Oder wie ich im Gewinnerteam des gegnerischen Wettbewerbs Machines Can See 2018 gelandet bin.
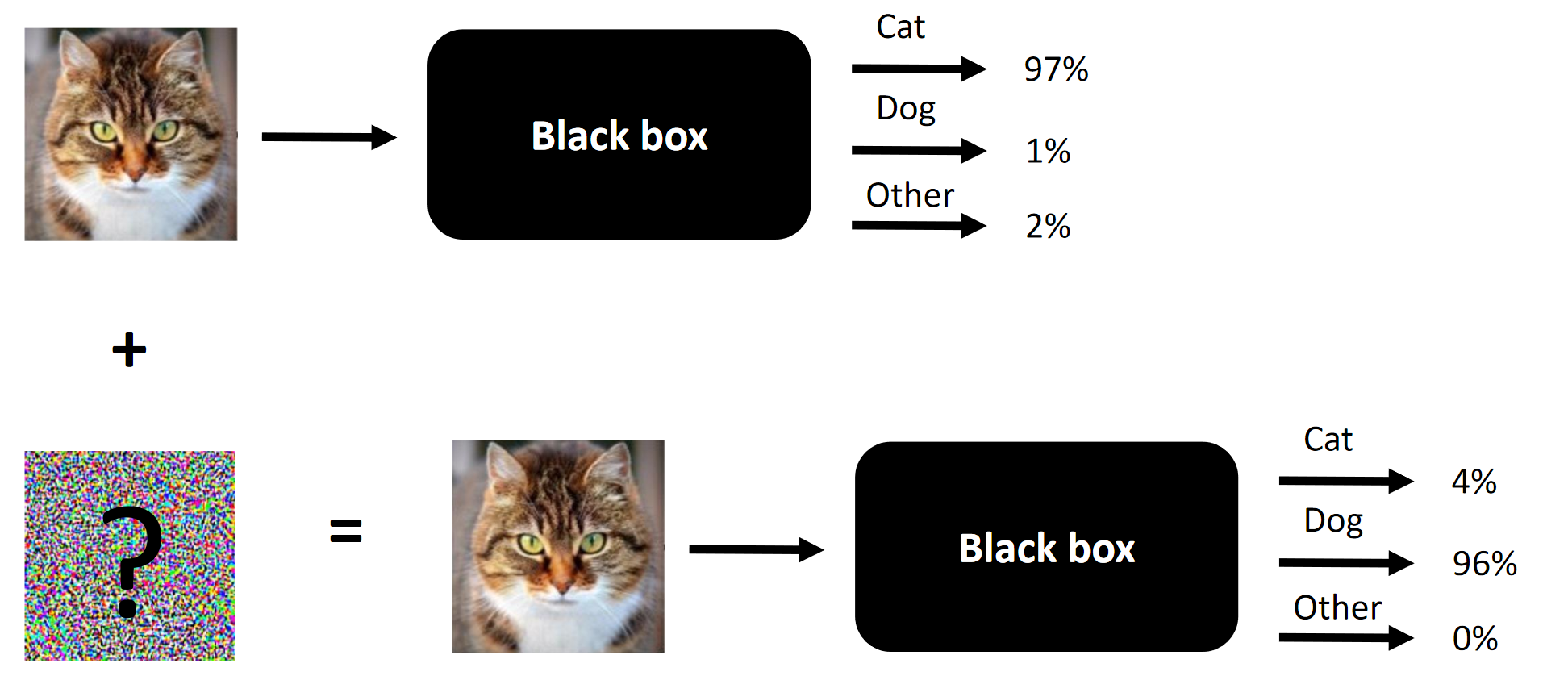 Die Essenz von Wettbewerbsangriffen ist ein Beispiel.
Die Essenz von Wettbewerbsangriffen ist ein Beispiel.Es ist einfach so passiert, dass ich zufällig am Wettbewerb Machines Can See 2018 teilgenommen habe. Ich habe mich etwas spät (ungefähr eine Woche vor dem Ende) dem Wettbewerb angeschlossen, bin aber in einem Team von 4 Personen gelandet, wo der Beitrag von uns dreien (einschließlich mir) war notwendig für den Sieg (entfernen Sie eine Komponente - und wir wären Außenseiter).
Der Zweck des Wettbewerbs besteht darin, die Gesichter von Menschen so zu verändern, dass das von den Organisatoren als Black Box präsentierte Faltungsnetzwerk das Quellgesicht nicht vom Zielgesicht unterscheiden kann. Die Anzahl der zulässigen Änderungen wurde von
SSIM begrenzt .
Originalartikel
hier gepostet.
Hinweis Die ungeschickte Übersetzung der Terminologie oder ihre Abwesenheit wird durch das Fehlen einer etablierten Terminologie in der russischen Sprache bestimmt. Sie können Ihre Optionen in den Kommentaren vorschlagen. Das Wesentliche des Wettbewerbs besteht darin, das Gesicht am Eingang so zu verändern, dass die Black Box nicht zwischen zwei Gesichtern unterscheiden kann (zumindest unter dem Gesichtspunkt der L2 / euklidischen Entfernung).
Das Wesentliche des Wettbewerbs besteht darin, das Gesicht am Eingang so zu verändern, dass die Black Box nicht zwischen zwei Gesichtern unterscheiden kann (zumindest unter dem Gesichtspunkt der L2 / euklidischen Entfernung).Was funktioniert bei Wettbewerbsangriffen und was hat in unserem Fall funktioniert:
- Fast Gradient Sign Method (FGSM). Das Hinzufügen von Heuristiken machte es ein wenig besser;
- Fast Gradient Value Method (FGVM). Das Hinzufügen von Heuristiken machte es STARK besser;
- Genetische differentielle Evolution (großartiger Artikel über diese Methode) + Pixel-für-Pixel-Angriffe;
- Modellensembles (Top-End-Lösung ... 6 "gestapeltes" ResNet34);
- Intelligente Umgehung von Kombinationen von Zielbildern;
- Im Wesentlichen frühes Stoppen während eines FGVM-Angriffs;
Was in unserem Fall nicht funktioniert hat:
- Hinzufügen eines „Trägheitsmoments“ zur FGVM (obwohl dies für das Team mit niedrigerem Rang funktionierte, ist es also möglich, dass Ensembles + Heuristiken besser funktionierten als ein Moment hinzuzufügen?);
- C & W- Angriff (im Wesentlichen ein End-to-End-Angriff, der auf die Protokolle des White-Box-Modells abzielt) - funktioniert für die White-Box (BY), funktioniert nicht für die Black-Box (CN);
- Ein Ansatz, der auf dem durchgängigen siamesischen LinkNet basiert (Architektur ähnlich wie UNet, jedoch basierend auf ResNet). Funktionierte auch nur für BY;
Was wir nicht versucht haben (hatten keine Zeit, hatten nicht genug Mühe oder waren zu faul):
- Interpretative Augmentationstests für das Lernen von Schülern (ich müsste auch die Deskriptoren wiedergeben - es ist einfach, aber eine so einfache Idee kam nicht sofort);
- Augmentation während des Angriffs - zum Beispiel das Bild von links nach rechts „spiegeln“;
Über den Wettbewerb im Allgemeinen:
- Der Datensatz war "zu klein" (1000 5 + 5 Kombinationen);
- Der Netto-Trainingsdatensatz für Schüler war relativ groß (1 Million + Bilder);
- CE wurde als eine Reihe vorkompilierter Modelle für Caffe vorgestellt (in unseren Umgebungen haben sie natürlich zuerst Fehler ausgegeben). Dies führte auch zu einer gewissen Komplexität, da QW keine Bilder mit Stapeln akzeptierte.
- Der Wettbewerb hatte eine hervorragende Basislinie (Grundlösung), ohne die sich meiner Meinung nach nur wenige direkt ernsthaft engagieren würden;
Ressourcen:
1. Überblick über den Wettbewerb Machines Can See 2018 und wie ich dazu gekommen bin
Wettbewerb und Ansätze
Ehrlich gesagt hat mich ein neues interessantes Gebiet angezogen, die GTX 1080Ti Founders 'Edition mit Preisen und ein relativ geringer Wettbewerb (der mit 20 Personen in einem Wettbewerb bei Kaggle gegen den gesamten ODS mit 20 GPUs pro Team nicht zu vergleichen wäre).
Wie oben erwähnt, bestand der Zweck des Wettbewerbs darin, das CE-Modell zu täuschen, so dass dieses nicht zwischen zwei verschiedenen Personen unterscheiden konnte (im Sinne der L2-Norm / euklidischen Distanz). Nun, da es sich um eine Black Box handelte, mussten wir Studentennetzwerke anhand der bereitgestellten Daten destillieren und hoffen, dass die Gradienten von QW und BYW ähnlich genug sind, um den Angriff auszuführen.
Wenn Sie Artikelrezensionen lesen (zum Beispiel
hier und
da , obwohl solche Artikel nicht wirklich sagen, was in der Praxis funktioniert) und zusammenstellen, was die Top-Teams erreicht haben, können Sie solche Best Practices kurz beschreiben:
- Die einfachsten Angriffe in der Implementierung umfassen BY oder die Kenntnis der internen Struktur des Faltungsnetzwerks (oder einfach der Architektur), auf dem der Angriff ausgeführt wird.
- Jemand im Chat schlug vor, die Inferenzzeit auf dem CE zu verfolgen und seine Architektur zu erraten.
- Wenn Sie auf eine ausreichende Datenmenge zugreifen können, können Sie QW mit gut geschultem QW emulieren
- Vermutlich sind die fortschrittlichsten Methoden:
- End-to-End-C & W-Angriff (hat in diesem Fall nicht funktioniert);
- Intelligente FGSM-Erweiterungen (d. H. Trägheitsmoment + knifflige Ensembles);
Ehrlich gesagt waren wir immer noch verwirrt darüber, dass zwei völlig unterschiedliche End-to-End-Ansätze, die unabhängig voneinander von zwei verschiedenen Personen aus dem Team implementiert wurden, dumm für CH nicht funktionierten. Im Wesentlichen könnte dies bedeuten, dass bei unserer Interpretation der Problemstellung irgendwo ein Datenleck aufgetreten ist, das wir nicht bemerkt haben (oder dass die Hände schief waren). Bei vielen modernen Computer-Vision-Aufgaben sind End-to-End-Lösungen (z. B. Stilübertragung, tiefe Wasserscheide, Bilderzeugung, Reinigung von Rauschen und Artefakten usw.) entweder viel besser als alles, was zuvor war, oder funktionieren überhaupt nicht. Meh.
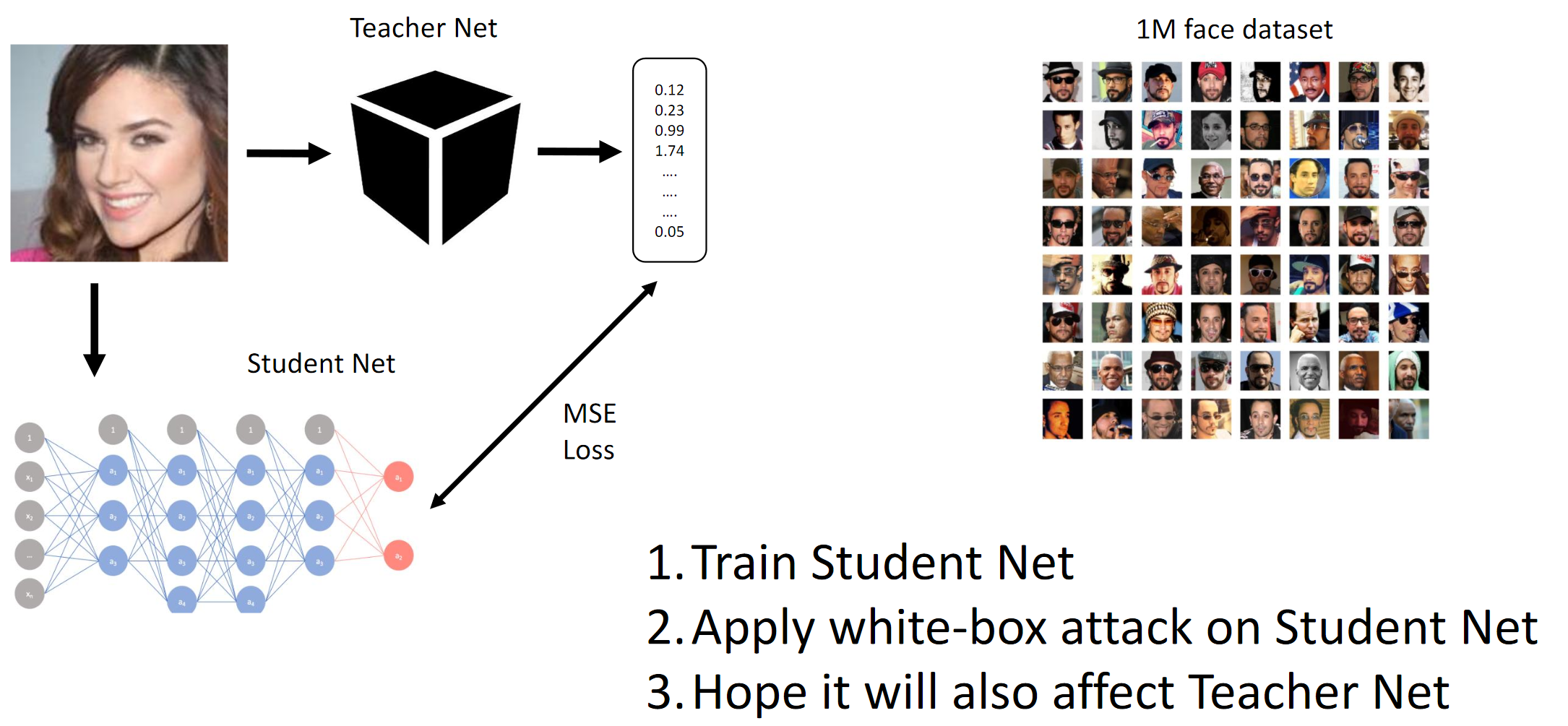 1. Trainieren Sie das Studentennetz. 2. Wenden Sie einen BY-Angriff auf Student Net an. 3. Hope Teacher Net-Angriffe breiten sich ebenfalls ausWie die Gradientenmethode funktioniert
1. Trainieren Sie das Studentennetz. 2. Wenden Sie einen BY-Angriff auf Student Net an. 3. Hope Teacher Net-Angriffe breiten sich ebenfalls ausWie die Gradientenmethode funktioniert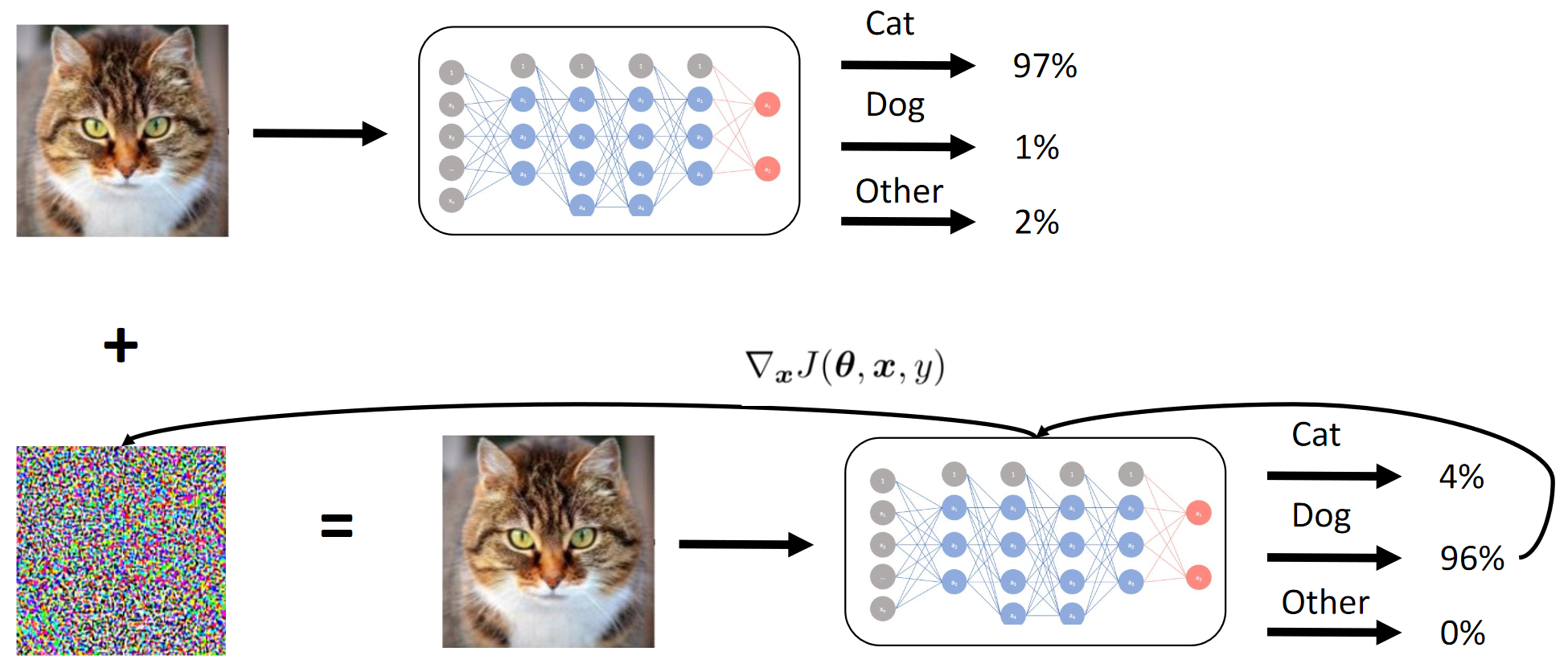
Wir erreichen im Wesentlichen durch Destillation, dass das BY das BY emuliert. Dann werden die Gradienten der Eingabebilder relativ zur Ausgabe des Modells berücksichtigt. Das Geheimnis liegt wie immer in der Heuristik.
Zielmetrik
Die Zielmetrik war die durchschnittliche L2-Norm (euklidischer Abstand) zwischen allen 25 Kombinationen von Quell- und Zielbildern (5 * 5 = 25).
Aufgrund der Einschränkungen der Plattform (CodaLab) war es wahrscheinlich, dass die privaten Punktzahlen (und die Zusammenlegung von Teams) manuell berechnet wurden, was eine solche Geschichte wäre.

Das Team
Ich trat dem Team bei, nachdem ich Student Grids trainiert hatte, besser als alle anderen in der Rangliste (soweit ich weiß), und nach einer kleinen Diskussion mit
Atmyre (sie half mit einem korrekt zusammengestellten QW, da sie selbst mit dem gleichen
Problem konfrontiert war). Dann teilten wir unsere lokalen Ergebnisse, ohne Ansätze und Code zu teilen, und tatsächlich geschah 2-3 Tage vor der Ziellinie Folgendes:
- Meine Endlosmodelle floppten (ja, auch in diesem Fall);
- Ich hatte die besten Studentenmodelle;
- Sie (Teams) hatten die besten heuristischen Variationen für FGVM (ihr Code basierte auf der Basislinie);
- Ich habe gerade Modelle mit Verläufen ausprobiert und eine lokale Geschwindigkeit um 1,1 erreicht. Anfangs wollte ich keine Basislinie aus meinen persönlichen Vorlieben verwenden (ich habe mich selbst herausgefordert).
- Sie hatten zu dieser Zeit nicht genug Rechenleistung;
- Am Ende haben wir unser Glück versucht und uns zusammengetan - ich habe meine Rechenleistung / Faltungs-Neuronale Netze / eine Reihe von Ablationstests investiert. Das Team legte seine Codebasis ein, die sie für ein paar Wochen polierten.
Ich möchte mich noch einmal bei ihr für die unschätzbaren Ratschläge und organisatorischen Fähigkeiten bedanken.
Teamzusammensetzung:
github.com/atmyre - basierend auf den Aktionen, war zunächst der Kapitän des Teams. In der endgültigen Einreichung wurde ein genetischer differentieller Evolutionsangriff hinzugefügt.
github.com/mortido - die beste Implementierung von FGVM-Angriffen mit hervorragenden Heuristiken + trainierte 2 Modelle unter Verwendung des Basiscodes;
github.com/snakers4 - Zusätzlich zu allen Tests, um die Anzahl der Optionen für die Suche nach einer Lösung zu verringern, habe ich 3 Studentenmodelle mit den besten Metriken + bereitgestellter Rechenleistung + geschult, die in der Phase der endgültigen Einreichung und Präsentation der Ergebnisse geholfen haben.
github.com/stalkermustang;Infolgedessen haben wir alle viel voneinander gelernt, und ich bin froh, dass wir unser Glück in diesem Wettbewerb versucht haben. Das Fehlen von mindestens einem von drei Beiträgen würde zu einer Niederlage führen.
2. Destillationsstudent CNN
Beim Training von Studentenmodellen konnte ich die beste Geschwindigkeit erzielen, da ich anstelle des Basiscodes meinen eigenen Code verwendete.
Wichtige Punkte / was hat funktioniert:- Auswahl eines Trainingsplans für jede Architektur einzeln;
- Erstes Training mit Adam + LR Zerfall;
- Sorgfältige Überwachung der Unter- und Überanpassung sowie der Modellkapazität;
- Manuelle Anpassung der Trainingsmodi. Vertrauen Sie den automatischen Schemata nicht vollständig: Sie können funktionieren, aber wenn Sie die Einstellungen gut einstellen, kann die Trainingszeit um das 2-3-fache reduziert werden. Dies ist besonders wichtig bei schweren Modellen wie DenseNet.
- Schwere Architekturen schnitten besser ab als leichte Architekturen, ohne VGG;
- Das Training mit L2-Verlust anstelle von MSE funktioniert ebenfalls, ist jedoch etwas schlechter.
Was hat nicht funktioniert:- Inception-basierte Architekturen (aufgrund hoher Abwärtsabtastung und höherer Eingangsauflösung nicht geeignet). Obwohl das Team auf dem dritten Platz Inception-v1 und Full-Cut-Bilder (~ 250x250) irgendwie verwenden konnte;
- VGG-basierte Architekturen (Überanpassung);
- Lichtarchitekturen (SqueezeNet / MobileNet - Unteranpassung);
- Vergrößerung von Bildern (ohne die Deskriptoren zu ändern - obwohl das Team sie irgendwie vom dritten Platz gezogen hat);
- Arbeiten Sie mit Bildern in voller Größe.
- Ebenfalls am Ende der von den Organisatoren des Wettbewerbs bereitgestellten neuronalen Netze befand sich eine Batch-Norm-Schicht. Dies hat meinen Kollegen nicht geholfen, und ich habe meinen Code verwendet, da ich nicht ganz verstanden habe, warum diese Ebene vorhanden war.
- Verwenden von Ausnahmekarten mit pixelbasierten Angriffen. Ich nehme an, dies gilt eher für Bilder in voller Größe (vergleiche einfach 112x112x Suchbereich und 299x299x Suchraum).
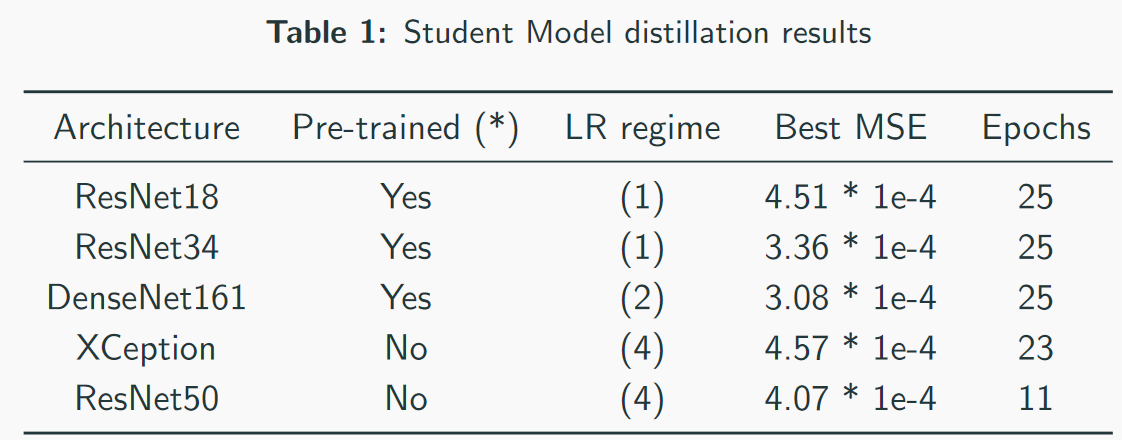 Unsere besten Modelle - beachten Sie, dass die beste Geschwindigkeit 3 * 1e-4 ist. Anhand der Komplexität der Modelle kann man sich grob vorstellen, dass QW ResNet34 ist. In meinen Tests schnitt ResNet50 + schlechter ab als ResNet34.
Unsere besten Modelle - beachten Sie, dass die beste Geschwindigkeit 3 * 1e-4 ist. Anhand der Komplexität der Modelle kann man sich grob vorstellen, dass QW ResNet34 ist. In meinen Tests schnitt ResNet50 + schlechter ab als ResNet34.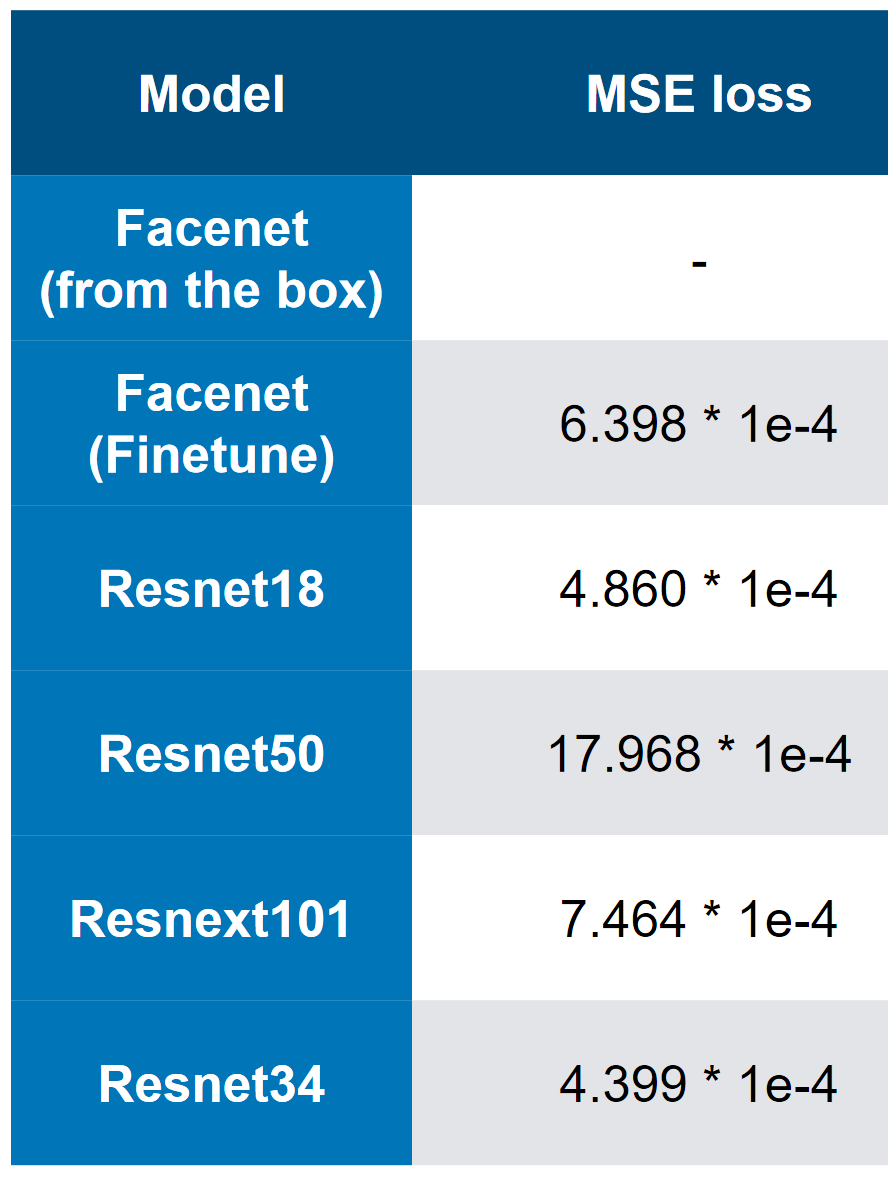 Verlust des ersten Platzes bei MSE
Verlust des ersten Platzes bei MSE3. Die Endgeschwindigkeits- und "Ablations" -Analyse
Wir haben unsere Geschwindigkeit so gesammelt:
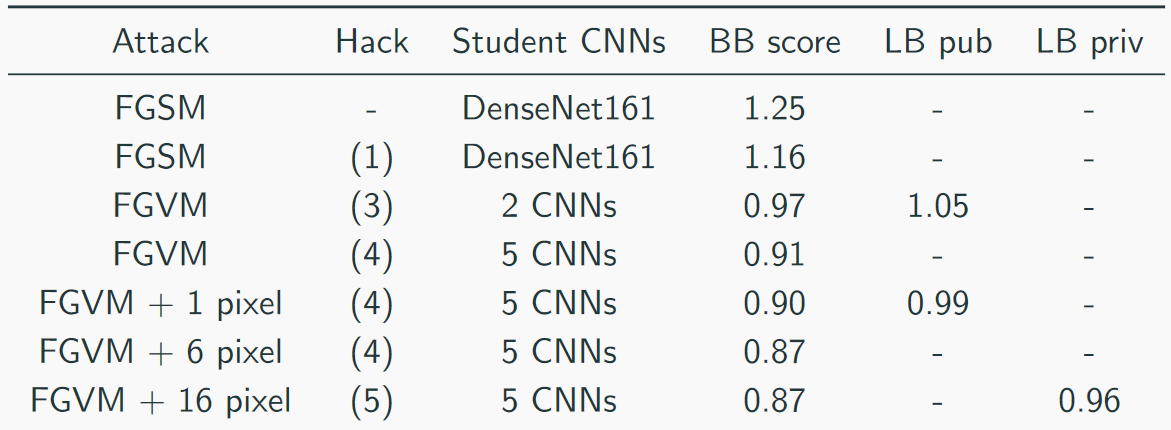
Die Top-Lösung sah so aus (ja, es gab Witze darüber, dass nur das Stapeln von Schlachtung, Sie können sich vorstellen, dass CH eine Schlachtung ist):
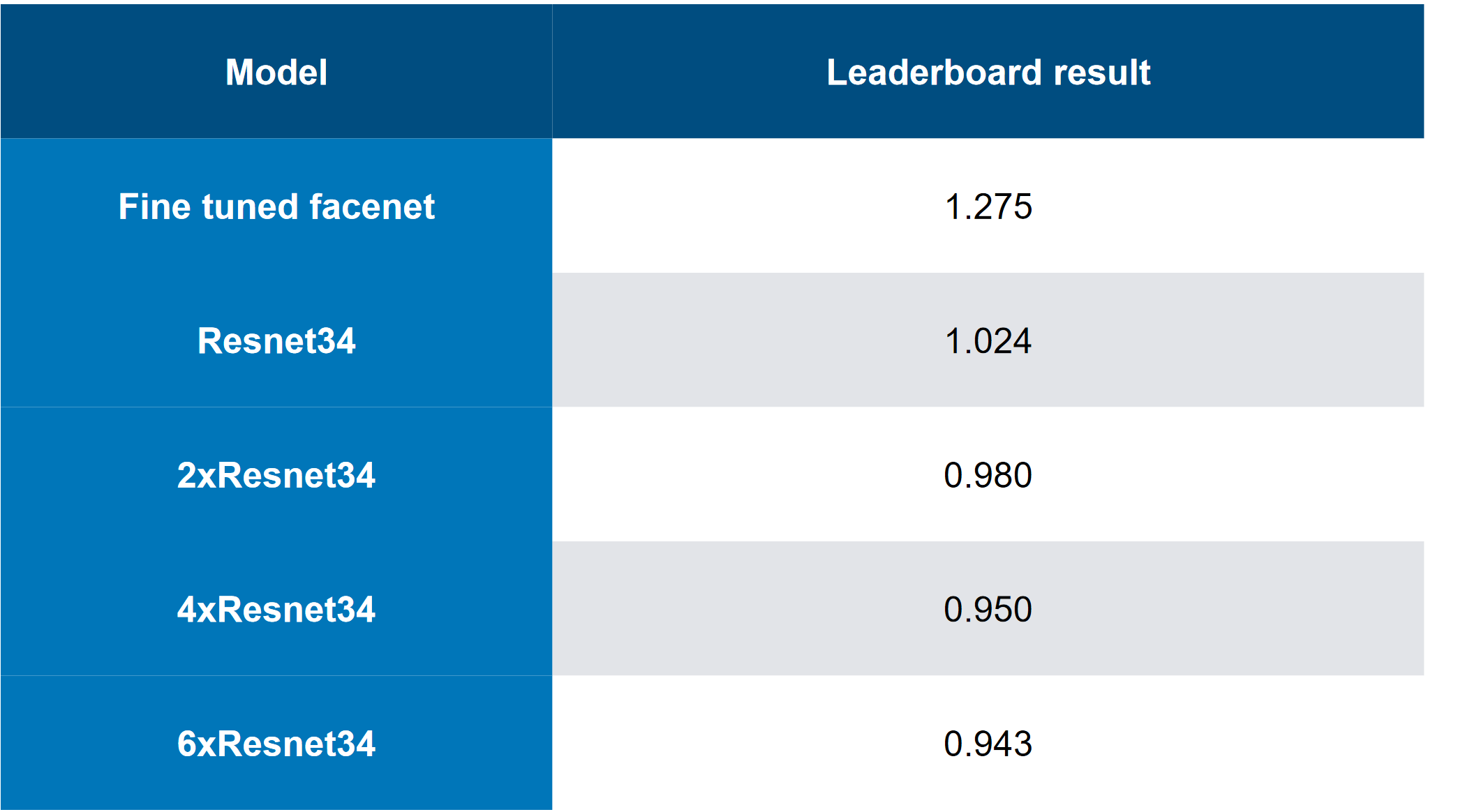
Andere nützliche Ansätze von anderen Teams:
- Adaptiver Parameter epsilon;
- Datenerweiterung
- Trägheitsmoment;
- Der Moment von Nesterov ;
- Spiegelbilder;
- Die Daten ein wenig „hacken“ - es gab nur 1000 eindeutige Bilder und 5000 Bildkombinationen => es konnten mehr Daten generiert werden (nicht 5 Ziele, sondern 10, da die Bilder wiederholt wurden);
Nützliche Heuristiken für FGVM:
- Geräuschentwicklung nach der Regel: Geräusch = eps * clamp (grad / grad.std (), -2, 2);
- Ein Ensemble mehrerer CNNs durch Gewichtung ihrer Gradienten;
- Speichern Sie Änderungen nur, wenn sie den durchschnittlichen Verlust verringern.
- Verwenden Sie Zielkombinationen für ein konsistenteres Targeting
- Verwenden Sie nur Farbverläufe, die höher als der Mittelwert + Standard sind (für FGSM).
Kurzer Sammari:
- In erster Linie war eine "ungeschickte" Entscheidung
- Wir hatten die "abwechslungsreichste" Lösung;
- An dritter Stelle stand die „eleganteste“ Lösung;
End-to-End-Lösungen
Selbst wenn sie versagt haben, sind sie in Zukunft einen weiteren Versuch wert, neue Aufgaben zu erledigen. Sehen Sie sich die Details im Repository an, aber tatsächlich haben wir Folgendes versucht:
- C & W-Angriff;
- Siamesisches LinkNet;
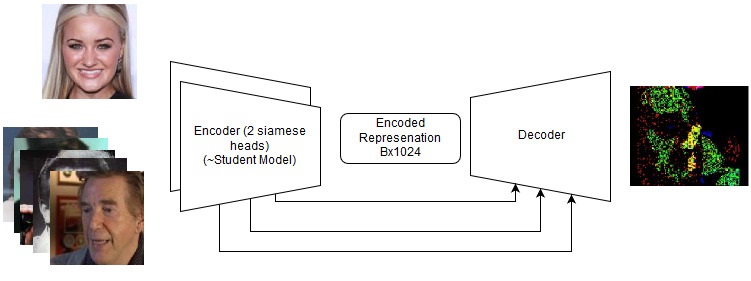 End-to-End-Modell
End-to-End-Modell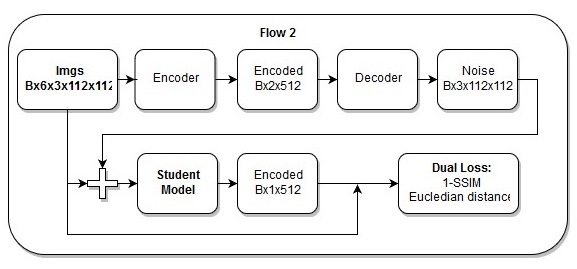 Die Reihenfolge der Aktionen im End-to-End-Modell
Die Reihenfolge der Aktionen im End-to-End-ModellIch denke auch, dass mein
Verlust einfach wunderschön ist.
5. Referenzen und zusätzliches Lesematerial