10) + theme(legend.position = "none", axis.title = element_text(size = 11), axis.text.y = element_text(size=10, angle=0))
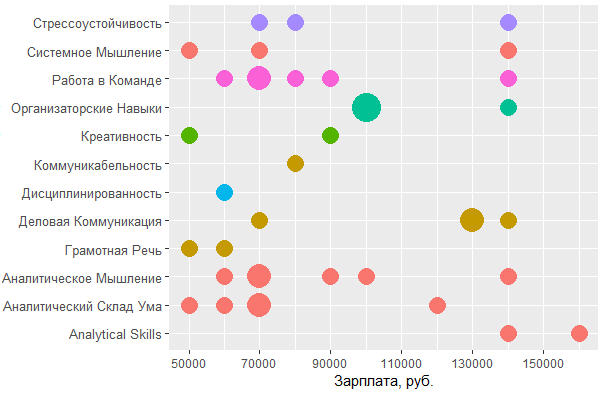
, MS Office , — , - . , , , .
, , : UML ARIS, SQL ( ) , IDEF — , "".
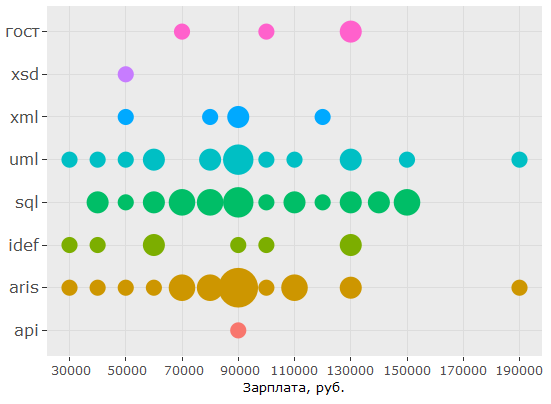
, , , . , 1478 - key_skills. , - .
, data frame:
> jobdf$Responsibility[[1]] [1] "Training course in business analysis. ● Define needs of the user/client, understand the problem which needs to be solved. ● " > jobdf$Requirement[[1]] [1] "At least 6 months' experience in business analysis. ● Knowledge of qualitative methods such as usability testing, interviewing, focus groups. ● "
, , . URL' , .
hh.get.full.desrtion <- function(df) { df$full.description <- NA for (myURL in df$URL) { try( { data <- fromJSON(myURL) if (length(data$description) > 0) { df$full.description[which(df$URL == myURL, arr.ind = TRUE)] <- data$description } print(paste0("Filling in " , which(df$URL == myURL, arr.ind = TRUE) , " out of " , length(df$URL))) } ) } df$full.description <- tolower(df$full.description) return(df) }
- , html- ., gsub :
remove.Html <- function(htmlString) { #remove html tags return(gsub("<.*?>", "", htmlString)) }
, , , , . data frame ( df), , df "id, skill.group, category".
skills.from.desc <- function(df, dictionary) { sk <- data.frame( id = numeric() , skill.group = character() , category = character() ) for (myskill in dictionary$skill) { category <- dictionary[dictionary$skill == myskill, "category"] mypattern <- paste0(na.omit(t(dictionary %>% filter(skill == myskill) %>% select(starts_with("syn")))), collapse = "|") if (nchar(mypattern) > 1) { mypattern <- paste0(c(myskill, mypattern), collapse = "|") } else { mypattern <- myskill } cond = grep(x = df$full.description, pattern = mypattern) tmp <- data.frame( id = df[cond, "id"], skill.group = rep(myskill, length(cond)), category = rep(category, length(cond)) ) sk <- rbind(sk, tmp) } return(sk) }
# 5 text analysis # 5.1 get full descriptions jobdf <- hh.get.full.description(jobdf) jobdf$full.description <- remove.Html(tolower(jobdf$full.description)) sk.from.desc <- skills.from.desc(jobdf, dict)
, ?
> head(sk.from.desc) id skill.group category 1 25638419 axure tools 2 24761526 axure tools 3 25634145 axure tools 4 24451152 axure tools 5 25630612 axure tools 6 24985548 axure tools > tmp <- as.data.frame(table(sk.from.desc$skill.group), col.names = c("Skill", "Freq")) > htmlTable::htmlTable(x = head(tmp[order(tmp$Freq, na.last = TRUE, decreasing = TRUE),], 20), rnames = FALSE, header = c("Skill", "Freq"), align = 'l', css.cell = "padding-left: .5em; padding-right: 2em;")
, ! Project management, key_skills, ( ).
, , key_skills -5.
, . 1478 , , key_skills, , .
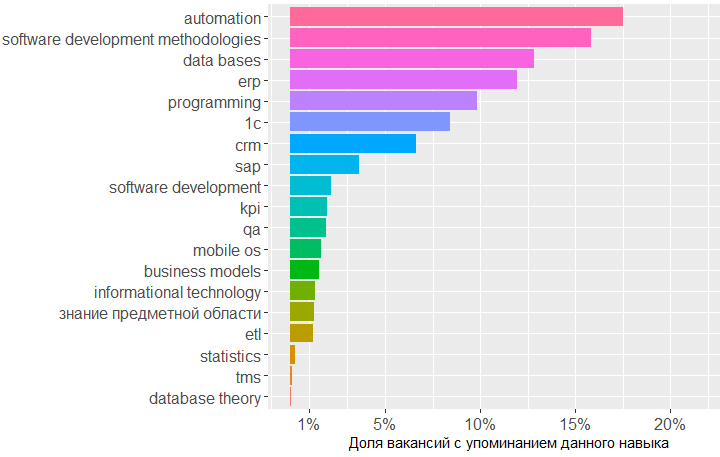
, , BA , - .
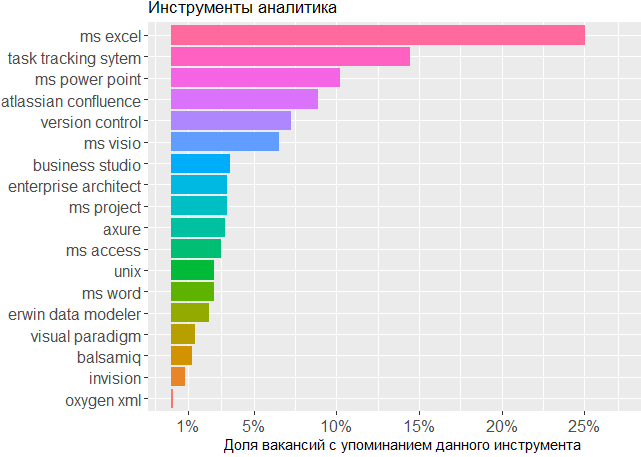
, .
data frame , , . , -.
tmp <- na.omit(merge(x = sk.from.desc, y = jobs.paid %>% filter(City %in% c("", "-")) %>% select(id, salary, lvl, City), by = "id", sort = FALSE))
> head(tmp) id skill.group category salary lvl City 1 25243346 uml standards 160000 middle 2 25243346 requirements management activities 160000 middle 3 25243346 designing business processes activities 160000 middle 4 25243346 communication skills personal 160000 middle 5 25243346 mobile os knowledge 160000 middle 6 25243346 ms visio tools 160000 middle
, , , .
ggplotly(ggplot(tmp %>% filter(category == "activities"), aes(skill.group, lvl)) + geom_count(aes(color = salary, size = ..n..)) + scale_size_area(max_size = 13) + theme(legend.position = "right", legend.title = element_text(size = 10), axis.title = element_blank(), axis.text.y = element_text(size=10)) + coord_flip() + scale_color_continuous(labels = function(x) format(x, scientific = FALSE), breaks = round(seq(min(tmp$salary), max(tmp$salary), by = 70000),1), low = "blue", high = "red", name = ", ."))
?
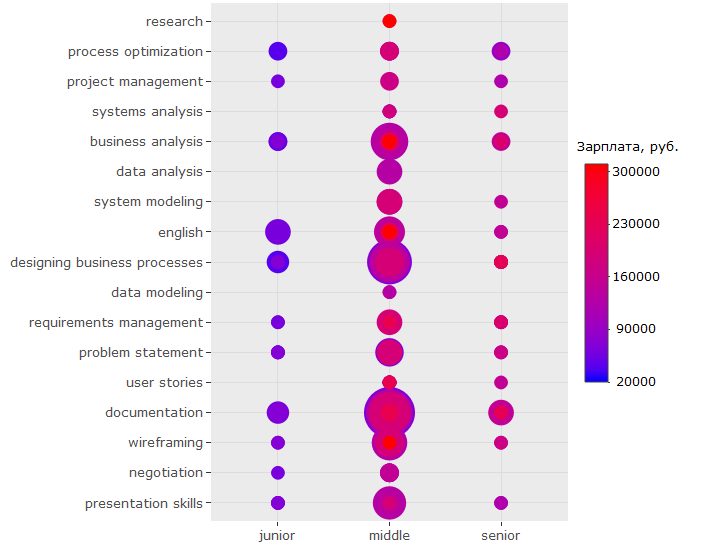
-, , - . ( , , , .)
-, , "" -, .
, key_skills.
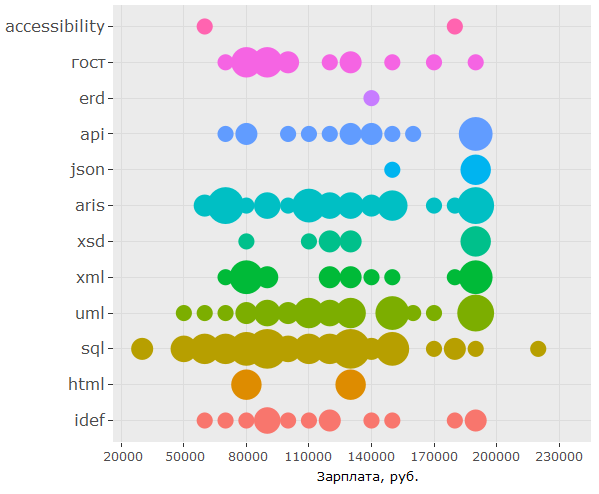
, , 150 .. UML ARIS, IDEF, , — .
:

, - , , key_skills , . , 150 .. , .
?
, - :

, , , ? , . , , . , ó ( )
, - :

-
BA/SA ,
- . , ;
- ( ) 200 .. , , ;
- ;
- — - ( , , )
key_skills hh , ;- , , , (!) ;
- , -, UX ;
- . , - 150 ..;
- , , SQL, UML & ARIS. , .. . , , ,
wordcloud2::wordcloud2(data = table(sk.from.desc$skill.group), rotateRatio = 0.3, color = 'random-dark')
