Veröffentlicht am 17. Mai 2018Unmittelbar nach der Installation des Bienenstocks dachte ich: „Ich frage mich, wie ich die Anzahl der ankommenden und abreisenden Bienen berechnen soll.“
Eine kleine Studie hat gezeigt: Bisher scheint niemand ein gutes nicht-invasives System zur Lösung dieses Problems entwickelt zu haben. Aber es wäre wahrscheinlich nützlich, solche Informationen zu haben, um die Gesundheit des Bienenstocks zu überprüfen.
Zunächst müssen Sie Datenproben sammeln. Raspberry Pi, Standard-Pi-Kamera und Solarpanel: Diese einfache Ausrüstung reicht aus, um alle 10 Sekunden ein Bild aufzunehmen und mehr als 5000 Bilder pro Tag (von 6 bis 21 Uhr) zu speichern.

Unten ist ein Beispielbild ... Wie viele Bienen können Sie zählen?

Was genau ist die Frage?
Zweitens muss das Problem formuliert werden, was genau das neuronale Netzwerk tun soll. Wenn die Aufgabe darin besteht, „Bienen im Bild zu zählen“, können Sie versuchen, bestimmte Zahlen zu ermitteln. Dies scheint jedoch nicht die einfachste Option zu sein, und das Verfolgen einzelner Bienen zwischen Frames macht keinen Spaß. Stattdessen habe ich mich darauf konzentriert, jede Biene im Bild zu lokalisieren.
Eine schnelle Überprüfung eines Standard-Einzelbilddetektors ergab keine besonderen Ergebnisse. Dies ist nicht überraschend, insbesondere angesichts der Dichte der Bienen um den Eingang zum Bienenstock (Hinweis: Das Übertragen von Training funktioniert nicht immer), aber dies ist normal. Ich habe also ein sehr kleines Bild, nur eine Klasse zum Erkennen von Objekten, und es gibt keine besonderen Probleme mit dem Begrenzungsrahmen als solchem. Entscheide einfach, ob es eine Biene gibt oder nicht. Welche Lösung wird einfacher sein?
v1: Vollfaltungsnetzwerk "Biene frisst / nicht" auf einem Fragment
Das erste schnelle Experiment war der Detektor "Biene auf dem Bild ist / ist nicht". Das heißt, wie hoch ist die Wahrscheinlichkeit, dass sich mindestens eine Biene auf diesem Bildfragment befindet. Wenn Sie dies in Form eines
vollständig gefalteten Netzwerks auf sehr kleinen Bildfragmenten tun, können Sie die Daten problemlos in voller Auflösung verarbeiten. Der Ansatz schien zu funktionieren, schlug jedoch für den Bienenstock-Eingangsbereich mit einer sehr hohen Bienendichte fehl.
v2: RGB-Bild → Schwarzweiß-Bitmap
Mir wurde schnell klar, dass das Problem auf das Problem der Bildtransformation reduziert werden kann. Am Eingang ist das Kamerasignal RGB und am Ausgang ist ein Bild eines einzelnen Kanals, wobei das „weiße“ Pixel die Mitte der Biene anzeigt.
 RGB-Eingang (Fragment) und Einkanal-Ausgang (Fragment)
RGB-Eingang (Fragment) und Einkanal-Ausgang (Fragment)Markierung
Der dritte Schritt ist die Kennzeichnung, dh die Zuordnung von Bezeichnungen. Es ist nicht allzu schwierig, eine kleine
TkInter- Anwendung
bereitzustellen , um Bienen im Bild auszuwählen /
abzuwählen und die Ergebnisse in der SQLite-Datenbank zu speichern. Ich habe ziemlich viel Zeit damit verbracht, dieses Tool richtig zu konfigurieren: Jeder, der manuell eine erhebliche Menge an Markierungen durchgeführt hat, wird mich verstehen: /
Später werden wir glücklicherweise sehen, dass Sie mit einer großen Anzahl von Proben mit halbautomatischen Methoden ein ziemlich gutes Ergebnis erzielen können.
Modell
Die Netzwerkarchitektur ist ein ziemlich normales U-Net.
- Vollfaltungsnetzwerk, das auf Fragmenten mit halber Auflösung trainiert wurde, aber mit Bildern mit voller Auflösung arbeitet;
- Die Codierung ist eine Folge von vier Windungen 3 × 3 in Schritten von 2
- Decodierung - eine Folge von Größenänderungen bei den nächsten Nachbarn + 3 × 3-Faltung in Schritten von 1 + Überspringen der Verbindung von den Codierern;
- die letzte Faltungsschicht 1 × 1 mit Schritt 1 mit der Aktivierung der Sigmoidfunktion (dh die binäre Wahl "Biene ist / ist nicht" für jedes Pixel).
Nach einigen empirischen Experimenten entschied ich mich, zur Dekodierung mit halber Auflösung zurückzukehren. Es war genug.
Ich habe dekodiert, indem ich die Größe auf die nächsten Nachbarn geändert habe, anstatt mehr aus Gewohnheit zu dekonvolvieren.
Das Netzwerk wurde nach der
Adam- Methode trainiert und war zu klein, um eine
Chargennormalisierung anzuwenden. Das Design erwies sich als überraschend einfach, eine kleine Anzahl von Filtern reichte aus.

Ich habe die Standardmethode zur Datenerweiterung, zufällige Rotation und Farbverzerrung angewendet. Das Training an Fragmenten bedeutet, dass wir im Wesentlichen eine Variante des zufälligen Schneidens des Bildes erhalten. Ich habe das Bild nicht gedreht, da die Kamera immer auf einer Seite des Bienenstocks steht.
Die Vorhersage der Ausgabe nach der Verarbeitung weist einige Nuancen auf. Mit probabilistischen Ergebnissen erhalten wir eine verschwommene Wolke, in der es Bienen geben kann. Um es in ein klares Bild von einem Pixel pro Biene umzuwandeln, habe ich einen Schwellenwert hinzugefügt, der verwandte Komponenten berücksichtigt und Zentroide mithilfe
des Skimage-Messmoduls erkennt . All dies musste manuell installiert und rein per Auge konfiguriert werden, obwohl es theoretisch als Lernelement am Ende des Stapels hinzugefügt werden kann. Vielleicht macht es Sinn, es in Zukunft zu tun ... :)
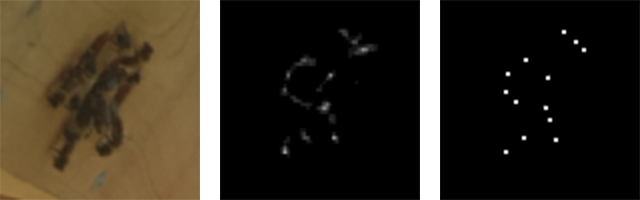 Input, Raw Output und Cluster-Schwerpunkte
Input, Raw Output und Cluster-SchwerpunkteEin paar Tage Verallgemeinerung
An einem Tag
Zunächst wurden Experimente mit Bildern in einem kurzen Zeitraum von einem Tag durchgeführt. Es stellte sich als einfach heraus, aus diesen Daten ein gutes Modell mit einer kleinen Anzahl markierter Bilder (ca. 30) zu erhalten.
 Drei Proben am ersten Tag erhalten
Drei Proben am ersten Tag erhaltenSeit vielen Tagen
Die Dinge wurden komplizierter, als ich anfing, längere Zeiträume von mehreren Tagen in Betracht zu ziehen. Einer der Hauptunterschiede ist der Unterschied in der Beleuchtung (Tageszeit und unterschiedliches Wetter). Ein weiterer Grund ist, dass ich die Kamera jeden Tag manuell installiert habe und sie nur mit Klettverschluss befestigt habe. Der dritte und unerwartetste Unterschied bestand darin, dass Löwenzahnknospen mit dem Wachstum von Gras wie Bienen aussehen (das heißt, in der ersten Runde sah das trainierte Modell die Knospen nicht, und dann erschienen sie und lieferten einen kontinuierlichen Strom falsch positiver Ergebnisse).
Die meisten Probleme wurden durch Datenerweiterung gelöst, und kein einziges Problem wurde kritisch. Im Allgemeinen variieren die Daten nicht zu stark. Dies ist großartig, da Sie sich auf ein einfaches neuronales Netzwerk und Trainingsschema beschränken können.
 Proben in drei Tagen erhalten
Proben in drei Tagen erhaltenPrognosebeispiel
Das Bild zeigt ein Beispiel für eine Prognose. Es ist interessant festzustellen, dass es viel mehr Bienen gibt als auf jedem Bild, das ich manuell beschriftet habe. Dies ist eine großartige Bestätigung dafür, dass ein vollständig faltungsorientierter Ansatz mit Lernen an kleinen Fragmenten wirklich funktioniert.

Das Netzwerk funktioniert in einer Vielzahl von Optionen einwandfrei. Ich nehme an, ein einheitlicher Hintergrund hilft hier, und das Starten des Netzwerks in einem beliebigen Bienenstock führt nicht zu einem so guten Ergebnis.
 Von links nach rechts: hohe Dichte um den Eingang; Bienen unterschiedlicher Größe; Bienen mit hoher Geschwindigkeit!
Von links nach rechts: hohe Dichte um den Eingang; Bienen unterschiedlicher Größe; Bienen mit hoher Geschwindigkeit!Beschriftungstricks
Halbkontrolliertes Training
Die Möglichkeit, eine große Anzahl von Bildern zu erhalten, legt sofort die Idee nahe, ein halbkontrolliertes Training zu verwenden.
Ein sehr einfacher Ansatz:
- Aufnehmen von 10.000 Bildern.
- Beschriftung von 100 Bildern und Trainingsmodell_1.
- Verwenden Sie
model_1 , um die verbleibenden 9900 Bilder zu markieren. - Training
model_2 auf den "beschrifteten" 10.000 Bildern.
Infolgedessen zeigt
model_2 ein besseres Ergebnis als
model_1 .
Hier ist ein Beispiel. Beachten Sie, dass
model_1 einige falsch positive (Mitte links und Grashalm) und falsch negative Auslöser (Bienen um den Eingang zum Bienenstock) zeigt.
 Linkes Modell_1, rechtes Modell_2
Linkes Modell_1, rechtes Modell_2Markieren durch Reparieren eines schlechten Modells
Solche Daten sind auch ein gutes Beispiel dafür, wie das Reparieren eines fehlerhaften Modells schneller ist als das Markieren von Grund auf neu ...
- Wir markieren 10 Bilder und trainieren das Modell.
- Wir verwenden das Modell, um die nächsten 100 Bilder zu markieren.
- Wir verwenden das Markierungswerkzeug, um Markierungen auf diesen 100 Bildern zu korrigieren .
- Bilden Sie das Modell in 110 Bildern neu aus.
- Wir wiederholen ...
Dies ist ein sehr verbreitetes Lernmuster und zwingt Sie manchmal dazu, Ihr Beschriftungswerkzeug ein wenig zu überarbeiten.
Zählen
Die Möglichkeit, Bienen zu entdecken, bedeutet, dass wir sie zählen können! Und zum Spaß zeichnen Sie lustige Grafiken, die die Anzahl der Bienen während des Tages anzeigen. Ich mag die Art und Weise, wie sie den ganzen Tag arbeiten und gegen 16 Uhr nach Hause kommen. :) :)
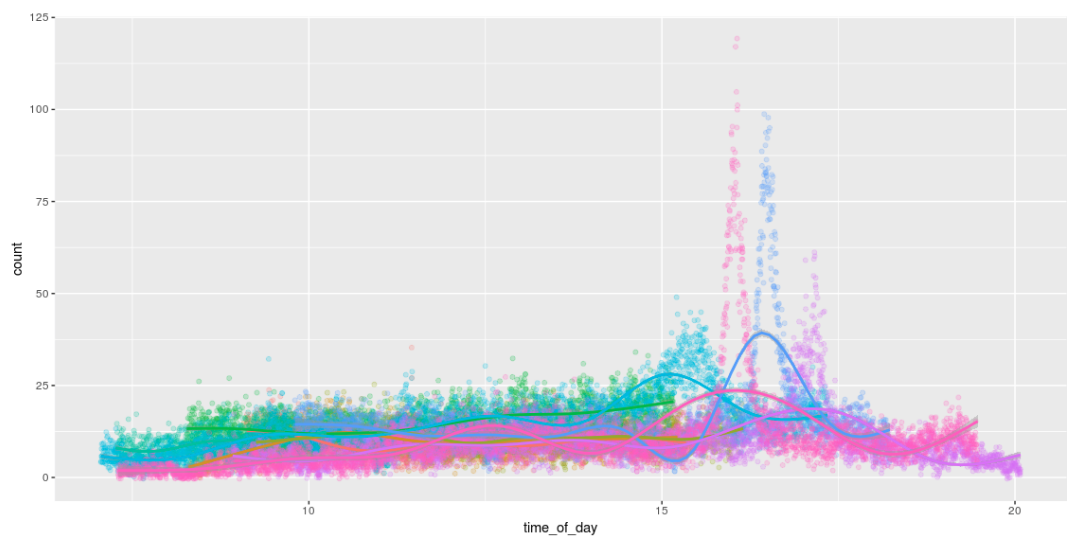
Himbeer-Pi-Ausgabe
Das Starten des Modells auf dem Pi war ein wichtiger Teil dieses Projekts.
Direkt auf dem Eisen Pi
Es war ursprünglich geplant, das TensorFlow-Diagramm einzufrieren und es einfach direkt auf dem Pi auszuführen. Dies funktioniert ohne Probleme, aber nur Pi nimmt nur 1 Bild pro Sekunde auf. : /
Wird auf dem Movidius-Computermodul ausgeführt
Ich war sehr interessiert an der Möglichkeit, mit dem
Movidus Neural Compute Stick ein Modell auf einem Pi zu starten. Dies ist ein erstaunliches Gerät.
Leider ist nichts passiert: /. Die API zum Konvertieren eines TensorFlow-Diagramms in das interne Modellformat unterstützt meine Decodierungsmethode nicht. Daher war es notwendig, die Größe zu erhöhen (Upsizing), indem die Entfaltung verwendet wurde, anstatt die Größe der nächsten Nachbarn zu ändern. Es gibt keine Probleme außer der Tatsache, dass nichts passiert ist. Es gibt viele kleine Schwierigkeiten, aufgrund derer sich die
Fehler vermehrten . Wenn sie behoben sind, können Sie zu diesem Thema zurückkehren ...
Modell v3: RGB-Bild → BienenzählungDies führte mich zur dritten Version des Modells: Können wir direkt vom RGB-Eingang zur Bienenzählung übergehen? Auf diese Weise vermeiden wir Probleme mit nicht unterstützten Operationen auf dem Movidus Neural Compute Stick, obwohl es unwahrscheinlich ist, dass das Ergebnis so gut ist wie im Schwerpunktmodell v2.
Zuerst hatte ich Angst, diese Methode auszuprobieren: Ich dachte, dass es viel mehr Beschriftung erfordern würde (es ist kein fragmentbasiertes System mehr). Aber! Mit einem Modell, das Bienen und viele nicht markierte Daten ziemlich gut findet, können Sie einen guten Satz synthetischer Daten generieren, indem Sie das v2-Modell anwenden und nur die Anzahl der Erkennungen zählen.
Ein solches Modell ist recht einfach zu erlernen und liefert aussagekräftige Ergebnisse ... (obwohl es immer noch nicht so gut ist wie eine einfache Berechnung der vom v2-Modell erkannten Zentroide).
| Tatsächliche und vorhergesagte Anzahl von Bienen in einigen Testproben |
| Das echte | 40 | 19 | 16 | 15 | 13 | 12 | 11 | 10 | 8 | 7 | 6 | 4 |
| v2 (Schwerpunkt) prädiktiv | 39 | 19 | 16 | 13 | 13 | 14 | 11 | 8 | 8 | 7 | 6 | 4 |
| v3 (einfache Berechnung) Prognose | 33.1 | 15.3 | 12.3 | 12.5 | 13.3 | 10,4 | 9.3 | 8.7 | 6.3 | 7.1 | 5.9 | 4.2 |
... leider funktioniert das Modell auf dem Neural Compute Stick
immer noch nicht (das heißt, es funktioniert, liefert aber nur zufällige Ergebnisse). Ich machte noch
ein paar Fehlerberichte und schob das Gadget wieder auf, um später zurückzukehren ... eines Tages ...
Was weiter?
Wie immer blieben ein paar Kleinigkeiten übrig ...
- Start auf dem Neural Compute Stick (NCS); Jetzt warten wir auf ihre Arbeit ...
- Portieren Sie alles auf die eingebaute JeVois-Kamera . Ich habe ein bisschen mit ihr herumgespielt, aber zuerst wollte ich ein Modell auf NCS starten. Ich möchte Bienen mit 120 FPS verfolgen !!!
- Verfolgen Sie Bienen zwischen mehreren Bildern / Kameras, um den optischen Fluss zu visualisieren.
- Informieren Sie sich ausführlicher über die Vorteile eines halbkontrollierten Ansatzes und trainieren Sie ein größeres Modell, um Daten für ein kleineres Modell zu kennzeichnen.
- Entdecken Sie die NCS-Funktionen. Was tun mit dem Einstellen von Hyperparametern?
- Entwickeln Sie anschließend eine kleine Version von FarmBot, um einige genetische Experimente mit CNC-Sämlingen durchzuführen (d. H. Etwas völlig anderes).
Code
Der gesamte Code wird
auf Github veröffentlicht .